Intel 32nm Westmere-EP处理器首发评测
SiSoftware Sandra的缓存内存性能测试也比较有参考价值:
SiSoftware Sandra Pro Business 2010 | |||
|---|---|---|---|
测试对象 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
Memory Bandwidth Benchmark 内存带宽测试 | |||
Int Buff'd iSSE2 Memory Bandwidth | 38GB/s | 35GB/s | 35.2GB/s |
Float Buff'd iSSE2 Memory Bandwidth | 38GB/s | 35GB/s | 35.18GB/s |
Memory Latency Benchmark(Random) 内存延迟测试(随机) | |||
Memory(Random Access) Latency (越小越好) | 80ns | 83ns | 82ns |
Speed Factor (越小越好) | 55.50 | 57.00 | 64.60 |
Internal Data Cache | 4clocks | 4clocks | 4clocks |
L2 On-board Cache | 11clocks | 10clocks | 10clocks |
L3 On-board Cache | 49clocks | 57clocks | 60clocks |
Memory Latency Benchmark(Linear) 内存延迟测试(线性) | |||
Memory(Linear Access) Latency (越小越好) | 7ns | 7ns | 7ns |
Speed Factor (越小越好) | 4.80 | 5.10 | 5.50 |
Internal Data Cache | 4clocks | 4clocks | 4clocks |
L2 On-board Cache | 10clocks | 11clocks | 11clocks |
L3 On-board Cache | 13clocks | 13clocks | 13clocks |
Cache and Memory Benchmark 缓存及内存测试 | |||
Cache/Memory Bandwidth | 142GB/s | 183.26GB/s | 195.6GB/s |
Cache/Memory Bandwidth vs SPEED | 49.57MB/s/MHz | 63.96MB/s/MHz | 60.07MB/s/MHz |
Speed Factor (越小越好) | 21.20 | 31.00 | 35.20 |
Internal Data Cache | 471GB/s | 663.51GB/s | 744.49GB/s |
L2 On-board Cache | 295.4GB/s | 537.88GB/s | 611GB/s |
不出意外的是,Westmere-EP的内存读写带宽数值反而要低一些——它们的内存存取延迟也要长一点。内存带宽低了约7.4%,内存随机延迟高了2~3ns,L3缓存延迟高了约10个时钟周期。为什么会这样呢?因为Nehalem-EP/Westmere-EP所有的核心都是通过一个交叉开关的结构来连接到L3缓存乃至内存控制器、QPI的,核心数量越多,那么核心访问发生冲突的几率就越大,这导致了其内存潜伏期的提升。在八核心的Nehalem-EX上,为了避免这种情况变得更严重,开始采用了新的总线来代替这个交叉开关,如下所示:
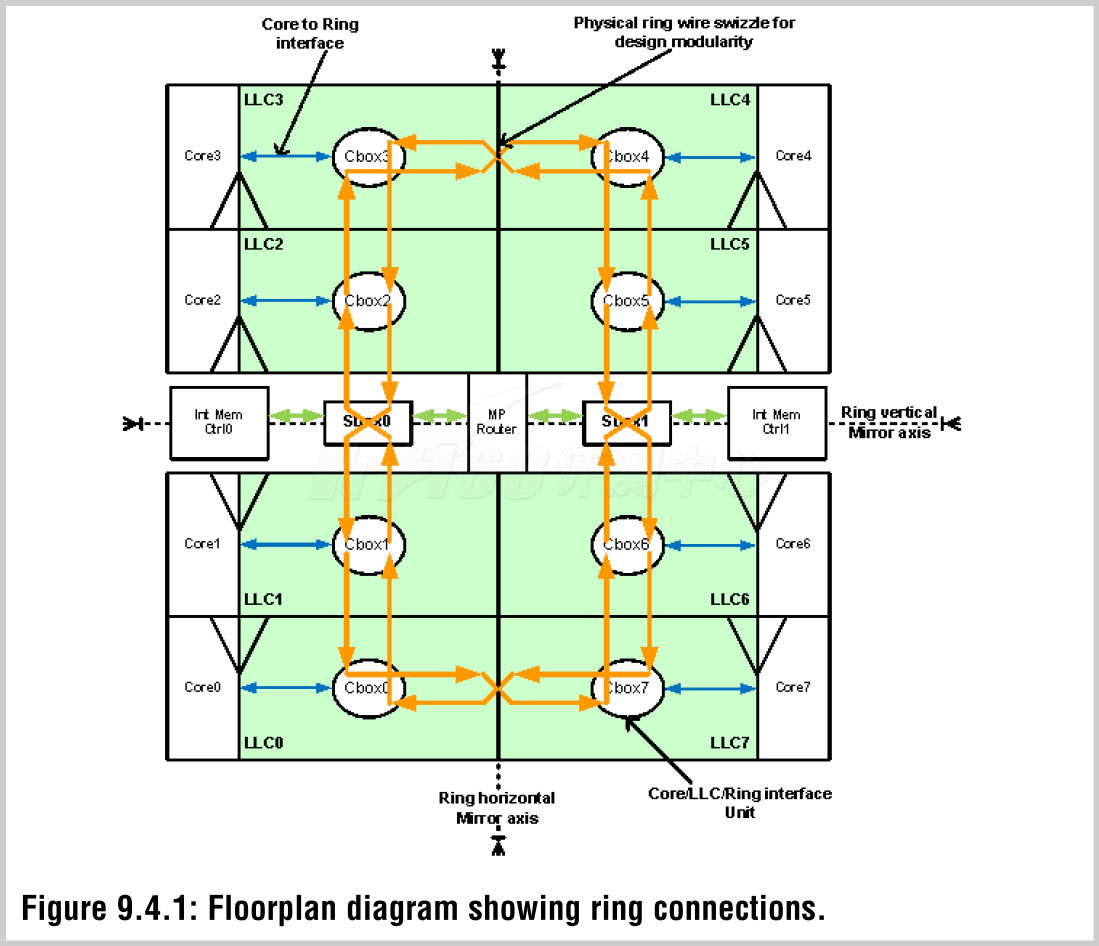
Nehalem-EX:Ring Interconnet
这个总线提供了极高的带宽(一共1.2TB/s)和很低的延迟(5个时钟周期)。在Nehalem-EX的发布文章当中笔者将会继续解析这个结构。
0
第1页:Intel 32nm Westmere-EP六核心处理器第2页:再谈Intel Tick-Tock钟摆战略第3页:70亿美元:32nm晶圆厂的花费第4页:32nm工艺:更低功耗、更高性能第5页:ISSCC:Westmere处理器的电路艺术第6页:Westmere-EP处理器架构第7页:AES、SSL、HTTPS,你需要吗?第8页:虚拟化:Nehalem的弱点暴露?第9页:Westmere与Tylersburg:平台的改进第10页:Westmere-EP:处理器规格对照表第11页:Westmere-EP实物包裹开箱第12页:测试平台与测试环境第13页:CPU-Z软件检测第14页:EVEREST软件检测第15页:SiSoftware Sandra 2010处理器性能测试第16页:SiSoftware Sandra 2010缓存内存性能测试第17页:EVEREST Ultimate Edition性能测试第18页:CINEBENCH性能测试第19页:MMM、SunGard与Black Schles测试第20页:初步的平台功耗测试第21页:IT168评测中心观点
相关文章
关注我们

