多任务学习在转转搜索意图理解的实践
搜索是转转主要的流量分发入口,搜索场景覆盖了App首页搜索、App频道页搜索以及小程序搜索等各种服务入口。意图理解旨在准确地解读用户输入的搜索关键词背后的真正需求,对搜索体验的好坏至关重要。通过意图理解,搜索引擎可以调整搜索策略,提供与用户意图匹配的搜索结果,提高搜索结果的相关性和用户体验。此外,意图理解还可以帮助搜索引擎提供更多的个性化服务,如推荐相关内容、智能提示等,从而进一步提高搜索的效果和用户满意度。
意图理解简单来说就是从词法、句法、语义三个层面对 Query 进行结构化解析。在电商场景的首要问题是query的类目预测,例"iphone 15 pro 128 白色"的结构化类目为手机(类目)-苹果(品牌)-15 pro(型号)。转转的类目体系庞大、类目层级间存在关联,且query可能属于多个类目。转转的类目预测可理解为三个有关联性的任务。
本文主要介绍多任务学习在转转搜索意图理解的类目预测中的实践。首先介绍多任务学习的基本概念;其次介绍业界类目预测的方法;最后展示多任务学习在转转意图理解类目预测场景下的探索。
1 多任务学习简介
1.1 什么是多任务学习
多任务学习(MTL)机器学习中的一种学习范式,目的是利用包含在多个相关任务中有用的信息,以帮助提高所有任务的泛化性能。其核心思想是利用不同任务之间的共享表示来学习一个通用的特征提取器,从而实现知识的迁移和任务的协同优化。
MTL与机器学习的其他学习范式存在相关性,例如迁移学习(transfer learning)、多标签学习(multi-label learning)和多输出回归(multi-output regression)。多任务学习与迁移学习的设置相似但有显著差异;多任务学习不同任务没有区别,目标是提高所有任务的性能;而迁移学习是通过源任务来提高目标任务的性能。多标签学习和多输出回归每个数据都与多个labels相关联,这些labels可以是类别也可以是回归的数字;多标签学习和多输出回归是多个任务拥有相同的数据,但多任务学习不同的任务拥有的是不同的数据;如果把每个可能的标签作为一个任务,多标签学习和多输出回归某种意义上可以看作是多任务学习的一种特殊情况。多视图学习是机器学习的另一种范式,每个数据有多个视图,每个视图包含一组特征,尽管不同视图有不同特征,但所有视图被用于学习同一个任务,因此多视图学习属于具有多组特征的单任务学习。
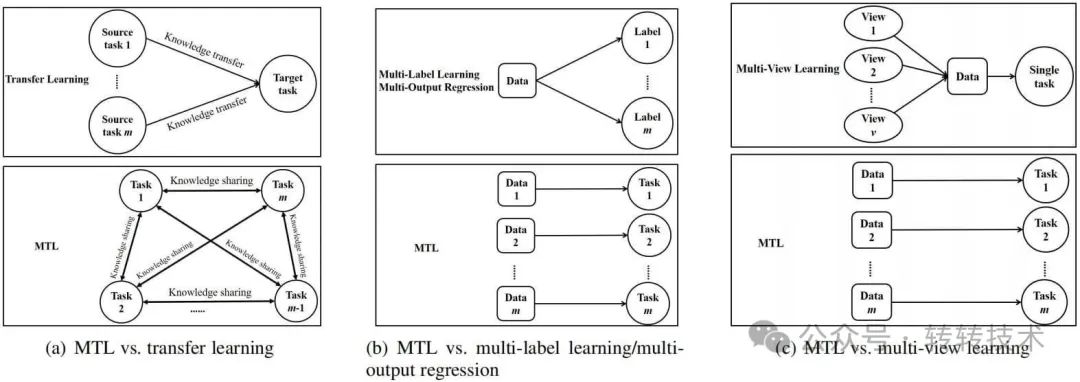
MTL与其他范式不同之处
多任务学习包含五种方法,特征学习方法、低秩方法、任务聚类方法、任务关联性学习方法和分解方法。这些方法的详细介绍可参考[1]。
1.2 NLP的多任务学习
近年来,在机器学习问题中,基于数据驱动的神经模型取得了巨大的成功。在自然语言处理(NLP)领域,引入transformer和预训练语言模型(PLMs)(如BERT、T5和GPT-3),在多个下游任务的性能上实现了巨大的突破。虽然预训练使得PLMs具备了通用的百科知识和语言知识,但在下游任务中使用PLMs仍然需要进行任务特定的适应。然而,充分训练这样的模型通常需要大量的标记训练样本,这在NLP任务中往往是昂贵的。随着神经模型的规模不断增大,训练它们需要巨大的计算能力,以及庞大的时间和存储预算。为了进一步提高模型性能,解决数据稀缺问题,并实现成本效益的任务适应,结合PLM和MTL的方法[2]被用于处理NLP任务。
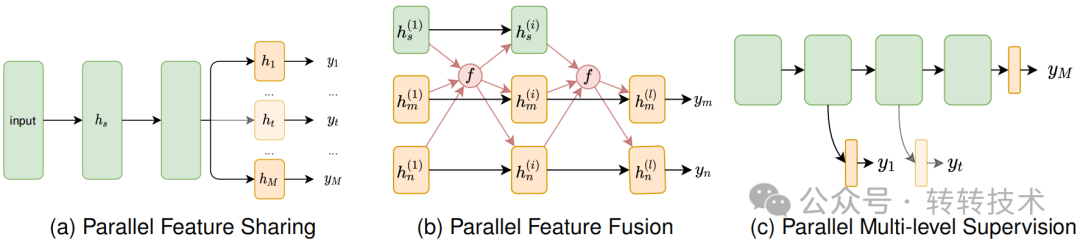
NLP的MTL-并行架构

NLP的MTL-层级架构
基于任务之间的关联性如何被利用,MTL架构可分为以下几类:并行架构、层级架构、模块化架构和生成对抗架构。并行架构将模型的大部分共享给多个任务,每个任务有自己的任务特定输出层。层级架构模型化了任务之间的层级关系。这种架构可以从不同任务中层级地组合特征,将一个任务的输出作为另一个任务的输入,或者明确地模型化任务之间的交互。模块化架构将整个模型分解为共享和任务特定的组件,分别学习任务不变和任务特定的特征。与上述三种架构不同,生成对抗架构借鉴了生成对抗网络的思想,以提高现有模型的能力。需要注意的是,不同类别之间的边界并不总是固定的,因此一个具体的模型可能适用于多个类别。尽管如此,这个分类体系可以阐明MTL架构设计背后的重要思想。NLP中多任务学习的架构和优化技术可参考[3]。
2 业界类目预测方法
意图理解在电商中扮演着不可或缺的角色,对于提升电商平台的竞争力和用户体验至关重要。这里的意图理解指狭义的类目预测(CP),其目标是识别给定文本的意图类别。
阿里[4]提出了一个深层次分类框架,将多尺度层级信息纳入神经网络中,并根据类别树引入了一种表示共享策略。作者还定义了一种新颖的联合损失函数,以惩罚层级预测损失。
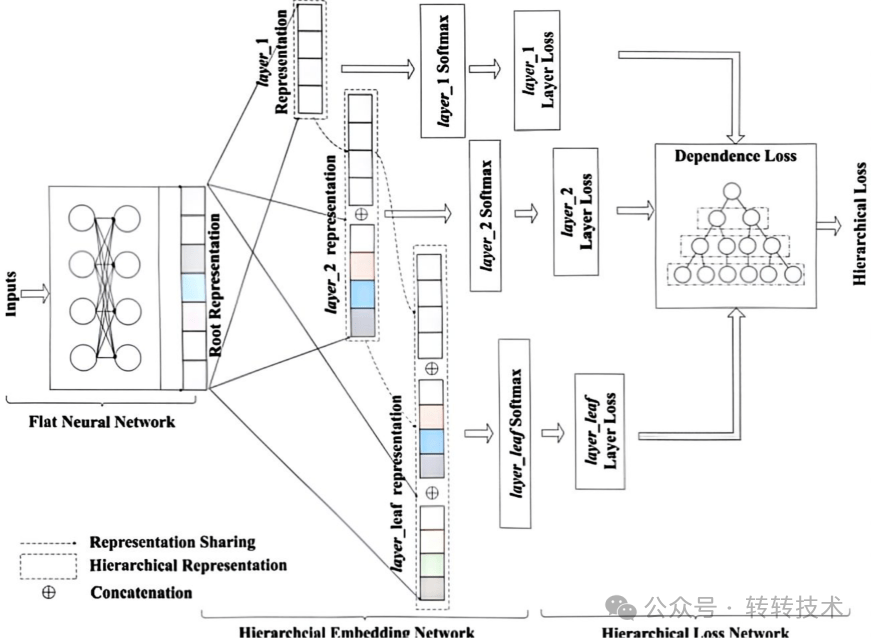
Deep Hierarchical Classification
美团[5]将意图识别分为两步,第一步是意图召回,这块是转换为了分类任务,只判断某个查询是否包含某种意图。线上采用词典匹配+规则+模型的方式进行识别,词典主要包含业务和领域相关数据,词典和Pattern规则,能比较好的解决热门识别,针对长尾部分,主要靠Bert模型来解决泛化识别问题;第二步是意图分布,意图召回完了以后,作者还要知道当前搜索的各个意图的强弱,尤其是找到主意图,就是图上面部分的意图分布,作者将其转化成排序问题。由于线上展示的每条POI结果,后台都有明确的业务归属,所以作者就可以依据这个业务归属信息和用户点击行为,获得有标注的训练语料,来训练排序模型。模型特征主要分为两部分,一是统计类的特征,包括一些CTR、CVR及相关的用户行为的特征。二是Embedding类特征,进行语义的表达。
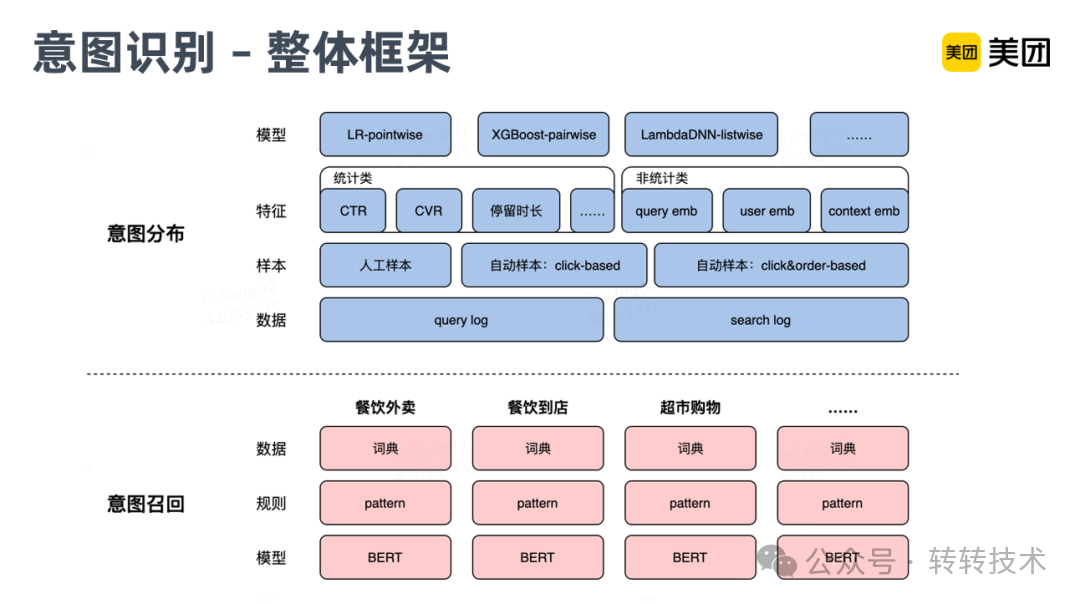
美团意图识别
京东到家[6]在搜索品类预测场景下主要尝试的方法有两种,一类是直接采用层级性多标签分类,第二类是采用语义模型,结合用户点击,订单,成交等特征进行融合模型拟合出对应不同品类的得分取topN作为预测的品类倾向。
京东意图识别
3 多任务学习在转转的实践
转转平台致力于促进低碳循环经济的更好发展,能够覆盖全品类商品。在N品类第二曲线背景下,我们需要在保证手机3C领域效果的同时,提升N品类的搜索体验。
3.1 多任务学习在类目预测的实践
转转的类目预测包含类目、品牌和型号三个层级。我们数据存在如下特点:(1)不同类目数据不均衡。(2)层次不一致: 有些query到类目,例手机、平板和吉他;有些query到品牌,例华为手机和卡西欧手表;有些query到型号,例realmegt大师骁龙778和airpods pro 二代。(3)类别巨大:品牌有上千个,型号有上万个。考虑到数据特点,我们从数据采样、技术选型和训练技巧三个层面通过组合拳提升类目预测效果。
我们基于优势品类降采样和弱势品类重采样的方式弥补数据不均衡问题,例如手机类目采样50%,4类目采样80%,N类目重采样200%。我们将类目预测转换为类目、品牌和型号三个任务,缓解某任务空标签占比较高的情况。我们使用分类解决类别较少的任务,类别较多的任务用文本匹配做,也即类目和品牌使用分类、型号使用匹配。
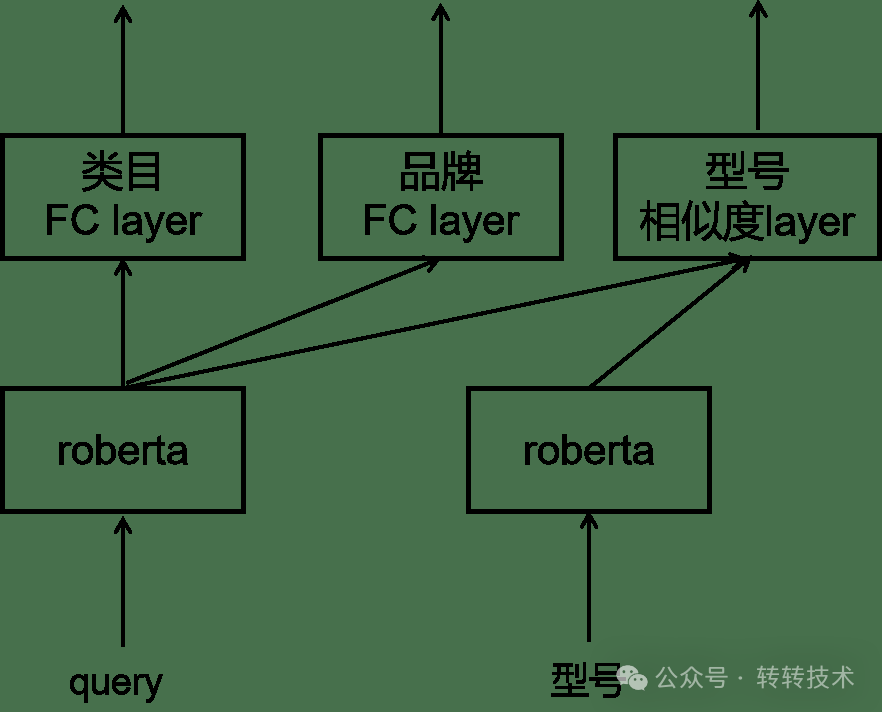
技术选型
对于类目和品牌分类任务,我们使用roberta[7]产出query文本向量后接全连接层获取类别得分;对于型号匹配任务,我们使用roberta孪生网络分别产出query和型号的文本向量再计算出相似度得分。分类模型使用交叉熵损失函数,匹配模型使用对比学习SimCSE[8]损失函数, MTL的loss使用三个任务loss的加权和。
我们利用多任务学习提升模型性能、增强泛化能力、提高数据效率,并促进知识迁移和跨任务学习的优势,应用到意图理解给线上带来下单提袋率的提升。
3.2 多任务学习在转转的未来规划
通过人工评估以及线上AB实验,充分确认了多任务学习训练多个相关任务的有效性,在类目预测模块落地后,可以用于意图理解其他模块,例命名实体识别。召回模块的向量召回或es召回都用到了文本的特征,也可以将多任务学习用于召回模块。

