曙光Nehalem-EP服务器I620r-G深度评测
The Core Front-End: Decode
处理器核心前端:解码
在将指令充填到可容纳18条目的指令队列之后,就可以进行解码工作了。解码是类RISC(精简指令集或简单指令集)处理器导致的一项设计,从Pentium Pro开始在IA架构出现。处理器接受的是x86指令(CISC指令,复杂指令集),而在执行引擎内部执行的却不是x86指令,而是一条一条的类RISC指令,Intel称之为Micro Operation——micro-op,或者写为µ-op,一般用比较方便的写法来代替希腊字母:u-op或者uop。相对地,一条一条的x86指令就称之为Macro Operation,或macro-op。
RISC架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过深长的流水线达到很高的频率(例如31级流水线的Pentium 4……当然Pentium 4要超过5GHz的屏障需要付出巨大的功耗代价),IBM的Power6就可以轻松地达到4.7GHz的起步频率。关于Power6的架构的非常简单的介绍可以看《机密揭露:Intel超线程技术有多少种?》,我们继续说Nehalem:和RISC相反,CISC指令的长度不固定,执行时间也不固定,因此Intel的RISC/CISC混合处理器架构就要通过解码器将x86指令翻译为uop,从而获得RISC架构的长处,提升内部执行效率。
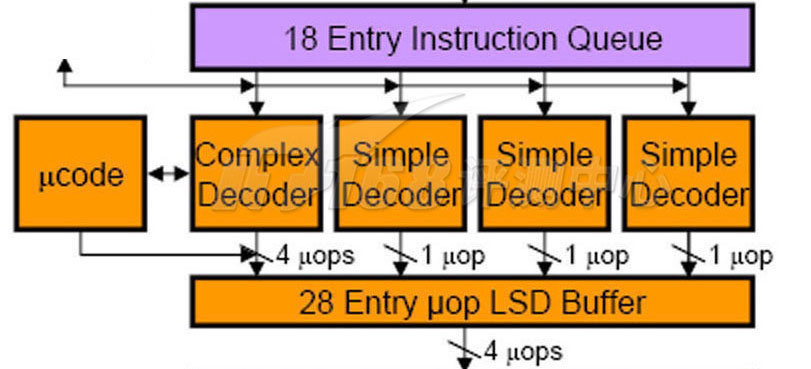
和Core一样,Nehalem的解码器也是4个:3个简单解码器加1个复杂解码器。简单解码器可以将一条x86指令(包括大部分SSE指令在内)翻译为一条uop,而复杂解码器则将一些特别的(单条)x86指令翻译为1~4条uops——在极少数的情况下,某些指令需要通过额外的可编程microcode解码器解码为更多的uops(有些时候甚至可以达到几百个,因为一些IA指令很复杂,并且可以带有很多的前缀/修改量,当然这种情况很少见),下图Complex Decoder左方的ucode方块就是这个解码器,这个解码器可以通过一些途径进行升级或者扩展,实际上就是通过主板Firmware里面的Microcode ROM部分。
2006年进行的一个研究当中表示,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
之所以具有两种解码器,是因为仍然是关于RISC/CISC的一个事实:大部分情况下(90%)的时间内处理器都在运行少数的指令,其余的时间则运行各式各样的复杂指令(不幸的是,复杂就意味着较长的运行时间),RISC就是将这些复杂的指令剔除掉,只留下最经常运行的指令(所谓的精简指令集),然而被剔除掉的那些指令虽然实现起来比较麻烦,却在某些领域确实有其价值,RISC的做法就是将这些麻烦都交给软件,CISC的做法则是像现在这样:由硬件设计完成。因此RISC指令集对编译器要求很高,而CISC则很简单。对编程人员的要求也类似。
The Core Front-End: Decode
作为对比,AMD的处理器从K8以来就具有强大的三组复杂解码器,并且大部分指令都可以解码为1~2条AMD的Micro-operations(这个Micro-op和Intel的uop是不同的东西)。

Macro Fusion功能
在进行解码的时候,会碰到Intel在Core 2开始加入的技术:Macro Fusion。关于Macro Fusion可以看这里《64位对决32位 SPEC CPU运算效能测试》,这项技术可以将一些比较并跳转的分支x86指令集合(CMP+TEST/JCC)最终解码为单条uop(CMP+JCC),从而提升了解码器的带宽、降低执行指令数量,让系统运行效率更高。和Core 2相比,Nehalem现在支持更多的比较/跳转分支情况,如JL/JNGE、JGE/JNL、JLE/JNG、JG/JNLE等,此外,Nehalem也开始更多地为服务器平台考虑,它的Macro Fusion开始支持64位模式,而不是Core 2的只支持32位模式。随着内存容量的日益增长,即使是在桌面平台及移动平台,64位用户也在不断增加,因此这个改进对用户很有吸引力。
除了将多条Macro Ops(就是x86指令)聚合之外,Nehalem也支持将多条uops聚合,也就是Micro Fusion功能,用于降低uop的数量。这是一个从Pentium M开始存在的老功能了,它在顺序上是在比Macro Fusion后面的后面,也就是在LSD循环流监测器后方。据说,Micro Fusion可以提升5%的整数性能和9%的浮点性能,而Macro Fusion则可以降低10%的uop数量。
The Core Front-End: Loop Stream Detector
处理器核心前端:循环流检测
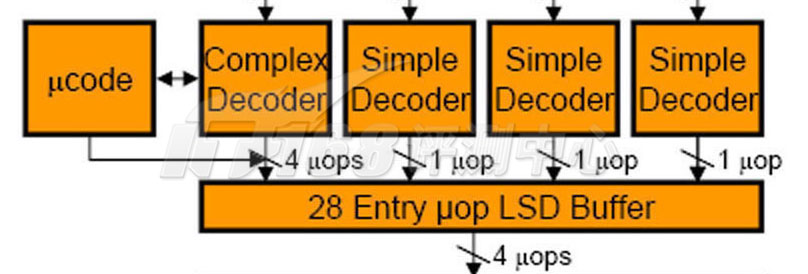
在解码为uop之后Nehalem会将它们都存放在一个叫做uop LSD Buffer的缓存区。在Core 2上,这个LSD Buffer是出现在解码器前方的,Nehalem将其移动到解码器后方,并相对加大了缓冲区的条目。Core 2的LSD缓冲区可以保存18个x86指令而Nehalem可以保存28个uop,从上一页可以知道,大部分x86指令都可以解码为一个uop,少部分可以解码为1~4个uop,因此Nehalem的LSD缓冲区基本上可以相当于保存21~23条x86指令,比Core 2要大上一些。
The Core Front-End: Loop Stream Detector
LSD循环流监测器也算包含在解码部分,它的作用是:假如程序使用的循环段(如for..do/do..while等)少于28个uops,那么Nehalem就可以将这个循环保存起来,不再需要重新通过取指单元、分支预测操作,以及解码器,Core 2的LSD放在解码器前方,因此无法省下解码的工作。
Nehalem LSD的工作比较像NetBurst架构的Trace Cache,其也是保存uops,作用也是部分地去掉一些严重的循环,不过由于Trace Cache还同时担当着类似于Core/Nehalem架构的Reorder Buffer乱序缓冲区的作用,容量比较大(可以保存12k uops,准确的大小是20KB),因此在cache miss的时候后果严重(特别是在SMT同步多线程之后,miss率加倍的情况下),LSD的小数目设计显然会好得多。不过笔者认为28个uop条目有些少,特别是考虑到SMT技术带来的两条线程都同时使用这个LSD的时候。
在LSD之后,Nehalem将会进行Micro-ops Fusion,这也是前端(The Front-End)的最后一个功能,在这些工作都做完之后,uops就可以准备进入执行引擎了。

