Intel Nehalem-EP处理器首发深度评测
The Memory sub-System: Cache
内存子系统:缓存
与Core 2相比,Nehalem新增加了一层L3缓存,这是为了多个核心共享数据的需要(Nehalem-EX具有8个核心),也因此这个L3的容量很大。出于消除多核心共享数据的压力,前面的缓存不能让太多的缓存请求到达L3,而且L3的延迟(约30~40个时钟周期)和L1的延迟(3~4个时钟周期)相差太大,因此L2是很有必要的。Nehalem简单地在很小的L1和大尺寸的L3之间插入256KB的L2来起到中继的作用——中继具有两个方面的含义:容量和延迟。256KB不算大,可以维持约低于10个时钟周期的延迟。Nehalem的L2和L1不是包含也不是非包含的关系。
 |
通常缓存具有两种设计:非独占和独占,Nehalem处理器的L3采用了非独占高速缓存设计(或者说“包含式”,L3包含了L1/L2的内容),这种方式在Cache Miss的时候比独占式具有更好的性能,而在缓存命中的时候需要检查不同的核心的缓存一致性。Nehalem并采用了“内核有效”数据位的额外设计,降低了这种检查带来的性能影响。随着核心数目的逐渐增多(多线程的加入也会增加Cache Miss率),对缓存的压力也会继续增大,因此这种方式会比较符合未来的趋势。在后面可以看到,这种设计也是考虑到了多处理器协作的情况(此时Miss率会很容易地增加)。这可以看作是Nehalem与以往架构的基础不同:之前的架构都是来源于移动处理设计,而Nehalem则同时为企业、桌面和移动考虑而设计。
在L3缓存命中的时候(单处理器上是最通常的情况,多处理器下则不然),处理器检查内核有效位看看是否其他内核也有请求的缓存页面内容,决定是否需要对内核进行侦听:
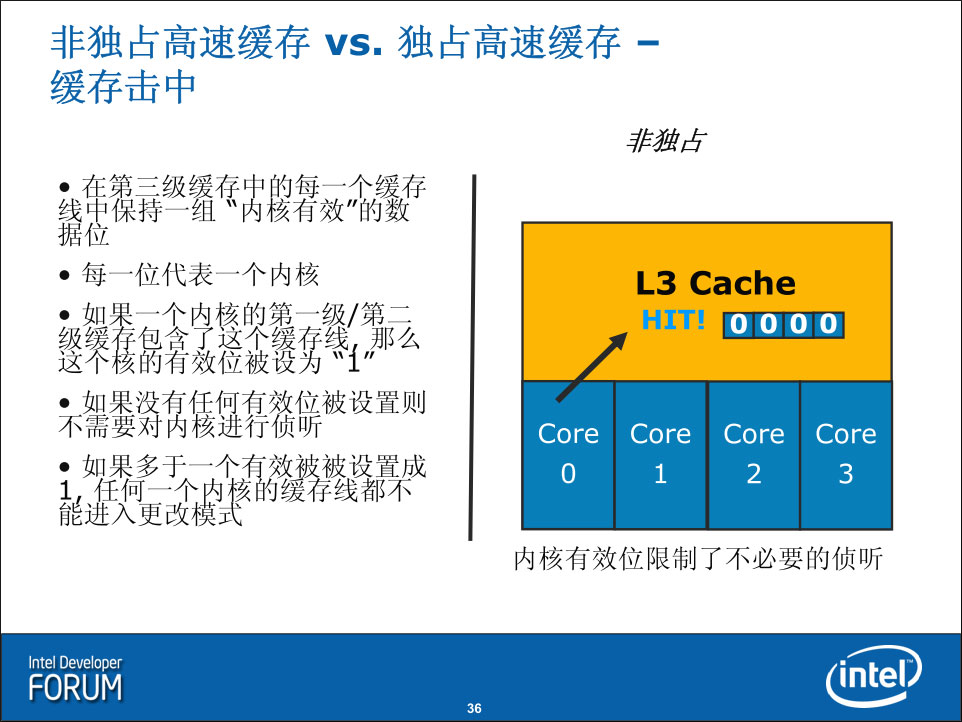
笔者相信这一点是不对的:假如一个L3页面被多个内核共享(多于一个有效被设置为1),那么这个处理器的该页面就不能进入Modified状态
基于后面的NUMA章节的内容,多个处理器中的同一个缓存页面必定在其中一个处理器中属于F状态(可以修改的状态),这个页面在这个处理器中没有理由不可以多核心共享(可以多核心共享就意味着这个能进入修改状态的页面的多个有效位被设置为一)。笔者相信MESIF协议应该是工作在核心(L1+L2)层面而不是处理器(L3)层面,这样统一处理器里多个核心共享的页面,只有其中一个是出于F状态(可以修改的状态)。见后面对NUMA和MESIF的解析。
在L3缓存未命中的时候(多处理器下会频繁发生),处理器决定进行内存存取,按照页面的物理位置,它分为近端内存存取(本地内存空间)和远端内存存取(地址在其他处理器的内存的空间):
|
Cache Miss时而页面地址为本地的时候,处理器进行近端内存访问
延迟取本地内存访问和远程CPU Cache Hit的延迟的最大值
|
Cache Miss时而页面地址为远程的时候,处理器进行远端内存访问
延迟取远程内存访问和远程CPU Cache Hit的延迟的最大值
|
近端访问约60个时钟周期,远端访问约90个时钟周期(据说仍然比Harptertown Xeon快),本地L3 Cache Hit则为30个时钟周期

