爱奇艺广告智能算力探索与实践
01# 背景
随着广告业务的发展,流量、订单、模型复杂度快速增长,算力消耗也愈加严重。同时我们也注意到,流量质量参差不齐,投入更多的计算资源呈现了边际效益递减的效应。如何平衡流量收益和计算资源成本成为了广告业务发展无法规避的挑战。爱奇艺广告引擎团队从22年开始探索并实践智能算力在广告场景中的应用,旨在实现一定算力约束下业务收益的最大化。目前我们在链路重要环节实现了包括流量价值预估、弹性淘汰、动态算力分配等关键技术,在同等的算力资源下,效果广告整体消耗有较大增长。
如何量化流量价值
广告请求一般携带广告位、用户相关特征信息,在投放时,会与投放侧的广告创意等特征进行点击率、转化率预估,计算当前流量最优匹配的广告。按照上述流程,流量价值需要走完整个召回、排序链路才能准确评估。但请求一旦经过全链路,意味着算力也已被消耗。如何在算力实际消耗前,或者说以较小代价的算力消耗评估出流量的公允价值成为了价值判断的一个难点。
如何量化算力
涉及计算密集的环节都会成为影响算力消耗的因子,比如召回通道的数量、竞价队列的长度、适用模型的选择等,进一步表现在cpu利用、内存占用、请求耗时等基础指标上。如何将多个指标量化为算力,采用什么样的计算方法,如何设置权重,需不需要和流量价值保持一样的量纲,这些都是需要考虑的问题。
如何寻找价值和算力分配的更优解
在量化完价值和算力以后,如何为不同价值的流量分配不同的算力,使满足系统算力约束的情况下,承载流量价值的总和最大?
稳定性保障
不同来源的流量由于其自身属性或者推送策略等原因,波动变得愈加严重。我们希望智能算力分配系统能足够快的响应流量的抖动以及价值分布的变化,避免算力分配调整不及时导致无法达到收益最大化的效果,甚至危害到服务安全。所以除了保证系统的响应速度,还应建设一些合适的降级策略,保障系统的稳定性。
02# 方案
我们对上述问题场景进行建模分析,设Vi为不同请求的价值,V为当前时刻流量价值总和,Ci为不同请求分配的算力,C为当前时刻的总算力约束,f即为我们要求解的流量价值和算力分配间的关系。

即随着流量价值分布V的变化,我们需要不断调整参数k, B, 使算力消耗始终达到最大约束水平,让有限的算力承载最大价值的流量。
当然,实际场景算力消耗和流量价值不可能是简单的线性关系,我们倾向于引入更复杂的模型(大模型)拟合这种关系,但模型本身的算力消耗,响应耗时、拟合效果都有巨大的不确定性,对于智能算力探索初期来说并不合适。
为了简化问题,我们将算力分配拆解为两个阶段,第一个阶段在流量入口处将不值得分配算力的流量直接截断(Vi < V0),值得分配算力的流量(Vi > V0)作为流量基本盘,由第二阶段召回、排序环节进行更细粒度的算力分配。
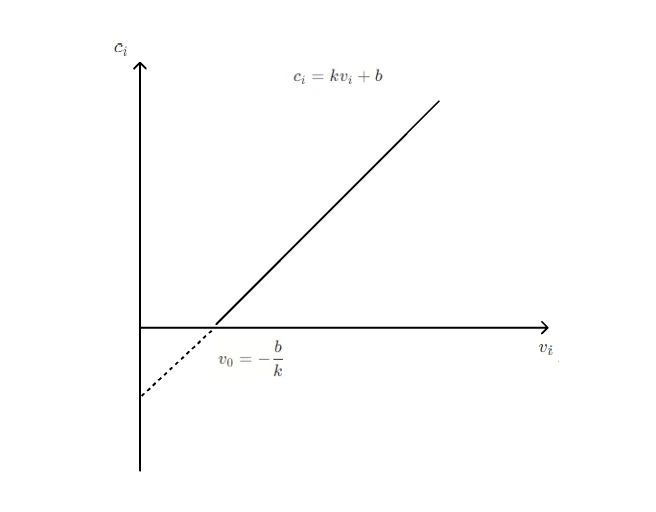
如上所述,我们最终在流量入口实现了弹性淘汰对流量进行优选,在召回、排序阶段实现了动态算力进行更精细化的算力分配。下面我们来具体介绍一下。
量化价值
流量价值的准确性和分布的稳定性是至关重要的,所以我们从多个层面设计了流量价值的计算方法,如在线计算、离线统计、模型预估等, 进一步在归一化后按实验效果分配不同计算方法的权重。这样不仅可以通过实验保证效果,而且在某种计算方式发生故障时,可以通过配置权重,消除影响,提高系统稳定性。
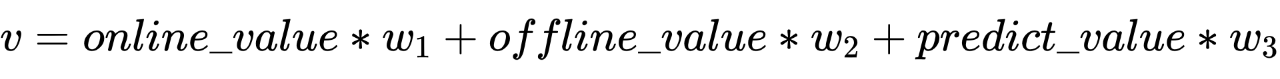
在线计算
利用缓存统计时间窗口内用户维度的填充率、ecpm等指标,由于流量规模较大,且填充率低的特点,缓存淘汰时间注定不能设的很长(分钟级别)。经实践,计算出的流量价值较为稀疏,导致算力分配过程中流量抖动较大,所以在整个价值计算公式上,权重调的较低,相当于在其他价值计算方式上做了微调。
离线统计
由于在线计算有抖动的风险,我们希望在一些更粗粒度的维度统计流量价值,比如广告位,离线计算时间窗口内(天级别)广告位单位流量价值排名作为流量价值,赋予高权重因子,加上在线计算的低权重的用户维度的价值作为微调,这样既保证了流量价值分布的稳定性,又兼顾了准确性。
模型预估
模型预估流量价值我们正在深入探索、实验中,暂且不做展开。
量化算力
可以参考qps、cpu负载、内存消耗、请求耗时等指标,归一化后取较大值作为算力的量化指标,即
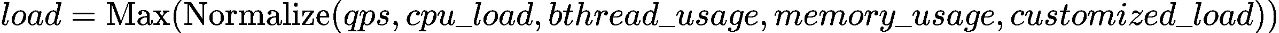
设计时我们增加了可选的自定义负载(customized_load),目的是让服务可以自定义某些业务指标,使算力负载表达更加全面。目前,我们根据阶段特点,如流量入口为重IO服务,则选取qps作为因子;召回排序环节为密集计算服务,则使用cpu负载作为算力的表达。
智能算力分配
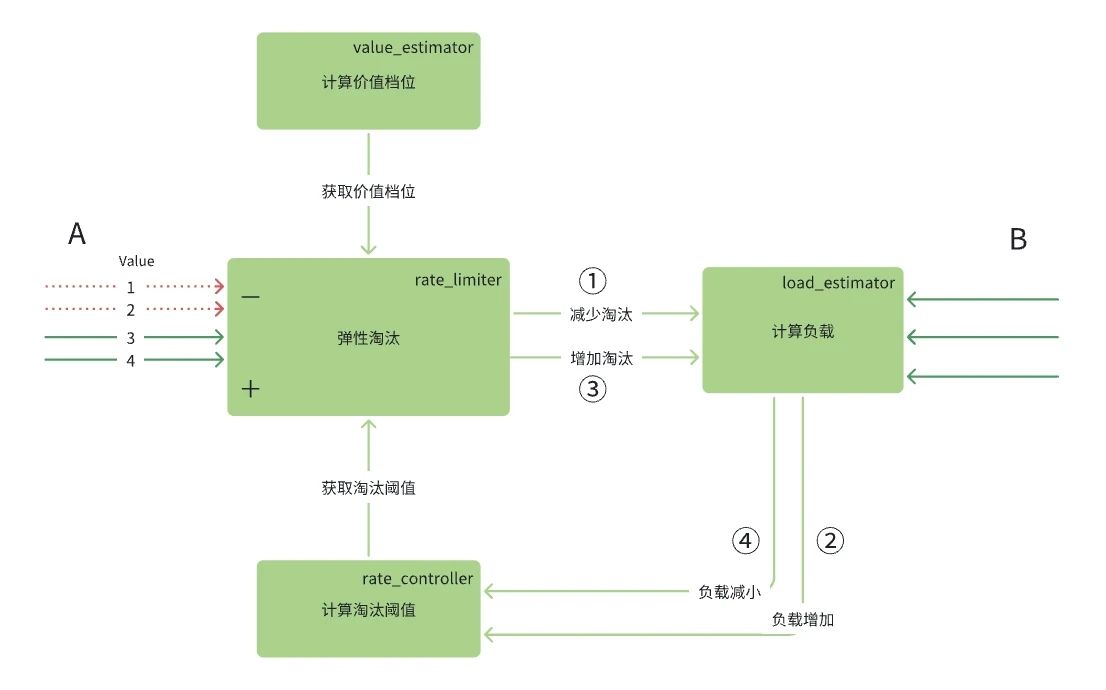
3.1 弹性淘汰
在流量入口,我们需要实时计算流量价值阈值V0,将低于此阈值的流量进行淘汰,整个系统的运作原理如下:
随着请求侧A流量价值变化或者投放侧B负载的变化,整个系统总是在实时负反馈调节中使淘汰阈值和负载趋于平衡。
PID算法
PID是一种通过合适的计算,反馈并调节输入端,使输出快速、精准、平滑的趋向稳定的一种算法。非常适合这种负反馈调节的场景。而且算力约束和流量价值本不属于同一量纲下的两个变量可以借助PID这种算法巧妙的结合到一起。
我们对PID算法进行建模:

随着流量价值和负载的变化,通过上述计算便会得到一个实时的淘汰阈值Value0(t),将流量价值与此阈值作比较,按分段函数求得的比例percent(t)进行淘汰即可。
自恢复策略
结合业务场景需求,被淘汰的流量是有可能通过优化手段提高自身价值的,所以我们需要为这些流量留下试探的口子,即PID模型中淘汰力度向淘汰阈值和概率的转换,使低于阈值的流量保留小比例的试探流量,当流量价值提高时可以随时挤下临近价值的流量。这样流量价值在竞争中不断提高,为流量生态注入了正向循环的驱动力。


3.2 动态算力
流量在经过弹性淘汰的优选后,便进入到了召回、排序等计算密集的环节,与入口服务对流量有无价值做取舍的思路不同,这些流量都是有价值的,需要设计更精细化的算力分配策略,让不同价值的流量得到最合适的算力分配,进而使整体收益最大化。
结合业内提出的DCAF[1]智能算力分配算法求得最优档位。将算力分配问题转化为含约束条件的最优化问题,使用拉格朗日乘子法求解。经过公式推导,当所有请求刚好消耗了所有算力时,可达到系统全局最优。该算法的核心是,根据当前时刻不同价值流量的规模分布,找到最合适的系统算力参数,该参数可以使不同价值流量找到其算力消耗收益最高的档位,从全局看恰好能消耗所有的系统容量。关键计算如下(完整推导见原论文):
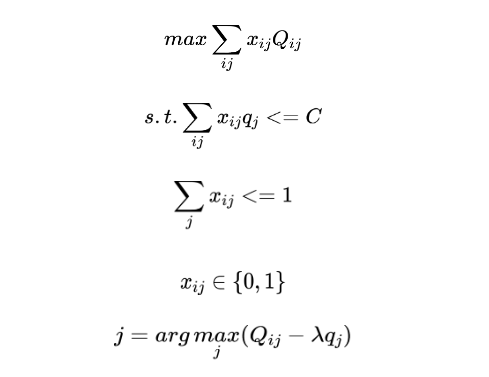
其中,Qij是对于流量i,决策档位j时产生的预期收益,Xij表示是否为流量i选取档位j,qj为采取档位j时系统所消耗的算力,参数lambda可通过离线流量回放试探求得,j即为我们要实时求解的决策档位。
求得决策档位后,便可应用于对应的弹性策略:
弹性队列:根据档位弹性分配不同召回队列的长度。
弹性通道:在多通道召回中,不同通道组合意味着不同的算力消耗,档位决策也可以通过选择通道实现。
弹性模型:大模型相对小模型预估效果更好的同时消耗的算力也更多,根据配置的档位与模型的映射,可在不同档位选择合适的模型进行计算。

03# 成果
1.提收益
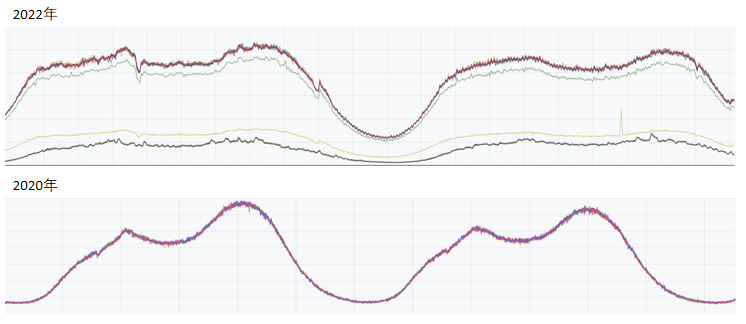
智能算力方案上线后,在同等算力规模下,效果广告可用库存提高了30%以上,消耗增长5%左右。
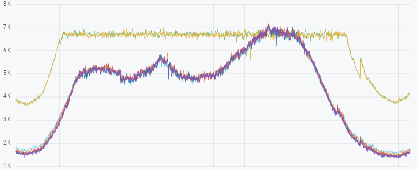
如图所示,上线前,我们通过人工挑量配合限流,可以控制流量在波峰时不超过系统安全负载,但波谷总会存在算力闲置的现象。策略上线后,可以看到波谷算力得到了有效利用,系统总是处在最高安全负载下,计算着最高价值的流量,发挥服务的最大价值。
增效率
从人工介入调控流量和协调资源,到系统自适应算力分配,节省人力3人/天,大大提高了运维效率。
方案上线前,不管是流量自然波动还是新接入流量,都需要从产运人员到链路上下游开发人员,人工介入进行放量控制和资源评估。上线后,系统会根据外部流量和内部负载的变化,自适应到平衡状态,不再需要人工介入。
促稳定
大幅减少了流量抖动、算力耗尽等线上问题,保障了服务全年可用性时间超过99.99%。
智能算力构建的这种自适应稳态机制,让系统有了自我调节的能力,多次在端侧突发流量或者服务资源故障时,以“最小化损失”的方式(如优先淘汰价值低的流量)使系统迅速恢复到平衡状态,大大提高了服务的稳定性。
04# 未来规划
目前我们团队内部根据业务场景在链路上下游实现了不同的智能算力方案,这种方式解耦性好,开发效率高,能很快看到业务收益,但得到的仍是局部更优解。接下来我们会以全局视角进行架构、策略和算法的迭代优化,包括引入模型预估,甚至是大模型技术来更精准的评估流量价值,探寻算力分配的全局更优解,进一步发挥智能算力的价值。

