曙光Nehalem-EP服务器I620r-G深度评测
The Core Execution Engine: Execution Unit
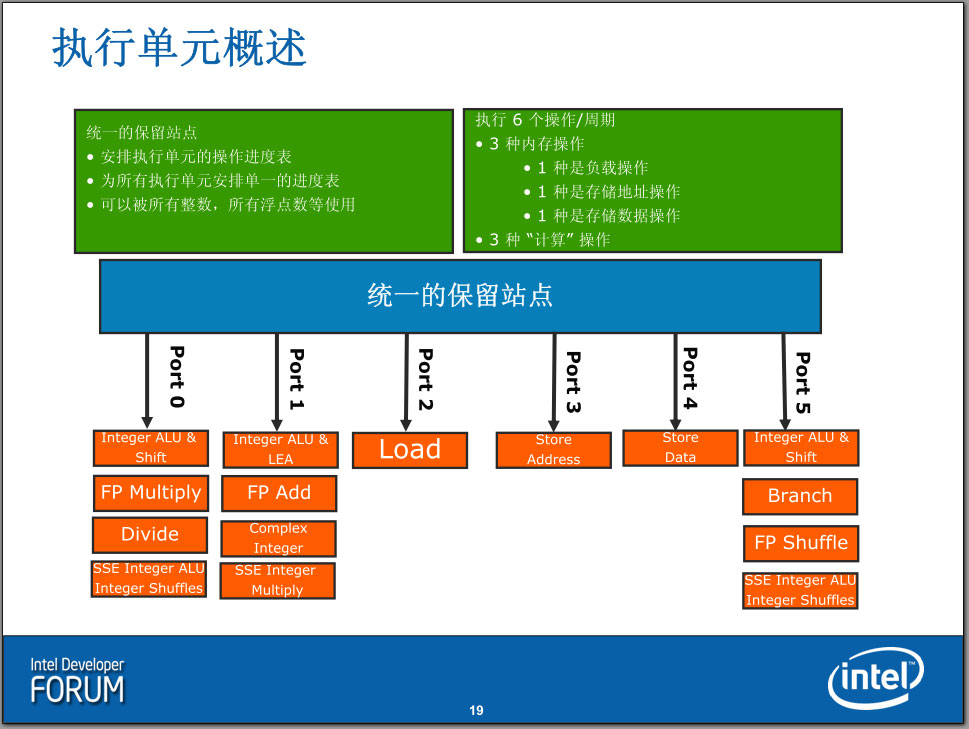
处理器核心执行引擎:执行单元
在为SMT做好准备工作并打乱指令的执行顺序之后,uops通过每时钟周期4条的速度进入Reservation Station中继站(保留站),总共36条目的中继站uops就开始等待超标量(Superscaler)执行引擎乱序执行了。自从Pentium开始,Intel就开始在处理器里面采用了超标量设计(Pentium是两路超标量处理器),超标量的意思就是多个执行单元,它可以同时执行多条没有相互依赖性的指令,从而达到提升ILP指令级并行化的目的。Nehalem具备6个执行端口,每个执行端口具有多个不同的单元以执行不同的任务,然而同一时间只能由一条指令(uop)进入执行端口,因此也可以认为Nehalem有6个“执行单元”,在每个时钟周期内可以执行最多6个操作(或者说,6条指令),和Core一样;令人意外的是,古老的Pentium 4每时钟周期也能执行最多6个指令,虽然它只有4个执行端口,然而其中两个执行端口的ALU单元是双倍速的(Double Pump,每时钟周期执行两条ALU指令)。
Nehalem:Superscale Execution Unit超标量执行单元
中文版本可能反而不便于理解(如负载操作实际上是Load载入操作),下面是英文原版:
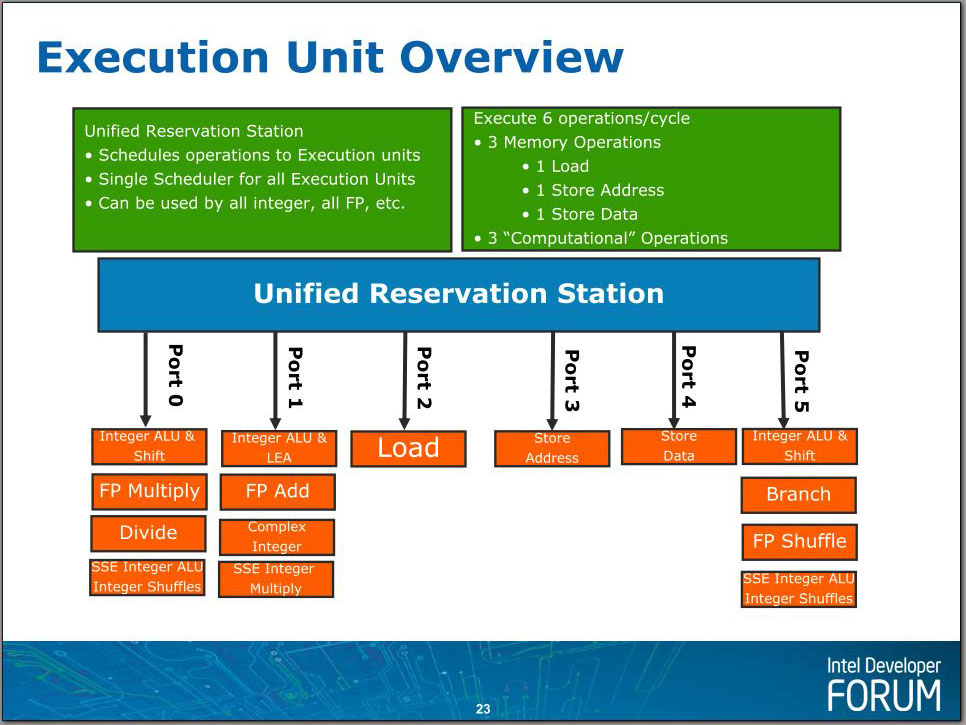
Nehalem:Superscale Execution Unit超标量执行单元
36条目的中继站指令在分发器的管理下,挑选出尽量多的可以同时执行的指令(也就是乱序执行的意思)——最多6条——发送到执行端口。
这些执行端口并不都是用于计算,实际上,有三个执行端口是专门用来执行内存相关的操作的,只有剩下的三个是计算端口,因此,在这一点上Nehalem实际上是跟Core架构一样的,这也可以解释为什么有些情况下,Nehalem和Core相比没有什么性能提升。
计算操作分为两种:使用ALU(Arithmetic Logic Unit,算术逻辑单元)的整数(Integer)运算和使用FPU(Floating Point Unit,浮点运算单元)的浮点(Floating Point)运算。SSE指令(包括SSE1到SSE4)是一种特例,它虽然有整数也有浮点,然而它们使用的都是128bit浮点寄存器,使用的也大部分是FPU电路。在Nehalem中,三个计算端口都可以做整数运算(包括MMX)或者SSE运算(浮点运算不太一样,只有两个端口可以进行浮点ADD和MUL/DIV运算,因此每时钟周期最多进行2个浮点计算,这也是目前Intel处理器浮点性能不如整数性能突出的原因),不过每一个执行端口都不是完全一致:只有端口0有浮点乘和除功能,只有端口5有分支能力(这个执行单元将会与分支预测单元连接),其他FP/SSE能力也不尽相同,这些不对称之处都由统一的分发器来理解,并进行指令的调度管理。没有采用完全对称的设计可能是基于统计学上的考虑。和Core一样,Nehalem的也没有采用Pentium 4那样的2倍频的ALU设计(在Pentium 4,ALU的运算频率是CPU主频的两倍,因此整数性能明显要比浮点性能突出)。
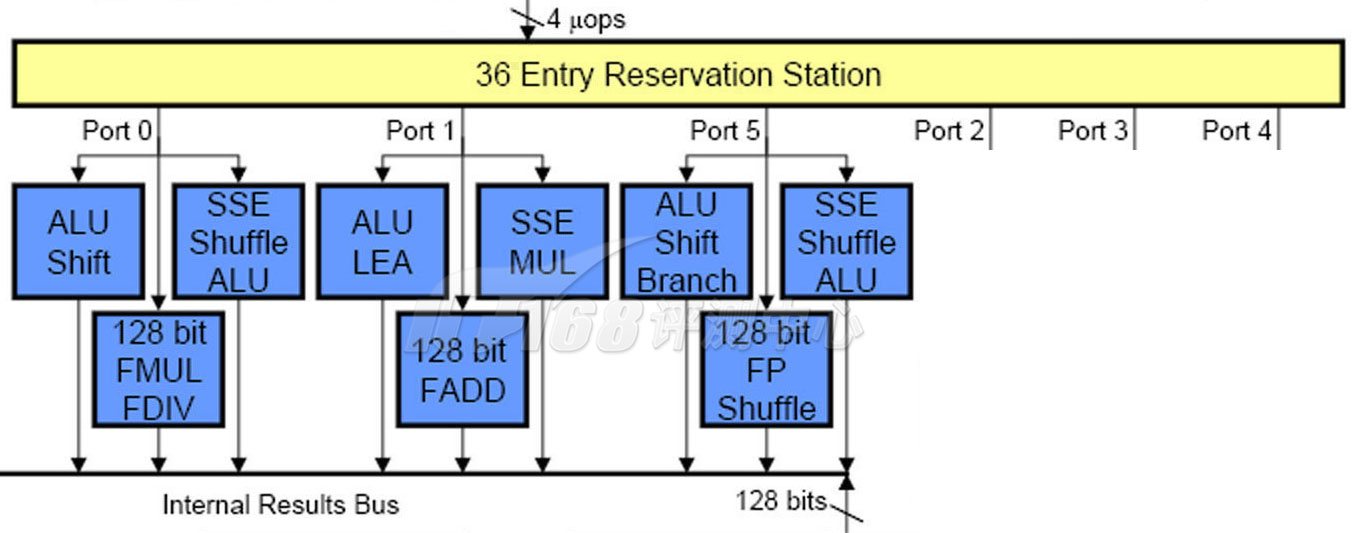
The Core Execution Engine: "Computional" Unit
Nehalem的ALU和FP/SSE单元都使用了相同的三个端口,相比之下,Barcelona Opteron的FP/SSE单元和ALU单元具有不同的入口,因此每时钟周期可以同时执行最多6条计算指令。不过,Barcelona Opteron的3存取操作使用和ALU单元一样的端口,因此其执行单元每时钟周期可以同时执行的指令仍然为6条。
不幸的是,虽然可以同时执行的指令很多,然而在流水线架构当中运行速度并不是由最“宽”的单元来决定的,而是由最“窄”的单元来决定的。这就是木桶原理,Opteron的解码器后端只能每时钟周期输出3条uops,而Nehalem/Core2则能输出4条,因此它们的实际最大每时钟运行指令数是3/4,而不是6。同样地,多少路超标量在这些乱序架构处理器中也不再按照运算单元来划分,Core Duo及之前(到Pentium Pro为止)均为三路超标量处理器,Core 2/Nehalem则为四路超标量处理器。可见在微架构上,Nehalem/Core显然是要比其他处理器快一些。顺便说一下,这也是Intel在超线程示意图中,使用4个宽度的方块来表示而不是6个方块的原因。

