解析:从Atom微处理器到通用处理器市场
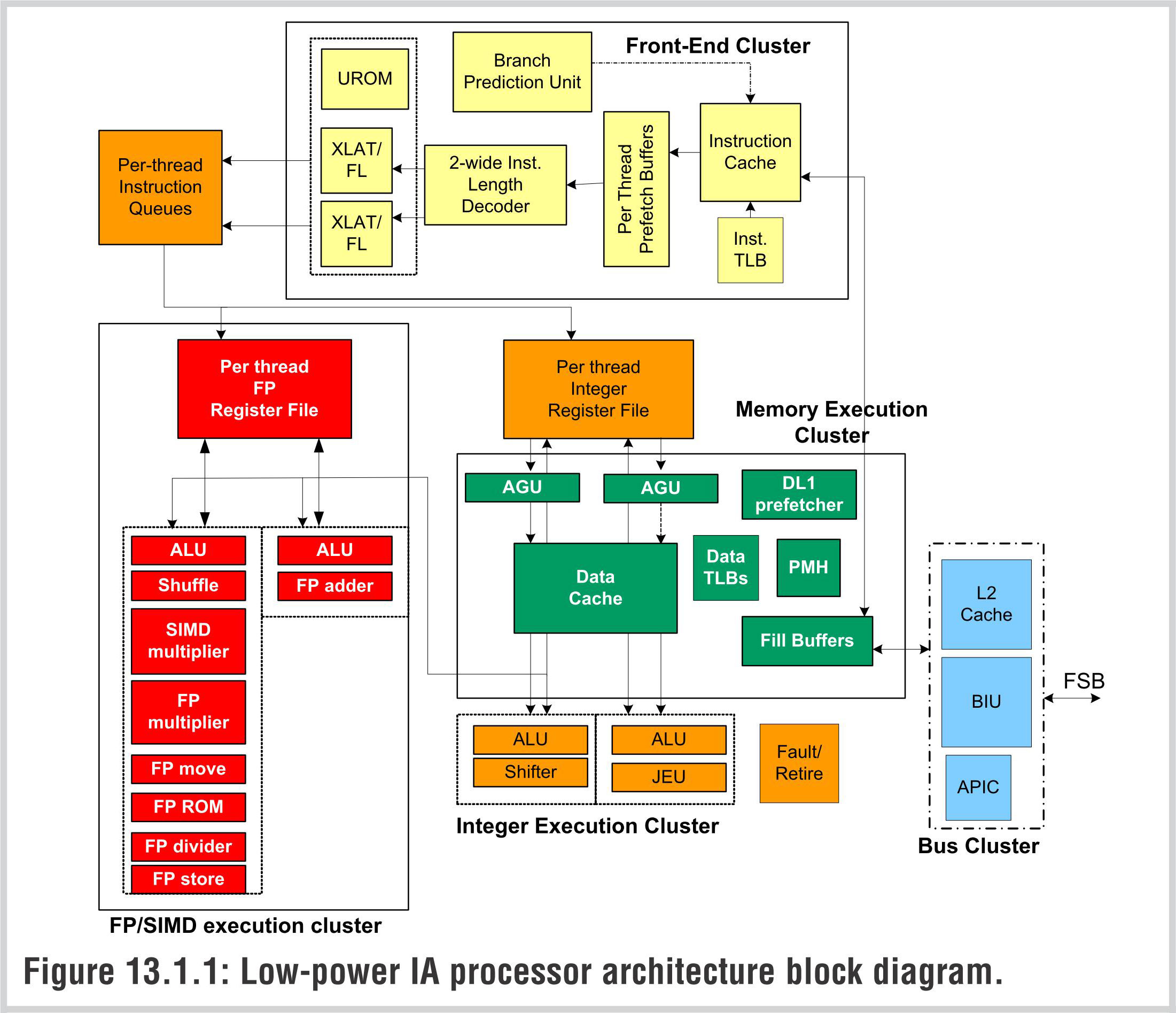
Intel Silverthorne Atom Microarchitecture
基于FUB设计,Silverthorne Atom处理器的划分用的是Cluster,簇。其中指令拾取和指令解码都属于前端簇,它们包含了6个级别的流水线——比通常的都要长一些,这是因为,通常x86处理器的瓶颈在两处地方:缓存读取和解码,长一些的流水线可以起到平衡的作用,并且增加的级数可以引进一个(或几个)指令队列,从而区段性地将流水线划分起来,这样在后方执行阶段的Critical Signal导致流水线级数的冻结要少一些。实际上,Atom还采用了“半乱序”的设计来降低顺序执行带来的分支预测失败惩罚。
| IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Instruction Fetch | Decode | Dispatch | Reg. File | Data cache read | Execute | Exceptions & MT | Write-back | ||||||||
在描述半乱序之前,我们必须先说一下Atom的顺序执行架构,它对解码器造成了影响:一般的现代x86处理器为了充分发挥乱序执行的能力,内部都通过解码器将x86指令翻译为类RISC的微指令uop,从而获得RISC架构的长处;为了提升效率,Load/Store和通常的Ops指令都是分开的。

而在Atom的顺序执行架构中,分开的Load/Store/Ops指令没有什么用处——反而有害,因为这些指令不能乱序执行,一条通常的Macro Ops(就是x86指令)解码成三条Load-Ops-Store指令最终仍然要顺序执行。因此Atom的解码器将这些操作都解码成单条的uop,从而提升了解码器的输出能力——x86处理器的瓶颈之一。这实际上有点像Nehalem上的Macro Fusion技术,体现了一些x86指令保持其顺序指令效率更高的情况。由于类RISC指令仍然具有优势,因此Atom内部仍然使用了uop架构。
和Pentium一样,在拾取缓冲之后,指令会先经过一个Length Decoder,由于x86需要面对不等长的指令,因此长度解码器它用来进行猜测指令的长度,这样虽然增加了流水级,然而配合后级解码器时可以达到更大的解码输出能力(不同的指令解码时间不同)。Atom的长度解码器可以同时输出两条指令。
Length Decoder之后就是常规的解码器,它包含三个解码器:一个复杂,两个简单。这些解码器将x86指令解码为uop微指令。

