序列推荐系统的前世今生
前言
推荐系统在各种在线平台中有广泛的应用。用户在各种在线平台的行为天然地具有先后顺序,并且用户兴趣也会随着时间发生变化。考虑用户行为的时序关系和兴趣变化可以给用户提供更好的推荐体验。在序列推荐模型发展的过程中,借鉴了很多其他领域的优秀算法。本文大致按照时间顺序,介绍序列推荐模型的发展历程。首先,本文介绍非深度学习方法用于序列推荐的尝试。然后,本文介绍Transformer诞生之前的基于深度学习方法的序列推荐模型,随后介绍基于Transformer架构和其变种的序列推荐模型,最后介绍近期将对比学习用于序列推荐的尝试。
早期非深度学习方法
FPMC
Factorizing Personalized Markov Chains for Next-Basket Recommendation. WWW 2010.
尽管FPMC是比较早期的非深度学习方法,还是经常被各种新序列推荐模型的作为比较方法,所以放在这里作为我们的开篇。FPMC运用了非常经典的思想,和矩阵分解(MF)有异曲同工之妙。
FPMC是矩阵分解和马尔可夫链分解的结合。在FPMC中,作者假设每一时刻用户可能和多个物品交互,同一用户同一时刻交互的所有物品,就构成了一个basket. 在FPMC中,作者使用用户ID和当前时刻用户交互过的物品ID预测下一时刻用户将要交互的物品。可以认为,在FPMC中,作者仅使用了用户最近交互过的物品作为用户的行为序列。
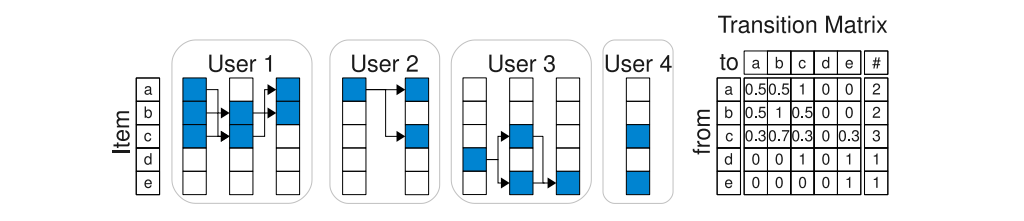
图1:FPMC的物品转移矩阵
作者把用户下一时刻将要交互的物品的得分分解成为两部分,第一部分使用用户本身的特征预测,第二部分使用当前物品预测。第一部分的分数使用矩阵分解计算,等于用户向量和物品向量的点积。第二部分的分数通过物品间的转移矩阵估计得到。FPMC使用类似矩阵分解的方法建模物品间的转移矩阵,使用当前时刻物品的向量和下一时刻物品的向量的点积拟合物品转移矩阵。最终,用户对物品的兴趣分数是这两部分得分的相加。
FPMC使用S-BPR损失训练。S-BPR和BPR损失计算方法基本相同,只是额外考虑了当前时刻用户交互的物品。
Transformer诞生前的深度学习方法
GRU4Rec
Session-based Recommendations with Recurrent Neural Networks. ICLR 2016.
RNN一般被用来建模序列数据,常常被用在自然语言处理(NLP)中。RNN和前馈神经网络的区别是RNN会保存隐藏状态。GRU是为了解决RNN梯度消失问题的一种改进模型。
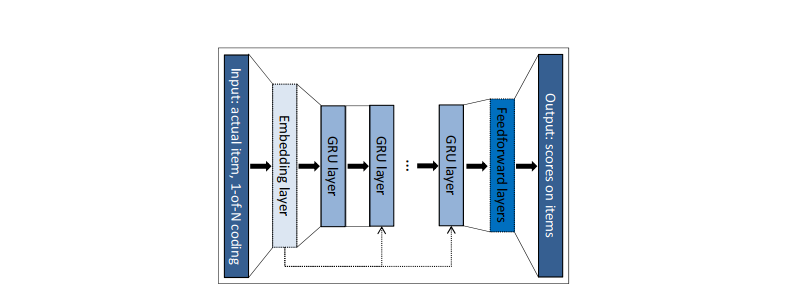
图2:GRU4Rec的模型结构
GRU4Rec的输入为用户的行为序列,通过embedding层后送入到GRU,GRU会在每个时刻预测候选物品的分数。由于不同用户的行为序列长度差异很大,为了充分利用GPU的并行计算能力,作者将比较短的用户序列拼接在一起,合成一个序列,然后多个序列组成batch,进行训练。在训练时,如果一个序列包含了多个用户,会在用户发生变化时,把GRU对应的隐藏状态重置。
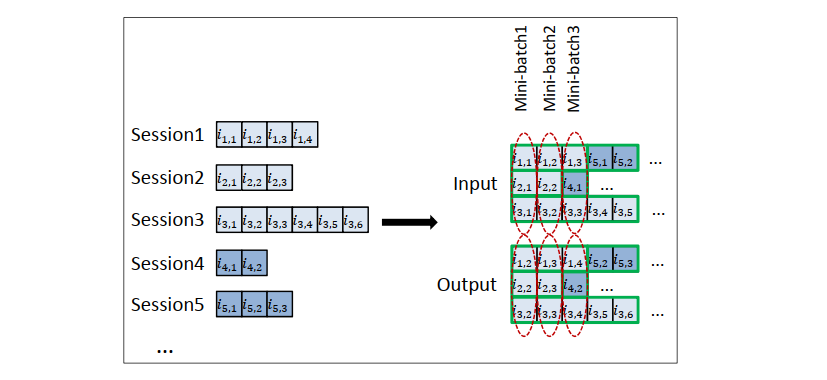
图3: GRU4Rec在构建batch时会把较短的用户行为序列拼成一个比较长的序列
GRU4Rec使用BPR或者由作者提出的TOP1损失训练。TOP1损失通过逼近正样本物品在参考物品中的归一化排序来优化模型。作者未能使用多分类交叉熵稳定地训练模型。在GRU4Rec中,输入层的Embedding和输出层不共享。
GRU4Rec+
Recurrent Neural Networks with Top-k Gains for Session-based Recommendations. CIKM 2018.
在保持GRU4Rec模型结构不变的情况下,新的作者对负采样策略和损失函数进行了改进。模型效果取得了大幅提升。
负采样方面,在GRU4Rec中,作者使用同一个batch中其它用户行为序列对应的目标物品作为负样本。例如每个 batch 有N条用户行为序列,每条用户行为序列对应1个目标物品。这样,每条用户行为序列对应的1个目标物品作为正样本,其他N-1个物品作为负样本。这种采样方法等价于基于流行度采样。在GRU4Rec+中,除了使用当前batch中的其他用户行为序列的目标物品作为负样本以外,作者还同时使用从某个预定义分布中采样得到的物品作为负样本。这个预定义的分布可以是均匀分布或者流行度分布,或者两者的混合。
在损失函数方面,作者通过对多分类交叉熵损失的数值稳定性进行修正,使模型能够使用交叉熵训练,大大提高的模型的效果。作者还提出了TOP1-max和BPR-max损失,效果有进一步提升。
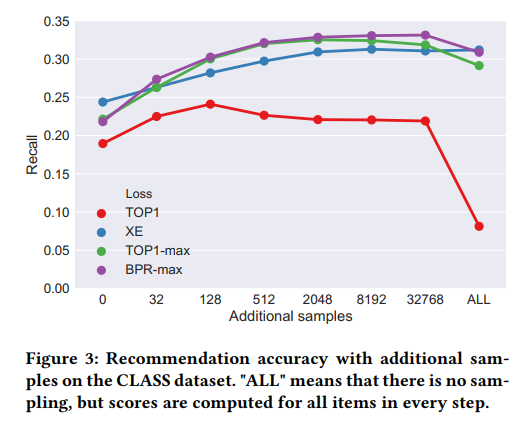
图4: GRU4Rec+中不同损失函数和不同额外负样本数量对模型效果的影响
最后,作者还对NLP中常用weight-tying技术,在序列推荐数据集中做了实验。作者发现,大部分数据集,共享模型输入层和输出层的embedding权重,效果都会提高。除了提高性能之外,通过共享权重,模型的参数也大大减少。因此,默认情况下,当前的序列推荐模型都会使用weight-tying.
Caser
Personalized top-n sequential recommendation via convolutional sequence embedding. WSDM 2018.
既然RNN可以用来学习序列推荐任务。通过将时间作为一个维度,Embedding维度作为另一个维度,看作二维图片,能否用卷积神经网络(CNN)来进行建模呢?在Caser中,作者就使用CNN学习序列推荐任务。
在Caser中,模型使用用户近期交互过的L个物品预测接下可能的交互的T个物品。模型的输入为用户ID和用户交互过的物品ID序列。经过embedding层之后,用户的行为序列变为一个矩阵,一个维度为时间,维度的大小记为L ,一个维度为物品的 embedding维度,维度的大小记为d. 为了方便后续讨论,我们把这个矩阵称为 embedding序列。
模型使用两种卷积滤波器对embedding序列进行处理。一种卷积滤波器只会沿着时间维度滑动,卷积核的尺寸为h × d, h可以是任意小于等于L的数。另一种卷积滤波器只会沿着embedding维度滑动,卷积核的尺寸为L × 1,等价于对每个embedding维度不同时刻的特征进行加权求和。第一种滤波器的输出结果,还会在时间维度进行最大池化,每个滤波器最终得到一个d维向量。所有的滤波器的输出拼接在一起,经过一个全连接层后再和用户embedding拼接在一起,输入预测层,得到在不同物品上的分数。
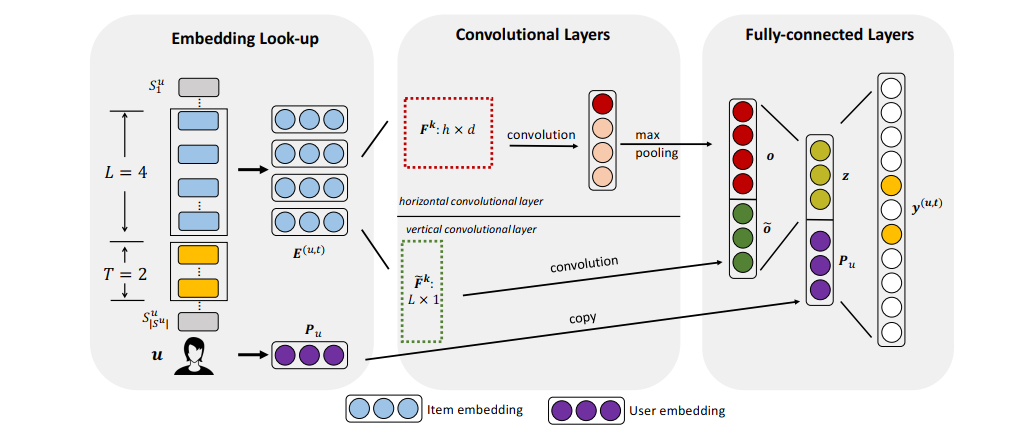
图5: Caser的模型结构
Caser使用二分类交叉熵(BCE)损失训练。
基于Transformer的方法
SASRec
Self-attentive sequential recommendation. ICDM 2018.
2017年,谷歌提出了使用自注意力机制建模自然语言处理任务的模型的Transformer, 在机器翻译任务上取得了杰出的效果。机器翻译是序列输入序列输出的任务。用于机器翻译的Transformer由编码器(Encoder)和解码器(Decoder)组成。使用位置编码协助自注意力机制处理序列中不同元素(称为Token)之前的先后顺序关系。相对于使用RNN处理序列,使用自注意力机制更高效,效果更好。
序列推荐是一个输入序列输出Token的任务,和机器翻译任务有相同点。所以作者在这篇论文中尝试使用自注意力机制解决序列推荐问题。作者只使用Transformer 的解码器部分。自注意力层使用单向注意力。模型的输入为用户最近交互过的物品序列的embedding和可学习的位置编码,预测用户将要交互的下一个物品。这个任务称为下一个物品预测任务(Next Item Prediction Task).
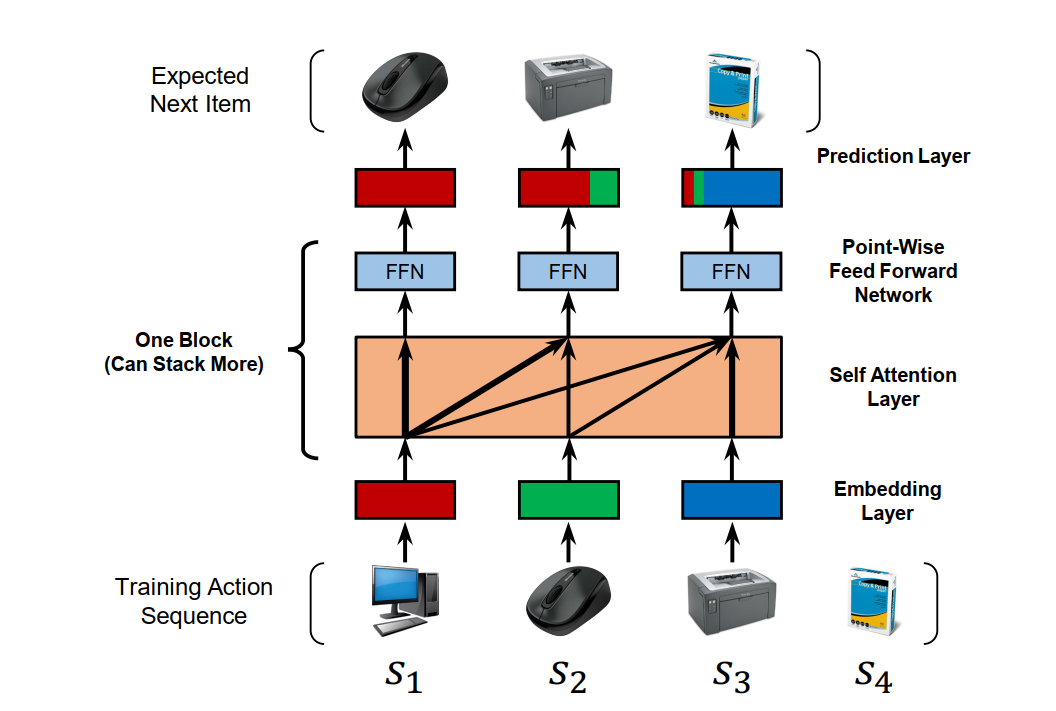
图6: SASRec的模型结构
SASRec使用BCE损失序列,为每一个正样本采样一个负样本。
由于引入了自注意力机制,SASRec在各个数据集上的表现超过了前文提到的所有模型。
BERT4Rec
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. CIKM 2019.
NLP 的经典任务除了预测下一个词,还有完形填空任务(Cloze Task),就是将一个句子中的某个词遮盖住,要求模型从所有词中选出最合适的一个。BERT4Rec就是通过学习完形填空任务进行序列推荐。BERT4Rec使用Transformer编码器和双向注意力。
在BERT4Rec训练时,首先会抽取一个用户的交互物品序列,将其中的部分物品遮盖住,用[Mask]替换,作为模型的输入序列。模型学习预测被遮盖的物品。由于序列推荐的任务是使用用户已经发生的交互物品序列预测接下来用户要交互的物品,因此在推断时,BERT4Rec将[Mask]拼接在用户交互过的物品序列最后,输入模型。模型预测[Mask]位置的物品就是用户将要交互的物品。
由于遮盖物品预测任务(Mask Item Prediction Task)和实际推断时的下一物品预测任务对齐地不是很好,所以模型在训练时还会增加一部分样本,这部分样本只遮盖最后一个物品。
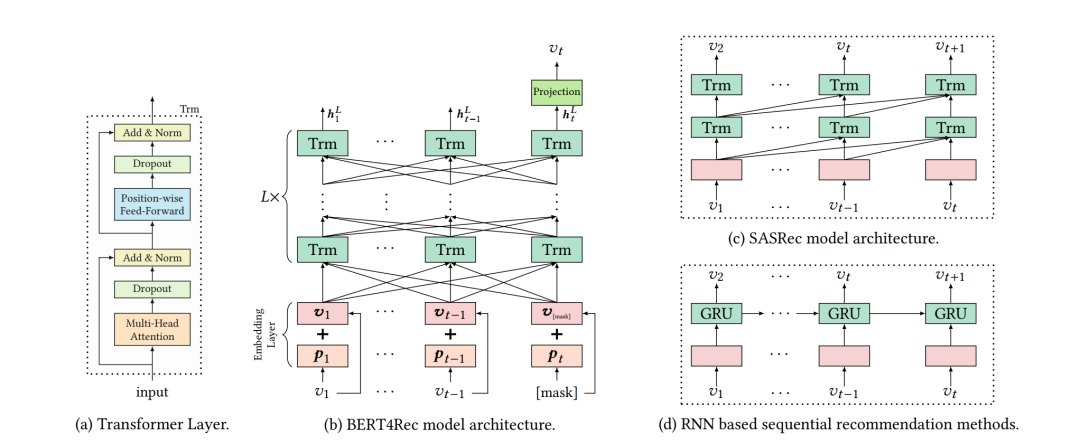
图7: BERT4Rec的模型结构,以及和SASRec等模型结构的对比
BERT4Rec使用多分类交叉熵训练(Categorical Cross Entropy)。除了目标物品外,训练集中的其他物品都作为负样本。
TiSASRec
Time Interval Aware Self-Attention for Sequential Recommendation. WSDM 2020.
用户的行为序列中,除了有交互物品之间的先后顺序信息之外,还有交互物品之间的时间间隔信息。大部分序列推荐模型中,都没有考虑交互物品之间的时间间隔。在TiSASRec中,作者使用相对位置编码(Reletive Positional Encoding)和自注意力机制,显式建模用户行为序列中物品之间的时间间隔和先后顺序。
相对于 SASRec将位置编码和物品Embedding直接在模型输入层相加,TiSASRec在模型自注意力层加入位置编码和时间间隔编码,具体通过在自注意力层计算时,向Key和Value向量中加入位置信息和时间间隔信息实现。以Key计算为例,在计算 Key时,Key会加入时间间隔向量和位置向量。时间间隔向量和位置向量都通过 Emebdding Lookup得到。用户交互过的物品之间的时间间隔是连续值,通过除以一个预先定义好的值再取整变为一个整数,使用这个整数查询时间间隔Embedding表得到时间间隔向量。Value向量计算同理,Value计算时也会加入时间间隔向量和位置向量。不过,Key和Value的时间间隔嵌入矩阵和位置嵌入矩阵是不共享的。
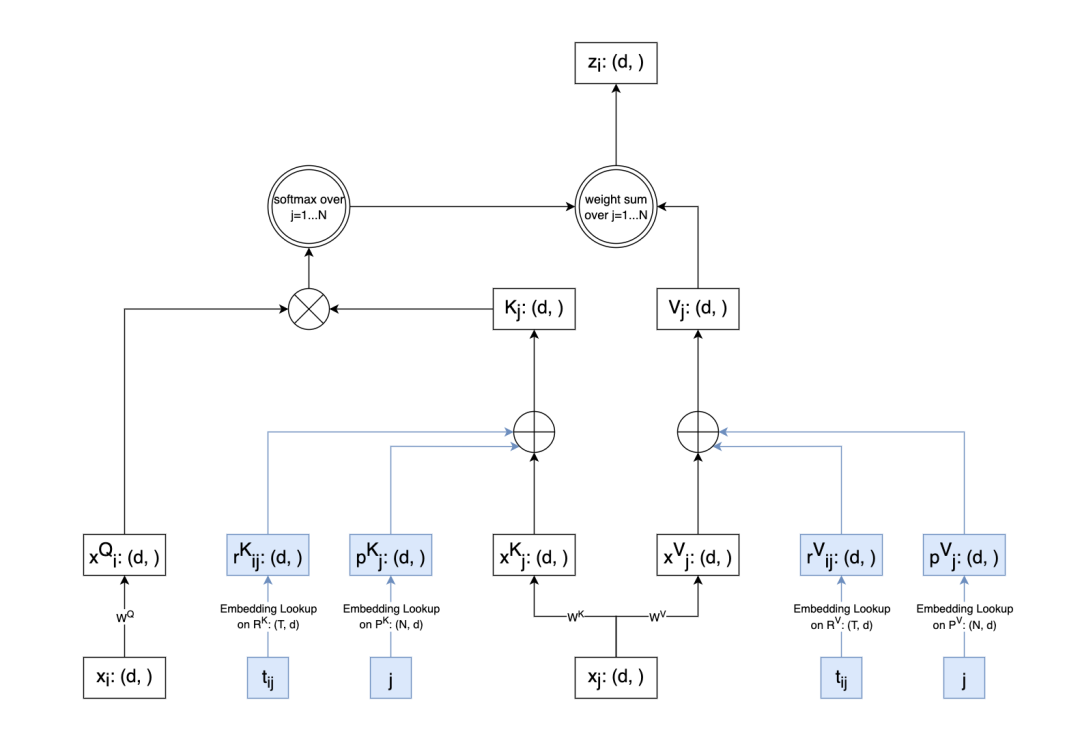
图8: TiSASRec中基于相对位置编码建模用户行为序列中物品交互的时间间隔和先后关系
和SASRec一样,TiSASRec使用单向注意力, 使用BCE损失训练,每一个正样本抽取一个负样本。
由于增加了时间间隔注意力,TiSASRec效果相对于SASRec会有一定提升。
FMLP-Rec
Filter-enhanced MLP is All You Need for Sequential Recommendation. WWW 2022.
Transformer 使用自注意力机制学习不同物品间的相互关系,实现不同位置Token之间的信息交互。除了自注意力机制外,其他方法也可以实现不同Token之间的信息交互。在FMLP-Rec中,作者使用信号处理中的滤波方法对Token序列进行处理。
FMLP-Rec 模型结构整体上和 Transformer 编码器类似,只是对自注意力层进行了替换,新的层称为滤波器层(Filter Layer )。滤波器层首先使用离散傅立叶变换将Token的Embedding序列变换到频域,然后使用可学习的滤波器对频域信号进行滤波处理。数学上,频域滤波就是使用频域信号和滤波器的频域表示相乘(Element-wise Product)。滤波后,使用傅立叶逆变换将频域信号变回时域。使用滤波方法对行为序列Embedding进行处理,具有一定的可解释性。可以理解为对用户行为信号中的不同频率进行过滤或加强。相对于自注意力层O(N^2)的计算复杂度,包含快速傅立叶变换(FFT)的滤波器层的计算复杂度只有O(NlogN),小于自注意力层。
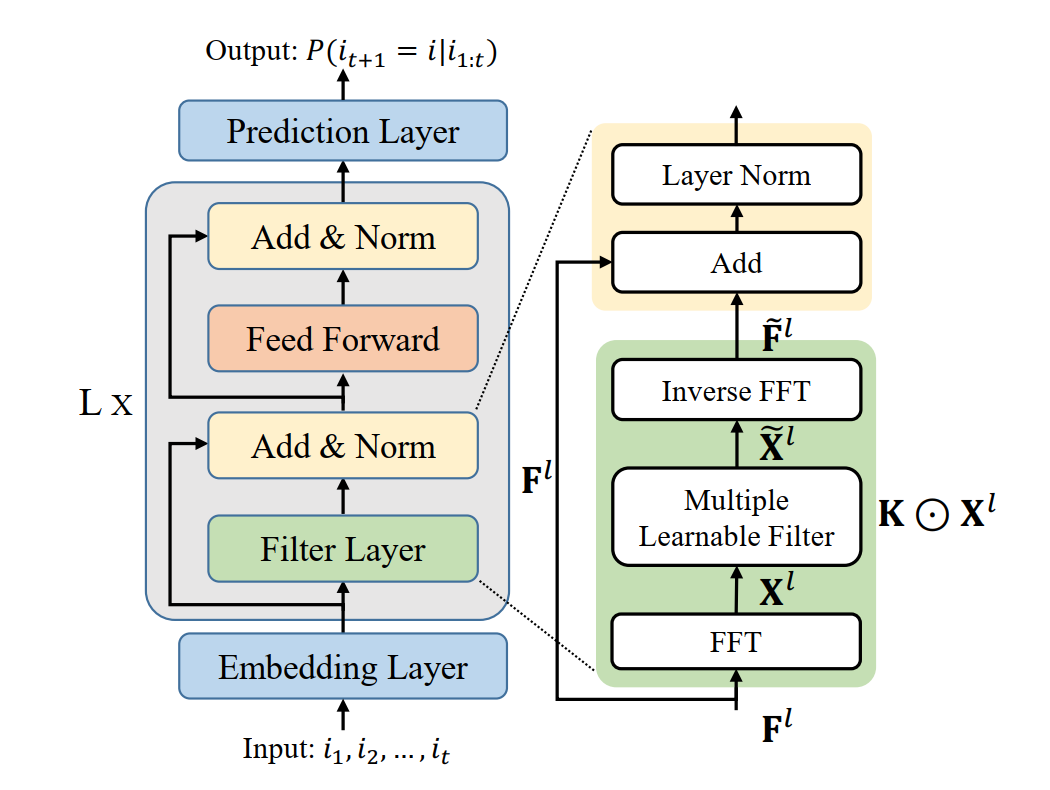
图9: FMLP-Rec的模型结构
FMLP-Rec使用多分类交叉熵训练,训练集中除目标物品和用户交互过的物品以外的所有物品作为负样本。
基于对比学习的方法
CLS4Rec
Contrastive Learning for Sequential Recommendation. SIGIR 2021.
近几年,对比学习在人工智能的其他领域,如计算机视觉中受到了很大的关注。在CLS4Rec中,作者尝试使用对比学习来增强序列推荐的效果。之所以说是增强,是因为,CLS4Rec仍然会学习下一个物品预测任务。在这个任务的基础上,作者增加了对比学习任务。
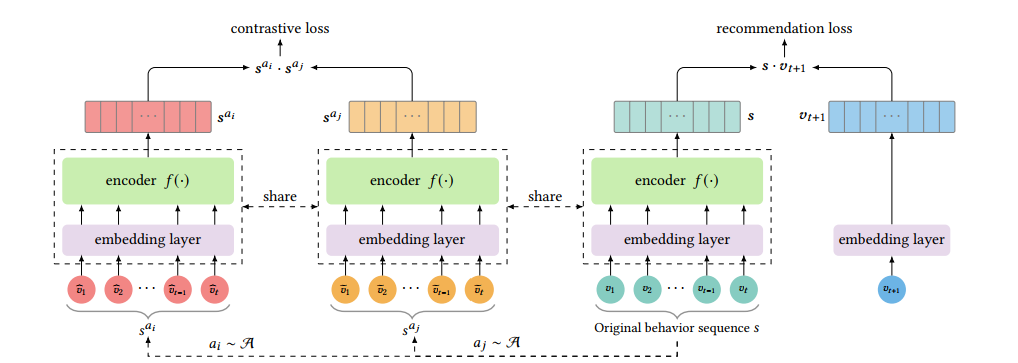
图10: CLS4Rec同时学习对比学习任务和推荐任务
新增的对比学习任务主要首先对每个Batch中的每个用户的行为序列进行小幅度的变换,然后让网络判断变换后序列哪些来源于同一个序列。这个变换可以是物品裁剪(Item Crop),物品遮盖(Item Mask),物品打乱(Item Reorder).文章发现,通过要求序列模型学习判断变换后的序列是否来源于相同的原序列,可以提升模型的效果。但是不同的数据集适合的变换可能不同。

图11: 用于生成对比学习样本的变换
下面介绍论文中涉及到的三种变换和对比损失的计算。物品裁剪是指把用户行为序列中的一部分连续的序列截取出来,和其他变换后的序列比较,计算相似度,判断哪些变换后的序列属于同一用户。物品遮盖是指把用户行为序列中的某一部分物品遮盖起来,用零向量替代。物品打乱是指将用户行为序列中一小段连续几个物品的顺序打乱。计算对比损失时,一个batch包含N个未变换的序列和2N个变换后的序列,即每个未变换的序列生成两个变换后的序列。对于某一个用户变换后的序列,来自相同用户通过不同变换得到的序列作为正类别,其他用户变换后的序列,总共2N-2个作为负类别,组成总共2N-1类的分类问题,模型预测哪一个样本也来自这个用户,使用交叉熵计算对比损失。
作者发现,物品裁剪在多个数据集上都有效果。物品遮盖和物品打乱在部分数据集上可能会有负向作用。
CLS4Rec使用多分类交叉熵学习下一物品预测任务,随机采样的物品作为负样本。对比学习任务损失的权重小于下一物品预测任务损失的权重。
结语
我们从非深度学习方法FPMC出发,首先回顾如何将矩阵分解思想运用到序列推荐。随着深度学习的发展以及在深度学习在自然语言处理和计算机视觉领域展现出非凡的效果,适合这些领域的模型也被改造应用到了序列推荐,取得了不错的效果。 Transformer和自注意力机制的应用则进一步推进了序列推荐的发展。近期,对比学习大热,序列推荐领域也进行了对比学习的尝试,取得了初步的效果。
应用建议
由于当前基于Transformer结构的序列推荐模型已经是主流的序列推荐方法,所以实际应用一般可以考虑SASRec或者SASRec的改进模型。直接选择SASRec,也能取得不错的效果。后续的大部分序列推荐方法都是基于SASRec进行改进,因此,如果从SASRec和BERT4Rec中选一个的话,选择SASRec. 我们上线了SASRec和 FMLP-Rec, 用于网易新闻中视频推荐的召回环节,都取得了一定的效果。

