曙光Nehalem-EP服务器I620r-G深度评测
The Core Execution Engine: Out-of-Order Execution
处理器核心执行引擎:乱序执行
OOOE——Out-of-Order Execution乱序执行也是在Pentium Pro开始引入的,它有些类似于多线程的概念,这些在《机密揭露:Intel超线程技术有多少种?》里面可以看到相关的介绍。乱序执行是为了直接提升ILP(Instruction Level Parallelism)指令级并行化的设计,在多个执行单元的超标量设计当中,一系列的执行单元可以同时运行一些没有数据关联性的若干指令,只有需要等待其他指令运算结果的数据会按照顺序执行,从而总体提升了运行效率。乱序执行引擎是一个很重要的部分,需要进行复杂的调度管理。
然而乱序执行架构中,不同的指令可能都会需要用到相同的通用寄存器(GPR,General Purpose Registers),为了在这种情冲突的况下指令们也能并行工作,处理器需要准备解决方法。一般的RISC架构准备了大量的GPR,而x86架构天生就缺乏GPR(x86具有8个GPR,x86-64具有16个,一般RISC具有32个,IA64则具有128个),为此Intel开始引入重命名寄存器(Rename Register),不同的指令可以通过具有名字相同但实际不同的寄存器来解决,这有点像魔兽世界当中的副本设计,当然其出现要比WoW早多了。
此外,为了SMT同步多线程,这些寄存器还要准备双份,每个线程具有独立的一份。
The Core Execution Engine: Out-of-Order Execution
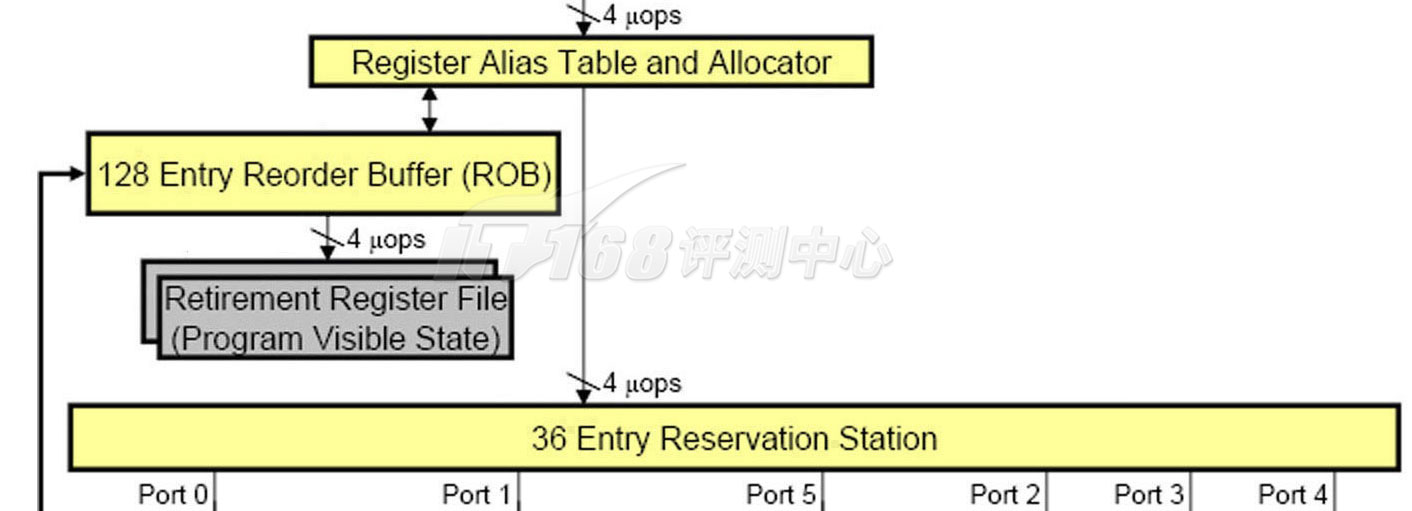
乱序执行从Allocator定位器开始,Allocator管理着RAT(Register Alias Table,寄存器别名表)、ROB(Re-Order Buffer,重排序缓冲区)和RRF(Retirement Register File,退回寄存器文件)。在Allocator之前,流水线都是顺序执行的,在Allocator之后,就可以进入乱序执行阶段了。在每一个线程方面,Nehalem和Core 2架构相似,RAT将重命名的、虚拟的寄存器(称为Architectural Register或Logical Register)指向ROB或者RRF。RAT是一式两份,每个线程独立,每个RAT包含了128个重命名寄存器(Pentium 4之前——Pentium Pro到Pentium III的重命名寄存器基于ROB,数量为40个;据说Pentium 4有128个)。RAT指向在ROB里面的最近的执行寄存器状态,或者指向RRF保存的最终的提交状态。
ROB(Re-Order Buffer,重排序缓冲区)是一个非常重要的部件,它是将乱序执行完毕的指令们按照程序编程的原始顺序重新排序的一个队列,打乱了次序的指令们依次插入这个队列,当一条指令通过RAT发往下一个阶段确实执行的时候这条指令(包括寄存器状态在内)将被加入ROB队列的一端,执行完毕的指令(包括寄存器状态)将从ROB队列的另一端移除(期间这些指令的数据可以被一些中间计算结果刷新),因为调度器是In-Order顺序的,这个队列也就是顺序的。从ROB中移出一条指令就意味着指令执行完毕了,这个阶段叫做Retire回退,相应地ROB往往也叫做Retirement Unit(回退单元),并将其画为流水线的最后一部分。
在一些超标量设计中,Retire阶段会将ROB的数据写入L1D缓存,而在另一些设计里,写入L1D缓存由另外的队列完成。例如,Core/Nehalem的这个操作就由MOB(Memory Order Buffer,内存重排序缓冲区)来完成。
ReOrder Buffer重排序缓冲区是一个Retire Queue回退队列,是OOOE乱序架构流水线的最后一段
ROB是乱序执行引擎架构中都存在的一个缓冲区,重新排序指令的目的是将指令们的寄存器状态依次提交到RRF退回寄存器文件当中,以确保具有因果关系的指令们在乱序执行中可以得到正确的数据。从执行单元返回的数据会将先前由调度器加入ROB的指令刷新数据部分并标志为结束(Finished),再经过其他检查通过后才能标志为完毕(Complete),一旦标志为完毕,它就可以提交数据并删除重命名项目并退出ROB了。提交状态的工作由Retirement Unit(回退单元)完成,它将确实完毕的指令包含的数据写入RRF(“确实”的意思是,非猜测执性、具备正确因果关系,程序可以见到的最终的寄存器状态)。和RAT一样,RRF也同时具有两个,每个线程独立。Core/Nehalem的Retirement Unit回退单元每时钟周期可以执行4个uops的寄存器文件写入,和RAT每时钟4个uops的重命名一致。
由于ROB里面保存的指令数目是如此之大(128条目),因此一些人认为它的作用是用来从中挑选出不相关的指令来进入执行单元,这多少是受到一些文档中的Out-of-Order Window乱序窗口这个词的影响(后面会看到对ROB会和MOB一起被计入乱序窗口资源中)。
ROB确实具有RS的一部分相似的作用,不过,ROB里面的指令是调度器通过RAT发往RS的同时发往ROB的,也就是说,在“乱序”之前,ROB的指令就已经确定了。指令并不是在ROB当中乱序挑选的(这在RS当中进行),ROB担当的是流水线的最终阶段:一个指令的Retire回退单元;以及担当中间计算结果的缓冲区。
RS(Reservation Station,中继站):等待源数据到来以进行OOOE乱序执行(没有数据的指令将在RS等待)
ROB(ReOrder Buffer,重排序缓冲区):等待结果到达以进行Retire指令回退(没有结果的指令将在ROB等待)

The Core Execution Engine: Out-of-Order Execution
Nehalem的128条目的ROB担当中间计算结果的缓冲区,它保存着猜测执行的指令及其数据(猜测执行也是在Pentium Pro开始引入的,Pentium Pro真是一个划时代的产品),猜测执行允许预先执行方向未定的分支指令,Nehalem的分支预测成功率没有被提及(只是含糊地说“业内最高”)。在大部分情况下,猜测执行工作良好——分支猜对了,因此其在ROB里产生的结果被标志为已结束,可以立即地被后继指令使用而不需要进行L1 Data Cache的Load操作(这也是ROB的另一个重要涌出,典型的x86应用中Load操作是如此频繁,达到了几乎占1/3的地步,因此ROB可以避免大量的Cache Load操作,作用巨大)。在剩下的不幸的情况下,分支未能按照如期的情况进行,这时猜测的分支指令段将被清除,相应指令们的流水线阶段清空,对应的寄存器状态也就全都无效了,这种无效的寄存器状态不会也不能出现在RRF里面。

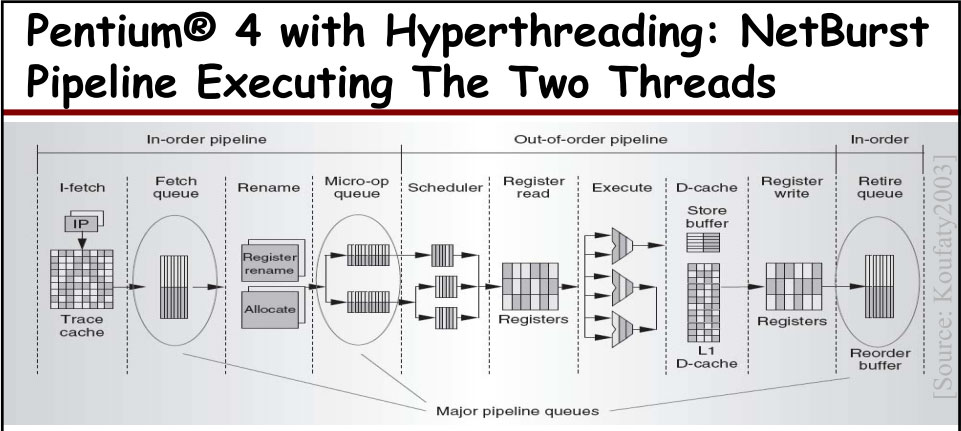
Pentium Pro架构,可见在后继型号在OOOE方面变化的基本只是一些数字变大了
重命名技术并不是没有代价的,在获得前面所说的众多的优点之后,它令指令在发射的时候需要扫描额外的地方来寻找到正确的寄存器状态,不过总体来说这种代价是非常值得的。RAT可以在每一个时钟周期重命名4个uops的寄存器,经过重命名的指令在读取到正确的操作数并发射到统一的RS(Reservation Station,中继站,Intel文档翻译为保留站点)上。RS中继站保存了所有等待执行的指令。
和Core 2相比,Nehalem的ROB大小和RS大小都得到了提升,ROB重排序缓冲区从96条目提升到128条目(鼻祖Pentium Pro具有40条),RS中继站从32提升到36(Pentium Pro为20),它们都在两个线程(超线程中的线程)内共享,不过采用了不同的策略:ROB是采用了静态的分区方法,而RS则采用了动态共享,因为有时候会有一条线程内的指令因等待数据而停滞,这时另一个线程就可以获得更多的RS资源。停滞的指令不会发往RS,但是仍然会占用ROB条目。由于ROB是静态分区,因此在开启HTT的情况下,每一个线程只能分到64条,不算多,在一些极少数的应用上,我们应该可以观察到一些应用开启HTT后会速度降低,尽管可能非常微小。

