58大数据:智能加速引擎的探索与演进
01 演进背景
智能加速引擎是58大数据平台自主研发的复杂计算系统组件,在支撑集团业务发展和平台稳定性建设方面,发挥了巨大作用。随着大数据技术的日益成熟和AIGC技术的迅猛发展,我们期望能够通过对智能加速引擎的技术迭代与架构升级,实现在降本增效方面的显著提升与突破。
02 架构解析
58同城大数据团队经过多年的技术积累与更新迭代,逐步形成了较为系统和规范的平台架构:

图1:大数据平台架构
其中,智能加速引擎又依托高效解析、灵活转发及强大的执行能力,实现对即席查询场景的业务支持。
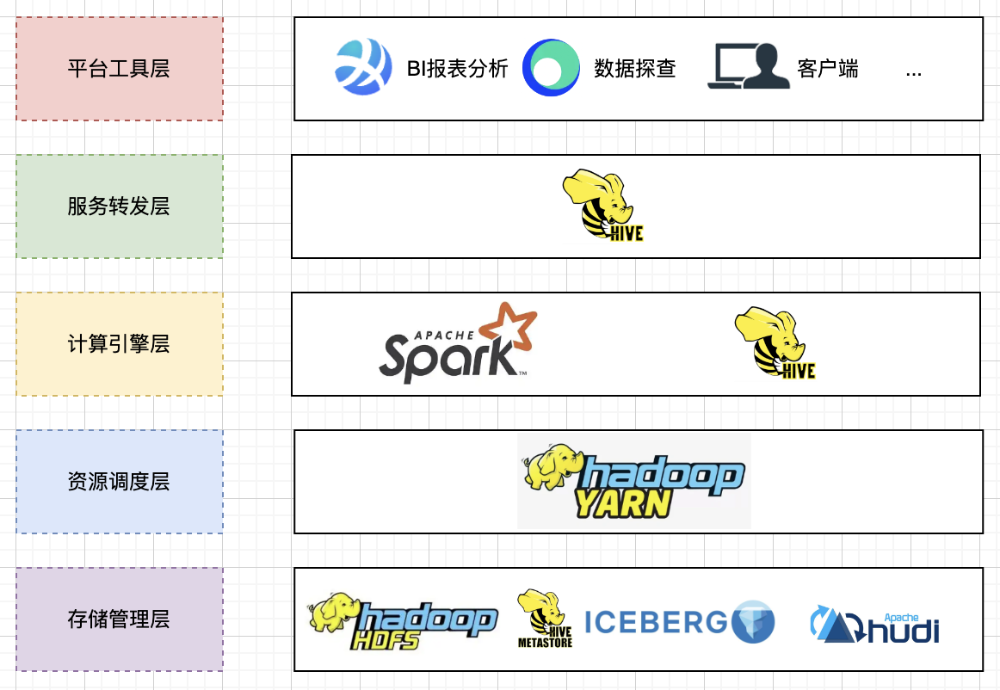
图2:智能加速引擎架构(旧)
但是,随着业务规模增长和数据量的增加,智能加速引擎面临的问题也日渐突出:
代码耦合性问题:多模块之间的数据交互和依赖关系过于复杂,导致代码复杂度高,维护难度大;
多引擎扩展问题:与Hive源码的耦合过于严重,角色定位不够清晰,面对更多数据类型和更复杂的计算场景时,无法快速实现多引擎的支持,水平扩展能力较弱,不利于未来SQL入口统一构想的实现;
系统稳定性问题:既要作为网关服务又要承担计算任务,经常出现单节点服务负载高、查询时间过长等故障和问题,集群稳定性颇具挑战;
跨机房隔离需求:多业务共享资源池的现状,导致计算集群压力大时,重点业务查询时效无法保障,存在业务及资源隔离的场景需求。同时,当前架构下仍存在跨机房调度的问题,机房专线流量带宽被打满的风险仍然存在;
综合考虑技术发展趋势、兼容性及适配性等多方面因素,我们决定对智能加速引擎架构进行升级改造,采用Apache Kyuubi作为独立的网关服务,同时引入StarRocks丰富底层计算引擎种类,解决当前现网问题并实现即席查询性能的大幅提升。

图3:智能加速引擎架构(新)
整体上,智能加速引擎的核心组件和逻辑分为如下几个关键流程:
用户通过符合JDBC或RESTful协议的数据探查产品或客户端发起查询请求,数据探查产品主要负责用户作业的提交与管理,并承担接收与展示执行引擎返回结果的任务;
Kyuubi Server接收到查询请求后,将SQL发送到Parse Server进行处理。作为统一的网关服务核心,它不仅负责接收来自客户端的各类请求,还承担执行引擎与会话的调度和管理任务,能够将请求调度到最合适的执行引擎进行高效处理;
Parse Server对SQL语句进行解析并判断是否满足StarRocks等多引擎的语法规则,根据解析结果决定是否进行SQL改写。随后,通过基于历史的HBO优化策略和综合智能算法矩阵对查询进行评估,确定最优的执行计划;
最后,Kyuubi Server根据Parse Server的评估结果,结合当前系统的负载情况、引擎性能等因素,决定如何将SQL语句转发到最优的底层计算引擎执行;
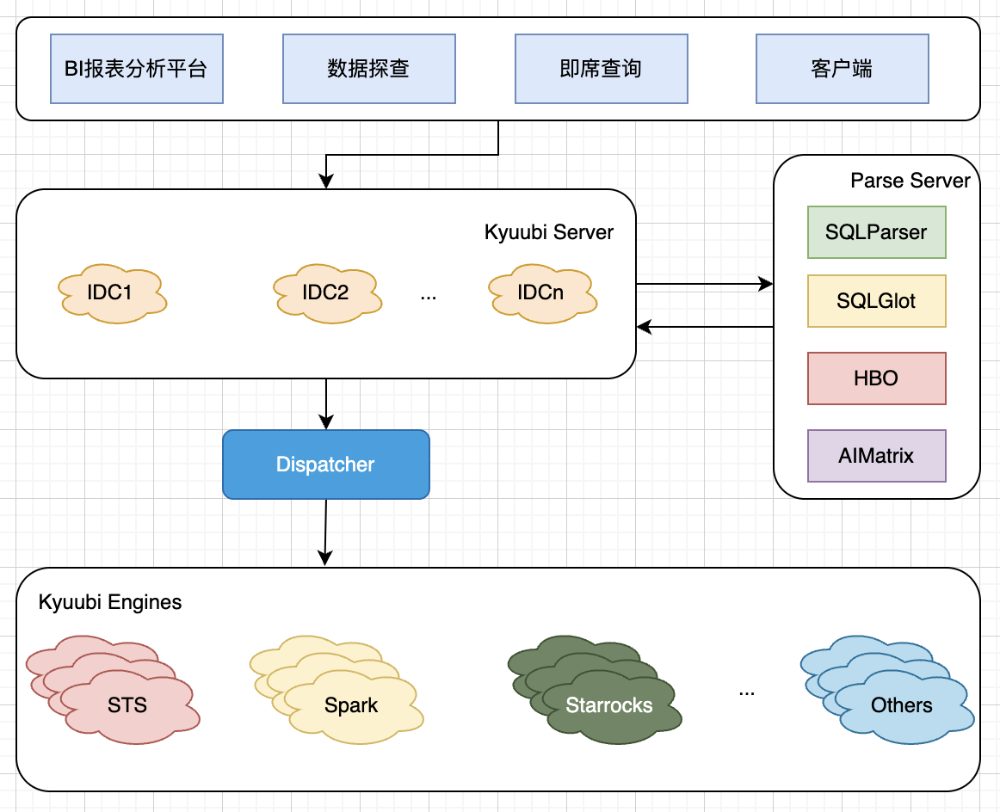
图4:智能加速引擎核心组件及流程
03 能力建设
3.1 多租户架构方案改造
区别于原生架构采用代理用户的权限认证方式实现多租户的支持方案,我们通过对Apache Kyuubi中Engine启动时的Proxy User代理用户权限认证使用的修改,在具体SQL分发执行过程中,采用doAs运行的方式,实现Session级别真实用户模拟执行的效果,从而实现多租户功能需求。

图5:多租户方案
3.2 分组隔离多引擎支持
我们在Apache Kyuubi的Server部署方式下,通过Namespace对不同机房的服务做了物理隔离和区分。同时,通过逻辑改造,实现同Namespace下能够支持多台机器节点和多个服务的创建、共存、选择等能力。
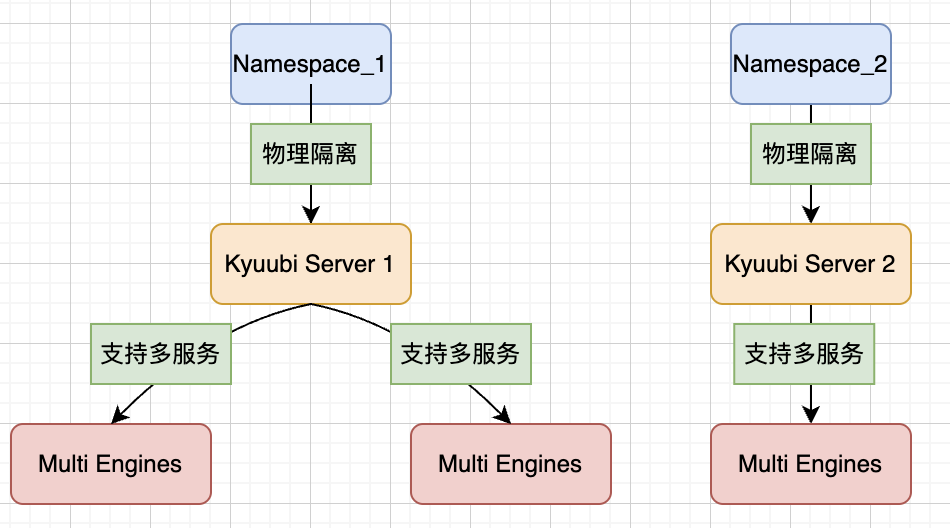
图6:分组隔离多引擎
3.3 跨机房调度能力增强
针对跨机房导致的机房带宽和POD流量冲击问题,我们在任务分发逻辑和引擎选择策略上进行了改造和完善,实现了按账户和按读取数据量分发SQL到不同机房,甚至不同引擎执行的能力。
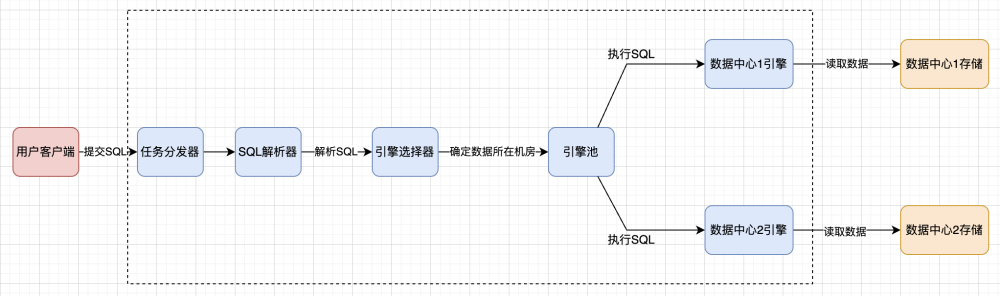
图7:跨机房调度流程
3.4 引擎选择策略的丰富
Apache Kyuubi当前对于引擎选择的策略相对单一,通过Namaspace获取到Engine后,选择固定的其中一个引擎作为备选使用。由于我们内部实现了对同Namespace下多引擎实例的支持,在引擎选择阶段就希望能够有更丰富和灵活的引擎选择策略,以避免单节点高负载的问题。
因此我们在原来固定选择Engine的基础上,增加引擎选择策略,支持RANDOM随机选择策略、LEASTACTIVE负载均衡选择策略以及WEIGHT权重选择策略。
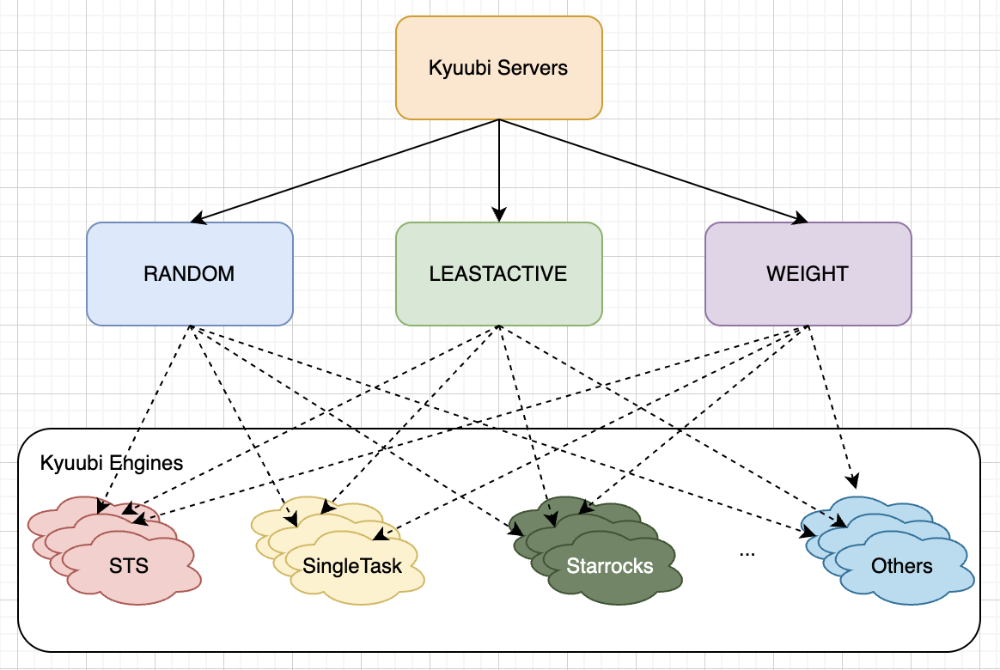
图8:引擎选择策略
3.5 解析及转发能力完善
在Apache Kyuubi作为统一网关的部署模式下,我们实现了对多引擎的全面支持与高度的扩展灵活性。然而,引擎的选择与运用方式依赖于用户在创建或提交SQL作业时对所需执行引擎的明确指定,此流程不仅增加了用户的操作难度,更阻碍了业务自动化加速与效率提升的步伐。
鉴于此,我们在现有架构基础上强化并完善了服务解析与转发能力:
SQL Parse:增加针对StarRocks语法的全面SQL解析能力,通过优化词法分析器,实现对StarRocks特有关键字和兼容函数的支持;更新语法树构建逻辑,确保能够实现对复杂查询语句的准确解析;增强错误处理机制,对不满足条件的SQL语句,提供更详细信息提示和处理逻辑;
SQLGlot:引入针对StarRocks语法规则的方言改写能力,支持用户自定义函数和类型的映射规则,同时对改写过程进行优化,减少转换开销,提高整体执行效率;
HBO:建设基于SQL历史运行情况的优化规则策略,通过收集并分析包括执行时间、资源消耗、数据质量等在内的SQL历史运行数据,依据分析结果构建一套针对StarRocks的优化规则库,在SQL执行前,根据当前SQL信息和历史行为数据,智能选择最优的执行计划和优化策略;
AI Matrix:支持基于算法推荐模型的高效运行更优解预测机制,利用机器学习技术,训练针对StarRocks等多引擎的算法推荐模型;在SQL执行前,利用训练好的模型对多种执行计划和引擎进行预测和评估,达到选择更优解执行的目的;同时建立模型更新机制,确保数据时效性和模型准确性;
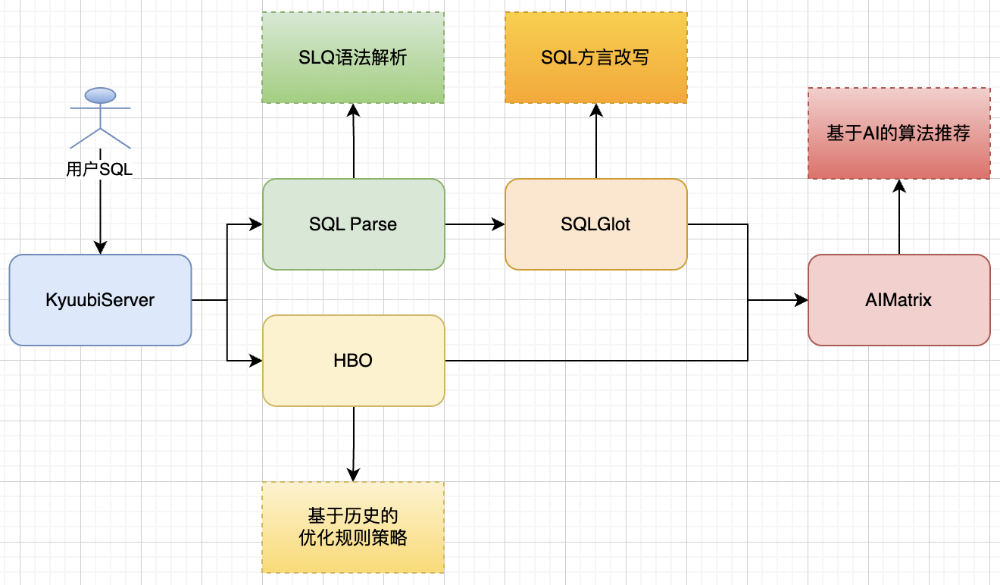
图9:解析转发核心组件及流程
04 架构实现
4.1 兼容性适配改造
在SQL执行的不同阶段,我们进行了广泛的兼容性适配与改造,旨在克服引擎间存在的兼容性差异,从而确保数据质量的准确。
语法解析阶段
直接修改 StarRocks 源码以兼容 Spark 的语法特性(如大小写不敏感的表别名);
在 FE 端集成 SQLGlot 插件,实现 SQL 方言间的相互转换,解决关键字冲突等问题;
扩展 StarRocks 的能力,支持 Spark 的高阶语法(如 LATERAL VIEW、GROUP BY ... WITH CUBE、GROUP BY ... GROUPING SETS(...));
元数据绑定阶段
关闭 Hive Catalog 的元数据缓存功能,避免因缓存导致的查询结果不一致问题;
查询优化阶段
梳理并兼容 Spark 和 StarRocks 的隐式转换规则,确保数据类型转换的一致性;
查询执行阶段
扩展 StarRocks 对 Text+LZO 存储格式的支持,并使其能够查询 Map 类型字段;
修复 Hive 表字段分隔符、临时文件处理、空文件处理等兼容性问题;
对于函数名称不同但功能相同的情况,进行函数名称映射;
对于StarRocks不支持或不兼容的Spark函数,通过创建Java UDF或修改StarRocks代码的方式,实现40+涉及日期处理、字符串处理、正则匹配、聚合函数等的兼容性支持;
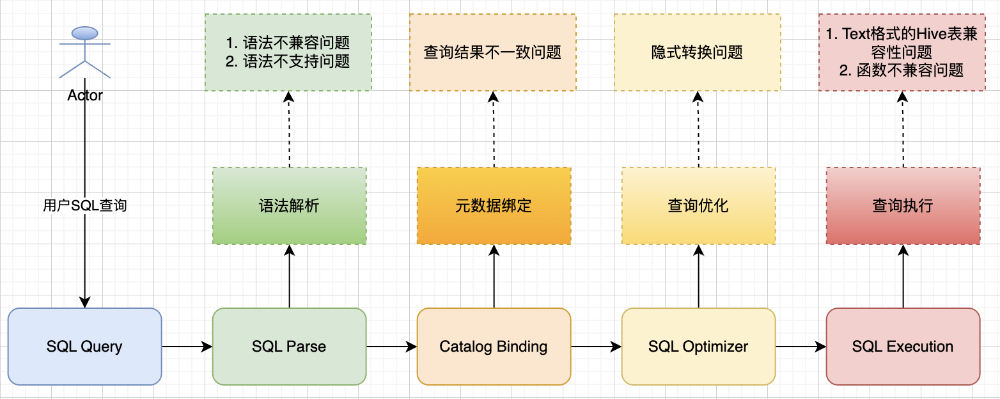
图10:兼容性改造
4.2 稳定性问题修复
项目推进过程中,遇到过FE节点卡死、BE节点崩溃等诸多典型问题,我们积极采取优化措施,对遇到的一些稳定性问题进行修复,如:CBO统计信息可能导致的集群故障问题。
对于字段数量庞大的表,CBO 优化器在查询时构造的 SQL 语句会异常庞大,当查询涉及多个字段时,CBO 使用 UNION ALL 连接多个查询,导致生成的 SQL 语句极其复杂,查询所有字段时,生成的 SQL 语句会消耗大量内存,可能导致 FE 内存溢出,进而影响集群稳定性。
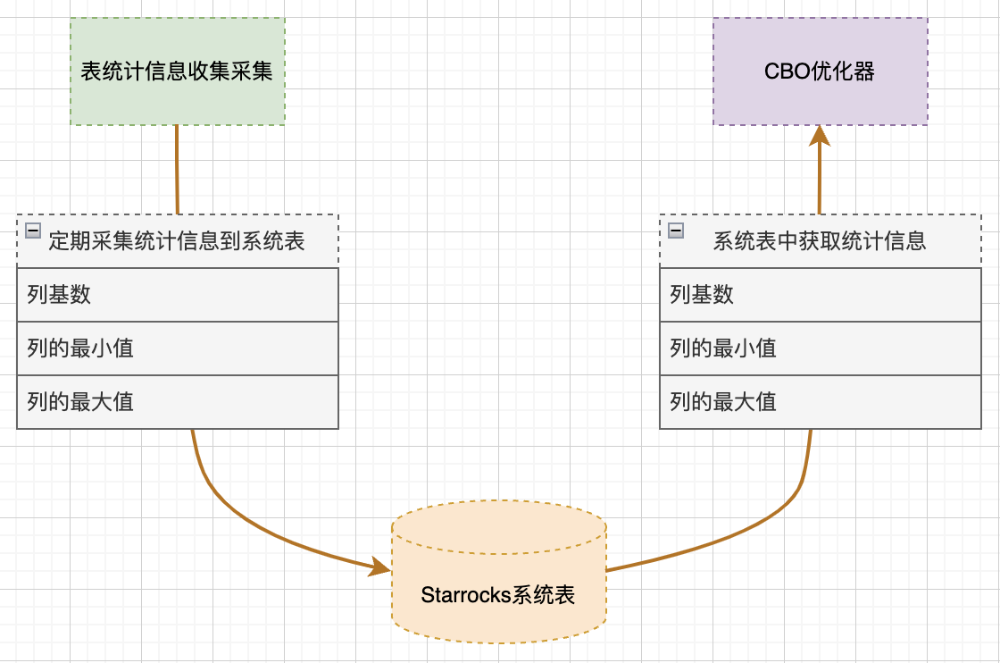
图11:CBO统计信息示意
考虑到 StarRocks 默认并没有采集 Hive 表的统计信息,且在查询 Hive 表时,构造 SQL 语句从系统表获取的统计信息也没有实际意义。我们对此处逻辑做了修改及规避,有效降低了查询负载,增强了系统的稳定性。
4.3 易用性增强完善
JAVA UDF支持从HDFS下载JAR包
为实现用户UDF的支持能够更好的适配内部架构,我们通过此功能的扩展,利用HDFS实现对UDF JAR包的管理、维护和传递能力。
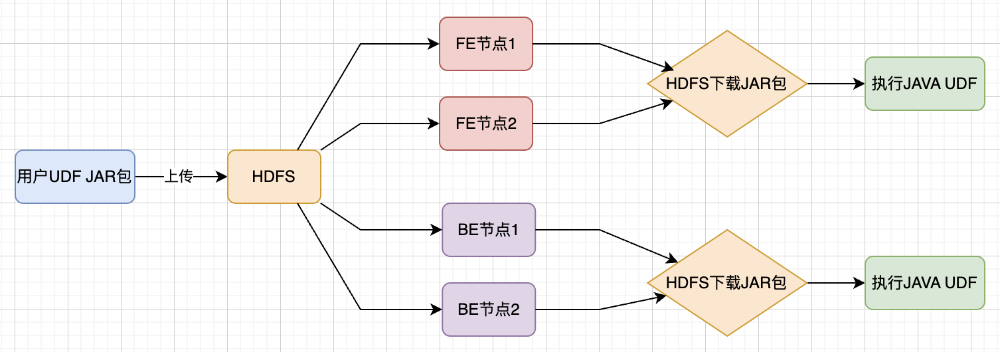
图12:JAVA UDF方案支持
SQL黑名单持久化方案
StarRocks将SQL黑名单信息保存在FE内存中的处理方案,可能导致黑名单在各 FE 之间不互通,且重启后黑名单会失效的问题。我们通过实现将SQL黑名单信息持久化到元数据中,以提高SQL黑名单方案的易用性。

图13:黑名单持久化
4.4 容器化部署探索
为了推进降本增效战略,我们在StarRocks部署形式上尝试了云集群混部和反向混部。
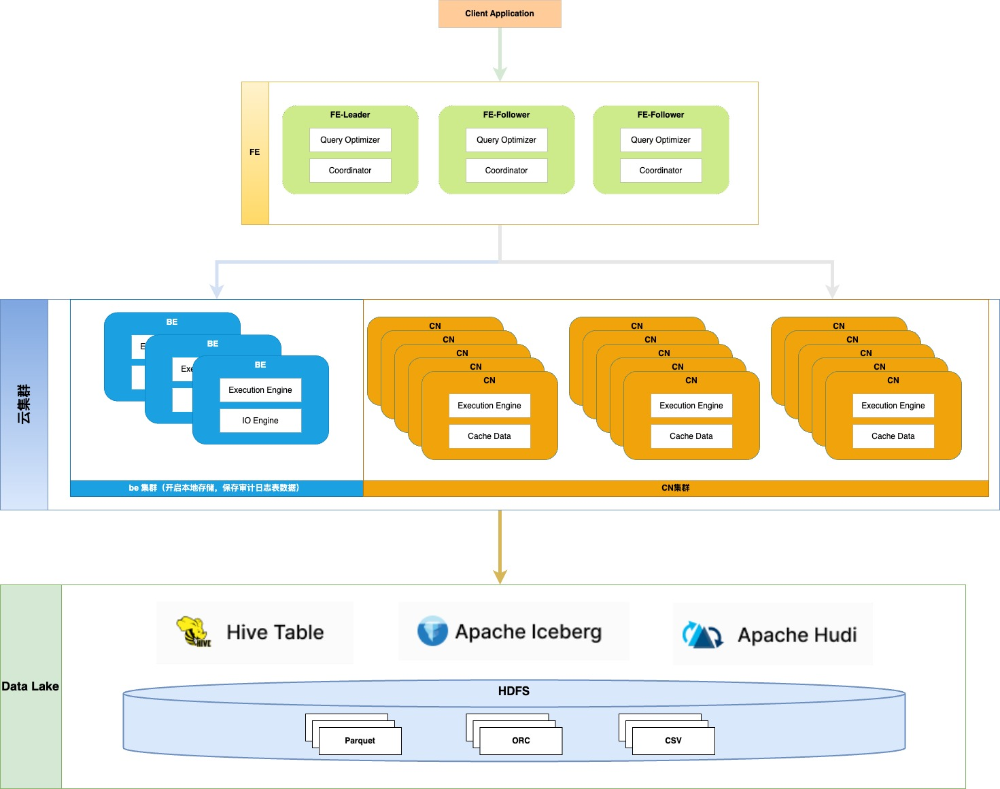
图14:容器化部署架构
整体上:
由于容易使用资源限制及FE对内存资源要求较高的原因,FE节点未上云,仍使用物理机部署;
BE集群仅少量实例部署在云上,主要用于存储审计日志表数据,并开启了云集群本地存储;
CN集群作为主要的计算节点,无状态,支持快速扩缩容,通过设置资源组隔离、开启中间结果落盘、减少CN进程线程数、限制CN进程JVM内存等方式,解决因容器内存资源不足,可能造成的内存溢出问题和稳定性挑战。
4.5 性能提升与优化
针对性能的提升与优化,我们积极尝试社区功能特性。在开启Data Cache功能加速查询的情况下,线上大多数场景的查询性能都可满足要求。只有少数由于个别HDFS DataNode慢节点的情况,可能导致个别查询的长尾问题。为此,我们联同HDFS模块实现读写规避慢节点能力,在StarRocks中使能并取得了相当显著的效果。
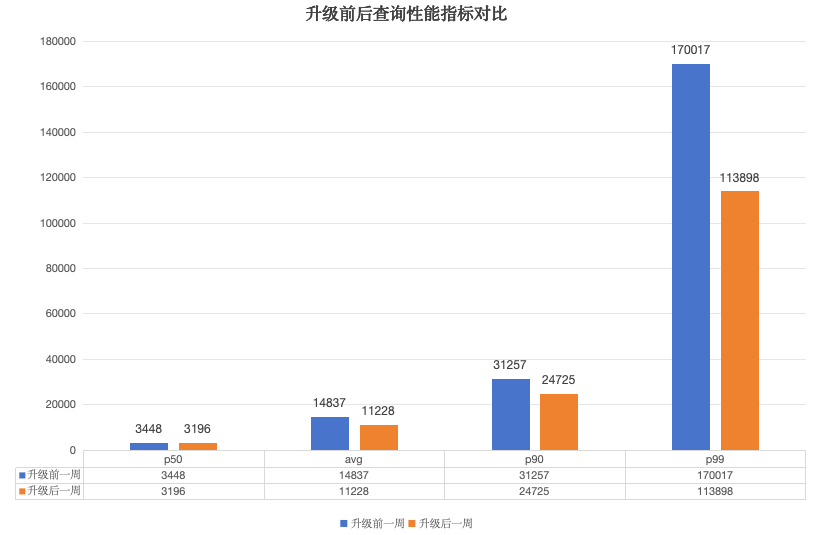
图15:慢节点规避效果
05 落地表现
智能加速引擎架构全面落地,Kyuubi作为统一网关,支撑业务日运行SQL数超10W+;
StarRocks湖仓一体架构实现,即席查询业务增长明显,稳定日运行SQL数突破6W+,
落地ETL实例超 1W+,查询效率大幅提升,提效实例平均占比71%,平均提效41%;
促进即席查询由传统引擎向高性能引擎转变,HiveSQL迁移率92.4%,P95提升43.8%;
AI算法+HBO能力应用并落地,模型准确率提升82%,任务转发回退率failover降低50%;
通过架构升级,实现资源高效利用,优化成本结构,整体累计减少CPU计算资源超1.5W核;
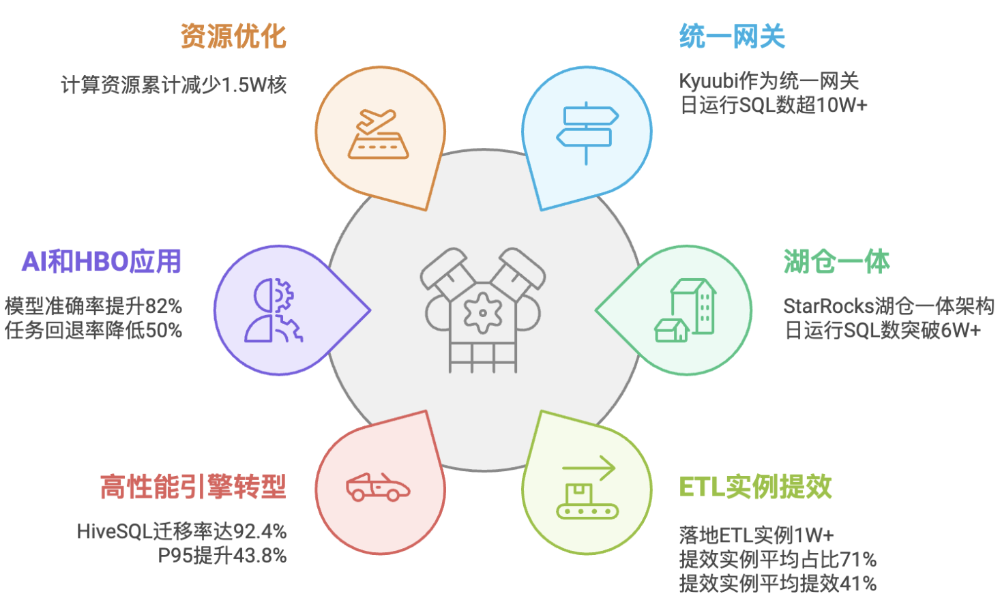
图16:智能加速引擎收益
05 总结展望
项目的开展与落地过程中,Apache Kyuubi与StarRocks社区给予了诸多帮助与支持,这些宝贵的沟通与协助,促进了彼此间的互助与合作,我们深感荣幸并致以最诚挚的谢意。
同时,我们将持续在以下几个关键领域不懈努力:
紧跟技术前沿,持续迭代和完善Kyuubi及StarRocks组件;
深入挖掘Spark 3.5等引擎潜力,实现智能加速引擎架构常态化更新;
致力于向量化技术的研发与应用,在数据处理速度和效率上实现质的飞跃;
积极探索并实践AI及算法在大数据计算领域的创新应用,为业务决策提供更为精准和高效的支持;
展望未来,让我们继续以用户需求为导向,以技术创新为驱动,携手并进,共探数据智能新边界!

