一 背景
近两年云厂商的机房事故时有发生,如何在各种事故发生时保持业务平稳运行,是大部分互联网公司必须面对的问题,不过既然是普遍的问题,那必然已经有了很多成熟的方案,如同城双活、两地三中心、异地多活等,这些方案已经有很多文章进行介绍,这里就不赘述了,大家感兴趣可以自行搜索一下。这些方案随着解决问题的程度不断加深,其复杂度也会不断增加,边际效应也在不断减少。我们需要根据企业的现状和规模选择合适方案,并根据企业实际情况进行适当优化和本地化适配,不应追求最完美的方案,而是应当寻找最合适的方案。
在货拉拉,我们综合各方面考虑定下了以下目标:
需要支持同城多可用区高可用,当发生可用区故障时,我们应当可以在30分钟内恢复
架构带来的额外IT成本应当控制在总IT成本的5%
根据以上目标,我们结合业内成熟方案和公司实际情况演变出适合货拉拉的跨可用区高可用架构-多泳道架构。
二 多泳道介绍
多泳道架构是一种将业务请求流量调度到目标AZ(即:可用区,一个数据中心region一般会包含多个物理AZ机房,AZ机房之间距离一般十几公里或几十公里不等),并且单个业务请求的后端处理过程会在单个AZ内闭环的基础系统架构。我们内部简称“多泳道架构”,每个AZ表示一个“泳道”,每一个“泳道”都部署了完整的业务链路服务,所以每一个“泳道”都能处理所有业务功能。整个货拉拉系统由N个泳道组成,单个“泳道”承担着1/N流量负载,当某个AZ发生机房硬件故障或者核心业务服务故障时,我们可以在分钟级时间内将这1/N流量切到其他泳道里,从而达到故障隔离(AZ容灾)的效果。
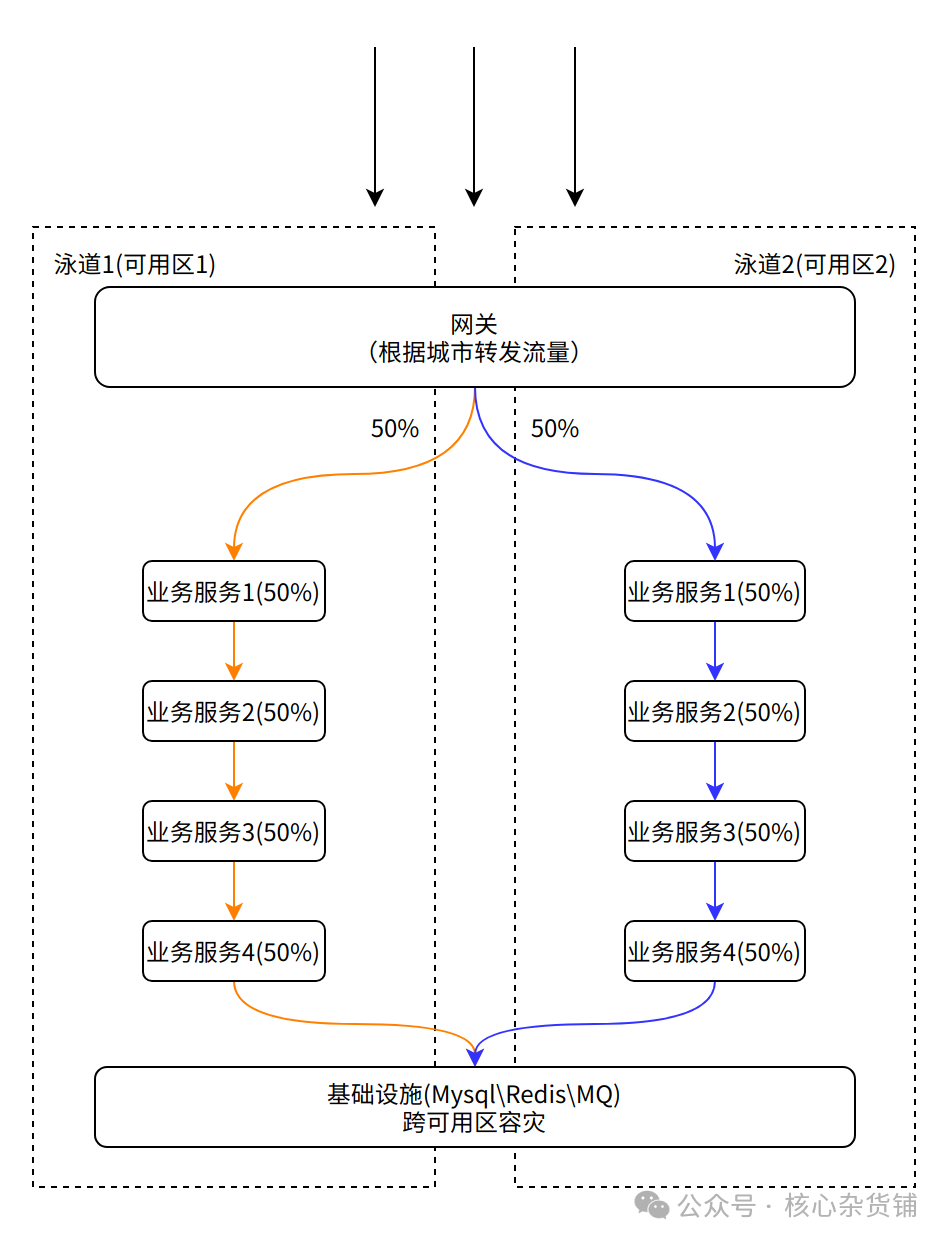
接下来对多泳道架构的几个关键点做一下详细说明。
2.1 应用部署
我们在每个泳道都部署了完整的业务链路,可以做到单个泳道可以处理完整的业务流程,但是由于我们的成本预算只有5%,所以我们没有在每个泳道部署100%的实例,而是在两个泳道各部署50%的实例,这样成本几乎没有增加,但是这样做的代价就是单个泳道无法处理100%的流量,当发生单泳道故障时,我们需要对另外一个泳道进行扩容,为此我们最大程度的优化扩容流程,做到一键扩容,但由于涉及服务器众多,所以扩容仍然需要30分钟。
2.2 服务注册与发现
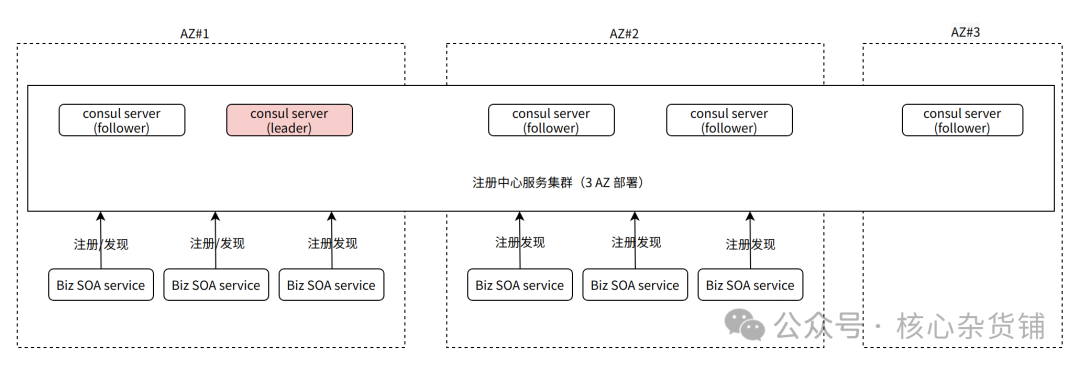
注册中心我们用的是Consul,由于Consul有完善的跨可用区高可用架构方案,所以我们采用跨可用区高可用的单一Consul注册中心集群来为所有泳道提供服务,整个Consul集群有5个server节点,横跨三个可用区,任何一个可用区故障,Consul都能自动感知并切主,自动恢复正常。所有泳道里的应用服务都依赖同一个注册中心,相比于传统SOA的默认设计,货拉拉SOA服务在注册时会额外写入服务实例的AZ meta数据,用于表示当前实例位于哪个泳道,注册中心维护了全局的服务状态信息。
2.3 配置中心
在配置层面我们考虑到两个泳道的服务由于是一样的服务,所以肯定存在相同的配置,同时又由于两个泳道的性能差异以及应急过程中可能需要对某个泳道单独更改配置,所以希望配置中心可以支持两个泳道既能共享一样的配置,又能根据实际情况单独设置不同的配置。出于这个目的,我们制定了以下这套方案。
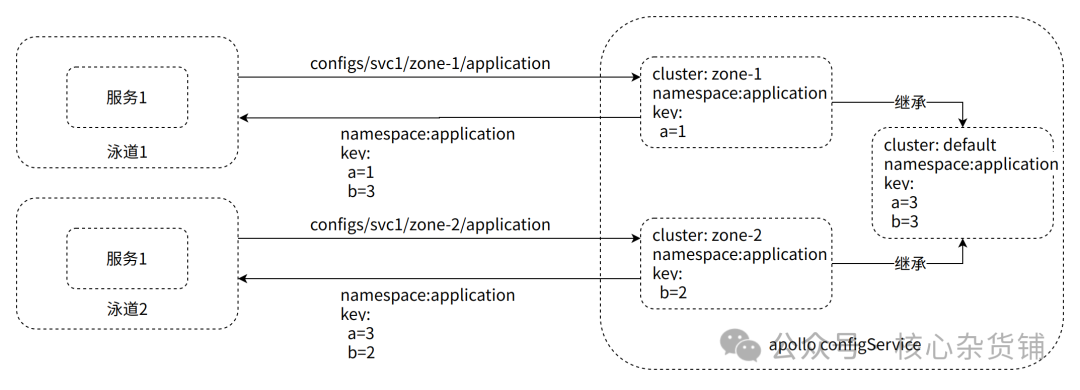
配置中心我们用的是Apollo,服务的配置信息在Apollo中对应的设计是集群(Cluster)概念,每一个泳道均对应着一个集群,所有的集群均继承于Default集群。当创建多泳道时,我们会为对应的服务创建在配置中心里面对应的集群。
业务启动时,Apollo SDK将会读取环境信息,如果部署在多泳道中,将会读取到泳道信息,并组成请求配置的URL(configs/appid/cluster/namespace)。
Apollo 配置中心收到请求后,将根据业务请求的url参数查询对应的cluster配置信息,再继续查询default的cluster,然后对每个配置项做覆盖逻辑处理(指定的cluster配置优先),从上图可以看到,服务1去获取zone-1 cluster的application配置时,zone-1本身已经有a=1的配置,但由于没有b的配置,所以b会从default获取,最后返回给服务的配置就是a=1和b=3
这里我们对Apollo做了二次开发,在Apollo原来的逻辑中只能做到整个ns的继承,也就是只有当对应cluster下没有对应namespace时,Apollo才会引用default cluster下的namespace,而我们的二次开发则是将这个机制从namespace层面改为key层面,这样会更加灵活。
2.4 基础设施
在多泳道架构中,考虑到同城的可用区延迟较低,我们对于Mysql、RabbitMQ、ES、Redis等基础设施并没有做特殊的定制化方案,全部都是采用组件自身成熟的跨可用区高可用方案,云上组件则使用云厂商的跨可用区高可用方案, 例如Mysql的主备架构、RabbitMQ的镜像模式等,这里篇幅有限不再赘述,大家有兴趣可以查阅相关资料。
2.5 流量调度
系统分成多个泳道后,我们首要问题就是要解决流量调度的问题,流量主要分两种,外网流量和内网流量。
2.5.1 外网流量调度
外网流量调度关键在于如何将流量均匀的调度到两个泳道,关于这个问题业界主要有两种方案:
第一种是基于DNS的调度,将两个集群的入口IP挂到同一个域名下让DNS随机解析,这个方案是最简单的,但是没什么扩展性。
第二种就是将流量全部解析到统一的网关,由网关来统一调度,将流量均匀分发到所有泳道,这个方案会相对复杂一些,并且流量会多经过一个网关,但是好处是可扩展性强,可以方便的定制各种分发策略和应急措施。
虽然还有其他做法,但是本质上还是基于以上两种变化而来。
在货拉拉的业务场景下,我们主要是做车货匹配,我们的业务场景是需要用户+司机+平台三方参与,所以我们需要做到能将同一个物理区域内的司机和用户的流量转发到同一个泳道,这是无法通过DNS解析这种简单的方式来实现的,所以我们最终选择采用网关+定制分发策略的方式来实现多泳道流量调度。
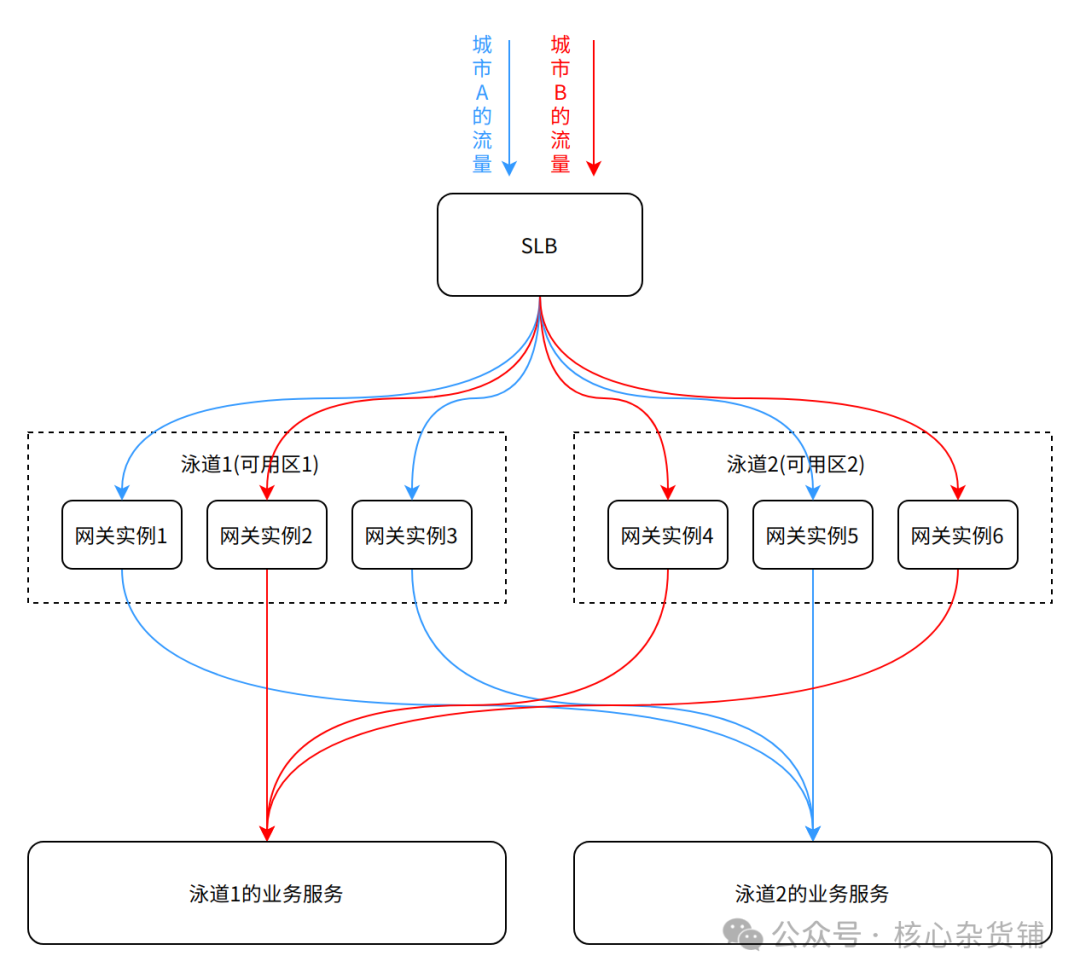
从上面这个图可以看到,我们在两个泳道前面放置了一个网关,网关本身也是跨可用区部署,外部流量进入网关后,网关会根据流量的来源城市将流量转发到特定的泳道,从而实现流量调度的功能。
2.5.2 内网流量调度
内网流量调度的主要目的是让单个请求尽量可以在单个泳道内闭环处理,这样一方面可以降低泳道间的互相影响,另一方面可以极大的降低跨可用区调用带来的时延。
内网流量要比外网流量复杂得多,想要做好内网流量的治理,我们需要对内网流量有清晰的认识,通常一个请求进入系统后,完整的处理链路大概会包含以下环节:
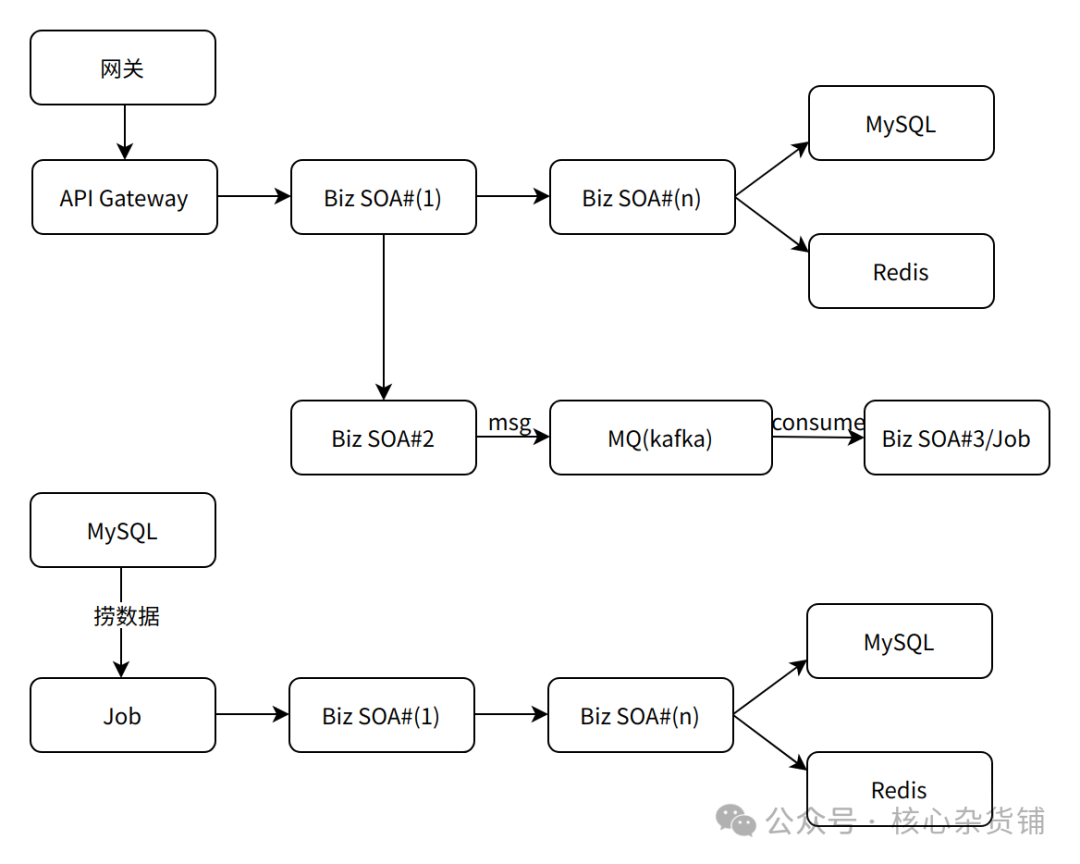
请求处理链路主要包含3类服务调用类型:系统同步RPC/HTTP调用、异步消息、Job主动触发的请求,请求在单个泳道内闭环处理的设计措施有:
网关将流量转发到API Gateway时,会透传流量标识到目标AZ的API Gateway
API Gateway继续透传流量标识到下游SOA服务,Gateway默认会调用同AZ的SOA服务
SOA服务之间的RPC调用继续透传流量标识到下游SOA服务,RPC调用会默认调用同AZ的下游SOA服务
SOA服务写消息到消息队列时,会将流量标识写入消息头,consumer服务会读取到流量标识并透传流量标识到下游SOA服务,但是这里我们没有做到让consumer只消费同AZ的消息,所以会存在跨泳道调用的情况
Job在主动发起RPC调用时,会通过Job服务所属AZ获得流量标识并透传到下游服务
三 与同城双活的不同之处
在大家看完多泳道架构的介绍后可能会觉得跟同城双活很像,这里再说一下多泳道架构与同城双活的不同之处:
部署方式:同城双活在两个可用区都部署了100%的服务实例,但多泳道架构出于成本考虑,每个可用区只部署了50%的实例。
数据库:同城双活会在可用区各部署一整套完整的数据库,可用区之间再实现数据同步,而多泳道架构没有实现这个复杂的机制,仅靠数据库本身的高可用方案,也就是数据库的主库只存在于其中一个泳道,从库在其他泳道,这个优点就是实现简单,不需要解决因数据库双向复制带来的复杂问题,缺点就是访问数据库存在跨可用区的情况,这样一方面会增加请求的RT,另一方面发生故障时,数据库在切主的过程中也会导致服务出现抖动。
同城双活一般是只有两个可用区,而多泳道架构支持N个泳道,扩展性更强。
四 总结
以上就是本次多泳道架构分享的全部内容,看起来似乎不是很复杂,但是实际方案与落地过程远比文章写的复杂得多,真正的难点在于多泳道这种跨可用区高可用架构涉及组件非常多,要让这些组件配合好要考虑的细节非常多,方案实现后如何在不影响业务迭代进度的情况下平稳落地,以及持续保鲜保证在故障来临时能真正发挥作用,这些都是非常复杂的挑战,但是考虑到微信公众号的用户阅读特点我对文章篇幅进行了大幅精简,旨在让读者能快速了解我们整体架构的主旨和设计思路,希望能给广大读者带来一些参考和启发。

