转转搭建平台——魔方数据中心实战分享
写在前面
魔方是转转内部的可视化搭建平台,用于快速创建活动页面。然而,尽管平台相对稳定,却缺乏一个集中的数据中心来全面查看各项数据指标,给运营团队带来了一些挑战。
接下来用一张图带大家走进魔方的世界:
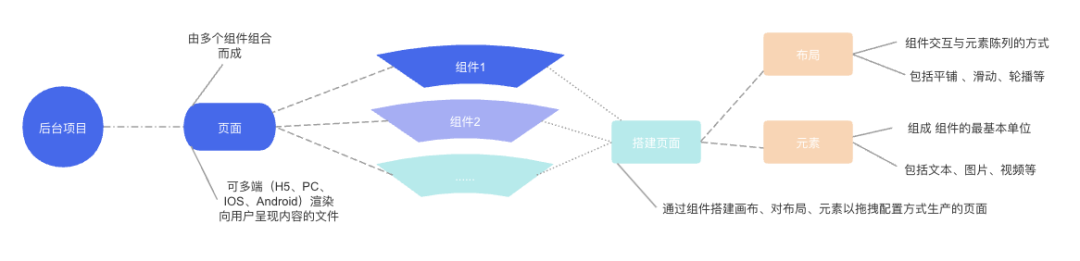
魔方搭建设计图
相信通过这张图,大家已经初步领略了魔方平台的内部工作机制。当然,这只是一个序幕,魔方的数据“视界”还有更多深度和细节等待我们去发掘。
现在,邀请大家继续跟随我,深入探索魔方所构建的数据“视界”。在这里,数据不再是冰冷的数字,而是辅助运营、提升效率的源泉。
那么,一听到“魔方数据中心”,我们自然会想到与数据相关的诸多问题:
这些数据是什么?
这些数据源自何处?
数据被用于哪些方面?
而数据的积累又将为我们带来什么样的收益?
希望大家能够带着这些问题继续阅读后续内容。
一、项目背景
截至2024年,魔方已成功支持了上万个专题和几十个组件,涵盖了B2C、C2B、平台、商业、风控等多个业务方向。然而,由于缺乏完整的数据链,我们无法验证专题或组件的效果,也无法为运营团队提供有力的数据支持,以优化搭建方向。此外,分散在多个数据平台上的数据查看也增加了运营过程中的不便。
数据缺少:无法获取关键数据,如订单转化、停留时长、找靓机专题流量、坑位流量等。
多个数据平台不统一:目前存在三个数据平台,运营需要在这些平台上查找数据,导致操作繁琐且不统一。
二、目标
目标是建立一个统一的魔方数据中心,满足运营团队对现有数据平台的需求,并让魔方脱离对zeye-转转之眼(基于数据表的元信息做数据个性化分析展示的报表工具)和高斯自助分析平台(高斯产品集埋点元数据管理+自助分析功能于一身,致力于解决从产生埋点数据至消费埋点数据的全流程)的依赖,
简化运营查看数据的过程。通过分析PV、UV、点击率等指标,将深入了解现有专题、组件数据和大促数据,为运营团队提供更好的专题搭建支持。
三、方案设计
1. 出发点
从运营角度出发,提升页面搭建效率,需解决的核心问题有:
如何完善关键数据指标,减少运营各方收集数据的困扰;
如何将不同平台数据统一,减少搭建时的学习成本和耗时;
正是基于这些深刻的洞察,魔方数据中心的概念应运而生。它不仅代表着一个创新的解决方案,更是我们对运营流程优化承诺的体现。
2. 核心设计思想
本着充分利用现有资源的目的,以及保持用户的使用习惯,通过:
ZEYE-转转之眼 + 高斯自助分析平台 + 中后台设计规范
即可为运营打造兼顾效率和灵活性的数据分析,下图是传统楼层搭建方式与本方案的对比,可以看出直接可以减少2步,查看效率显著提升。
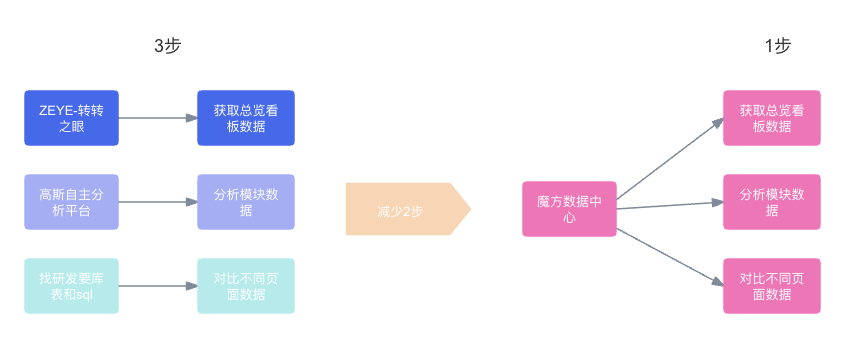
新旧数据查看对比图
3. 核心架构
本系统提供的核心能力包括:
专题总览看板: 查看所有专题的整体数据,获取关键指标和总体趋势的概览。
专题详情看板: 针对特定专题,观察不同时间段内不同组合指标的变化趋势,深入了解专题内部的数据变化。
专题对比模块: 比较不同专题在相同时间段内的同比或环比数据,帮助你发现不同专题之间的差异和趋势。
组件区域看板: 分析单个专题的分区域数据、分业务数据、分品类数据等,以区域为维度展示数据,助力你了解专题在不同区域的表现。
组件热度看板: 查看一段时间内组件的使用次数,了解组件的热度排名和趋势。
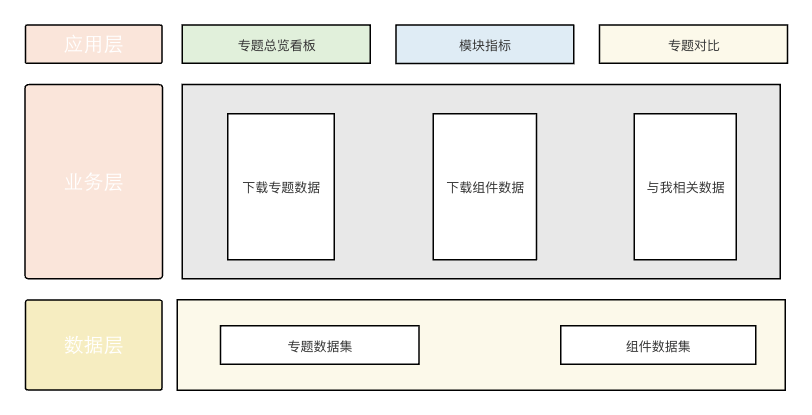
整体架构图
四、核心解决方案
1. 数据处理
相信每个公司都有自己的数据集,通过业务日志、埋点日志等对数据进行处理、存储、应用等等,最终呈现在用户面前。
相同的,转转也有自己的数据集,根据不同的业务大数据可以生成不同的数据集,最终暴露成scf或者http的接口,供业务方调用。但是因为涉及的业务方太多,所以返回的格式相对固定。
为了满足后台规范需要对获取的大数据接口进行数据格式转换,来生成后台所需要的数据格式。
格式转换:
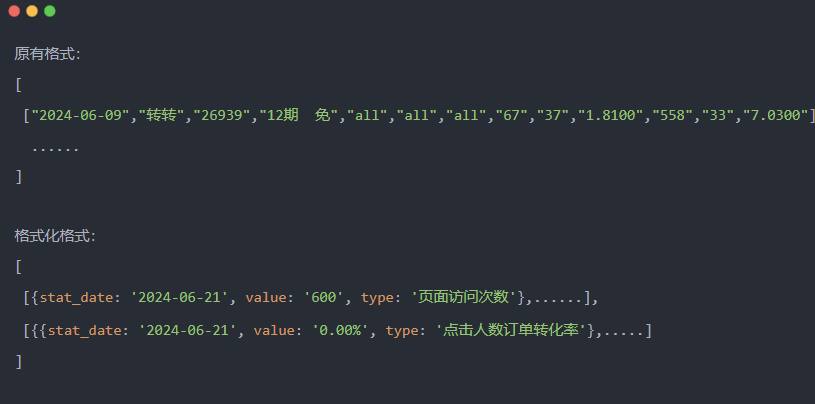
数据处理图:
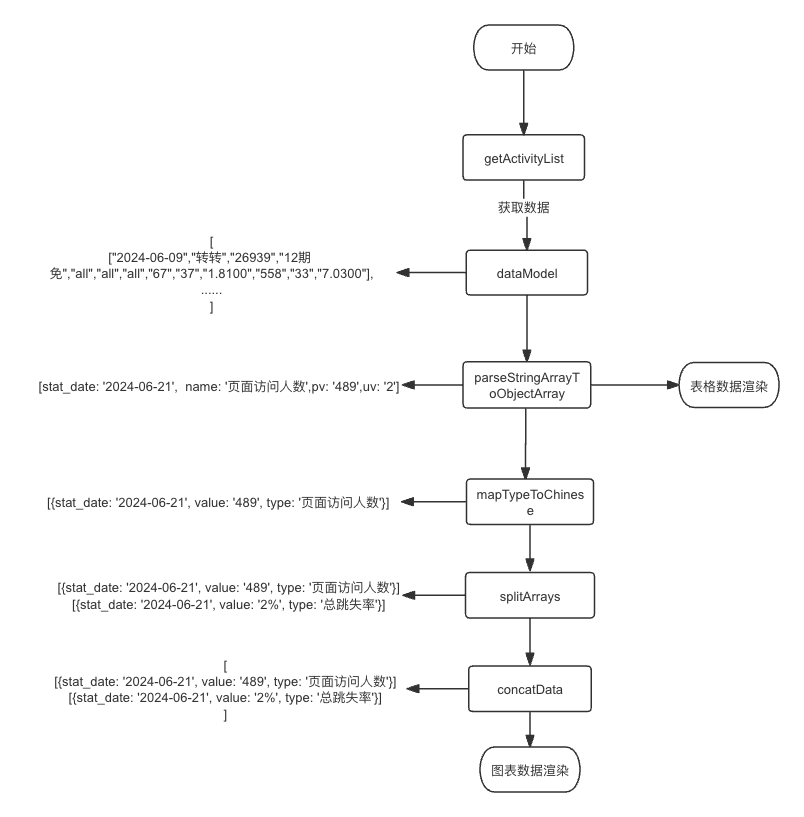
数据处理图
将dataModel作为全局共享数据,以方便其他组件获取和处理数据。
在数据处理阶段,首先对整个数据进行平铺处理,以辅助后续操作。
使用逐步更新数据的不同方法,以避免数据之间的过多耦合,从而防止混乱的出现。
核心代码:
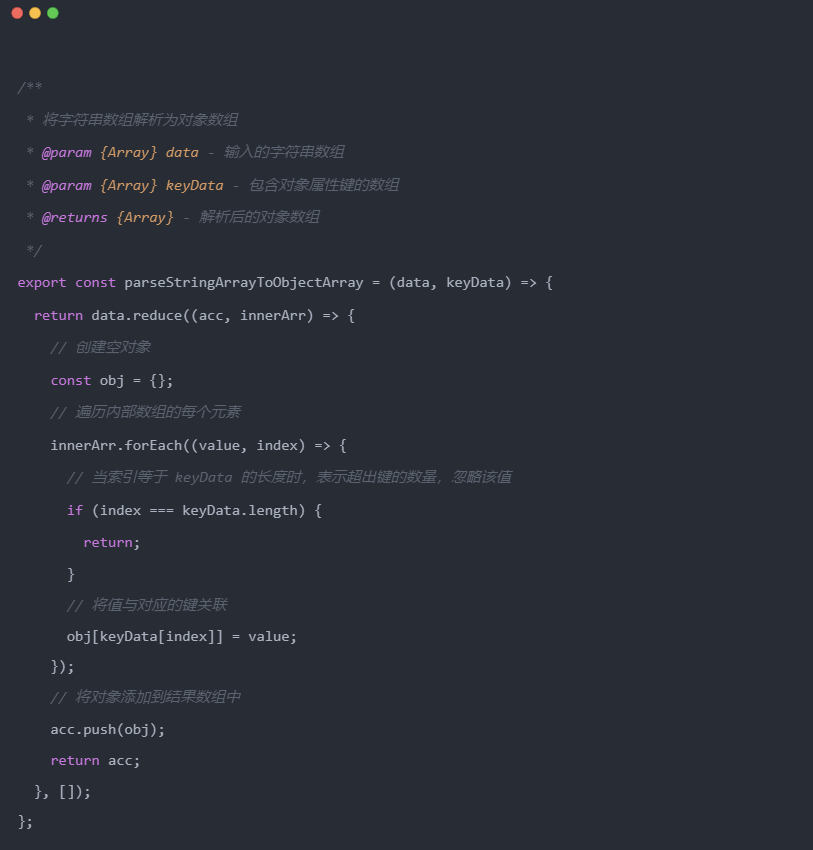
二次封装
当然为了让运营更迅速的找到自己负责的专题,需要提供个性化的专题数据筛选功能。,但是由于魔方本身的库表(MongoDB)和大数据的库表(mySql)不是一套,所以需要结合重新封装生成一个Node接口
大家都知道写一个Node接口需要清楚一些模块功能,这里只是简单的描述一下,不过多赘述,如果不清楚的话可以去看以下Node官网
Controller(控制器):负责处理路由请求和响应。它接收来自客户端的请求,调用 Service 层处理业务逻辑,并将响应返回给客户端。常见的控制器模块包括 Express.js 的路由处理函数。
Model(模型):用于定义数据模型和进行数据操作。它通常与数据库交互,提供了对数据的增删改查等操作。常见的模型模块包括 Mongoose(用于 MongoDB)或 Sequelize(用于关系型数据库)等。
Service(服务):包含业务逻辑的处理。它封装了对数据的操作和其他处理,提供了更高层次的抽象,供控制器调用。在 Service 中,您可以执行数据验证、数据转换、调用外部 API 等操作,以满足接口的业务需求。
了解了这些以后,可以开始写一个获取数据的查询接口,以下是数据处理流图
service层数据处理流:
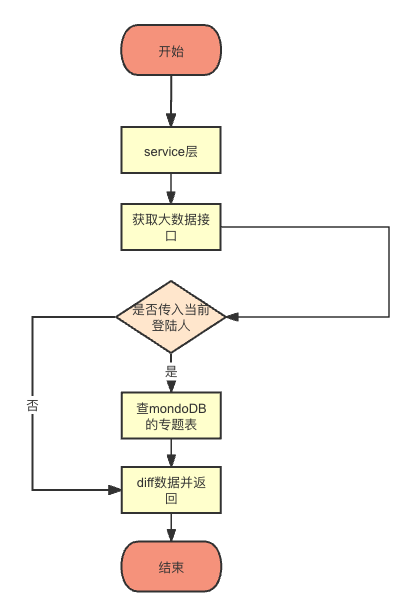
service层数据处理图
仅仅拥有数据是不够的,对于运营团队而言,他们并不会直接通过SQL查询数据库来获取数据。因此,我们需要提供一种直观清晰的方式,让运营团队轻松获取所需的专题数据,比如通过表格或图表的形式呈现。
进而就有了指标切换器
2. 指标切换器
为了更好地分析当前已有的数据,需要支持运营组合数据的查看和自选数据的对比。这样,才能根据特定需求选择和组合所需的指标,获得准确和有针对性的分析结果。
特点:
智能分类指标: 将指标分为两类,推荐指标和自选指标,以满足不同需求的分析要求。
灵活选择: 每次可以选择三个指标进行比较,当选择第四个指标时,系统会智能取消勾选前面三个指标中的第一个,帮助保持选择的指标数量。
图表多样性: 根据数据类型进行展示优化,百分比数据将以折线图形式展示,而其他数据则以柱状图形式展示,能更清晰地理解数据变化趋势。
自由切换: 可以根据需要自由切换表格和图表的展示方式,以便更直观地观察和分析数据。
交互处理流:
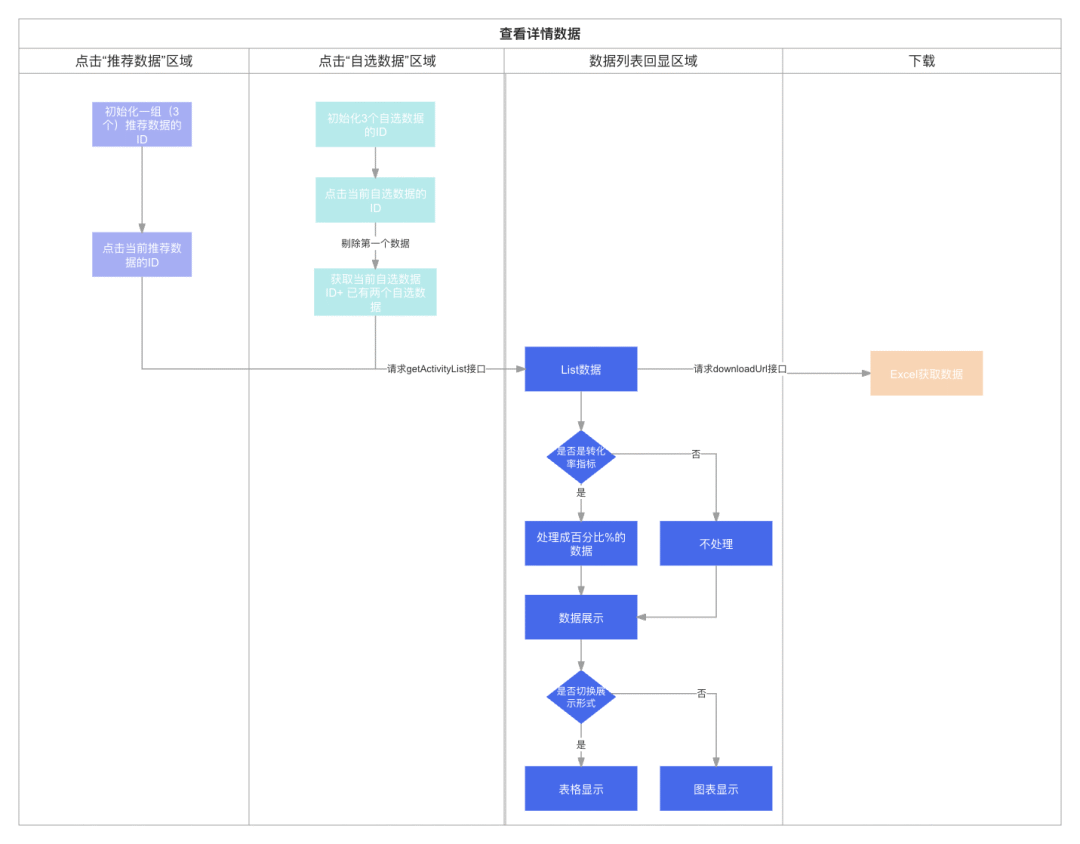
交互处理流图
核心代码:
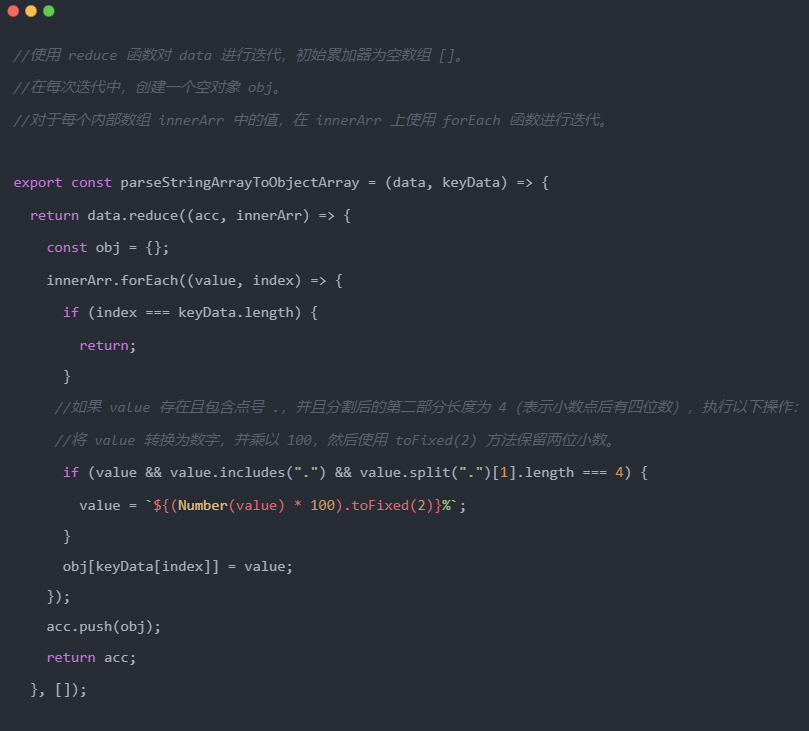
最终,通过魔方数据中心项目的实施,我们成功实现了以下预期目标:
简化流程: 通过Node.js接口集成,减少运营人员在多个平台上的数据查看负担。
模块化数据: 提供易于分析的模块化数据,支持产品分析人员进行深入洞察。
图表展示: 利用图表化手段增强数据的直观性和易理解性,辅助决策制定。
统一管理: 通过Node.js接口实现数据的统一处理和存储,提高数据管理的效率和一致性。
写在最后
作为一名开发人员,我有幸通过魔方数据中心的经历,亲身体会了从产品方案落地、开发、自测到上线的完整过程。这一过程让我更加深入地理解了用户需求,对我个人而言也是一种成长的机会。

