网易基于DataOps构建数据生产流水线
01 DataOps相关介绍
1. DataOps背景介绍
首先分享一下DataOps的背景。DataOps概念最早在2014年由国外学者提出,随后业界逐步对其内涵进行补充。2018年DataOps正式被纳入Gartner的数据管理技术成熟度曲线当中,由此进入了国际的视野。2022年中国信通院正式牵头成立了DataOps能力标准工作组,以此为基础推动我国大数据产业的多元发展,助力企业完成数智化蜕变。
网易数帆在2023年3月28日与中国信通院共同成立了DataOps创新孵化基地,共同进行DataOps的标准制定以及相关探索。
对于DataOps,不同的企业或个人有着不同的理解:
Gartner:DataOps是一种协作性的数据管理实践,专注于改善整个组织的数据管理者和消费者之间的沟通、整合和数据流的自动化。
IBM:DataOps是人员、流程和技术的有机结合,用于快速向数据公民提供可信的高质量数据。
维基:DataOps是一套实践、流程和技术,将综合的、面向流程的数据观点与敏捷软件工程中的自动化和方法相结合,以提高质量、速度和协作,然后促进数据分析领域的持续改进文化。
自2018年被Gartner纳入数据管理技术成熟度曲线以来,DataOps热度逐年上升,在2022年达到关注顶峰,预计未来2-5年DataOps将得到广泛的实践应用。
2. DataOps解决的问题
网易很早就开始了DataOps的探索,并形成了一定的积累。DataOps要解决很多问题。比如:
人工依赖度高:过度依赖人工经验、过度依赖人工决策。
需求响应慢:数据需求提出量暴增、需求提出的质量低。
开发效能不足:数据开发运营运维流程浪费严重、数据工作流割裂。
团队协作难:工具系统多、团队链路长、沟通成本高。
管理有缺失:效能管理缺失、DT一体化管理缺失。
02 网易大数据概述
1. ⽹易⼤数据的发展历史
在介绍网易大数据对DataOps的探索之前,先来简单介绍一下网易大数据的情况:
2006年:分布式数据库、分布式⽂件系统、分布式搜索引擎,三驾⻢⻋⽀撑了⽹易互联⽹2.0时代。
2009年:开始基于Hadoop做数据分析以及运维。
2014年:大数据平台猛犸、⽹易有数上线,加速了⼤数据规模化应⽤。
2017年:网易大数据正式对外商业化。
2018年:网易严选、考拉、⾳乐、新闻等业务相继开始数据中台构建,⽹易发布“全链路数据中台” 解决⽅案。
2020年:网易提出“数据⽣产⼒”理念,倡导“⼈⼈⽤数据、时时用数据”。
2022年:⽹易发布数据治理和数据开发⼀体化“数据治理 2.0”解决⽅案。
2.网易大数据产品矩阵
到目前为止网易大数据形成了丰富的产品矩阵,从最底层的数据计算、存储,再到上层的基于DataOps的全生命周期数据开发,在数据生命周期开发里面包含数据集成、数据开发、数据测试、运维等基础能力,基于DataOps全生命周期数据开发之上,搭建了一系列数据治理产品体系,包括数据地图、数据质量、数据标准、模型设计、数据资产等数据治理方面的能力,在数据治理能力之上,还有对应的数据报表、机器学习平台、CDP标签画像等能力。

3.⽹易⼤数据的客户
网易目前服务了一系列客户,包括金融、券商、银行、教育、传统制造业等。在持续服务客户的过程中,也逐渐发现客户们在数据开发、数据中台建设存在的各种问题,网易也在持续地解决、优化,从而让整个数据开发链路更加高效,同时提升数据开发质量。
03 为什么需要DataOps流水线
1. 一些教训及原因
为什么需要DataOps流水线,首先来看一些教训:
在某电商业务中,业务三单有礼,因为上游任务变更,导致下游涉及资损数据计算异常,造成P1级别>30W的生产事故。
在某电商业务中,由于订单标签任务依赖配置缺失,下游任务空跑造成数据异常,给⽼客发了红包,造成P1级别> 20W的资损。
我们在内部做过统计,因为数据开发任务变更导致的⽣产环境数据问题占比达到65%。
2. 为什么会出现这些问题?
出现这些问题的原因有如下几点:
缺少全链路影响分析:任务依赖复杂,某客户有9540个任务依赖上游,下游任务有17层任务依赖,数据开发在变更任务的时候,根本不知道下游涉及的影响。
缺少发布管控:任务的发布缺少发布审核,涉及核心资产的任务变更缺少管控。任务发布上线更改随意,没有经过发布审核,Code Review相关环节,甚⾄核⼼任务变更,相关负责⼈都不知道。
缺少⾃动化数据测试:任务变更缺少数据测试,因为缺少⾃动化⼯具的⽀撑,导致很多任务,未经过严格的数据测试,甚⾄有16%的任务都未运⾏过,就提交上线,最终导致⽣产事故发⽣。
任务依赖容易缺失:任务依赖容易缺失,任务依赖配置复杂,很容易造成缺失,任务空跑,最终下游数据出错。
3.⼤数据平台的DataOps
网易数帆认为,DataOps是⼀种将软件⼯程CI/CD的⽅法融⼊数据开发的流程,基于⾃动化的数据测试、任务发布等技术,构建数据发布流⽔线,使得数据开发效率更⾼、交付更加频繁,交付质量更有保障。
DataOps要解决的问题:
研发过程中需求频繁变化的情况下,确保数据的质量。
数据开发人员能够更快速地分阶段完成数据开发,阶段性成果能够更快速地被验证。
通过引⼊数据测试,让数据质量通过系统工具得到保障。
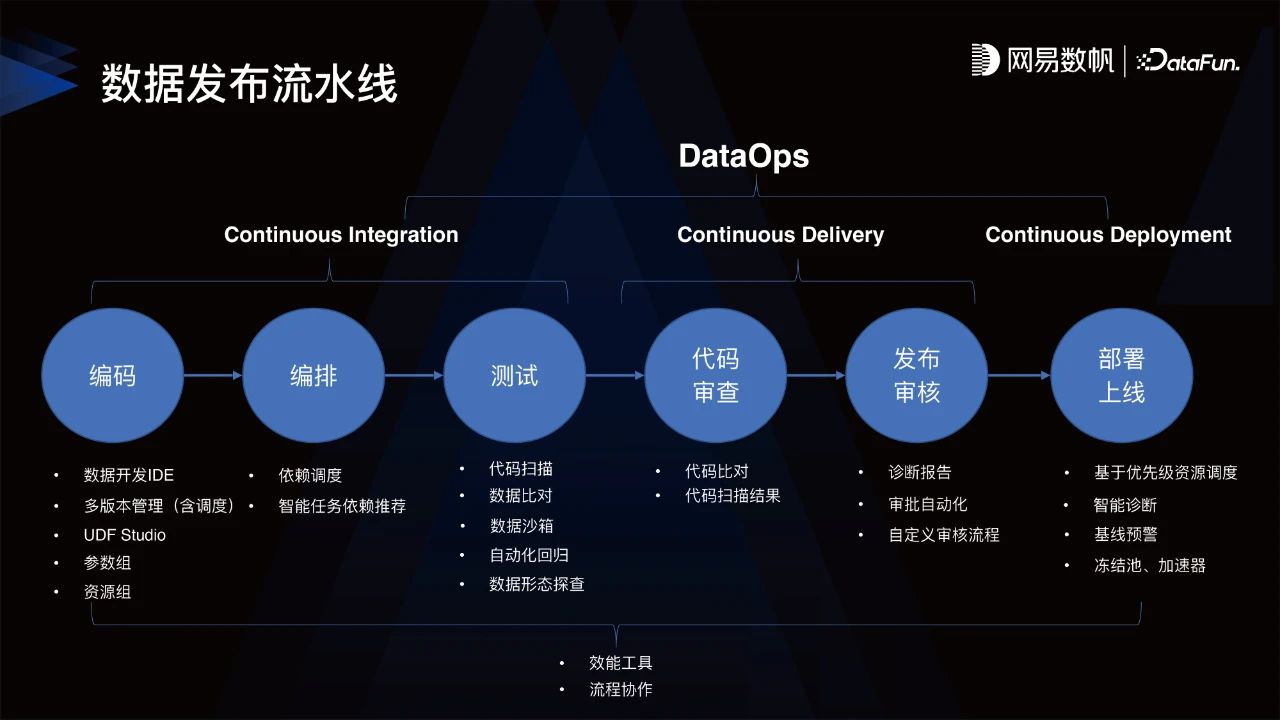
4.数据发布流水线
在网易内部形成了数据发布流水线,包括编码、编排、测试,代码审查、发布审核和运维这6个阶段。
编码:数据开发人员做数据开发等工作。
编排:构建任务的依赖推荐等。
测试:一是测试代码本身有无问题;二是对产出的数据进行高效快速的测试。
代码审查:由架构师等角色帮助数据开发人员提前发现所写代码的问题。
发布审核:除了代码层面上的审核,还涉及到配置、增删等,最终确定任务是否允许提交到线上。
部署上线:运维层面最理想的状况是线上不要出错,但是如果真的出了错,那就需要有相应的平台能力让问题能更快的得到解决。
04 流水线的六个环节详解
1. 环节⼀:编码
编码主要是进行数据处理任务的代码编写。
对于数据团队而言,通常都会根据主题域的划分,由不同人员进行不同主题域的数据建设。在建设过程中有常见场景,最典型的有数据加工新业务,或者基于成熟业务进行分析或根据运营人员的新指标需求进行老任务修改,无论新任务还是老任务,都会涉及到代码编写需求。另外还有任务回滚场景。
对于DataOps而言,最核心的是解决效率问题,提供目录检索和定位等能力;第二是在代码编辑时,DataOps能够助力快速编写,比如自动联想、错误提醒、语法高亮等能力;还有在任务回滚场景中,提供多版本管理能力以及回滚机制。

除了上述在编码过程中的快速定位等能力之外,还需要数据开发过程中的公共产品能力,比如公共的参数组、资源组、UDF。这些对应能力也应该是作为DataOps在编码阶段所具备的能力。

2.环节⼆:编排
编排,主要内容是构建任务依赖DAG。
任务通常都不是孤立的,而是基于数仓等理念做分层建设,涉及到不同任务之间、不同表之间有不同的分层访问,对应有不同任务的依赖。
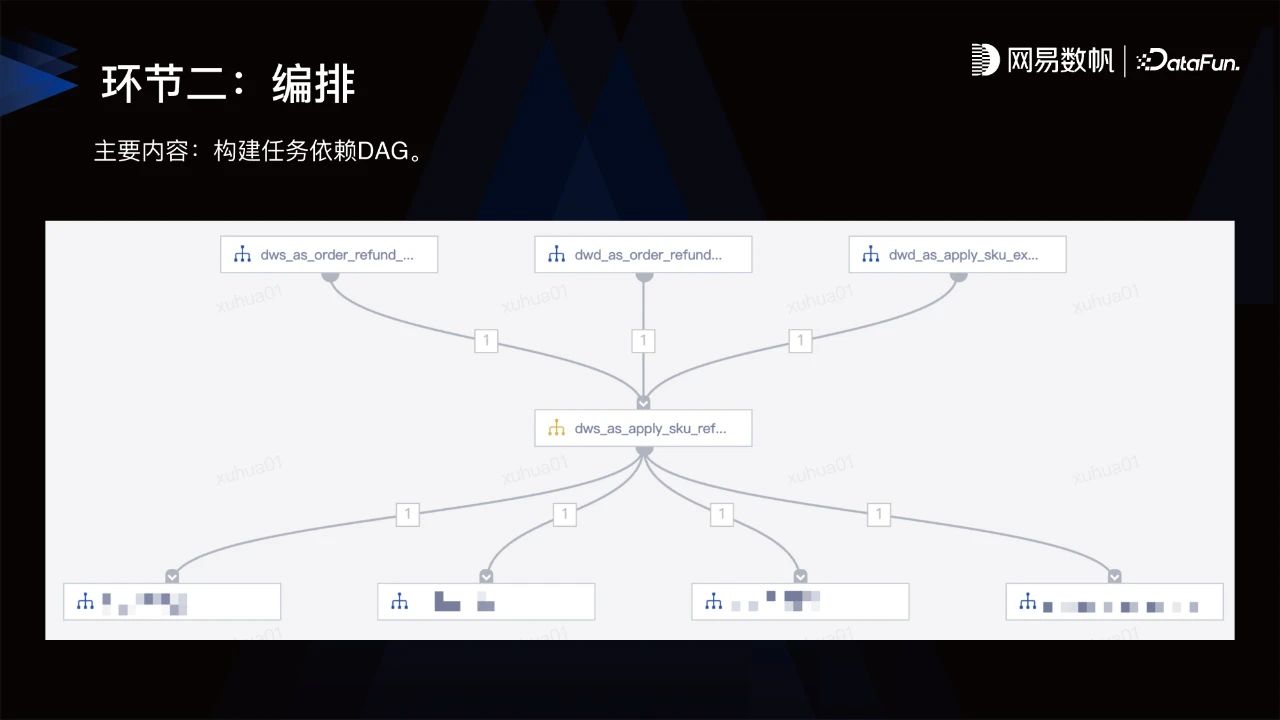
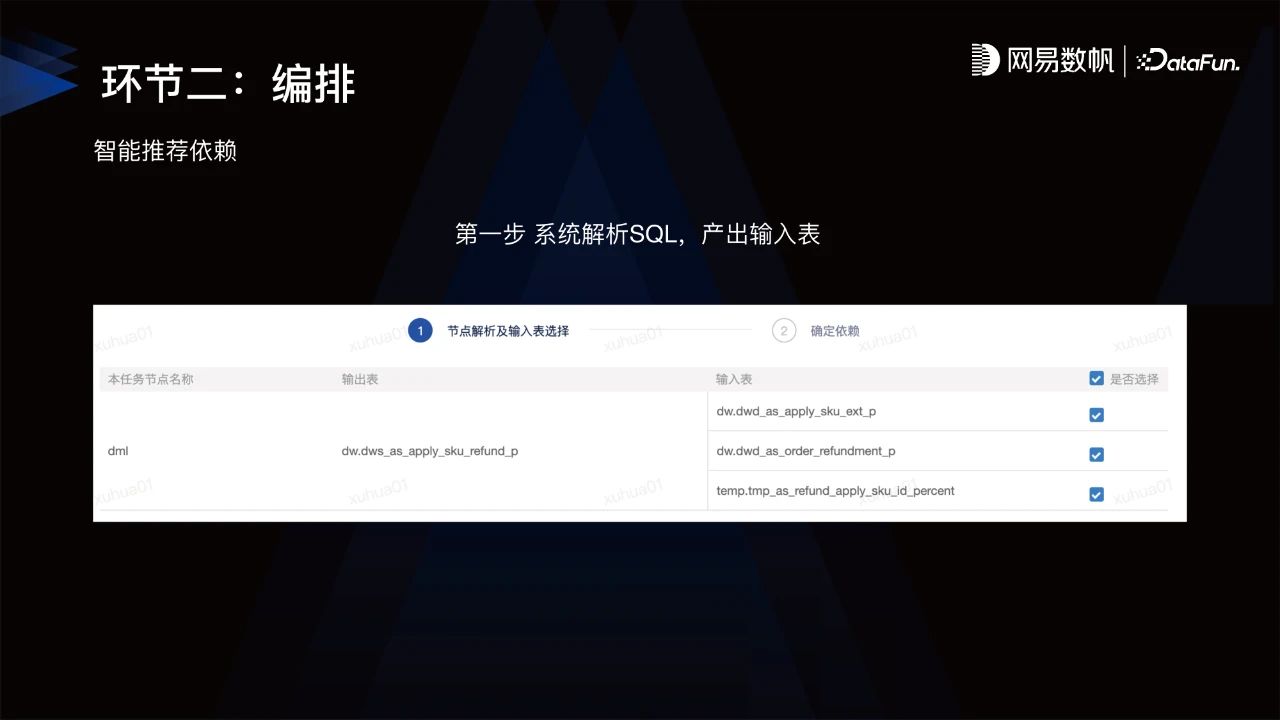
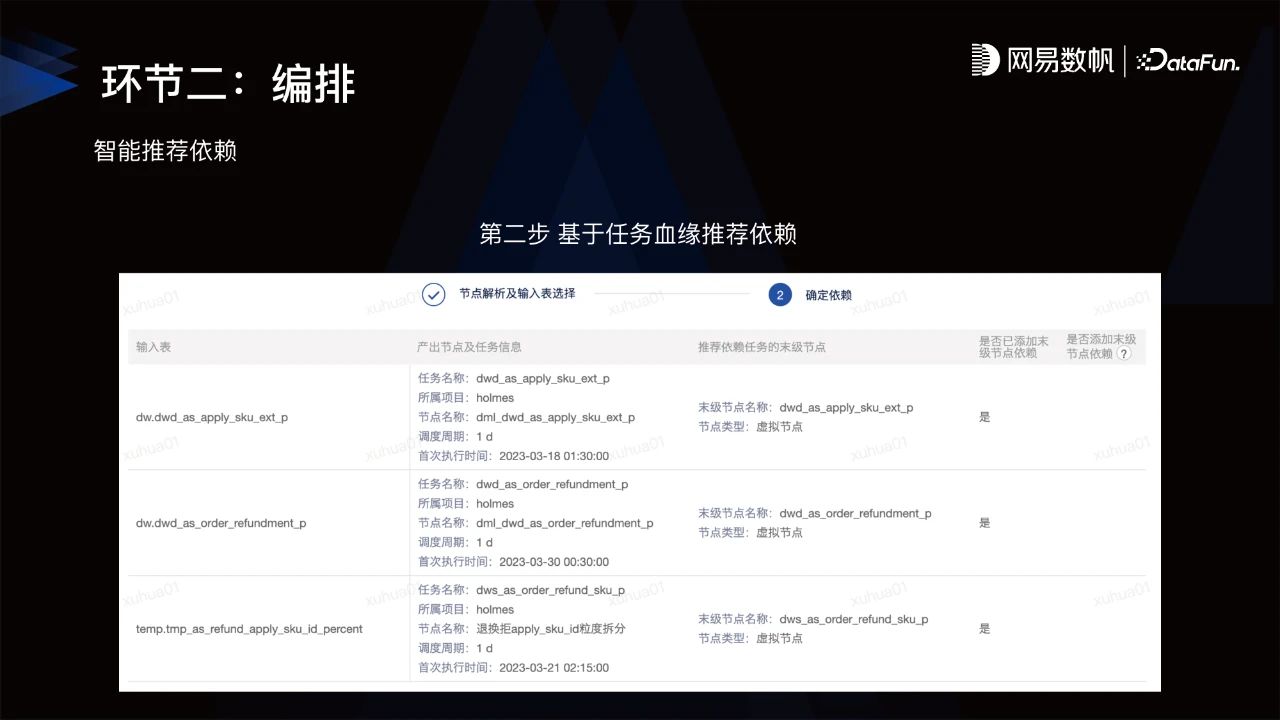
在编排方面,最主要的是能够快速帮助数据开发人员构建任务依赖DAG,网易探索出智能推荐依赖能力。第一步,系统解析数据开发人员所编写的代码,产出输入表;第二步,基于输入表根据任务血源推荐依赖,让用户不需要手动浏览代码,就可一键快速完成DAG的构建,大大降低因为依赖缺失所带来的风险。
3.环节三:测试
完成DAG构建后,需要进行数据测试。在测试中,可能会遇到各种问题:
关于源头表数据质量:需要使⽤ODS源头表进⾏数据处理,探查源头表有无问题,比如探查表组件的唯一性、某些字段的枚举值、分布空值比率等,这种人工探查的成本非常高。
关于修改历史任务:修改原有任务逻辑,需要新建测试表,修改代码。
关于表模型重构:⽼的表下游需要迁移。虽然是低频行为,但遇到则是非常大的挑战。
关于团队新⼈:代码⽔平不过硬,未测试就上线等问题。
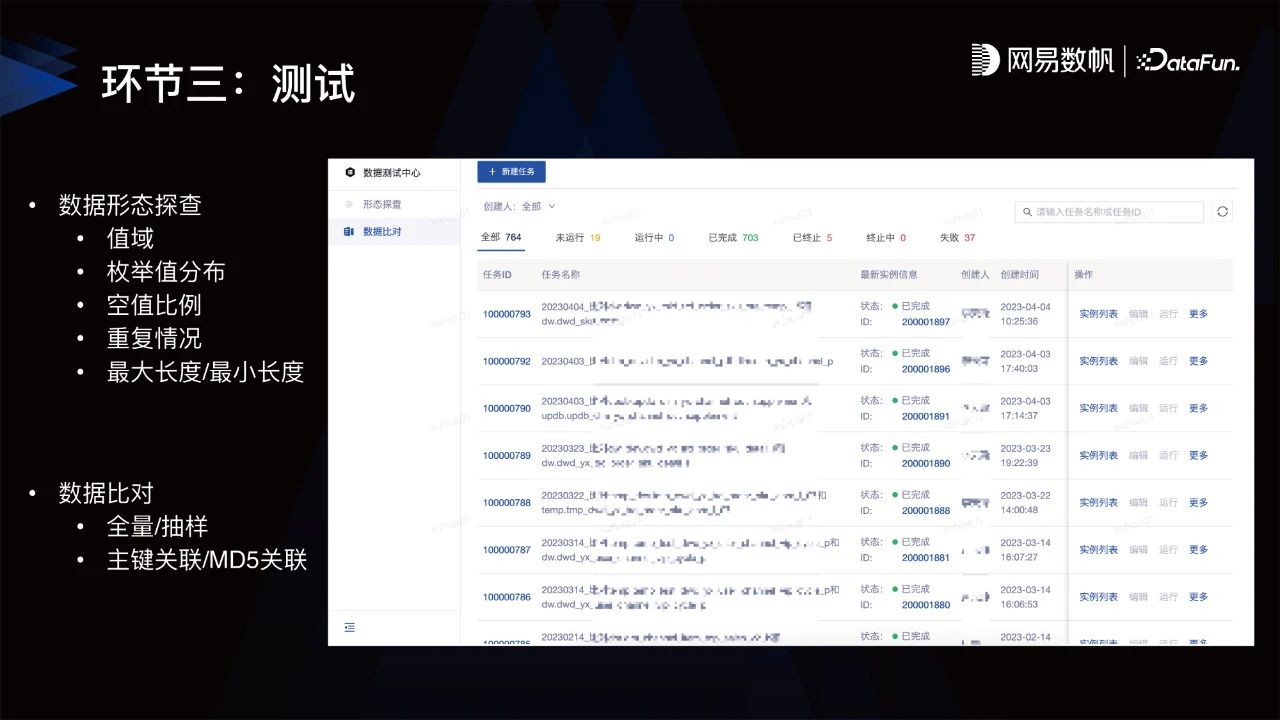
针对这些问题,网易数据平台沉淀了对应的5项能力,分别是数据形态探查、数据比对、数据沙箱、代码扫描和强制测试。

数据形态探查:针对一份数据,探查值域、枚举值分布、空值⽐例、重复情况、最⼤⻓度/最⼩⻓度等。
数据比对:比如在模型重构的下游迁移场景,需要下游信任新的模型数据;还有一些可能涉及财报的核心数据模型修改,不能影响到其他数据。这些情况都可以用到数据对比。通过全量/抽样、主键关联/MD5关联等方式完成两张数据表的数据比对,产出比对报告后推动下游数据迁移。
数据沙箱:下方右图是数据平台沙箱架构,上层是数据开发平台和调度系统,下面是开发模式和线上模式。⽣产、测试物理集群隔离,互不影响。开发模式下,从⽣产和测试集群下读取数据,写⼊到测试集群。线上模式下,⽆法从测试集群读取⽣产数据,写⼊⽣产集群,避免⽣产集群数据被污染。开发集群和⽣产集群,⼀套代码,直接运⾏,不需要发布修改代码。

代码扫描:帮助数据开发人员更快速提前发现问题,比如代码规范类、代码质量类、代码性能类、⾃定义规则、其它规则等问题。
4.环节四:代码审查
在数据开发过程中,很多规则无法通过产品化实现。比如,业务逻辑无法通过代码扫描支撑住,还有一些代码扫描出来的弱规则需要人工check。数据团队架构师,或相对资深的数据开发⼈员,或者数据开发交叉审查。代码审查内容包括:业务逻辑、数仓规范、安全问题、性能问题。另外在审查过程中,还有代码比对能力,代码比对有差异高量显示,可以提高审批人员的审批效率。

5.环节五:发布审核
在完成代码审查后,任务正式上线时,可以通过⼯单流转审批,验证任务的各项配置。需要回答5个问题:
审什么:任务包括SQL代码、调度配置、依赖、输出结果表。
谁来审:一级审批人QA,二级审批人数据架构师。
审批依据:主要根据诊断报告、下游影响、数据准确性作为依据。
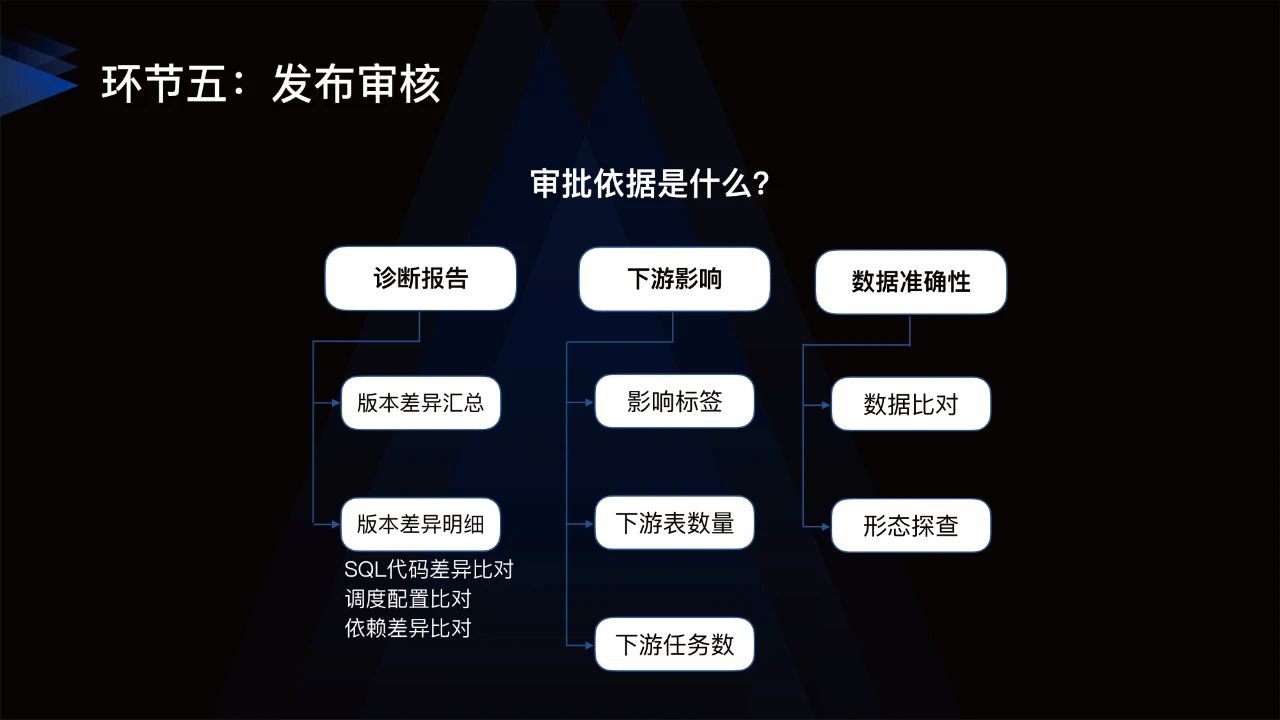
审批任务范围怎么确定:通过文件夹圈定的方式直接指定;基于产出的影响圈定任务范围;基于任务修改规则命中任务范围。

怎样节约审批者的时间:对应的自动审批能力。比如轻度修改、白名单机制、无下游的影响,都可启用自动审批。
6.环节六:部署上线
网易数帆不断探索希望能够助力运维更高效、更简单。
基于优先级的调度:需要Yarn集群为CS调度;⽀持L1-L4共4级优先级;⽀持临时调整为更⾼的L5~L6级。
基线预警:⽀持天、周、⽉调度任务设置基线;⽀持预警、预计破线、已破线、任务失败报警。
加速器:圈定的任务可运⾏,其它任务冻结。
智能诊断:任务运⾏失败快速定位问题,给出解决⽅案。
冻结池:⼀键冻结异常任务及所有下游;⼀键重跑所有被冻结任务。

以上就是网易数帆DataOps流⽔线的六个环节。网易和几百个客户会持续交流在使用过程中发现的问题,并持续完善DataOps流程。
05 两条流水线的探索
最后再介绍一下两条流水线的探索。
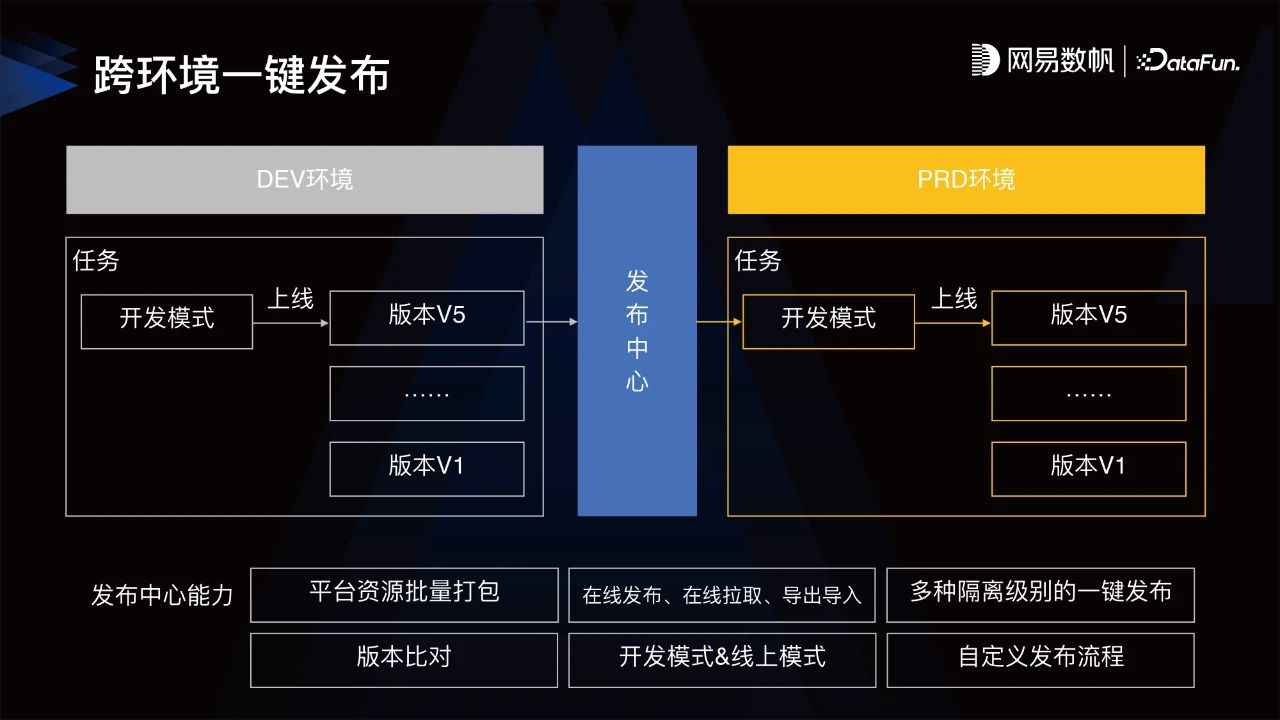
金融领域客户提出需要多套环境满足测试、生产等多环境的隔离要求,目前网易在做发布中心的能力,能够实现任务从一个平台发布到另一个平台。
发布中心的能力包括:
平台资源批量打包:将多种任务如传输任务、质量监控任务、资源组、参数组等进行批量打包的能力。
在线发布、在线拉取、导出导⼊:分别适配不同网络隔离要求的客户,能够实现从一个环境把对应的资源发布到另一个环境。
多种隔离级别的⼀键发布:发布中心也可以通过多种环境一键发布方式在不同的隔离级别都实现一键发布。
版本比对:任务发布时,可对开发模式资源和线上模式资源进行比对。
开发模式&线上模式:开发模式预览、试运行,无问题再到线上模式。
自定义发布流程:支持自定义审批流程等,能够再次增强数据质量提升。