近年来随着大数据时代的到来和计算能力的提升,人工智能在各个领域都取得了显著的进展。原先在云端进行特征的存储与处理、模型的训练、在线推理,在客户端进行数据的展示的架构展现出越来越多的缺点和局限性。本文将结合端智能的优势,结合哈啰一站式AI平台的现状,讲述一站式AI平台如何支持多端智能(服务端、flink端、移动端)。
云端推理模式
具体流程
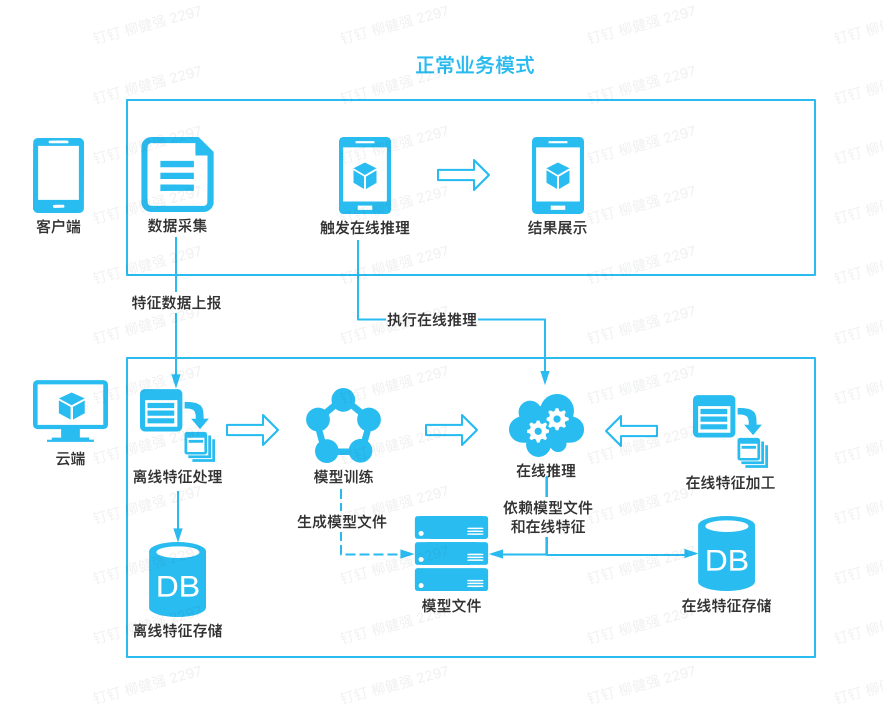
图1-1 云端推理模式流程图
首先云端会将客户端上报的的离线特征和在线特征数据进行存储
云端将离线特征数据喂给模型进行模型训练
模型在云端训练完毕后进行模型上线或者模型更新
客户端触发在线推理请求调用云端进行在线预测
云端在线推理结合特征数据和模型文件进行预测
云端返回排序结果和数据在客户端展示
问题
带宽和延迟问题:所有客户端用户的请求都要先到云端进行推理后,才能在客户端进行展示,网络传输存在一定耗时;若推理所需特征较大(如图片,视频等),会导致延迟很高,以及网络带宽压力非常大
数据安全:用户的数据都需要通过网络传输上传到云端,存在泄漏风险
数据隐私:部分数据为用户隐私数据,无法存储在云端
成本问题:所有的在线推理都在云端,则云端需要部署大量服务器提供在线推理能力,成本巨大
中心化问题:所有的在线推理都需要走云端接口,若网络异常或者云端服务异常,则会导致推理能力失效
端智能模式
端智能技术是指将计算、存储和推理从中心化的云端转移到网络边缘设备(如智能手机、物联网设备等)的技术。
具体流程
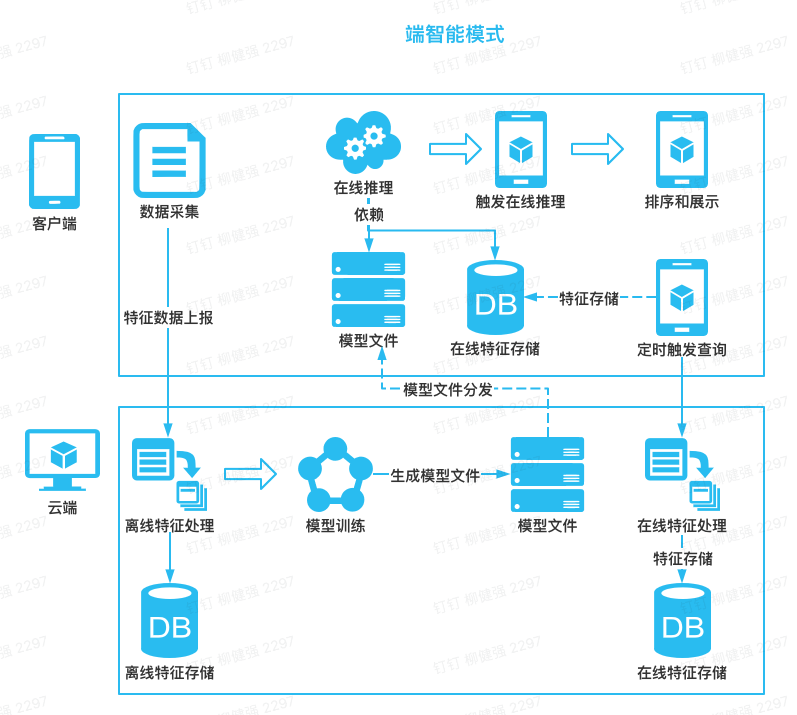
图1-2 端智能推理模式流程图
首先云端会将客户端上报的的离线特征和在线特征数据进行存储
云端将原有的离线特征数据和新上报的离线特征数据喂给模型进行模型训练
模型在云端训练完毕后的模型进行模型上线或者模型更新
客户端定时触发模型版本更新,云端识别到客户端模板版本过旧会告诉客户端需要更新模型
客户端定时触发云端特征查询,会将云端查询的数据和历史数据存储起来
客户端结合特征数据和模型文件进行在线推理
客户端进行排序和结果展示
端智能优势
客户端的在线推理依赖的特征和模型都在本地运行,无网络带宽和延迟问题
数据本地化存储,无数据安全和隐私问题
在线推理本地化,云端故障或者网络故障不会导致无法在线推理
在线推理本地化,云端无需提供服务,可降低成本
哈啰一站式AI平台当前现状
整体架构
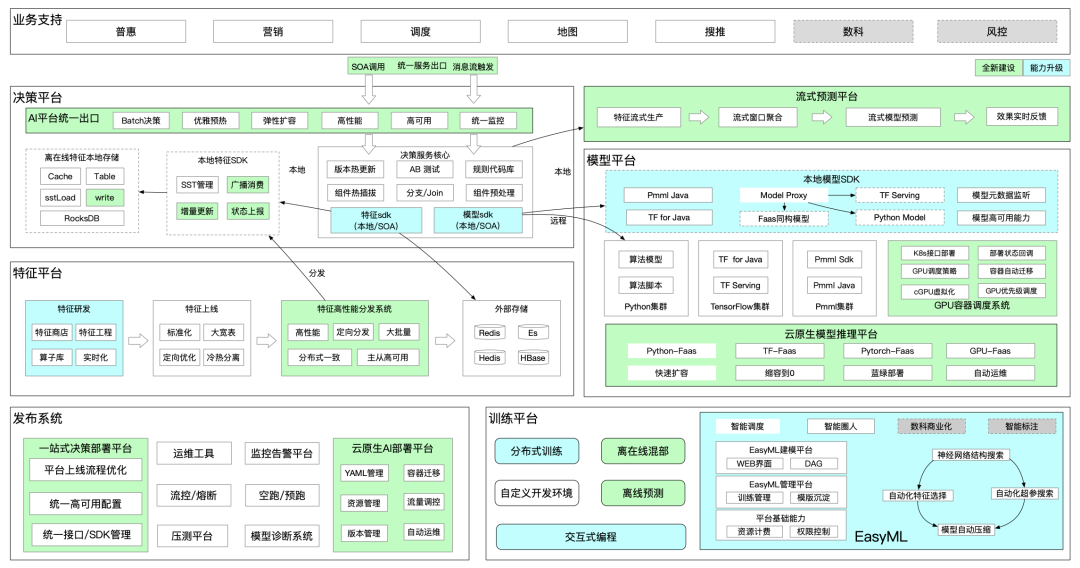
图2-1 一站式AI平台架构图
一站式AI平台从划分来说划分为训练平台、模型平台、特征平台、决策平台
训练平台
提供离在线模型的训练、模型开发环境资源管控、模型训练资源管控、离线模型推理、离线模型管理、分布式训练、分布式预测
模型平台
提供tf1/tf2、pmml、python、python-gpu四类在线模型的模型管理、模型资源管控、在线推理能力
特征平台
提供离在线特征存储、实时特征计算、特征关联、特征加工、特征选择、特征清洗、特征查询等能力
决策平台
基于DAG流程编排能力,提供了串联groovy脚本、多模型,多特征的流程编排,统一对外提供在线推理能力
整体流程
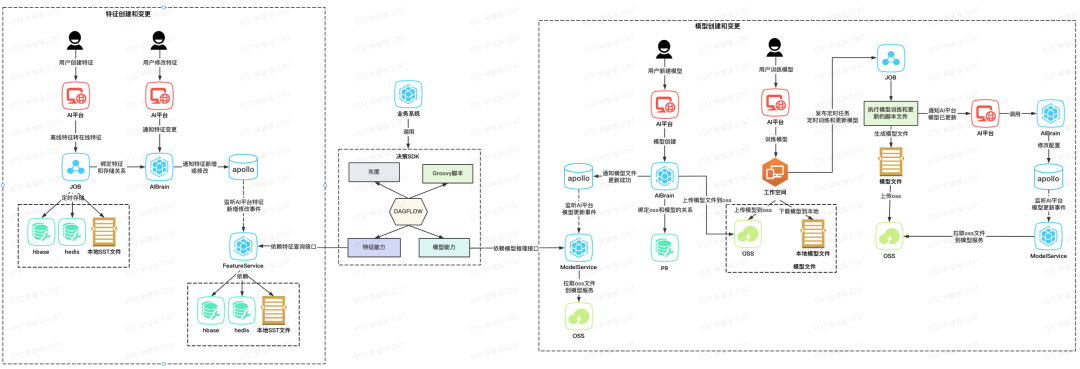
图2-2 AI平台简易流程图
如图2-2所示,表示了简易的一站式AI平台的流程图。
1. 特征创建和变更
在线特征存储:用户在AI平台先创建特征,将离线特征转为在线特征存储起来
在线特征新增和变更:特征和特征存储的关系会通过AI平台的配置变更,同步给在线特征服务FeatureService
2. 模型训练和创建,以及模型版本管理
模型训练:用户在AI平台通过远端任务触发模型的训练,训练完成后产生模型文件,生成本地文件或者上传到oss
新增模型:用户在AI平台通过新增模型模块将本地模型文件或者oss模型文件和模型绑定
模型变更:用户可通过离线训练方式手动在AI平台更新模型,也可以通过定时任务训练模型后触发自动模型更新
3. 在线推理
用户在决策平台先绑定模型和特征的关系以及groovy规则的关系,生成决策
业务服务调用决策服务,经过groovy规则、灰度、特征查询、特征预处理后传给模型进行在线推理
决策服务将推理结果返回给业务系统
移动端智能
整体流程
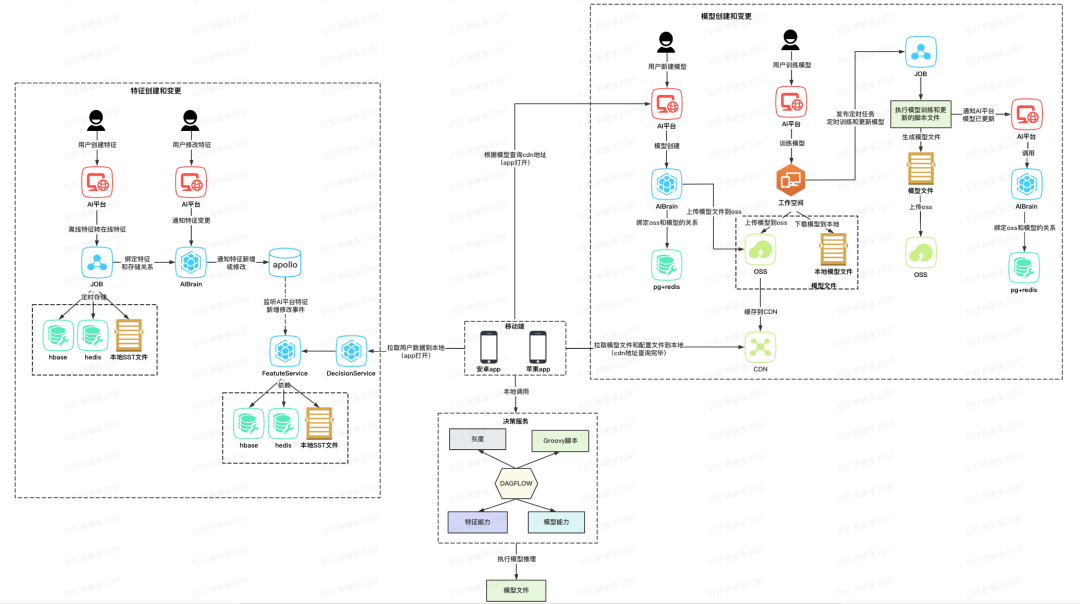
图3-1 AI平台移动端智能方案简易流程图
如图3-1所示,表示了移动端智能方案简易流程图,和2-1对比差异点如下。
1. 模型模块
模型版本管理:原先模型版本管理是在一站式AI平台完成,业务调用方只需要给出决策id就能知道可运行的模型,而端智能后,前端需要配合进行模型管理
模型文件分发:原先模型文件产生后,会将模型文件分发到云端的模型服务ModelService,端智能后需要将模型文件分发到每个用户的移动端
模型运行环境:原先模型的运行环境是在ModelService集成的,现在模型在线推理在移动端,需要在移动端支持模型的运行环境
2. 特征模块
特征的存储原先只在云端,端智能后端上会存储数据
在线推理不再依赖云端数据,而是依赖本地特征数据(端智能后移动端会定时拉取云端特征到本地)
3. 决策模块
原先决策是作为服务给业务方调用,端智能后需要打成sdk包给移动端调用
决策服务原先只给后端服务调用,端智能后需要支持移动端请求访问
挑战和方案
1. 端上版本更新挑战
在端上运行模型会依赖特征数据、特征预处理逻辑、模型文件、groovy规则,依赖库会有依赖关系,如果部分是实时分发更新,部分是依赖移动端发版,则可能会导致不一致,且依赖移动版发版时间。
方案
将可以动态发布的模型文件、特征预处理文件,groovy规则,依赖库打包成一个算法包,支持动态更新和统一版本管理
2. 模型文件分发挑战
从ModelService转为移动端,数量大大增加。ModelService为云端系统pod数,基本是几百,移动端是用户收集app,则会在千万级别。
方案
云端通过用户手动或者自动训练完模型后更新的oss,用户打开App后定时check算法包是否存在更新,若存在更新,则从用户最近的CDN节点拉取算法包到app
3. 包大小挑战
由于端上资源有限,因此对新增的决策sdk包和模型文件大小以及计算资源会有一定限制。
方案
决策:对决策做最大化的瘦身,只保留一站式决策可运行的最小版本能力(如:groovy规则、特征预处理)
模型:控制模型的参数量级、拆分部署;基于MNN框架对模型进行压缩
4. 适配挑战
移动端由于每个用户的设备都不一样,会有不同的适配成本。
方案
目前一期仅支持在基于MNN在安卓设备进行,IOS兼容方案仍在探索中
5. 模型运行挑战
模型文件需要在端上运行,端侧得支持可运行模型文件的环境。
方案
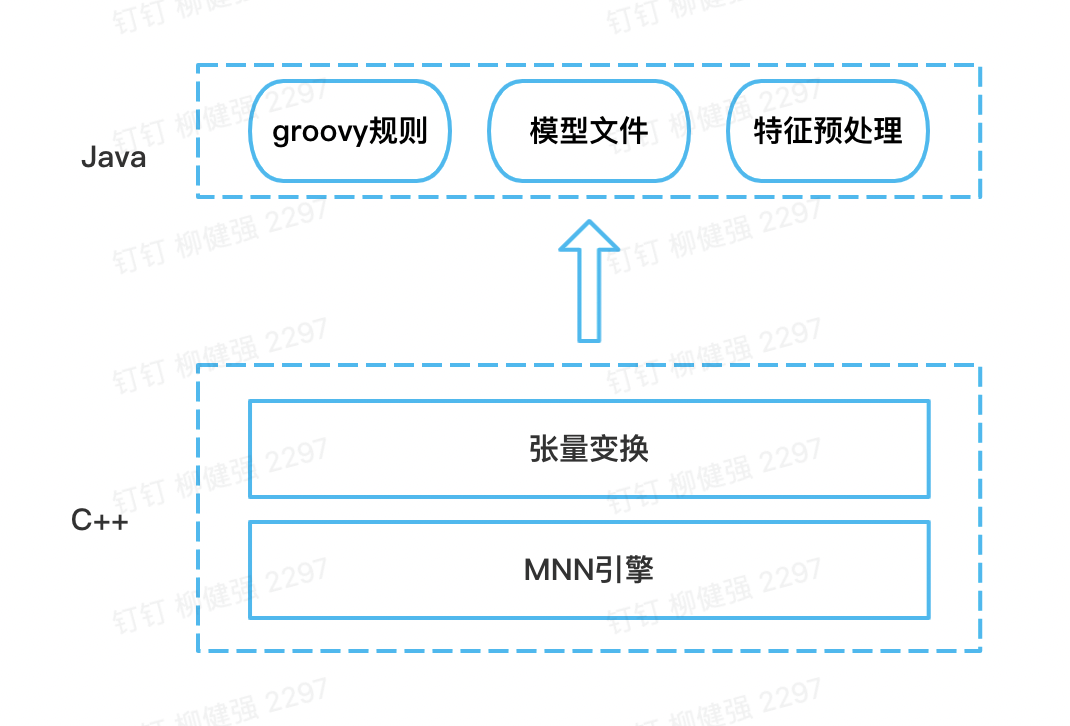
图3-4 基于MNN的运行结构图
基于淘宝MNN开源引擎,在端侧适配模型可运行的环境
flink端智能
整体流程
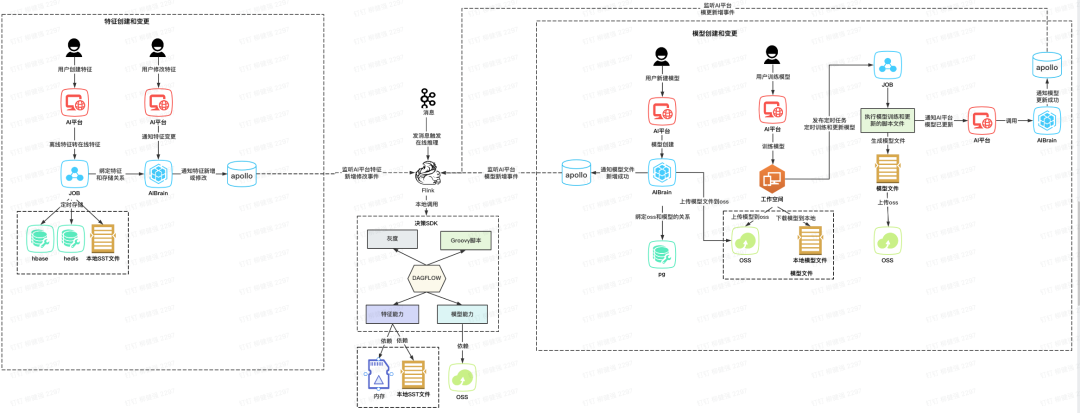
图4-1 AI平台flink端智能方案简易流程图
如图4-1所示,表示了flink端智能方案简易流程图,和2-1对比差异点如下。
1. 触发逻辑
原先云端的模型触发都是基于soa接口方式触发,改为flink端后,在线推理都是基于消息触发
2. 模型模块
模型运行环境:原先模型的运行环境是在ModelService集成的,现在模型在线推理在flink,需要在flink端支持模型的运行
模型更新交互变化:原先模型的加载都是ModelService中监听模型新增或者修改,现在模型的新增和更新需要在flink端监听apollo配置变化,在flink端替换新模型
3. 特征模块
特征存储介质变化:特征的存储原先只在云端的在线存储中,flink端智能后需要将特征存在在本地磁盘或者内存中
特征更新交互变化:原先特征的新增或者修改都是在FeatureService监听特征的变化,将特征和存储的关系维护在特征服务中,现在需要在flink端监听特征变化,且需要将特征直接拉取到flink本地磁盘或者内存中
4. 决策模块
原先决策是作为服务给业务方调用,端智能后需要打成sdk包给flink端调用
挑战和方案
1. 模型调用本地化
模型调用由SOA方式改为本地调用。
方案
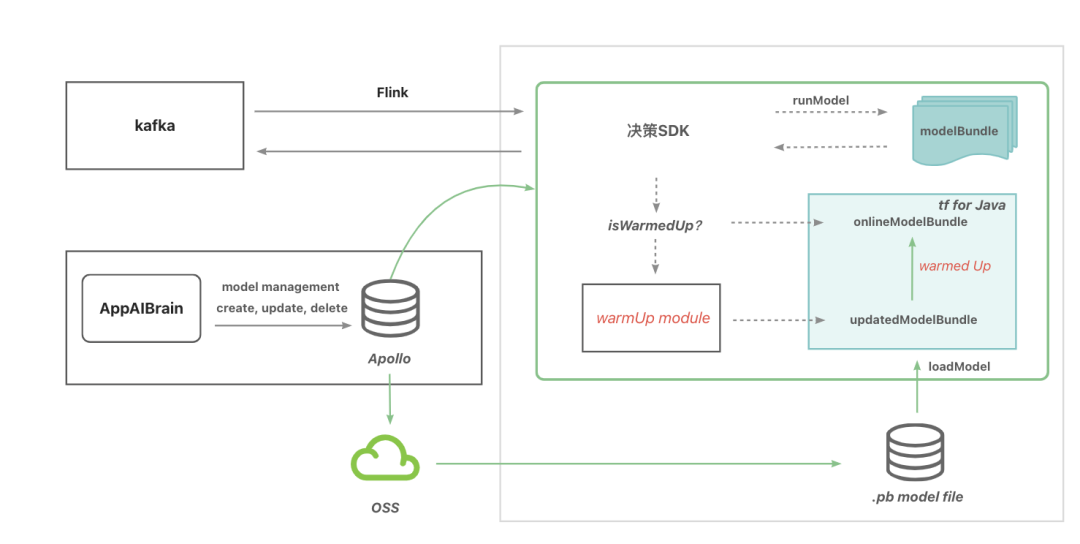
图4-2 模型调用本地化
flink会接入决策SDK,并通过tf for java将模型加载到本地,提供模型在线推理能力。模型更新后由AI管理平台更新apollo配置信息,flink端通过监听apollo方式进行模型更新。
2. 特征本地化
通过将在线数据预加载到内存或者本地磁盘,进行特征的加工处理和本地调用。
RocksDB方案
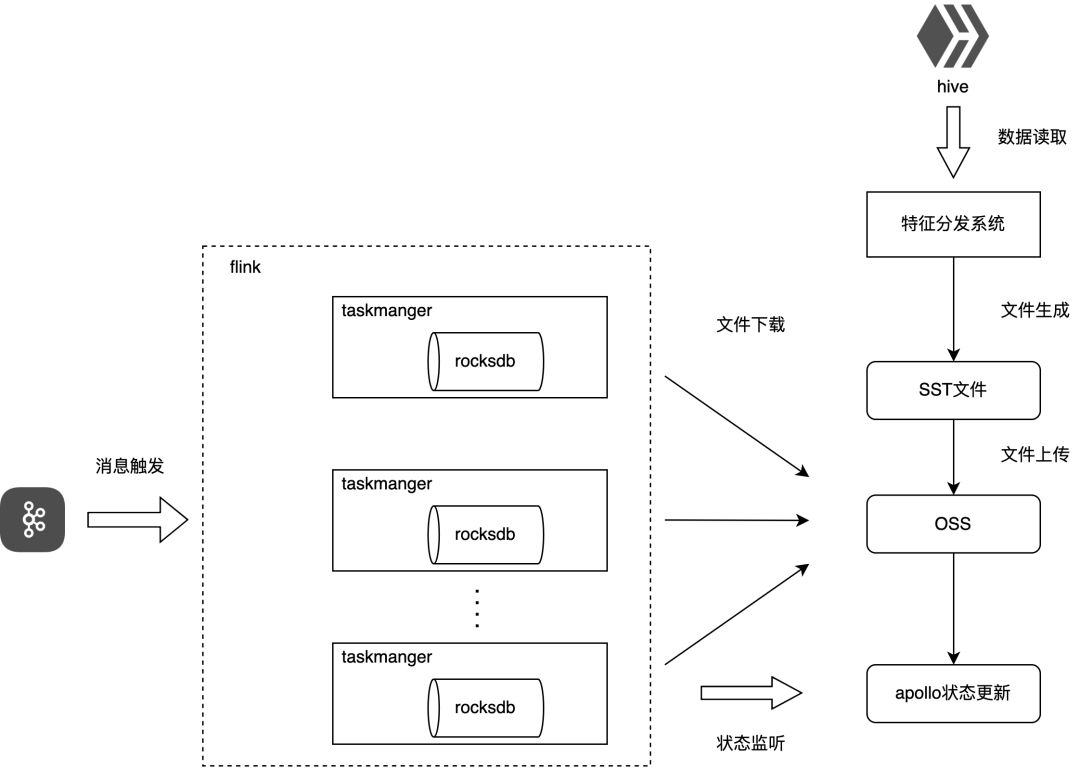
图4-3 RocksDB方案
a. 特征变更
特征分发系统会监听hive表特征变更,在特征分发系统将特征数据转成SST文件
特征分发系统会将SST文件上传到oss,并将配置变更通知apollo配置中心
flink端监听apollo配置变更,将sst文件拉到本地磁盘
b. 特征查询
flink端执行在线推理会从RocksDB查询本地磁盘的数据
内存存储的方案
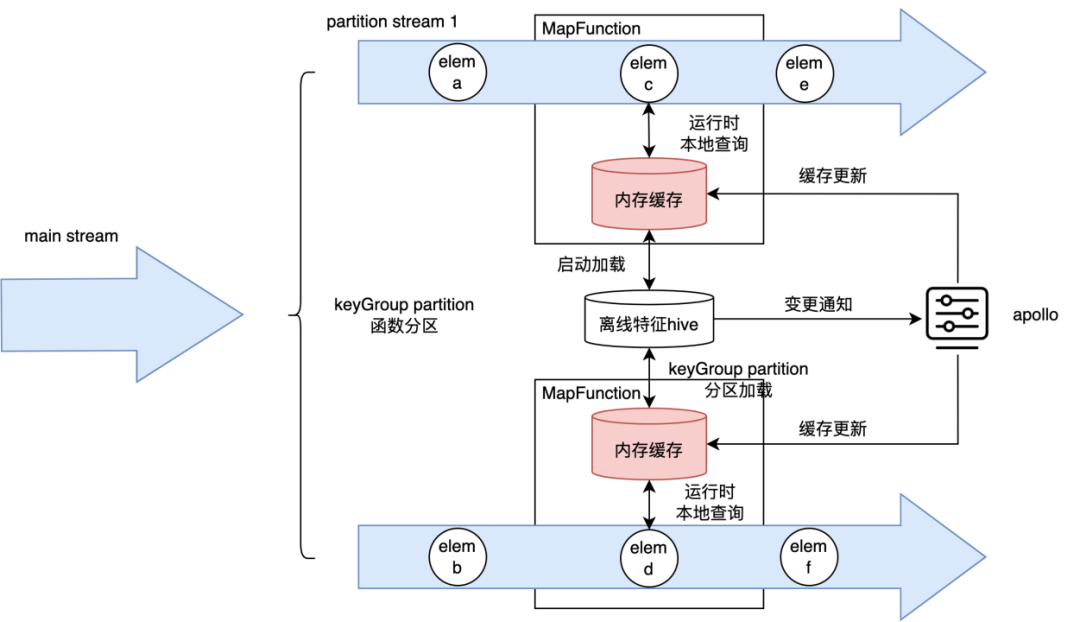
图4-4 内存方案
通过flink hive connector的改造,将hive的离线数据,通过Partitioned的方式,让每个taskmanager只加载部分所需的维表数据。
内存存储的优化挑战
a. Partition分区如何做?
基于用户id对数据进行预设分区
b. 内存如何优化?
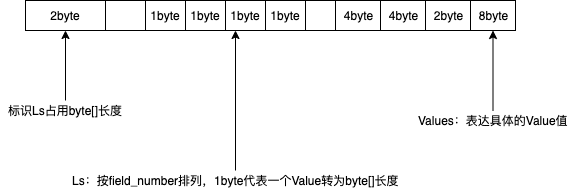
图4-5 自研序列号方案
基于团队自研的fast_bytes序列化方案,可以将内存数据降低为之前的三分之一
应用端智能
应用端智能即在业务应用服务中,直接存储特征数据,运行模型进行在线推理。
整体流程
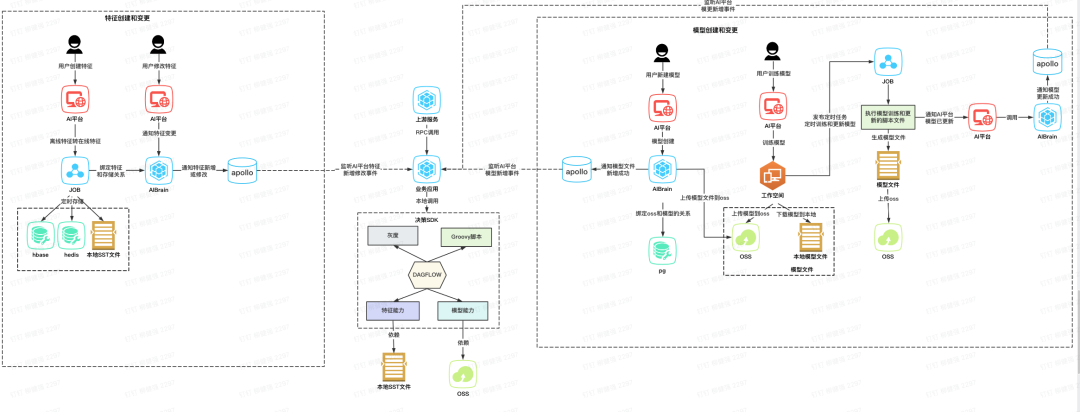
图5-1 业务应用端智能方案简易流程图
如图5-1所示,表示了应用端智能方案简易流程图,和2-1对比差异点如下。
1. 模型模块
模型运行环境:原先模型的运行环境是在ModelService集成的,现在模型在线推理在业务应用,需要在业务应用支持模型的运行
模型更新交互变化:原先模型的加载都是ModelService中监听模型新增或者修改,现在模型的新增和更新需要在业务应用监听apollo配置变化,在业务应用替换新模型
2. 特征模块
特征存储介质变化:特征的存储原先只在云端的在线存储中,业务应用智能后需要将特征存在在本地磁盘
特征更新交互变化:原先特征的新增或者修改都是在FeatureService监听特征的变化,将特征和存储的关系维护在特征服务中,现在需要在业务应用监听特征变化,且需要将特征直接拉取到业务应用本地磁盘或者内存中
3. 决策模块
原先决策是作为服务给业务方调用,端智能后需要打成sdk包给业务应用本地执行在线推理
挑战和方案
1. SDK设计
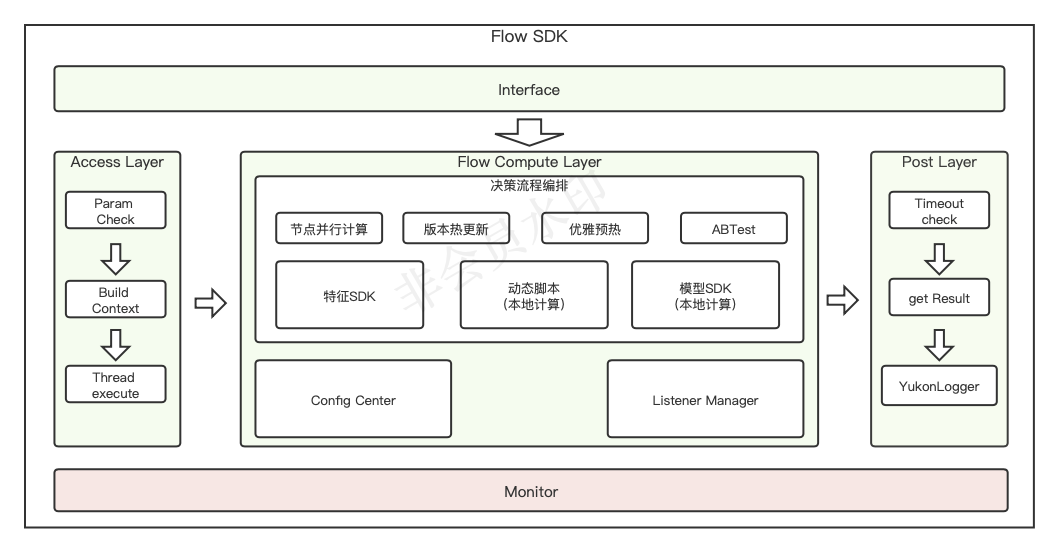
图5-2 决策sdk设计图
如图5-2所示,展示了决策sdk的整体设计。
模型服务将模型的加载,监听模型变更,优雅预热等逻辑打包成模型sdk
特征服务将特征的加载,监听特征变更等逻辑打包成特征sdk
决策在线服务将ABTest,流程编排,计算逻辑,特征预处理逻辑以及模型sdk,特征sdk逻辑打包为决策sdk,给业务应用调用
2. 模型类型兼容挑战
当前的业务应用如为java应用,则在运行时,只支持tf和pmml模型,python和python-gpu模型无法支持。
方案
目前短期解决方案为将部分python模型转为tf或者pmml模型打入业务应用进行运行,长期来说AI平台会探索为各类模型提供一个统一的运行环境,或者可支持的转换工具支持各类模型在同一环境中运行
3. 模型本地化
模型调用由SOA方式改为本地调用。
模型运行方案
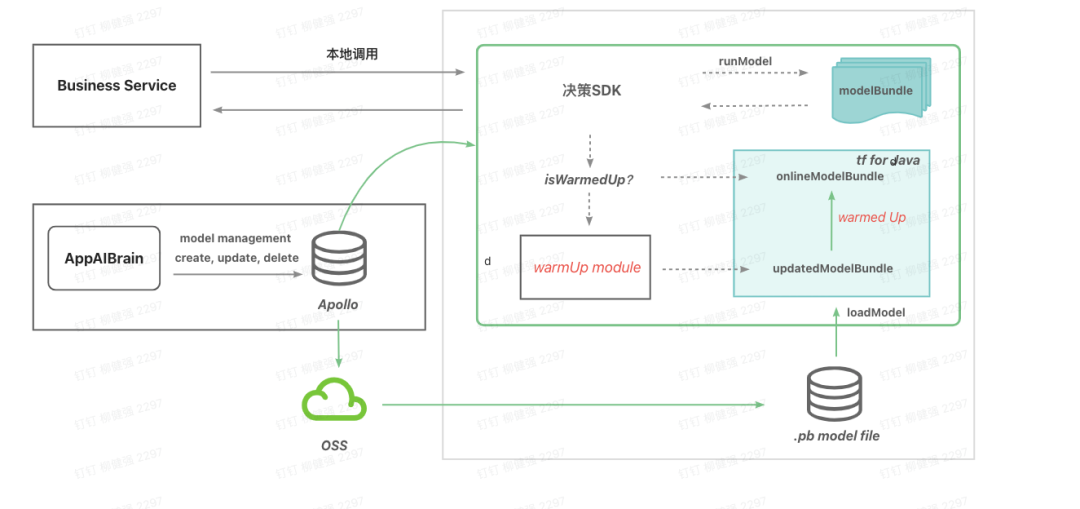
图5-3 模型调用本地化
业务应用会接入决策SDK,并通过tf for java将模型加载到本地,提供模型在线推理能力。模型更新后由AI管理平台更新apollo配置信息,业务应用通过监听apollo方式进行模型更新。
模型生命周期管理方案
新增或者修改模型上传到oss,通知apollo配置变更,应用服务监听配置变更,调用jni的tf接口加载模型到内存。在新老模型预热完毕后调用api接口卸载模型。
模型更新方案
a. 新老模型如何同步运行?
创建两个模型对象进行管理,支持同模型新老版本同时运行。
b. 新老版本更新的如何优雅预热?
基于模型历史一小时的rt均值,以及当前最近20次请求rt是否小于该均值进行判断是否预热成功。如果预热成功则新老模型切换。
4. 特征本地化挑战
本地化特征存在特征数据过大,导致业务应用启动过慢,无法快速扩容等问题。
方案
将特征加载从单线程转为多线程加载,并最大限度用上ESSD盘或NAS盘的IO上限
5. 在线特征挑战
在线特征如果业务应用直接调用,会存在连接池无法管控,调用量无法管控,在线存储压力过大导致互相影响等问题。
方案
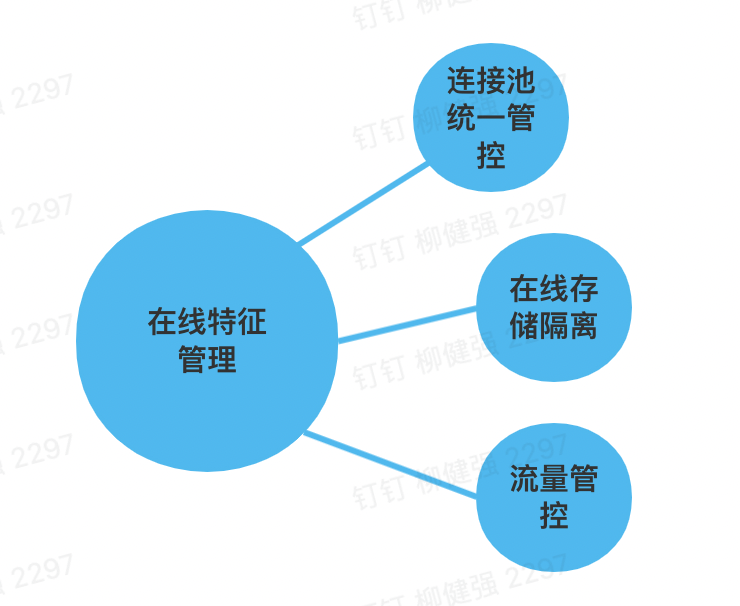
图5-4 在线特征管理图
通过AI平台统一的连接池管理,核心业务在线存储隔离以及限流机制避免在线存储的压力过大,互相影响问题。
目前一站式AI平台已经能够支持在多端进行在线推理能力,但是很多细节点需要持续优化。后续一站式AI会基于当前问题对各端智能方案进行持续优化,也会基于业界主流的AI平台架构和方案,持续对AutoML、AutoFE、模型Fass化部署、分布式训练和预测进行持续的建设和演进工作。