Intel Nehalem-EP处理器首发深度评测
The Uncore: IMC
核外系统:集成内存控制器
从形式上来看,L3缓存、集成的内存控制器乃至QPI总线都属于Uncore核外部分,从L2、L1一直到执行单元都属于Core核内部分。由于Nehalem首次采用了这种核心内外的相对独立设计思路,因此核心之外的设计相对于Core架构来说显得新颖许多,这就是Nehalem的模块式设计。
 |
模块式设计可以提供灵活的产品给用户,现在4核心、三通IMC和单QPI的桌面Nehalem已经面市,预计明年3月将会出现4核心、4通道IMC和双QPI的企业级Nehalem产品。包含了PCIE控制器乃至集成显卡的产品也已经在路线上了。
继续回到处理器架构:我们都知道,Nehalem和Intel以往处理器相比最大的特点就是直联架构——包括两个方面:处理器直联以及内存直联,前者就是依靠QPI总线的实现,后者则是由于处理器内置了内存控制器(IMC,Integrated Memory Controller)。当处理器在L3 Cache未找到所要内容(L3 Cache Miss)的时候,它将会继续通过IMC集成内存控制器往系统内存索取,同时通过QPI总线询问其他处理器(如果是多处理器平台)。
为什么直联架构可以很明显地提升性能?这要先从x86架构的存储体系说起。在很久很久以前,在一个记忆体短缺的时代——不仅仅处理器外面记忆体很少,处理器里面也是。使用了CISC架构的x86处理器里面只有8个GPR通用寄存器(一般的RISC处理器有32个以上的通用寄存器,现在的x86-64有16个通用寄存器),由于通用寄存器数量上的短缺,因此不像RISC处理器那样,CISC的x86处理器使用了堆叠运算指令。堆叠运算也就是将运算结果保存在源寄存器上的,如ADD AX, BX指令会将AX寄存器与BX寄存器的内容相加,并将结果保存到AX上——这样对比于使用三个寄存器做同一运算的非堆叠指令RISC架构就节约了一个寄存器,然而相应地源寄存器的内存就销毁了。x86架构需要执行大量的Load/Store微指令(Pentium Pro开始具备)来进行寄存器-寄存器或寄存器-内存之间的数据搬运操作。RISC处理器当中,Load/Store操作也很频繁。
如前面所述,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
mov、push、pop都是和load/store直接相关的,add、cmp等则间接相关
顺便:
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
单操作数指令占37%,双操作数指令占60%
双操作数指令中,直接数操作20%,寄存器操作数56%,绝对寻址操作数1%,间接寻址操作数23%
Load操作占据了x86 uops当中的约30%
大量的Load/Store操作已经通过ROB/MOB降低到一定程度,不过,在多核心/超线程的情况下,对缓存/内存子系统仍然具有很大的压力
现在来看这样的设计简直是无法想象,不过这样脑残的设计不仅仅用到了今天,而且还加速到了一个不可思议的境界……在与各种RISC架构处理器的交锋也不落下风……回到架构上,由于x86架构实际上是通过耗费寄存器带宽及缓存-内存带宽来节约处理器内部寄存器数量,大量的Load/Store操作(Load操作占据了x86 uops当中的约30%),对缓存乃至内存的性能非常依赖。
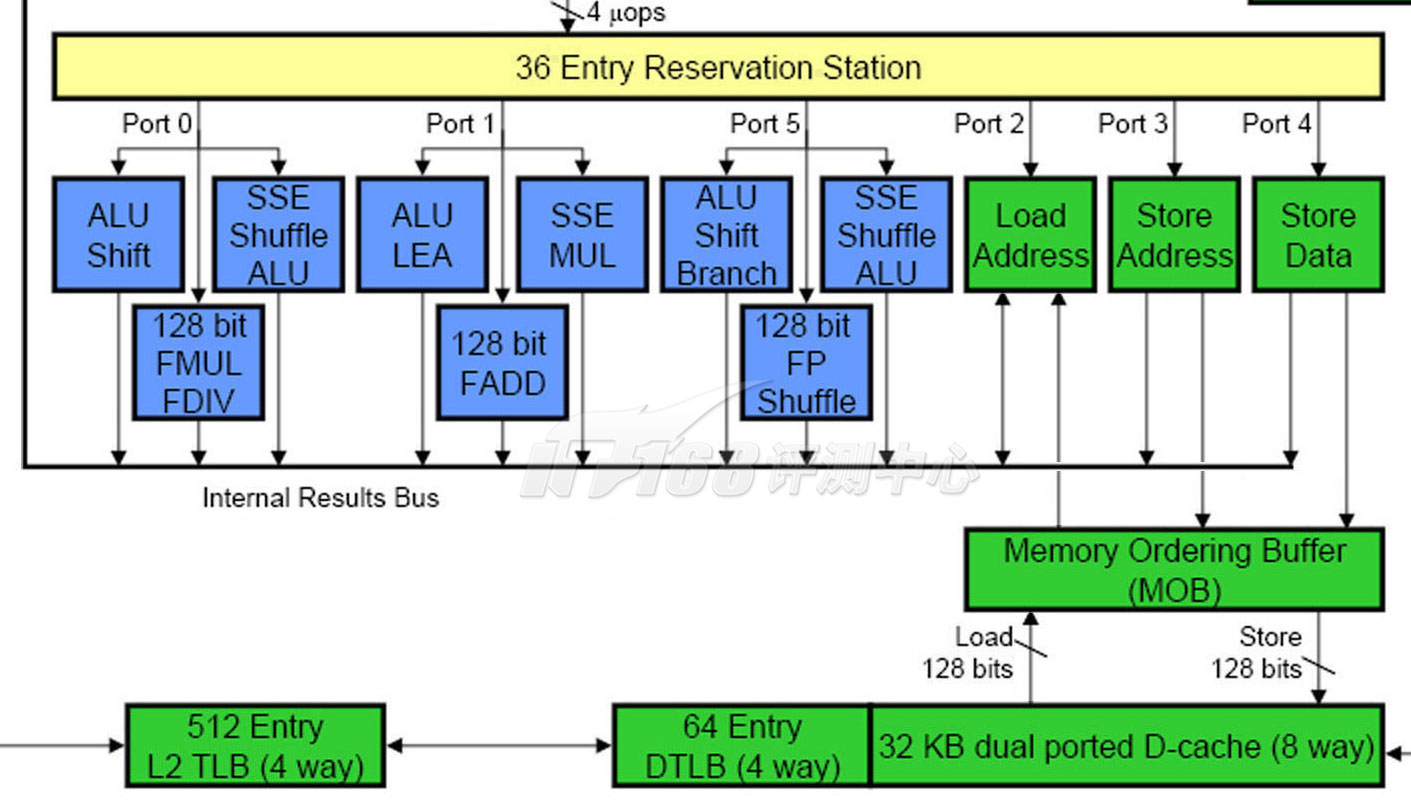
Nehalem具有三个Load/Store单元以及一个MOB架构,并支持内存数据相依性预测功能,缓存性能非常出色
缘此,x86架构在缓存-内存上的提升是不遗余力,不提2008年度评测报告:深入Nehalem微架构中说到的内存数据相依性预测功能(Memory Disambiguation),对于Nehalem而言,这方面最大的改进就是直联架构带来的IMC集成内存控制器,它使CPU到内存的路径更短,大幅度降低了内存的延迟,同时每一个CPU都具有自己专有的内存带宽。这一点在数据库应用中表现非常显著,数据库应用对存储器的延迟很敏感。

