语音合成技术在货拉拉的应用实践
背景介绍
TTS(Text To Speech)技术可将文本转换为语音输出,货拉拉主要将其应用于智能客服和电话通知场景。智能客服利用 TTS 实现实时语音反馈,提升用户体验;电话通知则通过离线合成多样化语音内容。相比传统人工预录制方式,TTS 更能满足动态场景和多样化话术需求,实现灵活且个性化的语音合成。
存在问题
1.延迟较高,难以满足实时沟通场景需求。
2.自然度和情感表达不足,语音常显得机械。
3.多语种支持有限,难以实现语种间的无缝切换。
解决方案
针对上述问题,提出了以下解决方案:
延迟:开发流式TTS,使系统实现实时语音输出。
自然度:进行多音色混合训练提升自然度。
情感表达:引入情感建模,使语音更加贴近真实情感。
跨语种:采用迁移学习共享语音特征,确保多语种切换流畅且合成质量一致。
通过以上解决方案,进一步提升了货拉拉TTS技术的自然度、情感表达、流畅度和实时性,从而更好地满足智能客服和电话通知等应用场景的需求。
系统框架
以下是整个工程结构框架
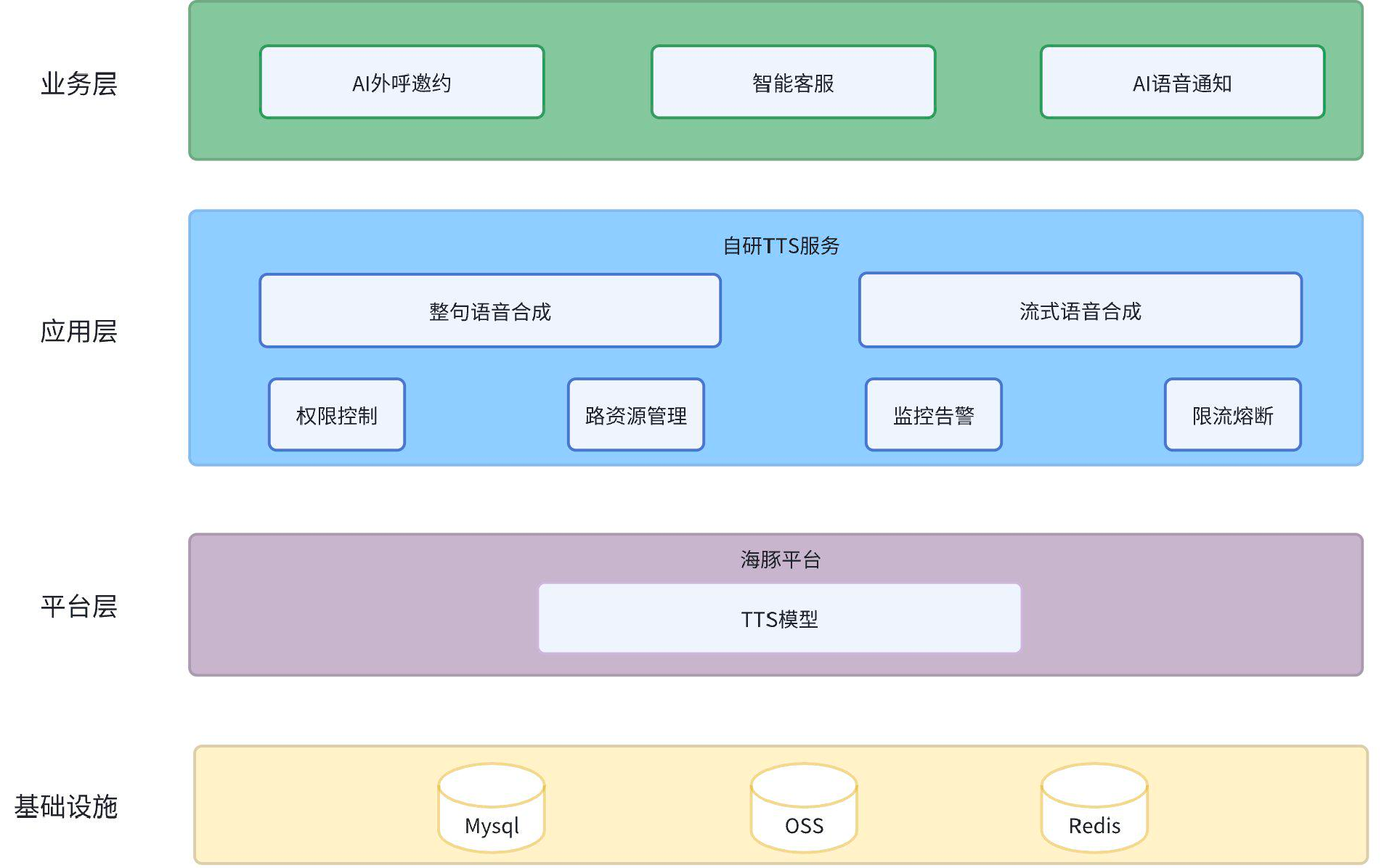
图1 自研TTS系统架构图
TTS系统主要分为四个层次:
基础设施层:提供数据存储等能力,确保系统稳定运行。
平台层:支撑语音算法实现,提供高效语音生成能力。
应用层:适配不同场景需求,保障系统安全稳定。
业务层:应用于 AI 外呼邀约、智能客服等领域。
算法方案
1 主流方案
目前,主流语音合成方案多基于稳定的深度学习模型,包括百度的 PaddleSpeech、谷歌的 Tacotron 系列和微软的 FastSpeech系列等。这些技术通过创新且稳定的模型架构,实现了高质量且自然流畅的语音输出,广泛应用于内容创作、教育、智能客服等领域。
其中,PaddleSpeech 是百度飞桨生态中的开源语音处理工具包,支持多语言、多场景的语音合成,已成功落地多个行业,与多家企业达成合作。
其 TTS 实现流程以文本前端、声学模型和声码器为核心,生成过程清晰高效,具体流程如图2所示:
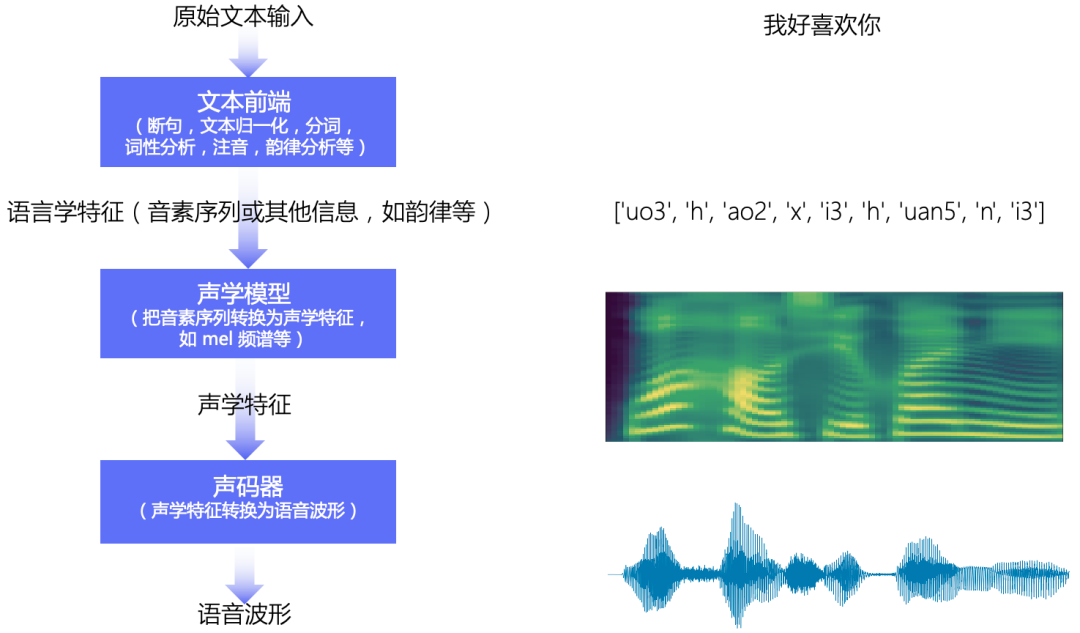
图2 主流TTS实现方案的流程
2 自研方案
货拉拉自研的TTS方案同时支持流式和非流式语音合成。核心基于VITS2,并优化解码器以支持流式合成。同时,借鉴Bert-VITS2的设计,引入Bert文本分析模型,利用语义特征提升语音的自然度和表现力。
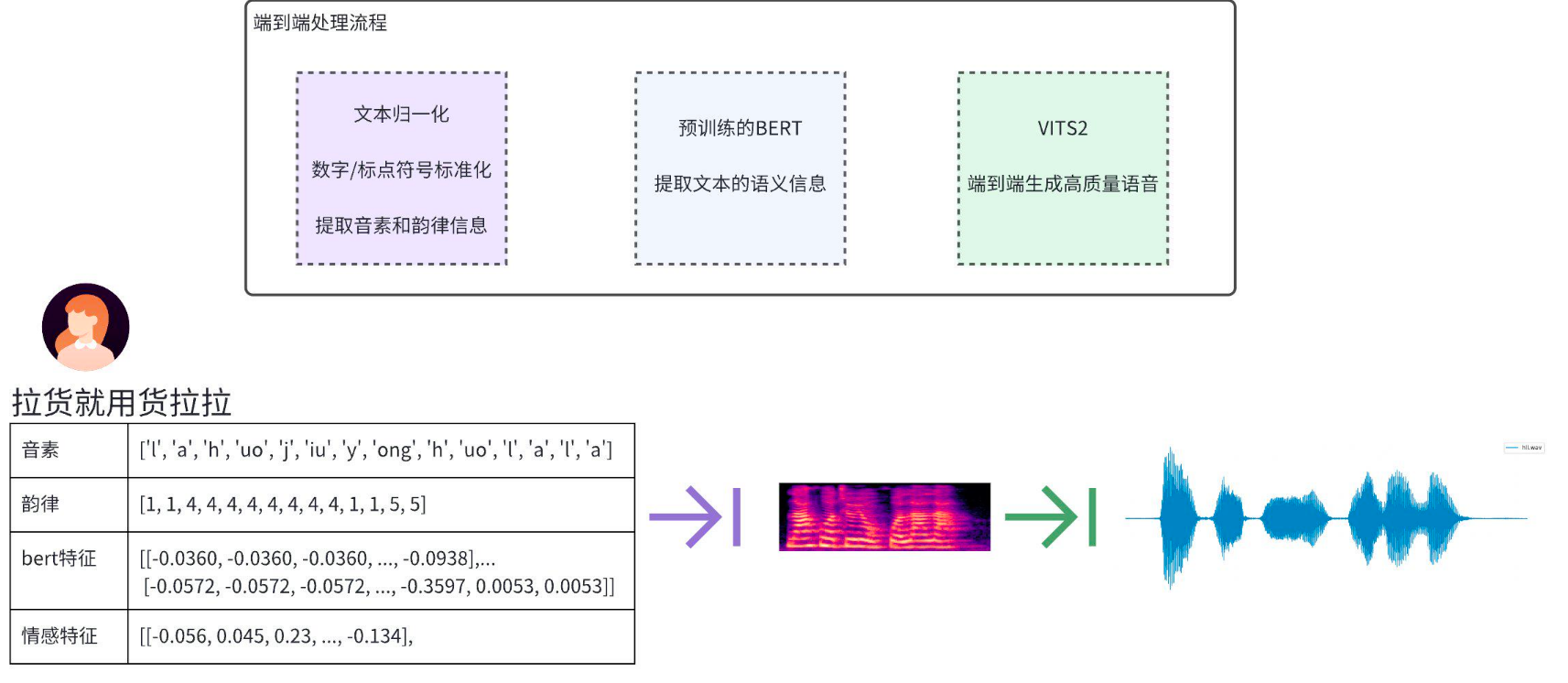
图3 自研TTS实现方案的流程
文本编码
文本编码器是 TTS 系统中将文本转换为模型可识别信息的关键组件,我们的优化如下:
文本正则化:清洗并标准化文本,规范输入格式。
音素提取:准确捕捉中文语境下的音素。
韵律优化:动态调整语调,优化停顿与重音。
语义增强:提取语义特征,提高语音合成表现力。
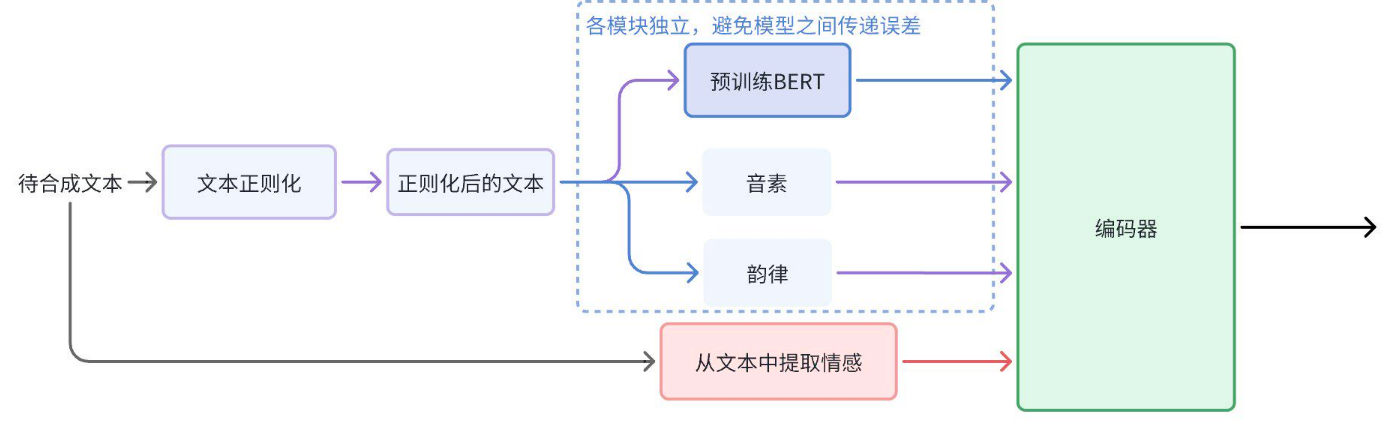
图4 文本编码器的整体架构
流式合成
Decoder的功能是将音频特征转化为音频信号。为支持流式合成,我们对VITS2模型的Decoder进行了优化。
解码器首先将文本编码器提取的特征转化成音频特征,并分块处理。每个分块实时解码为语音,经过去重叠处理确保块间平滑衔接。通过这种分块生成和即时返回设计,模型在保持语音自然度的同时,实现了高效的实时语音输出。

图5 Decoder的分块处理流程
情感特征的引入
在语音合成中引入情感特征,提升语音的情感真实度和表现力。
采用基于 CLAP(Contrastive Language-Audio Pretraining)的情感特征分类模型,从文本中提取情感嵌入,进一步增强语音的情感表达能力。
这种方法能够在语音生成的同时保持语义准确性,并更好地呈现丰富的情感变化。

图6 情感标签的提取
支持音色定制
音色定制是TTS个性化的关键能力,能够满足多样化的应用需求。
小样本训练:通过小样本数据快速实现特定音色微调,满足多样化场景需求。
高效迁移学习:针对目标音色进行轻量化调整,快速适配不同音色风格。

图7 定制音色流程
跨语种迁移学习
为支持多语种合成,采用迁移学习技术,通过共享声学特征将现有语言模型的知识迁移至新语种。
模型适应性:降低训练成本,实现不同语种间的无缝切换。
语音生成效果:利用多语种预训练BERT模型,确保语种切换的流畅性和合成质量。
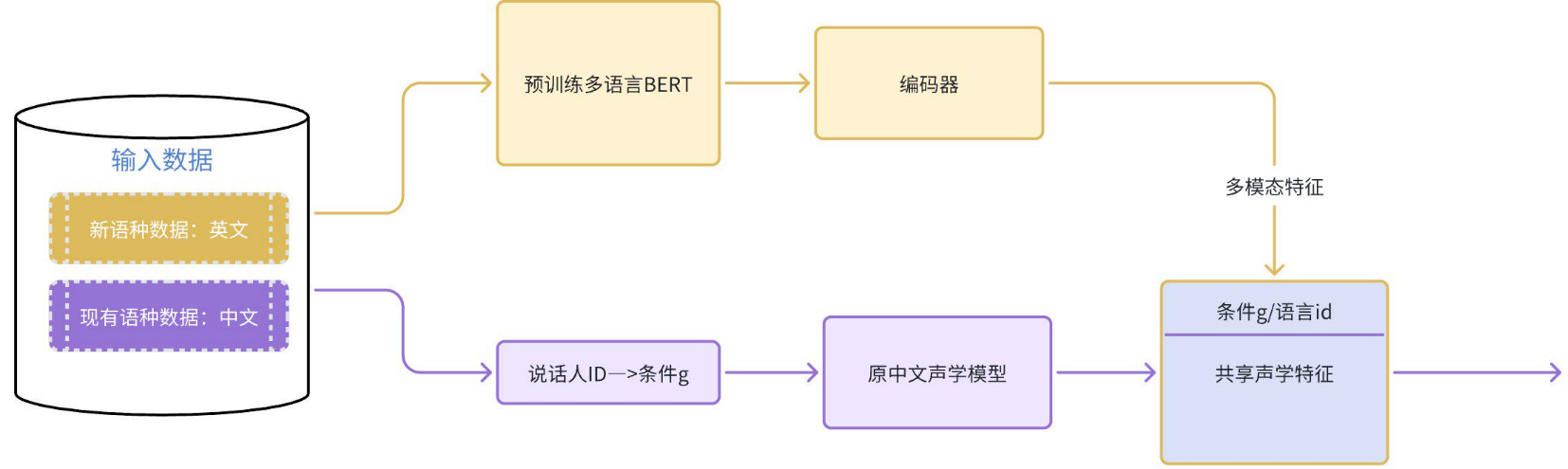
图8 实现多语言的流程
总结展望
本文介绍了货拉拉自研TTS技术的应用与优化,包括情感表达、流式合成、多语种支持和音色定制等关键技术,致力于实现更加灵活、实时和自然的语音交互。未来,我们将继续推动TTS技术的创新,为货拉拉的生态系统提供更多智能化应用场景,提升用户体验。

