计算资源vcore的优化不同于内存优化,vcore严重影响着任务的运行效率。如何在保证任务运行效率不变甚至提高的情况下,能进一步优化vcore的利用率?我们需要对任务做出全面的分析,给出不同的优化策略。这篇文章主要围绕任务运行阶段,介绍任务全链路诊断针对任务不同检查项异常给予的优化策略,以及带来的收益。
对于大数据离线任务来说,由于流转服务节点较多、技术栈要求较高、数据采集难度大、指标复杂难懂等一系列原因,造成业务方对任务的掌控力非常差:不清楚异常出现在哪;不确定任务是否可以优化、如何优化。
目前大数据基础设施组开发了一款EasyEagle产品,并通过其中的任务全链路诊断模块,帮助用户去解决上述的问题。
本篇文章大致介绍任务全链路诊断模块,通过部分案例和数据,帮助用户更好的了解该功能模块能带来什么样的收益,以及如何简单的使用。本篇文章仅涉及计算资源vcore的优化,对于异常定位会有其他文章进行介绍。
01 什么是任务全链路诊断?
任务全链路,指的是任务从提交到产出结束,整个生命周期内流转的各个服务、节点的集合。
诊断,指的是将上述整个链路,按照已有的运维经验和特征进行抽象划分,细分成不同检查项进行诊断定位。
总结起来就是:将任务从提交到产出结束(包括各个流转节点以及流转服务),抽象并划分成不同阶段,并对上述各个阶段细分不同的检查项进行诊断定位,提供相关专业化的优化以及解决建议,提高业务方对任务运行过程的掌控,包括任务运行效率的提升以及资源利用率的提升。
02 对业务能产生什么价值?
主要的价值其实就一点:增加业务方对任务的掌控能力。这里的掌控能力主要分以下几个方面:
资源:指的是资源申请和实际使用是否合理,利用率是否正常
效率:任务运行效率是否可以提升,是否可以加快产出
异常定位:异常在哪,如何解决
配置:配置是否合理,不合理的配置如何修改
在目前的系统中,业务方提交任务之后,直至结束,对任务的整个运行完全属于一个摸黑状态。任务全链路诊断就能解决这种摸黑状态,并且提升业务方上述几个方面的掌控能力,达到降本增效的目的。
说到这里,可能有的小伙伴会问,这是真的吗🤔?那我们就直接贴图以及数据来展示~
目前内部我们针对音乐进行了一次任务计算资源的优化,优化时间范围为0-7点(业务高峰期),优化任务数量为前200的任务,总体统计数据均只包含该时间段(0-7点)。
整体优化效果如图:
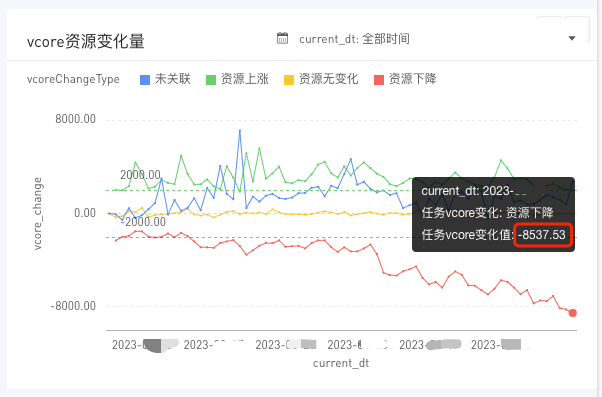
在针对0-7点的前200任务优化后,vcore的资源水位下降如上所示。
对于一个只有5.3w的vcore的集群而言,前200的任务占集群43%的资源,能够达到上述的优化效果,还是非常可观的,并且音乐业务方本身对于任务的优化情况就较好。
单个任务的优化效果如图:
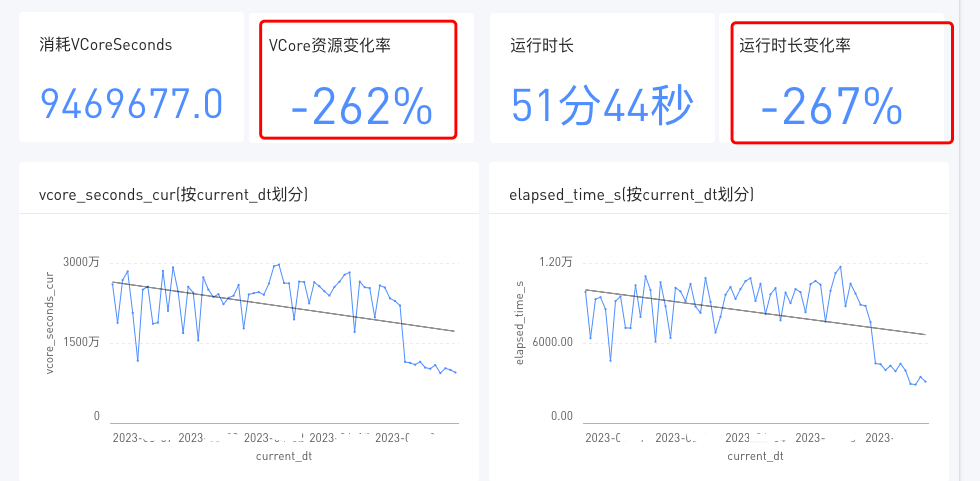
单个任务的优化效果如上所示,不言而喻。
看到这里,小伙伴对于任务全链路诊断这块对于业务方是否能带来收益,是否还有疑问?
03 任务全链路诊断我们是怎么做的?
首先,我们将任务生命周期大致分为三个阶段,如下所示:

任务准备阶段,主要是指资源的初始化、本地化等一系列的前期准备。涉及到yarn的调度、资源、本地节点、hdfs等。
任务运行阶段,主要是指任务按照既定逻辑运行。
任务产出阶段,主要是指任务具体逻辑运行完毕后,数据持久化或其他的一系列操作。涉及到hdfs、metastore等。
针对每个阶段,我们再根据内部运维相关经验以及特征,抽象划分成不同的检查项对其进行诊断。如果诊断出异常,会附加相关的标签。标签会携带异常原因、异常表象、优化建议等。
看到这里,大家可能会有个疑问:任务根据标签按照优化建议优化后,就能加快产出、提高资源的利用率吗?
答案是可以的。因为每个检查项的评判标准都是时长和资源,所有的优化最终的表现都可以通过时长和资源两个维度进行衡量。
下面我们会详细说明下各个阶段的检查项划分。
3.1 任务准备阶段
针对这一阶段,我们对其进行了抽象划分,分为如下各个检查项:
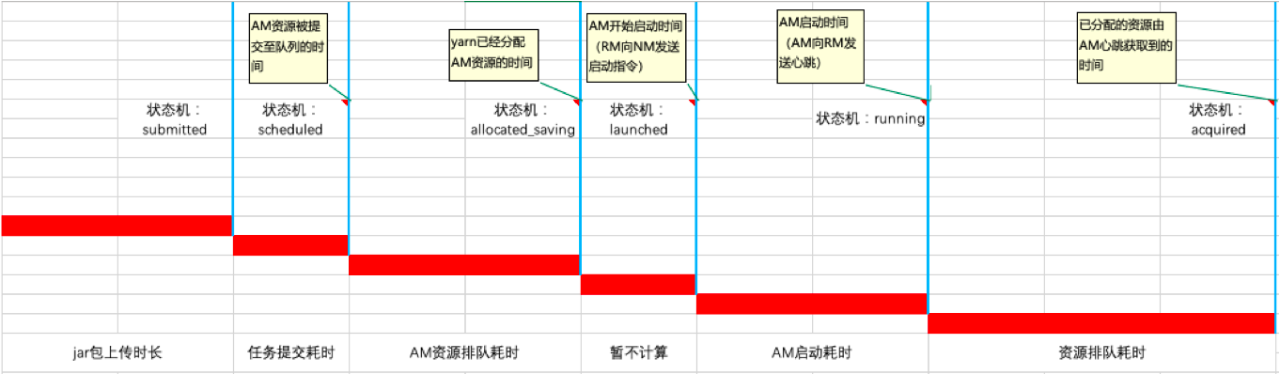
该阶段,我们通过对不同类型container的状态机变化的间隔时长,进行检查项划分。上述的各个检查项,也可以关联相关节点和服务。
在这之前,这个阶段基本上对于所有的业务方来说,甚至开发,都是属于完全不了解、不掌控的阶段。实际监控后,发现很多任务在该阶段都存在问题。
目前在产品中,我们将其检查项提取成4组标签,展示如下:

上述检查项的优化,主要带来的是任务产出时长的优化。这里我们简单的举一个例子来说明下我们是如何做的。
AM分配耗时过长
以AM分配耗时这个检查项为例,判断的依据如下:
获取任务该检查项的耗时
与集群AM分配速率以及该任务此检查项的历史水平进行对比
如发现不匹配集群的分配速率或超出历史统计模型设置的上限,则检查任务提交队列的资源水位
如该队列资源水位已满,则告知业务方由于队列资源不足造成;如该队列资源水位正常,但是AM资源已满,则告知业务方由于AM资源不足造成,建议修改AM资源配比
如该检查项异常,业务方可以根据给出的相关建议进行处理,加快任务的产出。
3.2 任务运行阶段
针对这一阶段,我们也将spark任务进行了一个大概的抽象,如下所示:
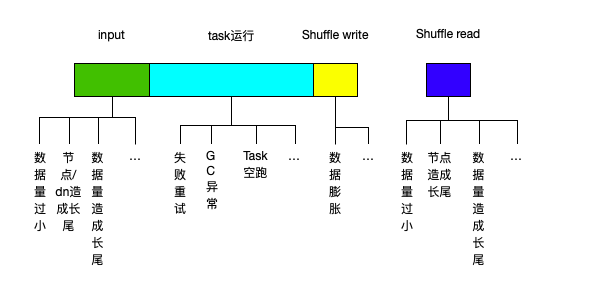
该阶段,我们主要通过实时统计分析spark的event指标进行检查项的诊断。
当前此阶段检查项的划分还处于增长的状态,目前大致已有20余项,部分检查项标签如下所示:

上述检查项的优化,为什么能带来资源利用率的提升以及运行效率的提升?我们以几个简单的检查项来举例说明一下。
(1)Input Task数量检查
该检查项主要是针对input阶段task数量过多,但是input数据量不大的情况(这里不大,是指的小于等于目前我们诊断配置的阈值,一般默认为128Mb)。
在目前生产环境中,我们发现很多input阶段的stage存在10W+的task在运行。这里很多人会认为,这些任务应该会很快产出,任务没啥问题。
但是我们通过实际的数据分析后发现以下规则:
input阶段的stage存在巨量的task,一般会伴随GC检查项异常,GC耗时占整个stage运行时长超过10%以上
相同任务相同阶段的task处理数据量增加,并不会使task的运行时长呈现等比例的增长。因为调度开销以及序列化会有部分消耗,另外input阶段网络以及磁盘IO对task运行时长的影响较大
这种含有巨量task的stage,不可能一轮就能运行完毕
因此针对input阶段的stage,存在巨量的task运行并不是一个很好的主意。
针对该检查项,我们一般会建议用户将spark.sql.files.maxPartitionBytes配置提高,例如由默认的128Mb提高至512Mb。我们可以简单的计算下,大致对于该阶段的stage资源以及时长能节约多少:
原先每个task处理数据量:128Mb
原先input阶段stage的task数量:16w
该任务同时最大task运行数量:2w
原先一轮task运行耗时:t
现每个task处理数据量:512Mb
现input阶段stage的task数量:4w
该任务同时最大task运行数量:2w
数据量增长后,task耗时增长倍数:2.5(数据量提升4倍后,大致为2-3倍的耗时增加)
资源:
该阶段vcore资源下降比例:37.5% = (2w * 16w/2w * t - 2w * 4w/2w * 2.5t) / (2w * 16w/2w * t)
如果算上GC耗时的降低,该阶段vcore资源下降比例应为:40%+
时长:
该阶段运行时长下降比例:37.5% = (16w/2w * t - 4w/2w * 2.5t) / (16w/2w * t)
如果算上GC耗时的降低,该阶段运行时长同样下降比例应为:40%+
(2)ExecutorCores空跑检查
该检查项主要是针对Executor只有少量的core在运行task,其他大量的core在空跑的情况。
在目前的生产环境中,我们发现一些任务存在Executor只有不到一半的core在运行task,其他的core均在空跑。造成这个现象的原因,主要是Spark任务在运行过程中每个Stage的task数量均会变化,若某个Stage的task数量骤减,且该数量小于当前可用的core数量,在认为每个task占用一个core的情况下,会存在大量Exeucotors的core出现空跑。因为在当前生产环境中,一个Executors经常会被分配4个core,若其中只有一个core被占用,那么这个executors既不会被释放,且另外的3个core也处于空跑浪费的情况。
该现象会造成任务大量的占用集群的vcore计算资源,但是却没有使用,降低任务以及该集群的资源利用率。
针对该检查项,我们一般会建议用户将spark.executor.cores降低一半,以及将spark.locality.wait.process配置调大以保证更多的task能分配至一个executor中。我们也可以简单的计算下,该操作大致对于该阶段的stage资源能节约多少:
原该stage运行的executor数量:2000
原每个executor配置的vcore数量:4
现该stage运行的executor数量:2000
现每个executor配置的vcore数量:2
资源:
该阶段vcore资源下降比例:50% = (2000 * 4 - 2000 * 2) / (2000 * 4)
3.3 任务产出阶段
任务产出阶段,目前诊断的比较简单。主要通过数据量、时长的统计,来判断是否存在问题。如果存在问题,关联hdfs以及metastore进行问题的进一步定位。
在此不进一步进行介绍了。
04 业务方是怎么使用这块功能并优化的?
在目前的EasyEagle产品中,业务方进行上述的优化操作其实非常简单。根据任务运行概览中的可优化任务列表展示的优化建议进行相关处理即可,如下所示:

该列表目前暂时只能展示所选标签下的任务列表(已排序,按照该标签打分进行排序)。后续版本将会以任务维度,通过任务运行时长以及资源消耗排序展示任务全部异常标签。
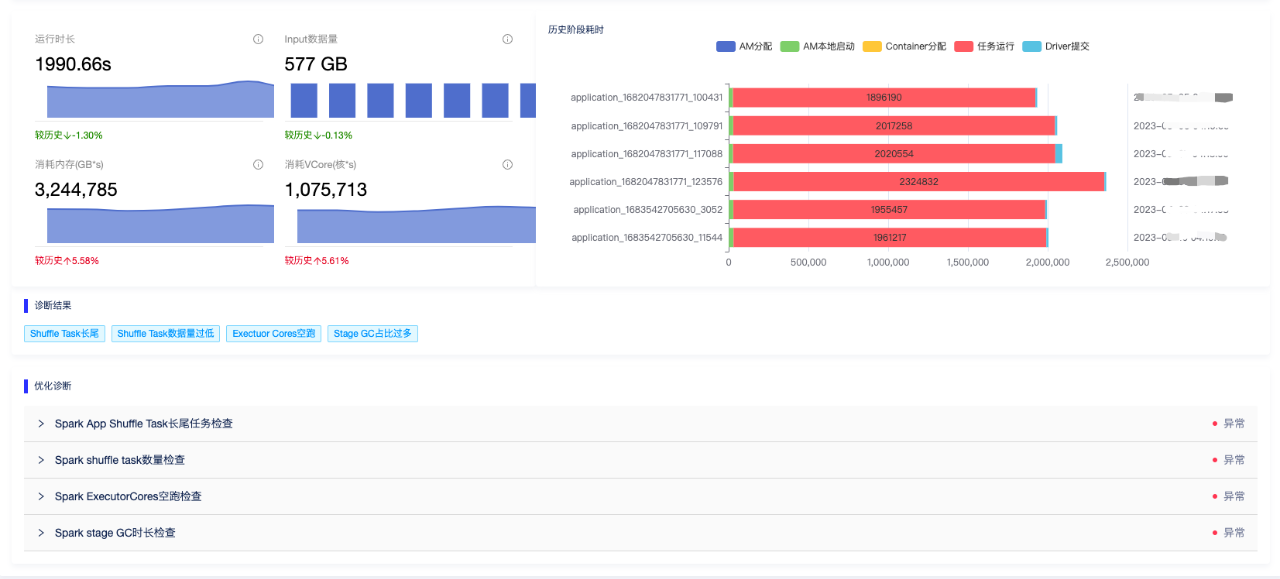
业务方在点击具体app id时,可以跳转至任务的全链路诊断详情页面,该页面会将任务全部的异常检查项进行展示,并会历史相关数据进行对比展示。让用户也进一步了解优化前后的资源、时长情况。
05 背不足思考
业务方的确可以非常方便的通过可优化任务列表获取相关任务以及优化建议,但是优化操作其实对于用户并不友好,需要用户进行手动配置修改。
平台侧对于周期提交的任务,是否可以通过目前我们EasyEagle提供的优化建议,进行自动的配置调优,而不依赖用户手动性的行为?

