- 全球领先!中科曙光新一代全闪存率先突破2亿IOPS
5月13日,中科曙光正式发布FlashNexus 9000高端全闪存存储。这是继去年FlashNexus 8000以双控阵列登顶SPC-1全球第 一后,曙光再次完成的关键迭代。
陶然 · 2026-05-13 21:05 - AI手工测试用例的实践进阶之路
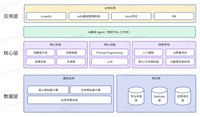
这篇文章分享一条真实的落地路径:我们不是直接追求“AI 一键生成完美用例”,而是先用 MVP 验证方向,再用 1.0 补齐输入解析、Prompt 工程化、知识工程和检索闭环,最后把能力沉淀到测试智能体并skill化赋能“小龙虾”。文末会给出可直接复用的实践方法与避坑点。 -- AI用例生成项目组
陶然 · 2026-05-12 09:55 - 心怀挚爱,共绽光芒——鲲鹏昇腾开发者大会2026即将启幕
当前AI以前所未有的速度蓬勃发展,模型迭代以周为单位,应用场景持续拓展,迈向Agentic AI智能体时代。在这一浪潮下,面向开发者一年一度的技术盛典——鲲鹏昇腾开发者大会 2026(KADC2026)将于5月22日-23日,在北京中关村国际创新中心举办,帮助开发者学习和使用鲲鹏、昇腾软硬件技术、平台和工具,高效自主开发和AI创新。
陶然 · 2026-05-07 16:32 - 万智互联,跃升行业智能化 | 华为全景亮相数字中国建设峰会
在第九届数字中国建设峰会期间,华为以“万智互联,跃升行业智能化”为主题参展,以四大主题论坛、九场行业分论坛、两大核心展区为载体,全面展示了华为在根技术突破与数智基础设施夯实方面的持续努力。秉持“软件开源、硬件开放”的理念,华为携手合作伙伴共建繁荣数智生态,推动前沿技术与千行百业深度融合,全方位助力数字中国各领域的建设与发展。
陶然 · 2026-04-30 16:21 - 加速城市数智创新,AI赋能高质量发展——数字中国AI CITY分论坛成功举办
4月28日晚,第九届数字中国建设峰会前夜,由华为主办的数字中国AI CITY分论坛成功举办,论坛以“加速城市数智创新,AI赋能高质量发展”为主题。活动期间,隆重发布广州人工智能融合赋能中心样板点、武汉全球城市治理数字化转型样板点等系列成果。
陶然 · 2026-04-29 21:37 - 开源鸿蒙亮相数字中国峰会丨全域使能推动生态全面提速
日前,第九届数字中国建设峰会召开前夕,鸿蒙生态峰会在福州海峡国际会展中心成功举办。峰会聚焦OpenHarmony生态建设与落地实践,来自政府机构、开放原子开源基金会及产业链上下游企业代表齐聚一堂,围绕芯片、模组、设备、行业应用等关键环节,共同探讨OpenHarmony在万物智联时代如何加速在千行百业的产业化落地和规模化应用。
陶然 · 2026-04-29 13:46 - 至强x锐炫新品发布:为AI工作站平台做加法,让专业创作从容表达
今日,英特尔公司在北京举办新一代AI工作站平台发布会,推出英特尔至强600工作站处理器与英特尔锐炫Pro B70、B65 GPU。双芯的强强联合,将为AI开发者与企业打造覆盖从日常应用和专业重负载AI应用、且颇具成本效益的高效工作平台。
陶然 · 2026-04-23 22:23 - 生成式召回在得物的落地技术分享与思考
推荐系统在提升用户体验的同时,也面临着信息茧房、兴趣收敛和内容同质化的挑战。随着用户与系统交互的深入,"推荐→用户反馈→再推荐"的闭环会逐渐强化用户的少数主兴趣,导致推荐结果趋同,降低用户的新鲜感与满意度。
陶然 · 2026-04-23 09:27 - AI翻译:出海企业如何跨越“语言鸿沟”?
目前地球上正式的语言超过了1100种,但大部分人通常只能掌握 2-3种。一旦涉及到我们不会的语言,就需要借助工具或他人来翻译。你是否好奇过,现在AI热度那么高,它能掌握其中多少语言呢?如果借助AI工具,翻译工作又是否可以完美完成?
陶然 · 2026-04-17 14:07 - 智汇天府・数智赋能|华为坤灵中国行 2026・四川站圆满举办
天府之国春意盎然,智能化转型浪潮澎湃。面向中小企业智能化转型的迫切需求,以“华为坤灵,助力中小企业跃升智能化”为主题的华为坤灵中国行 2026・四川站,于 4 月 15 日在成都圆满举办。
陶然 · 2026-04-16 18:33 - 国内最大规模6万卡AI4S计算集群投入使用
4月14日,中科曙光提供的6万卡科学智能(AI for Science)计算集群系统,在位于郑州的国家超算互联网核心节点投入使用。作为国内最大的AI4S计算集群,其以超智融合全栈技术能力,满足用户从集群性能、软件模型优化、科研应用效率到科学智能体开发的多维需求,为“人工智能+科学技术”在国内的规模化落地提供保障。
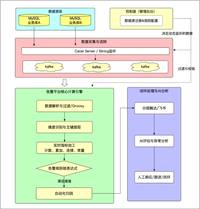
陶然 · 2026-04-14 16:14 - 数据质量告警平台的建设与应用实践
告警平台通过监听业务数据库的 Binlog(基于 Canal 采集),将数据变化转化为实时流式指标,实现了对业务逻辑的非侵入式监控。AI 决策中枢,把传统告警系统从“发现问题”升级为“理解问题、判断风险、指导止损”。
陶然 · 2026-04-13 17:10 - 全球首发!南方医院联合华为及多家医疗机构发布医院通用人工智能平台(HAIP)
今日,以“数智融合·赋能医疗”为主题的“AI驱动智慧医院建设新范式高峰论坛”在广州举行。会上,南方医院联合华为及行业伙伴首次面向全球发布医院通用人工智能平台(Hospital AI Platform,以下简称“HAIP”)、《医院通用人工智能平台技术白皮书》,并为医疗AI全场景智慧医院联合创新实验室揭牌,引领智慧医疗新范式。
陶然 · 2026-04-10 22:57 - 曙光数创发布全球首个MW级基础设施整体解决方案
曙光数创在“液冷聚能·智算向新”2026战略发布会上,正式发布全球首个MW级相变浸没液冷整机柜及其基础设施整体解决方案(C8000 V3.0)。
陶然 · 2026-04-08 23:42 - 超节点迈入普及阶段:中科曙光发布革新性超节点
中科曙光3月26日在中关村论坛现场发布了世界首个无线缆箱式超节点scaleX40,并同步开启全渠道预售。这款产品的意义,并不只在于性能提升,而在于它试图回答一个关键问题——如何让超节点从“少数人的能力”,变成“多数人的标配”。
陶然 · 2026-03-26 15:36 - Arm AGI CPU重磅发布:构筑代理式AI云时代的芯片基石
Arm 今日正式发布 Arm AGI CPU,该产品是基于 Arm Neoverse 平台打造的全新量产级芯片,旨在为下一代人工智能 (AI) 基础设施提供核心算力支撑。
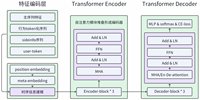
陶然 · 2026-03-25 10:26 - OpenClaw处理流程链路解析
OpenClaw作为一款开源的AI智能体(Autonomous Agent)框架,自2026年1月开源以来迅速成为AI领域的现象级产品。它的核心价值在于将大语言模型的推理能力与本地系统操作深度结合,实现了从"对话式AI"到"行动式AI"的跨越。本文将深入解析OpenClaw的处理流程链路,揭示其背后的技术架构和工作原理。
陶然 · 2026-03-23 17:22 - 华为云发布FlexNPU,打造弹性伸缩的“算力金箍棒”
华为云中小企业AI解决方案发布会上推出了一项算力黑科技——柔性智算操作系统FlexNPU,将Token消耗“吞金兽”有效控制在企业预算范围内,打造面向Agentic时代的极致Token性价比,为企业级智能体的普及突破算力瓶颈。
陶然 · 2026-03-21 20:26 - “伙伴+华为”:共筑AI时代数智新基建,跃升AI新价值
今日,以“因聚而升 融智有为”为主题的华为中国合作伙伴大会2026在深圳继续举行。继大会首日系统阐述了战略创新、体系升级、政策变化后,今日华为进一步解读了如何以“伙伴+华为”体系为核心,与伙伴共筑AI时代数智新基建,抓住AI时代机遇,跃升“行业+AI”价值。
陶然 · 2026-03-21 20:15 - 因聚而升 融智有为:华为中国合作伙伴大会2026成功启幕
今日,华为中国合作伙伴大会2026在深圳隆重举行。大会以“因聚而升 融智有为”为主题,旨在通过“伙伴+华为”在战略、能力、价值的全面融合、协同共进,实现高质量服务客户数智化升级,共创千行百业数智化的价值跃升。
陶然 · 2026-03-19 20:22