全链路血缘是大数据时代企业数据管理的重要组成部分,在企业数据治理、链路追踪、问题排查、价值评估等方面具有重要意义。本文将从全链路血缘的概念、使用场景、产品实践等方面进行详细介绍。
01 什么是全链路血缘
全链路血缘是指数据在其生命周期内变化的完整流程,包括数据的起源、传输、存储、加工和使用等生命周期的各个环节。我们今天要介绍的全链路血缘覆盖了业务端到端的完整血缘链路,即包括最上游的来源业务系统、业务库表传输到数仓表、数仓表间加工关系、表和指标的关系、表和标签的关系、表和API的关系、表和BI报表的关系等,旨在厘清数据最源端来自哪里,数据最下游被用去了哪里。
02 全链路血缘使用场景
为什么我们反复强调数据血缘?为什么要费力去构建数据血缘关系?因为数据血缘在数据管理过程中发挥了重要作用,总结为以下几点:
1. 问题追溯和下游影响评估
当数据出现异常时,数据开发及运维人员可以根据数据血缘来分析和追溯异常数据的源头,并评估对下游数据的影响范围,及时对下游进行数据修复,提高数据稳定性。
2. 辅助数据治理,数仓链路优化
通过数据血缘查看数据链路上是否存在不合理的数据依赖,例如跨层依赖或者循环依赖,从而进一步分析是否存在重复计算或资源浪费的情况。此外,数据血缘也可用于孤岛数据清理。当一个数据没有上下游时,可将其初步识别为孤岛数据,并进行分析和清理,从而避免不必要的存储和计算开销。
3. 数据价值衡量
通过对数据节点的下游进行汇总,排序及分析,可作为数据价值评估依据。下游输出较多的数据节点,其业务使用场景较多、价值密度较高,可添加数据质量监控和基线保障措施等;对于没有下游使用的冰冷数据,可以进行归档冷备、或下线等。
4. 基于血缘的变更通知
随着业务的复杂度和数据量级的增加,数据间的关系错综复杂,牵一发而动全身。当出现业务变更或数据异常时,需要将变更情况及时通知下游,此时一一寻找下游负责人并逐个通知则非常困难,极容易出现漏通知、重复通知的情况,而基于数据血缘自动通知下游相关业务方则省时省力、精准高效。
03 全链路血缘构建实践
3.1 整体方案介绍
我们将数据流转过程大致分为4个部分:
源业务系统:数据的来源业务系统,例如OA系统、人力资源系统、柜台系统、订单系统等;
业务库表:各业务系统数据对应的实际存储的业务库表信息;
大数据平台:通过实时传输、离线传输,将业务数据传输到大数据平台上,后续可对数据进行离线/实时加工、指标关联、标签关联等;
数据应用:加工完成的数据,可用于生成数据服务API、BI报表等,用于业务分析决策。
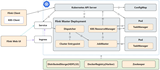
如下图所示:

根据上面的数据流转示意图,并结合某电商订单的业务场景为例,一个精简化的全链路血缘示意图如下所示:
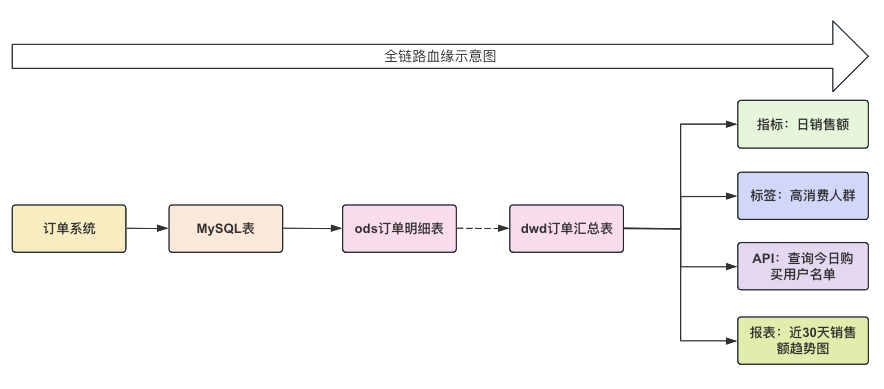
3.2 产品操作演示
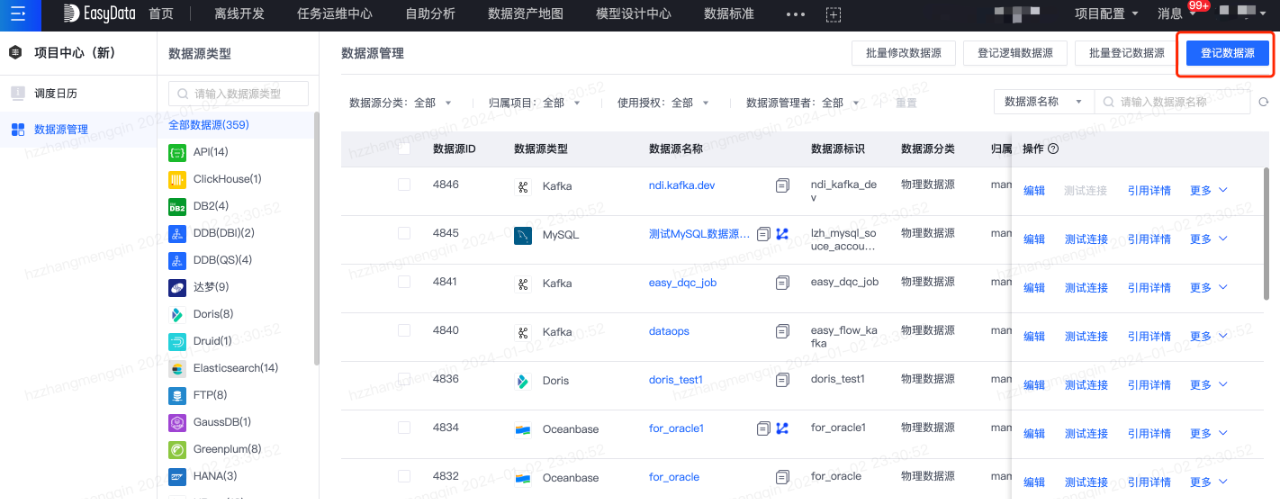
第一步:登记外部数据源
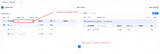
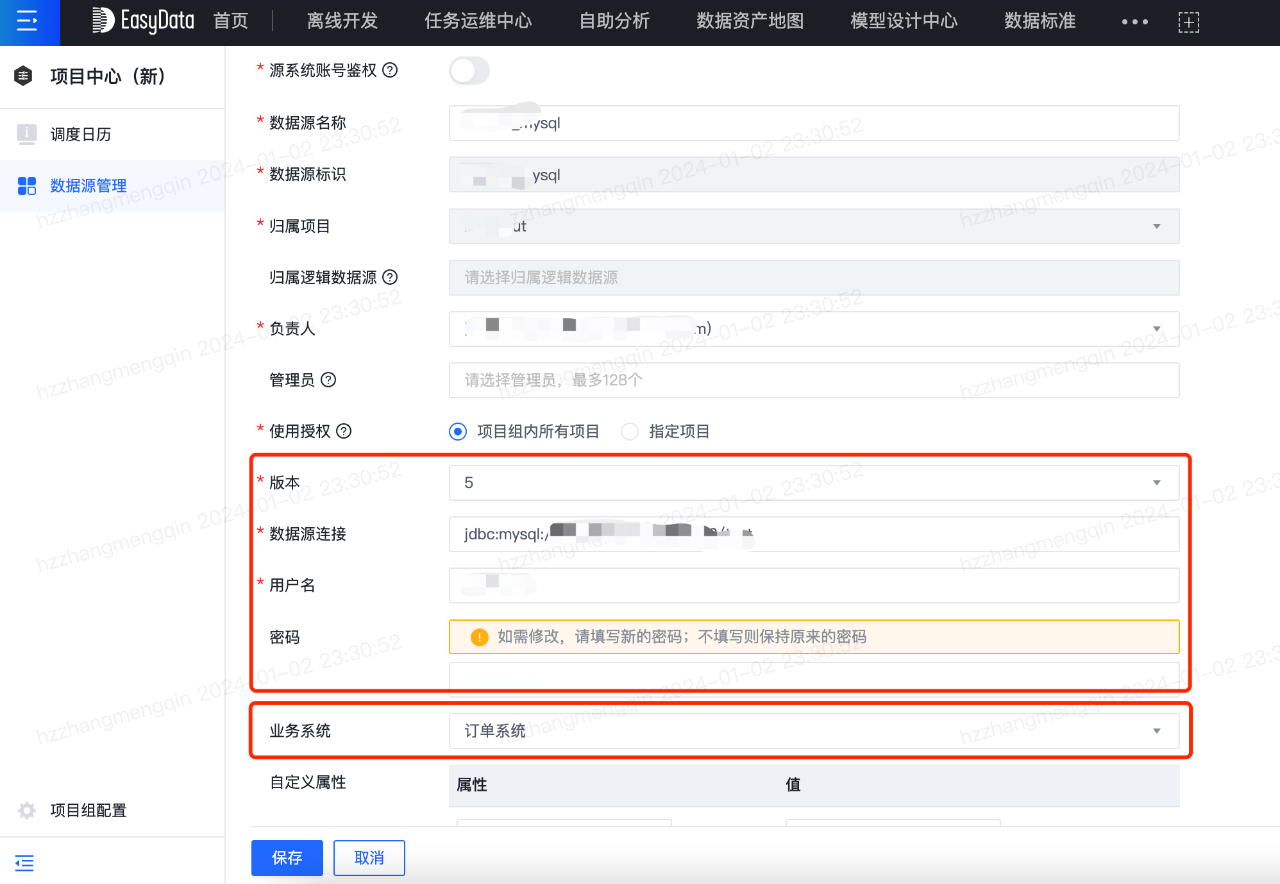
外部业务系统的数据首先需要登记在平台上,才能进行数据传输和后续的加工。数据源登记如下图所示:
第二步:创建数据传输/数据加工任务
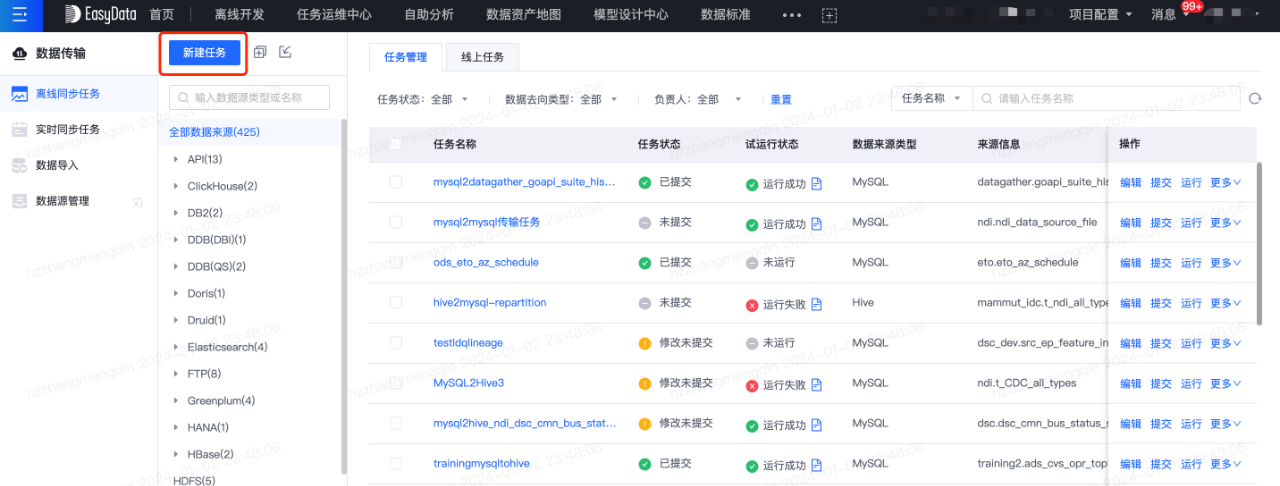
数据源登记完成后,接下来先创建数据传输任务,将MySQL中原始数据同步到数仓ods层表中。数据传输任务创建流程如下:
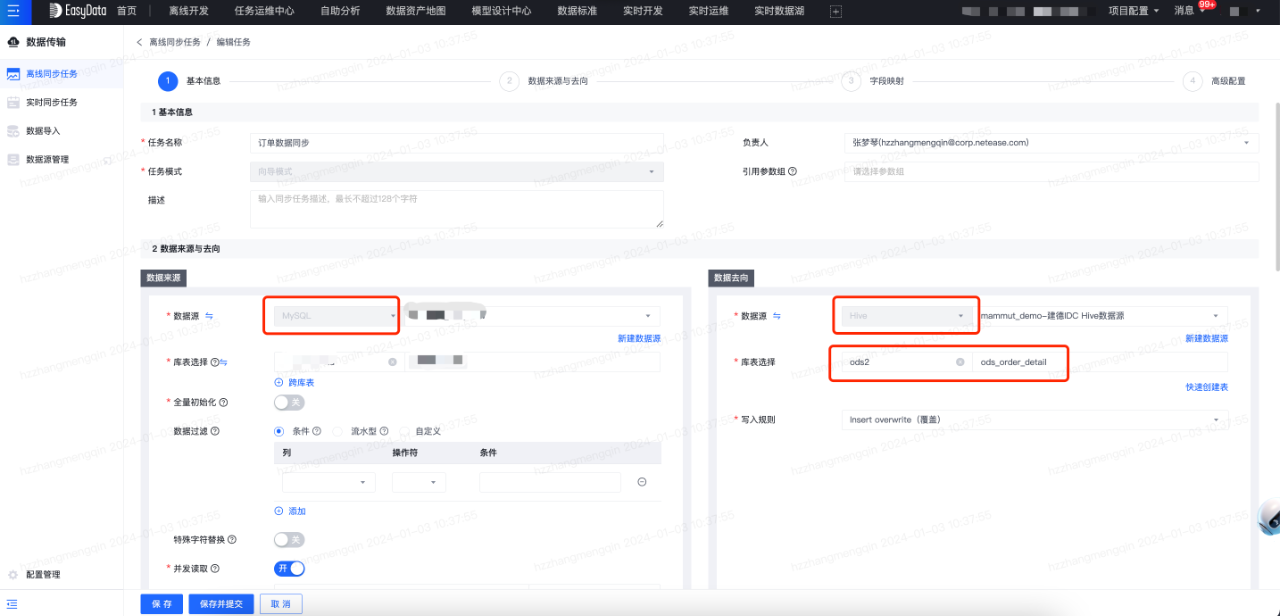
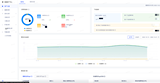
接下来创建离线开发任务,将传输任务同步过来的ods层表进一步加工成汇总表,离线加工任务流如下所示:
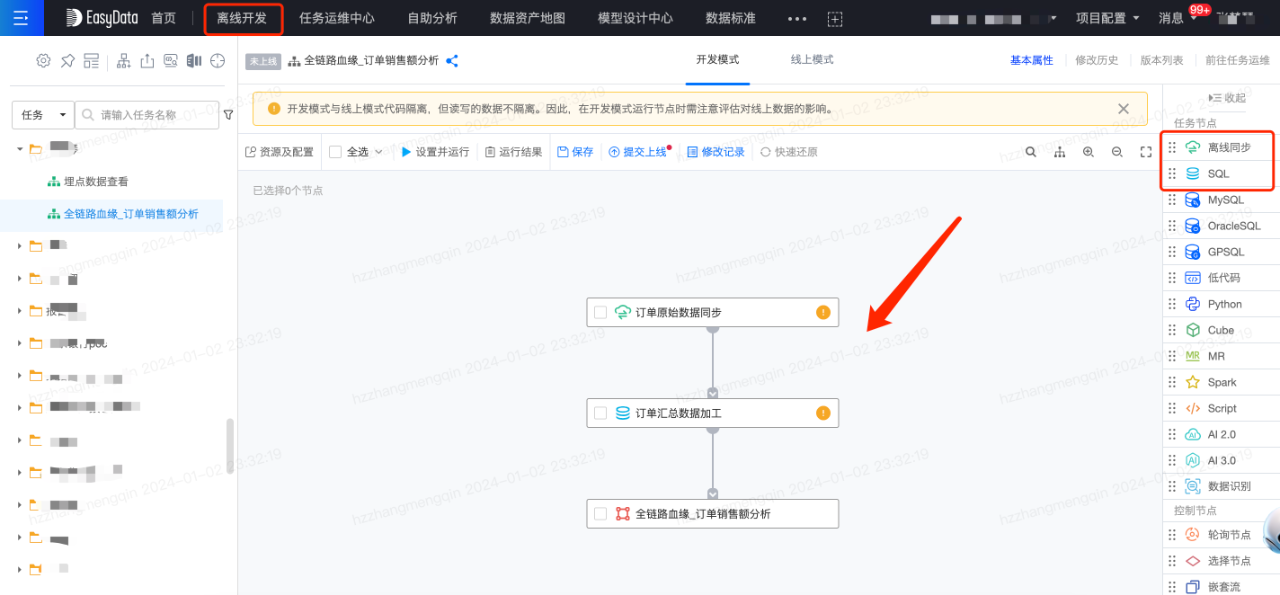
任务创建完成后,编辑SQL代码,最后调试运行完成后即可发布上线,这里不做详细介绍了。至此已实现【源业务系统->MySQL表->数仓ods表->数仓dwd表】的血缘链路构建,如下图所示:

第三步:关联指标、关联标签
为了呈现全链路血缘中指标、标签、API、报表等血缘,我们继续进行后续操作。指标和标签的血缘关系建立渠道较多,这里我们从元数据视角出发,给表字段关联指标和标签即可。
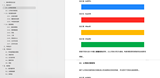
在元数据管理模块中,给表字段关联指标如下图所示:
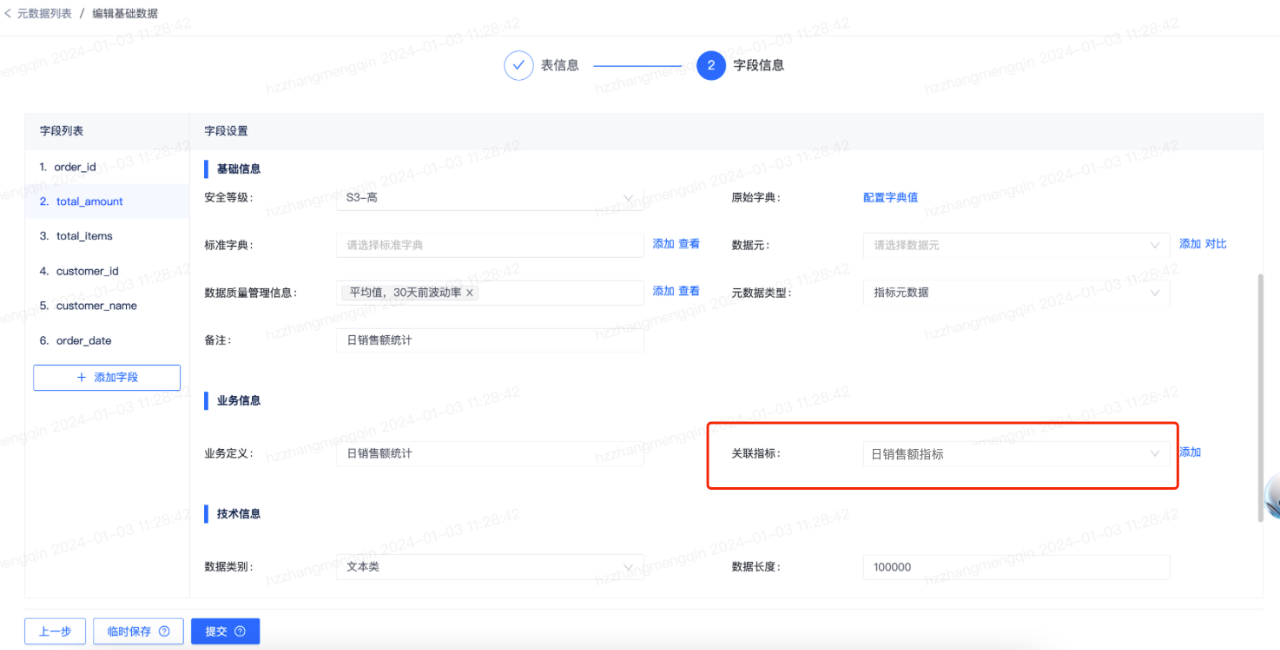
在元数据管理模块中,给表字段关联标签如下图所示:

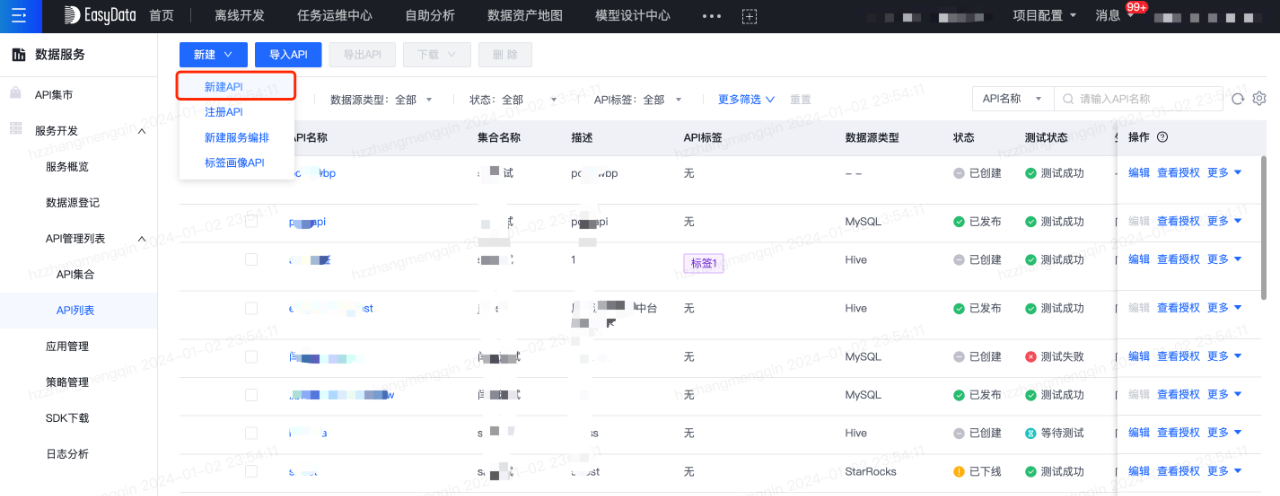
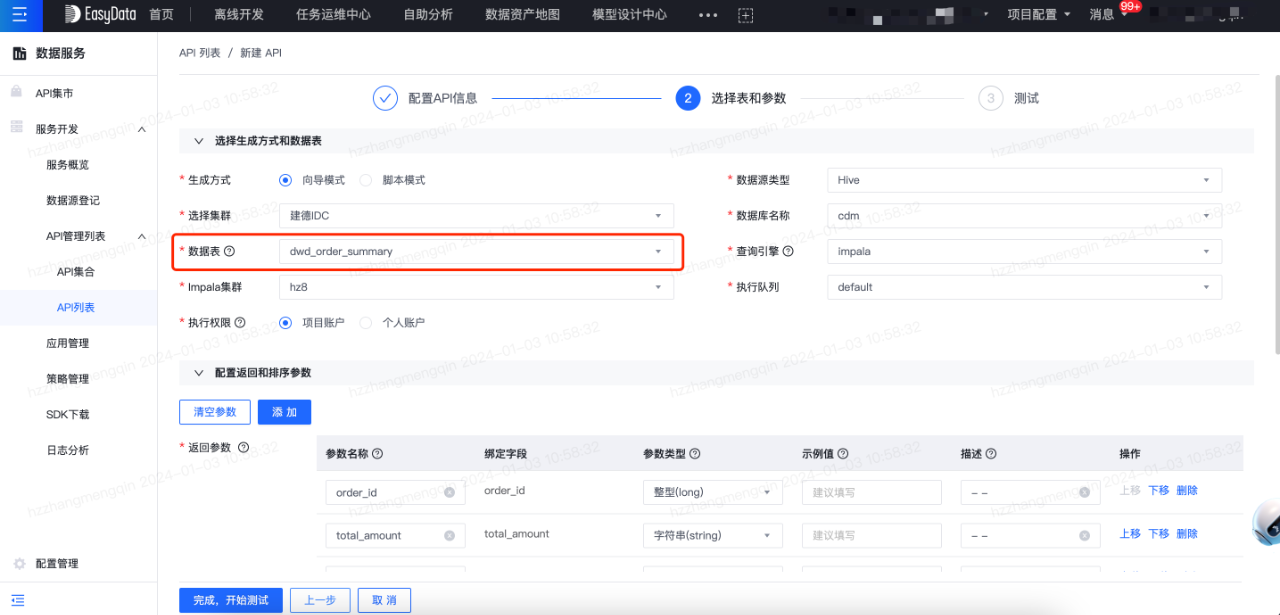
第四步:创建数据服务API
将表生成数据服务API后,系统将自动建立表和API间的血缘关系。在数据服务模块中,创建API流程如下:
第五步:创建BI报表
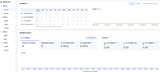
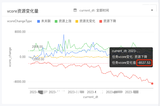
加工完成的表可以在BI系统中通过可视化配置生成需要的各种报表。在BI系统中需要将数仓Hive集群的信息先登记上来,然后建立模型表,最后选择模型表后就能绘制报表数据了。报表编辑页如下所示:
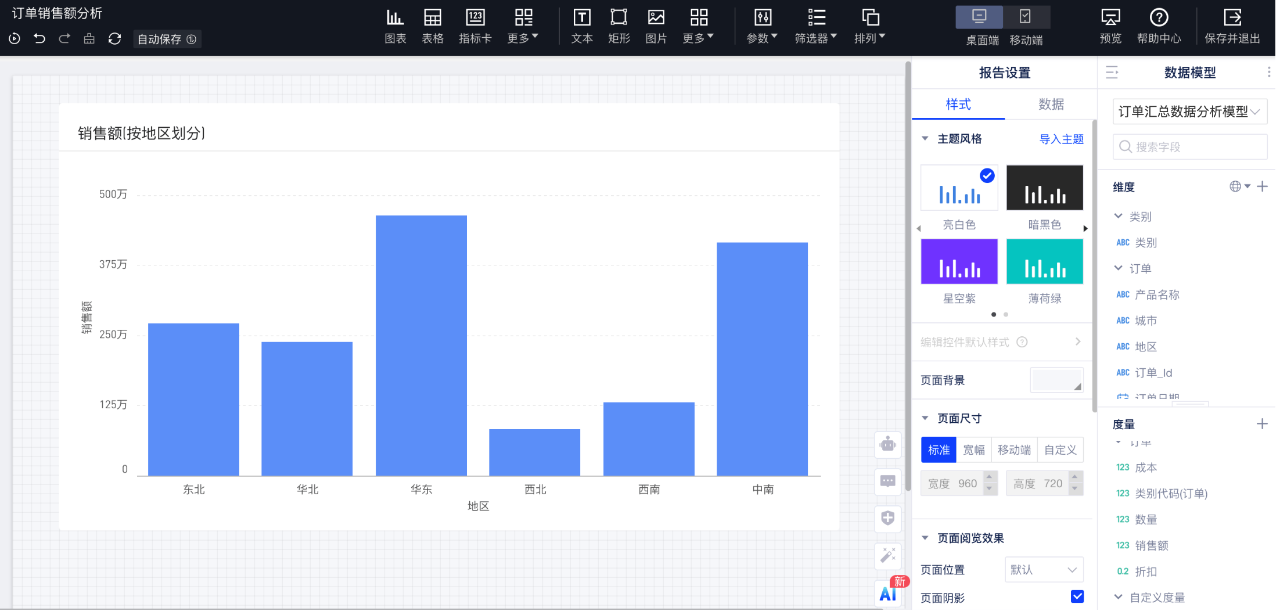
第六步:查看全链路血缘图
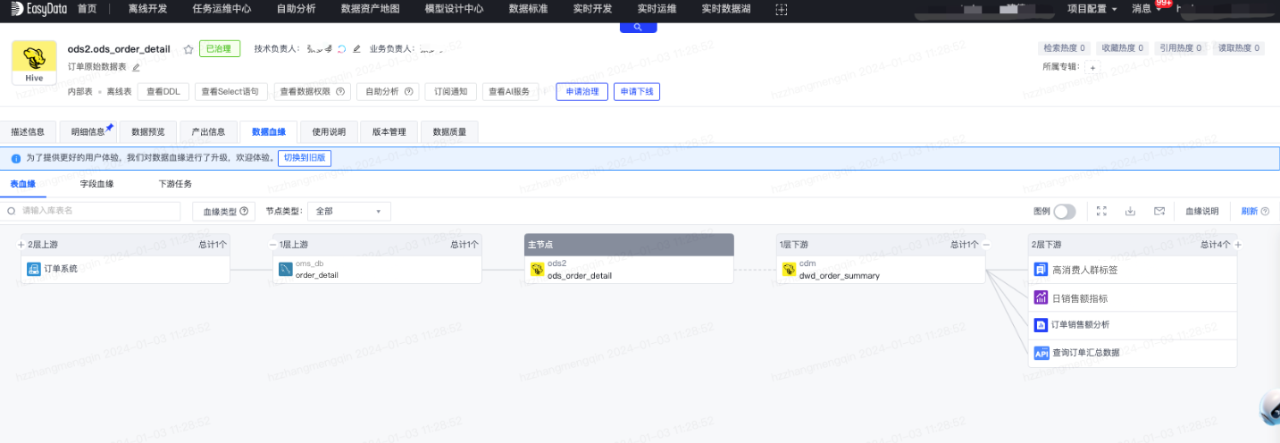
通过以上步骤,基本已经完成了从源端业务系统到表、表间数据加工、表和指标关联、表和标签关联、表生成API、表生成报表的全链路血缘构建,完整的血缘图展示如下:
04 写在最后
在实际数据生产过程中,由于业务的复杂性高、数据来源广、数据应用场景多,血缘图会更加的错综复杂,上述案例只是一个精简的数据链路,目的是介绍全链路血缘中的关键节点要素。在推进全链路血缘的过程中,我们也在思考一些问题,怎样保障数据血缘的准确度、怎么评估血缘的覆盖率、怎样将数据血缘价值最大化等等。
围绕数据血缘领域,我们也实现了手工血缘、字段血缘、血缘下载、血缘OpenAPI等能力,也落地了一套血缘覆盖率统计规则,如果您对以上内容或者其他数据血缘相关内容感兴趣可以在评论区留言,小编可根据大家反馈情况考虑后期继续发表血缘相关文章,期待和您分享哦~