货拉拉 API 异常流量检测实践
一、背景
API(应用程序编程接口)在企业信息流通以及应用程序和系统之间的连接中扮演着重要的角色,随着企业业务的不断拓展,越来越多的攻击者通过攻击 API 来达到破坏信息系统和窃取数据的目的,API 逐渐成为一个巨大的风险敞口来源之一。本文将从流量分析角度切入,简要阐述 API 异常流量检测的实践过程。
二、目标
//关注点在检测和止损
摸清资产:盘点全量 API,整理 API 的风险场景,掌握 API 整体的威胁态势
能力建设:结合业务场景和 API 风险类别,建立异常检测和打击能力
防范风险:数据泄露、敏感信息、被爬取风险
专注于敏感数据和与业务强关联场景下数据,通过大数据分析、机器学习、统计学等技术,形成 API 资产管理、敏感信息泄露检测、业务威胁防护、安全事件溯源等能力,降低重大安全事件发生的概率和损失。
三、方案
3.1 整体框架和事件响应 SOP
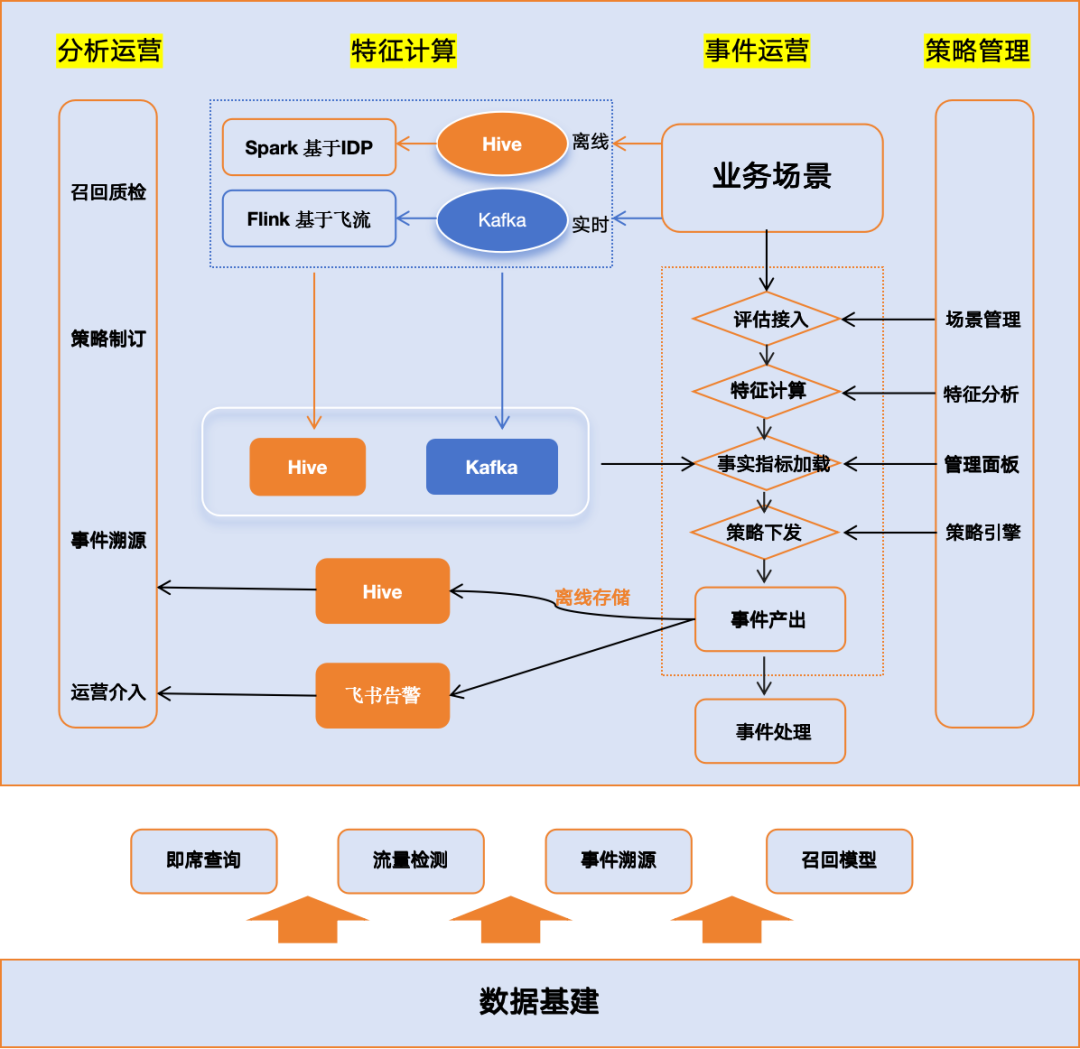
图1 整体框架
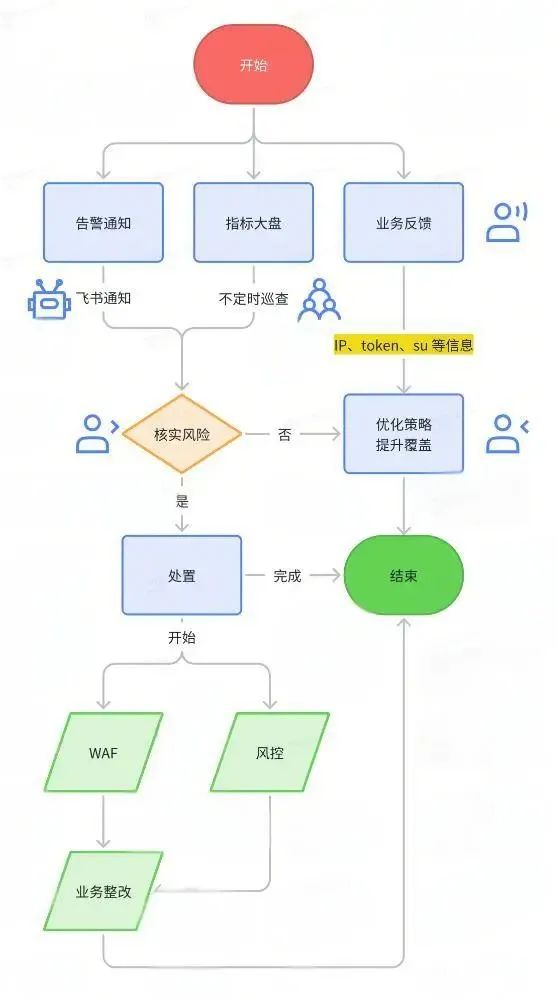
图2 事件响应SOP
3.2 实践流程
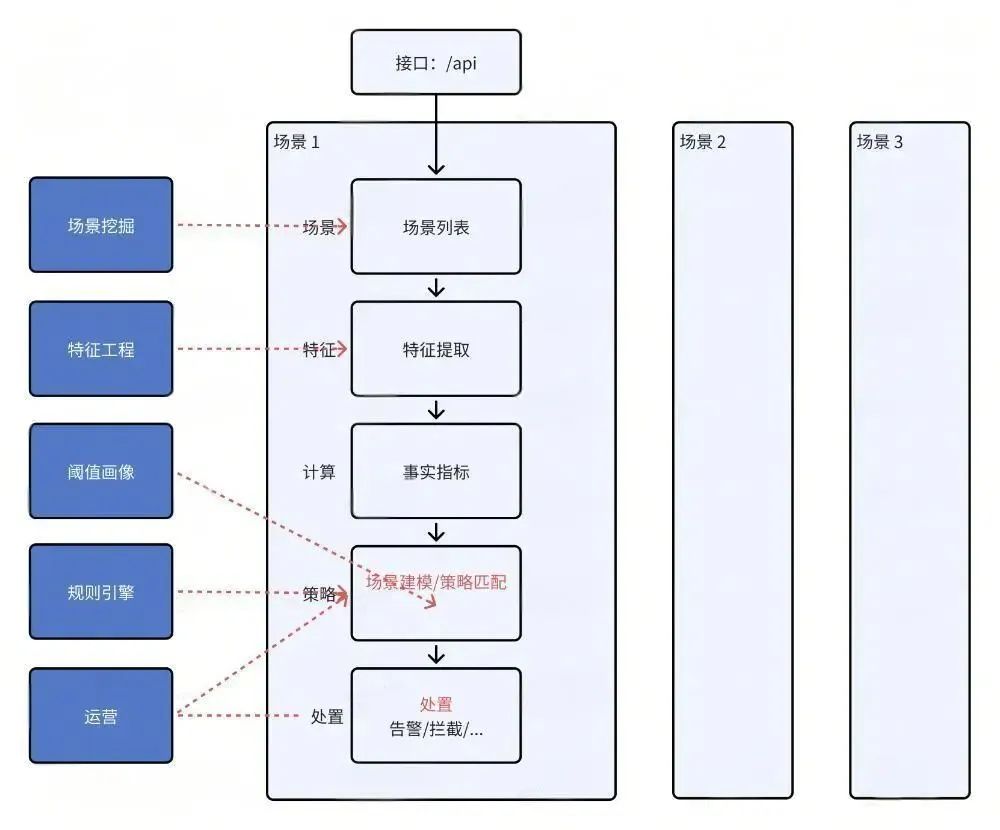
图3 实践流程
1 场景挖掘
//理想状态下,我们总是希望能接入并且覆盖所有的接口和场景,但是实际上总会由于各种因素限制,无法覆盖所有可能的情形。
参考业界的主流方案,比如某海外厂商基于它积累的海量数据资源, 其 Bot Management 产品可以对每条流量给予威胁分数,但国内厂商更多的是根据需求方在细分的业务场景深耕,比如某厂商的方案是根据情报和敏感数据接口划分。
结合自身的现状以及以往的经验,我们先从敏感数据等级出发,对存量和增量的高、中敏感数据接口优先覆盖,然后结合我们自身对业务的理解对 API 的场景训练分类模型。
2 特征工程
//特征工程指的是将原始数据转化为更适合机器学习、统计学模型的特征数据,通过合理的特征工程对原始数据进行加工提取,模型可以更加轻松地发现数据中的关联关系和降低计算成本。
根据实际的需要,我们目前特征工程主要有两个链路: 离线 和 实时 。
离线分析 vs. 准/实时分析

离线链路:基于 Spark 的 IDP(数据平台)在 Hive 中进行批量处理,离线计算负责将流量数据进行指标汇总、清洗和特征提取,以供下游分析和模型训练使用。离线计算适用于应对较长时间周期内的数据,生成多维度的统计指标,可以检测比较隐蔽、低频的异常流量。
实时链路:基于 Flink 的实时流处理,数据从 Kafka 中读取并经过处理后,提取实时特征输出至 Kafka,供下游 规则引擎快速响应和决策。实时计算适合应对较短时间周期内细分业务场景数据,比如基于交易订单、账号操作实时数据生成即时统计特征,可以检测中高频的异常流量。
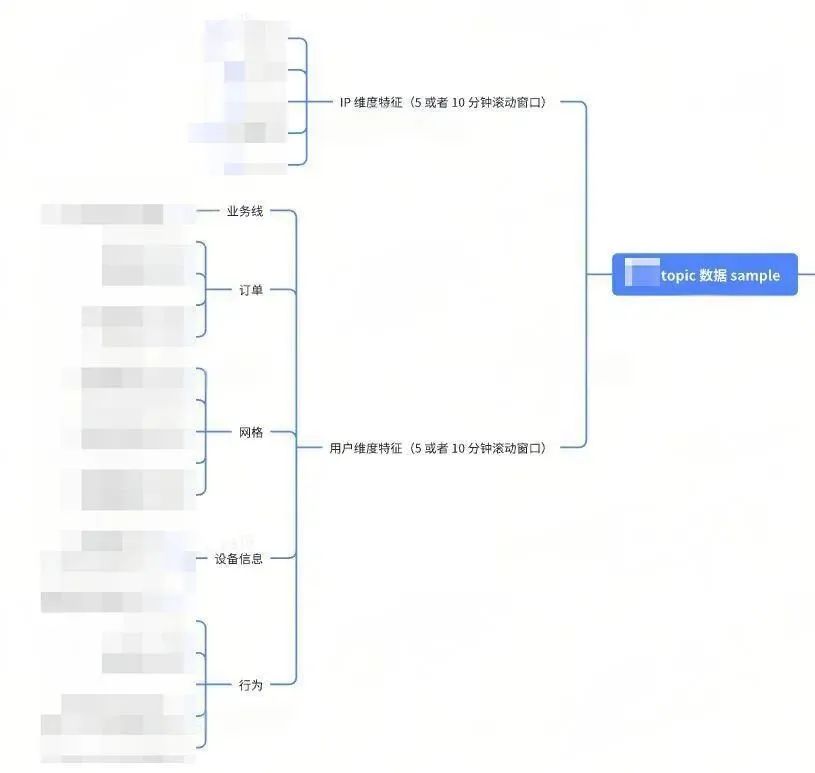
图4 构建特征集
3 阈值画像
//目前,HLL 平台包含众多 API,其中部分为涉敏 API ,为此需要针对不同的 API 接口设定差异化的访问频次限制,以更精细地管理访问行为。通过限制异常频次访问用户的行为,可以有效实现监控和隔离,降低敏感数据泄露的风险,同时提升平台的整体安全性。
根据用户在短时间内(连续 N 分钟)对不同 API 接口的访问频次,构建 API 画像。随后,利用算法模型( DBSCAN、OneClassSVM),针对这段时间内某个特定 API 接口的用户访问行为,检测异常点。由于大多数正常用户的访问频次较为集中,而异常用户的访问频次通常与正常用户有显著差异,这些偏离正常范围的用户即为离群点。算法判定的离群点对应的最小数值被定义为该时间段内的异常检测阈值。
为了提高策略初期的准确性,在设置策略时,会对一个周期内不同时间段所计算的阈值进行比较,取其最大值,作为该 API 接口在这一周期内的参考阈值。这样可以更有效地应对访问频次波动,确保策略的稳健性。
4 日常运营
(1)检测手段
一般来说,常见的检测手段包括以下几类:日志与流量分析、用户行为建模、大数据分析、机器学习、时序行为分析等。API 异常检测中异常检测手段有如下几类:
日志与流量分析:对服务器、网络设备等生成的访问日志进行离线分析,挖掘异常行为模式,如异常访问频次、错误请求率、特定时间段的流量突增等
用户行为建模:基于细分场景下的异常用户访问频率、路径等特征建立行为模型;使用聚类算法如 DBSCAN、孤立森林、K-Means,检测离群 IP 和用户
时序分析:分析用户访问操作的时间间隔,检测是否存在异常的访问速度(如过快或固定间隔)
威胁情报、多维度交叉验证
(2)异常类型
可以检测的异常流量类型有:
爬虫流量:计价爬虫、低频刷验证码爬虫
伪造参数欺诈流量:伪造用户凭证流量、伪造设备流量
中/高频访问流量:明显偏离正常基线流量、偏离正常业务需求流量
(3)策略划分
在实际业务场景中,为了应对各种异常流量和安全威胁,检测策略通常会被划分为不同类型,以覆盖从简单规则到复杂行为分析的需求。这些策略可以根据使用场景和技术手段分为以下几类:
规则型策略:依赖预定义的静态规则,对流量或行为进行匹配和判断。这类策略实现简单、易于配置。
a. 阈值规则:设定访问频次、请求量、响应时间等指标的上下限,比如每分钟最大请求数不得超过 N 次
b. 统计策略:频次分析、时间间隔分析
模型检测策略:
a. 异常检测模型:使用如 Isolation Forest、OneClassSVM 等无监督模型,自动识别异常点
b. 聚类分析:利用 K-Means、DBSCAN 等聚类算法,对用户行为进行分组,通过孤立的簇发现异常
基线策略:通过对正常业务运行的历史数据进行建模,建立行为基线,检测偏离基线的异常行为。
5 处置链路
根据特征链路的维度,异常流量通常有如下属性维度:
IP、设备
鉴权凭证
用户
处置时效:
准实时:5min/10min
离线:2h
处置手段:
自动:基于 WAF 规则引擎和风控处置能力,准实时链路自动推送处置异常账号
半自动/手动:基于 WAF,手动下发处置策略
其实,在整个框架中,首先需要考虑具备哪些维度的处置能力,然后再根据处置能力开展特征工程、场景挖掘等后续工作。
FAQ
1. 场景是否能覆盖所有接口?
在 API 异常检测中,理想状态下希望能覆盖所有的场景和接口以确保较高的安全性。然而在实际中,由于接口数量庞大、模型误差、计算资源限制等原因,并不能覆盖所有的接口。不过,可以通过持续监控增量接口、优化分类模型、梳理存量接口等手段最大程度提升 API 的覆盖率。
2. 异常行为如何判定?阈值画像引入是否可以解决问题?
离线层面适合应对低频、隐蔽、分布式的异常流量,比如计价场景的低频计价爬虫为了防止被检测,通常会使用大量 IP 以极低的频次持续访问,通过常规的观察手段难以识别。而通过离线分析手段可以分析网络流量的行为模式,如访问频率、访问时间、访问路径等,以识别出与正常行为不符的异常行为。
准实时/实时层面适合应对显著偏离正常模式的流量,在缺少标签的情况下,通过阈值画像无监督学习(DBSCAN、OneClassSVM、孤立森林算法)建立 API 接口的基线行为模型,检测细分场景下特定 API 的离群值流量。
3. 哪些环节需要投入较多的人力?
一般来说,项目的前期人力主要投入在数据清洗、特征工程,等到项目成熟开始后,更多的精力需要投入到策略运营和场景挖掘环节。目前,以爬虫场景为例,我们主要从流量中学习爬虫的行为模式和流量特征,从行为模式提取的策略生命周期相对来说比较长久,而流量特征则需要结合具体的业务场景去定义数值参数。

