58商业搜索场景中的算法实践
01 导 读
随着产业化的深入,商业搜索场景需要更深入理解业务,与业务结合。本文将介绍商业搜索场景中,围绕用户体验和商业收入提升,所做的技术迭代和升级。第一部分重点介绍业务场景和业务中的问题;第二部分介绍知识图谱的挖掘和应用;第三部分介绍大模型如何在知识图谱场景中进行应用和落地。
02 商业搜索场景介绍
2.1 用户入口
用户搜索入口一般处于APP头部,因为搜索场景可以让用户很好的表达真实需求,是平台接触用户的第一大入口。
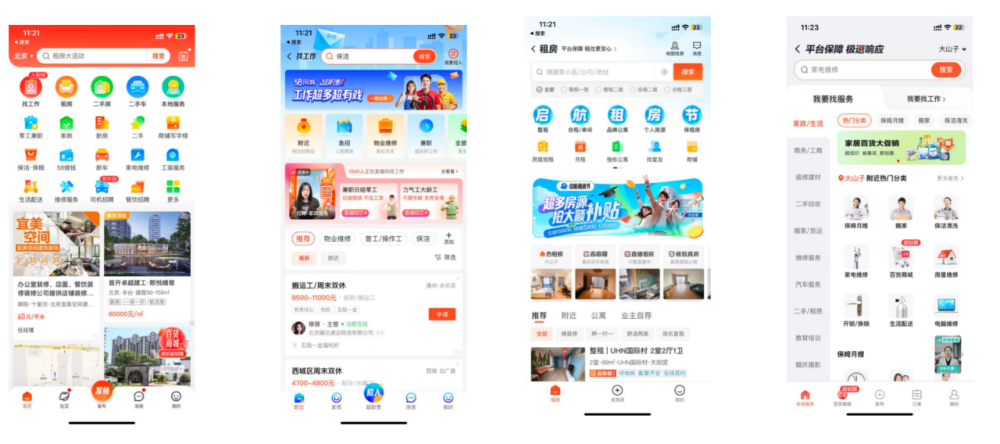
图1: 58 同城 APP 中首页搜索及各业务搜索入口
2.2 用户意图分析
搜索场景是表达用户需求的入口,因此我们需要知道用户来 58 找什么?
按不同业务场景,用户有如下几类需求:
• 生活服务:搬家、开锁、空调维修、管道疏通
• 租房买房:看小区租金、查房源房价
• 找工作:普工、电工、保洁员、外卖员
对应不同的用户需求,商家提供什么?
• 生活服务:到家到店服务
• 房产:房源信息
• 招聘:招聘岗位、招聘要求
平台提供什么?
• 链接用户和商家,满足用户需求,保障用户与商家的权益
商业模式?
• 通过链接用户与商家,向商家收取广告费用
2.3 行业搜索场景
行业内不同搜索场景有不同业务特性,下图为百度搜索,美团搜索,淘宝搜索场景的示例。对于网页搜索偏向于泛搜索,内容无结构化信息。对于餐饮和商品搜索,则偏向垂类搜索,其内容有结构化信息。

图2: 百度搜索,美团搜索,淘宝搜索场景的示例
2.4 58商业搜索场景
对应 58 同城商业搜索场景,不同业务之间略有差异。整体上,因为是同城业务,都有强 LBS 约束,用户大部分场景只搜索所在城市的服务。对于黄页场景,因为用户来找服务,目标意图非常明确,相关性要求会比较高,同时商家内容为文本加图片信息,无结构化信息。对于招聘场景,用户来找工作,目标意图相对较明确,但可以给其推荐类似的工作,因此是搜索加推荐场景。对于房产业务,用户在不同找房阶段,目标不同,因此其意图可能发生变化,也是搜索加推荐场景。
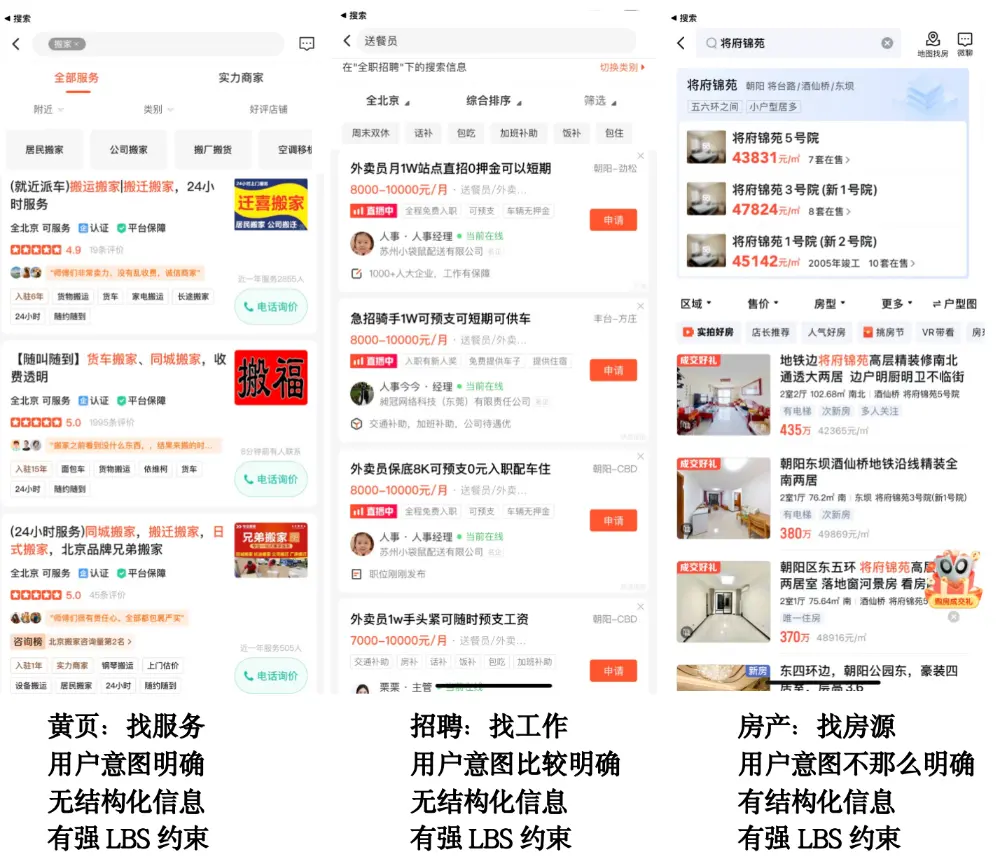
图3: 不同业务在58商业搜索场景上的差异
2.5 黄页搜索场景中的问题
下文主要针对黄页搜索业务进行展开:
1. 商家信息未结构化
目前商家发布的内容信息为文本信息,其中包含商家所提供的服务内容,服务承诺,以及服务具体信息。但是对商家服务并未进行结构化,需要对文本进行语义理解和挖掘。

图4: 商家信息未结构化示例
2. 相关性不足
因为在该业务场景下,用户意图十分明确,因此搜索结果需要有很高的相关性。而原有策略方案有两路召回,一路为切词Term召回,一路为向量化语义召回;这两路召回,召回率较高,但准确率较低,导致最终展示给用户的搜索结果相关性不足,体验不佳。
2.6 解法:业务知识结构化
针对黄页业务中的两个问题,我们的解法是对业务知识进行结构化。对于黄页业务,用户和商家的核心在于服务。通过对 query 抽样,我们发现80%的搜索词都是服务,因此我们重点对服务进行结构化。
03 知识图谱赋能
3.1 知识图谱介绍
针对黄页业务场景,我们挖掘的知识图谱结构如下图:
分类层:抽象实体类别;包括服务实体、工种实体、服务对象实体、服务承诺
原子实体层:服务的最细粒度拆分
复合实体层:原子实体聚合后的实体
用户需求层:用户原始搜索需求
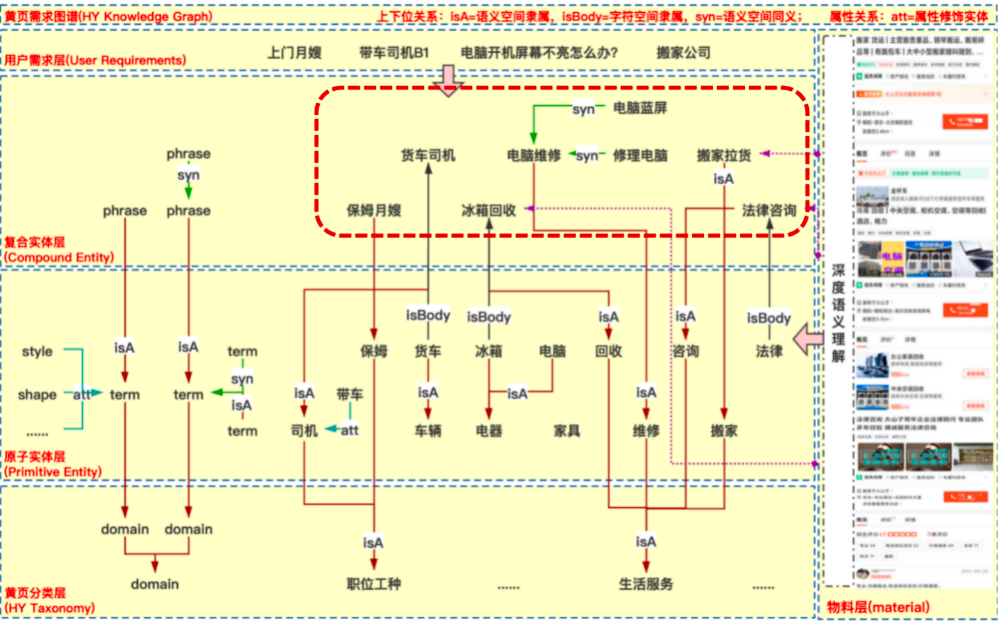
图5: 知识图谱结构
3.2 知识图谱挖掘
问题定义:NER(命名实体识别)。与传统 NER 不同的是,我们需要自定义一个实体类别,即服务实体
服务实体定义:商家所提供服务,一般为动名词组合;如冰箱维修,开锁,搬家,管道疏通
3.2.1 服务实体挖掘
服务实体的挖掘,经历4个版本的迭代
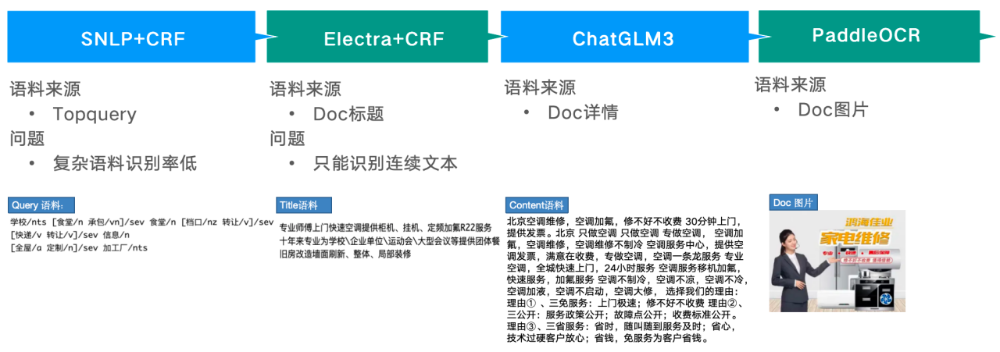
图6: 服务实体挖掘的4个迭代
1. 第一阶段:快速验证逻辑
• 挖掘来源:热门搜索词
• 方案:传统机器学习模型 CRF
• 问题:挖掘准确率较低;75%+
第一阶段,使用传统模型 CRF 进行实体识别,使用语料来源于热门搜索词,其准确率相对较低(75%),因此经过人工审核。上线后头部相关性提高,通过提高用户体验带来了商业收入提升。本阶段通过快速上线,验证了结构化信息的作用。
2. 第二阶段:批量挖掘大量实体
• 挖掘来源:商家描述中的标题,文本长度较短
• 方案:Electra+CRF;其中 Electra 为 Bert 变种,挖掘性能更好一些
• 问题:序列标注方案无法识别非连续实体
通过 Electra + CRF 的方案,大幅提高准确率(90%),并将实体库数量扩充到 10w+;此时,文本中的大部分实体可通过直接匹配的方式进行识别。
经过数据分析,实体召回能覆盖70%曝光,但依然有30%曝光未被覆盖。分析这部分曝光内容,发现序列标注方案无法覆盖非连续实体。例如【本公司提供空调、冰箱、洗衣机等家电维修服务】,直接匹配只能匹配到【家电维修】实体,而【空调维修】、【冰箱维修】、【洗衣机维修】这些实体,需要通过语义进行挖掘。
3. 第三阶段:大模型实体挖掘
• 挖掘来源:商家描述中的详情;文本长度比较长
• 方案:GLM3微调;使用该场景实体数据构造 Prompt 进行微调
相对于传统模型,大模型的语义理解能力更强,且生成范式可以解决非连续实体挖掘的问题。通过构造业务 prompt 数据微调,准确率可以达到 92%;经过第三阶段,实体召回曝光占比得到进一步提高。
4. 第四阶段:多模态挖掘
• 挖掘来源:商家相册中服务实体
• 方案:PaddleOCR;通过 OCR 提取图片中文本,然后再进行实体识别
经过数据分析发现,平均每个商家有20+ 图片,图片中有一些服务信息。因此通过 OCR 提取文本信息,进一步匹配服务实体,也带来一定业务提升(Cash/UV+20%)。
总结:
经过 4 个版本的迭代,我们通过完善图谱,将服务数据结构化,从而提高了搜索结果的相关性,对用户体验有很大的提升,因此带来了商业收入与链接的提升。
3.2.2 同义实体挖掘
问题:在挖掘服务实体的同时,我们发现对于同一个服务,不同用户之间,以及用户和商家之间,有不同的文本描述,因此需要在语义上进行统一
方案:训练时,人工标注的同义对作为正样本,随机抽样实体对作为负样本,通过 Bert 模型同义对分类模型;推理时,先从实体库中用 fasttext 粗筛一批候选同义对,再经过训练好的 Bert 模型,根据阈值取 TopN
规则:人工构造原子实体库;以及挖掘同义规则,例如AB和BA为同义
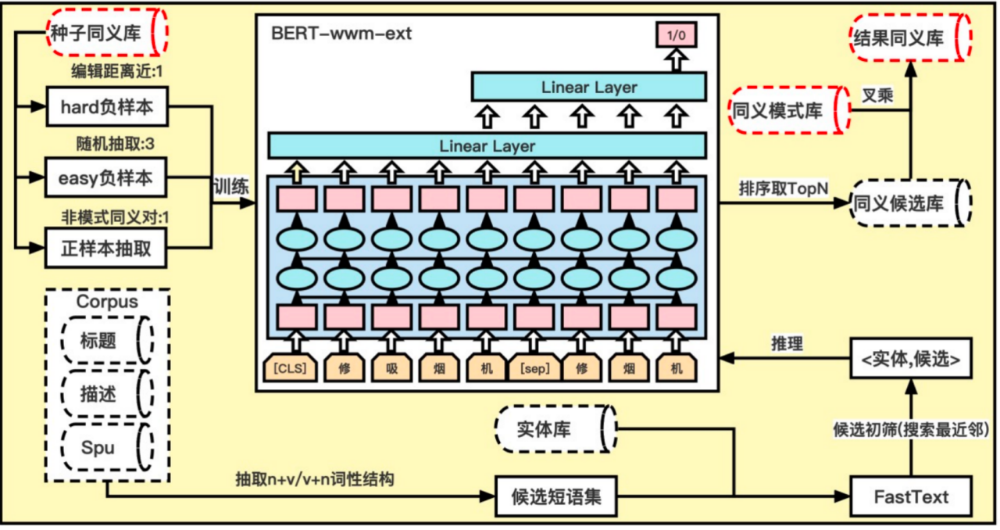
图7: 同义实体挖掘架构
3.3 知识图谱应用
挖掘出的服务实体和实体同义落地于搜索场景的召回、排序、相关性过滤、创意、投放各个链路中
召回场景:服务实体作为主要的召回路;通过对Doc侧实体识别,建立倒排索引;Query侧进行实体识别后,通过同义实体簇进行召回
排序场景:使用实体粒度的相关性分数,作为排序特征
相关性过滤:计算服务实体之间的相关性分数,进行实体粒度过滤
创意场景:对召回 Doc 相关实体进行飘红露出,并对服务承诺进行露出
投放场景:在 OCPC 产品中,对实体词进行售卖
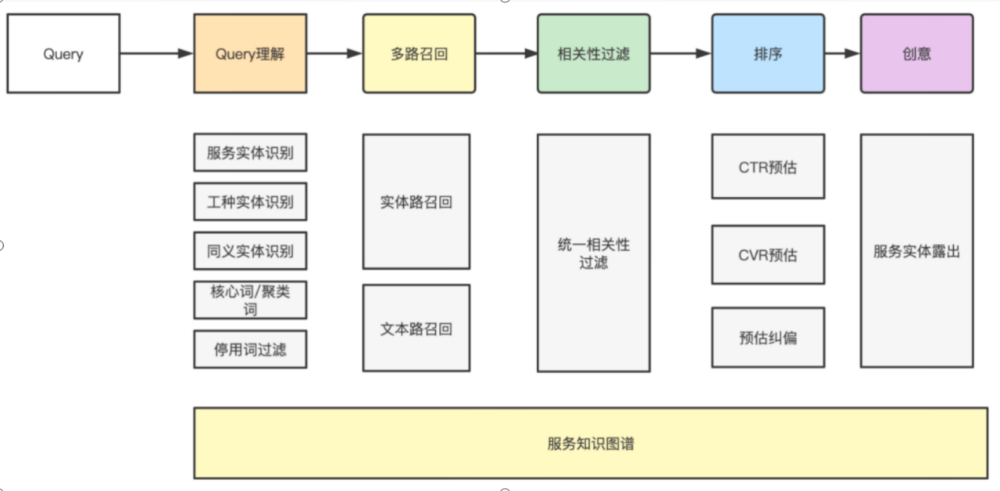
图8: 知识图谱应用流程
04 大模型助力知识图谱升级
随着大模型时代的到来,NLP领域迎来新的升级。
大模型相对于传统模型,有以下优点:
• 语义理解能力更强
• 少样本学习能力更强
• 生成范式可以适配各种 NLP 任务
• 开源大模型能力不断升级
可以考虑升级大模型的业务场景:
• 需要大量数据标注 NLP 任务
• 复杂 NLP 任务
我们在知识图谱中对应2个场景适合进行升级:
• 服务实体挖掘场景,NER任务需要较多标注数据,借助大模型可以减少标注成本
• 服务承诺挖掘场景,该场景需要更强的语义理解能力,大模型可以更好的完成任务
4.1 服务实体挖掘
背景:知识图谱应用中,服务实体挖掘,以及 Doc 侧服务实体识别,使用传统 NER 方案无法解决非连续实体的问题。而大模型的强语义理解能力,以及生成范式的适配性,可以很好的解决传统方案的问题。
如下图,对文本【上门维修冰箱、电视、洗衣机等家电】进行服务实体提取,序列标注方案无法进行提取,基于SPAN的NER可以提取,但长文本下复杂度较高。而生成式大模型可以很好解决这类问题。
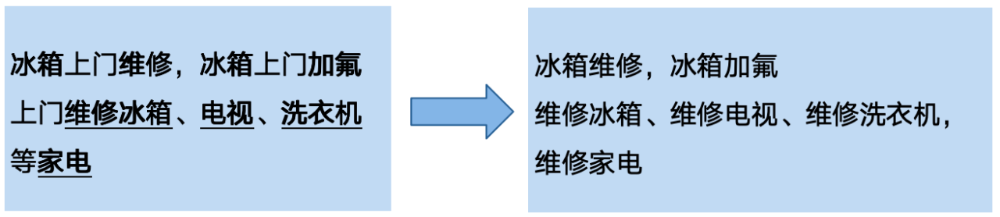
图9: 服务实体挖掘示例
针对此类问题,我们通过大模型对详情文案中实体进行挖掘。考虑到微调需求以及算力性价比因素,大模型选择 GLM3 的 6B 模型,一张3090显卡即可进行微调实验。微调方式使用了开源方案中默认的 ptunningv2。
提示词优化技巧:
• 根据对话的 badcase,提供一些约束规则。例如商家描述中有时会携带地名,可以在规则中禁止返回地名
• 在 prompt 中提供一个挖掘的示例
我们最终的提示词如下:
prompt:
你是一个出色的文本关键词提炼工具,我是一个寻找本地生活服务的用户,正在从商家描述中寻找商家可提供的服务项目。商家服务项目是商家可提供的服务内容,可以解决我遇到的生活难题,如"同城搬家"、"附近开锁";商家服务项目不是商家提供服务项目时提供的服务承诺或者商家的服务特色。请你根据上述我对商家服务项目的定义,帮助我从商家文本提取商家服务项目关键词。要求:
1)充分理解商家的描述内容,遵从商家描述原文描述;
2)禁止输出重复的商家服务项目关键词;
3)禁止输出商家的服务承诺,如"上门服务"、"安全承诺";
4)输出的词是由动宾结构组成的复合短语,每个短语都描述了一种具体的服务或行为,如"维修自动门"、"同城搬家"、"道路救援";
5)输出格式要求:输出的服务项目使用","分割,并以"关键词"开头输出;
6)禁止输出地名的词,如"成都"。
回答后,不需要输出你回答内容的原因。
以下是一个示例,以便你更好地理解我的诉求:
示例:
以下是一个商家描述:
高价回收黄金首饰、铂金钯金、足金回收千足金、金条项链手镯耳环戒指、钻戒。支持上门回收丨黄金免费上门无上门费 免费鉴定 不压价国际行情价黄金、金银首饰回收【黄金】1、黄金回收:千足金、足金、24k、22k金、20k金、18k金、万足金、14k金、金条、金砖等所有黄金。
关键词:
回收黄金首饰、回收铂金、回收钯金、回收千足金、回收金条、回收项链、回收手镯、回收耳环、回收戒指、回收钻戒、回收黄金、回收金银首饰、足金回收、金条回收、金砖回收
以下是一个商家描述:{商家描述}
response:{人工标注服务实体}
随着微调数据量提升,准确率有所提升:此处过滤非实体文本规则是根据 badcase 定制业务规则
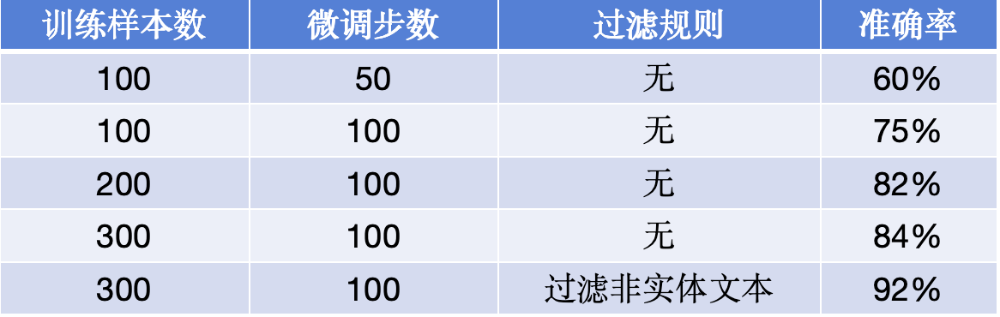
图11: 微调数据量提升,准确率有所提升
可以看到随着训练样本数增加,准确率可以线性增长。但有一定天花板,这跟大模型容量有关。
最终离在线训练推理流程如下图:
• 离线构造微调样本后,微调大模型
• 推理侧定时获取每日新增商家内容信息,进行推理,输出帖子与服务实体关系
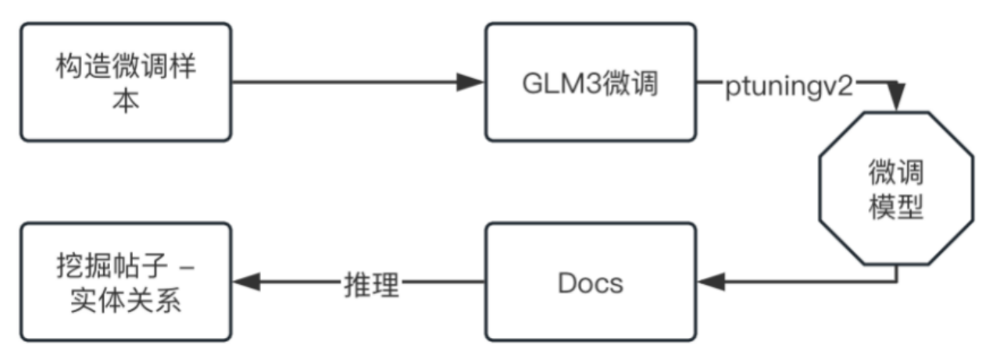
图12: 离在线训练推理流程
该项目推全后,带来的业务收益为Cash/UV+6%
4.2 服务承诺挖掘
背景:挖掘商家服务实体过程中,发现商家描述信息中有一些承诺信息未结构化,希望将其挖掘后在列表页露出展示给用户,一方面可以展示商家的优点,另一方面方便用户筛选商家。
服务承诺定义:商家对服务的承诺,有一定特色,如下图横线部分

图13: 服务承诺定义示例
该场景面临的挑战:
• 相对于服务实体,承诺挖掘无明显规则,更偏语义理解
• 小数据量下微调,准确率不足
大模型挖掘方案:
• 分段式抽取;对于复杂任务,思维链模式下效果更好;因此先生成摘要,再抽取承诺;与服务实体相同,进行 1shot 提示
• 分类目挖掘;因为不同类目下商家描述格式有所不同,模型学习不够全面,因此准确率只能到80%+;分类目微调,每个类目300个样本进行微调后,准确率可收敛到90%+;因为黄页类目有200+,我们只选取 Top 类目进行微调
该项目推全后,带来的业务收益为Cash/UV+10%;APP展示效果如下:
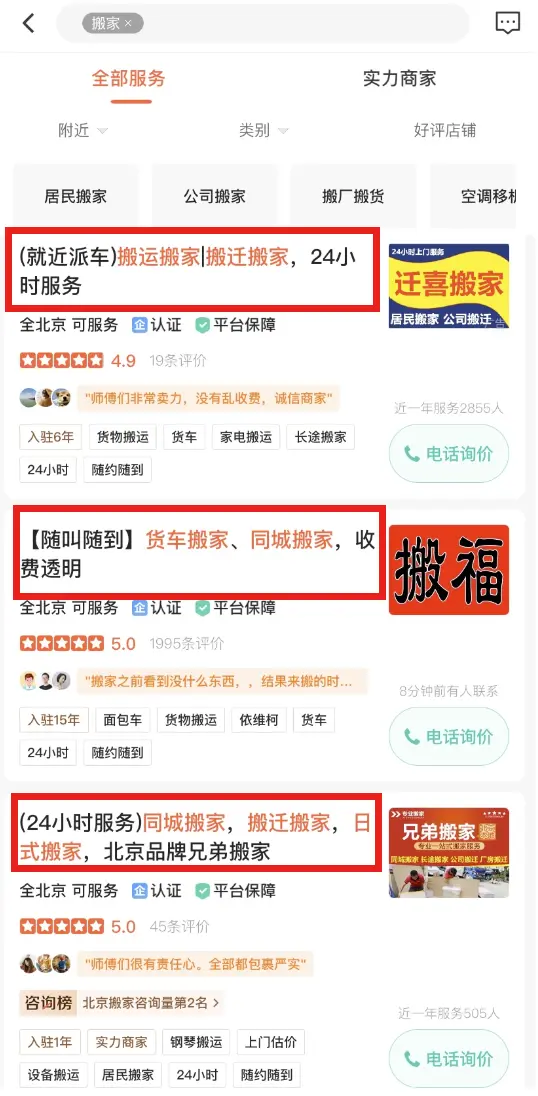
图14: APP展示效果示意图
总结:
在大模型落地的2个场景中,通过优化用户体验,带来10w+/日的商业收益。但大模型升级中依然面临一些技术挑战。大模型落地过程中,优先考虑将准确率提升到90%+,但长文本下有召回率不足的问题,未来需要通过加强大模型对长文本的理解进行优化,对此我们将结合业务场景,持续进行探索。

