曙光Nehalem-EP服务器I620r-G深度评测
【IT168评测中心】2009年3月31号,春季的最后一天,在Nehalem处理器架构的桌面版本Core i7(代号Bloomfield)发布134日之后,其双路服务器版本Nehalem-EP(代号Gainestown)终于发布了。Nehalem-EP处理器是Nehalem处理器架构的集中体现,在桌面版本乃至移动版本上看不到的多QPI总线等特性开始在Nehalem-EP上现身——我们早已经知道,不同于之前的Core处理器,Nehalem架构是为企业应用而设计,因此,Nehalem架构的精髓,只有在服务器版本Nehalem-EP/Nehalem-EX上才能完完全全地看到。

两个Xeon E5540处理器,主频2.53GHz,QPI频率2.93GHz
Nehalem架构仍然基于成熟的Core微架构并在其基础上进行改进,因此,桌面版本Nehalem使用了Core i7的系列名称(上一代则是Core 2),服务器版本也不例外,仍然使用了Xeon的名称,不过处理器系列更新为5500(上一代为5400,上上一代为5300)。
 |
| Nehalem桌面版本——Core i7 920与其搭档Intel X58主板 |
几天前,我们曝光了Nehalem-EP处理器——Xeon E5540的实物(同时给出了基于X58主板的上机图),并发布了我们根据当前资料做出的架构分析,不过由于NDA保密协议的缘故,我们不能给出其性能数据,现在随着Nehalem-EP的正式发布,禁令也相应消失,下面我们终于可以尽情地享受Nehalem-EP的极致性能了。由于篇幅较多,因此建议读者们使用下面的导航功能,直接打开到感兴趣的页面。

曙光提供的Nehalem-EP测试样机,型号为I620r-G,采用了Xeon E5540处理器
测试样机由大家都熟知能详的曙光(Dawning)提供,配置了两个Nehalem-EP Xeon E5540处理器,频率为2.53GHz。曙光也是最早向我们提供Nehalem-EP服务器样机的厂商。

对于Intel的Tick-Tock战略已经是老生常谈了——从另一方面讲,这标明了Tick-Tock战略的成功之处,一个简单、明晰、有序和易于理解的发展计划,对合作厂商、用户和投资者都是极为有利的。TIck-Tock战略简而言之就是Intel处理器在奇数年进行制程转换(Tick),例如2005年的65nm和2007年的45nm,而在偶数年进行处理器的架构更新(Tock),Nehalem架构发布的2008年轮换到了Tock,也就是处理器的架构更新。
Nehalem作为Intel用以取代Penryn微架构的新一代处理器架构,和Penryn相比,Nehalem的微架构并非是全新的,不过,架构上则是一个很大的飞跃:Nehalem采用了直联架构。除此之外,Nehalem还具有一个鲜明的设计理念,就是采用了可扩展的模块化设计,它将处理器划分为两个部分:Core核心和Uncore非核心(或者叫“核外”),所有产品线的Nehalem处理器,其Core核心部分都是一样的,只是Uncore部分可能不同,以满足Intel对其提出的动态可扩展的要求。Nehalem满足了这个要求,它的内核具有可扩展的高可伸缩架构。
由于共处在一个Tick-Tock上,因此Nehalem和Penryn都同样属于45nm工艺,从65nm工艺转变到45nm工艺带来的巨大能耗降低已经无法再次重新,因此Nehalem就不再注重于能耗的降低,而是注重于性能的提升,这样的设计理念,带来了处理器架构的巨大变化,这些变化均面向性能的提高,也即是说,我们可以期望Nehalem具有着强大的性能。
Harpertown是基于45nm Penryn的四核Xeon DP处理器:两个“双核”粘结而成
可以说,Core现在在所有产品线上都获得了成功——因为它强劲的性能,以及很好的功耗表现,然而,Core确实具有一个移动计算的起源,它的原始架构都是围绕着这个中心来设计。例如,古老的双核设计:笔记本不需要太多的处理核心(即使是现在,也只有少量工作站级别的笔记本配置了四核),让目前的Core架构已经不太适合于服务器市场,虽然6核心的7400系列Xeon已经推出,不过它和当前的四核产品一样,都是多个“双核”粘结在一起的产物。不会有基于Core架构(不是Core微架构)的8核心产品了,那样做的代价太大,基于FSB方面的原因,性能将会很受限制(六核心的Dunnington是Core架构/FSB总线的绝唱)。

六核心45nm Penryn至强Dunnington是Core架构/FSB总线的绝唱,并融合了Nehalem的“原生单核”设计
Core架构具有一个移动计算的起源,它源自Banias Pentium M处理器,Pentium M处理器是以色列(Israel)的海法(Haifa)研究中心专门针对笔记本电脑的产品,特点是高效、低耗。时值2004年,开发NetBurst架构的美国德克萨斯州(Texas)的奥斯丁(Austin)设计团队尚在设计Tejas(Prescott的下一代)。很快NetBurst失败,Core架构被扶正,之后迅速地成为Intel的主要架构,产品开始扩展到桌面乃至服务器产品线(很可怕地,Austin设计团队被分派去设计一个极低功耗的CPU,就是后来的Atom凌动处理器)。
初代Core架构:Banias Pentium M
Core架构的成功我们都已经看到了,然而随着时间的流逝,如古老的双核设计(4核是两个双核粘在一起,6核则是三个双核粘结)、过时的FSB总线以及没有充分为64位计算准备等等,让其无法获得很好的伸缩性,难以未来需要高性能多处理器需求的企业级市场。此外,在NetBurst架构上耗资了数亿美元的HTT超线程技术也没能得到体现,Intel需要制作一款新的处理器产品来满足未来的需求。
Intel对Core架构作出了改动,首先它将原来的架构扩展为原生4核(甚至6核、8核)设计,并为多核的需要准备了新的总线QPI来满足巨大的带宽需求,结果就是Nehalem内核。Nehalem内核还采用了集成内存控制器的设计,也是为了满足多核心巨大的带宽需求(丛目前来看,Nehalem-EP不会有6核、8核的型号,这些产品会出现在Nehalem-EX上面)。
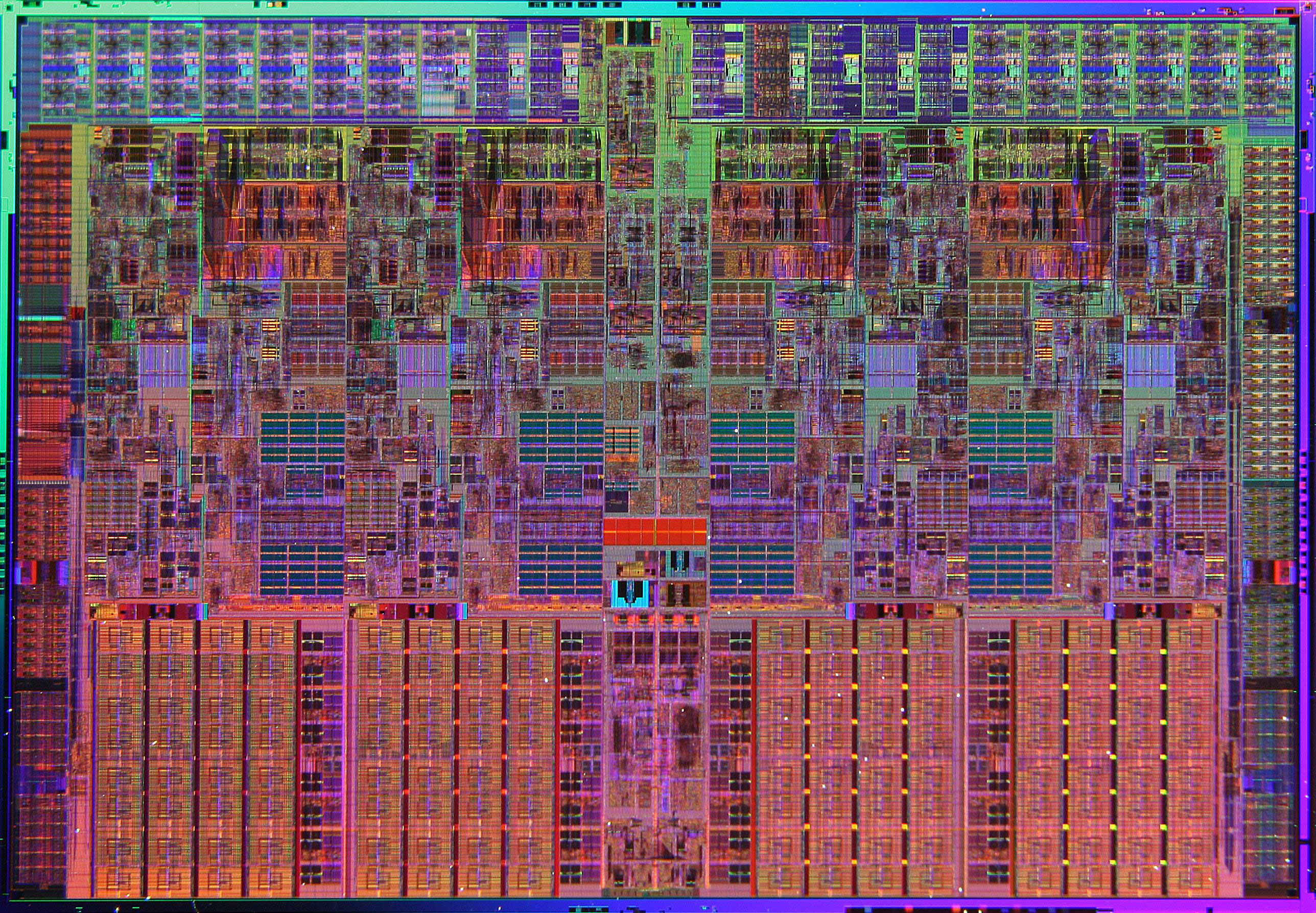
4核心Nehalem-EP处理器晶元图

4核心Nehalem-EP处理器的一些简要参数
了解Nehalem的设计思想之后,我们先来看看Nehalem微架构设计,和前面所说的一样,基于模块化设计,所有的Nehalem处理器的微架构都是一致的,因此接下来的内容适合于包括移动、桌面在内的Nehalem处理器。
The Core: Partition
核心:功能区间划分
首先我们需要清楚地知道,Nehalem是一款OOOE(Out of Order Execute)乱序执行的Superscaler超标量x86处理器。x86处理器上的超标量设计是从Pentium开始,乱序执行则是从Pentium Pro开始(Pentium仍然是IOE-In Order Execute的)。现在的乱序执行处理器采用的流水线可能深度不一,但是它们都离不开取指(Instruction Fetch)、解码(Decode)、执行(Execute)、串行顺序回退(Retire)这四个阶段。
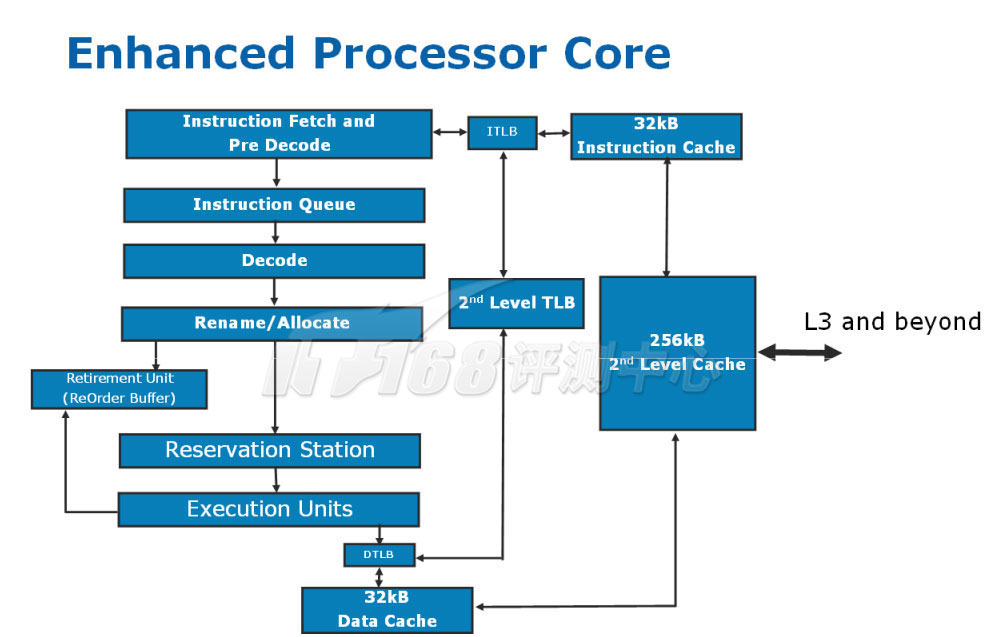
官方公布的简单的架构图
既然是乱序执行,那么四个阶段中,取指令、指令解码和回退阶段实际上仍然是属于In-Order顺序的。加上内存存取方面的内容,Nehalem处理器可以按下面的颜色划分:

Nehalem Microarchitecture,经笔者整理
紫色部分属于取指令部分,橙色则属于解码部分。黄色部分是乱序执行的准备部分(灰色Retirement Register File属于乱序架构的Retire部分),蓝色方框是计算单元,绿色方框是内存子系统(包括紫色部分的指令缓存在内),计算单元和内存子系统的一部分(存取单元)一起成为乱序执行单元。绿色方框包含了Core和Uncore两部分,Uncore的内容,不同系列的Nehalem的处理器是不同的,就上图标明和本文谈论到的,都适用于我们的主角:Nehalem-EP处理器。
下面就大致从指令拾取开始介绍Nehalem的微架构,这些内容就经过了笔者的多方面查证以确保具有较高的准确性。然而由于内容太多,错漏难以避免,欢迎读者们一一指出。
The Core Front-End: Instruction Fetch
处理器核心前端:指令拾取
处理器在执行指令之前,必须先装载指令。指令会先保存在L1缓存的I-cache(Instruction-cache)指令缓存当中,Nehalem的指令拾取单元使用128bit带宽的通道从I-cache中读取指令。这个I-cache的大小为32KB,采用了4路集合关联,在后面的存取单元介绍中我们可以得知这种比Core更少的集合关联数量是为了降低延迟。
为了适应超线程技术,RIP(Relative Instruction Point,相对指令指针)的数量也从一个增加到了两个,每个线程单独使用一个。

The Core Front-End: Instruction Fetch
指令拾取单元包含了分支预测器(Branch Predictor),分支预测是在Pentium Pro处理器开始加入的功能,预测如if then这样的语句的将来走向,提前读取相关的指令并执行的技术,可以明显地提升性能。指令拾取单元也包含了Hardware Prefetcher,根据历史操作预先加载以后会用到的指令来提高性能,这会在后面得到详细的介绍。

两级分支预测机制
当分支预测器决定了走向一个分支之后,它使用BTB(Branch Target Buffer,分支目标缓冲区)来保存预测指令的地址。Nehalem从以前的一级BTB升级到了两个级别,这是为了适应很大体积的程序(数据库以及ERP等应用,跳转分支将会跨过很大的区域并具有很多的分支)。Intel并没有提及BTB详细的结构。与BTB相对的RSB(Return Stack Buffer,返回堆栈缓冲区)也得到了提升,RSB用来保存一个函数或功能调用结束之后的返回地址,通过重命名的RSB来避免多次推测路径导致的入口/出口破坏。RSB每个线程都有一个,一个核心就拥有两个,以适应超线程技术的存在。

RSB:重命名的返回堆栈缓冲器
指令拾取单元使用预测指令的地址来失去指令,它通过访问L1 ITLB里的索引来继续访问L1I Cache,128条目的小页面L1 ITLB按照两个线程静态分区,每个线程可以获得64个条目,这个数目比Core 2的少。当关闭超线程时,单独的线程将可以获得全部的TLB资源。除了小页面TLB之外,Nehalem还每个线程拥有7个条目的全关联(Full Associativity)大页面ITLB,这些TLB用于访问2M/4M的大容量页面,每个线程独立,因此关闭超线程不会让你得到14个大页面ITLB条目。
指令拾取单元通过128bit的总线将指令从L1I Cache拾取到一个16Bytes(刚好就是128bit)的预解码拾取缓冲区。128位的带宽让人有些迷惑不解,Opteron一早就已经使用了256bit的指令拾取带宽。最重要的是,L1D和L1I都是通过256bit的带宽连接到L2 Cache的。
由于一般的CISC x86指令都小于4Bytes(32位x86指令;x86指令的特点就是不等长),因此一次可以拾取4条以上的指令,而预解码拾取缓冲区的输出带宽是6指令每时钟周期,因此可以看出指令拾取带宽确实有些不协调,特别是考虑到64位应用下指令会长一些的情况下(解码器的输入输出能力是4指令每时钟周期,因此32位下问题不大)。
75%的x86指令小于4Bytes。
指令拾取结束后会送到18个条目的指令队列,在Core架构,送到的是LSD循环流缓冲区,在后面可以看到,Nehalem通过将LSD移动后更靠后的位置来提高性能。
The Core Front-End: Decode
处理器核心前端:解码
在将指令充填到可容纳18条目的指令队列之后,就可以进行解码工作了。解码是类RISC(精简指令集或简单指令集)处理器导致的一项设计,从Pentium Pro开始在IA架构出现。处理器接受的是x86指令(CISC指令,复杂指令集),而在执行引擎内部执行的却不是x86指令,而是一条一条的类RISC指令,Intel称之为Micro Operation——micro-op,或者写为µ-op,一般用比较方便的写法来代替希腊字母:u-op或者uop。相对地,一条一条的x86指令就称之为Macro Operation,或macro-op。
RISC架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过深长的流水线达到很高的频率(例如31级流水线的Pentium 4……当然Pentium 4要超过5GHz的屏障需要付出巨大的功耗代价),IBM的Power6就可以轻松地达到4.7GHz的起步频率。关于Power6的架构的非常简单的介绍可以看《机密揭露:Intel超线程技术有多少种?》,我们继续说Nehalem:和RISC相反,CISC指令的长度不固定,执行时间也不固定,因此Intel的RISC/CISC混合处理器架构就要通过解码器将x86指令翻译为uop,从而获得RISC架构的长处,提升内部执行效率。
和Core一样,Nehalem的解码器也是4个:3个简单解码器加1个复杂解码器。简单解码器可以将一条x86指令(包括大部分SSE指令在内)翻译为一条uop,而复杂解码器则将一些特别的(单条)x86指令翻译为1~4条uops——在极少数的情况下,某些指令需要通过额外的可编程microcode解码器解码为更多的uops(有些时候甚至可以达到几百个,因为一些IA指令很复杂,并且可以带有很多的前缀/修改量,当然这种情况很少见),下图Complex Decoder左方的ucode方块就是这个解码器,这个解码器可以通过一些途径进行升级或者扩展,实际上就是通过主板Firmware里面的Microcode ROM部分。
2006年进行的一个研究当中表示,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
之所以具有两种解码器,是因为仍然是关于RISC/CISC的一个事实:大部分情况下(90%)的时间内处理器都在运行少数的指令,其余的时间则运行各式各样的复杂指令(不幸的是,复杂就意味着较长的运行时间),RISC就是将这些复杂的指令剔除掉,只留下最经常运行的指令(所谓的精简指令集),然而被剔除掉的那些指令虽然实现起来比较麻烦,却在某些领域确实有其价值,RISC的做法就是将这些麻烦都交给软件,CISC的做法则是像现在这样:由硬件设计完成。因此RISC指令集对编译器要求很高,而CISC则很简单。对编程人员的要求也类似。
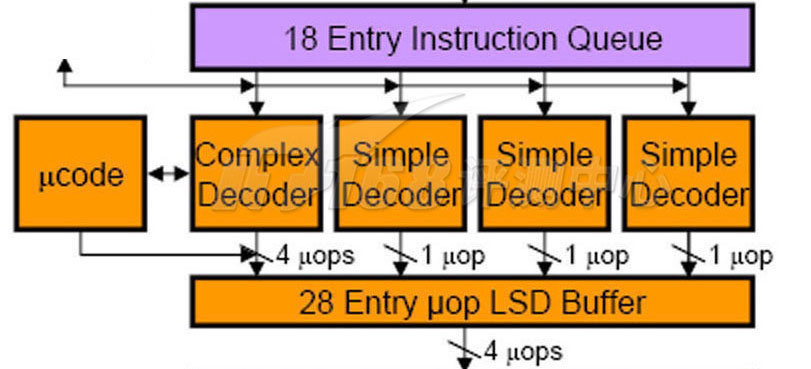
The Core Front-End: Decode
作为对比,AMD的处理器从K8以来就具有强大的三组复杂解码器,并且大部分指令都可以解码为1~2条AMD的Micro-operations(这个Micro-op和Intel的uop是不同的东西)。

Macro Fusion功能
在进行解码的时候,会碰到Intel在Core 2开始加入的技术:Macro Fusion。关于Macro Fusion可以看这里《64位对决32位 SPEC CPU运算效能测试》,这项技术可以将一些比较并跳转的分支x86指令集合(CMP+TEST/JCC)最终解码为单条uop(CMP+JCC),从而提升了解码器的带宽、降低执行指令数量,让系统运行效率更高。和Core 2相比,Nehalem现在支持更多的比较/跳转分支情况,如JL/JNGE、JGE/JNL、JLE/JNG、JG/JNLE等,此外,Nehalem也开始更多地为服务器平台考虑,它的Macro Fusion开始支持64位模式,而不是Core 2的只支持32位模式。随着内存容量的日益增长,即使是在桌面平台及移动平台,64位用户也在不断增加,因此这个改进对用户很有吸引力。
除了将多条Macro Ops(就是x86指令)聚合之外,Nehalem也支持将多条uops聚合,也就是Micro Fusion功能,用于降低uop的数量。这是一个从Pentium M开始存在的老功能了,它在顺序上是在比Macro Fusion后面的后面,也就是在LSD循环流监测器后方。据说,Micro Fusion可以提升5%的整数性能和9%的浮点性能,而Macro Fusion则可以降低10%的uop数量。
The Core Front-End: Loop Stream Detector
处理器核心前端:循环流检测
在解码为uop之后Nehalem会将它们都存放在一个叫做uop LSD Buffer的缓存区。在Core 2上,这个LSD Buffer是出现在解码器前方的,Nehalem将其移动到解码器后方,并相对加大了缓冲区的条目。Core 2的LSD缓冲区可以保存18个x86指令而Nehalem可以保存28个uop,从上一页可以知道,大部分x86指令都可以解码为一个uop,少部分可以解码为1~4个uop,因此Nehalem的LSD缓冲区基本上可以相当于保存21~23条x86指令,比Core 2要大上一些。
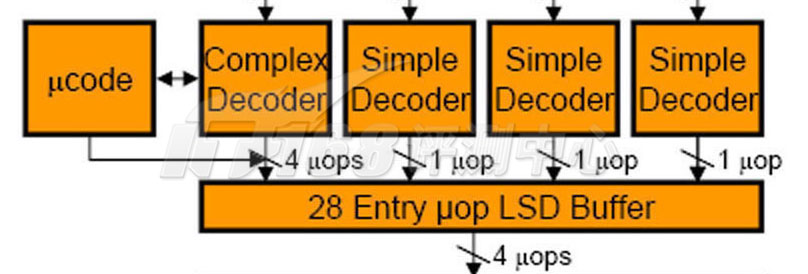
The Core Front-End: Loop Stream Detector
LSD循环流监测器也算包含在解码部分,它的作用是:假如程序使用的循环段(如for..do/do..while等)少于28个uops,那么Nehalem就可以将这个循环保存起来,不再需要重新通过取指单元、分支预测操作,以及解码器,Core 2的LSD放在解码器前方,因此无法省下解码的工作。
Nehalem LSD的工作比较像NetBurst架构的Trace Cache,其也是保存uops,作用也是部分地去掉一些严重的循环,不过由于Trace Cache还同时担当着类似于Core/Nehalem架构的Reorder Buffer乱序缓冲区的作用,容量比较大(可以保存12k uops,准确的大小是20KB),因此在cache miss的时候后果严重(特别是在SMT同步多线程之后,miss率加倍的情况下),LSD的小数目设计显然会好得多。不过笔者认为28个uop条目有些少,特别是考虑到SMT技术带来的两条线程都同时使用这个LSD的时候。
在LSD之后,Nehalem将会进行Micro-ops Fusion,这也是前端(The Front-End)的最后一个功能,在这些工作都做完之后,uops就可以准备进入执行引擎了。
The Core Execution Engine: Out-of-Order Execution
处理器核心执行引擎:乱序执行
OOOE——Out-of-Order Execution乱序执行也是在Pentium Pro开始引入的,它有些类似于多线程的概念,这些在《机密揭露:Intel超线程技术有多少种?》里面可以看到相关的介绍。乱序执行是为了直接提升ILP(Instruction Level Parallelism)指令级并行化的设计,在多个执行单元的超标量设计当中,一系列的执行单元可以同时运行一些没有数据关联性的若干指令,只有需要等待其他指令运算结果的数据会按照顺序执行,从而总体提升了运行效率。乱序执行引擎是一个很重要的部分,需要进行复杂的调度管理。
然而乱序执行架构中,不同的指令可能都会需要用到相同的通用寄存器(GPR,General Purpose Registers),为了在这种情冲突的况下指令们也能并行工作,处理器需要准备解决方法。一般的RISC架构准备了大量的GPR,而x86架构天生就缺乏GPR(x86具有8个GPR,x86-64具有16个,一般RISC具有32个,IA64则具有128个),为此Intel开始引入重命名寄存器(Rename Register),不同的指令可以通过具有名字相同但实际不同的寄存器来解决,这有点像魔兽世界当中的副本设计,当然其出现要比WoW早多了。
此外,为了SMT同步多线程,这些寄存器还要准备双份,每个线程具有独立的一份。
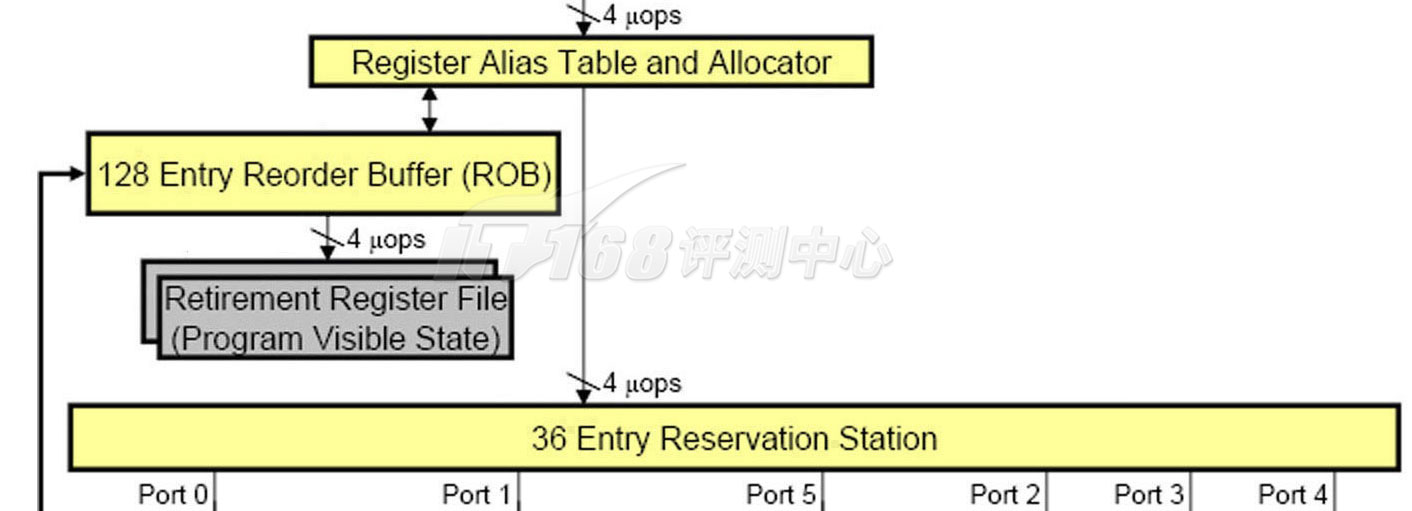
The Core Execution Engine: Out-of-Order Execution
乱序执行从Allocator定位器开始,Allocator管理着RAT(Register Alias Table,寄存器别名表)、ROB(Re-Order Buffer,重排序缓冲区)和RRF(Retirement Register File,退回寄存器文件)。在Allocator之前,流水线都是顺序执行的,在Allocator之后,就可以进入乱序执行阶段了。在每一个线程方面,Nehalem和Core 2架构相似,RAT将重命名的、虚拟的寄存器(称为Architectural Register或Logical Register)指向ROB或者RRF。RAT是一式两份,每个线程独立,每个RAT包含了128个重命名寄存器(Pentium 4之前——Pentium Pro到Pentium III的重命名寄存器基于ROB,数量为40个;据说Pentium 4有128个)。RAT指向在ROB里面的最近的执行寄存器状态,或者指向RRF保存的最终的提交状态。
ROB(Re-Order Buffer,重排序缓冲区)是一个非常重要的部件,它是将乱序执行完毕的指令们按照程序编程的原始顺序重新排序的一个队列,打乱了次序的指令们依次插入这个队列,当一条指令通过RAT发往下一个阶段确实执行的时候这条指令(包括寄存器状态在内)将被加入ROB队列的一端,执行完毕的指令(包括寄存器状态)将从ROB队列的另一端移除(期间这些指令的数据可以被一些中间计算结果刷新),因为调度器是In-Order顺序的,这个队列也就是顺序的。从ROB中移出一条指令就意味着指令执行完毕了,这个阶段叫做Retire回退,相应地ROB往往也叫做Retirement Unit(回退单元),并将其画为流水线的最后一部分。
在一些超标量设计中,Retire阶段会将ROB的数据写入L1D缓存,而在另一些设计里,写入L1D缓存由另外的队列完成。例如,Core/Nehalem的这个操作就由MOB(Memory Order Buffer,内存重排序缓冲区)来完成。
ReOrder Buffer重排序缓冲区是一个Retire Queue回退队列,是OOOE乱序架构流水线的最后一段
ROB是乱序执行引擎架构中都存在的一个缓冲区,重新排序指令的目的是将指令们的寄存器状态依次提交到RRF退回寄存器文件当中,以确保具有因果关系的指令们在乱序执行中可以得到正确的数据。从执行单元返回的数据会将先前由调度器加入ROB的指令刷新数据部分并标志为结束(Finished),再经过其他检查通过后才能标志为完毕(Complete),一旦标志为完毕,它就可以提交数据并删除重命名项目并退出ROB了。提交状态的工作由Retirement Unit(回退单元)完成,它将确实完毕的指令包含的数据写入RRF(“确实”的意思是,非猜测执性、具备正确因果关系,程序可以见到的最终的寄存器状态)。和RAT一样,RRF也同时具有两个,每个线程独立。Core/Nehalem的Retirement Unit回退单元每时钟周期可以执行4个uops的寄存器文件写入,和RAT每时钟4个uops的重命名一致。
由于ROB里面保存的指令数目是如此之大(128条目),因此一些人认为它的作用是用来从中挑选出不相关的指令来进入执行单元,这多少是受到一些文档中的Out-of-Order Window乱序窗口这个词的影响(后面会看到对ROB会和MOB一起被计入乱序窗口资源中)。
ROB确实具有RS的一部分相似的作用,不过,ROB里面的指令是调度器通过RAT发往RS的同时发往ROB的,也就是说,在“乱序”之前,ROB的指令就已经确定了。指令并不是在ROB当中乱序挑选的(这在RS当中进行),ROB担当的是流水线的最终阶段:一个指令的Retire回退单元;以及担当中间计算结果的缓冲区。
RS(Reservation Station,中继站):等待源数据到来以进行OOOE乱序执行(没有数据的指令将在RS等待)
ROB(ReOrder Buffer,重排序缓冲区):等待结果到达以进行Retire指令回退(没有结果的指令将在ROB等待)
The Core Execution Engine: Out-of-Order Execution
Nehalem的128条目的ROB担当中间计算结果的缓冲区,它保存着猜测执行的指令及其数据(猜测执行也是在Pentium Pro开始引入的,Pentium Pro真是一个划时代的产品),猜测执行允许预先执行方向未定的分支指令,Nehalem的分支预测成功率没有被提及(只是含糊地说“业内最高”)。在大部分情况下,猜测执行工作良好——分支猜对了,因此其在ROB里产生的结果被标志为已结束,可以立即地被后继指令使用而不需要进行L1 Data Cache的Load操作(这也是ROB的另一个重要涌出,典型的x86应用中Load操作是如此频繁,达到了几乎占1/3的地步,因此ROB可以避免大量的Cache Load操作,作用巨大)。在剩下的不幸的情况下,分支未能按照如期的情况进行,这时猜测的分支指令段将被清除,相应指令们的流水线阶段清空,对应的寄存器状态也就全都无效了,这种无效的寄存器状态不会也不能出现在RRF里面。
Pentium Pro架构,可见在后继型号在OOOE方面变化的基本只是一些数字变大了
重命名技术并不是没有代价的,在获得前面所说的众多的优点之后,它令指令在发射的时候需要扫描额外的地方来寻找到正确的寄存器状态,不过总体来说这种代价是非常值得的。RAT可以在每一个时钟周期重命名4个uops的寄存器,经过重命名的指令在读取到正确的操作数并发射到统一的RS(Reservation Station,中继站,Intel文档翻译为保留站点)上。RS中继站保存了所有等待执行的指令。
和Core 2相比,Nehalem的ROB大小和RS大小都得到了提升,ROB重排序缓冲区从96条目提升到128条目(鼻祖Pentium Pro具有40条),RS中继站从32提升到36(Pentium Pro为20),它们都在两个线程(超线程中的线程)内共享,不过采用了不同的策略:ROB是采用了静态的分区方法,而RS则采用了动态共享,因为有时候会有一条线程内的指令因等待数据而停滞,这时另一个线程就可以获得更多的RS资源。停滞的指令不会发往RS,但是仍然会占用ROB条目。由于ROB是静态分区,因此在开启HTT的情况下,每一个线程只能分到64条,不算多,在一些极少数的应用上,我们应该可以观察到一些应用开启HTT后会速度降低,尽管可能非常微小。
The Core Execution Engine: Execution Unit
处理器核心执行引擎:执行单元
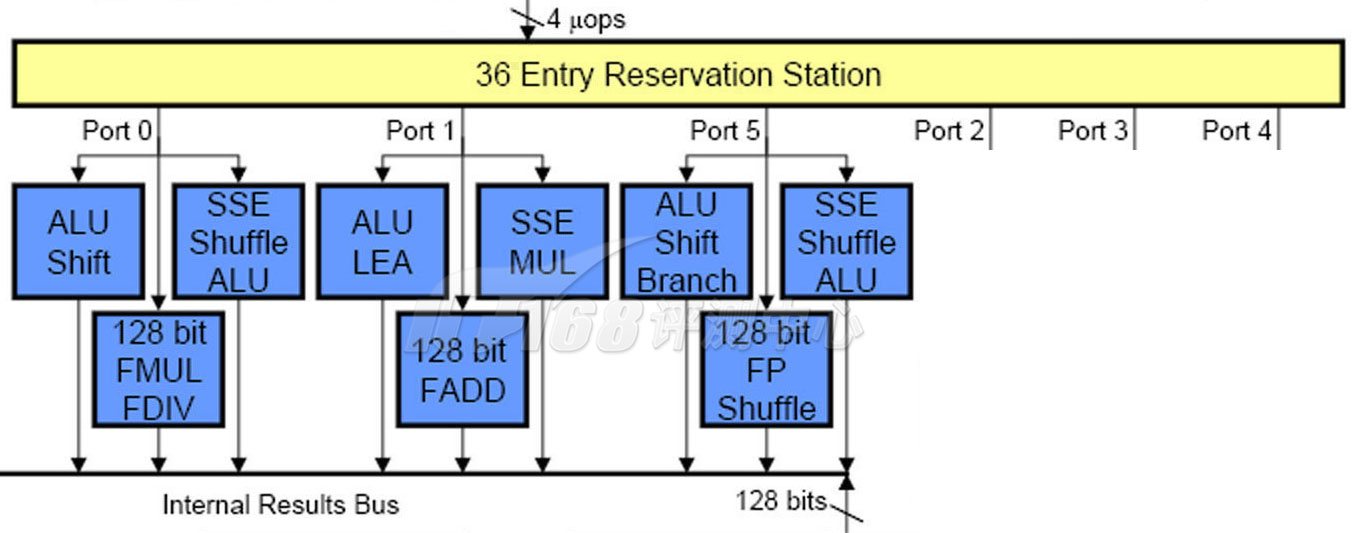
在为SMT做好准备工作并打乱指令的执行顺序之后,uops通过每时钟周期4条的速度进入Reservation Station中继站(保留站),总共36条目的中继站uops就开始等待超标量(Superscaler)执行引擎乱序执行了。自从Pentium开始,Intel就开始在处理器里面采用了超标量设计(Pentium是两路超标量处理器),超标量的意思就是多个执行单元,它可以同时执行多条没有相互依赖性的指令,从而达到提升ILP指令级并行化的目的。Nehalem具备6个执行端口,每个执行端口具有多个不同的单元以执行不同的任务,然而同一时间只能由一条指令(uop)进入执行端口,因此也可以认为Nehalem有6个“执行单元”,在每个时钟周期内可以执行最多6个操作(或者说,6条指令),和Core一样;令人意外的是,古老的Pentium 4每时钟周期也能执行最多6个指令,虽然它只有4个执行端口,然而其中两个执行端口的ALU单元是双倍速的(Double Pump,每时钟周期执行两条ALU指令)。
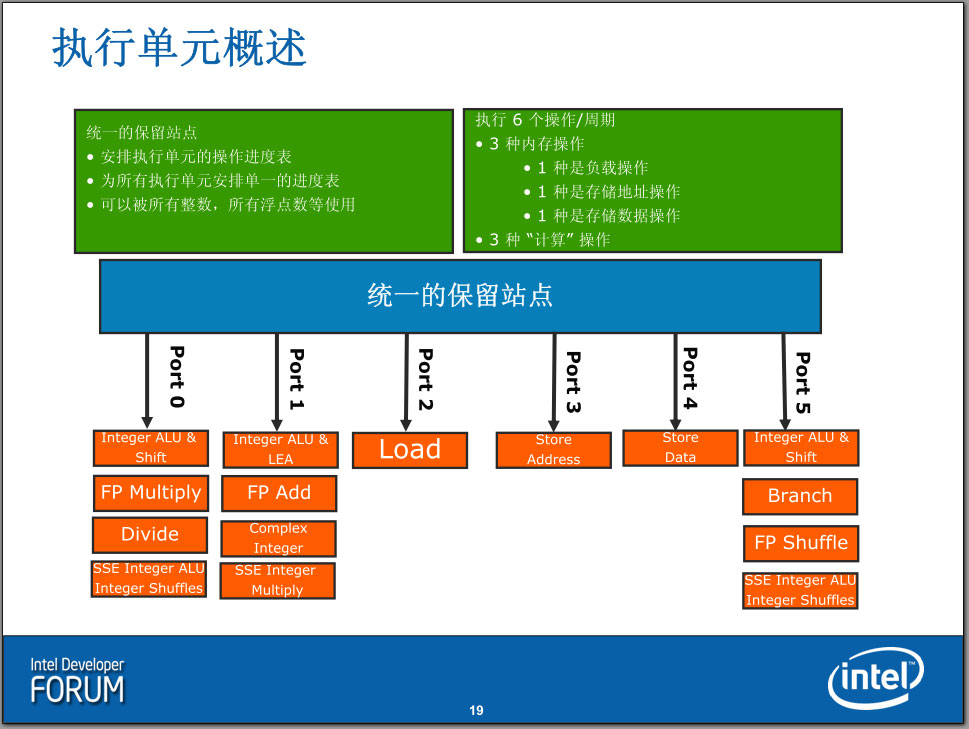
Nehalem:Superscale Execution Unit超标量执行单元
中文版本可能反而不便于理解(如负载操作实际上是Load载入操作),下面是英文原版:
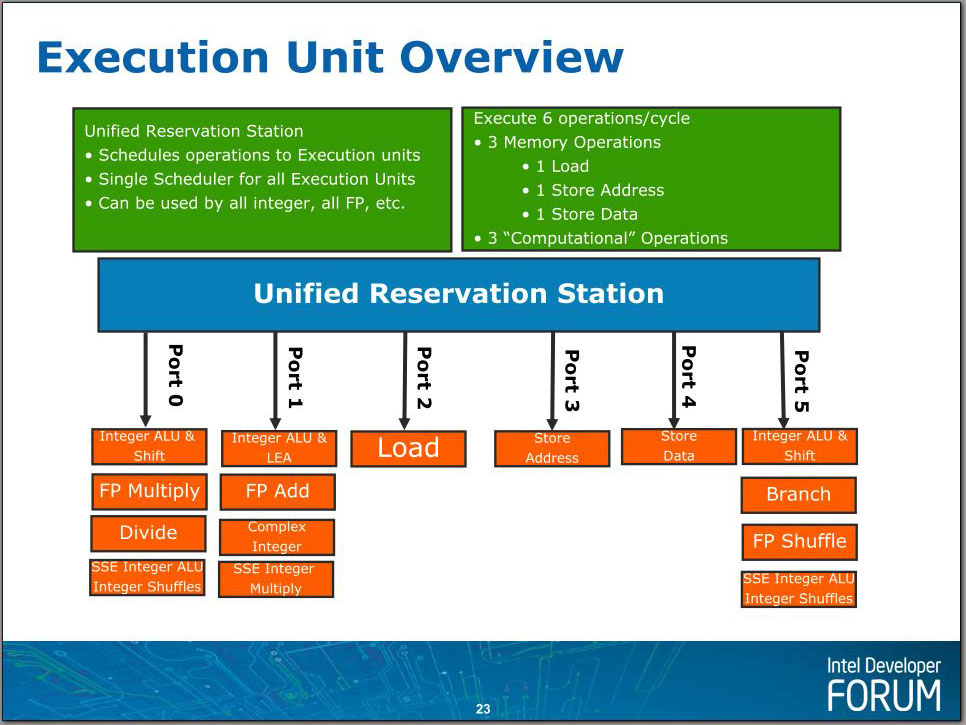
Nehalem:Superscale Execution Unit超标量执行单元
36条目的中继站指令在分发器的管理下,挑选出尽量多的可以同时执行的指令(也就是乱序执行的意思)——最多6条——发送到执行端口。
这些执行端口并不都是用于计算,实际上,有三个执行端口是专门用来执行内存相关的操作的,只有剩下的三个是计算端口,因此,在这一点上Nehalem实际上是跟Core架构一样的,这也可以解释为什么有些情况下,Nehalem和Core相比没有什么性能提升。
计算操作分为两种:使用ALU(Arithmetic Logic Unit,算术逻辑单元)的整数(Integer)运算和使用FPU(Floating Point Unit,浮点运算单元)的浮点(Floating Point)运算。SSE指令(包括SSE1到SSE4)是一种特例,它虽然有整数也有浮点,然而它们使用的都是128bit浮点寄存器,使用的也大部分是FPU电路。在Nehalem中,三个计算端口都可以做整数运算(包括MMX)或者SSE运算(浮点运算不太一样,只有两个端口可以进行浮点ADD和MUL/DIV运算,因此每时钟周期最多进行2个浮点计算,这也是目前Intel处理器浮点性能不如整数性能突出的原因),不过每一个执行端口都不是完全一致:只有端口0有浮点乘和除功能,只有端口5有分支能力(这个执行单元将会与分支预测单元连接),其他FP/SSE能力也不尽相同,这些不对称之处都由统一的分发器来理解,并进行指令的调度管理。没有采用完全对称的设计可能是基于统计学上的考虑。和Core一样,Nehalem的也没有采用Pentium 4那样的2倍频的ALU设计(在Pentium 4,ALU的运算频率是CPU主频的两倍,因此整数性能明显要比浮点性能突出)。
The Core Execution Engine: "Computional" Unit
Nehalem的ALU和FP/SSE单元都使用了相同的三个端口,相比之下,Barcelona Opteron的FP/SSE单元和ALU单元具有不同的入口,因此每时钟周期可以同时执行最多6条计算指令。不过,Barcelona Opteron的3存取操作使用和ALU单元一样的端口,因此其执行单元每时钟周期可以同时执行的指令仍然为6条。
不幸的是,虽然可以同时执行的指令很多,然而在流水线架构当中运行速度并不是由最“宽”的单元来决定的,而是由最“窄”的单元来决定的。这就是木桶原理,Opteron的解码器后端只能每时钟周期输出3条uops,而Nehalem/Core2则能输出4条,因此它们的实际最大每时钟运行指令数是3/4,而不是6。同样地,多少路超标量在这些乱序架构处理器中也不再按照运算单元来划分,Core Duo及之前(到Pentium Pro为止)均为三路超标量处理器,Core 2/Nehalem则为四路超标量处理器。可见在微架构上,Nehalem/Core显然是要比其他处理器快一些。顺便说一下,这也是Intel在超线程示意图中,使用4个宽度的方块来表示而不是6个方块的原因。
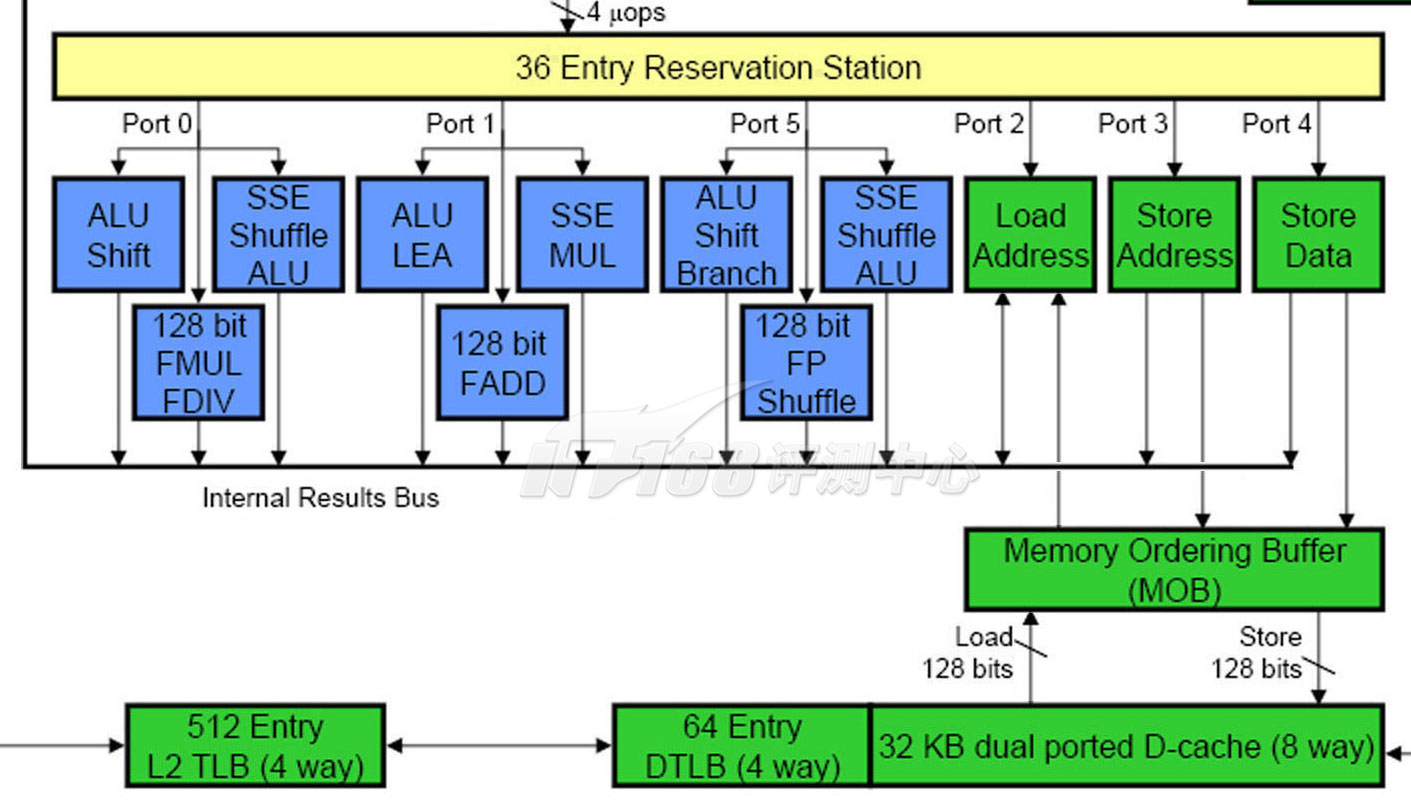
The Core Execution Engine: Load/Store Unit
处理器核心执行引擎:存取单元
运算需要用到数据,也会生成数据,这些数据存取操作就是存取单元所做的事情,实际上,Nehalem和Core的存取单元没什么变化,仍然是3个。
Nehalem的Load/Store结构和Core架构一样
这三个存取单元中,一个用于所有的Load操作(地址和数据),一个用于Store地址,一个用于Store数据,前两个数据相关的单元带有AGU(Address Generation Unit,地址生成单元)功能(NetBurst架构使用快速ALU来进行地址生成)。
The Core Execution Engine: Load/Store Unit
在乱序架构中,存取操作也可以打乱进行。类似于指令预取一样,Load/Store操作也可以提前进行以降低延迟的影响,提高性能。然而,由于Store操作会修改数据影响后继的Load操作,而指令却不会有这种问题(寄存器依赖性问题通过ROB解决),因此数据的乱序操作更为复杂。
 |
| 数据乱序操作的困境:Load/Store依赖性 |
如上图所示,第一条ALU指令的运算结果要Store在地址Y(第二条指令),而第九条指令是从地址Y Load数据,显然在第二条指令执行完毕之前,无法移动第九条指令,否则将会产生错误的结果。同样,如果CPU也不知道第五条指令会使用什么地址,所以它也无法确定是否可以把第九条指令移动到第五条指令附近。
内存数据相依性预测功能(Memory Disambiguation)
内存数据相依性预测功能(Memory Disambiguation)可以预测哪些指令是具有依赖性的或者使用相关的地址(地址混淆,Alias),从而决定哪些Load/Store指令是可以提前的,哪些是不可以提前的。可以提前的指令在其后继指令需要数据之前就开始执行、读取数据到ROB当中,这样后继指令就可以直接从中使用数据,从而避免访问了无法提前Load/Store时访问L1缓存带来的延迟(3~4个时钟周期)。
不过,为了要判断一个Load指令所操作的地址没有问题,缓存系统需要检查处于in-flight状态(处理器流水线中所有未执行的指令)的Store操作,这是一个颇耗费资源的过程。在NetBurst微架构中,通过把一条Store指令分解为两个uops——一个用于计算地址、一个用于真正的存储数据,这种方式可以提前预知Store指令所操作的地址,初步的解决了数据相依性问题。在NetBurst微架构中,Load/Store乱序操作的算法遵循以下几条原则:
- 如果一个对于未知地址进行操作的Store指令处于in-flight状态,那么所有的Load指令都要被延迟
- 在操作相同地址的Store指令之前Load指令不能继续执行
- 一个Store指令不能移动到另外一个Store指令之前
这种原则的问题也很明显,比如第一条原则会在一条处于等待状态的Store指令所操作的地址未确定之前,就延迟所有的Load操作,显然过于保守了。实际上,地址冲突问题是极少发生的。根据某些机构的研究,在一个Alpha EV6处理器中最多可以允许512条指令处于in-flight状态,但是其中的97%以上的Load和Store指令都不会存在地址冲突问题。
基于这种理念,Core微架构采用了大胆的做法,它令Load指令总是提前进行,除非新加入的动态混淆预测器(Dynamic Alias Predictor)预测到了该Load指令不能被移动到Store指令附近。这个预测是根据历史行为来进行的,据说准确率超过90%。
在执行了预Load之后,一个冲突监测器会扫描MOB的Store队列,检查该是否有Store操作与该Load冲突。在很不幸的情况下(1%~2%),发现了冲突,那么该Load操作作废、流水线清除并重新进行Load操作。这样大约会损失20个时钟周期的时间,然而从整体上看,Core微架构的激进Load/Store乱序策略确实很有效地提升了性能,因为Load操作占据了通常程序的1/3左右,并且Load操作可能会导致巨大的延迟(在命中的情况下,Core的L1D Cache延迟为3个时钟周期,Nehalem则为4个。L1未命中时则会访问L2缓存,一般为10~12个时钟周期。访问L3通常需要30~40个时钟周期,访问主内存则可以达到最多约100个时钟周期)。Store操作并不重要,什么时候写入到L1乃至主内存并不会影响到执行性能。
|
| 图9:数据相依性预测机制的优势 |
如上图所示,我们需要载入地址X的数据,加1之后保存结果;载入地址Y的数据,加1之后保存结果;载入地址Z的数据,加1之后保存结果。如果根据Netburst的基本准则,在第三条指令未决定要存储在什么地址之前,处理器是不能移动第四条指令和第七条指令的。实际上,它们之间并没有依赖性。因此,Core微架构中则“大胆”的将第四条指令和第七条指令分别移动到第二和第三指令的并行位置,这种行为是基于一定的猜测的基础上的“投机”行为,如果猜测的对的话(几率在90%以上),完成所有的运算只要5个周期,相比之前的9个周期几乎快了一倍。
The Core Execution Engine: Load/Store Unit
处理器核心执行引擎:存取单元
和为了顺序提交到寄存器而需要ROB重排序缓冲区的存在一样,在乱序架构中,多个打乱了顺序的Load操作和Store操作也需要按顺序提交到内存,MOB(Memory Reorder Buffer,内存重排序缓冲区)就是起到这样一个作用的重排序缓冲区(上图,介于Load/Store单元与L1D Cache之间的部件),所有的Load/Store操作都需要经过MOB,MOB通过一个128bit位宽的Load通道与一个128bit位宽的Store通道与双口L1D Cache通信。和ROB一样,MOB的内容按照Load/Store指令分发(Dispatched)的顺序加入队列的一端,按照提交到L1D Cache的顺序从队列的另一端移除。ROB和MOB一起实际上形成了一个分布式的Order Buffer结构,有些处理器上只存在ROB,兼备了MOB的功能。
和ROB一样,Load/Store单元的乱序存取操作会在MOB中按照原始程序顺序排列,以提供正确的数据,内存数据依赖性检测功能也在里面实现。Intel没有给出MOB详细的结构——包括外部拓扑结构在内,在一些玩家制作的架构图当中,MOB被放在Load/Store单元与Internal Results Bus之间并互相联结起来,意思是MOB的Load/Store操作结果也会直接反映到ROB当中。
The Core Execution Engine: Load/Store Unit
然而基于以下的一个事实,笔者将其与Internal Results Bus进行了隔离:MOB还附带了数据预取(Data Prefetch)功能,它会猜测未来指令会使用到的数据,并预先从L1D Cache缓存Load入MOB中(Data Prefetcher也会对L2至系统内存的数据进行这样的操作),这样MOB当中的数据有些在ROB中是不存在的(这有些像ROB当中的Speculative Execution猜测执行,MOB当中也存在着“Speculative Load Execution猜测载入”,只不过失败的猜测执行会导致管线停顿,而失败的猜测载入仅仅会影响到性能)。此外,MOB与L1D之间是数据总线,不带有指令,经过MOB内部的乱序执行之后,ROB并不知道进出的数据对应哪一条指令。最终笔者制作的架构图就如上方所示。

每个Core 2内核具有3个Prefetcher(1个指令,两个数据);每两个核心共享两个L2 Prefetcher

Nehalem的Hardware Prefetcher功能,其中L1 Prefetchers基于指令历史以及载入地址参数
数据预取功能和指令预取功能一起,统称为Hardware Prefetcher硬件预取器。笔者在年少时对BIOS里面通常放在CPU特性那一页里面的Hardware Prefetcher迷惑不解(通常在一起的还有一个Adjacent Cache Line Prefetch相邻缓存行预取,据说这些选项不包含L1 Prefetcher;亦尚不清楚是否包括MOB的预取功能),现在我们知道了这两个功能就是和这一页的内容相关的。很不幸,在以往的CPU中,失败的预取将会白白浪费掉L1/L2/L3/Memory的带宽,而在服务器应用上通常会进行跨度很大的Load操作,因此Hardware Prefetcher经常会起到降低性能的作用。对于这种情况,处理器厂商们除了在BIOS里面给出一个设置选项就没有更好的方法了(这些选项在桌面应用上工作良好)。糟糕的是,很多用户都不知道这些选项是干什么用的。据说Nehalem上这个情况得到了好转,用户可以简单地设置为Enable而不用担心性能下降。或许以后我们IT168评测中心会进行相关的测试检验是否是这样,不过我们可以想象,内存带宽得到巨大提升的Nehalem已经具有足够的资本来开启这些选项了。
提高并行度:扩大RS和MOB的容量(MOB包括了Load Buffers和Store Buffers),所谓的乱序窗口资源
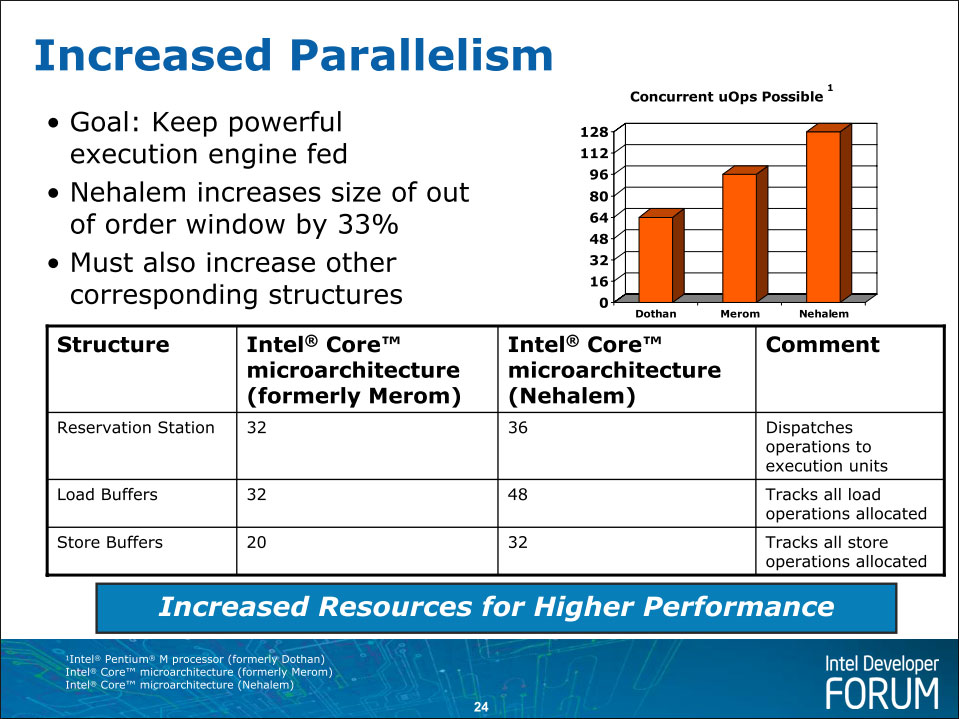
乱序执行中我们可以看到很多缓冲区性质的东西:RAT寄存器别名表、ROB重排序缓冲区、RS中继站、MOB内存重排序缓冲区(包括LB载入缓冲和SB存储缓冲)。在超线程的作用下,RAT是一式两份,包含了128个重命名寄存器;128条目的ROB、48条目的LB和32条目的SB都静态划分为两个分区:每个线程64个ROB、24个LB和16个SB;RS则是在两个线程中动态共享。可见,虽然整体数量增加了,然而就单个线程而言,获得的资源并没有提升。这会影响到HTT下单线程下的性能。
The Memory sub-System: Cache
内存子系统:缓存
MOB通过两条128位宽的Load/Store通道与L1D Cache连接,L1D Cache同时通过256位宽的总线与L2连接:L1D Cache是双口(Dual Ported)的。在缓存方面,Nehalem和Core相比具有了一些变化。
绿色部分都属于缓存相关部分
Nehalem/Core的L1I Cache(L1指令缓存)和L1D Cache(L1数据缓存)都是32KB,不过Nehalem的L1I Cache从以往的8路集合关联降低到了4路集合关联,L1 DTLB也从以往的256条目降低到64条目(64个小页面TLB,32个大页面TLB),并且L1 DTLB是在两个多线程之间动态共享的(L1 ITLB的小页面部分则是静态分区,也就是64条目每线程,是Core 2每线程128条目的一半;每个线程还具有7个大页面L1I TLB)。

Nehalem TLB架构
为什么L1I Cache的集合关联降低了呢?这都是为了降低延迟的缘故。随着现代应用程序对数据容量的要求在加大,需要提升TLB的大小来相应满足(TLB:Translation Lookaside Buffer,旁路转换缓冲,或称为页表缓冲;里面存放的是虚拟地址到物理地址的转换表,供处理器以及具备分页机构的操作系统用来快速定位内存页面;大概很多人知道TLB是因为AMD的处理器TLB Bug事件)。Nehalem采用了较小的L1 TLB附加一层较大的L2 TLB的方法来解决这个问题(512个条目以覆盖足够大的内存区域,它仅用于较小的页面,指令和数据共用,两个线程共享)。

为了降低能耗,Nehalem架构将以往应用的Domino线路更换为Static CMOS线路,并大规模使用了长沟道晶体管技术,速度有所降低,但是能源效率提升了
虽然如此,Nehalem L1D Cache的延迟仍然从Core 2的3个时钟周期上升到了4个时钟周期,这是由于线路架构改变的缘故(从Domino更换成Static CMOS,大量使用长沟到晶体管)。类似地L1I Cache乃至L2、L3的延迟都相应地会上升,然而指令缓冲的延迟对性能的影响要比数据严重;每一次取指令都会受到延迟影响,而缓存的延迟则可以通过乱序执行和猜测载入来解决。因此Intel将L1I Cache的集合关联从8路降低到4路,以维持延迟仍然在3个时钟周期。
Nehalem-EP Xeon E5540的缓存架构
The Memory sub-System: Cache
内存子系统:缓存
与Core 2相比,Nehalem新增加了一层L3缓存,这是为了多个核心共享数据的需要(Nehalem-EX具有8个核心),也因此这个L3的容量很大。出于消除多核心共享数据的压力,前面的缓存不能让太多的缓存请求到达L3,而且L3的延迟(约30~40个时钟周期)和L1的延迟(3~4个时钟周期)相差太大,因此L2是很有必要的。Nehalem简单地在很小的L1和大尺寸的L3之间插入256KB的L2来起到中继的作用——中继具有两个方面的含义:容量和延迟。256KB不算大,可以维持约低于10个时钟周期的延迟。Nehalem的L2和L1不是包含也不是非包含的关系。
|
通常缓存具有两种设计:非独占和独占,Nehalem处理器的L3采用了非独占高速缓存设计(或者说“包含式”,L3包含了L1/L2的内容),这种方式在Cache Miss的时候比独占式具有更好的性能,而在缓存命中的时候需要检查不同的核心的缓存一致性。Nehalem并采用了“内核有效”数据位的额外设计,降低了这种检查带来的性能影响。随着核心数目的逐渐增多(多线程的加入也会增加Cache Miss率),对缓存的压力也会继续增大,因此这种方式会比较符合未来的趋势。在后面可以看到,这种设计也是考虑到了多处理器协作的情况(此时Miss率会很容易地增加)。这可以看作是Nehalem与以往架构的基础不同:之前的架构都是来源于移动处理设计,而Nehalem则同时为企业、桌面和移动考虑而设计。
在L3缓存命中的时候(单处理器上是最通常的情况,多处理器下则不然),处理器检查内核有效位看看是否其他内核也有请求的缓存页面内容,决定是否需要对内核进行侦听:
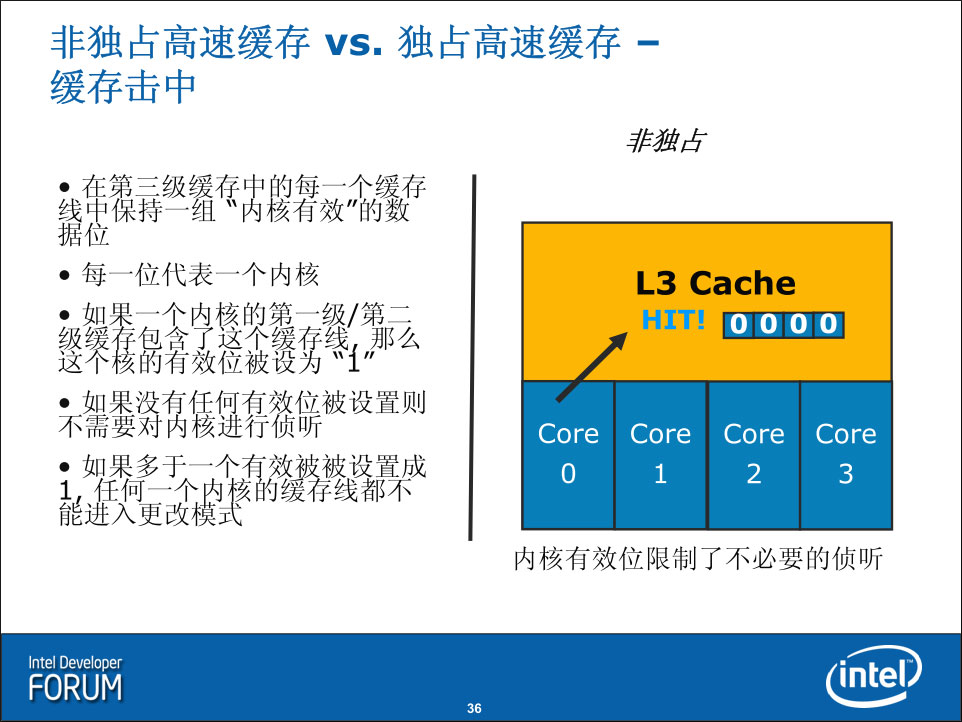
笔者相信这一点是不对的:假如一个L3页面被多个内核共享(多于一个有效被设置为1),那么这个处理器的该页面就不能进入Modified状态
基于后面的NUMA章节的内容,多个处理器中的同一个缓存页面必定在其中一个处理器中属于F状态(可以修改的状态),这个页面在这个处理器中没有理由不可以多核心共享(可以多核心共享就意味着这个能进入修改状态的页面的多个有效位被设置为一)。笔者相信MESIF协议应该是工作在核心(L1+L2)层面而不是处理器(L3)层面,这样统一处理器里多个核心共享的页面,只有其中一个是出于F状态(可以修改的状态)。见后面对NUMA和MESIF的解析。
在L3缓存未命中的时候(多处理器下会频繁发生),处理器决定进行内存存取,按照页面的物理位置,它分为近端内存存取(本地内存空间)和远端内存存取(地址在其他处理器的内存的空间):
|
Cache Miss时而页面地址为本地的时候,处理器进行近端内存访问
延迟取本地内存访问和远程CPU Cache Hit的延迟的最大值
|
Cache Miss时而页面地址为远程的时候,处理器进行远端内存访问
延迟取远程内存访问和远程CPU Cache Hit的延迟的最大值
|
近端访问约60个时钟周期,远端访问约90个时钟周期(据说仍然比Harptertown Xeon快),本地L3 Cache Hit则为30个时钟周期
The Uncore: IMC & QPI
核外系统:集成内存控制器及QPI
从形式上来看,L3缓存、集成的内存控制器乃至QPI总线都属于Uncore核外部分,从L2、L1一直到执行单元都属于Core核内部分。由于Nehalem首次采用了这种核心内外的相对独立设计思路,因此核心之外的设计相对于Core架构来说显得新颖许多,这就是Nehalem的模块式设计。
|
模块式设计可以提供灵活的产品给用户,现在4核心、三通IMC和单QPI的桌面Nehalem已经面市,预计明年3月将会出现4核心、4通道IMC和双QPI的企业级Nehalem产品。包含了PCIE控制器乃至集成显卡的产品也已经在路线上了。
继续回到处理器架构:我们都知道,Nehalem和Intel以往处理器相比最大的特点就是直联架构——包括两个方面:处理器直联以及内存直联,前者就是依靠QPI总线的实现,后者则是由于处理器内置了内存控制器(IMC,Integrated Memory Controller)。当处理器在L3 Cache未找到所要内容(L3 Cache Miss)的时候,它将会继续通过IMC集成内存控制器往系统内存索取,同时通过QPI总线询问其他处理器(如果是多处理器平台)。
为什么直联架构可以很明显地提升性能?这要先从x86架构的存储体系说起。在很久很久以前,在一个记忆体短缺的时代——不仅仅处理器外面记忆体很少,处理器里面也是。使用了CISC架构的x86处理器里面只有8个GPR通用寄存器(一般的RISC处理器有32个以上的通用寄存器,现在的x86-64有16个通用寄存器),由于通用寄存器数量上的短缺,因此不像RISC处理器那样,CISC的x86处理器使用了堆叠运算指令。堆叠运算也就是将运算结果保存在源寄存器上的,如ADD AX, BX指令会将AX寄存器与BX寄存器的内容相加,并将结果保存到AX上——这样对比于使用三个寄存器做同一运算的非堆叠指令RISC架构就节约了一个寄存器,然而相应地源寄存器的内存就销毁了。x86架构需要执行大量的Load/Store微指令(Pentium Pro开始具备)来进行寄存器-寄存器或寄存器-内存之间的数据搬运操作。RISC处理器当中,Load/Store操作也很频繁。
如前面所述,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
mov、push、pop都是和load/store直接相关的,add、cmp等则间接相关
顺便:
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
单操作数指令占37%,双操作数指令占60%
双操作数指令中,直接数操作20%,寄存器操作数56%,绝对寻址操作数1%,间接寻址操作数23%
Load操作占据了x86 uops当中的约30%
大量的Load/Store操作已经通过ROB/MOB降低到一定程度,不过,在多核心/超线程的情况下,对缓存/内存子系统仍然具有很大的压力
现在来看这样的设计简直是无法想象,不过这样脑残的设计不仅仅用到了今天,而且还加速到了一个不可思议的境界……在与各种RISC架构处理器的交锋也不落下风……回到架构上,由于x86架构实际上是通过耗费寄存器带宽及缓存-内存带宽来节约处理器内部寄存器数量,大量的Load/Store操作(Load操作占据了x86 uops当中的约30%),对缓存乃至内存的性能非常依赖。
Nehalem具有三个Load/Store单元以及一个MOB架构,并支持内存数据相依性预测功能,缓存性能非常出色
缘此,x86架构在缓存-内存上的提升是不遗余力,不提2008年度评测报告:深入Nehalem微架构中说到的内存数据相依性预测功能(Memory Disambiguation),对于Nehalem而言,这方面最大的改进就是直联架构带来的IMC集成内存控制器,它使CPU到内存的路径更短,大幅度降低了内存的延迟,同时每一个CPU都具有自己专有的内存带宽。这一点在数据库应用中表现非常显著,数据库应用对存储器的延迟很敏感。
直联架构不仅仅意味着处理器与内存直接相连,还让处理器之间也直接联系起来。Hyper-Transport总线的使用让Operton进入了高性能计算市场,QPI所作的事情是一样的。通过QPI总线,处理器之间可以直接相连,不再需要经过拥挤、低带宽的FSB共享总线,多处理器系统运行效率大为提升。 对于多处理器系统而言,QPI提供的巨大带宽对性能提升很有作用。
QPI vs. FSB | ||
名称 | Intel FSB(Front Side Bus) | Intel QuickPath Interconnect(QPI) |
| 拓扑 | 共享总线 | 点对点连接 |
| 物理总线宽度(bits) | 64 | 20 x 2(双向) |
| 数据总线宽度(bits) | 64 | 16 x 2(双向) |
| 传输速率 | 333MHz 1.333GT/s 10.6GB/s | 3.2GHz 6.4GT/s 12.8GB/s(单向) 25.6GB/s(双向) |
| 需要边带信号 | 是 | 否 |
| 引脚数 | 150 | 84 |
时钟数 | 1 | 1 |
集成时钟 | 否 | 否 |
总线传输方向 | 双向 | 单向 |
使用高频率DDR3内存,访问本地内存的延迟大约为60个时钟周期,而通过QPI总线访问远端的处理器并返回数据大约需要90个时钟周期(如上一页所述)。QPI的就是Core架构为了使用服务器市场而做出的进化,它可以建立一个庞大的可扩展的解决方案。
|
除了提供更高的带宽(每链路25.6GB双向带宽)之外,QPI总线还让多处理器系统更有效率:处理器之间可以直接连接。如上图,每个CPU都可以直接和其他三个CPU通信;4路Barcelona Opteron在对角线上是无法直接通信的,需要邻近的CPU进行接力,这显然会降低效率;不过Shanghai Opteron已经可以做到:《全国首发 AMD Shanghai/上海性能评测》。

Nehalem-EX的时钟架构
所有的Nehalem都按时钟分为三个部分:核心、核外(L3和系统逻辑)和IO(QPI和IMC),这三个部分的频率通常互不相同。由于L3缓存属于核外部分,因此它的频率和核心频率通常是不同的,在以往,CPU内的高速缓存通常都是全速的,只有Pentium II的L2缓存是半速的(它和CPU内核不在同一个晶圆上,虽然在同一个CPU封装内),而K6之前的L2缓存都是放在主板上面的,速度极低。现在,Nehalem架构下,L3缓存的时钟频率也不再是全速,而是要较低一些,例如,Core i7 920的L3频率应该是2.133GHz,Xeon X5570的L3频率应该是2.667GHz。
Nehalem-EP/Gainestown Xeon X5570处理器,主频2.93GHz,QPI总线频率高达3.2GHz,比主频还要高
QPI总线频率一般和L3频率也不同,不过它们具有一些联系。对于桌面处理器来说,QPI总线只有一条,简单地连接处理器与IOH,然而对于服务器处理器来说,除了连接IOH之外,处理器与处理器之间也需要通过QPI总线,因此服务器的处理器都具有很高的QPI频率,有些时候甚至高于处理器主频率,如Xeon X5570处理器。
桌面Nehalem:Core i7 920的主频是2.67GHz,而QPI总线频率只有2.4GHz
一些主板允许单独设置这些不同的频率以方便超频。在这里,笔者可以回答很多用户关心的UCLK频率(一些主板上具有的Uncore Clock设置选项)的问题:L3缓存频率和IMC集成内存控制器的频率是不同的,也就是UCLK和内存频率是不同的,不过它们具有一些内在关系。此外,由于UCLK关系的Uncore部分关系到了整个处理器的中枢部分:系统逻辑(包括中央路由器和集线器),因此它的频率设定可以很大地影响到整个处理器的运行效能。
Architecture: ccNUMA Architecture
架构:缓存一致的非一致性内存访问
由于IMC和QPI的存在,从形式上来看,多路Nehalem处理器系统将会组成一个NUMA(Non-Uniform Memory Access或者Non-Uniform Memory Architecture,非一致性内存访问或非一致性内存架构)系统,NUMA系统是多处理器系统的一种形式,以往的通过单条FSB连接多个Xeon处理器的系统叫做UMA(Uniform Memory Architecture,内存一致架构)系统——传统地,按照处理器架构来分的话属于SMP(Symmetric MultiProssecor,对称多处理器)系统。NUMA的特点是访问内存不同的区域具有着不一致的延迟,NUMA和UMA的共同点是所有内存是硬件共享的,操作系统只看到一片单一的内存区域,比起MPP大型并行处理系统在编程方面更为简便。
多个Nehalem处理器之间使用MESIF协议来保持缓存一致性
按照缓存页面同步的形式,NUMA可以分为两种:Cache Coherent缓存一致和Non-Cache Coherent缓存非一致性,由于编程上的艰难,因此后一种形式的实际产品几乎不存在,所以NUMA几乎就是ccNUMA(Cache Coherent NUMA)的代名词。多路Nehalem处理器就是一个典型的ccNUMA架构。ccNUMA的特点是多个处理器之间进行共享、传输的是缓存页面(缓存页面所对应的内存页面则固定地保留在某一个处理器连接的内存上)。
Nehalem通过MESIF协议来维护缓存页面的一致性(也就是Cache Coherent缓存一致的含义),而使用HT总线的AMD Opteron(多Opteron也组成一个ccNUMA架构)则使用的是MOESI协议,老的Xeon则使用MESI协议。MESIF的意思就是M(Modified)E(Exclusive)S(Shared)I(Invalid)F(Forward),MOESI则是M(Modified)O(Owner)E(Exclusive)S(Shared)I(Invalid),这些词分别代表了一个缓存页面的状态,Nehalem多了一个F状态,而Opteron则多了一个O状态。
Cache Coherent Protocol缓存同步协议 | |||||||
| 干净/脏 | 唯一 | 可写 | 转发 | 可安静地转化成的状态 | 说明 | ||
MESIF over QPI/CSI(Intel Nehalem) | |||||||
| M(Modified) 修改 | Dirty 脏 | 是 | 是 | 是 | 被请求时需要先写入内存 并转化为F状态 | ||
| E(Exclusive) 独占 | Clean 干净 | 是 | 是 | 是 | M、S、I、F | 被写入时转化为M状态 | |
| S(Shared) 共享 | Clean 干净 | 否 | 否 | 否 | I | 主副本被写入时转为无效 | |
I(Invalid) 无效 | - | - | - | - | - | ||
| F(Forward) 转发 | Clean 干净 | 是 | 否 | 是 | S、I | 主副本 被写入时转换为M状态 并使其他S副本无效 | |
MOESI over HTT(AMD Opteron) | |||||||
| M(Modified) 修改 | Dirty 脏 | 是 | 是 | 是 | O | 被请求时不需要写入内存 而仅仅转化为O状态 | |
| O(Owner) 拥有者 | Dirty 脏 | 是 | 是 | 是 | 主副本 转换为其他状态需要先写入内存 | ||
| E(Exclusive) 独占 | Clean 干净 | 是 | 是 | 是 | M、S、I | 被写入时转化为M状态 | |
| S(Shared) 共享 | 干净或脏 | 否 | 否 | 否 | I | 可以同时为干净或者脏 主副本被写入时转为无效 | |
I(Invalid) 无效 | - | - | - | - | - | ||
MESI over FSB(Intel Xeon) | |||||||
| M(Modified) 修改 | Dirty 脏 | 是 | 是 | 是 | 被请求时需先写入内存 | ||
| E(Exclusive) 独占 | Clean 干净 | 是 | 是 | 是 | M、S、I | 被写入时转化为M状态 | |
| S(Shared) 共享 | Clean 干净 | 否 | 否 | 是 | I | 可以转发 | |
I(Invalid) 无效 | - | - | - | - | - | ||
三种缓存同步协议对比:Nehalem MESIF、Opteron MOESI、Xeon MESI
MESIF可以说是Intel在多Xeon使用的MESI协议的扩充,增加了一个F状态(同时修改了S状态让其无法转发以避免进行过多的传输)。F状态就是这样一个状态:在一个多处理器之间共享的缓存页面中,只有其中一个处理器的该页面处于F状态,另外所有处理器的该页面均处于S状态,F状态负责响应其他没有该页面的处理器的读请求,而S状态则不响应并且不允许将缓存页面发给他人(或许S用Silent来代表更合适)。
当一个新处理器需求读取这个F页面时,原有的F页面则转为S状态,新的处理器获得的页面总是保持为F状态。在一群相同的页面中总有并且只有一个页面是处于F状态,其他的S副本则以F副本为中心。这种流动性让传输压力得以分散到各个处理器上,而不是总维持在原始页面上。
不会改变的页面的共享很好处理,关键的是对Dirty页面的对待(Dirty页面是指一个内容被修改了的缓存页面,需要更新到内存里面去),显然,一堆页面的副本中同一时间内只能有其中一个可以被写入。MESIF中,只具有一个副本的E状态在被写入的时候只需要简单地转化为M状态;而F状态被写入时则会导致其所有的S副本都被置为无效(通过一个广播完成);S副本是“沉默”的,不允许转发,也不允许被写入,这些副本所在的处理器要再次使用这个副本时,需要再次向原始F副本请求,F副本现在已经转化为M副本,被请求状态下M副本会写入内存并重新转化为F状态,不被请求时则可以保持在M状态,并可以不那么快地写入内存以降低对内存带宽的占用。
MESIF实际上只允许一堆共享副本当中的中央副本(F状态)被写入,在多个处理器均需要写入一个缓存页面的时候,会引起“弹跳”现象,F副本在各个处理器之间不停传输——这有点像令牌环——会降低性能,特别是F副本不在其所在的原始内存空间的时候。
Opteron的MOSEI协议不需要被写入的M状态写入内存就可以进行共享(这时M状态会转变为O状态,共享后的Dirty副本被标记为S状态),这避免了一次写入内存,节约了一些开销,尚不清楚为什么Intel没有在新生的总线上采用这种更为优化的协议;当再次写入O状态副本时,其他的S副本同样会被设置为无效。MOSEI也只允许一堆共享副本当中的中央副本(O状态)被写入,也存在着弹跳现象。
不过,在一个方面Nehalem具有优势:包含式(或者非独占式)L3缓存,当一个处理器被请求一个页面,或者被通知一个页面要被设置为无效的时候,它只需要检查L3就可以知道该如何操作。在L3缓存没有这个页面的时候,不需要像非包含式L3设计那样,再检查L1、L2页面。
Architecture: Hyper Threading
架构:超线程
HTT超线程技术出自Intel位于Oregen俄勒冈州的Hillsboro研发中心。Pentium Pro、Pentium 4、Nehalem架构都是出自这个Hillsboro研发中心。Pentium 4和Nehalem搭载的HTT超线程都是同一个东西,都是让处理器可以同时运行多条指令,实际上,它们属于多线程技术中的一个分类:SMT同步多线程。起先,Intel在资料中使用SMT来称呼Nehalem的HT技术,然而SMT实是一个专有名词,并不仅仅Nehalem有采用,于是Intel又改变了主意,又将其称作为HTT超线程。各种典故可以看这里:机密揭露:Intel超线程技术有多少种?。
|
Nehalem的超线程技术就是NetBurst超线程技术的升级版本,和Atom和Itanium的超线程技术都不同
并不是所有的Nehalem处理器都提供了超线程技术,在Nehalem-EP当中,只有末尾是0的型号才具有,是其他数字的就不具备HTT。如L5502是一款双核的、不搭载超线程技术的Nehalem-EP处理器,千颗售价$188,非常便宜。当然值不值得又是另外一回事了。
|
超线程技术可以通过很少的代价提升并行应用的性能,特别是在服务器领域,因此Nehalem在服务器领域的能力将会再一次得到提升。AMD目前并没有类似的技术,因此在未来的对阵当中,Nehalem更被看好些。
SMT属于MTT的一种,下面是MTT——MultiThreading多线程技术的主要分类,MultiThreading多线程就是在一个单个的处理核心内同时运行多个工作线程的技术,和CMP(Chip MultiProcessing,芯片多处理)不同,后者是通过集成多个处理内核的方式来让系统的处理能力提升——也就是现在常见的多核技术。现在主流的处理器都使用了CMP技术。主流的MultiThreading具有着三种形式,差别在于线程间共享的资源以及线程切换的机制:
多线程架构异同 | |||||
多线程技术 | 线程间共享资源 | 线程切换机制 | 资源利用率 | ||
粗粒度多线程 Coarse-Grained MultiThreading | 除取指令缓冲、寄存器、控制逻辑外 | 流水线停顿时 | 提升单个执行单元利用率 | ||
细粒度多线程 Fine-Grained MultiThreading | 除寄存器、控制逻辑外 | 每时钟周期 | 提升单个执行单元利用率 | ||
同步多线程 Simultaneous MultiThreading | 除取指令缓冲、返回地址堆栈、寄存器、控制逻辑、重排序缓冲、Store队列外 | 所有线程同时活动,无切换 | 提升多个执行单元利用率 | ||
其中CMT和FMT都是在单个执行单元下的技术,不同的线程在指令级别上并不是真正的“并行”,而SMT则具有多个执行单元,同一时间内可以同时执行多个指令,因此前两者有时先归类为TMT(Temporal MultiThreading,时间多线程),以和SMT相区分。
Itanium 2 Montecito也具有超线程技术,不过,和Pentium 4/Nehalem不同,它属于CMT粗粒度多线程技术
Nehalem: ccNUMA & SMT & OS
Nehalem:ccNUMA与SMT与操作系统
我们已经知道多路Nehalem会形成一个ccNUMA架构,在NUMA系统中,由于本地内存的访存延迟低于远程内存的访存延迟,因此将进程分配到本地内存附近的处理器上可极大优化应用程序的性能。这就需要操作系统支持并智能地进行这样的分配。
多个Nehalem处理器之间使用MESIF协议来保持缓存一致性
多个核心之间是否也使用MESIF协议来保持缓存一致性呢?
除了NUMA架构的要求外,Nehalem的SMT技术(超线程技术)也要求操作系统的支持,这是基于这样的一个事实:线程调度时在两个逻辑CPU之间进行线程迁移的开销远远小于物理CPU之间的迁移开销以及逻辑CPU共享Cache等资源的特性。这一点和NUMA上同一个CPU的不同核心之间进行线程迁移的开销远远小于多个CPU之间的迁移开销以及同核心的CPU共享Cache等资源的特性是一样的,要系统发挥最大的性能,操作系统必须对NUMA以及超线程这样的实质上比较类似NUMA的这些架构作出优化。
传统的基于NT核心的Windows都可以支持SMP对称多处理器技术,然而它们并没有很好地为NUMA和超线程优化(这也是当初Pentium 4 HT推荐使用WIndows XP而不是WIndows 2000操作系统的原因),在购买到Nehalem系统之后,你需要采用最新的操作系统:

Windows Server 2008内核对NUMA的优化
Windows Server 2008内核对NUMA IO的优化
Windows Server 2008对逻辑处理器们的划分(Group——Processor Group是Windows Server 2008 R2/Windows 7加入的功能)
经过多次升级的Windows Server 2003可以较好地支持NUMA技术(为了支持广泛应用的Opteron——典型的NUMA架构),Windows XP也为超线程技术做了优化,然而它们都不够Windows Server 2008深入。2008为NUMA做出了包括内存管理方面的多种优化:分布式的非分页池、系统页表、系统缓存以及内存分配策略,同时还更好地支持NUMA I/O。在使用多Nehalem或者多Opteron这样的处理器时,你应该使用Windows Server 2008操作系统或者Windows Vista操作系统(2008和Vista使用了相同的内核,区别只是一些小的特性)。甚至在使用单Nehalem的时候,你也应该使用Vista,因为超线程的缘故。
Linux 2.4内核中的调度器由于只设计了一个运行队列,可扩展性较差,在SMP平台表现一直不理想。后来在2.5内核开发时出现一个多队列调度器(Ingo Molnar),称为O(1),每个处理器具有一个运行队列,从2.5.2开始集成。由于O(1)调度器不能较好地感知NUMA系统中结点这层结构,从而不能保证在调度后该进程仍运行在同一个结点上,为此Linux 2.6内核出现了结点亲和的NUMA调度器(Eirch Focht),建立在Ingo Molnar的O(1)调度器基础上的(这个调度器后来也向后移植到2.4.X内核中),因此现在的Linux 2.6核心可以较好地支持NUMA和超线程。
FreeBSD的SMP功能直到7.0版本才算大为完善,就目前来看,FreeBSD对NUMA的支持还比较原始。
Nehalem: Virtualization
Nehalem:虚拟化
虚拟化作为Intel架构的重点,一直是Intel处理器的重要特性,每次处理器架构的更新,都会得到更多的支持。Nehalem也不例外,改进的地方虽然不多,然而这些改动大大提高了虚拟化性能。这些改动包括了两个部分:EPT扩展页表和VPID虚拟处理器ID,其中前者消灭了当前存在的虚拟机内存操作中存在的大量内存地址转换(以前使用软件来模拟EPT的功能,现在用硬件实现了,据说虚拟化延迟比Penryn降低了33%),后者则减少了对TLB的无效操作,这些都明显提升了虚拟机的性能。
|
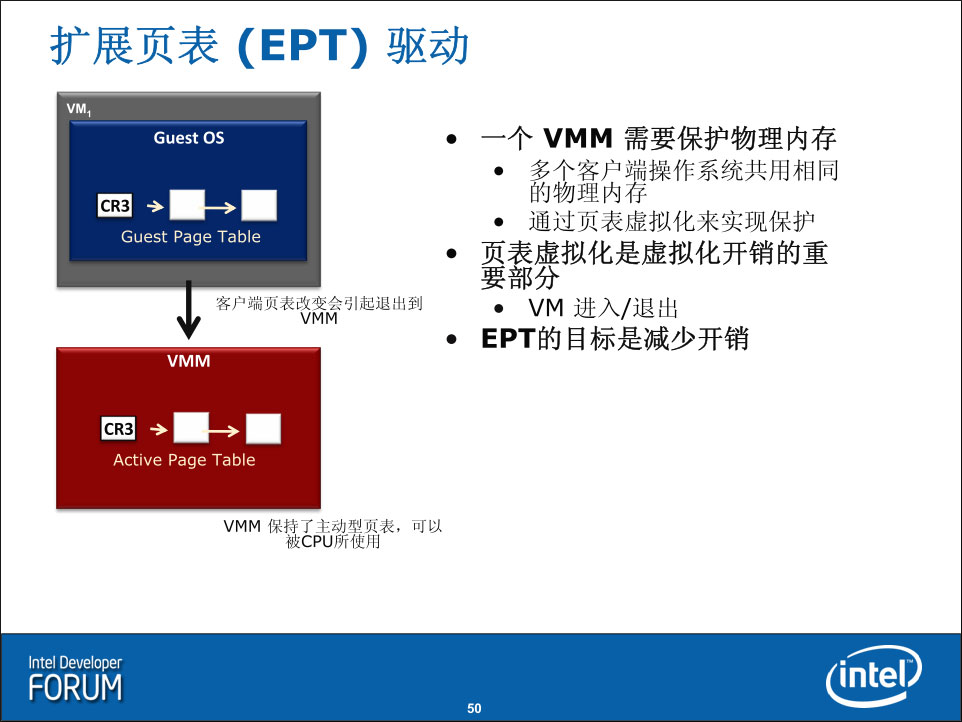

I/O虚拟化的关键在于解决I/O设备与虚拟机数据交换的问题,而这部分主要相关的是DMA直接内存存取,以及IRQ中断请求,只要解决好这两个方面的隔离、保护以及性能问题,就是成功的I/O虚拟化。在以前,Intel提供的设备虚拟化技术(VT-d,VT是Virtualization Technology虚拟化技术,d是device设备的意思)多出现在服务器芯片组上,现在随着Nehalem的出现,VT-d技术也开始流入桌面/移动市场(Core i7主板上已经可以见到VT-d功能)。
 |
| Core i7主板:Intel X58SO主板 - VT-d设置界面 |
 |
| Core i7主板:Intel X58SO主板 - VT-d设置界面 |
|
以往VT-d技术集成在北桥MCH内,和内存控制器的关系非浅
Intel的虚拟化平台包含了三个部分,除了EPT/VPID属于的VT-x虚拟化之外,还有关键的I/O虚拟化VT-d,用于解决I/O设备与虚拟机数据交换的问题,而这部分主要相关的是DMA直接内存存取,以及IRQ中断请求。在以前,Intel提供的设备虚拟化技术(VT-d,VT是Virtualization Technology虚拟化技术,d是device设备的意思)是集成在MCH芯片上面的,现在Nehalem集成了内存控制器,因此其部分功能也就相应地进驻处理器当中——剩下一部分则仍然留在了新的Tylersburg芯片组当中,并且得到了进一步的提升。
Intel 82576EB千兆网络芯片,支持VMDq,支持VT-c
Intel虚拟化平台策略的第三个部分是连接虚拟化VT-c(c是connetive的意思),在Nehalem-EP + Tylersburg平台上,这一点也得到了体现。关于VT-c技术,将另有专文介绍(计划中)。
最后,Nehalem-EP的超线程也是和虚拟化紧密相关的部分:多了一倍的逻辑处理器,可以支持更多的虚拟客户机数,而且,硬件实现的逻辑处理器,要比虚拟机软件虚拟出来的效果要好的多了。
Nehalem: SSE4.2 Instruction Set
Nehalem:SSE4.2指令集
由于现在的x86 CPU都可以通过解码器将x86指令解码为uops再执行,而这个解码阶段是可以通过Microcode ROM控制的,添加新的解码方法很容易,因此现在Intel处理器的指令集扩充显得有些任意:指令数目不停地增多。当然,从编程的角度来看,使用预先给出的硬件指令到底是会比自己进行繁琐的程序设计要方便得多,而性能也获多或少总有些提升:

Nehalem附带了SSE4.2指令集,共7条指令
|
SSE4指令集是自SSE以来最大的一次指令集扩展,它实际上分成了三个阶段来更新:提前发布的SSSE3、Penryn中出现的 SSE4.1和Nehalem中出现的SSE4.2,其中成熟的Penryn中集成的SSE4.1占据了大部分的指令,因此Nehalem中的SSE4指令集更新很少。要发挥新指令集的功能,需要在程序设计方面的支持,Intel自己的编译工具自然有所提供——从10.0版本开始。
Intel High-k Metal Gate晶体管
Intel High-k Metal Gate晶体管
和Penryn一样,Nehalem的生产工艺,都是45nm CMOS工艺,采用了金属栅极High-K电介质晶体管以及9层铜互联技术,总晶体管数量则为0.781 Billion——7.81亿,比Bloomfield要多一些,因为Gainestown要比Bloomfield多了一个QPI总线。
Nehalem-EP晶圆下部的左边是QPI0,右边是QPI1
在《2008年度评测报告:深入Nehalem微架构》中,笔者简单地提到了为了降低功耗,Nehalem将以前使用的Domino线路更换为了Static CMOS线路:
为了降低能耗,Nehalem架构将以往应用的Domino线路更换为Static CMOS线路,速度有所降低,但是能源效率提升了
除了线路类型的变更之外,Nehalem的晶体管也进行了变化:
基本CMOS MOSFET晶体管结构,channel沟道存在于图上的“通道”区域
Intel High-k Metal Gate晶体管,S极到D极的红色箭头就是“channel沟道”,也就是耗尽区所在
在同一个线路中,使用的晶体管不同,耗电也是不同的,MOSFET元件按沟道长度可以分为长沟道Long Channel和短沟道Short Channel,短沟道具有较好的性能,不过其漏电流也相应更大(耗尽区宽度不足而与源极合并而导致大量漏电电流)。
这个图可不容易明白:沟道长度与漏电的关系,请自行理解(越低的延迟,越高的漏电电流)
在IC设计当中通常需要根据不同的情况使用不同沟道长度的晶体管,对于Nehalem而言,非时序关键(non-timing-critical)的线路可以使用性能略差的长沟道MOSFET晶体管以减少亚阈值漏电(subthreshold leakage,MOSFET的subthreshold亚阈值特性被广泛利用在低电压线路上),实际上Intel用的是"longer-channel"——“更长沟道”的MOSFET。Nehalem核心部分的58%和核外部分(不包括缓存阵列)的85%都使用了更长沟道晶体管,最后,漏电功率被控制到总功耗的16%。代价是Nehalem的L1-D延迟由上一代的3时钟周期上升到4时钟周期。
在Nehalem处理器当中,除了大规模使用长沟道晶体管技术来降低总漏电之外,还搭载了一个新的单元,来管理所有的核心的工作状态,包括电压、频率等,这个单元的名字就叫作Power Control Unit电源管理单元。它也负责处理器参数的实时监测。空闲的核心和缓存将会被降低供应电压,并降低工作频率,以达到降低功耗、节约能源的目的。
PCU是Nehalem处理器的电源总管
在需要的情况下,空闲的核心和缓存可以设置为关闭模式以降低耗电。彻底避免这些线路用电是不太可能的,在关闭模式下,SRAM的供电将从0.90V降低到0.36V,提供83%的漏电功耗节约,作为比较,睡眠电压是0.75V,节约为35%。关闭模式是由Power Gate电源阀来实现的:
Power Gate是PCU的实际执行者之一
为了实现PCU,Nehalem使用了特别的工艺,在第9金属层上实现了非常低导通电阻和非常高关闭电阻及极低晶体管漏电的Power Gate电路。
通过Power Gate,在Nehalem上还实现了了一种新的能耗比控制技术:Turbo Mode,或者叫做Turbo Boosting,这种技术在笔记本上曾经出现过。作用就是当一些核心处于空闲状态,被Power Gate关闭之后,剩余的核心可以动态提升频率以提升负载的相应能力。
通常状态
两个核心被Turbo Boost
TDP允许的情况下,所有的核心都被Turbo Boost
TDP允许的情况下,部分核心允许更进一步地Turbo Boost
并不是所有的处理器都具有Turbo Mode功能,在Xeon 5500系列处理器当中,只有最后一位数字为0的处理器具备超线程技术和Turbo Mode,为其他数字的则没有。一开始,桌面版本的Nehalem也是没有超线程技术和Turbo Mode的,后来Intel改变了主意,这个举动应该是为了刺激市场,通过培养消费者来扩展它们的应用领域。
从前面可以看出,Nehalem架构比以往Intel处理器具有了较大的变迁,这个变迁带来了非常直接的性能提升,总结起来,Nehalem-EP/Gainestown比Penryn/Harperton具备的主要优势有三点:
直联架构带来了IMC和QPI
IMC:CISC的x86架构对缓存/内存带宽极度渴求,集成内存控制器让处理器避开了访问内存需要通过FSB总线的限制,并将带宽提升到三通道DDR3 1333(8核心Nehalem-EX支持四通道DDR3)每处理器,极大提升了Nehalem处理器的内存带宽,对服务器应用提升巨大。
QPI:新的点对点总线带宽更高,并且让处理器之间可以直接连接,避免了共享的FSB总线在处理器核心过多时的效率急剧下降,更适合扩展到大规模并行系统。同样处理器数量下,QPI点对点形成的ccNUMA拓扑比共享FSB的星型总线具有更高的效率。
|
虽然SMT有不少处理器采用,不过,在x86处理器上只有Intel具有
HTT:超线程技术在打游戏的时候或许看不出有作用,不过在企业级别应用上效果明显。在主要竞争对手也有IMC和类似QPI的情况下,HTT就成为了Nehalem的特别武器。这项据说耗资十亿开发费用的技术终于从Nehalem开始大放光芒。
要了解一款处理器,可以先看它的规格表。在Nehalem-EP 新Xeon 5500处理器首度曝光中我们已经有了一个简单的表格介绍Nehalem-EP/Gainestown处理器的规格,不过这个规格表不是非常完善,而且只有Nehalem-EP部分的数据,因此我们整理了以下表格,包括了Core i7/Bloomfield、Xeon Harptown和Nehalem-EP/Gainestown的完整处理器资料:
Intel Core i7/Bloomfield规格表 | ||||
名称 | Core i7 920 | Core i7 940 | Core i7 Extreme 965 | Core i7 Extreme 975 |
| 系列 | Nehalem/Core i7 | Nehalem/Core i7 Extreme | ||
| 每系统数 | 1 | |||
| 频率 | 2.66GHz | 2.93GHz | 3.20GHz | 3.33GHz |
| QPI速率 | 4.80GT/s | 6.40GT/s | ||
| Turbo Boost | ○ | |||
HTT(SMT) | ○ | |||
核心/线程 | 4/8 | |||
L2缓存 | 4 x 256KB | |||
L3缓存 | 8MB | |||
| TDP | 130W | |||
普通的Core i7和Core i7 Extreme的区别就在于主频,以及QPI总线规格。

45nm Harpertown Xeon的型号众多,可以按照FSB分为1333MHz(5400)和1600MHz(5402),或者分为低电压版和普通版。不同型号的差别只是在于主频、FSB总线和TDP。
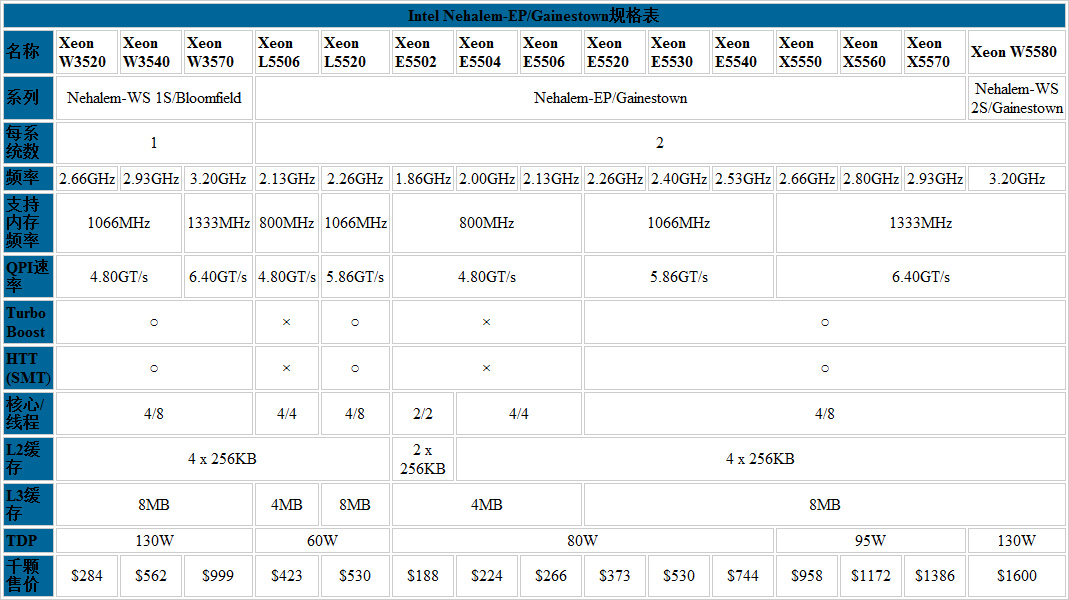
Nehalem-EP/Nehalem-WS规格对照表
上表除包括了Nehalem-EP/Gainestown之外,还包括了Nehalem-WS——这一系列CPU部分属于Bloomfield(Nehalem-WS 1S系列),部分属于Gainestown(Nehalem-WS 2S系列,只有一款型号:Xeon W5580)不过是面向Workstation市场,它们和Nehalem-EP的区别就是它们大部分只支持一路处理器系统(也就是Nehalem-WS 1S系列;支持二路系统的是Nehalem-WS 2S系列并只有一款处理器:W5580)。不同型号的差别在于主频、QPI总线(有三种)、L3容量(有两种)和TDP(有四种)。Nehalem-EP也提供了两款低电压版型号。Nehalem-EP还提供了一款双核的型号,此外并不是所有的Nehalem-EP都搭载了HTT超线程技术(同时和Turbo Boost技术)。
为了搭载全新的Nehalem处理器,需要同样是全新的芯片组,这个芯片组需要QPI总线,并且不需要内存控制器,这个芯片组就是Tylersburg。

如同Nehalem处理器有普通版本和Nehalem-EP版本一样,Tylersburg芯片组也有普通版本和Tylersburg-EP版本,普通版本的Tylersburg我们都已经很熟悉,就是搭配Core i7处理器用的X58芯片组。

由于Nehalem处理器已经集成了内存控制器,因此主板芯片组上就没有必要再有,因此北桥芯片组的名称也就不能再叫MCH(Memory Controller Hub),现在的Tylersburg叫做(IOH,I/O Hub)。
作为一个IOH,IO自然是其目的,Tylersburg的IO主要针对三个方面:CPU、PCIE设备和ICH南桥,这三种设备的连接分别由QPI、PCI Express、ESI来完成。其中PCI Express支持是Tylersburg最重要的部分。
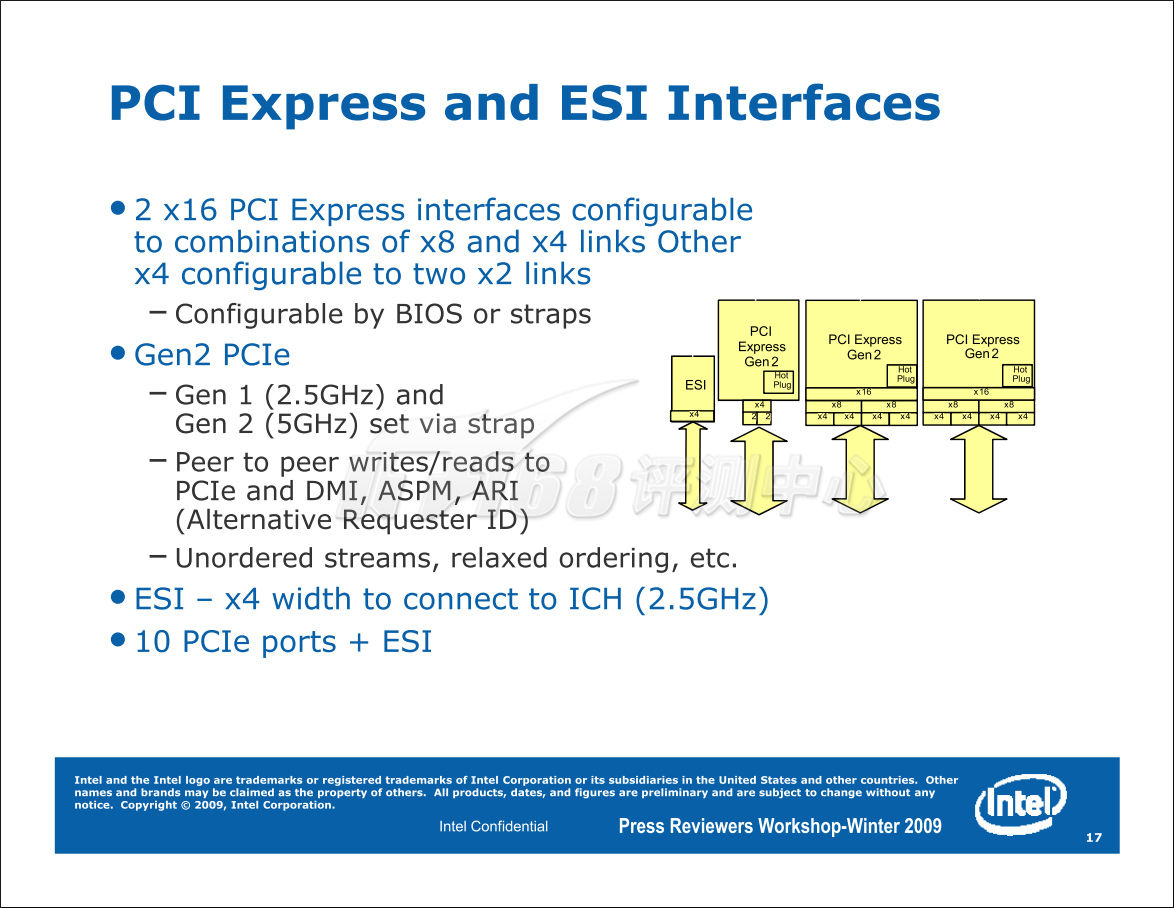
Tylersburg-EP IOH最多可以提供2个x16规格的PCI Express总线(Tylersburg-36D),并且可以分割为多个细小的连接,如分解为4个x8,或者最多分解为8个x4。除了两个这两个可以用来连接显卡的x16界面之外,Tylersburg-EP还可以额外提供一个x4界面用来在连接两块x16显卡之后连接其它如阵列卡这样的设备,这个额外的端口可以分割为两个x2界面。因此,Tylersburg-EP最多具有10个PCI Express端口,并且这些端口都属于第二代(PCI Express Gen 2,或者2.0),每信道带宽达到了500MB/s,是其上一代的两倍。
包括ICH10R在内,Tylersburg最多可以提供42个PCIe Lanes:36个Gen2,6个Gen1
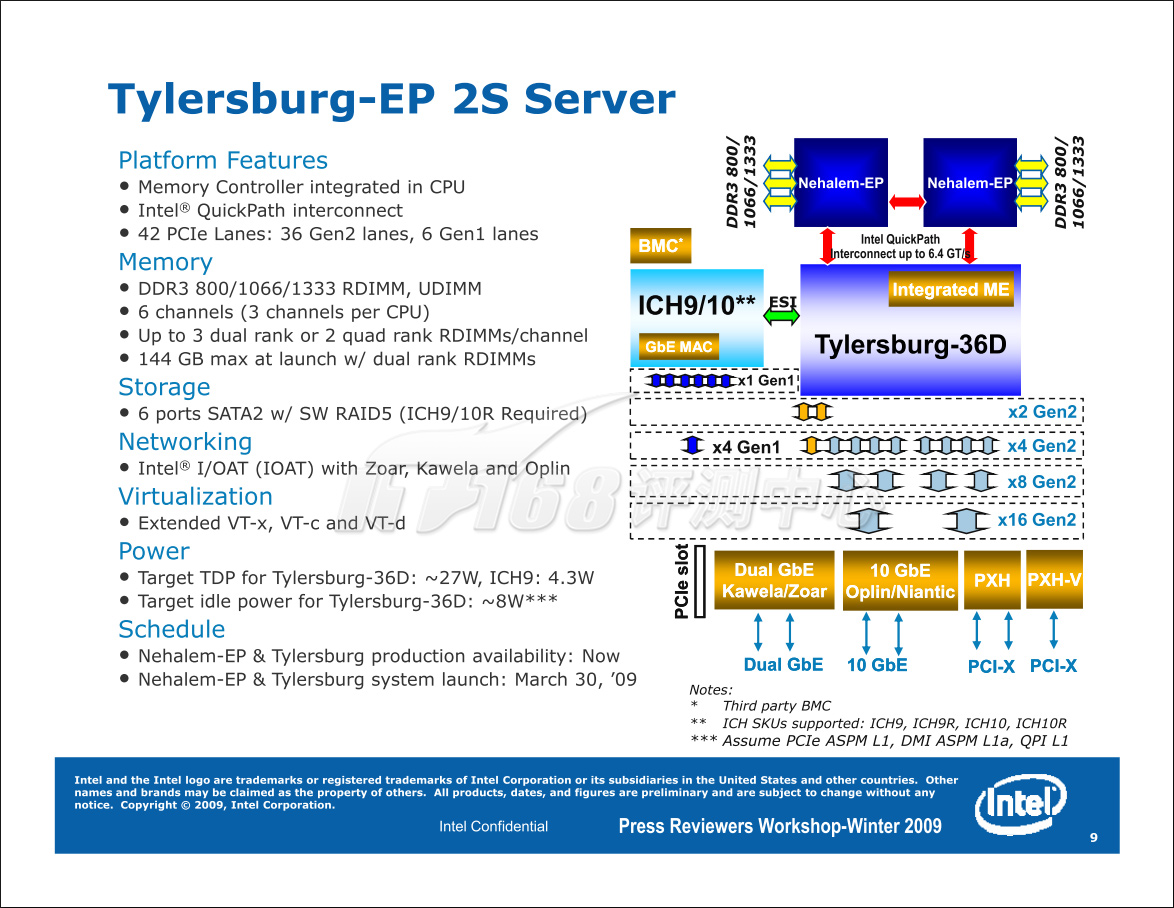
Tylersburg-EP最多提供两个QPI总线,可以最多支持两路Nehalem-EP处理器(我们尝试了将Core i7放上去,结果无法启动……)。Tylersburg-EP使用的南桥是ICH10R,而不是以往的ESB63x1系列,这一点和桌面版本的Tylersburg/X58一样。
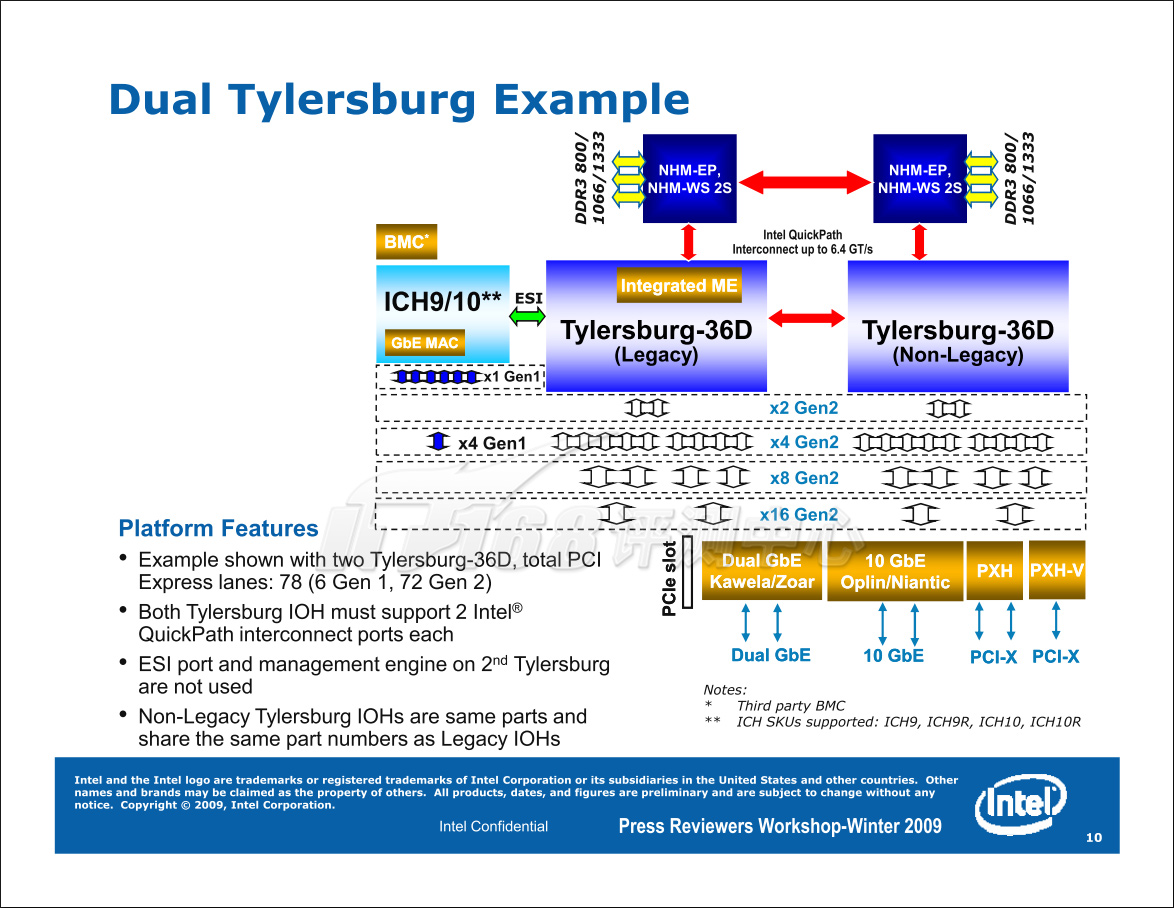
Tylersburg-EP还支持特别的双芯片组设置:两个Tylersburg通过QPI总线互相连接,并分别连接一个Nehalem-EP处理器,这样,整个系统就可以提供非常多的PCI Express信道,例如,连接4块全速的PCI Exress 2.0 x16显卡等。

Tylersburg-EP最多支持两个QPI总线,最高3.2GHz,6.4GT/s
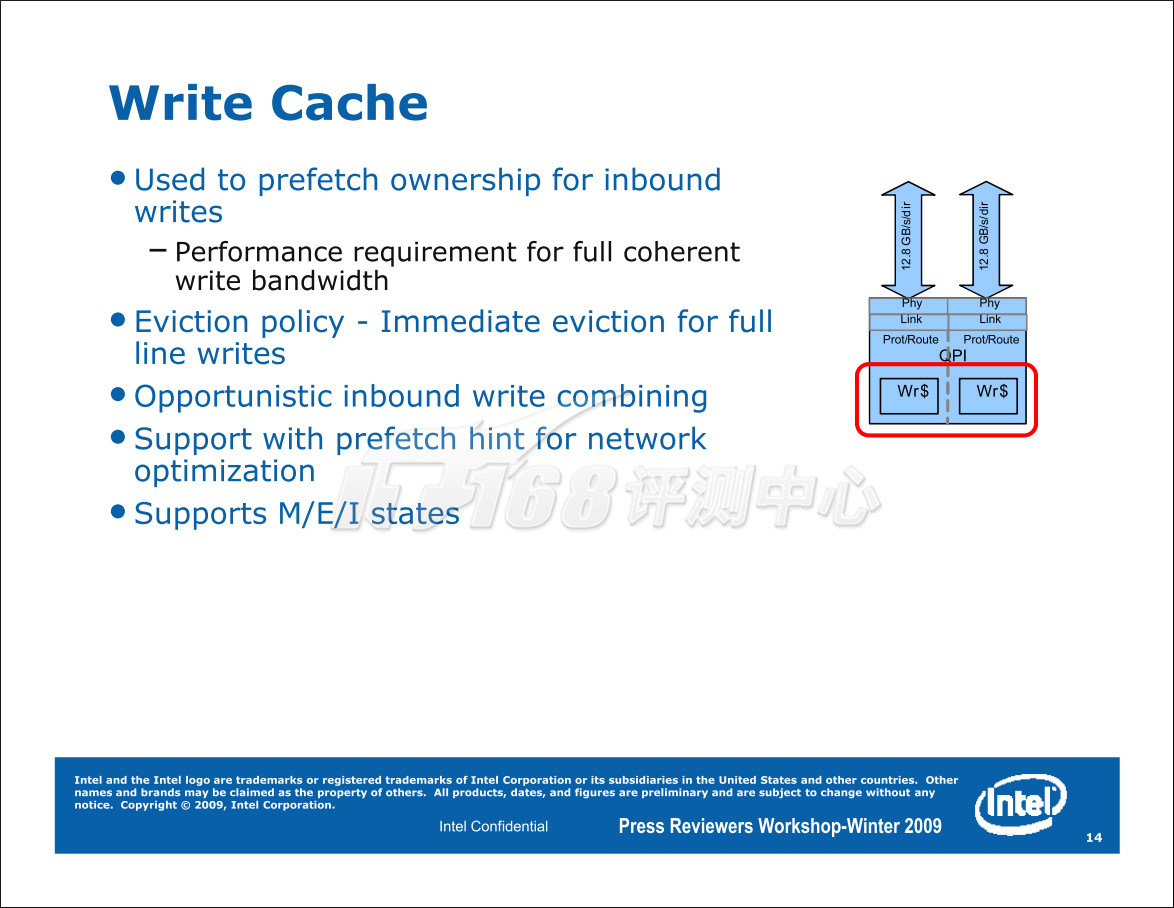
Tylersburg-EP还拥有写入缓存,用于缓冲QPI发来的写入请求以提高性能

除了在Nehalem处理器集成的部分VT-d虚拟化增强技术之外,Tylersburg-EP也集成了这个技术的一部分(依赖于PCI Express的那部分),Tylersburg-EP支持IOAT2,支持ATS和中断重映射特性,并提供更强的性能

Tylersburg-EP还支持Intel Intelligent Power Node Manager(Intel智能电源节点管理器),进一步提升Intel平台的远程管理能力
Tylersburg芯片其实分为四个型号,按照单处理器/双处理器分两种,按照PCI Express信道的数量又分为两种,二二得四,最终的型号就有:Tylersburg-24S、Tylersburg-36S、Tylersburg-24D和Tylersburg-36D,这些型号非常好记:数字表明了PCI Express信道的数量,字母表示单处理器还是双处理器,S就是Single单处理器,D就是Dual双处理器。
Intel Tylersburg芯片组规格表 | ||||
名称 | Tylersburg-24S | Tylersburg-36S | Tylersburg-24D | Tylersburg-36D |
| 系列 | Tylersburg-DT | Tylersburg-EP | ||
| 对应处理器 | Nehalem/Bloomfield | Nehalem-EP/Gainestown | ||
| QPI数/处理器数 | 1 | 2 | ||
| PCIE Lanes | 24(16+8) | 36(16+16+4) | 24(16+8) | 36(16+16+4) |
| QPI速率 | 6.40GT/s | |||
| VT-d Gen 2 | ○ | |||
IOAT2 | ○ | |||
南桥总线 | DMI/ESI | |||
南桥 | ICH10R | |||
单处理器版本是因为只具有一个QPI总线,双处理器则是因为具有两个。我们目前接触到的Tylersburg-EP都是Tylersburg-36D。桌面的Core i7处理器搭配的X58芯片组实际上就是Tylersburg-36S。

两块Nehalem-EP Xeon E5540

主频2.53GHz,QPI总线频率2.93GHz

Nehalem-EP/Gainestown vs Penryn/Harpertown

Nehalem-EP/Gainestown vs Shanghai

Nehalem-EP/Gainestown vs Shanghai

Nehalem-EP/Gainestown vs Xeon-DP/Dunningtown

Nehalem-EP/Gainestown vs Xeon-DP/Dunningtown


Intel Tylersburg-EP芯片组实物
这个Intel Tylersburg-EP芯片型号为Intel 5520,属于Tylersburg-36D系列,提供了36条PCI Express信道,其结构如下:
Intel 5520/Tylersburg-36D结构图
Intel 5520/Tylersburg-36D结构图

曙光的Nehalem-EP测试样机I620r-G是一台2U机架式服务器

曙光I620r-G服务器面板

曙光I620r-G服务器面板
曙光I620r-G服务器最多支持12个3.5英寸热插拔SAS硬盘

曙光I620r-G服务器

此次送测的曙光I620r-G服务器采用了单电源配置

曙光I620r-G服务器:主要的CPU-内存部分被一个导风罩罩住集中散热

曙光I620r-G服务器

曙光I620r-G服务器选用额定功率为600W的服务器电源

曙光I620r-G服务器:AVC热插拔风扇模块

曙光I620r-G服务器采用了Tylersburg-36D芯片组,可以提供总达42条的PCI Express Lanes

此次送测的曙光I620r-G服务器使用了Fujitsu的SAS硬盘

Fujitsu MBA3300RC,15000RPM,300GB,SAS 3Gbps,16MB Cache
这些硬盘使用板载的LSI SAS控制芯片
曙光I620r-G服务器:两个Xeon E5540处理器,主频2.53GHz,QPI频率2.93GHz

两个做工精良的三热管散热器


使用了12条2GB的R-ECC DDR3-1066内存

Micron美光的内存条

R-ECC模块的Registered部分

Intel Tylersburg-36D/Intel 5520芯片组

主板提供了一条PCI Express 2.0 x16插槽,不过其实际速度是x8。此外还有3条x8插槽,总共就是4条PCI Express 2.0 x8

Intel 82576双口千兆网卡,支持VMDq,支持IOAT2,支持VT-c,界面为PCI Express x4,直接挂在Tylersburg-36D的一个PCI Express x4接口上,性能非凡

Intel ICH10R南桥芯片

ICH10R提供的6个SATA 3Gbps接口

用于远程网络管理的Realtek RTL8201N百兆网络芯片

Winbond的FWH芯片
在2005年度服务器横评之后,我们认为当时的网络实验室无法满足今后继续发展的服务器测试的需要。所以,2006年我们IT168评测中心又斥资几十万对于IT168网络实验室的服务器测试平台进行了大幅度的升级,为思科Catalyst4500千兆交换机(WS-X4013+ Supervisor Engine II-Plus和WS-X4548-GB-RJ45)增加了一个思科全千兆24口模块WS-X4424-GB-RJ45,可同时连接72个千兆铜缆设备和2个光缆设备。另外,我们还购置了29台Dell PowerEdge SC430塔式服务器和原来的32台主流配置PC一起为服务器测试平台的提供负载。2007年,我们又采购性能更强的部分客户端,来确保为新一代的服务器提供足够的测试负载。2009年初,我们又对所有客户端的内存子系统进行了全面的升级。
Catalyst4500千兆交换机
部分Dell PowerEdge SC430服务器
在新的测试环境下,我们进一步完善了服务器性能测试方案:
SPEC CPU 2006 v1.0.1
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC CPU 2006是SPEC组织推出的CPU子系统评估软件最新版,我们之前使用的是SPEC CPU 2000。和上一个版本一样,SPEC CPU 2006包括了CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能,SPEC CPU 2006中对SPEC CPU 2000中的一些测试进行了升级,并抛弃/加入了一些测试,因此两个版本测试得分并没有可比较性。
SPEC CPU测试中,测试系统的处理器、内存子系统和使用到的编译器(SPEC CPU提供的是源代码,并且允许测试用户进行一定的编译优化)都会影响最终的测试性能,而I/O(磁盘)、网络、操作系统和图形子系统对于SPEC CPU2006的影响非常的小。
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、DCC以及科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库服务器、电子邮件服务器和Web服务器等基于整数应用的多处理器系统的性能。
我们在被测服务器中安装了当前最新版本的Intel C++ 10.1.025 Compiler、Intel Fortran 10.1.025 Compiler这两款SPEC CPU 2006必需的编译器,通过最新出现的QxS编译参数,Intel Compiler 10版本开始支持对Intel SSE4指令集进行优化(假如只支持SSE3,则使用QxT编译参数)。我们另外安装了Microsoft Visual Studio 2003 SP1提供必要的库文件。按照SPEC的要求我们根据自己的情况编辑了新的Config文件,使用了较多的编译选项。我们根据被测系统选择实际可同时处理的线程数量,最后得到SPEC rate base测试结果(基于base标准编译,SPEC base rate测试代表系统同时处理多个任务的能力)。
和其它测试部件不同,SPEC CPU 2006需要大量的系统物理内存,我们的SPEC测试在64bit Windows Server 2008 Enterprise下完成,对于每个运算核心,配置1.5GB内存。
Iometer 2006.7.27
Iometer是一款功能非常强大的IO测试软件,它除了可以在本机运行测试本机的IO(磁盘)性能之外,还提供了模拟网络应用的能力。在这次的测试中,我们仅仅让它在本机运行测试服务器的磁盘性能。为了全面测试被测服务器的IO性能,我们分别选择了不同的测试脚本。
Max_throughput(read):文件尺寸为64KB,100%读取操作,随机率为0%,用于检测磁盘系统的最大读取吞吐量
Max_IO(read):文件尺寸为512B,100%读取操作,随机率为0%,用于检测磁盘系统的最大读取操作IO处理能力
Max_throughput(write):文件尺寸为64KB,0%读取操作,随机率为0%,用于检测磁盘系统的最大写入吞吐量
Max_IO(write):文件尺寸为512B,0%读取操作,随机率为0%,用于检测磁盘系统的最大写入操作IO处理能力
SiSoftware Sandra v2009
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。从2007开始,Sandra的Arithmetic benchmarks增加了对SSE3 & SSE4 SSE4的支持,在Multi-Media benchmark中增加了对于SSE4的支持,另外还升级了File System benchmark和Removable Storage benchmark两个子项目。对于新的硬件的支持当然也是该软件每次升级的重要内容之一。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台,这也是我们选择这款软件的原因之一。
NetBench v7.03
NetBench是针对文件服务器的性能测试软件,影响NetBench性能的主要是服务器的磁盘子系统,服务器磁盘控制器、条带大小、读写缓存、硬盘类型、组建磁盘阵列模式、内存容量、网络拓朴结构等都会对测试结果有明显的影响。我们在被测服务器上设立了文件服务器,NetBench通过网络实验室中60个客户端来模拟网络中的PC向文件服务器所发出的文件传输请求,文件服务器则将存储在磁盘上的文件数据发送给相应的客户端。在测试过程中,客户端会以每四台一组的步进依次增加并且向服务器发送文件传输请求,测试结束后控制台收集数据并绘制出服务器的数据传输变化曲线。
Benchmark Factory 4.6
大部分的服务器应用都同数据库有着密切的联系,因此我们今年开始着手在在服务器测试中加入对于数据库性能的测试。我们选择了Benchmark Factory 4.6软件和Microsoft SQL2005 SP3来测试不同的硬件平台在数据库应用中的表现。
我们选择了Benchmark Factory内置的标准测试脚本AS3AP,这项测试可用于对于ANSI结构化查询语言(SQL)关系型数据库进行测试,它可用于测试DBMS(单用户微机数据库管理系统),也可用于测试高性能并行或者分布式数据库。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,在服务器测试平台中显示子系统不重要,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
ScienceMark 2.0
ScienceMark 2.0可以用来评估测试对象在执行科学计算时的运算效能,这部分效能主要和处理器子系统和内存子系统相关。我们主要用来评估测试对象的内存子系统的性能。
系统功耗监测
我们使用UNI-T UT71E智能数字万用表对于被测服务器系统的整体功耗进行了监测,利用随机附带的接口程序,我们可以记录被测服务器任意时间段内的功率变化。
本次Nehalem-EP评测基于一台曙光的服务器,型号为I620r-G,配置的是双路Nehalem-EP Xeon E5540处理器,测试结果并会与我们IT168评测中心的DELL PowerEdge 2900 III服务器进行对比,测试对比平台的详细参数如下:
测试平台、测试环境 | |||||
测试分组 | |||||
类别 | Dawning I620r-G服务器 双路Intel Gainestown Xeon E5540 | 双路Xeon E5430基准平台 DELL PE2900 III服务器 双路Intel Harpertown Xeon E5430 | |||
处理器子系统 | |||||
处理器 | 双路Intel Xeon E5540 | 双路Intel Xeon E5430 | |||
处理器架构 | Intel 45nm Nehalem | Intel 45nm Penryn | |||
处理器代号 | Gainestown | Harpertown | |||
处理器封装 | Socket 1366 LGA | Socke 771 LGA | |||
处理器规格 | 四核 | 四核 | |||
处理器指令集 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | |||
| 主频 | 2.53GHz | 2.66GHz | |||
| 处理器外部总线 | 2xQPI 2933MHz 5.86GT/s 单向11.73GB/s(每QPI) 双向23.46GB/s(每QPI) | FSB 333MHz 1333MT/s 10.6GB/s | |||
L1 D-Cache | 4x 32KB 8路集合关联 | 4x 32KB 8路集合关联 | |||
L1 I-Cache | 4x 32KB 4路集合关联 | 4x 32KB 8路集合关联 | |||
L2 Cache | 4x 256KB 8路集合关联 | 2x 6144KB 16路集合关联 | |||
L3 Cache | 8MB 16路集合关联 | ||||
主板 | |||||
主板型号 | Dawning Tylersburg-36D | DELL PE2900 III | |||
芯片组 | Intel Tylersburg-EP IOH:Intel 5520(Tylersburg-36D) ICH:Intel 82801JR(ICH10R) | MCH:Intel 5000X ICH:Intel ESB6321 | |||
| 芯片特性 | 2xQPI VT-d | 2xFSB1333 12MB Snoop Filter VT-d | |||
内存控制器 | 每CPU集成三通道R-ECC DDR3 1066 | 北桥集成四通道FBD DDR2 667 | |||
内存 | 2GB R-ECC DDR3 1066 SDRAM x12 | 2GB FBD DDR2 667 SDRAM x4 | |||
系统磁盘子系统 | |||||
磁盘控制器 | LSI Embedded MegaRAID SAS RAID Controller | DELL Perc 5/i RAID Controller | |||
磁盘控制器规格 | 8xSAS 3Gbps | 8xSAS 3Gbps | |||
磁盘控制器设置 | RAID 0 | RAID 5 | |||
磁盘控制器驱动 | LSI MegaSR 13.06.0212.2009 | LSI SAS 3.8.0.64 | |||
| 磁盘 | Fujitsu MBA3300RC x2 | Seagate Cheetah 15K.5 ST314655SS x3 | |||
磁盘规格 | 15000RPM 300GB SAS 3Gbps 16MB Cache | 15000RPM 146GB SAS 3Gbps 16MB Cache | |||
磁盘设置 | SAS 3Gbps 50GB系统分区 | SAS 3Gbps 20GB系统分区 | |||
网络子系统 | |||||
网卡 | Intel 82576 Gigabit Dual Port Network Controller | Broadcom BCM5708C PCI-E千兆网卡 x2 | |||
网卡设置 | PCI Express x4 I/OAT Intel Teaming Load Balancing | PCI Express x1 Broadcom NIC Teaming Load Balancing | |||
网卡驱动 | Intel PRO Set 10.3.49.00 | Broadcom NetXtreme 2 11.04.01 | |||
软件环境 | |||||
| 操作系统 | Microsoft Windows Server 2008 Enterprise Edition SP1 x64 | Microsoft Windows Server 2008 Enterprise Edition SP1 x64 | |||
45nm Nehalem-EP/Gainestown Xeon E5540
Nehalem-EP/Gainestown Xeon E5540处理器,主频2.53GHz。QPI总线频率2.933GHz,传输速率是5.866GT/s
Nehalem-EP缓存方面和桌面版本的Core i7一样
Intel Tylersburg芯片组,采用Intel 5520 + ICH10R芯片组
24GB R-ECC DDR3 1066内存,NB Frequency是Nehalem-EP处理器Uncore部分的频率,不是Tylersburg芯片组的频率
每条内存2GB,总共12条Micron PC3-8500F内存。SPD里面还保存了610MHz的内存参数,这个频率比较奇怪
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,它可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台。我们利用了其中多个性能测试模块对于被测系统的性能进行了快速的测试。
有一点需要说明的是,Sandra的处理器架构性能测试是根据处理器所能支持的所有指令集中选择进行的,不同的处理器支持的指令集不同,测试使用到的指令集也就不同。例如,Nehalem在这个测试当中就可以使用SSE4.2,而Penryn就只能使用SSE4.1,而Opteron可能就只能使用SSE3了。一般而言,由于可以使用SSE4,Intel的处理器理论性能会比较好。
SiSoftware Sandra Pro Business 2009 | |||
测试对象 | Dawning I620r-G Nehalem-EP服务器 双路Intel Gainestown Xeon E5540 2.53GHz | DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz | |
Processor Arithmetic Benchmark 处理器架构测试 | |||
| Dhrystone ALU | 129014MIPS | 91006MIPS | |
| Dhrystone ALU vs SPEED | 51.05MIPS/MHz | 34.21MIPS/MHz | |
Whetstone iSSE3 | 111000MFLOPS | 78385MFLOPS | |
| Dhrystone iSSE3 vs SPEED | 43.93MFLOPS/MHz | 29.47MFLOPS/MHz | |
Processor Multi-Media Benchmark 处理器多媒体测试 | |||
Multi-Media Int x16 iSSE4.1 | 269.08MPixel/s | ||
Multi-Media Int x8 aSSE2 | |||
| Multi-Media Int x8 iSSE4.1 | 199.33MPixel/s | ||
Multi-Media Int x16 iSSE4.1 vs SPEED | 106.48kPixels/s/MHz | ||
Multi-Media Int x8 aSSE2 vs SPEED | |||
| Multi-Media Int x8 iSSE4.1 vs SPEED | 74.94kPixels/s/MHz | ||
Multi-Media Float x8 iSSE2 | 206.19MPixel/s | ||
Multi-Media Float x4 iSSE2 | 108.69MPixel/s | ||
Multi-Media Float x8 iSSE2 vs SPEED | 81.60kPixels/s/MHz | ||
Multi-Media Float x4 iSSE2 vs SPEED | 40.86kPixels/s/MHz | ||
Multi-Media Double x4 iSSE2 | 113.93MPixel/s | ||
Multi-Media Double x2 iSSE2 | 55.75MPixel/s | ||
Multi-Media Double x4 iSSE2 vs SPEED | 45.09kPixels/s/MHz | ||
Multi-Media Double x2 iSSE2 vs SPEED | 20.96kPixels/s/MHz | ||
Multi-Core Efficiency Benchmark | |||
Inter-Core Bandwidth | 63.30GB/s | 20.54GB/s | |
Inter-Core Bandwidth vs SPEED | 25.65MB/s/MHz | 7.91MB/s/MHz | |
Inter-Core Latency (越小越好) | 22ns | 90ns | |
Inter-Core Latency vs SPEED (越小越好) | 0.01ns/MHz | 0.03ns/MHz | |
.NET Arithmetic Benchmark .NET架构测试 | |||
Dhrystone .NET | 29299MIPS | 10562MIPS | |
Dhrystone .NET vs SPEED | 11.59MIPS/MHz | 3.97MIPS/MHz | |
Whetstone .NET | 69736MFLOPS | 45399MFLOPS | |
Whetstone .NET vs SPEED | 27.60MFLOPS/MHz | 17.07MFLOPS/MHz | |
.NET Multi-Media Benchmark .NET多媒体测试 | |||
Multi-Media Int x1 .NET | 53.25MPixel/s | 31.28MPixel/s | |
Multi-Media Int x1 .NET vs SPEED | 21.07kPixels/s/MHz | 11.76kPixels/s/MHz | |
Multi-Media Float x1 .NET | 23.09MPixel/s | 8.68MPixel/s | |
Multi-Media Float x1 .NET vs SPEED | 9.14kPixels/s/MHz | 3.26kPixels/s/MHz | |
Multi-Media Double x1 .NET | 45.02MPixel/s | 24.75MPixel/s | |
Multi-Media Double x1 .NET vs SPEED | 17.81kPixels/s/MHz | 9.30kPixels/s/MHz | |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
处理器架构性能测试分为整数和浮点两个部分,在频率更低的情况下,曙光I620r-G服务器的测试成绩全面强于对比的基准服务器,领先幅度在50%~100%左右。
在以往,缓存/内存上,AMD的Opteron和Intel的Xeon基本上是采用了两个策略:AMD Opteron采用了直联架构,处理器独立拥有L1/L2,所有核心共享L3,每一个处理器都直接访问RAM和另外的处理器;Intel Xeon则采用了传统的MCH架构,4核心处理器中,独立拥有L1,每两个核心共享一个L2,没有L3,此外所有的处理器通过FSB互通,以及通过FSB再通过MCH访问RAM。相对来说,在处理器大架构上,AMD的无疑更为先进一些。现在,Nehalem-EP也采用了直联架构,因此对比起来,AMD Operton的优势就消失了。
无论AMD还是Intel,目前的内存架构仍然是读取和写入对称:速度都一样。毫无疑问,虽然不同的应用具有不同的读写比,不过在大多数情况下都应该是读需求远高于写需求的,未来可能会采用特别为读取优化的不对称内存读写架构。
|
SiSoftware Sandra Pro Business 2009
|
|||
|
测试对象
|
Dawning I620r-G Nehalem-EP服务器 双路Intel Gainestown Xeon E5540 2.53GHz |
DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz |
|
|
Memory Bandwidth Benchmark
内存带宽测试 |
|||
|
Int Buff'd iSSE2 Memory Bandwidth
|
9.02GB/s
|
6.13GB/s | |
|
Int Buff'd iSSE2 Memory Bandwidth vs SPEED
|
9.43MB/s/MHz | ||
|
Float Buff'd iSSE2 Memory Bandwidth
|
8.90GB/s
|
6.13GB/s | |
|
Float Buff'd iSSE2 Memory Bandwidth vs SPEED
|
9.43MB/s/MHz | ||
|
Memory Latency Benchmark
内存延迟测试 |
|||
|
Memory(Random Access) Latency
(越小越好) |
96ns
|
108ns | |
|
Memory(Random Access) Latency vs SPEED
(越小越好) |
0.16ns/MHz | ||
|
Speed Factor
(越小越好) |
59.40
|
95.20 | |
|
Internal Data Cache
|
4clocks
|
3clocks | |
|
L2 On-board Cache
|
10clocks
|
18clocks | |
|
L3 On-board Cache
|
52clocks
|
||
|
Cache and Memory Benchmark
缓存及内存测试 |
|||
|
Cache/Memory Bandwidth
|
122.06GB/s
|
68.88GB/s | |
|
Cache/Memory Bandwidth vs SPEED
|
49.46MB/s/MHz | 26.52MB/s/MHz | |
|
Speed Factor
(越小越好) |
22.80
|
111.90 | |
| Internal Data Cache | 398.74GB/s | 421.23GB/s | |
| L2 On-board Cache | 368.03GB/s | 122.68GB/s | |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
和上一页类似,采用了直联架构之后,Nehalem-EP的缓存/内存性能大幅度提升。
SPEC CPU 2006整数运算主要包含编译、压缩、人工智能、视频压缩转换、XML处理等,此外,各种日常操作也主要是基于整数操作。SPEC CPU 2006的整数运算包含了400.perlbench PERL编程语言、401.bzip2 压缩、403.gcc C编译器、429.mcf 组合优化、445.gobmk 人工智能:围棋、456.hmmer 基因序列搜索、458.sjeng 人工智能:国际象棋、462.libquantum 物理:量子计算、464.h264ref 视频压缩、471.omnetpp 离散事件仿真、473.astar 寻路算法、483.xalancbmk XML处理共12项。
曙光I620r-G服务器Nehalem-EP/Gainestown Xeon E5540 SPEC CPU 2006整数运算性能
对比频率更高的Harpertown,曙光I620(r)-G服务器Nehalem-EP/Gainestown的性能可谓让人大吃一惊:提升超过了100%,Xeon E5540的得分为153,比Xeon E5430的74.8分高104.5%,同时CPU的主频要低4.95%,成绩斐然。在测试当中,403.gcc C编译器(194.6%)、429.mcf 组合优化(257.6%)、462.libquantum 物理:量子计算(298.8%)、471.omnetpp 离散事件仿真(211.3%)、473.astar 寻路算法(139.9%)、483.xalancbmk XML处理(169.9%)这6项的提升都很明显,这些项目都能因直联架构而获益。所有的项目都能从超线程当中获得提升。
SPEC CPU 2006的浮点运算测试包括的全部都是科学运算,科学运算需要用到大量的高精度浮点数据,如410.bwaves 流体力学、416.gamess 量子化学、433.milc 量子力学、434.zeusmp 物理:计算流体力学、435.gromacs 生物化学/分子力学、436.cactusADM 物理:广义相对论、437.leslie3d 流体力学、444.namd 生物/分子、447.dealII 有限元分析、450.soplex 线形编程、优化、453.povray 影像光线追踪、454.calculix 结构力学、459.GemsFDTD 计算电磁学、465.tonto 量子化学、470.lbm 流体力学、481.wrf 天气预报、482.sphinx3 语音识别共17项测试。
曙光I620r-G服务器Intel Nehalem-EP/Gainestown Xeon E5540 SPEC CPU 2006浮点运算性能
浮点运算上的提升比整数上更大,曙光I620r-G服务器Nehalem-EP/Gainestown的得分为137,比Harpertown的57分高140%,这是IMC、QPI、HTT的集合成果,表明了Nehalem架构的强大优势。在测试当中,410.bwaves 流体力学(390.6%)、433.milc 量子力学(434.8%)、434.zeusmp 物理:计算流体力学(110.5%)、436.cactusADM 物理:广义相对论(122.7%)、437.leslie3d 流体力学(310.9%)、450.soplex 线形编程、优化(279.4%)、459.GemsFDTD 计算电磁学(221.8%)、465.tonto 量子化学(97.0%)、470.lbm 流体力学(278.2%)、481.wrf 天气预报(174.6%)、482.sphinx3 语音识别(333.0%)这11个项目的提升都很大,提升幅度都是几倍几倍的,最高的是433.milc 量子力学(434.8%),Xeon E5540的性能是Xeon E5430的5倍以上。
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
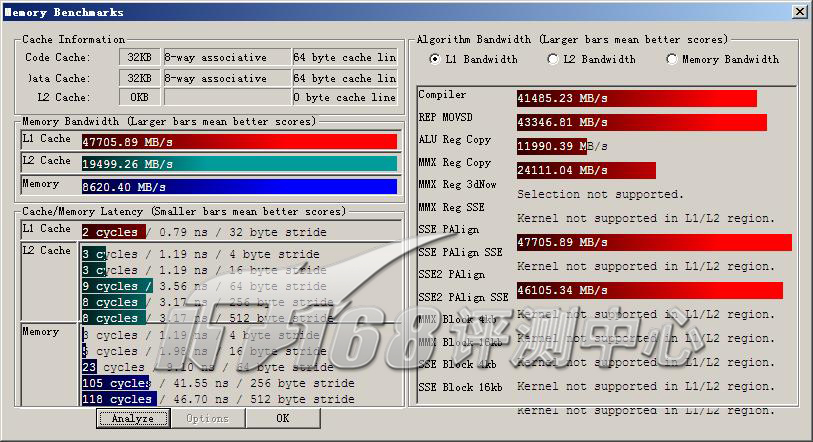
ScienceMark v2.0 Membench L1测试成绩
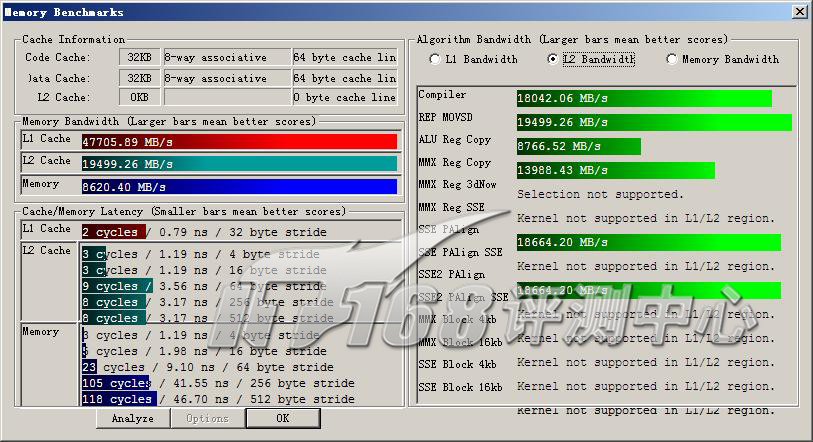
ScienceMark v2.0 Membench L2测试成绩

ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是——当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
ScienceMark Membench | |||
| 厂商 | Dawning | DELL | |
| 产品型号 | I620r-G Nehalem-EP Intel Gainestown Xeon E5540 2.53GHz | PowerEdge 2900 III Intel Harpertown Xeon E5430 2.66GHz | |
| 内存技术参数 | 2GB R-ECC DDR3-1066 SDRAM x12 | 2GB FBD DDR2-667 SDRAM x4 | |
| L1带宽(MB/s) | 47705.89 | 55376.16 | |
| L2带宽(MB/s) | 19499.26 | 16757.55 | |
| 内存带宽(MB/s) | 8620.40 | 4485.09 | |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 2 cycles 0.79 ns | 1.13 ns | |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 41485.23 | 25201.968 | |
| REP MOVSD | 43346.81 | 25467.15 | |
| ALU Reg Copy | 11990.39 | 13093.65 | |
| MMX Reg Copy | 47705.89 | 25242.19 | |
| SSE PAlign | 46105.34 | 52826.21 | |
| SSE2 PAlign | 48167.88 | 55376.16 | |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.19 ns | 1.13 ns | |
| 16 Bytes Stride | 3 cycles 1.19 ns | 1.50 ns | |
| 64 Bytes Stride | 9 cycles 3.56 ns | 4.51 ns | |
| 256 Bytes Stride | 8 cycles 3.17 ns | 4.51 ns | |
| 512 Bytes Stride | 8 cycles 3.17 ns | 4.89 ns | |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 18042.06 | 11880.48 | |
| REP MOVSD | 19499.26 | 12536.88 | |
| ALU Reg Copy | 8766.52 | 8577.86 | |
| MMX Reg Copy | 13988.43 | 13408.31 | |
| SSE PAlign | 18664.20 | 16719.97 | |
| SSE2 PAlign | 18664.20 | 16757.55 | |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.19 | 1.13 | |
| 16 Bytes Stride | 5 cycles 1.98 | 4.89 | |
| 64 Bytes Stride | 23 cycles 9.10 | 19.17 | |
| 256 Bytes Stride | 105 cycles 41.55 | 59.77 | |
| 512 Bytes Stride | 118 cycles 46.70 | 68.04 | |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 8013.28 | 3178.45 | |
| REP MOVSD | 8620.40 | 3220.23 | |
| ALU Reg Copy | 7066.53 | 2789.34 | |
| MMX Reg Copy | 8098.63 | 2972.91 | |
| MMX Reg 3dNow | - | - | |
| MMX Reg SSE | 7288.34 | 3978.53 | |
| SSE PAlign | 7121.20 | 4128.59 | |
| SSE PAlign SSE | 8001.72 | 4390.48 | |
| SSE2 PAlign | 7123.08 | 4326.42 | |
| SSE2 PAlign SSE | 7985.25 | 4441.71 | |
| MMX Block 4kb | 6499.16 | 4063.30 | |
| MMX Block 16kb | 6873.16 | 4479.88 | |
| SSE Block 4kb | 6582.42 | 4074.79 | |
| SSE Block 16kb | 4681.34 | 4485.09 | |
基本上,与处理器结合最紧密的L1,或L2(在有L3的情况下)的延迟总是跟处理器频率密集相关的,从总体测试结果来看,频率较低的Nehalem-EP的L1带宽要低一点,不过其运算带宽缺是Penryn Xeon的两倍左右。整体来说,Nehalem-EP的缓存/内存子系统比Penryn Xeon要强出不少。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
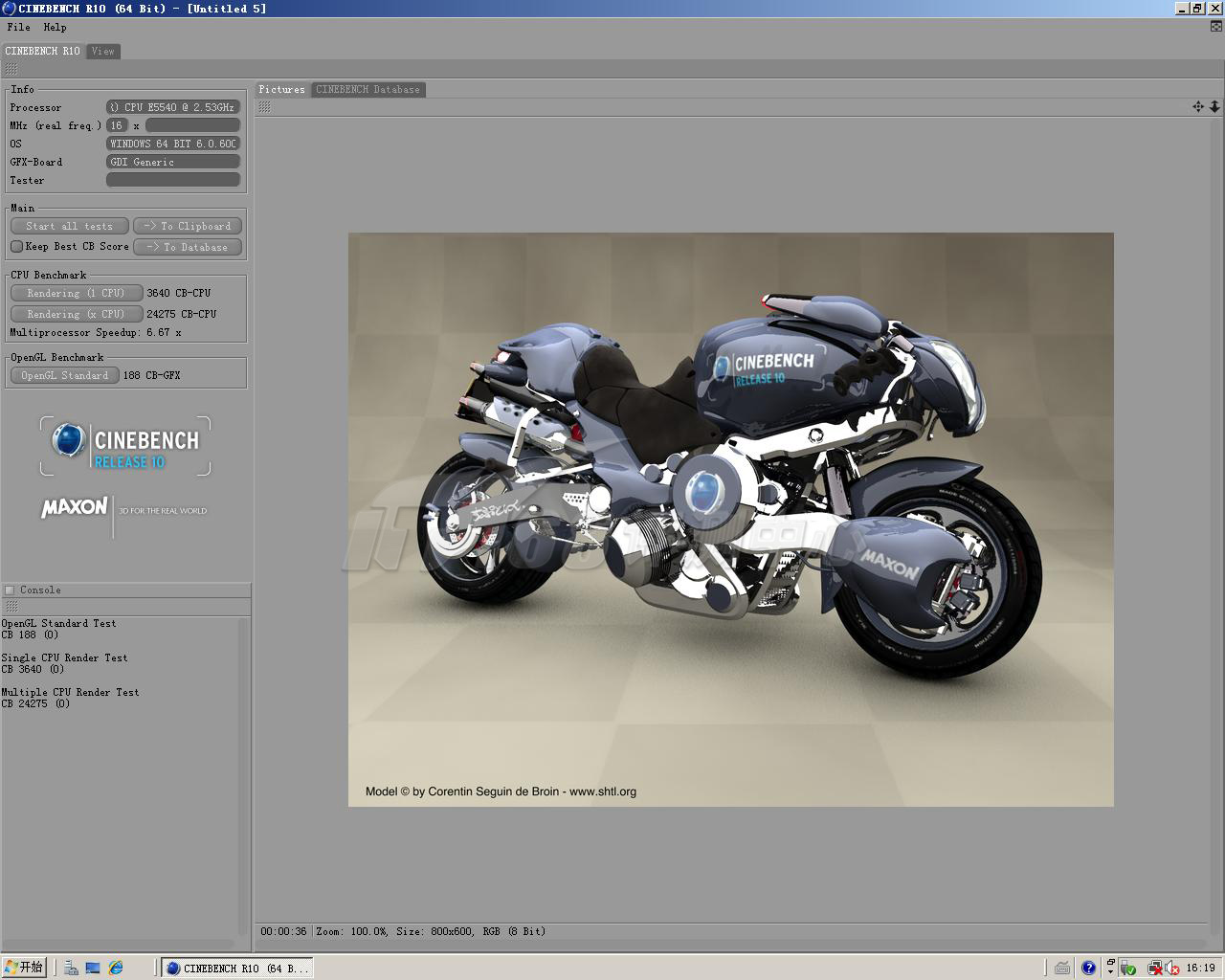
Nehalem-EP/Gainestown Xeon E5540测试成绩
CineBench R10 | |||
处理器 | 曙光I620r-G服务器 双路Intel Gainestown Xeon E5540 | DELL PE 2900 III 双路Intel Harpertown Xeon E5430 | |
| 显卡 | - | - | |
CPU Benchmark | |||
| Rendering (1 CPU) | 3640 CB-CPU | 2931 CB-CPU | |
| Rendering (x CPU) | 24275 CB-CPU | 16806 CB-CPU | |
Multiprocessor Speedup | 6.67x | 5.73x | |
OpenGL Benchmark | |||
OpenGL Standard | 188 CB-GFX | 176 CB-GFX | |
曙光I620r-G服务器测试成绩对比
单处理器的渲染性能,曙光I620r-G服务器要比基准服务器要高24.2%,频率上要低5%,架构提升很明显。
在多处理器的渲染测试中,曙光I620r-G服务器性能要高44.4%,从这一点来说,超线程起到的作用和直联架构起到的作用程度上是差不多的,都很明显。
Iometer 2006.07.27
我们的基准服务器采用了三块15000RPM的Seagate Cheetah 15K.5硬盘。曙光I620r-G服务器则是用两块15000RPM Fujitsu MBA3300C。基准平台使用了LSI MegaRAID SAS 8408E硬件阵列卡组建了RAID 5阵列,而曙光I620r-G服务器只使用了一块集成的LSI Embedded MegaRAID SAS阵列卡。从性能上说偏向于软阵列,显然不及我们的基准服务器,因此结果仅仅具有一点参考价值。
IO读
IO写
读吞吐量
写吞吐量
很传统的曲线,曙光I620r-G服务器的软RAID 0由于使用内存作为缓存,因此连续读取IOps和吞吐量,而随机写入IOps远不及硬件阵列。
NetBench v7.03
NetBench 7.03 Ent_dm.tst测试脚本模拟的是企业级文件服务器应用,它不但要求被测服务器的磁盘子系统可以提供足够的吞吐量,还需要其具有较高的IO处理能力,并且需要较为平衡的读取能力和写入能力。
曙光I620r-G服务器NetBench性能测试
由于磁盘差异比较大,并且处理器对NetBench的影响比较特别,因此曙光I620r-G服务器总成绩不高。这个成绩也是只有参考价值。关于NetBench性能与处理器、内存、磁盘的关系可以看这里《评测机密:文件服务器性能提升N大要义》。
Benchmark Factory 4.6
我们在被测服务器上安装了Microsoft SQL 2005 SP1,按照测试要求建立了数据库。BF在测试之前会在数据库中生成9个表,其中包括4个500万行的表格,每行包括100字节的数据,因此每个表格容量大约是476MB,整个数据库容量为1.86GB。我们用60个客户端模拟1000个用户,在这个数据库中进行查询、添加、删除、修改等操作。
曙光I620r-G服务器SQL2005数据库性能测试
数据库测试是一个综合性的测试,在较少客户端的时候,其性能依赖于处理器以及内存系统,在较多客户端的时候,则开始依赖于磁盘子系统。在这个测试里面,Nehalem-EP的三个优势都得以完全发挥,最终成绩非常惊人:在频率更低的情况下,平均TPS(每秒交易数)要高114%(90557.2对40397.217),提升超过了一倍以上。峰值TPS是96264.5。Nehalem真是理想的数据库平台。
为了体现出超线程对系统性能的影响,我们特地关闭了超线程又作了一遍测试。
SiSoftware Sandra Pro Business 2009 | |||
测试对象 | Dawning I620r-G Nehalem-EP 双路Intel Gainestown Xeon E5540 2.53GHz | Dawning I620r-G | |
Processor Arithmetic Benchmark 处理器架构测试 | |||
| Dhrystone ALU | 129014MIPS | 130767MIPS | |
| Dhrystone ALU vs SPEED | 51.05MIPS/MHz | 51.75MIPS/MHz | |
Whetstone iSSE3 | 111000MFLOPS | 68158MFLOPS | |
| Dhrystone iSSE3 vs SPEED | 43.93MFLOPS/MHz | 26.97MFLOPS/MHz | |
Processor Multi-Media Benchmark 处理器多媒体测试 | |||
Multi-Media Int x16 iSSE4.1 | 269.08MPixel/s | 228.02MPixel/s | |
Multi-Media Int x16 iSSE4.1 vs SPEED | 106.48kPixels/s/MHz | 90.23kPixels/s/MHz | |
Multi-Media Float x8 iSSE2 | 206.19MPixel/s | 172.03MPixel/s | |
Multi-Media Float x8 iSSE2 vs SPEED | 81.60kPixels/s/MHz | 68.08kPixels/s/MHz | |
Multi-Media Double x4 iSSE2 | 113.93MPixel/s | 89.72MPixel/s | |
Multi-Media Double x4 iSSE2 vs SPEED | 45.09kPixels/s/MHz | 35.50kPixels/s/MHz | |
Multi-Core Efficiency Benchmark | |||
Inter-Core Bandwidth | 63.30GB/s | 25.88GB/s | |
Inter-Core Bandwidth vs SPEED | 25.65MB/s/MHz | 10.49MB/s/MHz | |
Inter-Core Latency (越小越好) | 22ns | 58ns | |
Inter-Core Latency? vs SPEED (越小越好) | 0.01ns/MHz | 0.02ns/MHz | |
Memory Bandwidth Benchmark 内存带宽测试 | |||
Int Buff'd iSSE2 Memory Bandwidth | 9.02GB/s | 32.59GB/s | |
Float Buff'd iSSE2 Memory Bandwidth | 8.90GB/s | 32.56GB/s | |
Memory Latency Benchmark 内存延迟测试 | |||
Memory(Random Access) Latency (越小越好) | 96ns | 92ns | |
Speed Factor (越小越好) | 59.40 | 57.90 | |
Internal Data Cache | 4clocks | 4clocks | |
L2 On-board Cache | 10clocks | 10clocks | |
L3 On-board Cache | 52clocks | 51clocks | |
Cache and Memory Benchmark 缓存及内存测试 | |||
Cache/Memory Bandwidth | 122.06GB/s | 120.64GB/s | |
Cache/Memory Bandwidth vs SPEED | 49.46MB/s/MHz | 48.89MB/s/MHz | |
Speed Factor (越小越好) | 22.80 | 23.10 | |
| Internal Data Cache | 398.74GB/s | 401.21GB/s | |
| L2 On-board Cache | 368.03GB/s | 362.61GB/s | |
.NET Arithmetic Benchmark .NET架构测试 | |||
Dhrystone .NET | 29299MIPS | 28774MIPS | |
Dhrystone .NET vs SPEED | 11.59MIPS/MHz | 11.39MIPS/MHz | |
Whetstone .NET | 69736MFLOPS | 44516MFLOPS | |
Whetstone .NET vs SPEED | 27.60MFLOPS/MHz | 17.62MFLOPS/MHz | |
.NET Multi-Media Benchmark .NET多媒体测试 | |||
Multi-Media Int x1 .NET | 53.25MPixel/s | 46.38MPixel/s | |
Multi-Media Int x1 .NET vs SPEED | 21.07kPixels/s/MHz | 18.35kPixels/s/MHz | |
Multi-Media Float x1 .NET | 23.09MPixel/s | 13.30MPixel/s | |
Multi-Media Float x1 .NET vs SPEED | 9.14kPixels/s/MHz | 5.26kPixels/s/MHz | |
Multi-Media Double x1 .NET | 45.02MPixel/s | 24.73MPixel/s | |
Multi-Media Double x1 .NET vs SPEED | 17.81kPixels/s/MHz | 9.79kPixels/s/MHz | |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
只有极少数的项目中,关闭超线程获得了更好的测试成绩。Nehalem-EP的超线程比起Pentium 4时代有了不少的改进,你不应该将其关闭。
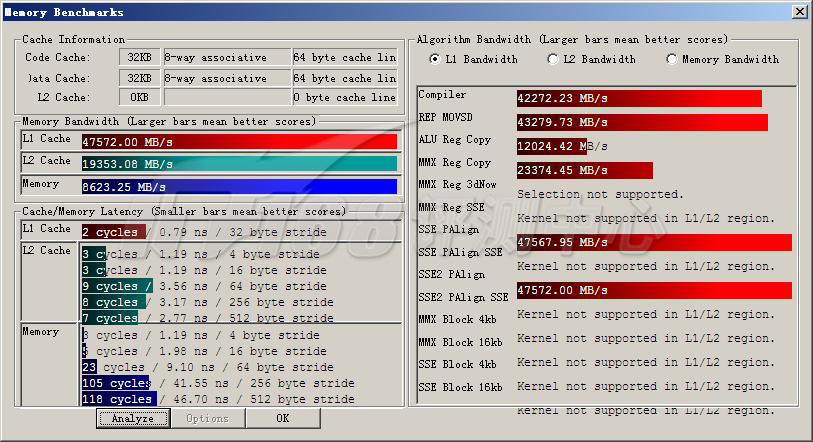
with SMT vs. without SMT
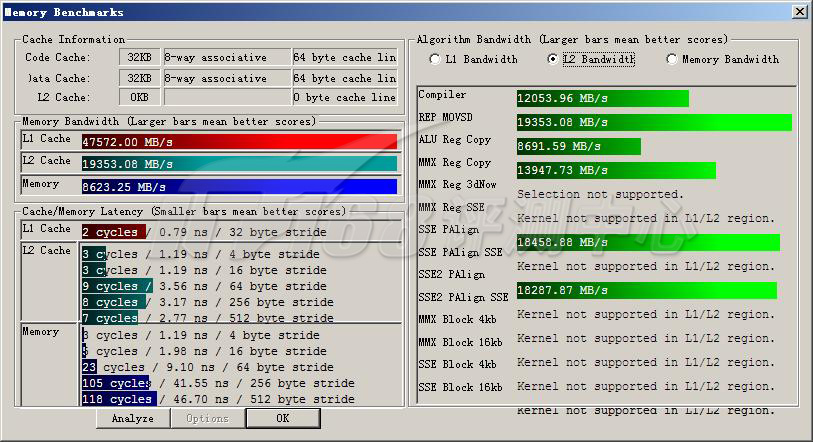
with SMT vs. without SMT
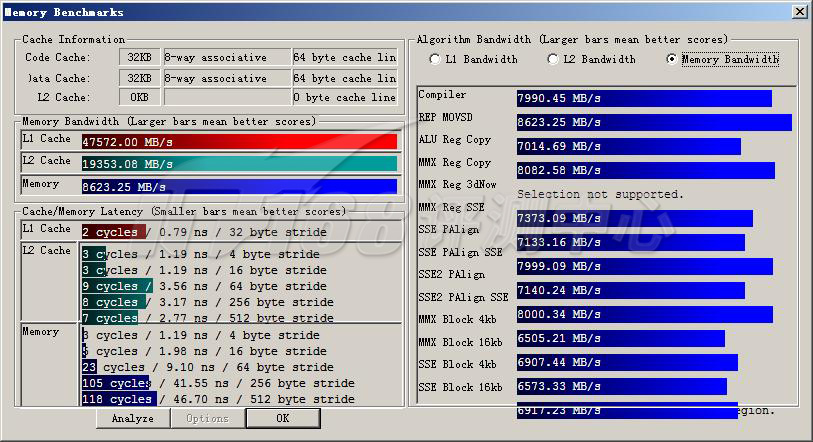
with SMT vs. without SMT
ScienceMark Membench | |||
| 厂商 | Dawning | Dawning | |
| 产品型号 | I620r-G Nehalem-EP Intel Gainestown Xeon E5540 2.53GHz | I620r-G Nehalem-EP Intel Gainestown Xeon E5540 2.53GHz 无超线程 | |
| 内存技术参数 | 2GB R-ECC DDR3-1066 SDRAM x12 | 2GB R-ECC DDR3-1066 SDRAM x12 | |
| L1带宽(MB/s) | 47705.89 | 47572.00 | |
| L2带宽(MB/s) | 19499.26 | 19353.08 | |
| 内存带宽(MB/s) | 8620.40 | 8623.25 | |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 2 cycles 0.79 ns | 2 cycles 0.79 ns | |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 41485.23 | 42272.23 | |
| REP MOVSD | 43346.81 | 43279.73 | |
| ALU Reg Copy | 11990.39 | 12024.42 | |
| MMX Reg Copy | 47705.89 | 23374.45 | |
| SSE PAlign | 46105.34 | 47567.95 | |
| SSE2 PAlign | 48167.88 | 47572.00 | |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.19 ns | 3 cycles 1.19 ns | |
| 16 Bytes Stride | 3 cycles 1.19 ns | 3 cycles 1.19 ns | |
| 64 Bytes Stride | 9 cycles 3.56 ns | 9 cycles 3.56 ns | |
| 256 Bytes Stride | 8 cycles 3.17 ns | 8 cycles 3.17 ns | |
| 512 Bytes Stride | 8 cycles 3.17 ns | 7 cycles 2.77 ns | |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 18042.06 | 12053.96 | |
| REP MOVSD | 19499.26 | 19353.08 | |
| ALU Reg Copy | 8766.52 | 8691.59 | |
| MMX Reg Copy | 13988.43 | 13947.73 | |
| SSE PAlign | 18664.20 | 18458.88 | |
| SSE2 PAlign | 18664.20 | 18287.87 | |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.19 | 3 cycles 1.19 | |
| 16 Bytes Stride | 5 cycles 1.98 | 5 cycles 1.98 | |
| 64 Bytes Stride | 23 cycles 9.10 | 23 cycles 9.10 | |
| 256 Bytes Stride | 105 cycles 41.55 | 105 cycles 41.55 | |
| 512 Bytes Stride | 118 cycles 46.70 | 118 cycles 46.70 | |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 8013.28 | 7990.45 | |
| REP MOVSD | 8620.40 | 8623.25 | |
| ALU Reg Copy | 7066.53 | 7014.69 | |
| MMX Reg Copy | 8098.63 | 8082.58 | |
| MMX Reg 3dNow | - | - | |
| MMX Reg SSE | 7288.34 | 7373.09 | |
| SSE PAlign | 7121.20 | 7133.16 | |
| SSE PAlign SSE | 8001.72 | 7999.09 | |
| SSE2 PAlign | 7123.08 | 7140.24 | |
| SSE2 PAlign SSE | 7985.25 | 8000.34 | |
| MMX Block 4kb | 6499.16 | 6505.21 | |
| MMX Block 16kb | 6873.16 | 6907.44 | |
| SSE Block 4kb | 6582.42 | 6573.33 | |
| SSE Block 16kb | 4681.34 | 6917.23 | |
关闭超线程之后,L1和内存性能着微弱的提升,但是L2性能下降比较明显,这表明Nehalem的L2 Cache可以充分满足处理器的需要,你不需要关闭超线程以获得极微弱的L1/内存性能提升。
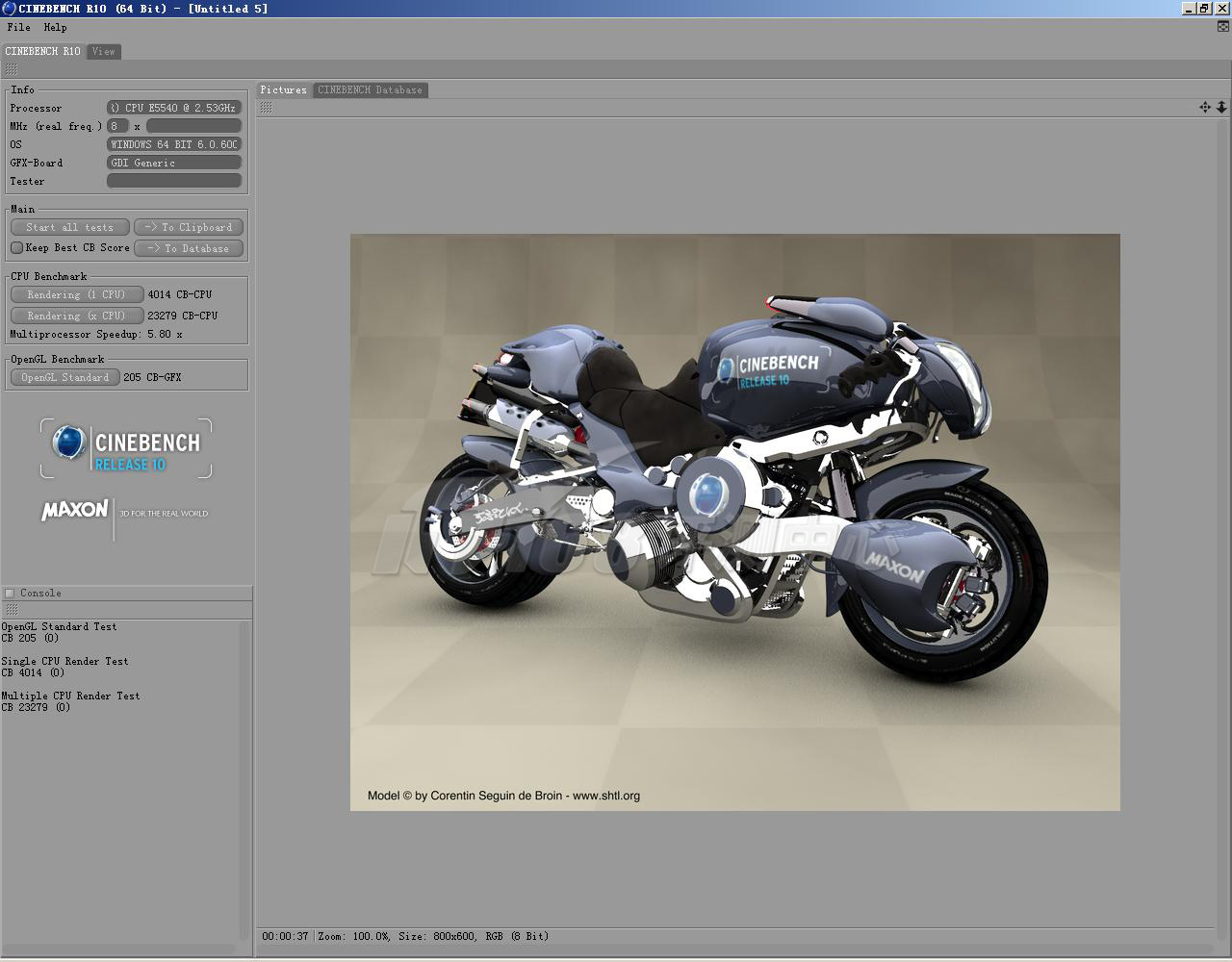
CineBench R10 | |||
处理器 | 曙光I620r-G 双路Intel Gainestown Xeon E5540 | DELL PE 2900 III 双路Intel Gainestown Xeon E5540 无超线程 | |
| 显卡 | - | - | |
CPU Benchmark | |||
| Rendering (1 CPU) | 3640 CB-CPU | 4014 CB-CPU | |
| Rendering (x CPU) | 24275 CB-CPU | 23279 CB-CPU | |
Multiprocessor Speedup | 6.67x | 5.80x | |
OpenGL Benchmark | |||
OpenGL Standard | 188 CB-GFX | 205 CB-GFX | |
曙光I620r-G服务器开关超线程测试成绩对比
没有超线程,单处理器渲染性能上升了10.3%,不过,多处理器渲染性能下降了4.10%。在一般情况下,你仍然没有必要关闭超线程。
IO读
IO写
读吞吐量
写吞吐量
曙光I620r-G Nehalem-EP测试平台的磁盘子系统是一个软阵列,因此性能和处理器子系统和内存子系统相关,关闭超线程会具有一些提升。
曙光I620r-G服务器:with SMT vs withou SMT
关闭超线程成绩略微高一些,总体影响不大。
曙光I620r-G服务器:with SMT vs without SMT
关闭SMT之后,数据库性能立降,降幅达40.4%——你不应该关闭SMT。
曙光I620r-G服务器SPEC CPU 2006整数运算性能:with SMT vs without SMT
关闭超线程之后,曙光I620r-G Nehalem-EP平台的测试成绩下降了12.4%,非常明显。超线程对大部分测试项目都有着正面的提升作用,除了一个项目:456.hmmer 基因序列搜索(关闭后提升4.05%)不算太明显,因此可以认为,在整数运算中,超线程可以很明显地提升处理器效能,你最好打开超线程技术。
曙光I620r-G服务器SPEC CPU 2006浮点运算性能:with SMT vs without SMT
关闭超线程之后,性能下降了7.3%,大部分测试成绩都下降了,少数项目在关闭超线程之后性能不降反升,这几个项目是450.soplex 线形编程、优化(关闭后提升9.35%)、459.GemsFDTD 计算电磁学(关闭后提升19.1%)、470.lbm 流体力学(关闭后提升5.77%)、481.wrf 天气预报(关闭后提升43.5%)共4项,481.wrf 天气预报影响非常巨大,进行相关工作的用户在配置曙光I620r-G服务器的时候可要好好掂量一下。其他的浮点运算用户一般都不必关闭超线程。
我们利用UNI-T UT71E智能数字万用表和相配套的软件对于对于被测服务器在几种不同的状态下的功耗进行了监测,主要包括如下项目:
P1:连接电源但不开机状态
P2:系统启动完毕,5分钟内无动作,但不休眠
P3:系统启动完毕,处理器满载、磁盘以最大吞吐量工作
功耗:Dawning I620r-G服务器与DELL PE2900 III平台
配置上,曙光I620r-G服务器具有24GB的内存,不过是DDR3,基准服务器则只有16GB,不过是大发热量的FBD DDR2。基准服务器平台的硬盘要多一个,不过曙光I620r-G服务器的机架式设计配置了数个比塔式DELL PE2900 III要更暴力散热风扇。总体来看,曙光I620r-G服务器的附件功耗更高一些。上表仅作参考:曙光I620r-G服务器在闲置时功耗确实要低一些,Nehalem的长沟道晶体管、Power Control Unit、Power Gate确实发挥了作用。不过在满负荷情况下,Nehalem-EP和Harpertown的功耗差不多——它们的TDP也比较相近。
【IT168评测中心】凭借着崭新的直联架构——集成内存控制器和双QPI总线,再配合超线程技术,Nehalem-EP的性能比起其上一代有了一个大的飞跃,同频率下处理器密集型和内存密集型运算的性能提升达到了一倍以上。
两个Xeon E5540处理器,主频2.53GHz,QPI频率2.93GHz
我们知道,由于处理器指令集架构的缘故,x86处理器非常依赖于缓存/内存性能,使用集成内存控制器之后,Nehalem-EP消除了FSB总线引起的内存瓶颈,通过每处理器三通道DDR3,提供了高带宽、低延迟的子系统,极大地提升了性能。
同样,高带宽的QPI总线也更有利于多处理器协同工作,虽然在双路系统中表现并不明显,不过,可以预先,在4路及4路以上市场以及非常多PCI Express IO设备的情况下,QPI总线可以发挥巨大的作用。
Nehalem-EP处理器:独孤求败
超线程技术也是Nehalem处理器的要点之一,虽然不是所有的应用中都有正面效果,然而总体来看,超线程技术对SPEC CPU 2006的成绩提升为14.2%(整数)和7.87%(浮点),在应用测试当,如SQL数据库性能测试中,超线程的存在让性能提升了67.8%,这是一个巨大的数字。这表明数据库应用可以将Nehalem-EP的超线程技术发挥到极致。
曙光I620r-G服务器,采用了Xeon E5540处理器
各方面的测试都表明,使用了Nehalem-EP Xeon E5540处理器的曙光I620r-G服务器比起上一代同频率的产品,性能提升非常大,最高在一倍以上,同时功耗并没有变化,成本也很相近,性价比很高。

