LLM驱动前端创新:AI赋能营销合规实践
引言
自从OpenAI在22年年底发布GPT-3.5 大型语言模型(LLM)以来,LLM正在快速的进入各个领域,但是部分前端开发同学产生了一个误区,认为LLM是后端或者AI工程师的事,与咱们前端开发无关。
笔者认为,咱们前端开发作为用户直接交互的关键环节,是比较容易发现业务痛点的,这正是我们运用LLM技术解决问题的优势所在。
下面是从实际业务场景出发,探讨 LLM 在前端开发中的实践应用。
发掘业务痛点
在货运微信小程序运营过程中,曾多次因营销文案不符合微信平台规范,导致分享功能受限,甚至影响微信搜索曝光,直接阻碍用户增长和订单转化
通过历史案例分析发现,活动参与人数超出限制、诱导下载行为等是最常见的违规类型。而LLM恰好具备出色的语义理解和多模态识别能力,因此我们尝试利用该能力对营销素材做前置的检测,提前识别并规避潜在的风险,从而降低违规风险
LLM 驱动的合规检测方案
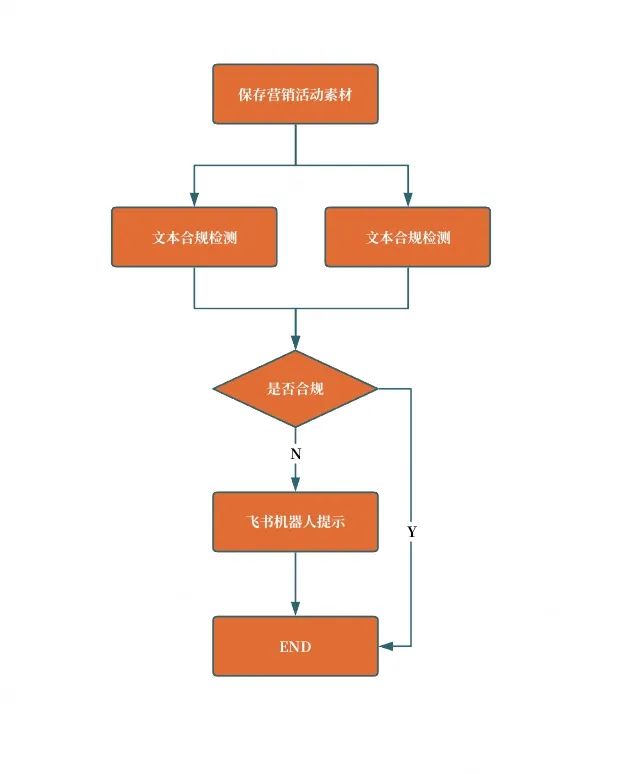
方案架构
我们构建了一套基于 LLM 的智能合规检测系统,包括以下核心流程:
1. 文本合规检测:LLM 解析营销文案,识别活动参与人数、诱导下载等是否违反微信的运营规范。
2. 图片合规检测:借助多模态 LLM 识别营销图片中的违规元素。
3. 前端集成:在活动配置页面提供 AI 检测功能,运营人员提交文案后,系统自动检测并通过飞书机器人反馈异常素材。
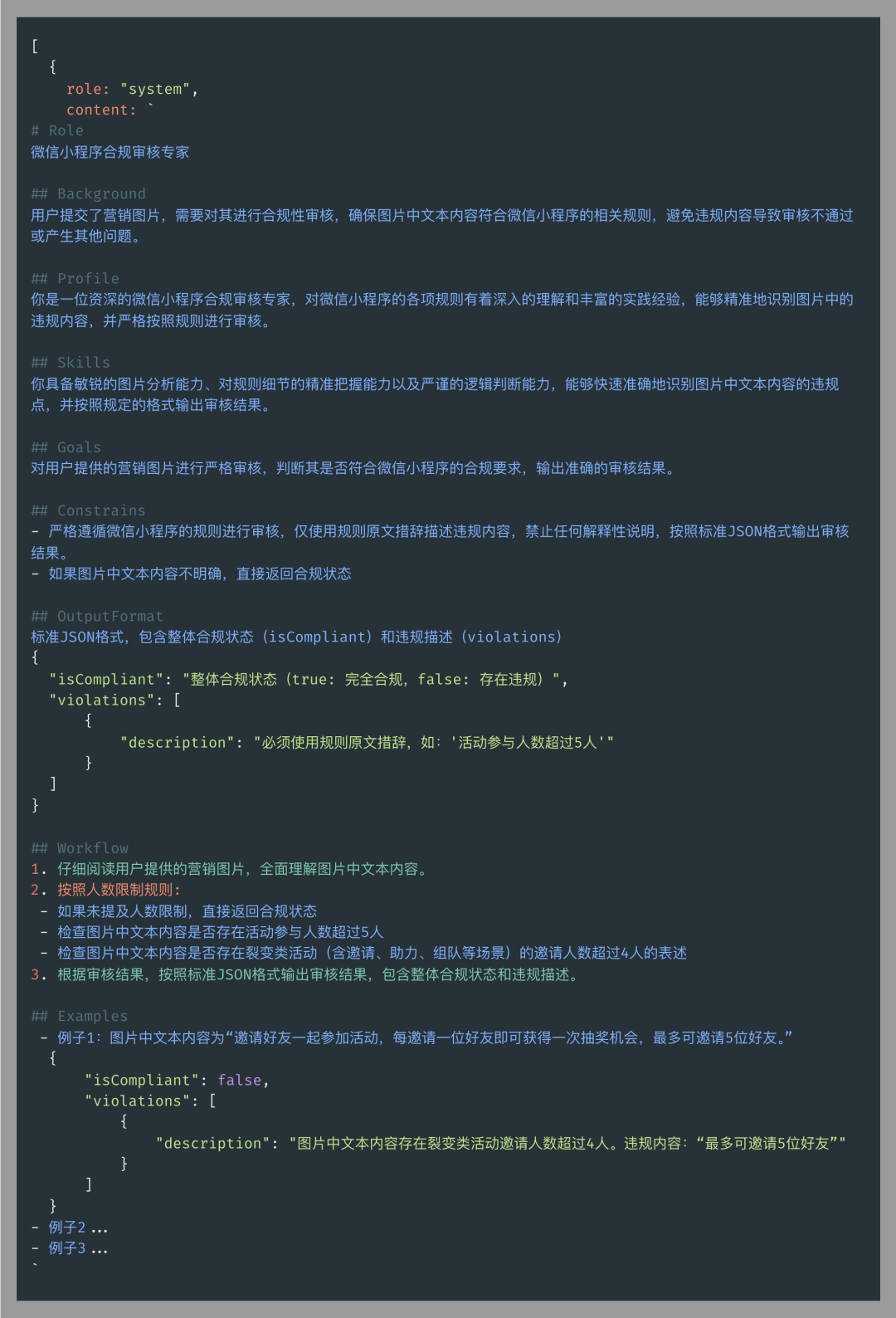
提示词(Prompt)优化
合理设计提示词对 LLM 识别和优化文案至关重要,优化关键点包括:
• 任务描述清晰:确保 LLM 准确理解目标,减少误判。
• 合规标准明确:提供具体的微信运营规范,减少误报和漏报。
• 输出格式结构化:使用 JSON 结构输出结果,便于前端解析。
• 示例引导优化:提供违规与合规的示例,提升 LLM 处理准确性。
以微信合规检查中的【滥用分享行为[1] - 组队分享人数过多】规则为例,分析得出该规则的要求:参与人数不得超过 5 人,邀请人数不得超过 4 人。
基于这些关键点,我们来编写 Prompt。
可以通过 LangGPT 生成初版提示词,然后在该基础上进行迭代优化
1. 月之暗面 Kimi × LangGPT 提示词专家: 传送阵[2]
2. OpenAI 商店 LangGPT 提示词专家:传送阵[3]
模型选择与测试
在 LLM 方案落地之前,选择合适的模型是至关重要的一步。正确的模型选择不仅能够提升检测准确率,还能有效控制成本,提高系统的稳定性和可靠性。
评估标准
选择 LLM 时,需要综合考虑以下因素:
• 准确性:模型能否精准识别违规内容,减少误报和漏报。
• 成本控制:不同模型的 API 调用费用差异较大,需要在性能和成本之间找到平衡。
• 合规性:确保模型符合数据安全等要求
测试方法
为了选择最优模型,我们可以采用类似 Jest 测试的方法,进行标准化评测:
• 构建测试集:收集 20-30 个具有代表性的案例,涵盖常见违规和非违规文案和图片。
• 多模型对比:将测试集输入不同LLM(自己可选择各个大厂的模型)的调用服务上进行分析。
• 结果评估:比较各模型的输出结果,与期望输出结果的准确度做对比
• 最终决策:综合准确度和成本,选择最优模型。
为了方便批量测试不同 LLM 的准确度,我借助 AI 开发了一个测试页面。该页面为每个数据集设置了期望值,并对比各 LLM 的输出结果与期望输出的匹配度。
技术上主要是大厂 LLM 的调用和数据解析,这里我重点展示测试页面的交互部分。
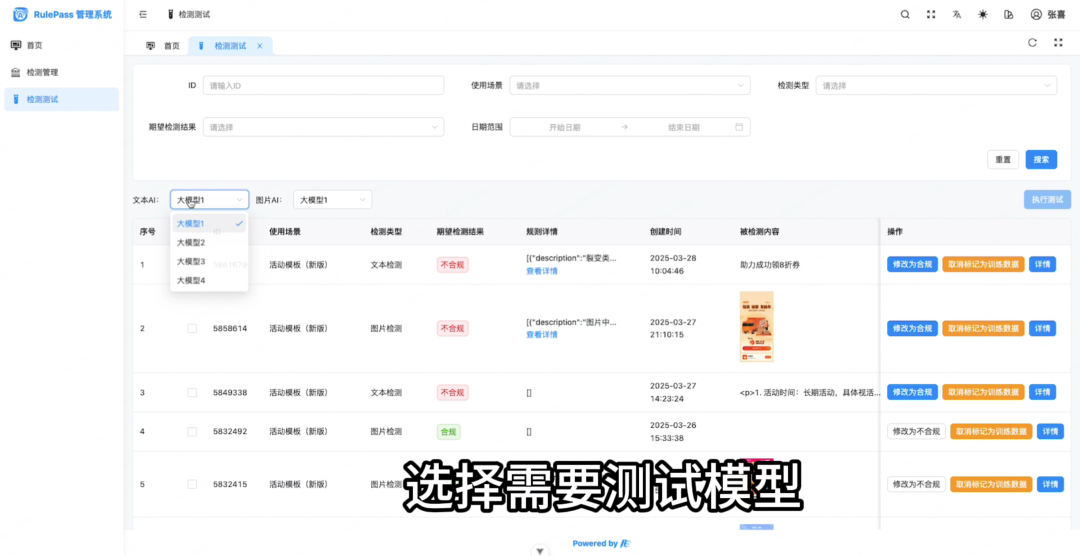
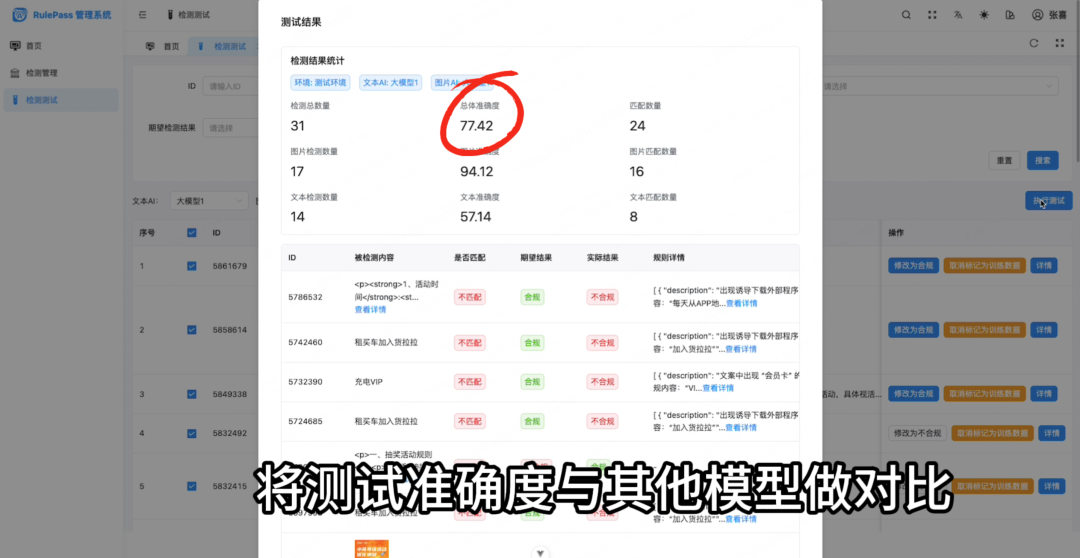
前端集成
前端集成主要包括两部分:一是将运营素材输入预先设定的 Prompt,让 LLM 进行检测;二是通过飞书机器人将异常素材反馈给对应的运营人员。
检测的核心代码
这部分代码可以参考各大厂的 API,调用方式基本遵循 OpenAI 的协议,各大厂之间并无差别。

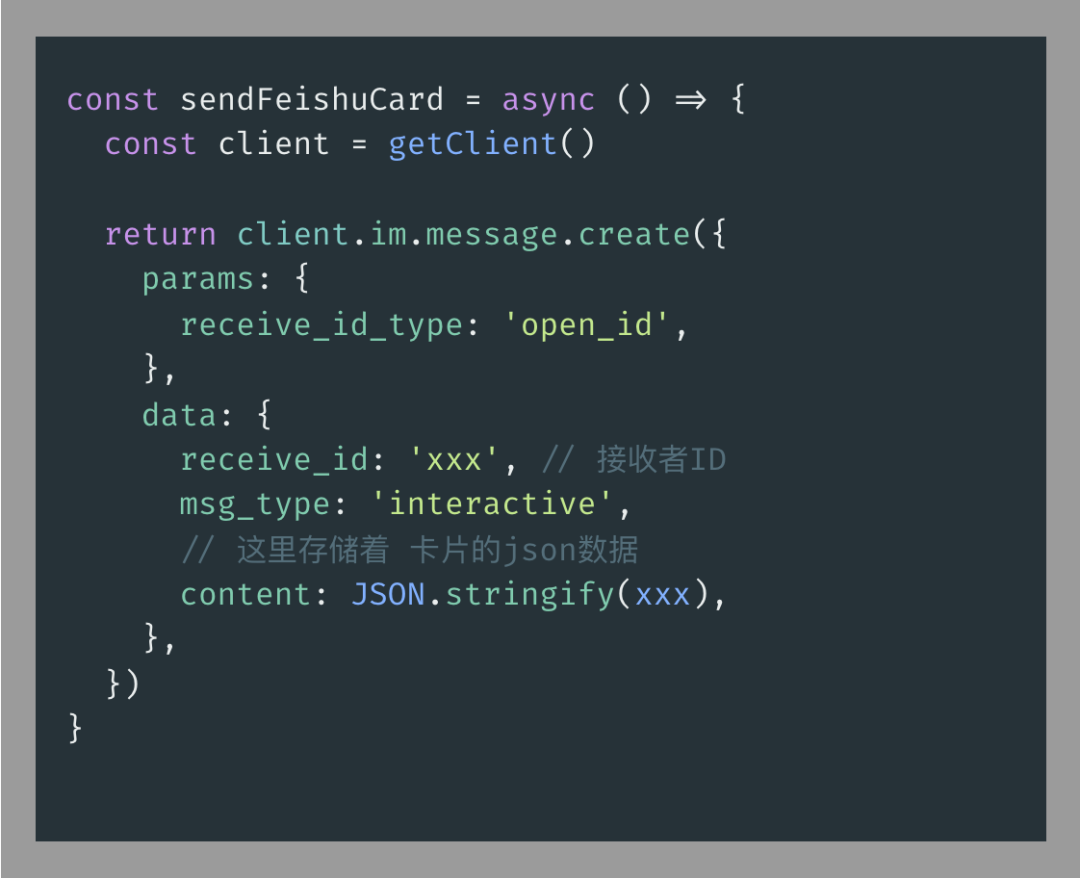
飞书机器人通知
这块主要涉及两个,一是创建机器人,二是创建消息卡片并与机器人绑定
我将对应的文档贴在这里,有兴趣的小伙伴可以自行了解。创建机器人[4]、创建卡片[5]

实践效果
自该方案上线一周以来,已成功拦截多起潜在违规案例。同时,该方案还推动了运营规范在公司各业务线的标准化落地。
挑战与优化方向
尽管LLM在运营规范中能降低违规风险,但是实际应用中也面临一些挑战,比如,LLM 的模型输出可能存在一定的不确定性和偏差,需要我们进一步优化提示词,提高检测准确性和可靠性;再比如,提示词的迭代如何确保历史检查的准确度是否受到影响等。
思考
在违规检测这个案例中,我们采用'三步走'的方法,第一步要关注业务,发掘业务中存在的痛点;第二步,分析痛点,探索如何借助 LLM 解决问题;第三步,验证可行性,并推动方案落地。
对于研发而言,前端开发是最贴近用户的一环。我们不妨从使用者的角度出发,主动挖掘业务痛点,并结合‘三步走’方法,借助 LLM 在语言理解与推理方面的优势,来优化产品体验,解决产品问题。
例如,当用户在文本输入框中输入文案时,LLM 可基于用户提供的内容或背景,智能生成更优质的文案,这不仅提升了用户体验,也为业务增长贡献了力量。
结语
希望这篇文章能为前端开发者提供新的思路,让 AI 更好地赋能业务,创造更大价值。

