1 背景
随着业务不断发展,一个服务中部分功能模块适合沉淀下来作为通用的基础能力。作为通用的基础能力,对提供的服务可用性和稳定性有较高的要求,因此把该部分功能模块拆分出来,单独一个服务是比较好的选择。为了更好的与业务服务物理隔离,不仅需要从代码层面拆分,数据库层面也需要拆分。在做技术方案设计时面临着以下几个问题:
迁移过程中是否允许停服?如果停服,停服时间窗口如何做到尽可能短?
旧库表数据如何迁移到新库?
迁移后如何保证旧库表数据与新库表数据一致?
2 数据迁移方案
面向C端用户的场景,我们可能会脱口而出一个数据双写的方案。面向B端用户场景,可能直接暴力停服迁移。很多时候线上业务场景都是读多写少,如果把上面两个方案折衷一下也是一个不错的迁移方案。
下面介绍两个数据迁移方案,一个是大家耳熟能详的数据双写,另一个是以短暂写入失败为代价的开关控制迁移方案。
2.1 方案一:双写新旧库
双写的迁移流程如下图所示:
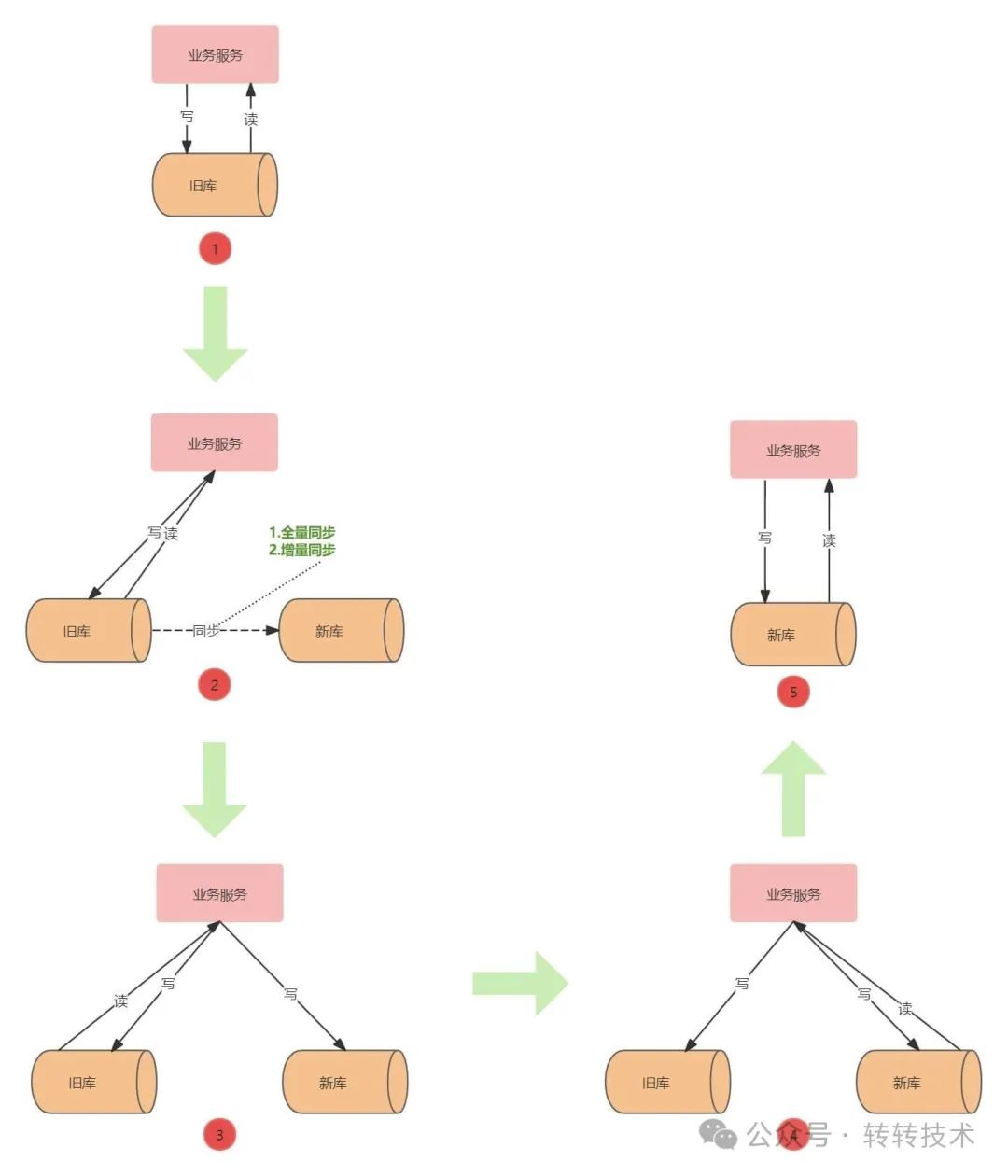
双写迁表
图-1
②新旧库数据同步:由DBA协助完成旧库表数据迁移到新库,并使用增量同步工具把旧库表数据同步到新库。
③开启双写:业务服务迁库代码改造上线,在业务写入低峰期校验新库与旧库表数据一致后,DBA断开旧库与新库的同步,业务服务同步开启写新库开关,开始双写。
④读新库:校验新库与旧库表数据一致后,读流量切换到新库进行数据验证,验证期间有问题可以随时切换回旧库。
⑤代码清理:读写流量全量切换新库,下线写旧库代码。
采用双写方案迁移库表可以做到用户无感知的平滑切换,验证过程中发现问题可以及时回滚。
双写引入了多个数据源,项目中如果使用了事务,面临着跨库事务,对事务代码块的改动成本相对较大。同时还面临着同步双写和异步双写的选择:
同步双写:新旧库的数据一致性有保障,写新库失败会影响现有的业务。
异步双写:写新库失败会导致数据不一致,不影响现有业务,需要额外的补偿方案保证新旧库数据的最终一致。
2.2 方案二:灰度开关切换新旧库
该方案不涉及双写,在代码里根据开关控制使用新库还是旧库,切换流程如下图所示:
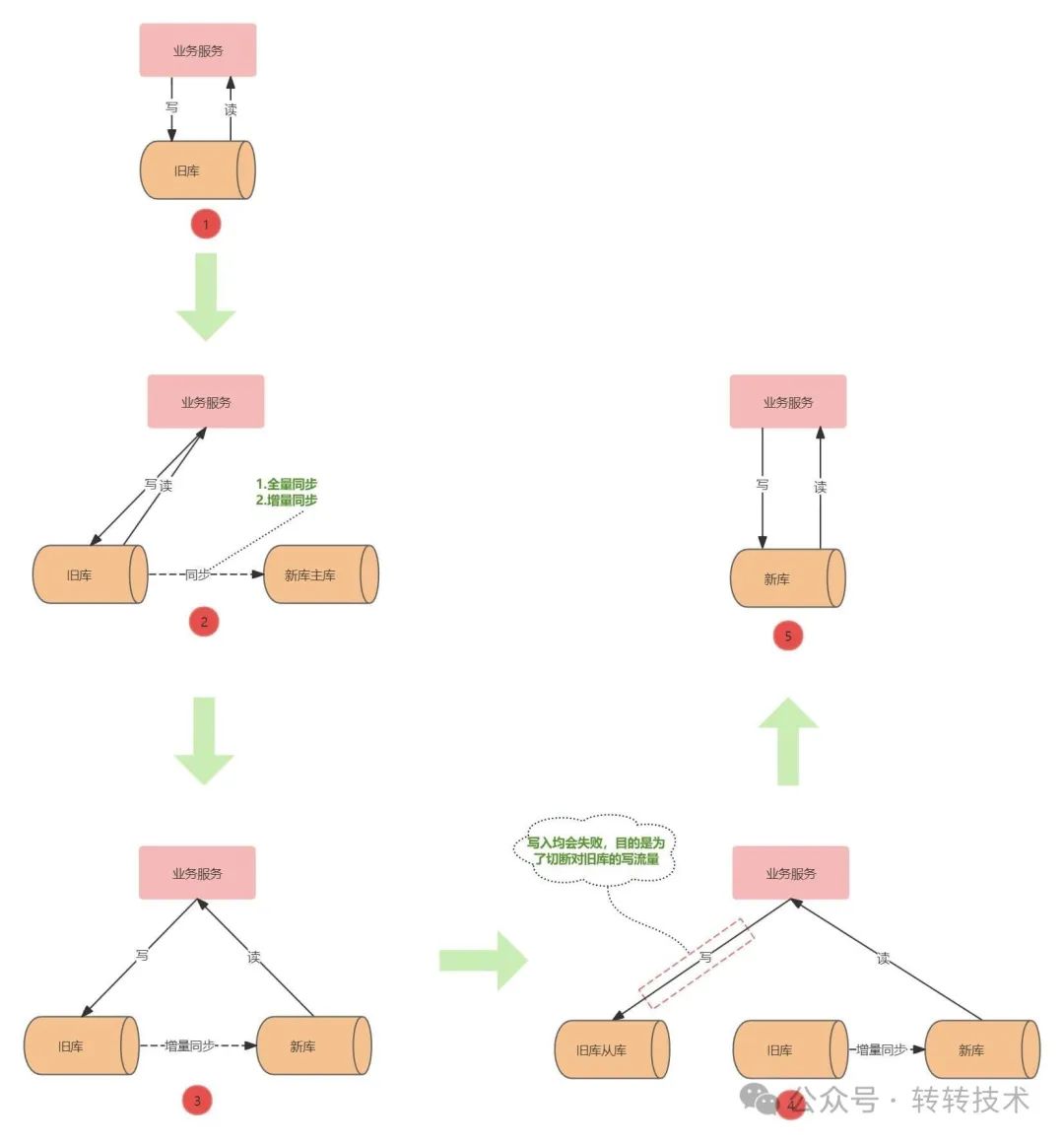
图-2
②新旧库数据同步:DBA协助先将旧库表数据迁移到新库,然后再使用增量同步工具把旧库表数据同步到新库。
③验证读新库:改造好的业务服务部署后,新库与旧库保持增量同步,开启读新库开关,读流量切换到新库进行验证,验证过程出现问题可以通过控制开关切回读旧库数据
④新旧库切换:整个切换流程的核心,改造好的业务服务上线。先切断对旧库的写入流量,让新库与旧库的增量同步追平,同时校验新库与旧库表数据的一致性,一致时便可把写流量切换到新库。
⑤代码清理:业务服务读写流量均切换到新库。
④为什么要把写流量切换到旧库的从库?
写流量切换到旧库的从库目的是为了断开对旧库相应表的写入流量,营造相对“静止”的环境让新库可以追上旧库。切断对旧库写入流量的方式有很多,选择写从库的方式来主要为了让开关都收拢到一处。
除此之外,我们可以对数据库帐号授权的形式来实现写流量的断开:
REVOKE INSERT, UPDATE, DELETE ON database_name.table_name FROM 'username';
从上述步骤中可以看到该方案有个硬伤:有短暂的停服过程。优点是确保迁移到新库的数据一定与旧库一致的,对有使用事务的场景,不需要考虑跨库事务,代码改造成本低。
3 迁移细节
我们要改造的业务服务代码中涉及声明式事务和编程式事务,为了降低跨库事务带来的改造成本,并结合上门履约的业务场景——业务数据写入多集中于白天,我们最终采用了“灰度开关切换新旧库”方案。
3.1 业务代码改造
需要迁移的表数量不多,实现时对DAO层代码进行改造,抽取ProxyDAO层,原来对DAO层的方法调用全部替换成ProxyDAO,ProxyDAO层代码植入开关控制代码,根据开关决定访问新库旧库。
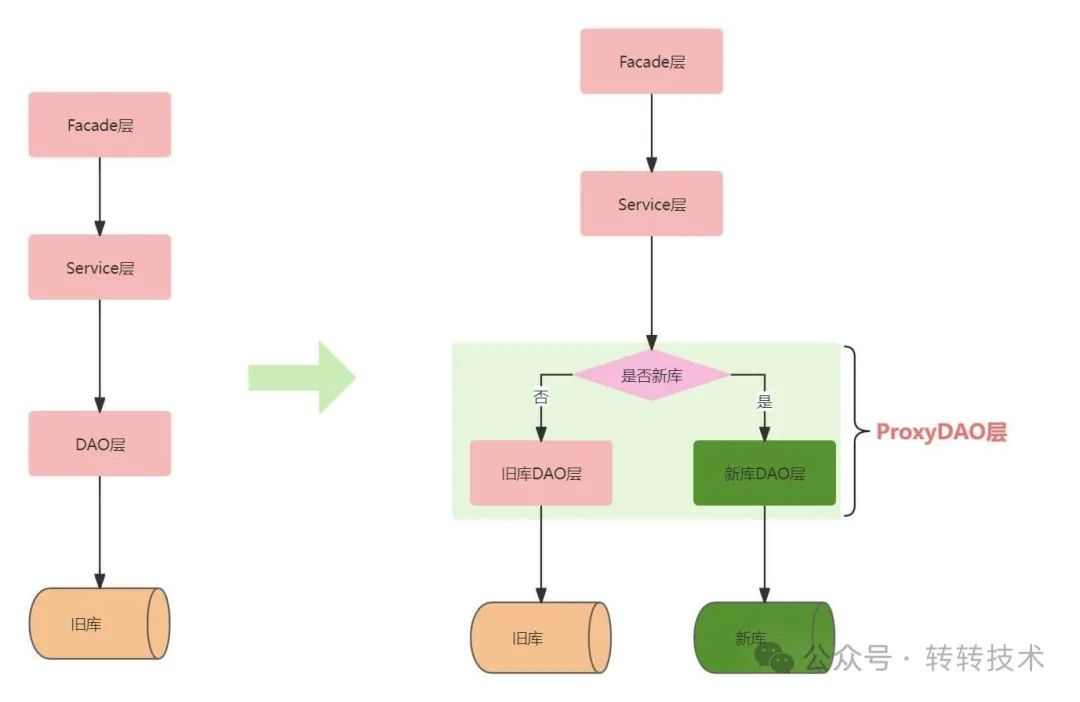
图-3
3.2 数据同步
创建好新库后,DBA将旧库需要迁移的表数据全量同步一次到新库,然后使用PingCAP的数据导入工具——Syncer,使用该工具进行数据增量同步需要满足以下前提:
5.5 < MySQL 版本 < 8.0
开启binlog,并且格式为ROW,且binlog_row_image必须设置为为FULL
从Syncer架构图不难看出:同步时Syncer把自己伪装成一个 MySQL Slave,和 MySQL Master 进行通信,然后不断读取 MySQL binlog,进行 binlog 事件解析,规则过滤和数据同步。
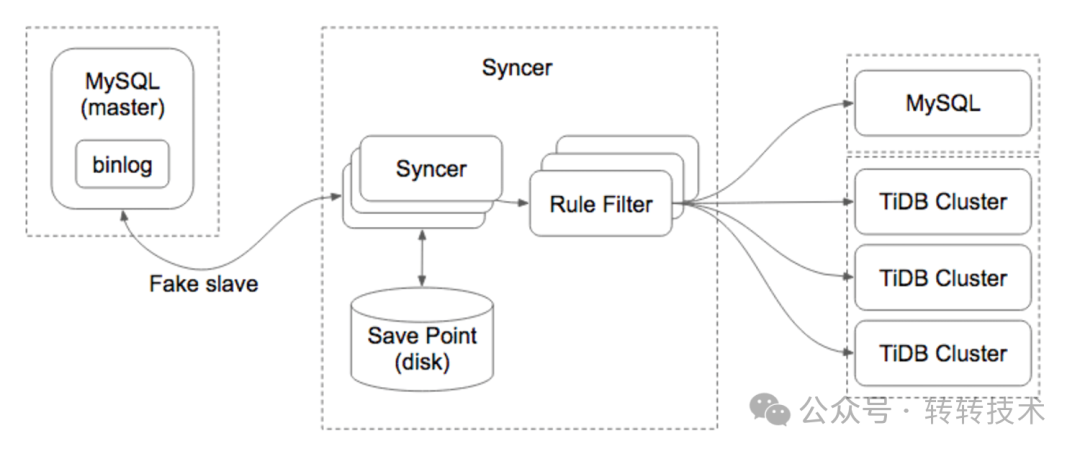
图-4
3.3 数据一致性校验
不管是双写还是灰度开关切换新旧库的方案,都绕不开数据一致性校验。数据不一致如何产生的?
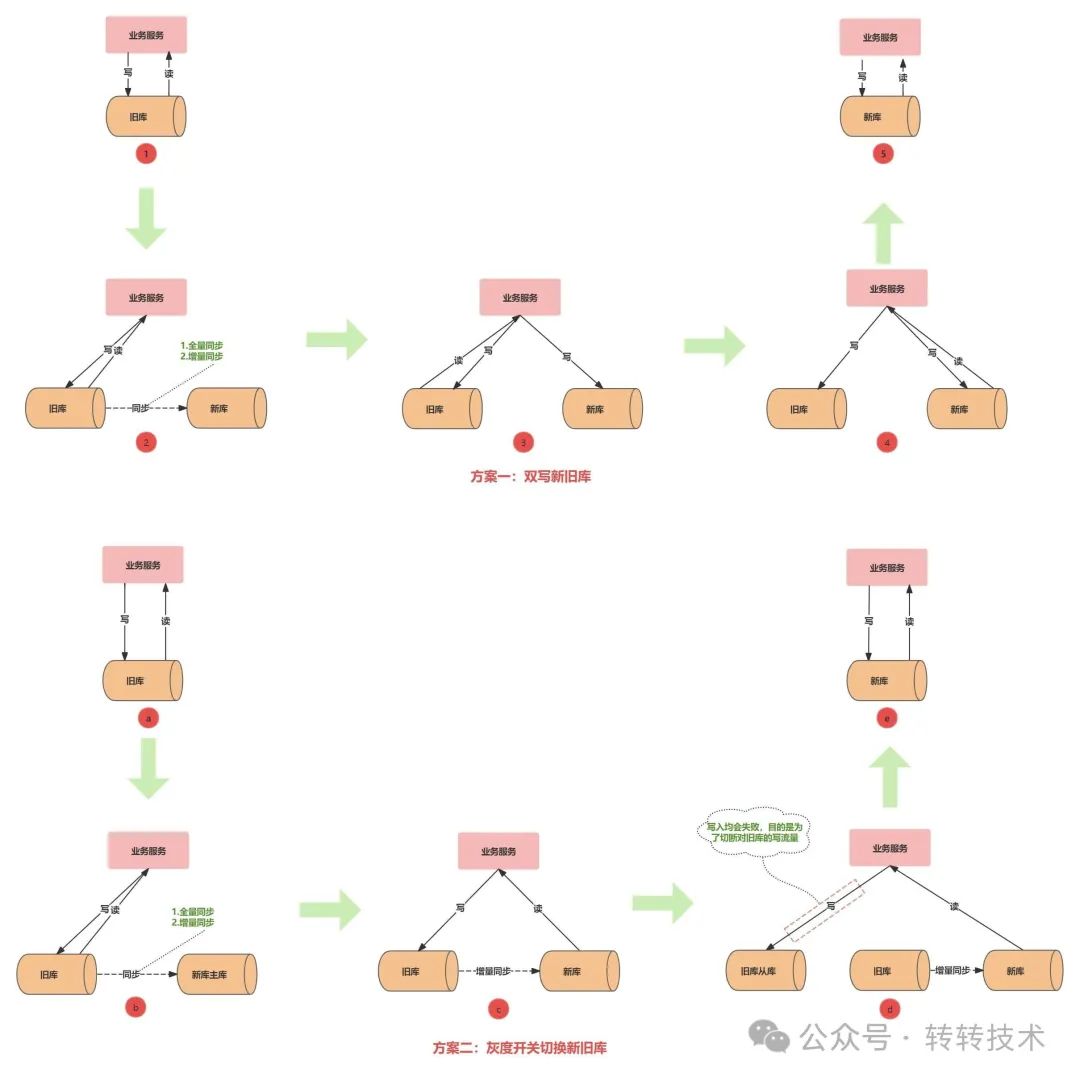
图-5
双写新旧库可能产生数据不一致的场景:
图-5③:DBA检测新旧库无差异后关闭同步,写新库开关未开启前旧库来了写入的流量
图-5③/④:双写后使用异步方式双写新库写入失败
灰度开关切换新旧库可能产生数据不一致的场景:
图-5c/d:数据同步工具挂了
我们所使用的迁移方案需要重点关注新旧库的同步情况,为此我们做了2层数据校验:
DBA在旧库写流量关闭后对数据进行一致性校验
业务服务写个定时任务定期去抽样校验
MySQL主从模式下可以通过show slave status 命令查看主从延迟情况,根据Seconds_Behind_Master的值是否为0来判定是否有延迟,有延迟2个库的数据肯定不一致。上面提到我们增量同步使用的是Syncer,它只是伪装成从库,并不是真正的从库,使用MySQL主从模式下数据一致性校验方法行不通了,因此借助了PingCAP官方提供的sync-diff-inspector工具进行数据一致性校验。
sync-diff-inspector工具架构图如下所示:
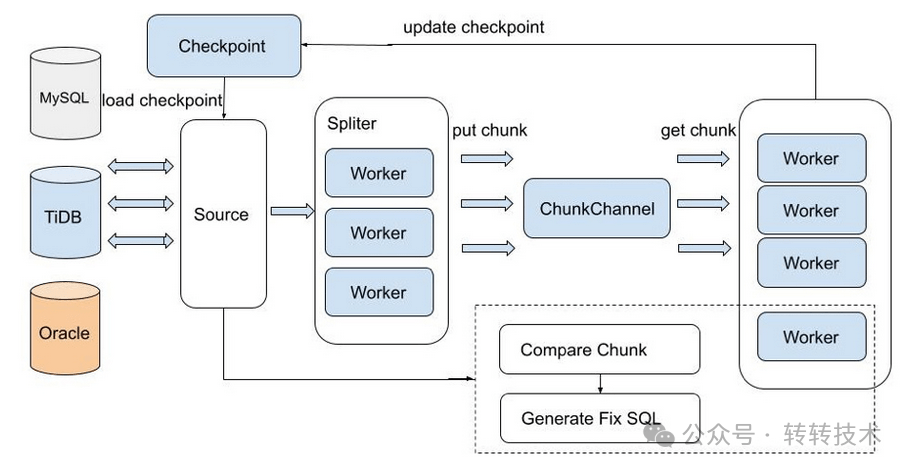
图-6
sync-diff-inspector校验流程主要分以下步骤:
对需要比较的表数据使用多线程方式划分为多个chunk,采用生产者-消费者模型将划分的chunk放入队列里
消费者线程从队列取出划分好的chunk,对这个chunk的上下游数据对比,计算出checksum
某个chunk的上下游checksum如果不一致,则对该chunk二分法方式找出不一致的数据,生成修复SQL
使用sync-diff-inspector工具对新旧库表全量校验后数据基本可以保障一致,不过该工具使用的前提是需要保证数据校验期间被校验的表上下游都没有数据写入。从校验工具的工作原理来看,校验耗时跟数据量成正比,迁移的数据越多校验时间越长,如果对全量数据的校验,校验周期会变得特别长。
根据目前业务现状,已经到终态的冷数据基本不会有写入操作。为尽可能缩短写入失败时间,业务数据校验的重点放在近期修改过的数据。冷数据不需要每次一致性校验时都参与进来。可以根据更新时间作为筛选条件,在新旧库抽取最近一段时间内修改过的数据,逐行对比数据是否一致,校验流程如下图所示:
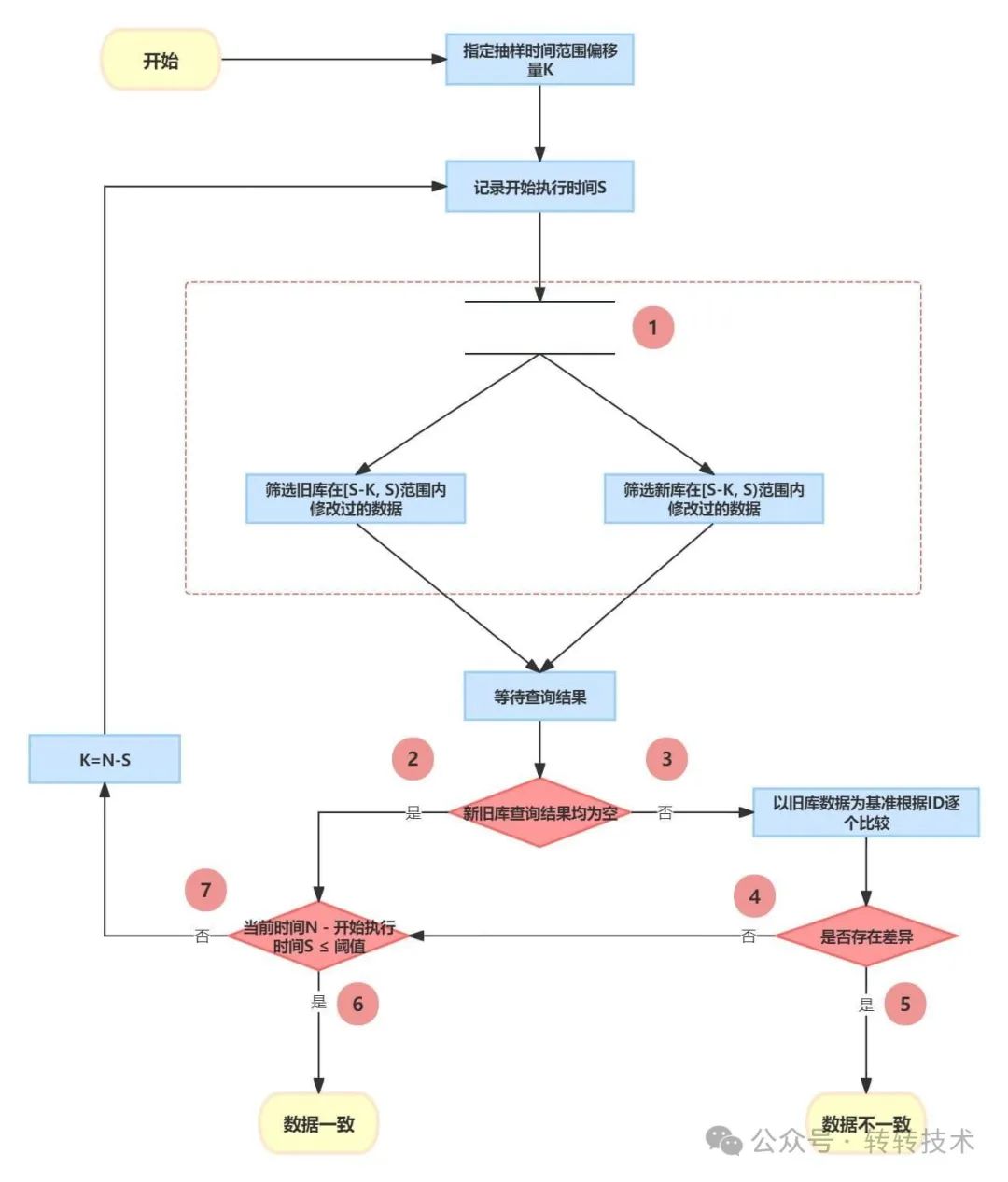
图-7
对旧库和新库按照更新时间筛选数据时,使用多线程并发的方式取数,尽可能减少时间差。根据更新时间筛选数据时,我们可能很自然的写出了下面的SQL:
select * from table where update_time >= X;
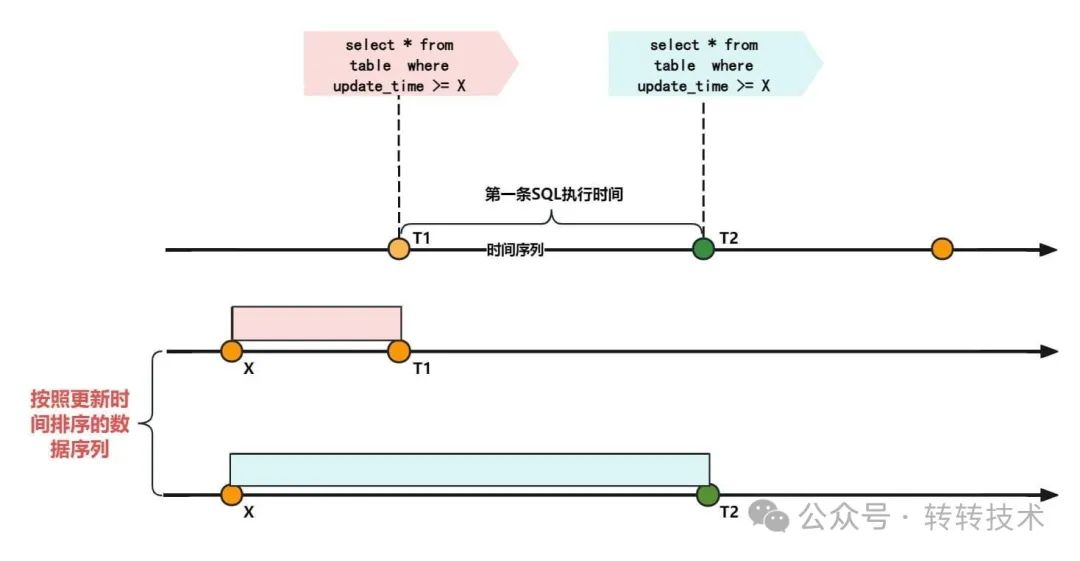
串行执行相同查询时序图
图-8
这个SQL如果使用单线程串行的方式执行,后面执行查出来的结果大概率会跟先执行的不一样。因为SQL筛选数据本身也会有耗时,特别是筛选时间范围比较大的时候,需要扫描更多的数据,耗费的时间越长。SQL筛选数据期间修改的数据,对先执行的SQL来说是不可见的。
校验时先对冷数据做一次全量校验,之后每次都是校验最近修改的,这样可以大大缩小查询范围,缩短校验数据一致性的时间。查询条件使用了上界和下界限定条件,保障了统计口径是一致的。校验代码消耗的时间,作为下一次迭代使用的时间偏移量,当“新旧库查询结果都为空”时表明最近都没有数据写入,并且N-S的时间差足够小,是可以认为两个库的表数据是一致的,这个时候把流量自动切换到新库可以实现平滑迁库。
N-S的时间差在什么量级?
初始时这个时间差会比较大,整个迭代过程中首次使用的更新时间筛选范围一般是最大的,除非一次取数时间加上程序校验时间的耗时比初始指定的偏移量K大。更新时间筛选范围会随着迭代越来越小,在写流量低峰期,SQL查出的数据也会越来越少,直至查不出数据。这个时间差差不多就是一条根据更新时间查数据的时间。如果更新时间是索引,查询的时间范围很小,N-S的时间差最优情况下是毫秒级的。
4 总结
最终我们采用保守的方式——旧库写流量切换从库,没有使用平滑切换的方案。以业务数据校验为主,DBA层数据校验为辅完成数据的迁移。整个过程读流量正常,写流量在切换到旧库从库 → 新旧库增量数据一致性校验 → 写流量切换到新库期间会失败,流量低谷期写入失败时间不超过5秒。
我们选择短暂停服的技术方案,这个方案虽然不是最优的,但是会跟业务更匹配,方案简单,改造成本低,对业务影响范围更小。技术方案的选择一定是贴合实际业务场景的,脱离业务场景的所谓更优方案不过是空中楼阁,当真正踏出登楼第一步时可能就坍塌了。
服务拆分&数据迁移对技术功底要求不那么高,并不需要使用高深的技术,更多的是考验一个人细心程度,对每个细节的深入思考与把控。失之毫厘,差之千里,一个细节没处理好,可能就会带来灾难性问题。
以上就是笔者在服务拆分库表迁移时的实践过程,大家还有什么好的平滑迁移库表数据的方法欢迎到评论区留言。

