随着人工智能的发展和技术进步,越来越多的企业开始使用人工智能技术做效率的提升和业务效果的提升,降低企业成本,增强企业竞争力。本文将基于哈啰AI平台的能力,以接入普惠工单系统自动转派为例,讲述如何通过算法能力赋能后端研发提效。
建模流程
整个模型建模流程主要需要四大步:特征处理、模型训练、模型评估、模型部署。并且模型还需要进行不断的迭代才能保证模型效果。
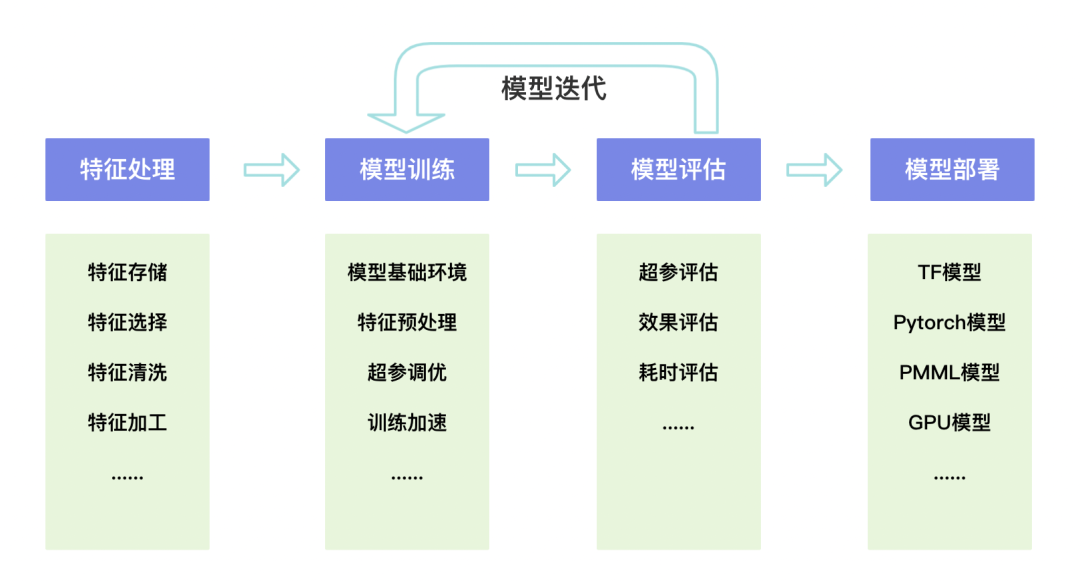
特征处理
包括特征存储、特征选择、特征清洗、特征加工等
模型训练
包括模型基础环境、特征预处理、超参调优、训练加速等
模型评估
包括超参评估、效果评估、耗时评估等
模型部署
包括TF模型、Pytorch模型、PMML模型、GPU模型等
AI平台方案
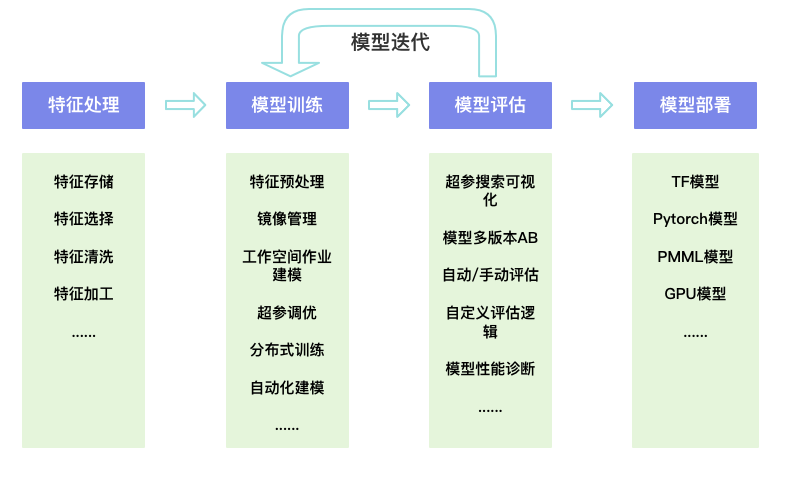
特征处理
包括特征存储、特征选择、特征清洗、特征加工等。下面以特征存储和特征加工为例,举例如何通过页面,最简化支持特征的存储和加工。
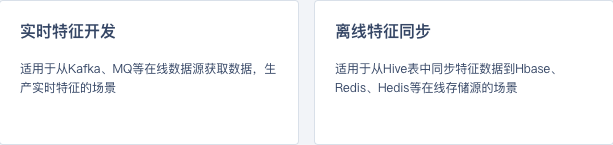
特征存储
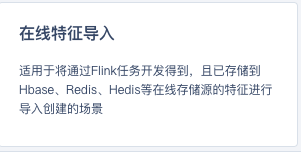
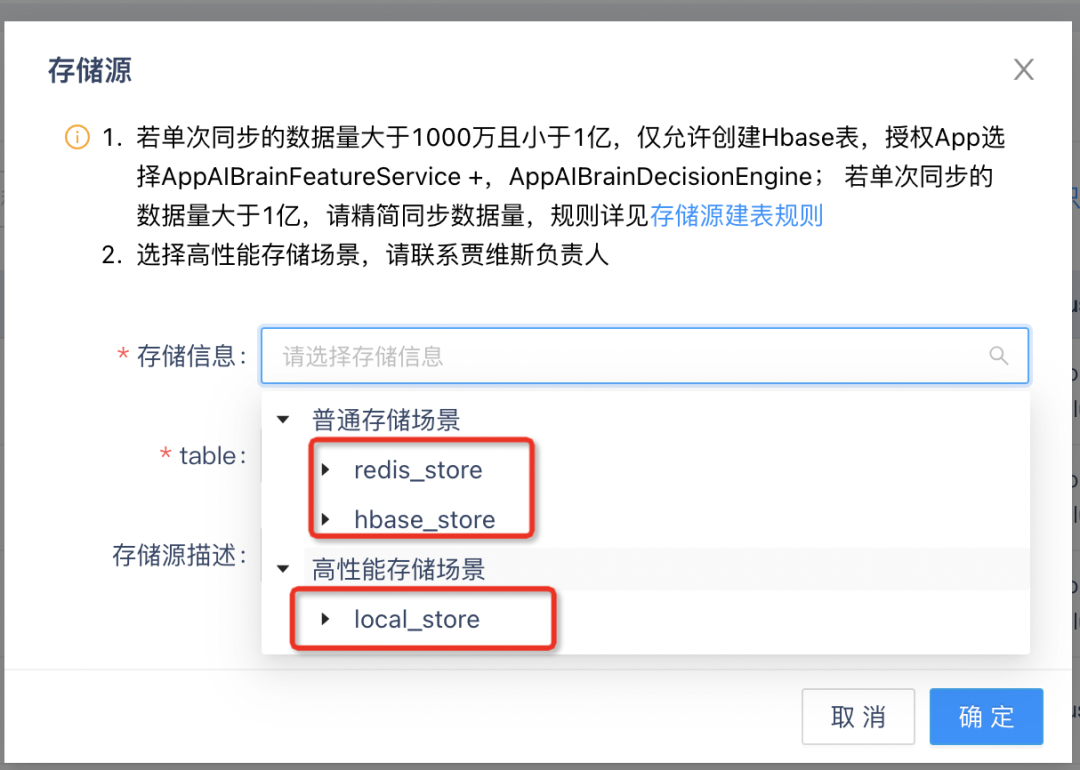
特征平台目前支持在线特征的存储,简单来说用户可以通过在AI平台点通过页面配置化的方式,将hive表数据或者kafka、rocketmq数据,同步到hbase、hedis、redis等在线存储中,也支持将数据存储到rocksdb进行本地化存储。如下图所示:
特征加工
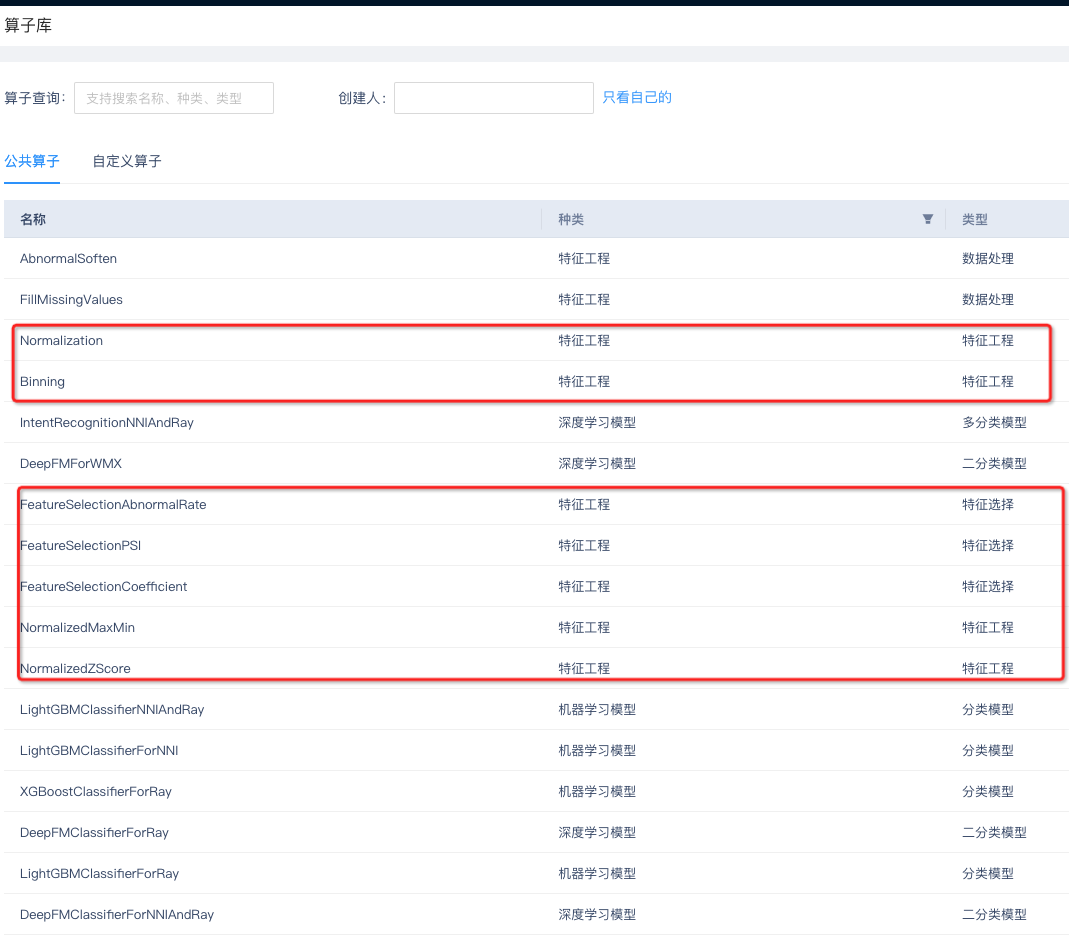
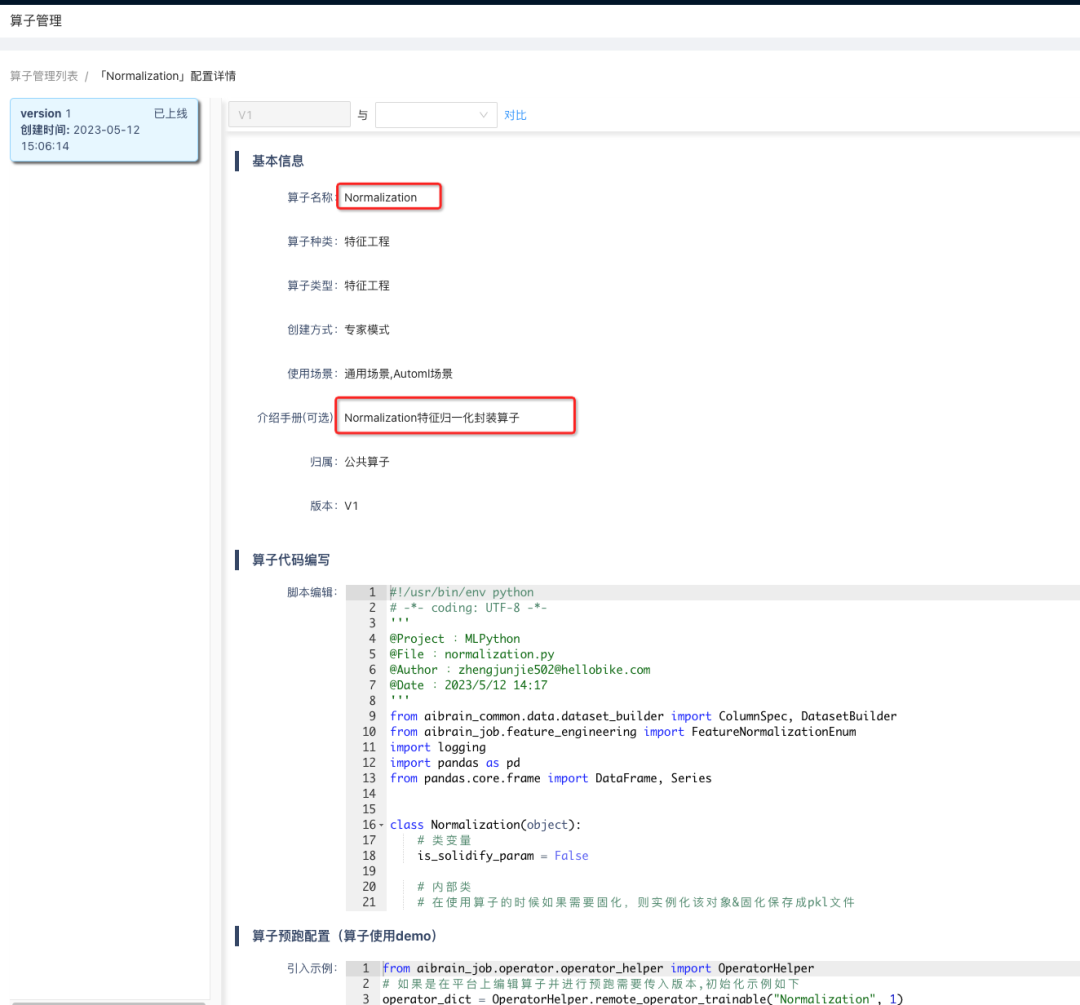
特征清洗的例子如下,AI平台先将部分特征工程逻辑算子化,如下图Normalizaiton为归一化算子。
落为算子后,后续自动化建模就可以直接在特征工程模块选择Normalization算子,这样在模型进行训练之前就会对特征进行归一化处理。
模型训练
包括特征预处理、镜像管理、工作空间作业建模、超参调优、分布式训练、自动化建模。
下文以自动化建模为例,讲述如何通过配置化的方式接入。
自动化建模
在自动化建模模块,先通过模型种类和模型分类,选择合适的模型类别。
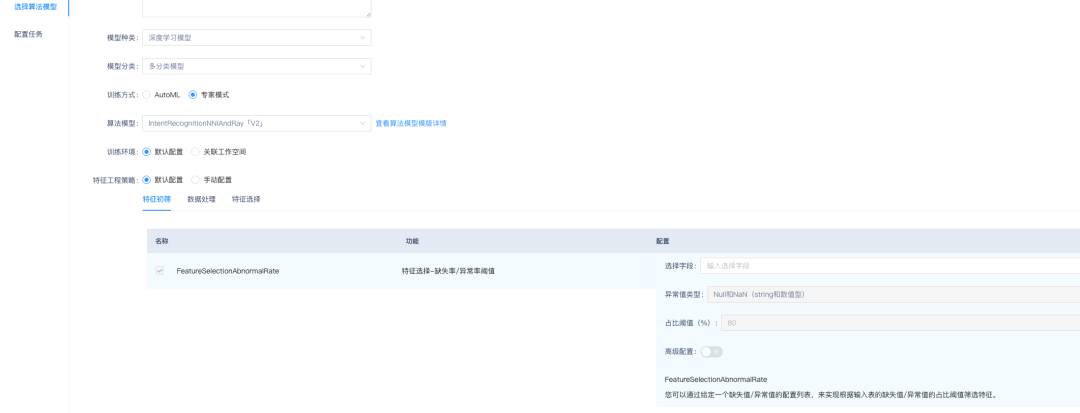
选择AutoML模式,则会自动帮用户选择模型。下图选择了专家模式,则需要用户自己选择深度学习的多分类模型。
如下图所示,选择了IntentRecognitionNNIAndRay模型,该模型是用ALBERT写的意图识别模型。选择意图识别模型后,可以选择特征的初筛、数据处理、特征选择逻辑,在自动化训练前进行特征的处理,下图展示了特征处理逻辑,可以对特征进行特征初筛、特征加工、特征选择。
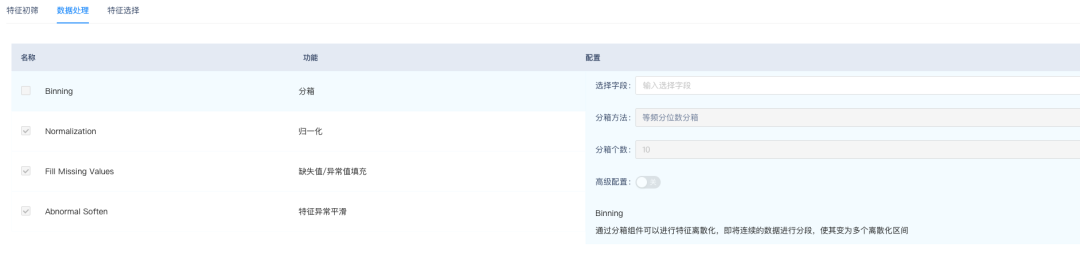
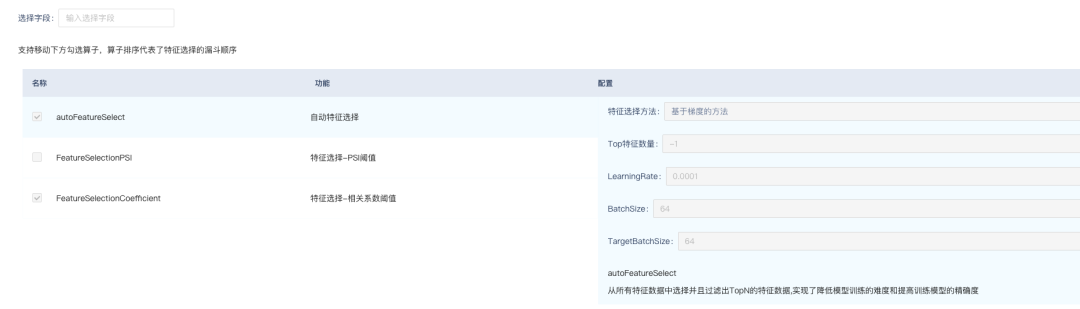
模型评估
超参搜索可视化、模型多版本AB、模型自动评估、模型手动评估、模型性能诊断、模型自定义评估逻辑等。
下文展示了AI平台实现的超参搜索可视化和模型评估。
超参搜索可视化
AI平台模型训练接入了NNI框架,将训练时的超参搜索可视化,这样用户在训练完成后可以通过超参搜索的分布判断模型是否存在问题,或者可以优化超参分布,从而使模型的效果更好。如下图所示:
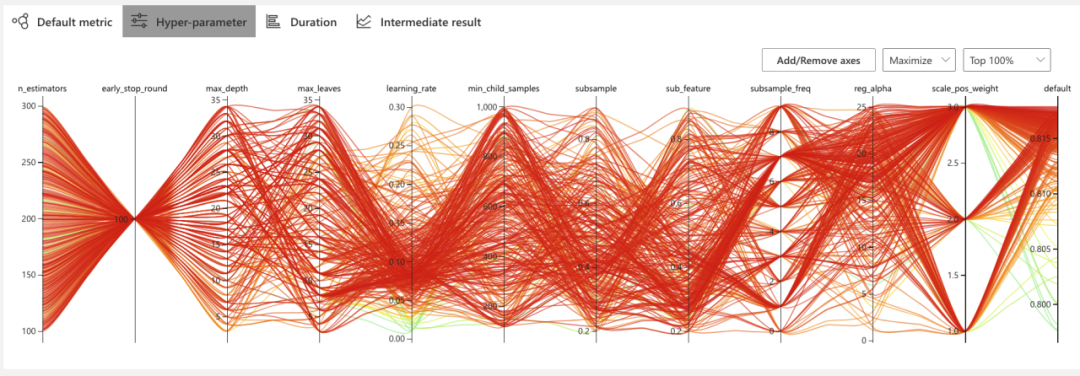
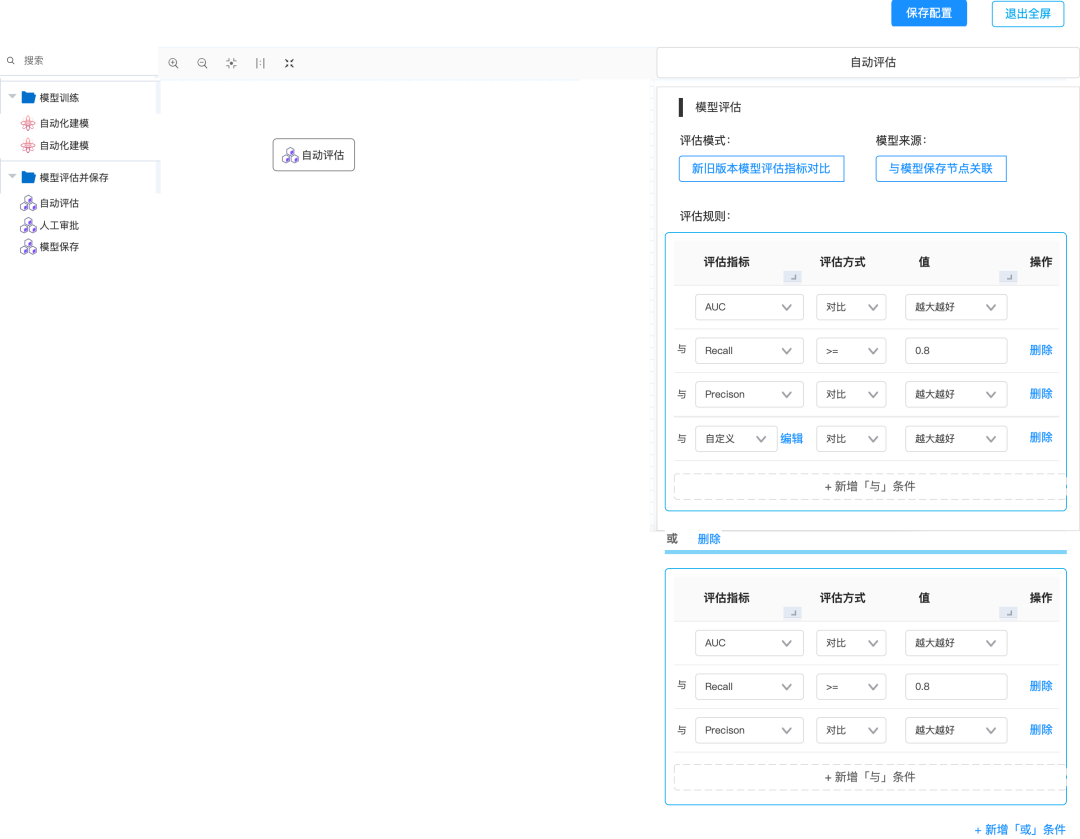
模型自动评估
通过自动化建模后,模型选择手动评估或者自动评估。以自动保存为例,可以在评估时选择评估的指标值,以及评估规则。后续模型训练后即可通过评估结果进行模型自动替换。
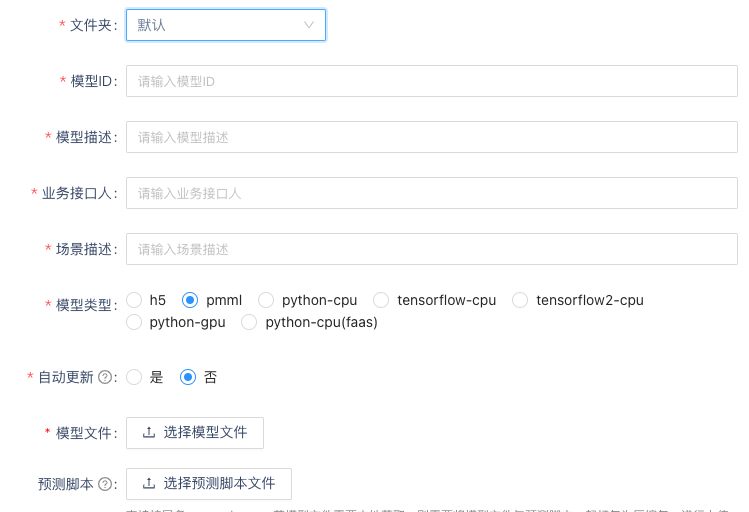
模型部署
支持TF模型、Pytorch模型、PMML模型、GPU模型。AI平台模型支持TensorFlow模型、PMML模型、Pytorch模型、GPU模型,还支持Faas化部署,如下所示,可以选择不同的类型,将模型文件上传,AI平台会将模型部署到对应的应用集群中。
意图识别算法
简单来说就是通过算法,识别用户的需求,即明白用户想做什么。
意图识别是人机对话构成的关键,而用户意图需要不断的对话才能真正的理解。
意图识别场景
意图识别的应用场景对话系统、搜索引擎等。
意图识别例子
搜索引擎很好理解,举例来说,你从谷歌输入了“八角笼”,意图识别会根据当前的热度和你的习惯进行识别,比如你是一个电影迷,会识别到你是想了解八角笼中的电影。
对话系统:举例来说,你输入小米,系统会至少有两种语义识别出来,一种是粮食小米,一种是小米品牌,而当你继续输入雷军,系统就了解你需要知道的是小米品牌。
BERT
BERT是自编码语言模型,通过Masked LM(随机屏蔽) 和 Next Sentence Prediction(下一句预测)两个任务来训练该模型。
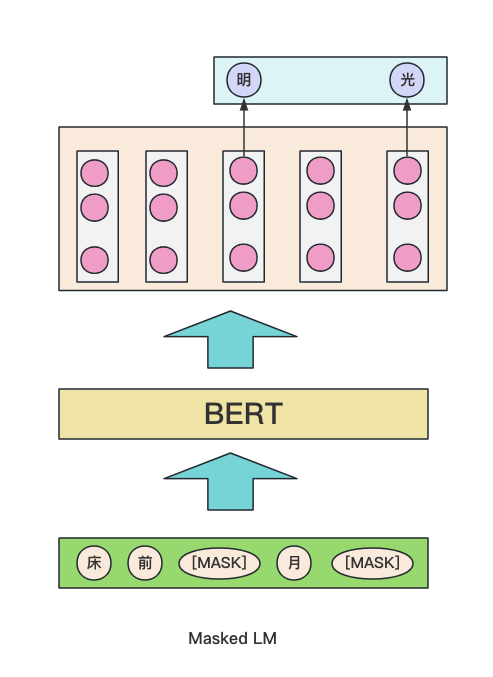
Masked LM
该思想来源于完形填空,简单来说,在一句话中,随机抹去这句话的一个或者多个词汇,要求根据剩余的词汇进行预测抹去的词分别是什么。如下图所示:bert分别隐去了一句话中的两个字,然后让模型进行“完形填空”自动补全。
好处:这样做迫使模型更多依赖上下文信息去预测,赋予了模型一定的纠错能力。
缺点:每批次只有15%的标记被预测,模型需要更多的预训练步骤来收敛。
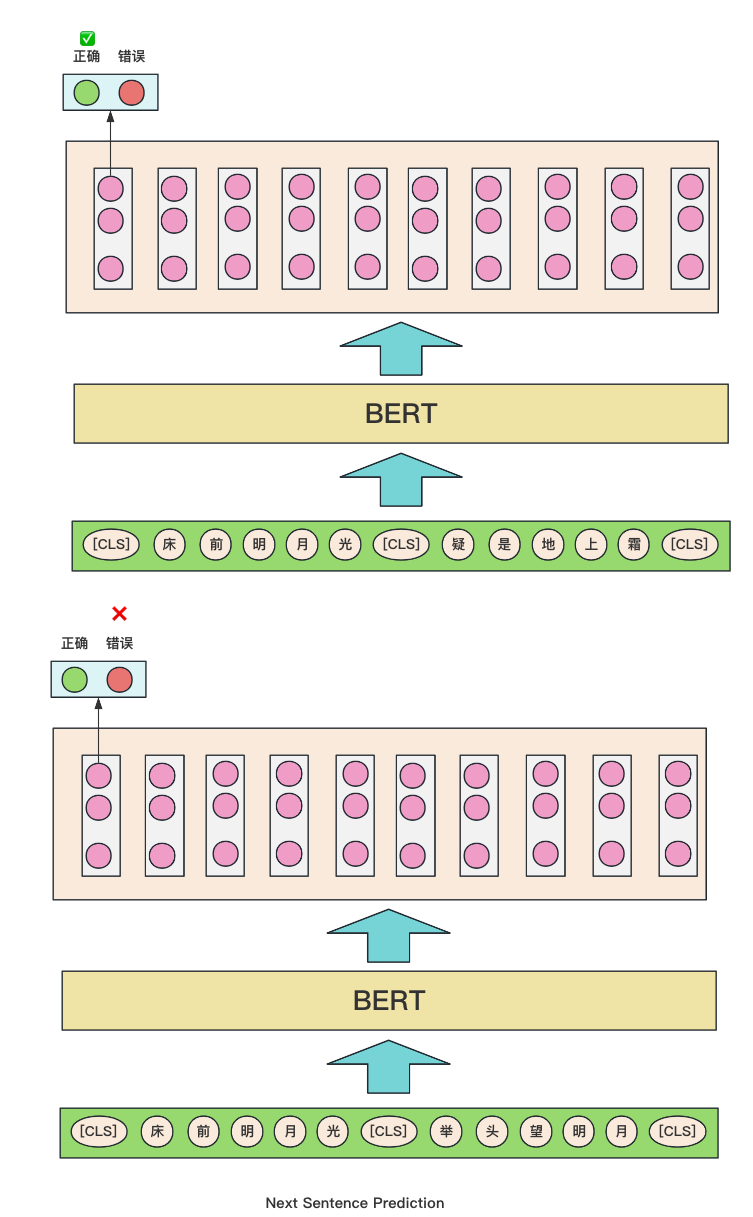
Next Sentence Prediction
判断第二句话是否在第一句话的后面。该任务与Masked LM任务相结合,让模型能够准确的理解和刻画语句或者文章的语义信息。
如下图所示:输入两句话,让模型能够判断是否为连续的句子,一个是正确的连续句子,一个是错误的连续句子。
ALBERT
BERT的改进版本很多,而ALBERT全称为A Lite BERT,是轻量化的版本。ALBERT采用了两种减少模型参数的方法,让其比BERT所需内存空间更小,并且提升训练速度。
原来的BERT由于模型参数过多,并且模型太大,导致少量数据容易过拟合,ALBERT则可以支持更少的数据,达到更好的效果。
普惠场景接入
普惠接入AI平台的场景是一个客服工单自动转派场景。该场景基于意图识别的ALBERT算法(由于普惠工单系统训练数据较少,因此ALBERT是很合适的模型),将客服客诉问题进行打标和打分,对符合分数要求的场景进行自动的转派和自动问题订正。
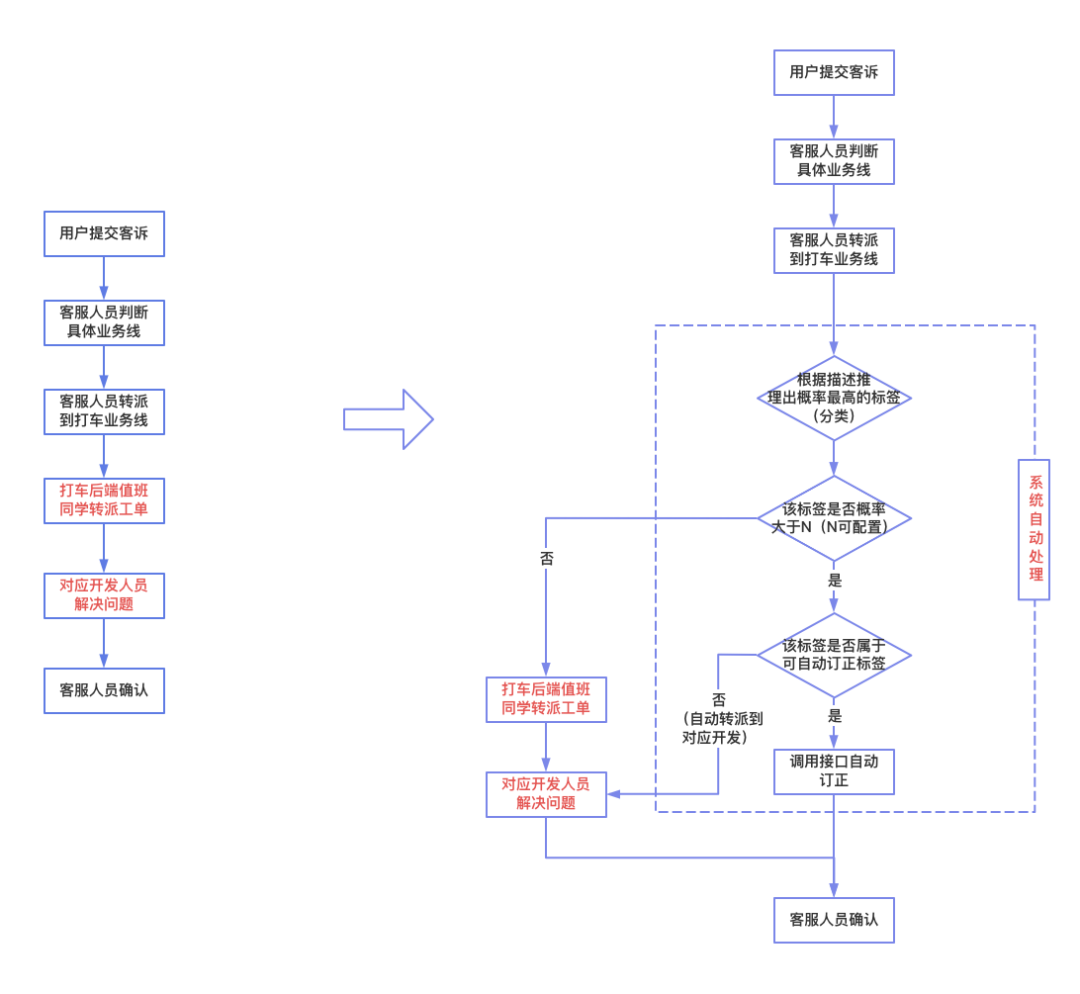
原流程
原流程步骤
原流程如下图左边所示:用户在哈啰app提交客诉->客服人员判断具体业务线->客服人员转派工单到打车业务线->打车后端值班同学转派工单->开发解决问题->客服人员确认。
该流程中,很重要的2步是打车值班同学转派工单和开发解决问题。
工单转派遇到的问题
以打车后端值班同学转派工单流程为例:由于日常客诉较多,因此每周会统一安排的一个开发进行值班,而开发人员每个人做的方向是不一样的,且水平有高有低,因此很多工单会转派错误,或者需要咨询对应的同学后进行转发,不仅准确率不高,且效率较低。
工单处理遇到的问题
开发解决问题也有和转派类似问题,由于开发人员的水平不一致和做的方向不一致,因此解决问题的人十分分散,且解决周期也各不相同。因此最好的解决办法是,工单能通过系统自动转派对应的人,且问题可以通过系统自动订正,这样值班人员不需要对该类问题进行工单转派,也不需要单独有人进行问题处理,系统能够完全进行自动的处理。
新流程
新流程如下图右边所示,主要变化为将打车值班同学转派工单和开发解决问题两步进行了自动化处理。
自动转派和自动处理方案
原方案
打车侧的原方案为关键词匹配,即根据客服的描述,通过关键字进行匹配,该方案的准确率很低(准确率不足10%)。
算法方案
自动转派逻辑
业务开发对不同的描述进行打标,每个标签对应不同的开发。举例如下:左边客服系统的描述,右侧是给该描述打的标签。而每一个标签后面都会对应相应的处理同学。
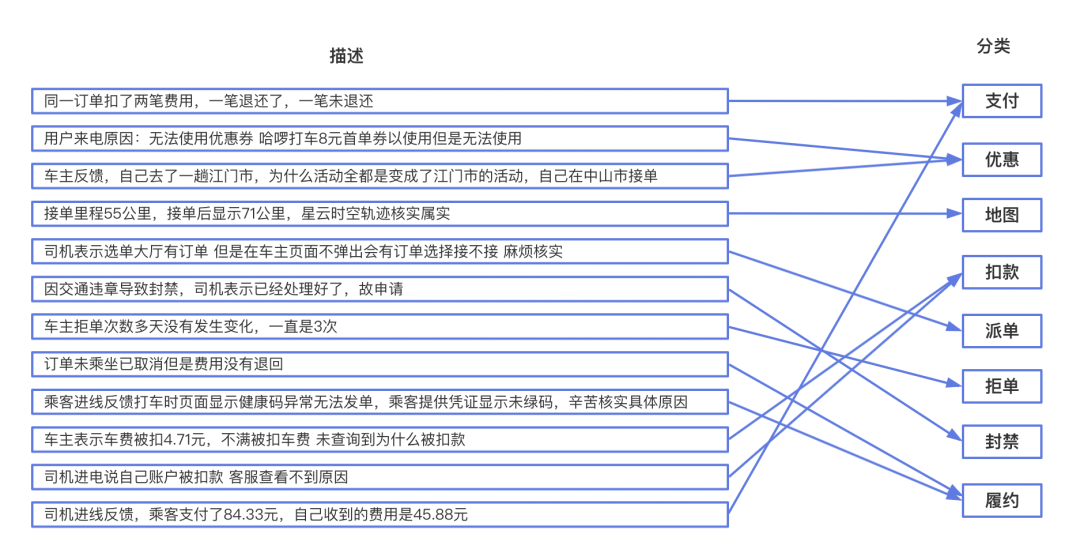
算法根据客诉描述,推理出该描述对应的标签和概率,然后对系统留下概率超过一定值的分类(线上为0.7),进行转派。如下图所示:

自动处理逻辑
根据标签的结果,对部分标签(配置化)进行调用接口自动化处理。
接入流程
新场景
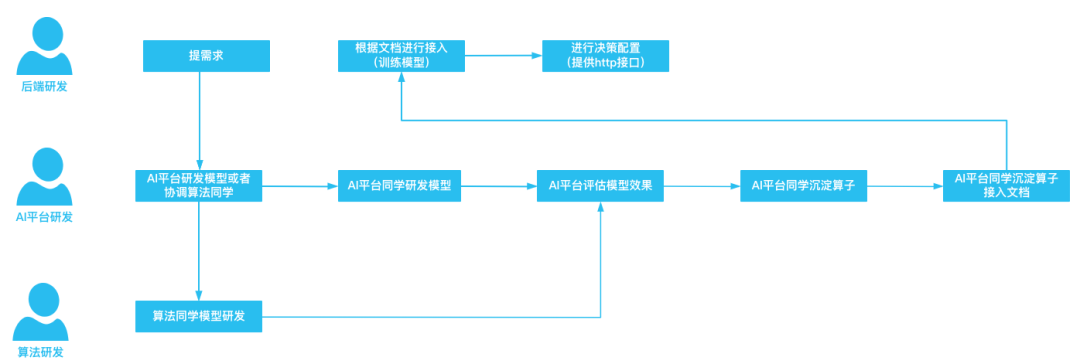
新场景接入流程如下所示(新沉淀算子流程):
需求新增:后端研发根据业务场景给AI平台提需求
需求评估:AI平台会根据用户需求评估可行性,并判断是否可以复用已有算子(模型)
模型研发:AI平台进行模型研发,如模型过于复杂,则AI平台会协调算法进行模型研发
模型评估:AI平台进行效果评估,如模型效果评估通过,会沉淀为算子,如不通过,会进行模型的分析和修正
算子沉淀:AI平台同学根据模型沉淀为算子
文档沉淀:AI平台会将该算子的使用方案和接入沉淀文档
用户接入:后端研发根据接入文档进行模型的在线推理的接入
复用算子场景
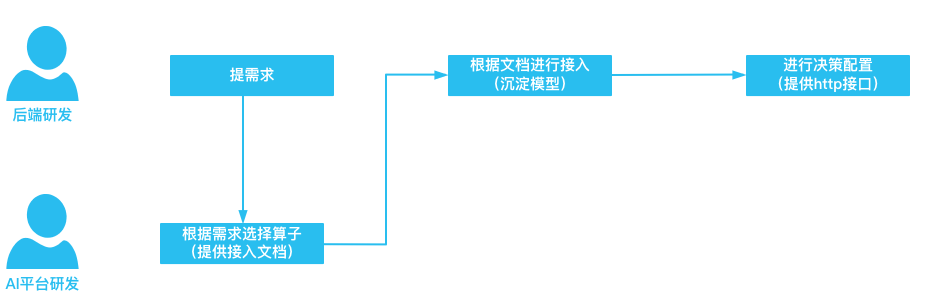
新场景接入流程如下所示(复用算子流程):
需求新增:后端研发根据业务场景给AI平台提需求
需求评估:AI平台会根据用户需求评估可行性,并判断是否可以复用已有算子(模型)
用户接入:后端研发根据接入文档进行模型的在线推理的接入
总结
整体来说,AI平台目前通过配置化的方式支持特征的存储,并通过算子库的方式,将特征的处理逻辑和算法算子化,这样用户完全无需算法的知识就能进行自主接入。并通过自动化工作流,实现了模型的自动训练、自动评估和自动替换。而有算法经验的同学,可以根据超参调优和超参调优可视化进行模型的调试和训练。目前基于EasyML2.0接入的场景上线大部分场景效果超过预期。

