哈啰算法实时化2.0建设实践
流式预测建设
为什么要建设流式预测
其中一个主要原因是新的决策调用场景的接入,原有的决策调用场景主要是通过RPC接口调用触发的,而流式预测承接的场景主要由kafka等消息中间件来调用,这些场景都存在调用量大的特点,单个场景有上千、万QPS调用。流式预测也存在一些定时触发调用的场景,如供需预测场景,波峰波谷明显。流式预测可以将峰值QPS打平,保证实时性的前提下降低机器成本。二是机器成本,决策服务目前机器资源成本较大。三是接入配置繁琐,非流式预测接入方式需新建服务,通过代码开发方式接入,每次迭代都需进行排期上线的方式进行,较为繁琐。
流式预测建设的难点
流式预测建设主要有三部分难点,一是如何进行预测,流式预测场景数据源多为消息中间件,需要进行预测的量较大,采用现有决策服务调用所需要的成本较高。二是如何进行特征查询,模型所需的特征查询也存在查询量大的情况,且存储至HBase查询耗时较高,需要开启多并发进行查询。三是稳定性建设,包括预测任务数据延迟监控、任务失败数据重新消费、调用情况监控等能力的建设。
Flink本地调用决策
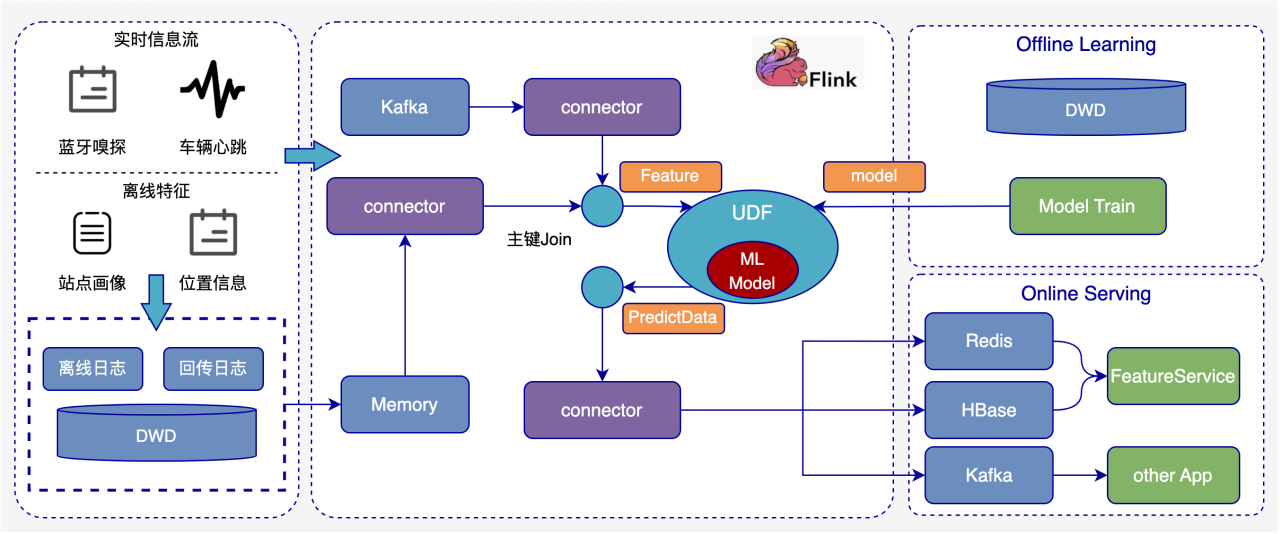
我们通过Flink接入决策SDK方式接入消息中间件数据,所有模型调用、规则调用都通过本地进行,脱离决策服务,只有元数据的加载、模型更新等存在依赖。关于Flink如何接入决策SDK, 我们通过Flink的UDF自定义算子的方式将决策SDK包装成一个通用的算子形式,再由Flink进行调用。
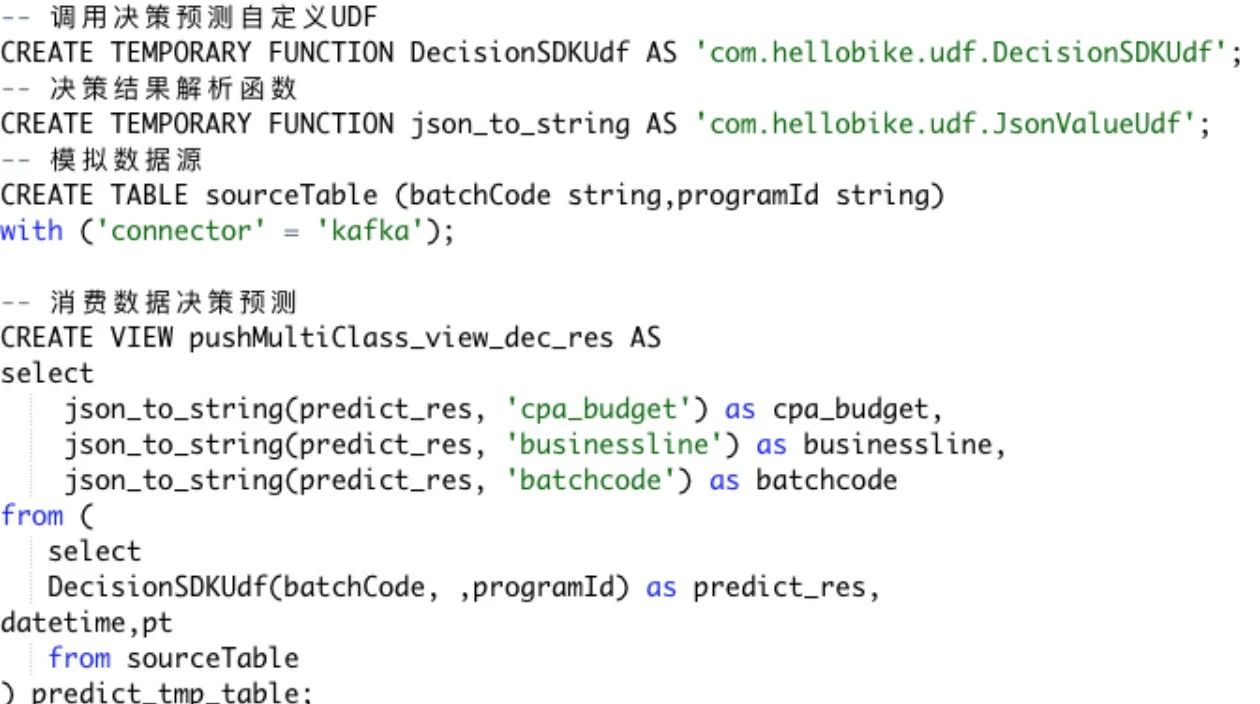
我们在实际场景接入中发现,Flink本地调用决策自定义算子的时候,相同的资源能够承受的QPS非常低,分析Fllink ui对应各个节点的执行代码,发现决策SDK存在重复调用的情况。
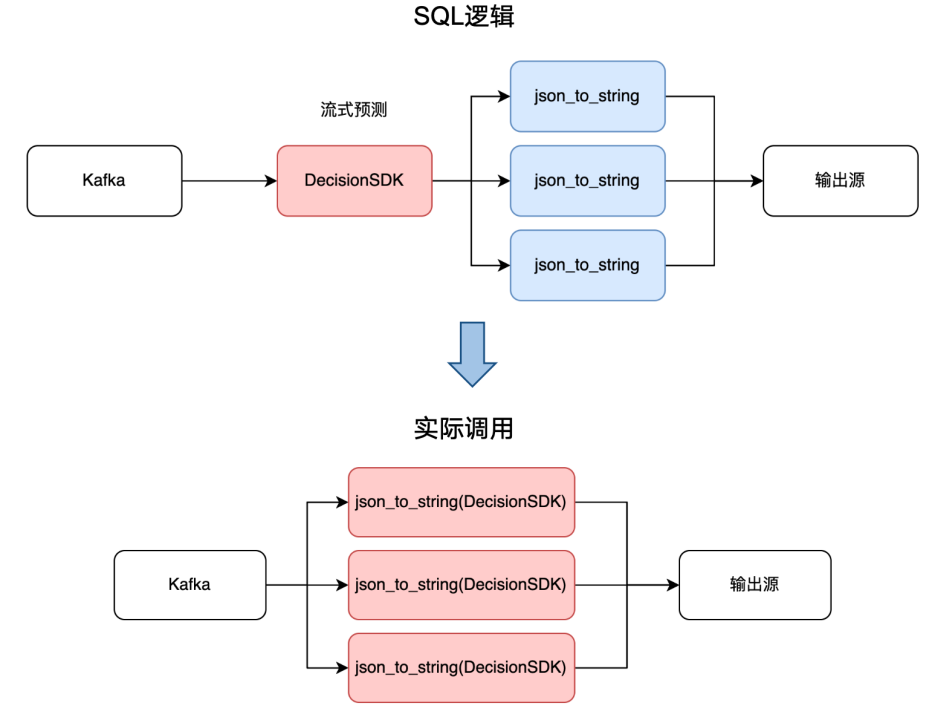
SQL逻辑可简化为上图,Kafka把数据发到决策SDK,通过json_to_string方式进行解析,给到输出源。实际上Flink在运行SQL时,会把SQL进行代码解析,生成AST语法树,最终实际调用不会复用决策SDK输出的结果。
我们查阅了具体的解决方案,一是修改底层Flink生成执行代码逻辑,判断用户udf是否可复用,生成可复用逻辑代码。这种方式部署时会影响其他任务,因此我们采用了第二种方案,添加一层透传专用的UDTF,牺牲少量的性能,解决重复调用问题。
特征本地查询
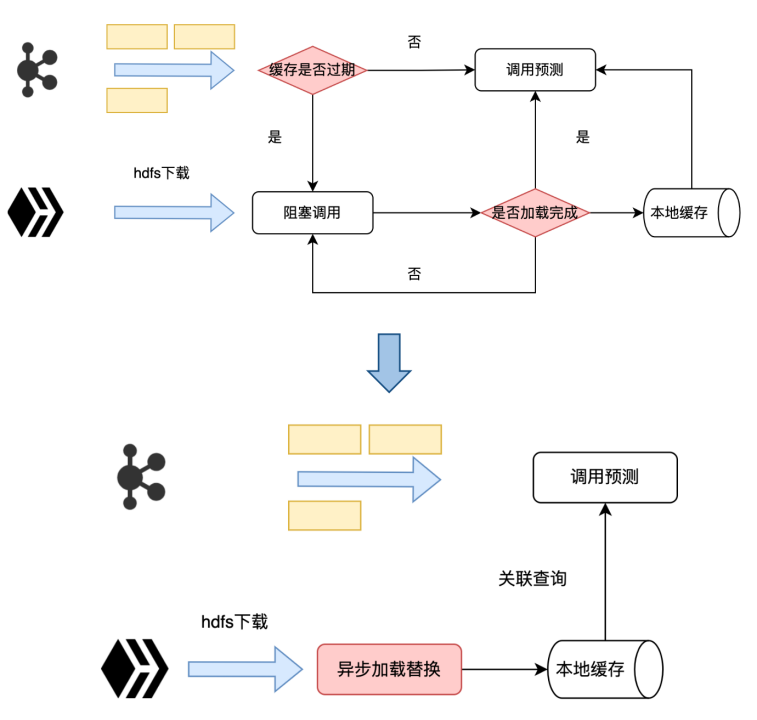
除了kafka消息中间件实时特征外,决策调用还需要离线的特征,这部分特征我们采用hive connector的方式缓存到本地内存中提供查询。这种方式存在一定问题,它的调用方式是全量拉取hive表数据,固定时间间隔更新,同步方式更新数据,会影响流式预测的实时性。因此我们对Flink自带的hive connector进行了修改,按照PT进行hive数据拉取,根据上游依赖方式进行数据更新,异步方式更新数据,保证预测的实时性。
我们还对底层存储类型进行了调整,原有的存储类型是全量缓存,flink为了支持大qps场景,会起多个subtask消费上游的kafka数据,每个subtask都会全量加载对应hive的数据,导致数据重复加载,内存占用非常高。我们采用Partitioned 方式做缓存优化,针对超大维表,按照Join Key进行Shuffle,每个进程上加载所需的维表数据,上游数据传输也需要按照对应方式传递。
我们也对存储格式进行了优化,原有Flink存储数据为自带RowData方式进行存储,改为通过byte数组方式进行存储,优化后相同10w条数据存储所需内存约之前三分之一。
稳定性建设
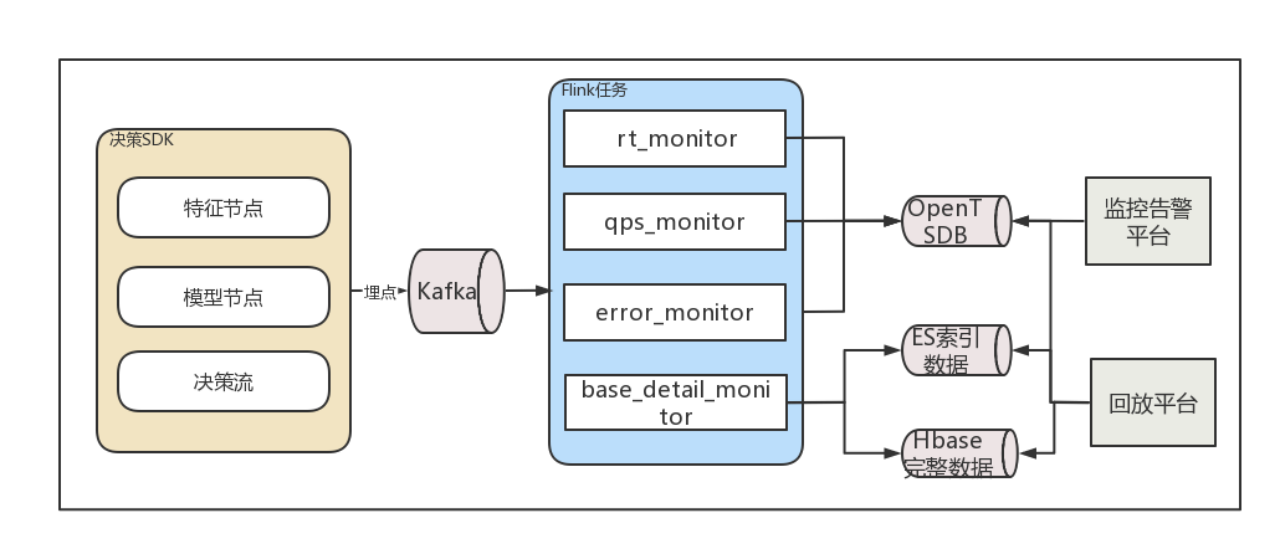
复用一站式AI平台现有的监控体系,把所有的请求通过埋点的方式写入到OpenTSDB和ES,OpenTSDB去监控调用情况和异常情况,提供给监控告警平台做监控告警。ES提供回放能力,出现异常时可以在决策日志查看里看到各节点的出入参情况。
实时特征模版化建设
为什么要进行实时特征模版化
主要有三个原因,一是实时特征统计逻辑相类似统计,我们统计已上线的实时特征发现,能够用模板化的方式进行配置的占到所有场景的76%,模版化方式能够降低用户学习配置成本,提高上线效率。二是节省工程同学人力,用户根据模板分类接入,减少咨询耗时,同时添加自动压测逻辑,减轻工程同学后续维护成本。三是底层逻辑优化,针对不同模板底层自动修改最终sql,优化Flink计算逻辑。
实时特征配置流程优化

原有的流程,用户需要做数据源定义、实时特征开发、存储源定义、特征上线,其中主要的耗时在实时特征开发。
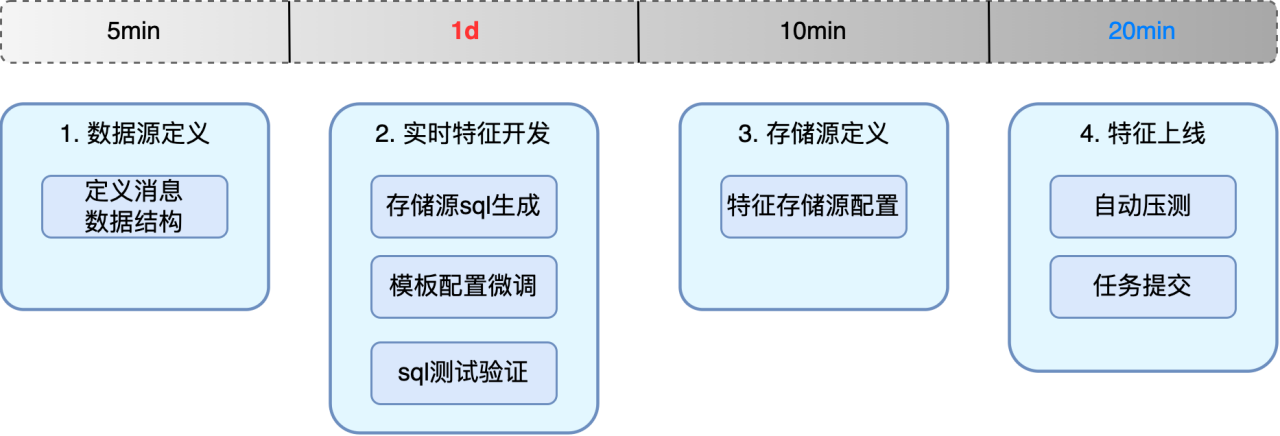
优化后sql编写通过模板配置方式完成,减轻用户配置工作,压测动作通过自动化方式完成,减少工程同学运维动作。
实时特征模板化的底层优化

以统计商品当天曝光次数为例,我们通过设置sql模版,添加提前触发参数,将原有的每来一次数据聚合写入的逻辑调整为按照时间间隔定时统计写入,减轻底层数据库写入压力。

二是流式聚合优化,以统计当天唯一用户登录数为例,进行count distinct往往存在数据倾斜,热点的问题,即使添加资源,调整并发也无法缓解从而造成数据消费积压。通过对这些场景模板化设定,采用拆分distinct聚合来消除数据倾斜的问题,减少资源浪费。
接入场景介绍

这里以供需预测场景为例,原有的供需预测采用离线预测T+1站点未来24小时的预测值提供给调度引擎进行调度任务生成,由于站点的流入流出变动较大,常常出现负收益的调度任务,所以希望通过在线预测的方式来对站点净流出数进行预测更新。

