智能判责在哈啰顺风车的应用
智能判责任务简介
智能判责定义
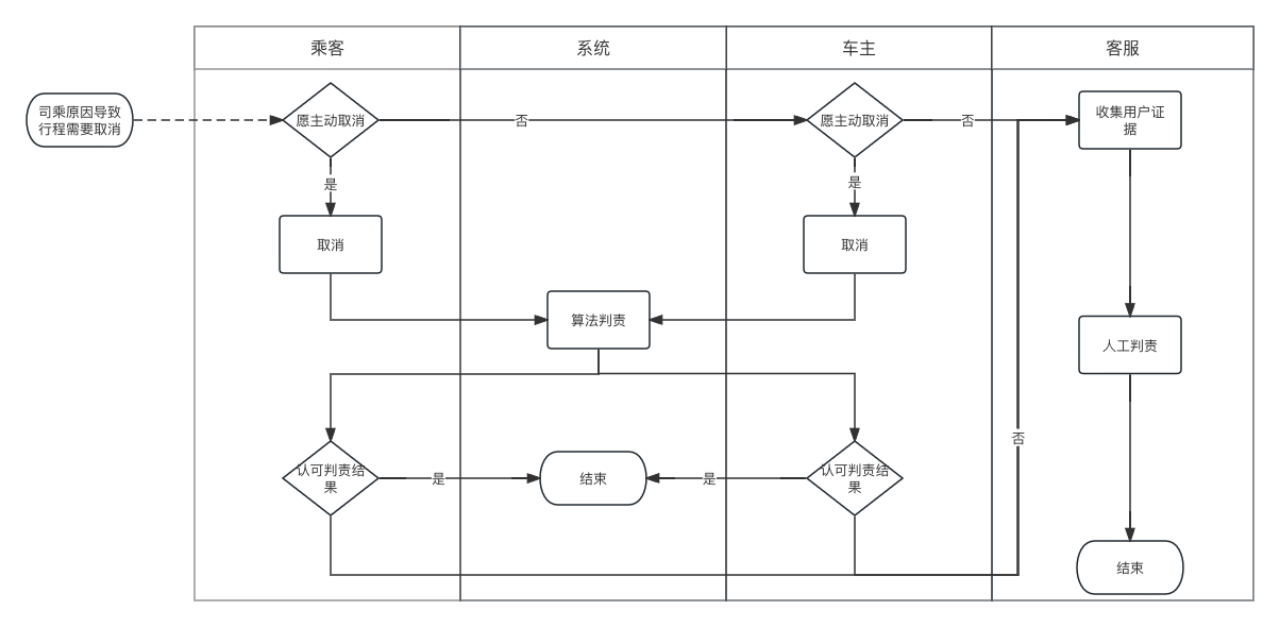
在普惠顺风车订单系统中,一旦司机和乘客建立订单关系后,若其中任何一方发起取消订单的请求,将触发判责算法,该算法将输出确定订单取消责任的一方。
智能判责难点
重要特征因子繁多:聊天记录、电话录音以及订单备注等皆属于最为关键的因素之一。然而,这些特征本身的形式多样,包括文字和录音等形式,因此其解读与消化变得相当困难。
训练样本匮乏:当前可用的训练样本中,判责结果的准确率本就不尽人意。因此,基于这些样本训练出的模型的可靠性也较低。
复杂的应用场景交叉:不同场景之间相互交织,例如订单取消可能因时间变更,也可能是因对方要求额外高速费或者额外增加人员等等问题。
特征数量与判断难度正相关:传统的算法模型认为特征越多准确率越高,然而,在智能判责领域,特征的增多意味着事务变得更加复杂,从而增加了模型准确判断的难度。
传统智能判责算法
工程判责:
判责介绍:利用一定的规则进行判责(容易被发现漏洞)
算法判责1.0_趋近客服改判:
训练数据集:客服改判结果
特征因子:订单基本信息、司乘基本信息
算法判责2.0_工程+客服改判:
训练数据集:90%工程判责数据(用户有选择取消原因&未进入客服侧的工程判责数据)+10%客服改判数据(客服改判后用户未再进线的改判数据)
算法判责3.0:
训练数据集:数千条双盲精确打标数据
特征因子:订单基本信息、司乘基本信息+85%准确率的聊天记录意图识别模型
结合大模型的智能判责
为什么要用大模型来进行判责
目前,传统的智能责任判定算法在处理无沟通记录的情况下,准确率高达99.7%,但对于具有聊天记录和通话记录的案例,准确率稍有下降。而根据业务反馈,复杂案例需要自然人参与听取通话内容进行判定。
为了进一步提高准确率,关键的提升点在于文本和语音的语义理解。目前的深度学习模型在此方面达到了大约80%的准确率,但在特征融合过程中存在着较大的信息损失。
大模型在这方面具有独特的优势。同时,我们的责任判定场景有明确的SOP,可以通过一定手段来确保模型准确率达到可接受的水平。此外,大模型还能够提供责任判定的原因,这是以前的深度学习模型所无法实现的。
一个例子感受下大模型的强大之处:

输入:订单的上下文信息和司乘聊天信息。

输出:明确按照我给的判责流程进行判责工作,并给出推理过程和判责依据。
Prompt工程
Prompt工程是创建Prompt、提问或指导像ChatGPT这样的语言模型输出的过程。
它允许用户控制模型的输出,生成符合其特定需求的文本。Prompt 工程的作用,通过提供清晰和具体的指令,可以引导模型的输出,确保其相关性。
简单举例,想创建一个负责生成文本的机器人,提示词需要遵循以下四个要点:
以第二人称而不是第三人称称呼机器人,让机器有自我认知
措辞尽可能地清晰,减少误解
可以在提示中使用方括号对指令进行扩展描述
使用Markdown有时可以帮助机器人更好地理解复杂的指令
这里的关键不在技术,而在提示词的质量与创作者的脑洞,以及善于利用AI解决问题的能力——“人机交互”能力。
随着使用越来越多大家也发现大模型直接给出答案似乎并不靠谱,那么是否可以让它像人类一样,一步一步思考呢?毕竟,人类在解决问题时,也是逐渐构建解决方案,而并非立即给出答案。因此,开始出现了一系列的尝试解法,比如思维链、多思维链、思维树和思维图等。

这可以通过两种方式实现,一种是具体说明,即要求模型详细地、一步步地思考;另一种是示例说明,即通过给定问题和答案的同时,提供思考过程。这样,当询问模型时,模型会模仿此过程,逐渐思考并给出答案。
外挂知识库
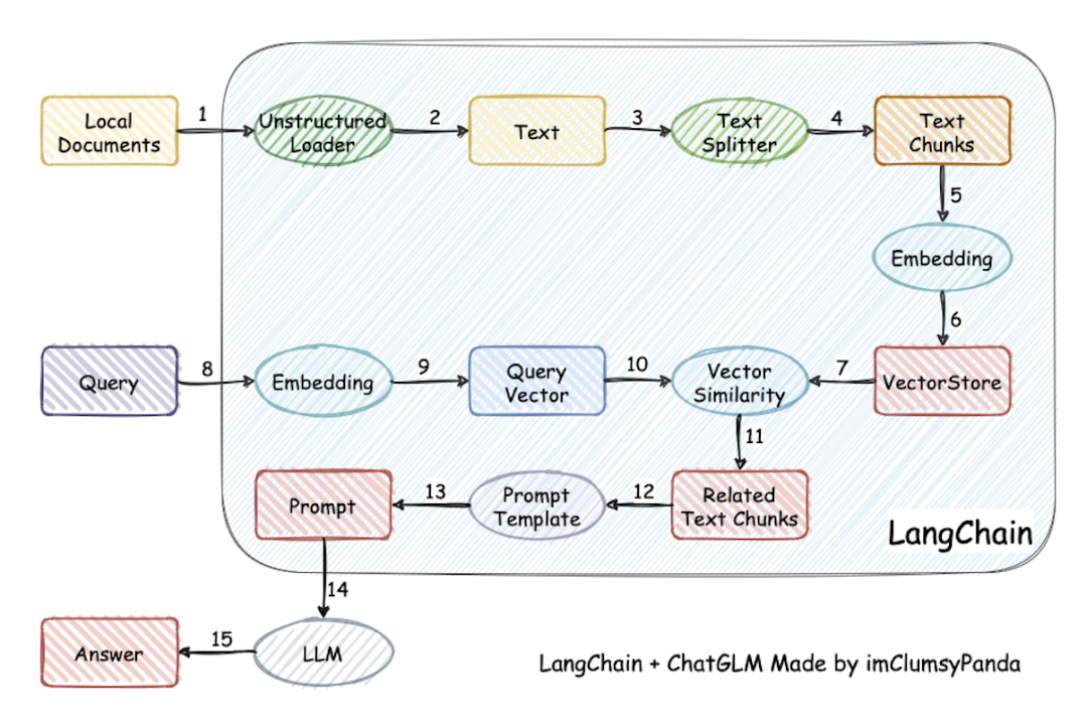
步骤:
将知识库的文本分块,并进行向量化(可以使用大模型的embedding也可以使用如BERT等方法)
用户的query向量化,并在知识库中进行检索,返回最相关的TOPN的文本块
采用合适的prompt + 上述步骤搜索到的文本,一并输入给LLM
利用LLM的语义理解能力和知识问答能力,生成问题的答案
缺点很明显:只是匹配到最相关部分,不是理解全部语义,准确率有损。
Agent
Agents=LLM + 任务规划(COT) + 记忆(LangChain) + 工具使用
其中LLM是核心大脑,记忆、任务规划和工具使用则是Agents系统实现的三个关键组件。再加上行动端,形成一个完整的Agent System。

记忆(Memory)
记忆可以定义为获取、存储、保留和稍后检索信息的过程,其中包括储存了Agent过去的观察、思考和行动序列的信息。
短期记忆(Short-term memory)
由于Transformer模型的上下文窗口有限,短期记忆是一种短暂且有限的记忆形式;为了应对这种限制,目前有以下解决方案:
1. 扩展主干架构的长度限制:通过改进Transformer模型固有的序列长度限制问题来提高短期记忆的容量。比如gpt4-8k, gpt4-32k, gpt4-128k。
2. 总结记忆(Summarizing):对记忆进行摘要总结,增强Agent从记忆中提取关键细节的能力,例如LangChain的Conversation Summary Buffer Memory
长期记忆(Long-term memory)
长期记忆是AI Agent可以在查询时处理的外部向量存储,可以通过快速检索访问,并使用适当的数据结构对记忆进行压缩,以提高记忆检索效率。
工具使用(Tool Use)
人类通过使用工具来完成超出我们身体和认知极限的任务。同样地,给LLM配备外部工具也可以显著扩展大模型的功能,使其能够处理更加复杂的任务。如联网工具、访问外部一切API的能力、访问业务服务API的能力。
任务规划(Planning Skills)
在具体实现中,规划可以包含两个步骤:
1. 计划制定(Plan Formulation):代理将复杂任务分解为更易于管理的子任务。
一次性分解再按顺序执行、逐步规划并执行、多路规划并选取最优路径等。
在一些需要专业知识的场景中,代理可与特定领域的 Planner 模块(SOP)集成,提升能力。
2. 计划反思(Plan Reflection):在制定计划后,可以进行反思并评估其优劣。这种反思一般来自三个方面:借助内部反馈机制;与人类互动获得反馈;从环境中获得反馈。
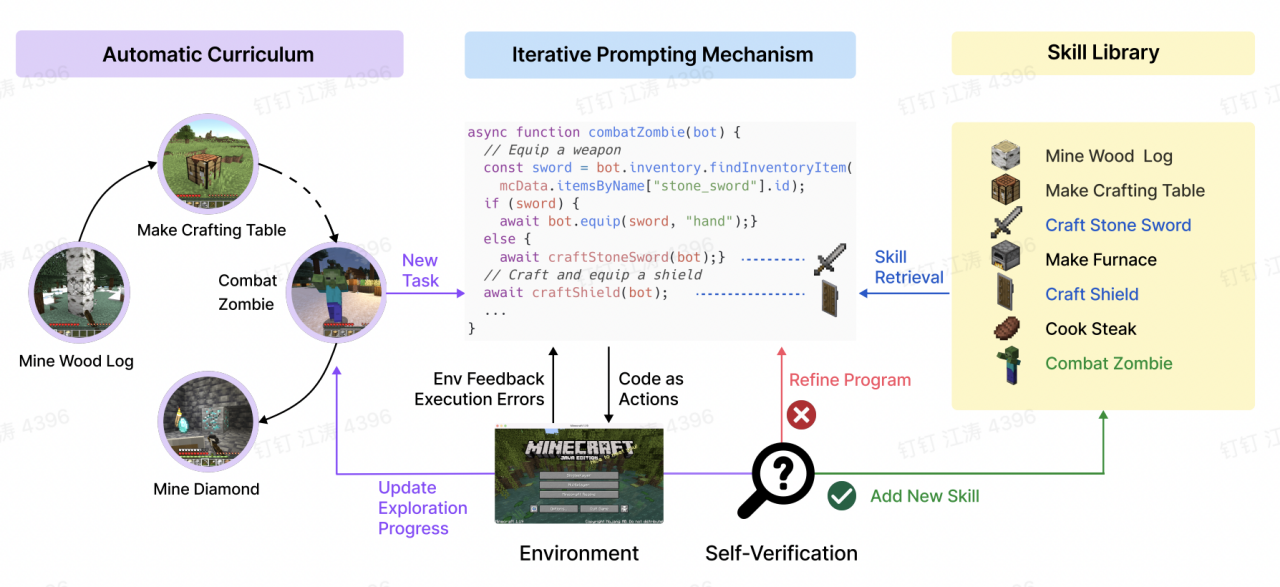
我们把Agent视作一个虚拟世界中的智能体,如MineCraft游戏中所设定的角色。这个角色可以沿着指定的路线,完成一些在环境中探索的任务,如建房子、挖矿、打怪等。这个角色首先需要被告知怎样去执行任务,例如自动训练课程计划的使用。然后逐步的完成任务,形成自己的执行代码库、技能库等,这样就算是在以后遇到相似的任务,它都能快速调用已有的技能和经验来完成任务。某种意义上,这就是一种强化学习的方式。
结合大模型的智能判责
之前的介绍的方案都是在不改变大模型原有参数的情况下。
在我们探索大模型的应用过程中,从prompt工程转向微调方案是一个重要的步骤。这个转变涉及到模型的训练和优化方式的根本性改变。
而微调方案都是在预训练模型的基础上,通过微调部分参数,来适应特定的任务。微调方案主要包括Freeze、prompt tuning、LoRA等。
这两种方法各有优势,Prompt工程的优点在于其高效性和灵活性,而微调方案则可以更精细地调整模型以适应特定任务。而且通常是结合起来使用。
Lora方法

LoRA(Low-Rank Adaptation of Large Language Models),直译为大语言模型的低阶自适应。LoRA 的基本原理是冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型参数参与微调类似的效果。
随着大语言模型的发展,模型的参数量越来越大,比如 GPT-3 参数量已经高达 1750 亿,因此,微调所有模型参数变得不可行。LoRA 微调方法由微软提出,通过只微调新增参数的方式,大大减少了下游任务的可训练参数数量。
A的输入维度和B的输出维度分别与原始模型的输入输出维度相同,而A的输出维度和B的输入维度是一个远小于原始模型输入输出维度的值,这也就是low-rank的体现(有点类似Resnet的结构),这样做就可以极大地减少待训练的参数了。
我们也尝试了lora微调实验,在同样的prompt和相同基座下准确率由之前的32%提升至微调后的60%。

