双线程还是双核?AMD推土机处理器简析
Bulldozer的微架构确实有些新意思,在设计工程量上估计不算太低——都集中在双“簇”运算单元上以及相关的指令调度上。因此在处理器前端上很可能是和目前比没有什么变化。当然双份的指令拾取是必要的。

AMD Bulldozer
在解码器上,目前的K8~K10架构都是具有三个复杂解码器,解码器将macro-ops——x86指令解码成一条或者多条micro-ops,不同的x86处理器虽然都运行相同的x86指令,不过内部的micro-ops则各有不同。Bulldozer很可能是具有四个复杂解码器。Nehalem则是一个复杂+三个简单,相对来说,笔者比较喜欢四个一样的复杂解码器。之所以说是复杂,是因为虽然大部分x86指令都可以解码成一条micro-ops,但是有些指令则可能会解码出数十条micro-ops。
解码器通常被认为是前端的一个瓶颈,特别是在多线程的情况下。Bulldozer解码器输出若无意外,应该是4条micro-ops指令每周期。

Nehalem Microarchitecture,经笔者整理
所谓的乱序架构,包含了寄存器重命名等一堆架构,大致包含在图上的Scheduler阶段,由于整数单元簇包含了整个硬件线程对数据缓存操作的Load/Store操作,因此Scheduler之前指令应该会按照硬件线程分开,再经过重命名结构发射入类似reservation satation这样的组件。reservation station用于保存一组当前正在执行或者等待执行的指令,AMD处理器一向有整数、浮点具有独立的reservation station的习惯。
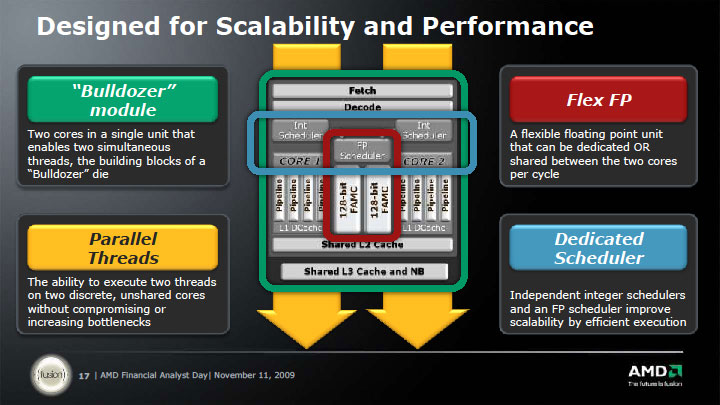
在执行单元上,AMD给出的是每个硬件线程具有4条整数执行流水线,此外两个128位浮点F-MAC运算单元,和一般的浮点运算单元有所不同,不过这不是现在的重点……重点在于整数运算流水线,有几个是Load/Store单元,或者具有另外的Load/Store单元?这些目前都是谜团。一个很可能的情况是一半是通常的运算单元,一半是Load/Store单元。这比较符合前端解码器的指令输出能力。不过这样,每个硬件线程就相当于一个双发射的处理器而不是通常的四发射处理器,因此笔者也倾向于每个硬件线程在四个整数流水线之外具有两个独立的Load/Store单元。

