曙光Nehalem-EP服务器I620r-G深度评测
The Core Execution Engine: Load/Store Unit
处理器核心执行引擎:存取单元
运算需要用到数据,也会生成数据,这些数据存取操作就是存取单元所做的事情,实际上,Nehalem和Core的存取单元没什么变化,仍然是3个。
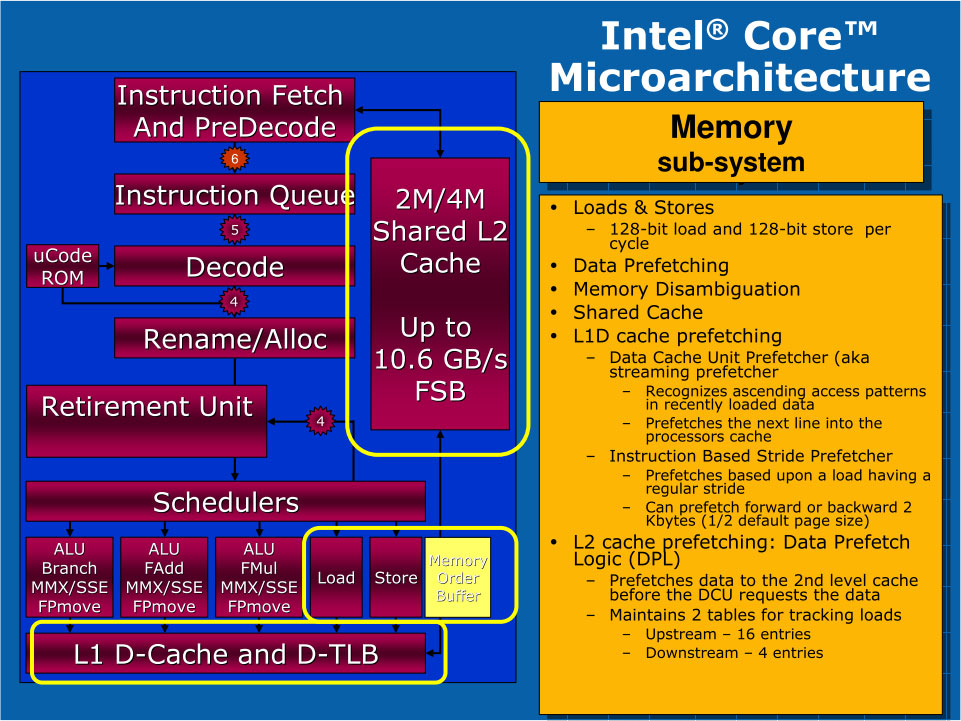
Nehalem的Load/Store结构和Core架构一样
这三个存取单元中,一个用于所有的Load操作(地址和数据),一个用于Store地址,一个用于Store数据,前两个数据相关的单元带有AGU(Address Generation Unit,地址生成单元)功能(NetBurst架构使用快速ALU来进行地址生成)。
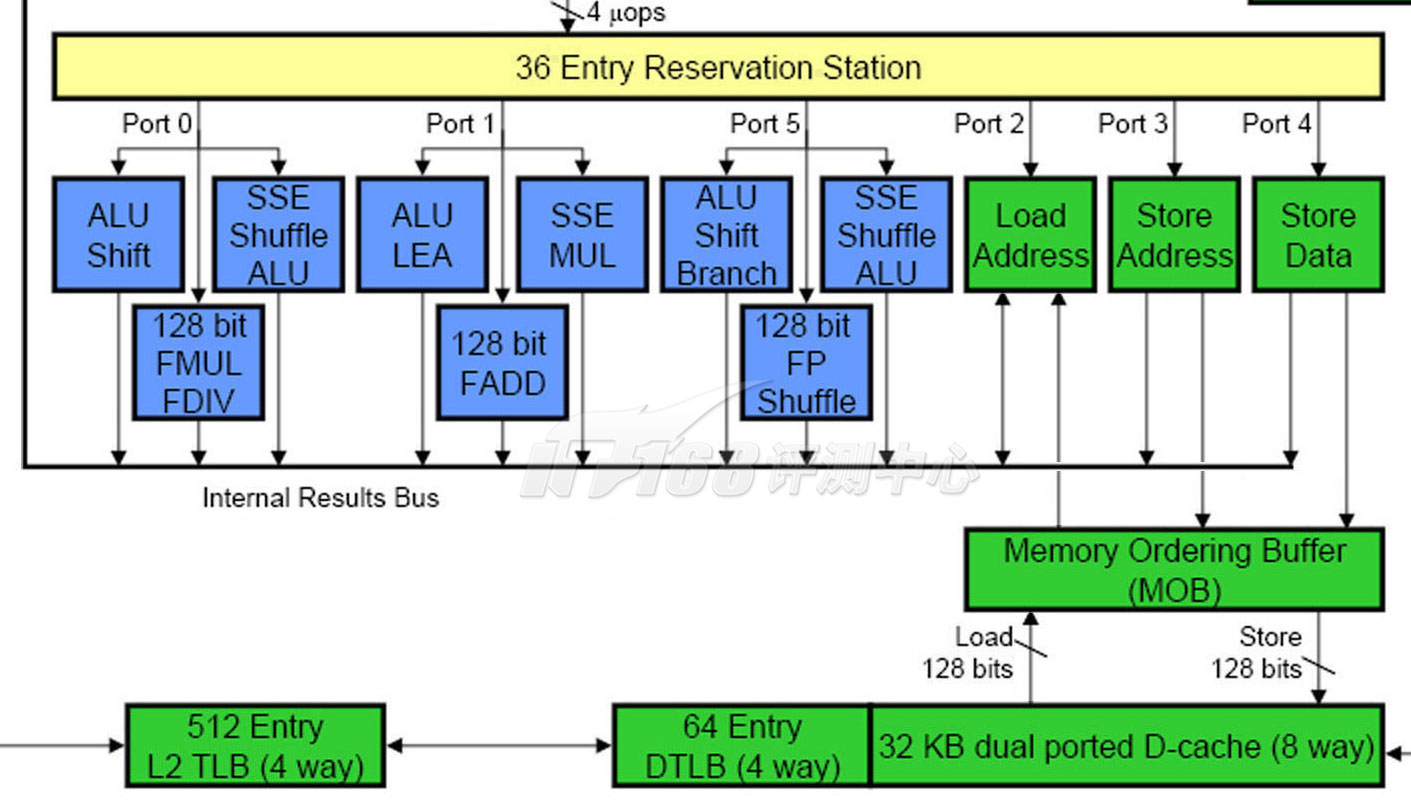
The Core Execution Engine: Load/Store Unit
在乱序架构中,存取操作也可以打乱进行。类似于指令预取一样,Load/Store操作也可以提前进行以降低延迟的影响,提高性能。然而,由于Store操作会修改数据影响后继的Load操作,而指令却不会有这种问题(寄存器依赖性问题通过ROB解决),因此数据的乱序操作更为复杂。
 |
| 数据乱序操作的困境:Load/Store依赖性 |
如上图所示,第一条ALU指令的运算结果要Store在地址Y(第二条指令),而第九条指令是从地址Y Load数据,显然在第二条指令执行完毕之前,无法移动第九条指令,否则将会产生错误的结果。同样,如果CPU也不知道第五条指令会使用什么地址,所以它也无法确定是否可以把第九条指令移动到第五条指令附近。

内存数据相依性预测功能(Memory Disambiguation)
内存数据相依性预测功能(Memory Disambiguation)可以预测哪些指令是具有依赖性的或者使用相关的地址(地址混淆,Alias),从而决定哪些Load/Store指令是可以提前的,哪些是不可以提前的。可以提前的指令在其后继指令需要数据之前就开始执行、读取数据到ROB当中,这样后继指令就可以直接从中使用数据,从而避免访问了无法提前Load/Store时访问L1缓存带来的延迟(3~4个时钟周期)。
不过,为了要判断一个Load指令所操作的地址没有问题,缓存系统需要检查处于in-flight状态(处理器流水线中所有未执行的指令)的Store操作,这是一个颇耗费资源的过程。在NetBurst微架构中,通过把一条Store指令分解为两个uops——一个用于计算地址、一个用于真正的存储数据,这种方式可以提前预知Store指令所操作的地址,初步的解决了数据相依性问题。在NetBurst微架构中,Load/Store乱序操作的算法遵循以下几条原则:
- 如果一个对于未知地址进行操作的Store指令处于in-flight状态,那么所有的Load指令都要被延迟
- 在操作相同地址的Store指令之前Load指令不能继续执行
- 一个Store指令不能移动到另外一个Store指令之前
这种原则的问题也很明显,比如第一条原则会在一条处于等待状态的Store指令所操作的地址未确定之前,就延迟所有的Load操作,显然过于保守了。实际上,地址冲突问题是极少发生的。根据某些机构的研究,在一个Alpha EV6处理器中最多可以允许512条指令处于in-flight状态,但是其中的97%以上的Load和Store指令都不会存在地址冲突问题。
基于这种理念,Core微架构采用了大胆的做法,它令Load指令总是提前进行,除非新加入的动态混淆预测器(Dynamic Alias Predictor)预测到了该Load指令不能被移动到Store指令附近。这个预测是根据历史行为来进行的,据说准确率超过90%。
在执行了预Load之后,一个冲突监测器会扫描MOB的Store队列,检查该是否有Store操作与该Load冲突。在很不幸的情况下(1%~2%),发现了冲突,那么该Load操作作废、流水线清除并重新进行Load操作。这样大约会损失20个时钟周期的时间,然而从整体上看,Core微架构的激进Load/Store乱序策略确实很有效地提升了性能,因为Load操作占据了通常程序的1/3左右,并且Load操作可能会导致巨大的延迟(在命中的情况下,Core的L1D Cache延迟为3个时钟周期,Nehalem则为4个。L1未命中时则会访问L2缓存,一般为10~12个时钟周期。访问L3通常需要30~40个时钟周期,访问主内存则可以达到最多约100个时钟周期)。Store操作并不重要,什么时候写入到L1乃至主内存并不会影响到执行性能。
|
| 图9:数据相依性预测机制的优势 |
如上图所示,我们需要载入地址X的数据,加1之后保存结果;载入地址Y的数据,加1之后保存结果;载入地址Z的数据,加1之后保存结果。如果根据Netburst的基本准则,在第三条指令未决定要存储在什么地址之前,处理器是不能移动第四条指令和第七条指令的。实际上,它们之间并没有依赖性。因此,Core微架构中则“大胆”的将第四条指令和第七条指令分别移动到第二和第三指令的并行位置,这种行为是基于一定的猜测的基础上的“投机”行为,如果猜测的对的话(几率在90%以上),完成所有的运算只要5个周期,相比之前的9个周期几乎快了一倍。

