Intel Nehalem-EP处理器首发深度评测
The Core Execution Engine: Load/Store Unit
处理器核心执行引擎:存取单元
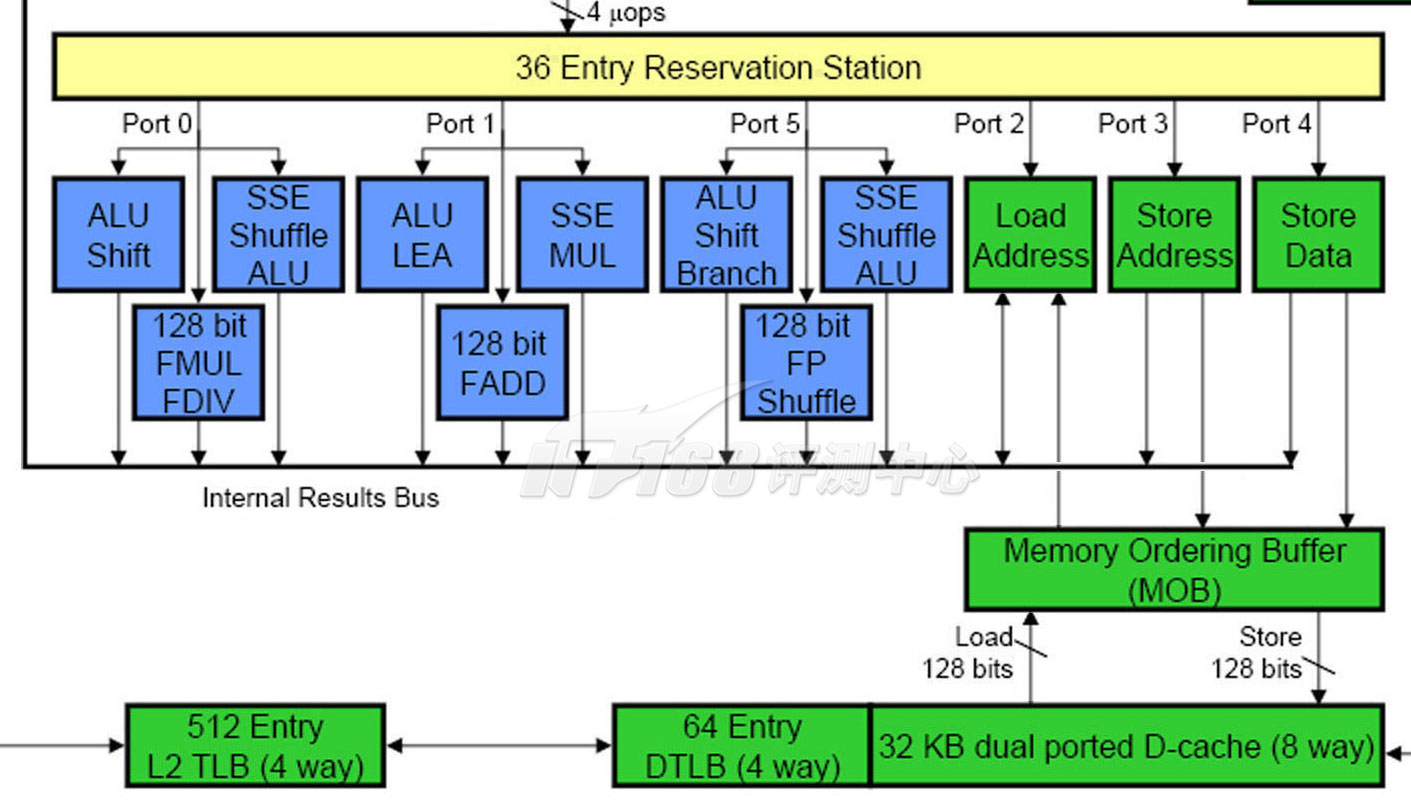
和为了顺序提交到寄存器而需要ROB重排序缓冲区的存在一样,在乱序架构中,多个打乱了顺序的Load操作和Store操作也需要按顺序提交到内存,MOB(Memory Reorder Buffer,内存重排序缓冲区)就是起到这样一个作用的重排序缓冲区(上图,介于Load/Store单元与L1D Cache之间的部件),所有的Load/Store操作都需要经过MOB,MOB通过一个128bit位宽的Load通道与一个128bit位宽的Store通道与双口L1D Cache通信。和ROB一样,MOB的内容按照Load/Store指令分发(Dispatched)的顺序加入队列的一端,按照提交到L1D Cache的顺序从队列的另一端移除。ROB和MOB一起实际上形成了一个分布式的Order Buffer结构,有些处理器上只存在ROB,兼备了MOB的功能。
和ROB一样,Load/Store单元的乱序存取操作会在MOB中按照原始程序顺序排列,以提供正确的数据,内存数据依赖性检测功能也在里面实现。Intel没有给出MOB详细的结构——包括外部拓扑结构在内,在一些玩家制作的架构图当中,MOB被放在Load/Store单元与Internal Results Bus之间并互相联结起来,意思是MOB的Load/Store操作结果也会直接反映到ROB当中。
The Core Execution Engine: Load/Store Unit
然而基于以下的一个事实,笔者将其与Internal Results Bus进行了隔离:MOB还附带了数据预取(Data Prefetch)功能,它会猜测未来指令会使用到的数据,并预先从L1D Cache缓存Load入MOB中(Data Prefetcher也会对L2至系统内存的数据进行这样的操作),这样MOB当中的数据有些在ROB中是不存在的(这有些像ROB当中的Speculative Execution猜测执行,MOB当中也存在着“Speculative Load Execution猜测载入”,只不过失败的猜测执行会导致管线停顿,而失败的猜测载入仅仅会影响到性能)。此外,MOB与L1D之间是数据总线,不带有指令,经过MOB内部的乱序执行之后,ROB并不知道进出的数据对应哪一条指令。最终笔者制作的架构图就如上方所示。

每个Core 2内核具有3个Prefetcher(1个指令,两个数据);每两个核心共享两个L2 Prefetcher

Nehalem的Hardware Prefetcher功能,其中L1 Prefetchers基于指令历史以及载入地址参数
数据预取功能和指令预取功能一起,统称为Hardware Prefetcher硬件预取器。笔者在年少时对BIOS里面通常放在CPU特性那一页里面的Hardware Prefetcher迷惑不解(通常在一起的还有一个Adjacent Cache Line Prefetch相邻缓存行预取,据说这些选项不包含L1 Prefetcher;亦尚不清楚是否包括MOB的预取功能),现在我们知道了这两个功能就是和这一页的内容相关的。很不幸,在以往的CPU中,失败的预取将会白白浪费掉L1/L2/L3/Memory的带宽,而在服务器应用上通常会进行跨度很大的Load操作,因此Hardware Prefetcher经常会起到降低性能的作用。对于这种情况,处理器厂商们除了在BIOS里面给出一个设置选项就没有更好的方法了(这些选项在桌面应用上工作良好)。糟糕的是,很多用户都不知道这些选项是干什么用的。据说Nehalem上这个情况得到了好转,用户可以简单地设置为Enable而不用担心性能下降。或许以后我们IT168评测中心会进行相关的测试检验是否是这样,不过我们可以想象,内存带宽得到巨大提升的Nehalem已经具有足够的资本来开启这些选项了。
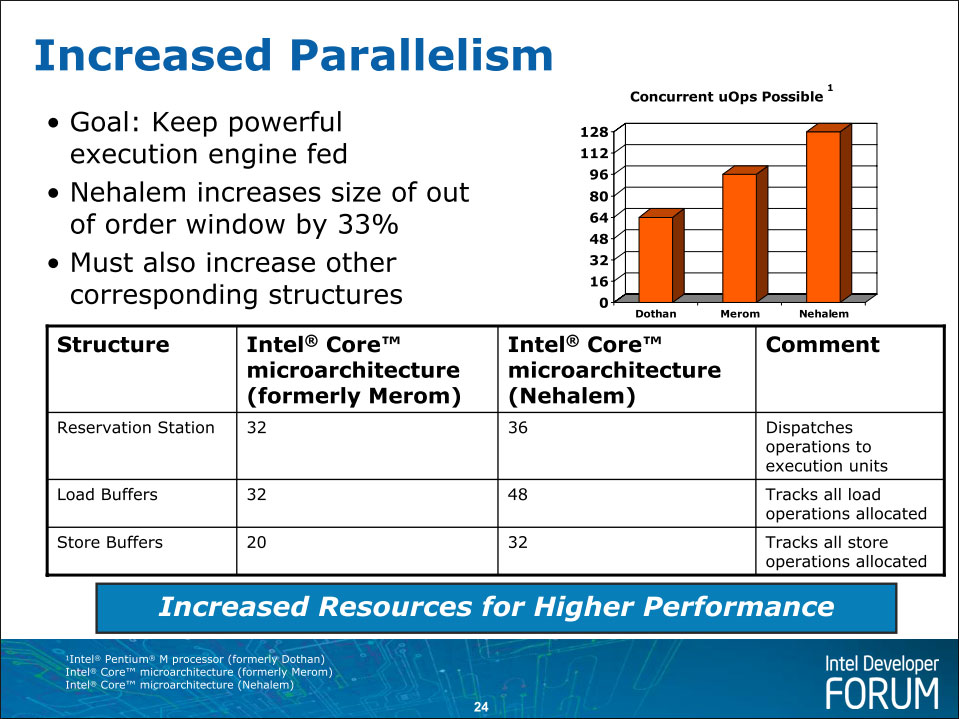
提高并行度:扩大RS和MOB的容量(MOB包括了Load Buffers和Store Buffers),所谓的乱序窗口资源
乱序执行中我们可以看到很多缓冲区性质的东西:RAT寄存器别名表、ROB重排序缓冲区、RS中继站、MOB内存重排序缓冲区(包括LB载入缓冲和SB存储缓冲)。在超线程的作用下,RAT是一式两份,包含了128个重命名寄存器;128条目的ROB、48条目的LB和32条目的SB都静态划分为两个分区:每个线程64个ROB、24个LB和16个SB;RS则是在两个线程中动态共享。可见,虽然整体数量增加了,然而就单个线程而言,获得的资源并没有提升。这会影响到HTT下单线程下的性能。

