解析:从Atom微处理器到通用处理器市场
【IT168评测中心】睿智的古希腊人相信物质并不是无限可分的,存在着一种最基本的“东西”,其它的物体都由其所组成。基于这样的信念,在公元前6世纪左右的时候,Leucippus(留基伯)提出了原子说,然后其学生Democritus(德谟克利特)进行了综合形成了原子论(哲学)并大约在公元前450年创造了Atomos(原子)这个词语。Atomos是古希腊文,意思是不可分的,a就是not(不、不可)的意思,tomos则是a cutting(分割)的意思,来源于temnein(to cut,还是分割)。后来演变成拉丁文的atomus到古法语的atome再到英文的atom。虽然现在的科学已经将原子分到了夸克的层次,不过atom的名字还是继续沿用了下来:

一个CH4甲烷分子:
molecule:分子;H:氢;C:碳
atom:原子;electron:电子;nucleus:原子核
neutrons:中子;proton、protons:质子
quark:夸克;pion:π介子
两个上夸克和一个下夸克通过π0介子传递的表观强相互作用力形成了质子(介子由一个下夸克和一个反下夸克组成);介子由夸克通过gluon胶子传递的强相互作用力“胶结”而成
希望这些没有把读者们都吓跑:这和本网站谈论的东西似乎不太搭边。其实我们想要说的是一个微处理器:Atom处理器。

Intel Atom Processor Logo
Atom处理器是数年前就开始研发,并在2008年IDF宣布的一个很特别的x86处理器,在发布后的一年多时间内,Atom获得了极快速的应用。同时,在这一年多时间内,随着金融危机的影响,半导体业界也是风云变幻,在一片混乱中,一些厂商消亡,一些厂商则试图建立新的秩序。
一年:Atom处理器发展历程
移动网络设备平台(MID,Mobile Internet Device)是Intel在2008年初推行的一个新概念,其特点就是:随时随地连接Internet——随时随地和Internet两个要素都很重要。MID需要轻巧便携。随着体积的减小,产品的散热是需要考虑的问题,功耗也是保障“移动”需要注重的地方。作为发热大户处理器当然是需要技术创新来做保障的。Intel在2008年3月2日为MID平台发布了新的低功耗处理器家族,命名为Atom。

当时使用的还是竖版LOGO
Intel给Atom处理器取了一个好听的中国名字,叫“凌动”。在发布的时候使用了两个LOGO,并按照计划划分为两个产品线系列:通常的Atom和Centrino,两者的区别主要是系统架构上:前者是三芯片体系,后者是两芯片体系,通俗地说,前者就是常见的Diamondville,面向标准PC架构;后者则是Silverthorne,专门面向MID设备。

Atom处理器与硬币
Atom处理器是Intel历史上体积最小和功耗最小的处理器。Atom基于新的微处理架构,专门为小型设备设计,旨在降低产品功耗,同时也保持了同酷睿2指令集级别上的完全兼容,Atom还能支持多线程处理。而所有这些只是集成在了面积不足25平方毫米的芯片上,内含4700万个晶体管。而11个这样大小的芯片面积才等于一美分硬币面积。

Atom:凌动处理器
Intel推出Atom是基于对市场的认识。在2008年之前,Intel已经有了以上网为应用中心的电脑(UMPC)平台,然而Intel认为对低功耗的需求会进一步增长,于是就有了Atom(当然,Atom的研发很早就开始了)。不过从上一年的市场来看,Atom原定的目标平台MID的发展缓慢,倒是在标准PC架构(包括NetBook上网本)上得到了广泛的应用,这也让Centrino Atom的名字少为人知,而三芯片Atom的高功耗缺点倒是广为流传,针对这一点,最近Intel的策略开始发生了变化,不过这一点后面再谈,下面我们先来分析一下Atom处理器崭新的微架构。
时值2004年,开发NetBurst架构的美国德克萨斯州(Texas)的奥斯丁(Austin)设计团队尚在设计Tejas(Prescott的下一代)。很快NetBurst失败,Core架构被扶正,之后迅速地成为Intel的主要架构,产品开始扩展到桌面乃至服务器产品线——很可怕地,Austin设计团队被分派去设计一个极低功耗的CPU,就是后来的Atom凌动处理器。

ISSCC2008: A Sub-1W to 2W Low-Power IA Processor for Mobile Internet Devices and Ultra-Mobile PCs in 45nm Hi-κ Metal Gate CMOS
很多人都已经知道或者听说过:Atom处理器基于和主流完全不同的微架构。确实,Atom最特别的地方就是它采用了IOE(In-Order Execution)顺序执行架构,需要知道,从15年前的Pentium Pro处理器(当时俗称686)开始,Intel的处理器就转向了OOOE(Out-of-Order Execution)乱序执行架构,采用IOE架构的原因是什么呢?
Intel Nehalem Microarchitecture,经笔者整理
答案是为了功耗,Intel当前的明星Nehalem处理器就属于典型的OOOE乱序执行架构,乱序执行是为了直接提升ILP(Instruction Level Parallelism)指令级并行化的设计,在具有多个执行单元的超标量设计处理器当中,一系列的执行单元可以同时运行一些没有数据关联性的若干指令,只有需要等待其他指令运算结果的数据会按照顺序执行,从而总体提升了运行效率。乱序执行引擎是一个很重要的部分,需要进行复杂的调度管理,需要大量的晶体管实现,这就意味着更高的功耗。
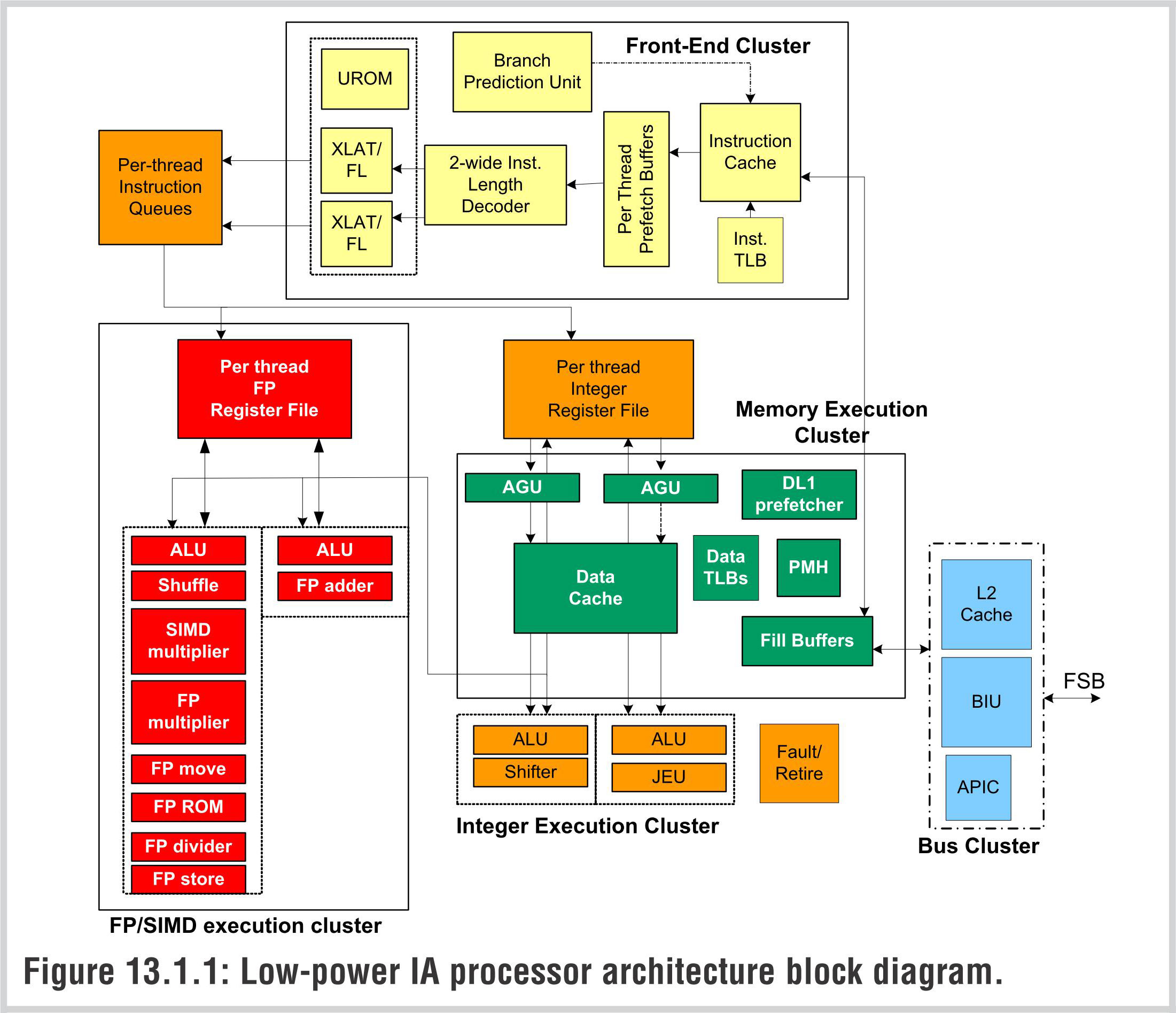
Intel Silverthorne Atom Microarchitecture
来源:ISSCC2008 Intel Paper: A Sub-1W to 2W Low-Power IA Processor for Mobile Internet Devices and Ultra-Mobile PCs in 45nm Hi-κ Metal Gate CMOS
采用了顺序执行架构之后,Nehalem架构图中的黄色部分就可以去掉了,如寄存器重命名相关部分、ROB/MOB相关部分的大量晶体管得以节省,从上图上看,Silverthorne Atom结构图远比Nehalem要简洁——当然这个简洁也有除了IOE架构之外的原因:Atom是一个2-issue(二发射)的超标量处理器,而Nehalem则是四发射的,在执行单元上Atom也能简化了不少。实际上,节电是Atom处理器设计上的首要目标。
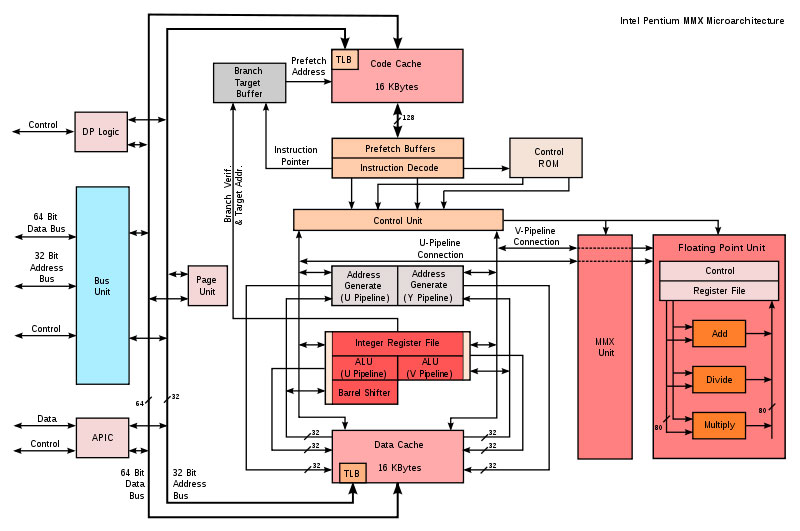
Intel Pentium MMX Microarchitecture
实际上,Atom看起来有点像以前的Pentium(俗称的586)处理器架构。Pentium也是一个二发射的超标量处理器架构,不过,Silverthorne Atom和Nehalem都是64位处理器,而Pentium是32位处理器。Atom当中也有不支持64位处理的型号。

Intel Silverthorne Atom处理器晶圆图
Atom处理器设计使用了功能单元模块化(sea-of-Functional-Unit-Blocks)设计,虽然和最终用户没有什么关系……这种基于对象的设计方式实现起来会方便一些,它将所有的功能都更细地划分为一个一个的功能单元FUB,这些功能单元可以使用标准的设计,从而降低设计复杂度(Atom设计团队规模比较小)。这种设计方法也可以很方便地对处理器的功能进行增删,以满足各式各样的应用需求。
Sea of FUBs
FEC: front-end cluster (plus L1 instruction cache)前端簇
FPC: floating point cluster浮点簇
IEC: instruction execution cluster指令执行簇
MEC = memory execution cluster (plus L1 data cache)内存执行簇
BIU = bus interface unit总线接口单元
Silverthorne Atom包含了205个特有FUB(不包括中继器)和4.1万个FUB-to-FUB联结,91%的FUB使用了标准的结构:45%使用了structured data-path结构化设计,46%使用了综合随机布线设计,这些单元的设计布线都可以通过计算机来完成。剩下的9%是全定制的功能模块,需要设计人员花费精力来完成。
Intel Silverthorne Atom Microarchitecture
来源:ISSCC2008 Intel Paper: A Sub-1W to 2W Low-Power IA Processor for Mobile Internet Devices and Ultra-Mobile PCs in 45nm Hi-κ Metal Gate CMOS
Atom Microarchitecture Features
虽然具体执行架构上不同,不过和乱序执行一样,顺序执行也包含了取指(Instruction Fetch)、解码(Decode)、执行(Execute)、回退(Retire)这四个阶段。Atom处理器包括了16级流水线,作为对比,Pentium处理器的流水线只有5级,Pentium MMX则有6级(执行MMX指令的时候流水线还要继续增加),而Cornoe也只有14级,更长的流水级数的一个原因为了能达到更高的频率(就像IBM的高频怪物Power6/6+一样;Power6也是一个顺序执行处理器)。

5 stage Pipeline: Intel Pentium
6 stage Pipeline: Intel Pentium MMX (normal interger execution)
16级流水线包括了三级的Instruction Fetch取指、三级Decode解码、两级分发、一级读寄存器和三级读数据缓存、一级执行、两级例外例程和多线程处理和最后一级写回。
| IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Instruction Fetch | Decode | Dispatch | Reg. File | Data cache read | Execute | Exceptions & MT | Write-back | ||||||||
Intel Silverthorne Atom Microarchitecture
基于FUB设计,Silverthorne Atom处理器的划分用的是Cluster,簇。其中指令拾取和指令解码都属于前端簇,它们包含了6个级别的流水线——比通常的都要长一些,这是因为,通常x86处理器的瓶颈在两处地方:缓存读取和解码,长一些的流水线可以起到平衡的作用,并且增加的级数可以引进一个(或几个)指令队列,从而区段性地将流水线划分起来,这样在后方执行阶段的Critical Signal导致流水线级数的冻结要少一些。实际上,Atom还采用了“半乱序”的设计来降低顺序执行带来的分支预测失败惩罚。
| IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Instruction Fetch | Decode | Dispatch | Reg. File | Data cache read | Execute | Exceptions & MT | Write-back | ||||||||
在描述半乱序之前,我们必须先说一下Atom的顺序执行架构,它对解码器造成了影响:一般的现代x86处理器为了充分发挥乱序执行的能力,内部都通过解码器将x86指令翻译为类RISC的微指令uop,从而获得RISC架构的长处;为了提升效率,Load/Store和通常的Ops指令都是分开的。
而在Atom的顺序执行架构中,分开的Load/Store/Ops指令没有什么用处——反而有害,因为这些指令不能乱序执行,一条通常的Macro Ops(就是x86指令)解码成三条Load-Ops-Store指令最终仍然要顺序执行。因此Atom的解码器将这些操作都解码成单条的uop,从而提升了解码器的输出能力——x86处理器的瓶颈之一。这实际上有点像Nehalem上的Macro Fusion技术,体现了一些x86指令保持其顺序指令效率更高的情况。由于类RISC指令仍然具有优势,因此Atom内部仍然使用了uop架构。
和Pentium一样,在拾取缓冲之后,指令会先经过一个Length Decoder,由于x86需要面对不等长的指令,因此长度解码器它用来进行猜测指令的长度,这样虽然增加了流水级,然而配合后级解码器时可以达到更大的解码输出能力(不同的指令解码时间不同)。Atom的长度解码器可以同时输出两条指令。
Length Decoder之后就是常规的解码器,它包含三个解码器:一个复杂,两个简单。这些解码器将x86指令解码为uop微指令。
Intel Silverthorne Atom Microarchitecture
由于顺序执行架构必须按照指令原定的顺序执行,因此最怕碰到的情况就是流水线停滞(pipeline stall),这种情况可以被高延迟缓存操作导致——特别是需要访问缓慢的内存的时候,这时顺序执行架构需要停工而一直等待数据的到来,性能可想而知,并且电力也一直在无谓的浪费,无疑非常糟糕。
| IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Instruction Fetch | Decode | Dispatch | Reg. File | Data cache read | Execute | Exceptions & MT | Write-back | ||||||||
乱序执行架构可以通过简单地挑选另外的指令来执行解决,对于完全的顺序架构来说显然无计可施。最后,Atom实现了一个折中的方案:半乱序架构。这种方案采用了一种叫做SIR(Safe Instruction Recognition,安全指令识别)的算法,该算法的机制是这样:当Atom需要执行一条高延迟的浮点运算,而后面跟着一条短延迟的整数操作时,顺序执行机制需要等浮点操作完成之后才能去执行后面的整数操作;但是采用SIR就可以先查看两条指令所需的数据是否有关联,如果没有关联SIR就允许将后面的整数操作提前执行,从而节省时间提高效率。它实际上就是在特殊情形下的乱序执行。
SIR只在很少的特殊情况下有效,它使Atom的顺序执行没有那么纯粹——当然这些情况不多见,因此通常仍然认为Atom是一种顺序架构。
Atom的HTT超线程技术和Pentium/Nehalem的一样都属于SMT,和Itanium 2的CMT不同
在解码之后,指令们将会先保存在一个队列当中,按照HTT超线程技术存在与否,分发器在当中寻找同一线程的两条指令,或两条线程的各一条指令来执行,分发阶段占用两个流水线级。
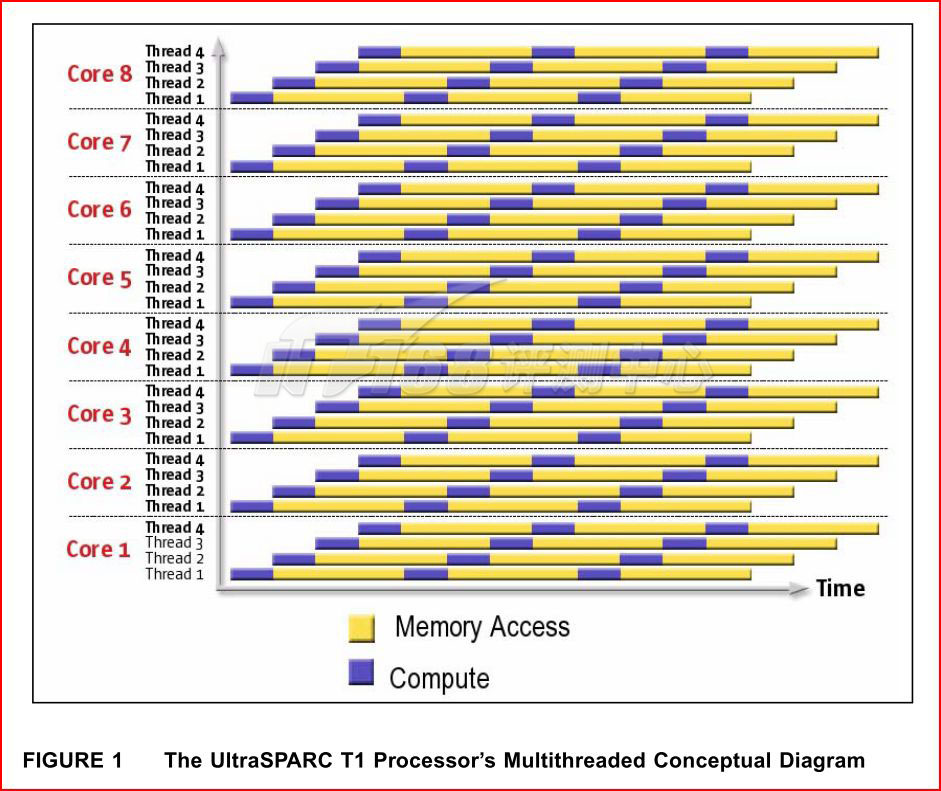
Sun UltraSPARC T1处理器,8核心,每核4个线程(基于FMT技术)
HTT超线程技术是多线程技术的一种,它可以以较小的晶体管代价(因此功耗代价也很小)获得不错的性能提升。在某种程度上,它也可以缓解顺序执行架构的停滞问题:当一线程在执行长延迟的内存读取的时候,分发器就可以全部选择另一个线程的两条指令来执行,这一点让它看起来很像CMT(粗粒度多线程技术)。很多顺序架构的处理器都采用了各种各样的多线程技术来降低高延迟内存读取的影响以及提升指令执行效率,如上图的Sun UltraSPARC T1。或许Atom未来会进一步采用CMT和FMT技术。各种多线程技术可以看下面:
| IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Instruction Fetch | Decode | Dispatch | Reg. File | Data cache read | Execute | Exceptions & MT | Write-back | ||||||||
由于通常的Load-Ops-Store这样的x86指令在Atom里面解码为单条的uop,因此和乱序架构不同,顺序架构的Atom在执行流水级内包含了所有的四级存取操作,一级是读寄存器——整数和浮点具有独立的寄存器文件;剩下三级和缓存读取有关:AG、DC1、DC2,AG就是Address Generate地址生成,Atom具有两个AGU地址生成单元。Atom没有寄存器重命名机制,Pentium有这个机制。




Intel Silverthorne Atom Microarchitecture
在读取好各种参数之后,uop们就可以进入执行单元执行了,从表面上看,Atom具有两个整数执行单元和两个SIMD/浮点执行单元,它们分别处于整数执行簇和浮点执行簇。不过,这些执行单元大部分都很简单,并且功能互相交叉:Atom没有专用的整数乘法器或整数除法器,这些运算都由SIMD/浮点单元来完成。Atom的两个整数单元,一个带有Shifter(移位运算),一个带有JEU(Jump Execution Unit,跳转执行单元),也就是说Atom一个时钟周期只能执行一条跳转指令。
Atom的两个SIMD/浮点单元也不同,一个只能执行浮点加法,另一个才能执行完整功能的浮点计算(同时SIMD也在这里进行)。一般浮点运算所占的比例不多,Atom的这种设计让所有的运算单元在平常也能得到较多的利用效率——都在做整数运算。相对来说,x86的浮点运算能力是比较强的。
由于复杂度和功耗的原因,Atom只实现了SSE3而没有实现SSE4。除了支持全精度整数SIMD和单精度FP ADD外,所有单元均为64位宽度。在同一时间,Atom能执行一条128位SIMD操作。



Intel Silverthorne Atom Microarchitecture
| IF1 | IF2 | IF3 | ID1 | ID2 | ID3 | SC | IS | IRF | AG | DC1 | DC2 | EX1 | FT1 | FT2 | IWB/DC |
| Instruction Fetch | Decode | Dispatch | Reg. File | Data cache read | Execute | Exceptions & MT | Write-back | ||||||||
写回是Atom处理器流水线的最后一级,指令结果会被写入到寄存器文件和缓存当中。Atom具有不对称的L1缓存结构:指令缓存为32KB,而数据缓存只有24KB。Atom具有512KB L2缓存。特别地,Atom还具有10.5KB C6缓存用来保存在深睡眠状态下的架构状态数据,这时核心电压已经降到了0.3V。
Atom的L1实现了1位校验,无ECC功能。Atom的L2实现了ECC,8路集合关联,可以以9个时钟周期的延迟和L1交换数据。和Nehalem一样,不需要用到的缓存块可以被关闭。
为了适用低电压,这些缓存使用了8-T静态随机存取器技术,这个技术在Nehalem/Dunnington行也有采用。和通常采用6个晶体管来保存一位数据不同,8-T晶体管技术增加了两个晶体管以分开读和写通道。8-T静态随机存取器技术使用更低的工作电压,因此更为省电。由于Silverthorne Atom里面缓存部分所占面积几乎达到了50%,因此这一举动无疑非常重要。
除了8-T SRAM技术之外,Atom还采用了如double stacked PFET这样的技术来降低能耗。


Atom目前仍然使用了FSB(Front Side Bus)总线——这表明其没有集成内存控制器。集成内存控制器的版本年内将会发布,后面将会继续提到。Atom支持400MT/s或者533MT/s的FSB,带宽分别为3.2GB/s和4.26GB/s。
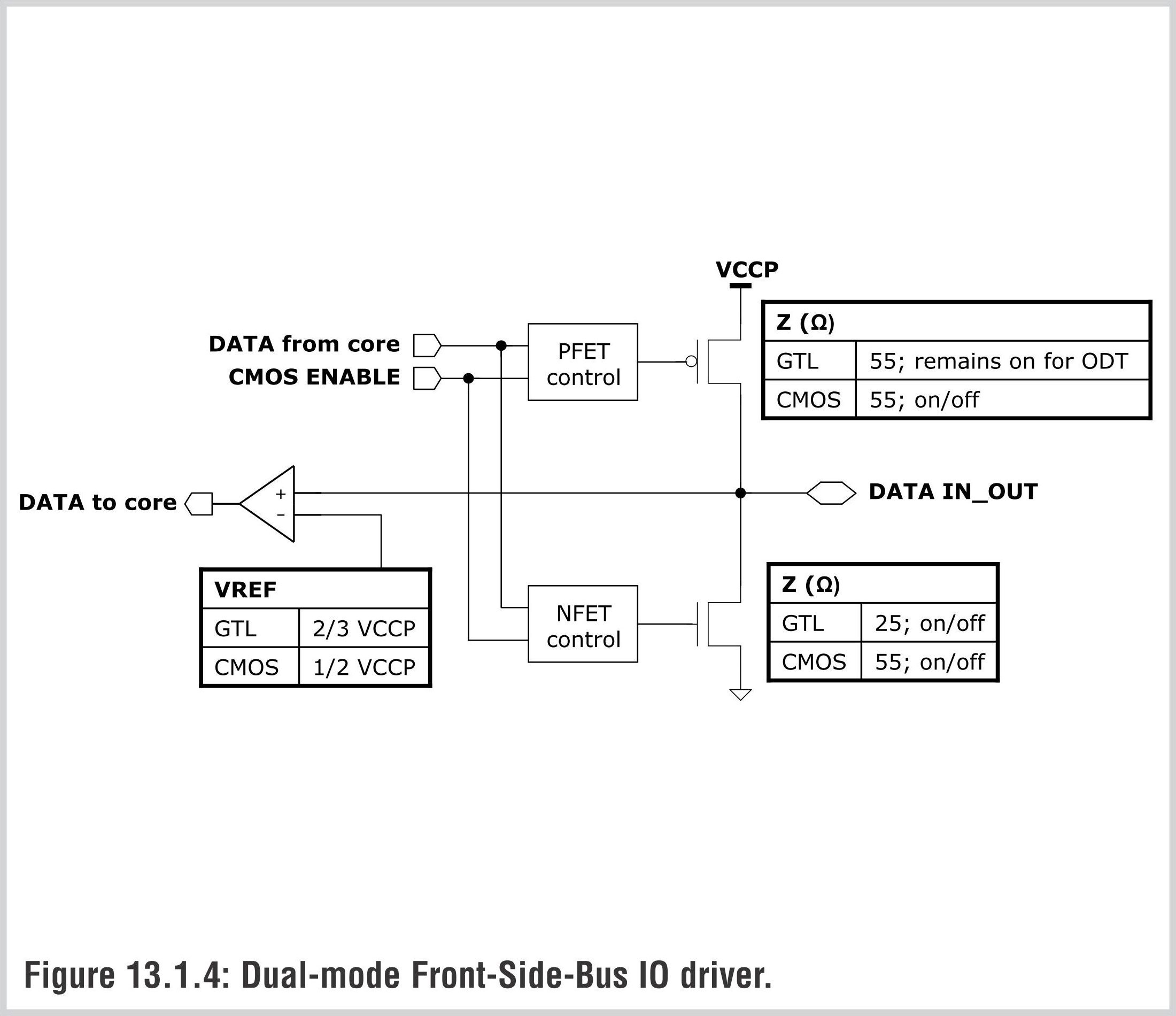
当前的Atom支持双模式FSB:GTL和CMOS,后者的功耗更低一些,提供两种模式选择是为了提供更好的芯片组兼容性(Poulsbo支持CMOS模式,一般的945支持GTL模式)。
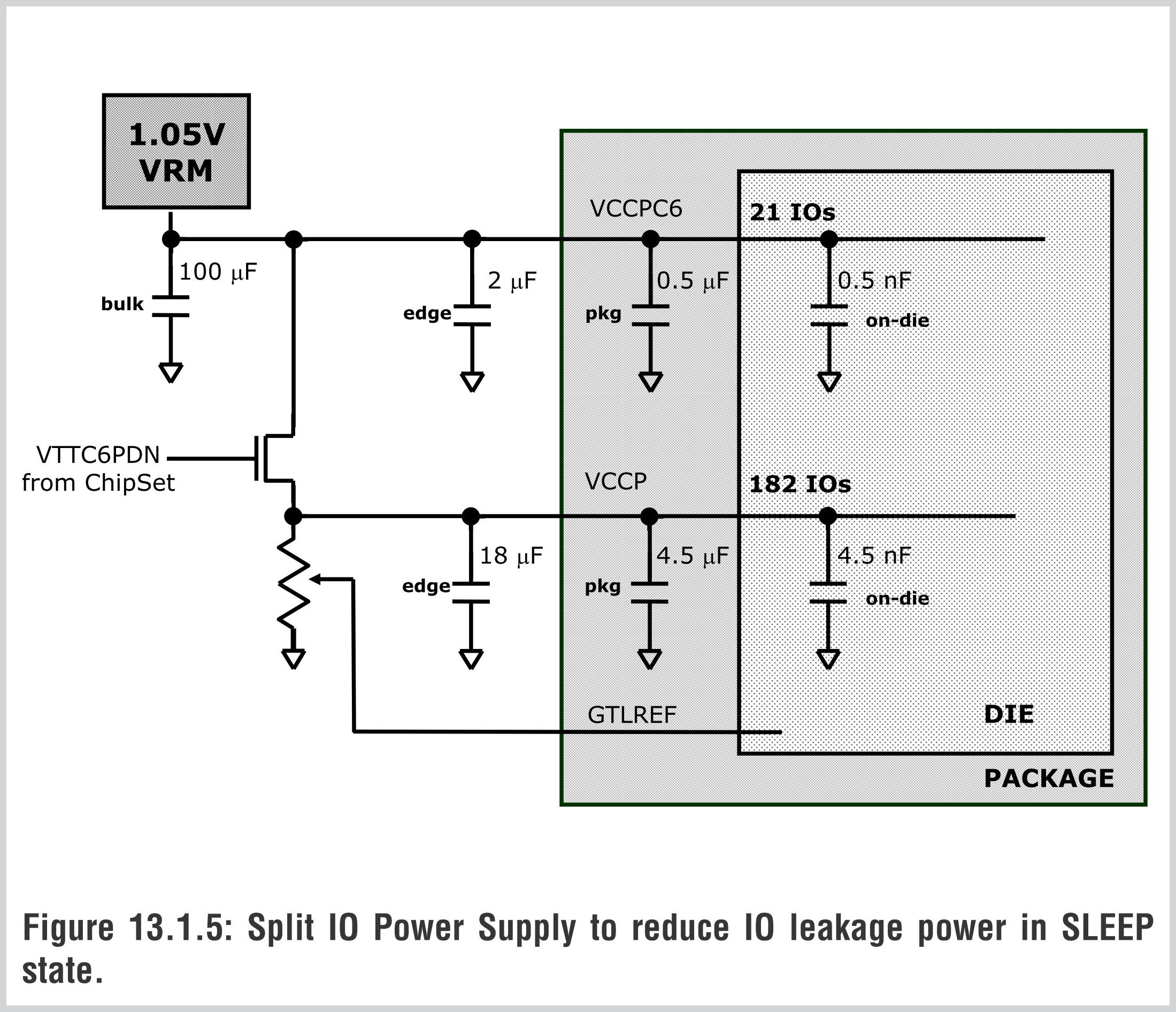
Atom提供的C6深层睡眠模式能耗为正常状态下的1.6%
Silverthorne Atom采用Intel的45nm High-K金属棚极工艺制造,晶体管数量为4700万,核心面积25mm2,使用了9层CMOS工艺,14x13mm2 441 uFCBGA封装。在2GHz时TDP功耗为2W。


当前Atom已经推出了很多种型号,按照前面说过的划分方法,它们分为Silverthorne和Diamondville两种。可以看出,Atom里面包含了多种类型,如支持VT硬件辅助虚拟化技术的型号、支持64位运算的型号,以及双核型号。不过遗憾的是没有一个包含所有这些增强特征的“终极”型号。支持VT的话,在未来会有比较特别的应用。
如本文一开始所说的那样,Intel准备了两种Atom平台:双芯片与三芯片,前者使用Silverthorne处理器与Intel SCH(System Controller Hub)芯片组,后者则使用传统的Diamondville处理器和945GSE/ICH7M芯片组。后面这种组合方式一直被人诟病:945芯片组实在太老,功耗太大(945GC TDP大约22W),远比处理器要高。在搭配945GSE的情况下,功耗可以降低到可以接受的情况(5.5W,其中4W北桥、1.5W南桥),不过此时整合GMA图形芯片的运行频率也从945GC的400MHz降低到了133MHz,对于NetBook来说,应该还是可以接受的。

Silverthorne

Silverthorne

Silverthorne

Diamondville三芯片家族

Menlow平台:Atom处理器与SCH芯片

Poulsbo芯片结构。Poulsbo采用了130nm工艺
使用传统945芯片组的Atom平台没有什么特别的地方,唯有使用了SCH——Poulsbo单芯片的Atom平台才值得一提,在体积越来越小、功耗越来越低的领域,数量更少的芯片解决方案是一个必然,最终的目标是单个芯片就能实现所有的功能:System-on-chip——SoC。Intel的这个平台的名字叫做Menlow。
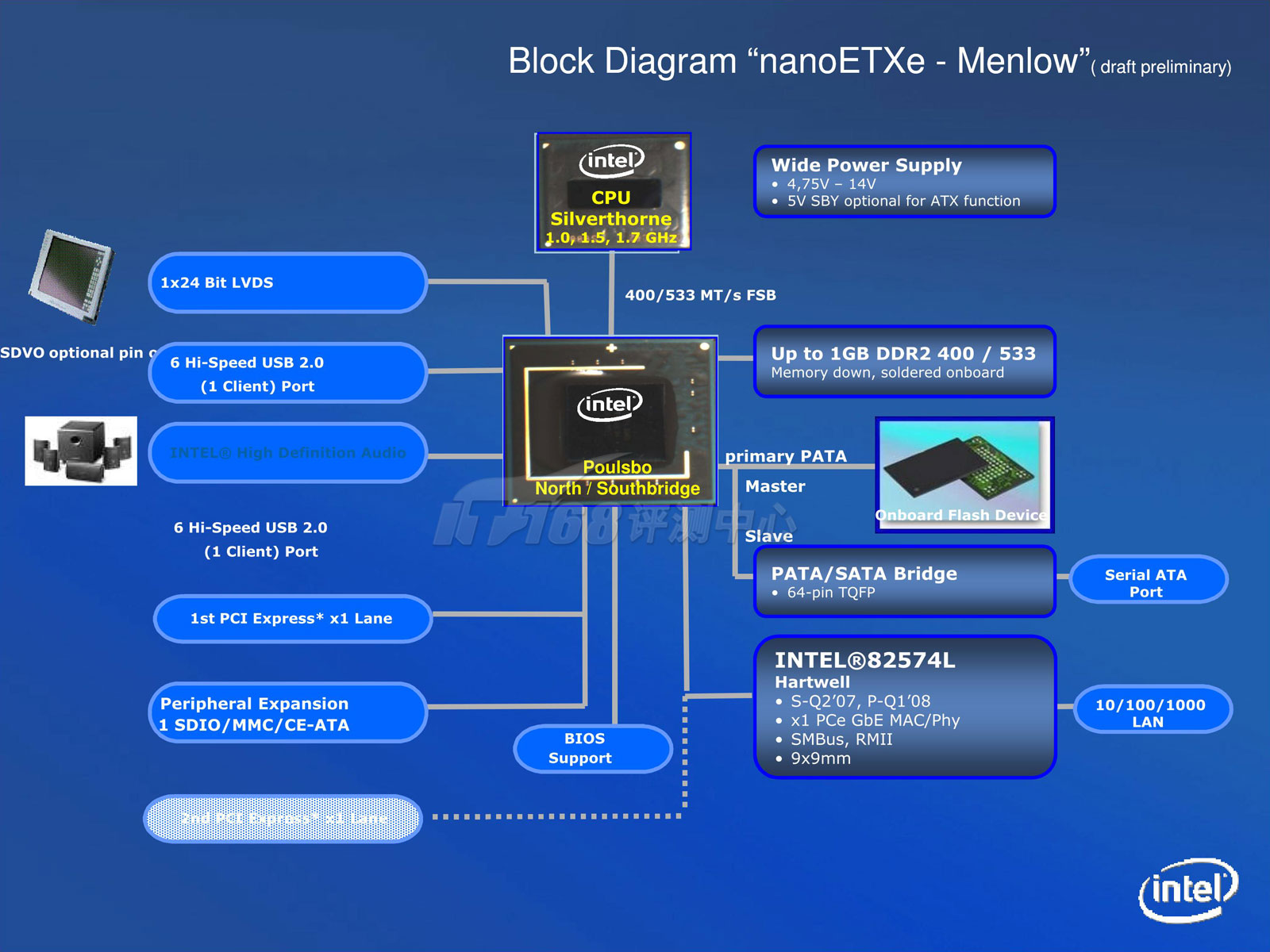
Menlow平台实现的ETX平台示例
Poulsbo是Intel从零开始的新设计,基本上就是把北桥和南桥的功能集成在一起,为了节能,多余的功能一概被去掉,如,Poulsbo只支持PATA,因为运作的时候,SATA要比PATA耗电得多。Poulsbo只支持单通道DDR2 400/533,并且最大只能支持1GB;Poulsbo支持特别的1.5V低电压版本DDR2,一般的DDR2电压为1.8V。其他如USB端口、PCI Express支持等都有所削减,总的来说,就是用功能换取功耗。Poulsbo集成了PowerVR SGX 3D引擎,2D部分则使用Intel自己的技术。

ETX规格的Menlow平台主板
显然,上网本厂商们相对于Diamondville + 945GC + ICH的方案会更加喜欢Menlow平台:更少的芯片,更低的功耗,产品也会更加小巧,然而Intel之前一直控制着Menlow平台仅供给MID平台,不过MID由于定位尴尬、电池续航力等问题,一直未能得到普及。
之前,因Intel担心冲击MID市场而不愿让Menlow平台用于普通PC、NB。然而和MID市场不景气的情况相比,Netbook市场却是竞争惨烈,各种厂商为推出更有特点、与既有市场相区隔的产品,纷纷表示希望转而采用Menlow平台,从而使得Intel态度转变,决定大举释出Menlow平台。
厂商们指出,虽然Menlow平台势将进一步冲击笔记本Notebook、上网本Netbook市场,但目前笔记本上网本产品线互踩的混乱局面已成事实。Intel在无法力阻下,目前至少可采取的策略是限制Netbook的屏幕尺寸。在下一代Moorestown将会很快推出的情况下,Menlow平台生命周期并不长,因此并不会造成太明显的影响,而年内推出的Moorestown平台会专注定位在MID,到时将会可能重新划清NoteBook、Netbook和MID的界线,提升MID的销量。





在5月,Intel召开媒体会,由Netbook/Nettop业务总经理Noury Al-Khaledy首次正式宣布了代号Pine Trail的下一代Atom上网本/Nettop平台。而事实上,有关Pine Trail的信息从今年年初开始就陆续被媒体披露出来,Intel此次只是进行了官方的证实。预计将于今年年底推出的Pine Trail平台仅由两颗芯片组成,分别是集成了CPU和北桥功能的Pineview,以及南桥芯片Tiger Point。从三颗芯片到两颗芯片,新设计可以节约平台成本,降低功耗并提升性能。
Menlow平台实现的ETX平台示例
同样是双芯片平台,Pine Trail和现在的Menlow有什么不同呢?答案是:定位不同,如同Atom处理器具有Silverthorne和Diamondville两个产品线一样,对应的平台也不同:Menlow是基于Silverthorne的第一代平台产品,而Pine Trail则是基于Diamondville的第二代产品,也就是上一代945GC/945GSE + ICH7的改良型,和Menlow相比,Pine Trail平台更加注重功能、扩展性,面向的市场也主要是较高性能的上网本和Nettop平台。而Menlow则是面向低功耗MID设备(当然现在也用于低功耗上网本)。
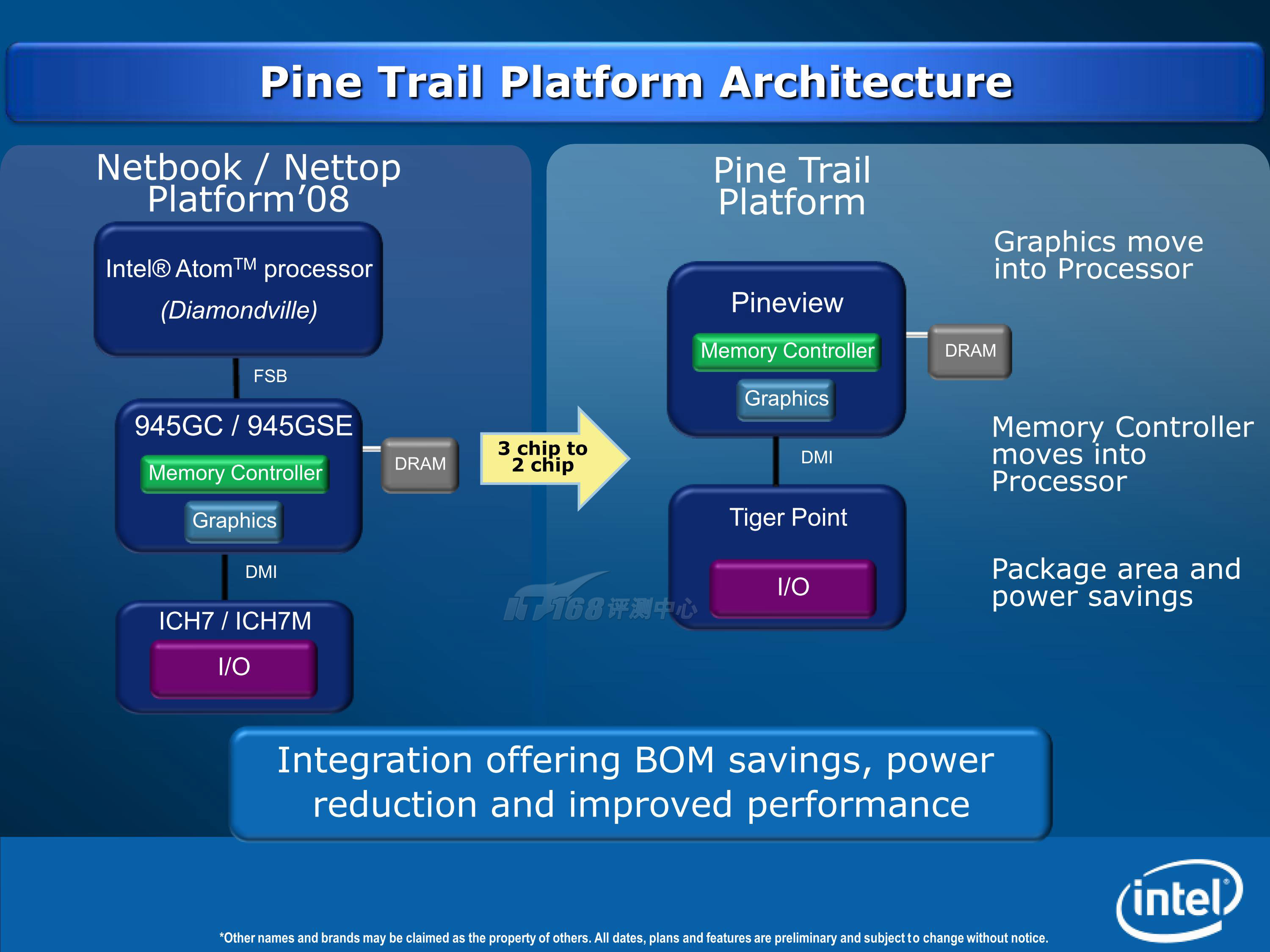
Pineview处理器的内部包括传统的Atom处理器核心、图形核心以及内存控制器等,使用45nm工艺制造。相比原有Diamondeville Atom + 945GC的组合,它的处理器核心以及图形核心频率都更高,再加上集成内存控制器,令其整体性能有所提升。不过,Intel此次更注重平台功耗的降低以及设计制造成本的下降。新的双芯片架构可使用低成本的四层PCB,芯片封装面积的缩小可简化设计,同时有望实现无风扇平台。
Tiger Point南桥负责PCI-E、SATA、HD Audio、USB等输入输出功能。根据之前的消息,该芯片可能仍然基于ICH7,制程也可能仍然为90nm。Pine Trail平台在性能上那个该会有不错的提升,而其最大亮点是整合度更高、功耗更低,可以打造更轻薄、更低价的上网本/Nettop。另外,集成图形核心的Pineview也有利于Intel打压NVIDIA ION离子平台这样的第三方Atom芯片组。
既然第二代Diamondville已经发布了消息,那么对应的Silverthorne也会有第二代产品,它就是Lincroft,对应的SCH叫做Langwell,整个平台叫做Moorestown。

Moorestown仍然基于45nm技术,主要目标放在进一步的功耗降低上,第一代的Menlow平台低功耗版本功耗约在5.5W左右,高功耗版本则会达到10W以上,只能面向MID平台(和上网本),Moorestown的目标功耗表现提高50倍,这样的功耗已经可以进入智能手机市场,不过,由于前面说过的原因,Intel应该会将其专注定位于MID,以充分拉回Menlow未能做到的振兴MID市场的任务。在手机上,暂时只能面向较高端的产品线。



更低的面积,整个系统就和一张信用卡的面积差不多
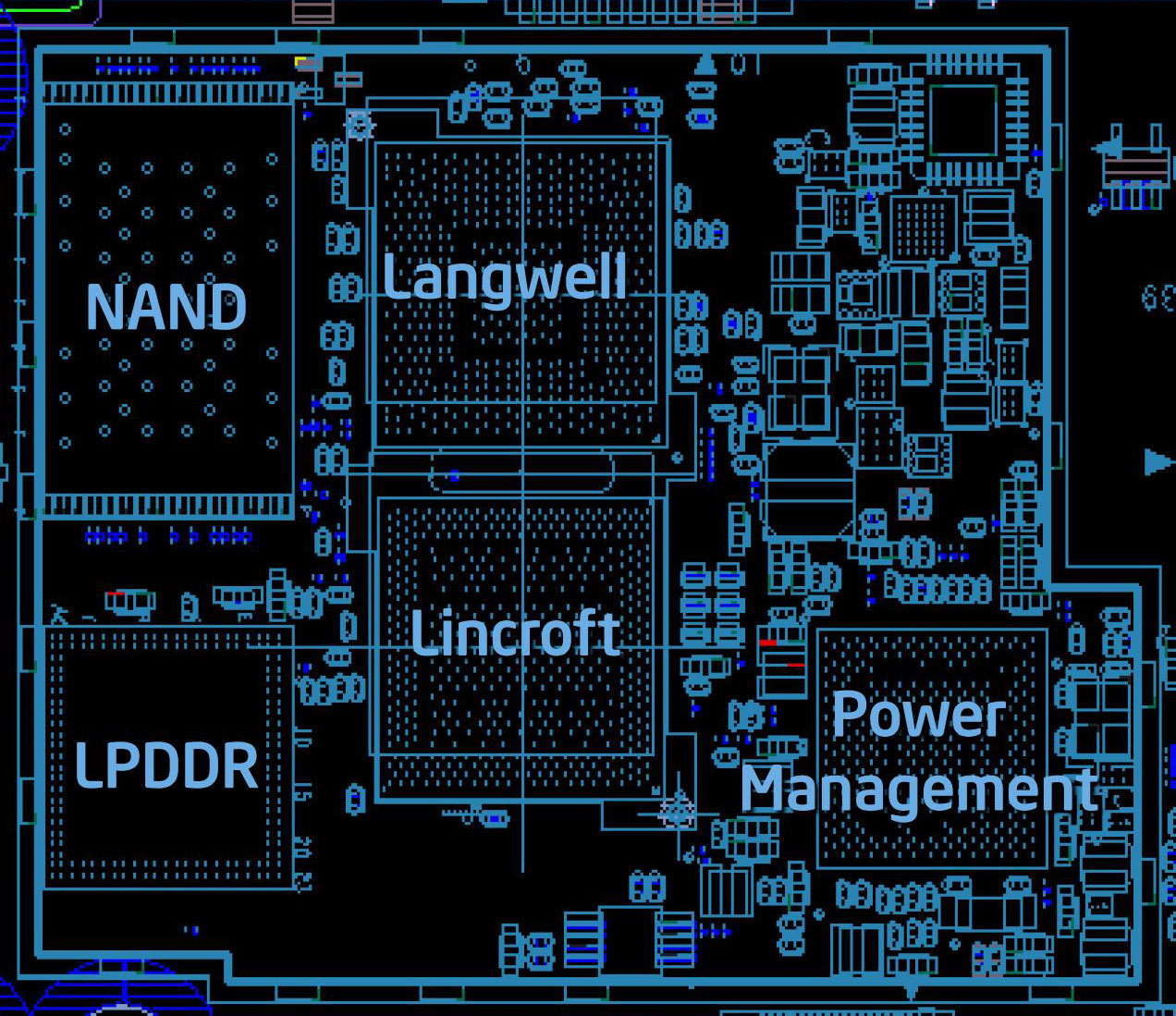
Moorestown平台;Langwell可能会由TMSC代工
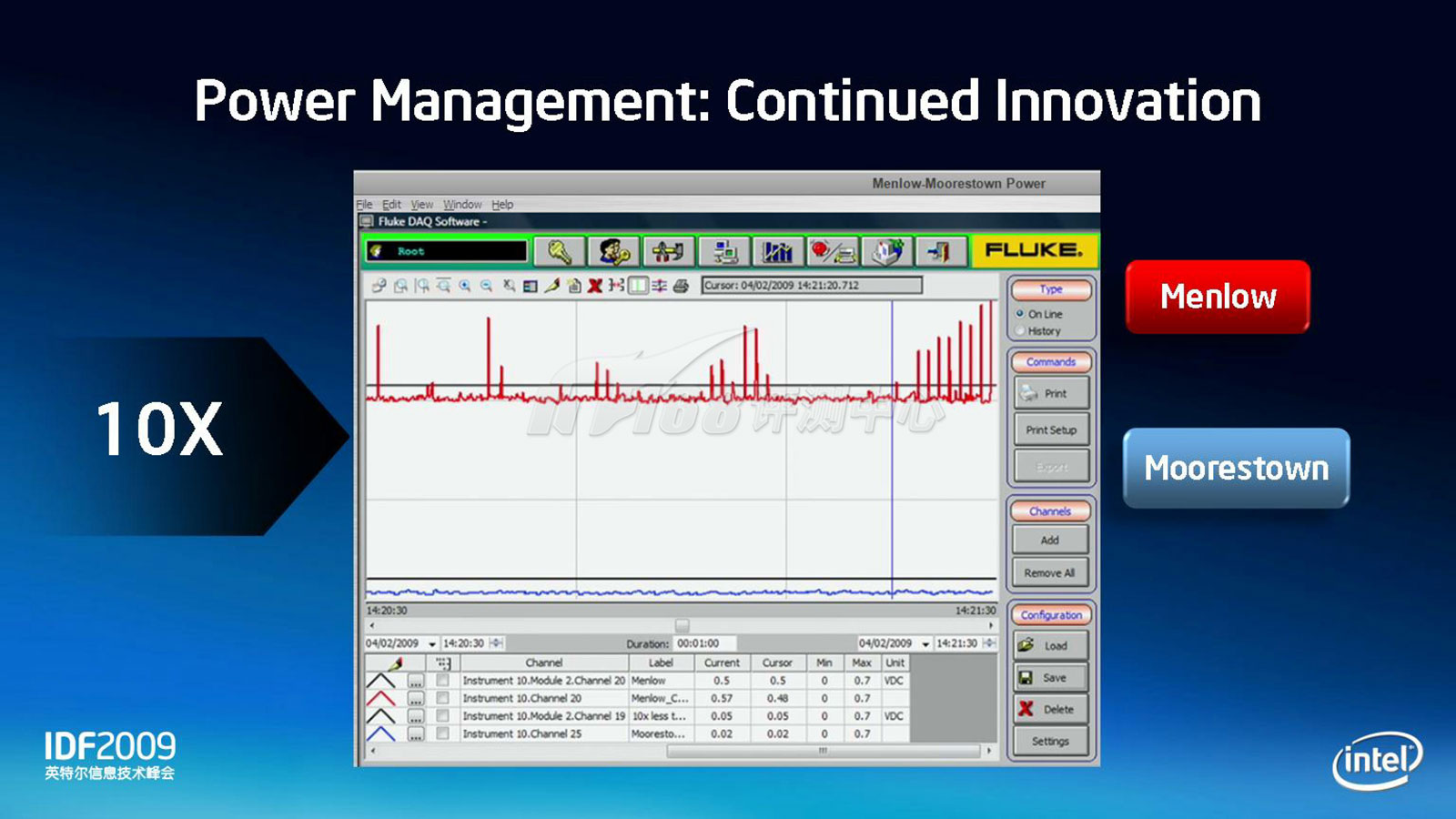
实测功耗
虽然我们还没能看到Moorestown大面积铺货(已经有一些样品了),不过Moorestown的下一代已经浮出水面了:Medfield,预定于2011年面世(尚有一大段时日)。32nm技术会在Intel明年的桌面处理器产品上得到应用,自然后面才会出现的Medfield会使用32nm技术。工艺制程的变化将会带来明显的功耗降低。

按照Intel的分析,智能手机对处理器的要求有以下几点:
峰值功耗 1.5到2W
典型功耗 300mW
续航时间 至少8小时
随时在线 无线宽带网络、电话网络
性能 高于3000DMIPS
兼容性 低开发成本,软件兼容性,代码复用性
如果说其上一代Moorestown只能用于一些高端智能手机的话,毫无疑问,Medfield就是瞄准了整个智能手机市场。



面积持续缩小

Intel预计Medfield Atom会得到广泛的应用
Atom:不断进化
从已有的路标上不难看出,作为一个长期性的处理器架构,Atom将会长久存在,并且将会是Intel的支柱产品之一,毕竟将一个处理器架构的潜力充分发挥一直就是Intel的拿手好戏,如同NetBurst架构也走了近十年才走到死胡同一样。Atom会走向一个什么样的领域呢?
显然,从路标来看,是移动处理器领域,Intel目前就是瞄准了智能手机市场(只需要通话功能的手机不需要强大的处理能力),虽然处理器巨头Intel目前在服务器和个人PC领域占据主导地位,不过在移动处理器方面,由QualComm、Texas Instruments、TMicroelectronics、MediaTek等这样的传统势力统治——它们的背后是ARM处理器。

一款采用Marvell PXA310处理器的手机
PXA310 SoC芯片,基于XScale处理器

Intel XScale处理器实际上基于ARM架构
QualComm高通公司的MSM7200芯片
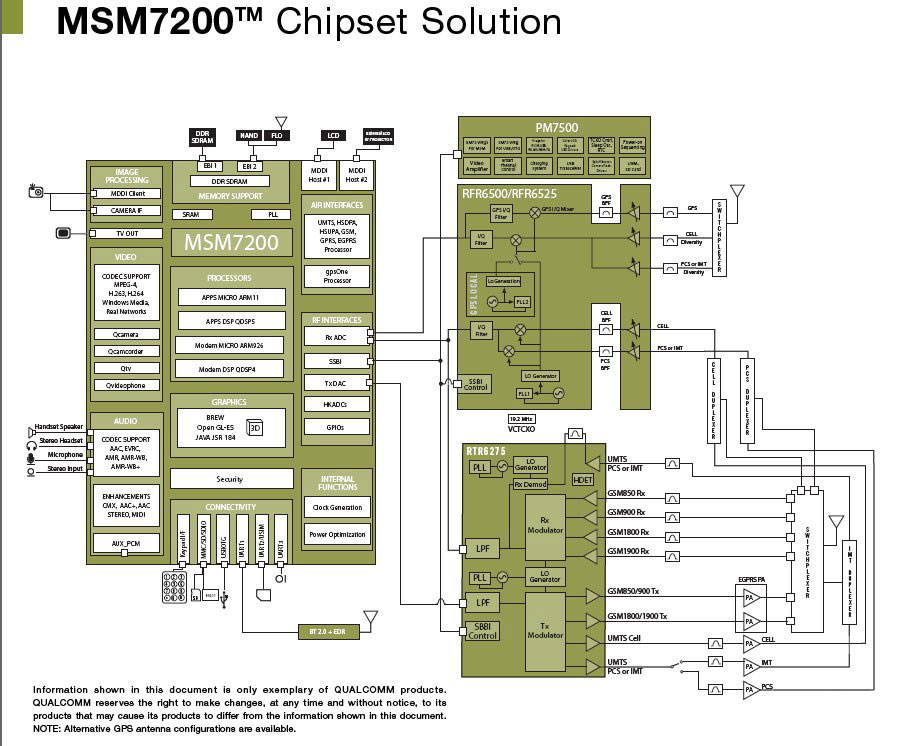
MSM7200 3G移动电话解决方案(似乎QualComm仍未能很好地解决单芯片集成射频电路,从这里来看Moorestown的双芯片方案也不是一个大的问题)
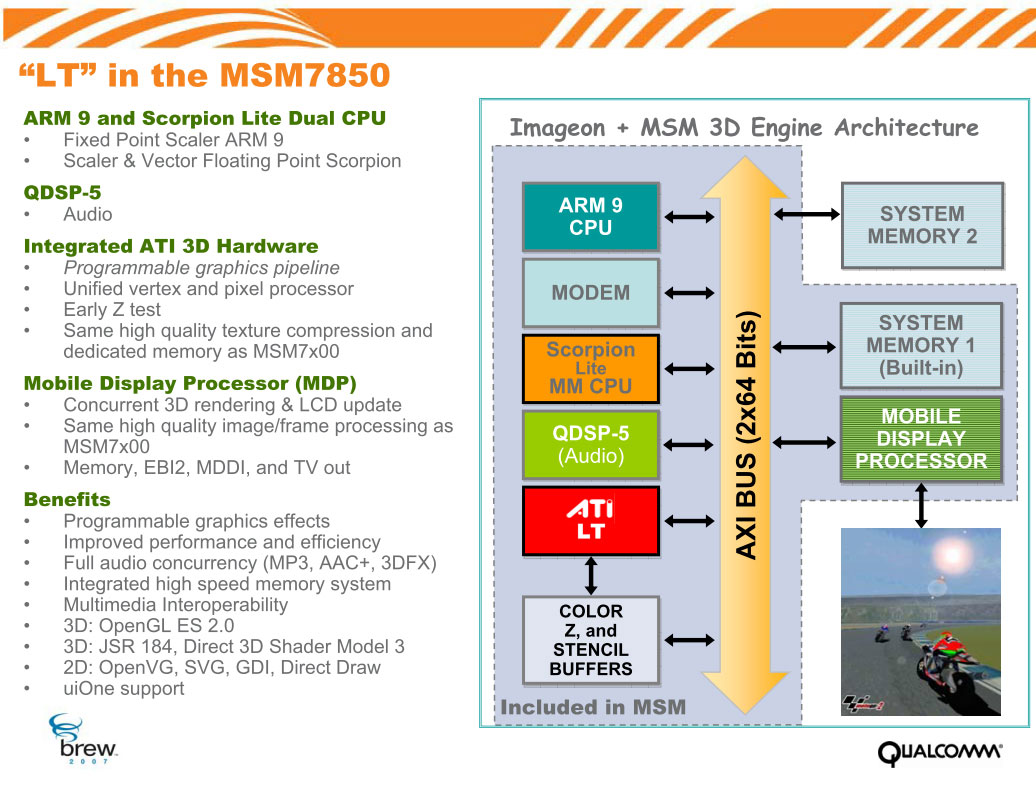
QualComm MSM7850,基于两个ARM处理器(一个ARM9和一个Scorpion Lit MM)集成ATI LT GPU(支持Unifined Shader)
关于Marvell PXA310处理器和MSM7200A处理器的对比,可以参阅笔者参与的小文章:
ARM(Advanced RISC Machines),既可以认为是一个公司的名字,也可以认为是对一类微处理器的通称,还可以认为是一种技术的名字。
1991年ARM公司成立于英国剑桥,主要出售芯片设计技术的授权。目前,采用ARM技术知识产权(IP)核的微处理器,即我们通常所说的ARM微处理器,已遍及工业控制、消费类电子产品、通信系统、网络系统、无线系统等各类产品市场,基于ARM技术的微处理器应用约占据了32位RISC微处理器75%以上的市场份额,ARM技术正在逐步渗入到我们生活的各个方面。
ARM公司是专门从事基于RISC技术芯片设计开发的公司,作为知识产权供应商,本身不直接从事芯片生产,靠转让设计许可由合作公司生产各具特色的芯片,世界各大半导体生产商从ARM公司购买其设计的ARM微处理器核,根据各自不同的应用领域,加入适当的外围电路,从而形成自己的ARM微处理器芯片进入市场。目前,全世界有几十家大的半导体公司都使用ARM公司的授权,因此既使得ARM技术获得更多的第三方工具、制造、软件的支持,又使整个系统成本降低,使产品更容易进入市场被消费者所接受,更具有竞争力。
在五月份,欧盟决定对英特尔处以14亿美元的罚款,从表面上上看,处罚的原因是很充分的:英特尔滥用了它在计算机处理器领域的垄断市场地位。据欧盟表示,英特尔通过各种威逼利诱的手段迫使电脑厂商使用它的芯片而不能使用竞争对手AMD的芯片。至少欧洲方面5月份的报道是这么说的。然而在6月4日Intel宣布它将收购操作系统软件厂商WindRiver风河的消息后,欧盟与英特尔之间的问题变得复杂了。
WindRiver是一个操作系统厂商,其产品是VxWorks操作系统,被广泛应用在各种嵌入式系统上(比较著名的是NASA的航天器),主要支持如ARM、MIPS这样的RISC处理器,欧盟的罚款与WindRiver/Intel有关系吗?
对于已经在PC处理器市场形成事实垄断地位的Intel来说,市场再难以开拓,要想继续扩大,就需要寻找其他市场。服务器市场上Intel确实还没达到垄断的位置,因此近年Intel着重在Nehalem处理器架构上,就是为了增强其在服务器市场上的应用。当然,除了继续已有的市场,开拓一个新市场显然也是一个方案:近几年来手机产品的销量不断上升,已经突破了10亿部。上网本电脑也出乎意料地大受消费者欢迎,很可能会取代笔记本电脑。
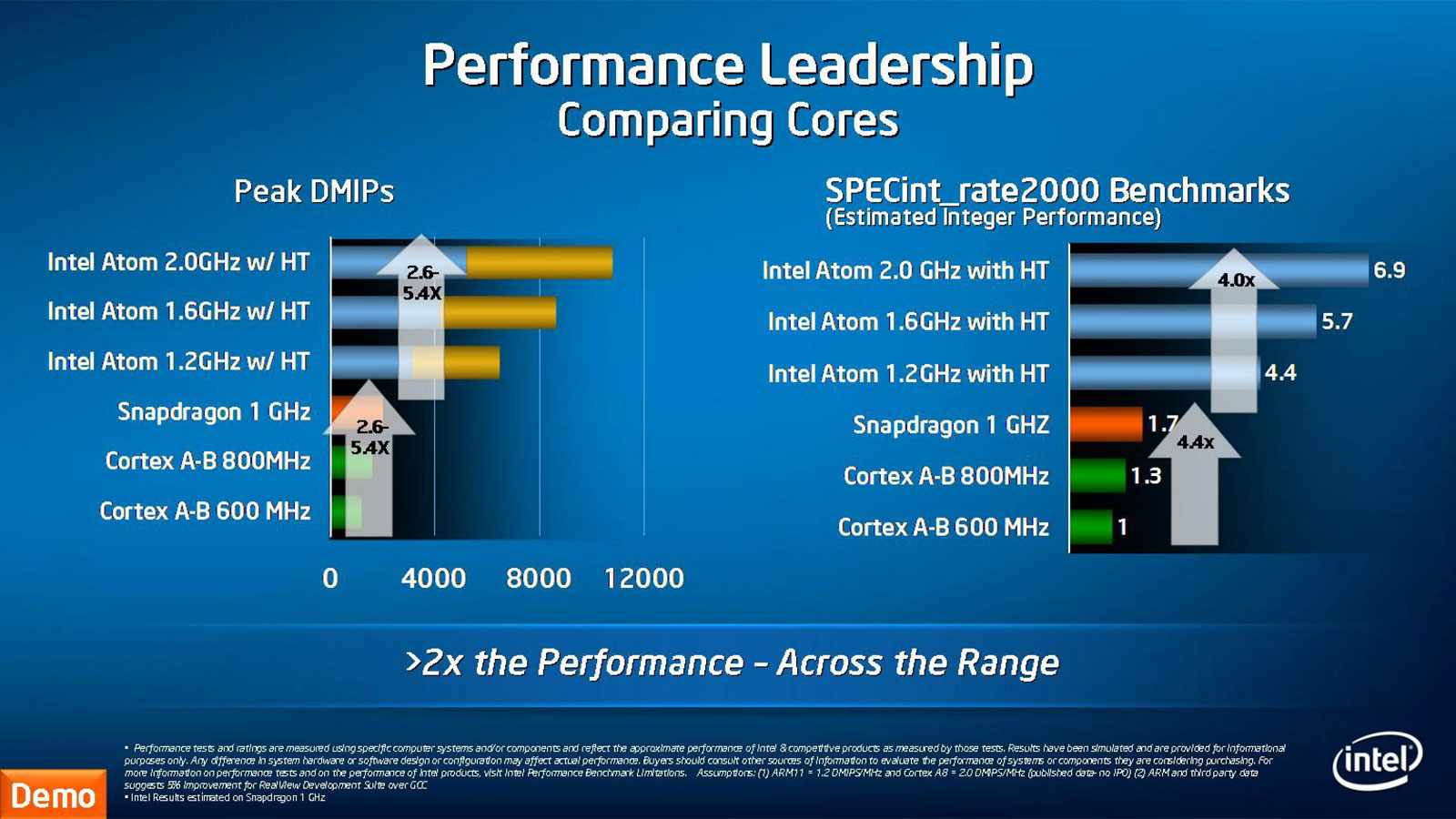
Intel肯定也注意到了这些市场——甚至可以说是很早之前就已经有了主意。因为在这些市场上,如Core/Nehalem这样的处理器都无法胜任,特别是手机市场,除非是使用UUULV级别的Core 2处理器(当然,现在还没有)。因此Intel在NetBurst晚期重新开发一个低功耗的处理器架构——也就是Atom处理器不说是高瞻远瞩至少也是目光犀利。

IA的优势:Runs ONLY on IA and Runs BETTER on IA
显然,当前引领手机处理器市场的厂商:英国剑桥的ARM肯定不会乐见这种情况,虽然在这片市场领域Intel仍然是一个新手,然而Atom具有两个传统、可怕的优势武器:生产工艺和X86兼容性。在生产这一块,Intel公司已经持续保持领先很多年了。而对x86的兼容性更是Atom的杀手锏——x86上具有无数的应用。苹果肯定对自家的iPhone开发感到不满意,因为iPhone应该说是苹果公司旗下唯一一款非X86架构产品,所以其应用软件不得不需要一个另外的团队来进行开发、测试、维护。因此苹果很可能会应用32nm的Medfield Atom。
欧盟死盯着Intel的目的是什么呢?这个可能无法搞清楚,不过,欧盟是否愿意为了大洋彼岸的另一家美国公司而在发展近乎停顿的桌面处理器市场上去找Intel的麻烦?还是欧盟是想让Intel远离欧洲蒸蒸日上的嵌入式处理器市场?
在从IDF2009看服务器处理器市场风云变幻中我们可以看到软件生态环境的重要性,在桌面市场上,Windows无疑是最大的赢家,然而包括嵌入式市场的话,那么Linux可能是份额最大的操作系统。如果想进入嵌入式市场,那么Intel就不能再依赖或者仅仅依赖Microsoft。
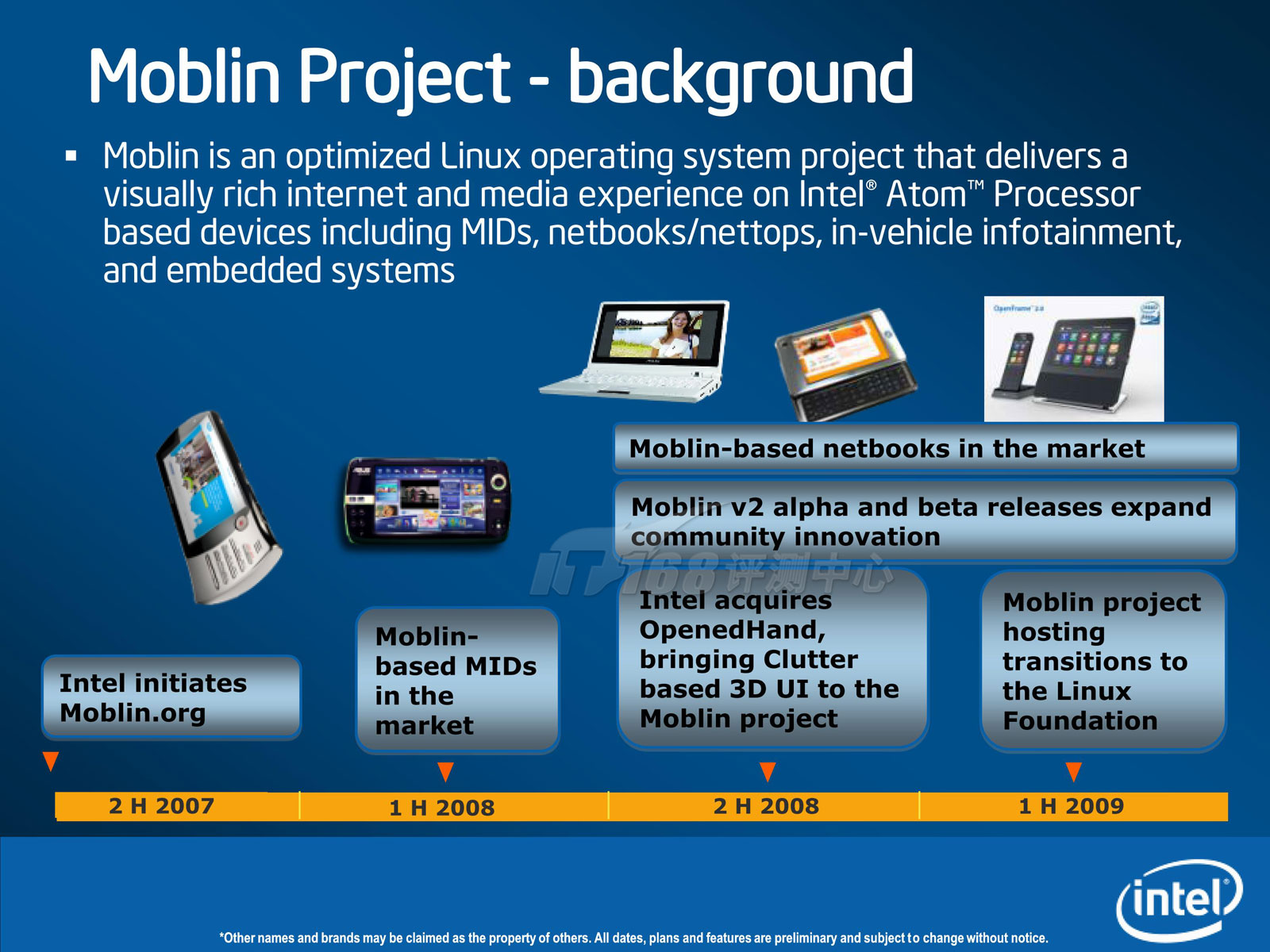
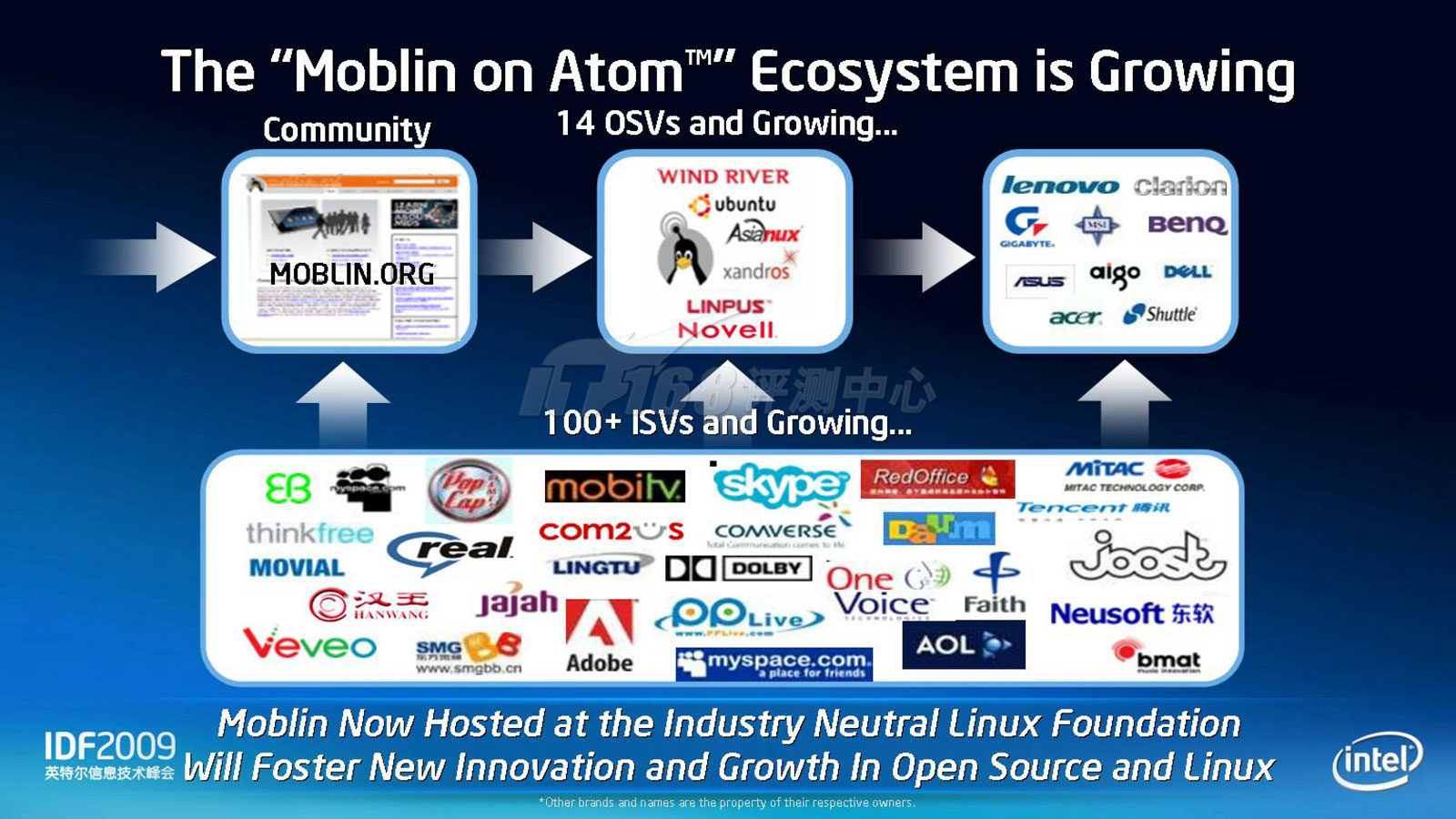


Moblin 2.0已经推出
不过,Wind River的VxWorks操作系统和Linux却有些不搭边:虽然它们都是一个单内核架构(或巨内核架构),不过,Linux是一个多进程的操作系统,而VxWorks则是一个单进程的操作系统(所有的模块都运行于同一进程空间);Linux架构先天上不适合实时(Real Time)操作,VxWorks则是一个实时操作系统。如生命维持装置、交通控制器这样的系统肯定不会希望在紧急情况下系统无法实时响应。尽管有着RTLinux这样的项目,不过也只是能在某种程度上弥补Linux的缺点。
Wind River:风河
因此,收购风河,Intel的目标可能有两点:扼住其他嵌入式处理器的喉咙(VxWorks以后肯定会向x86系统倾斜;也许是这一点激怒了欧盟?),或者开发自己的实时操作系统,对于实时操作系统来说,Linux只能是权宜之计,而单进程的VxWorks维护繁琐也不适合。未来应该是微内核操作系统的世界。
当然现在谈论Intel未来的实时微内核操作系统为时尚早,Intel今后将会以开源Linux产品作为重心,从多个方面对移动市场进行渗透。在移动市场,除了Intel自家的Moblin操作系统外,还有风河一直在研究的车载市场和Google目前大力推动Android操作系统。另外还有更偏向于手机操作系统的,和诺基亚合作的开源oFono项目。
基于ARM架构的Intel XScale数年前已经售出,Intel从此专注于培养自家的Atom
可以看出,Intel在移动市场早已经布下多个强力产品,从软件要硬件都有,和Wintel联盟所不同是,这次Intel开始自己主导软件部分的设计,或者和Google、诺基亚这样的行业巨头进行合作,而且其重点都是开源产品,这对于微软来说不是一个好消息。Intel也没有选择去重新设计一款ARM架构的产品,而是利用现有技术对产品线进行整合,我们可以看到,今后移动终端市场和传统的PC市场界限将会越来越小。
【IT168评测中心】在通用处理器市场包括了通常的桌面/服务器市场、嵌入式市场,Intel凭借着Core/Nehalem/Atom已经占据了或者进入了这些市场(有基于Atom服务器),除此之外,还有一个市场就是通信处理器市场,Intel曾经凭借x86/IXP杀入这个市场,然而在这个更注重系统性——SoC设计的地方,Intel曾黯然退出,然而随着Atom架构和其SoC的出现,Intel可能会再次进入这个市场。
Medfield SoC
Intel Atom Processor Logo
曾经说过:商业市场上以成败论英雄,Intel凭着持之以恒的维持着世界顶尖的工艺制程和产能,并在技术发展上采用了非常独特的线路,才达到了今天的成就。在中国有句古话叫作:“上兵伐谋”,Intel再次展示了如何借着敏锐触觉而重新开发的Atom处理器架构、凭着非常先进的生产工艺和x86指令集的强大兼容性发展壮大,以及收购Wind River、开发Moblin这样的釜底抽薪远交近攻的策略的行事方法。Atom处理器能像现实的原子那样无处不在,或者说Intel能达成x86 Everywhere这个目标吗?还要看未来分晓。
一个CH4甲烷分子:
molecule:分子;H:氢;C:碳
atom:原子;electron:电子;nucleus:原子核
neutrons:中子;proton、protons:质子
quark:夸克;pion:π介子
两个上夸克和一个下夸克通过π0介子传递的表观强相互作用力形成了质子(介子由一个下夸克和一个反下夸克组成);介子由夸克通过gluon胶子传递的强相互作用力“胶结”而成
基本物质粒子称为费米子,之间传递力的粒子称为玻色子
到目前为止,人类成功地用包括6个夸克和6个轻子作为费米子——最基本的物质粒子并从理论上解释了可见能量范围内的世界组成,6个夸克分别是:up quark(u,上夸克)、down quark(d,下夸克)、charm quark(c,桀夸克)、strange quark(s,奇异夸克)、top quark(t,顶夸克)、bottom quark(b,底夸克),6个轻子分别是:electron(e,电子)、muon(μ,μ子)、tauon(τ,τ子)、electron-neutrino(νe,电子中微子)、muon-neutrino(νμ,μ子中微子)、tau-neutrino(ντ,τ子中微子),然后每一个粒子都具有各自的反粒子。这些粒子分成三个族:(e-νe)、(μ-νμ)、(τ-ντ)以及(u-d)、(c-s)、(t-b),前面三个分别称为电子家族、μ子家族和τ子家族,每一个家族都是前一个家族的增重版本而其他特征一致。三个夸克家族也是类似。为什么具有三个族甚至是不是只有三个族仍然是一个迷,被称作“族问题”。
2008年诺贝尔物理奖的一半赋予了美籍日裔物理学家南部阳一郎 (Yoichiro Nambu) 由于“发现了亚原子物理中的对称性自发破缺机制”("for the discovery of the mechanism of spontaneous broken symmetry in subatomic physics") ,一半赋予日本物理学家小林诚 (Makoto Kobayashi) 和益川敏英 (Toshihide Maskawa) 以表彰他们“发现了预言自然界中至少存在三代夸克的破缺对称性的起源”("for the discovery of the origin of the broken symmetry which predicts the existence of at least three families of quarks in nature")。有了对称性自发破缺的杨振宁-米尔斯非阿贝尔规范理论,各种夸克、轻子才具有现在这样的各种参数(质量、相互作用),才有了延续至今的宇宙万物和五彩缤纷的世界。而小林诚和益川敏英提出的基于SU(2)群的三夸克家族模型则解释了三个夸克家族的问题,这个模型同时还给出了可用于区分物质与反物质的CP对称性破坏的解释。
当然,目前基于对称型自发破缺的规范理论(或者叫标准理论)仍然不够完美,或许M-理论(或者叫超弦)能够完成。

