实时数仓2.0:更低的成本获取更及时的数据
01# 引言
在爱奇艺的泛娱乐生态矩阵中,数据是驱动业务增长的核心引擎。从视频播放、会员运营到广告推荐,实时数据需求已渗透至业务全链路。例如,用户点击行为需在1分钟内反馈至推荐模型,广告投放需结合实时流量动态调整竞价逻辑。然而,随着业务规模扩大,基于Kafka构建的秒级实时数仓面临显著挑战:高昂的存储与计算成本。
02# 背景
2.1现有架构的成本困境
早期实时数仓采用Lambda架构,通过Kafka+Flink实现秒级数据处理,但其成本是iceberg存储的10倍以上。
具体表现为:
存储限制:Kafka通过保留多副本数据来保障高可用性,但由于其消息队列的存储周期较短(通常仅保留数小时),这使得Kafka无法满足长期数据存储和历史分析的需求。对于需要长时间存储和高效查询的历史数据,Kafka并不是一个理想的存储载体;
资源浪费:实时和离线双链路并行运行,导致了计算资源的冗余。两条数据处理链路在逻辑上重复,尤其是数据清洗和处理过程中的重叠部分,需要分别在实时和离线链路中执行,造成了不必要的资源消耗和代码维护上的复杂性;
业务适配性不足:多数场景仅需分钟级延迟,而秒级实时性成为“过度设计”。
2.2降本增效的技术转型
为解决上述问题,统一引入流批一体架构,以Iceberg数据湖为核心构建分钟级实时数仓,实现成本与效率的平衡:
存储成本降低90%:Iceberg基于HDFS的列式存储与压缩优化,存储成本仅为Kafka的1/10;
时效分级适配:秒级场景仍使用Kafka,分钟级场景迁移至Iceberg,按需分配资源;
数据治理升级:根据业务特点,将大而全的实时数据流,拆解为主题性更强的细流;通过拼接细流,支持不同的业务诉求
这一转型不仅将日均PB级数据的处理成本削减60%,更通过分钟级近实时化改造,将原本小时级或天级更新的数据升级为分钟级近实时化数据,显著提升业务响应速度与决策效率。
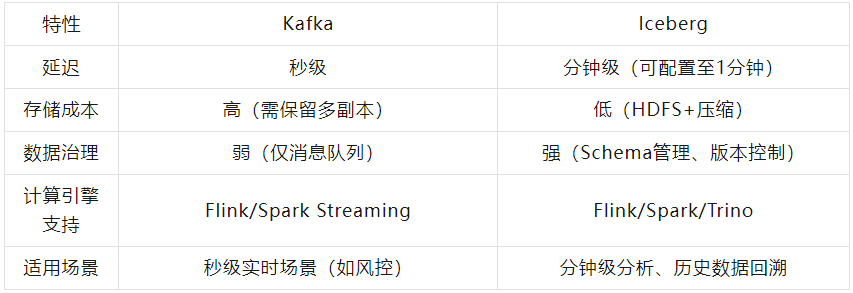
03# Kafka vs Iceberg
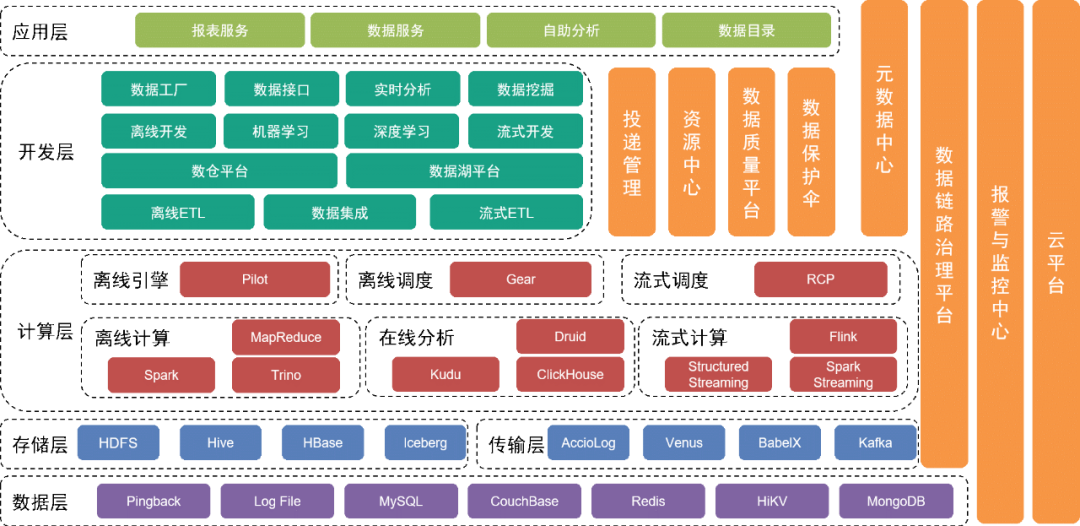
04# 实时数仓2.0架构
4.1架构改造
与kafka相比,Iceberg表具有显著的优势,因为它能够更好地支持行级更新,数据时效性虽然仅是分钟级别。在大部分数据处理场景中,分钟级的数据已经可以满足需求。
因此,我们可以方便地对现有的Lambda架构进行改造,实现流批一体架构:
4.2新老架构成本对比
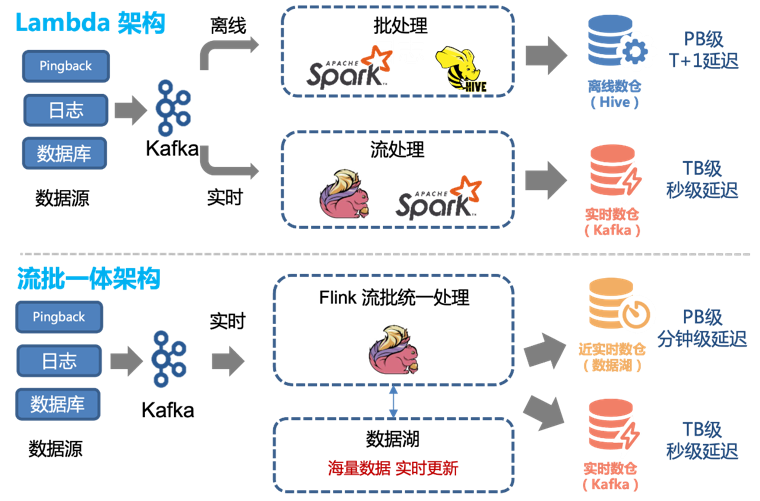
优化过程中,我们主要对DWD层表进行Iceberg改造,并将解析和数据处理加工重构为Flink任务。
为确保改造过程中,数据生产的稳定性和准确性不受影响,我们采取以下措施:
1. 对核心数据着手进行切换,主要是播放业务。
2. 通过对离线解析逻辑进行抽象处理,形成统一的Pingback解析入库SDK,实现了实时与离线的统一部署,使代码更加规范化。
3. Iceberg表以及新的生产流程部署完成后,我们进行了两个月双链路并行运行,并对数据进行常规化对比监测。
4. 确认数据和生产都没有问题后,我们对上层进行无感知切换。
改造后,收益如下:
将原有直接消费源数据的业务切换到消费统一数仓,保证消费流量最小,优化前后节约95%存储资源,计算资源节约50%。同时也能保证数据的安全性。
添加iceberg输出,部分原有消费kafka的任务迁移至消费iceberg,iceberg更易于sql开发者,与hive用法基本一致,方便下游开发。优化前后节约95%存储资源,计算资源基本一致。
原有kafka数据只能保存4小时,切换至iceberg后可以存储一个月或更久。
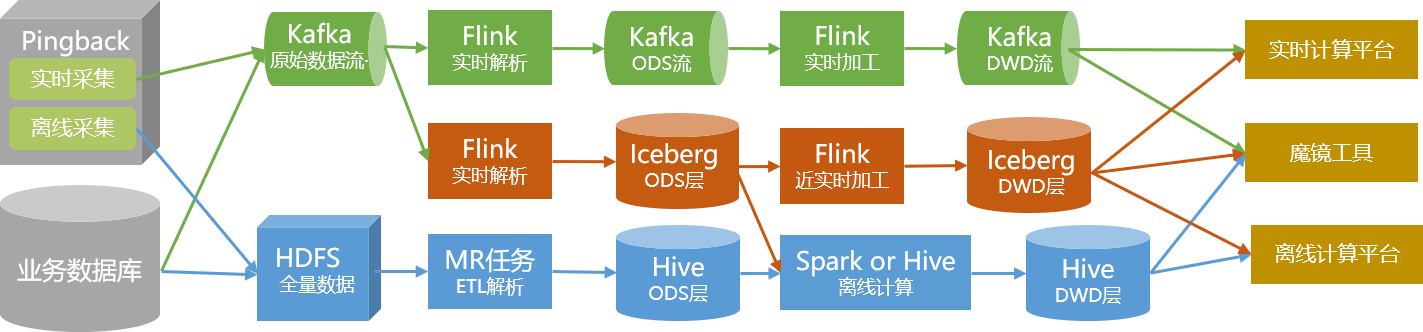
05# 数据链路
在引入数据湖技术之前,我们采用离线处理与实时处理相结合的方式,提供离线数据仓库和实时数据仓库。
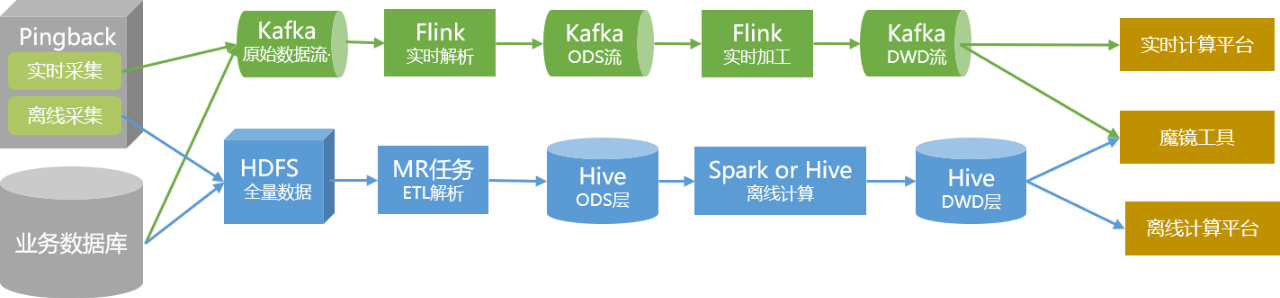
全量数据通过传统的离线解析处理方式,构建成为数仓数据,并以Hive表的形式存储在集群中。对于实时性要求高的数据,我们单独通过实时链路生产,并以Kafka中的Topic的形式提供给用户使用。
然而,这种架构存在以下问题:
实时和离线两条通路需要维护两套不同的代码逻辑。当处理逻辑发生变化时,实时和离线两条通路都需要同时更新,否则会出现数据不一致的情况。
离线链路的小时级更新以及1小时左右的延迟,使得在00:01的数据可能在02:00才能查询到。对于部分实时性要求较高的下游业务来说,这是无法接受的,因此需要支持实时链路。
虽然实时链路的实时性可以达到秒级,但其成本较高。对于大多数使用者来说,五分钟级别的更新已经足够满足需求。同时,Kafka流的消费不如直接操作数据表方便。
针对这些问题,通过使用Iceberg表与流批一体化的数据处理方式,可以较好地解决。
06# 架构升级的收益:成本、效率与业务价值
6.1成本优化:从Kafka到Iceberg的降本实践
原基于Kafka的实时数仓1.0架构中,存储与计算成本高昂成为核心瓶颈。Kafka需保留多副本数据且存储周期短(通常仅数小时),导致日均PB级数据的存储成本是Hive的10倍左右。
升级至Iceberg数据湖后,通过以下方式实现成本大幅降低:
存储成本削减90%:Iceberg基于HDFS的列式存储与压缩优化,存储成本仅为Kafka的1/10;
计算资源复用:流批一体架构下,同一份数据支持Flink流处理与Spark批处理,减少重复计算任务,集群资源利用率提升40%;
长周期数据保留:Iceberg支持历史数据长期存储与回溯,避免因Kafka数据过期导致的重复ETL任务。
效果:节省成本数百万/年
6.2时效性提升:从端到端的数据链路优化
在原有架构下,心跳计时等高实时性需求因成本限制无法实现。例如用户观看时长需在播放结束时批量上报,导致数据延迟达分钟级,影响推荐模型实时反馈能力。
升级后架构通过以下改进提升时效性:
分级时效设计:
秒级场景:保留Kafka链路支撑推荐、UG、广告等强实时需求;
分钟级场景:Iceberg支持1-5分钟延迟,可覆盖90%的实时指标监测场景;
心跳计时支持:借助Flink+Iceberg的增量处理能力,用户行为数据可每秒分片写入,播放时长实现秒级更新,数据反馈速度提升10倍。
6.3业务价值释放案例
播放时长的体现从结束播放切换到心跳流,有效支持用户播放数据的更快反馈,后续可以支持用户行为标签和模型的实时更新、特征和推荐模型的实时更新,以及支持更为广泛灵活的用户运营方式。
07# 后续规划
实时数仓 2.0 将继续推动更多下游使用分钟级数据源,继续优化架构,提升数据处理效率和降低成本。同时,将进一步拓展数据源,丰富数据分析场景,为公司业务发展提供更强的数据支持。

