AI翻译:出海企业如何跨越“语言鸿沟”?
背景
目前地球上正式的语言超过了1100种,但大部分人通常只能掌握 2-3种。一旦涉及到我们不会的语言,就需要借助工具或他人来翻译。你是否好奇过,现在AI热度那么高,它能掌握其中多少语言呢?如果借助AI工具,翻译工作又是否可以完美完成?

事实上,不同AI之间的差异,比不同人之间还要大得多。
传统的像DeepL这样的神经网络翻译技术,极限情况下也只能理解/输出30+的语言(仍远远超过人类能力),而主流的LLM,通常都已经能熟练使用50+种以上的语言能力。更有甚者,像Meta MMS 这样的“多语言专攻手”,能达到惊人的1000种以上的语音/文本处理能力,基本覆盖所有语言。
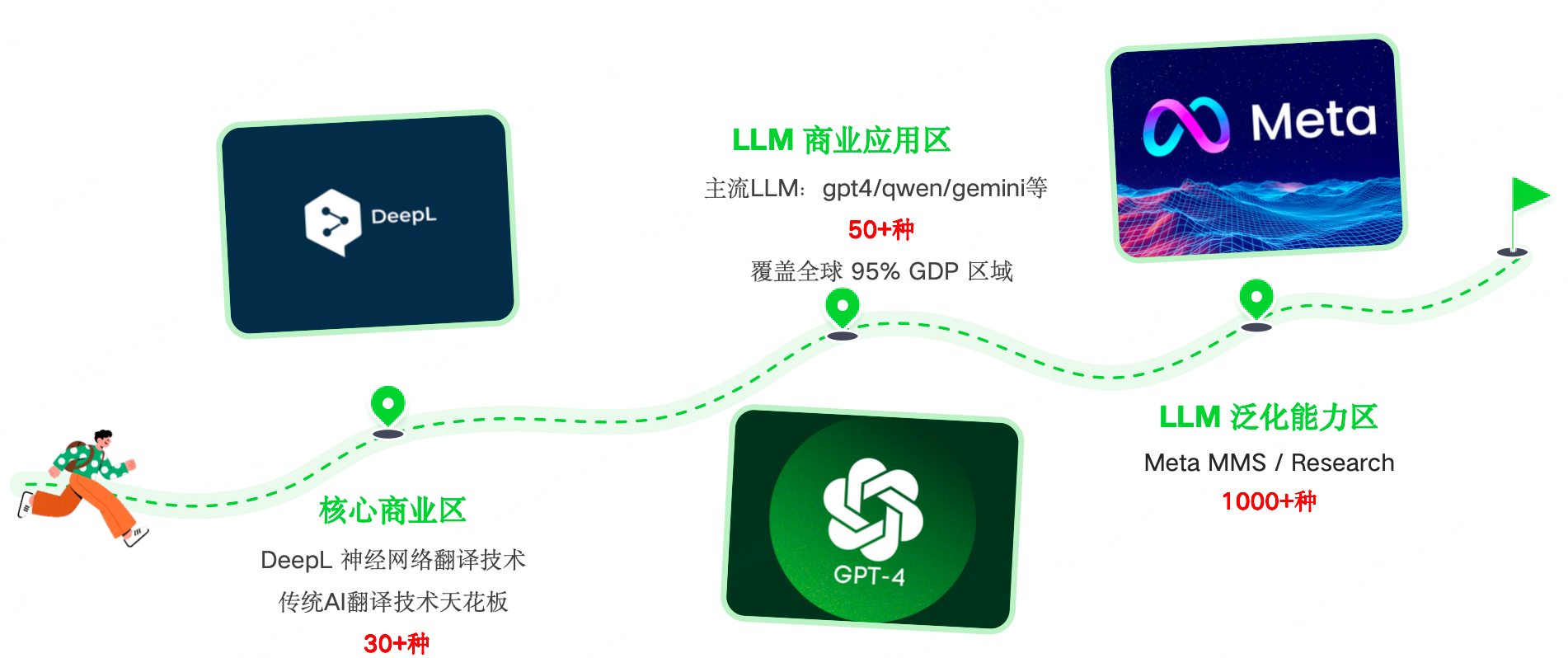
那再看看翻译质量呢?目前来看,如果只是让LLM进行一些句子、词汇的转换,大部分模型都可以做到快速且准确,而一旦需要AI去结合场景进行更精准的翻译,此时由于模型不了解相关背景知识,翻译时往往会比较吃力。
因此,单纯的AI直接翻译,可能离商业应用还有一段距离。
LaLamove的翻译挑战
Lalamove作为一个跨国经营企业,经常需要在开城时对App、官网的内容进行翻译。由于涉及的数据量大(上万条文本,部分为成段的营销文案),且混杂代码、UI文本等内容较难处理,需要一种准确、快速、可复用的支持方案来提升开城效率。我们尝试通过AI介入来缩短翻译耗时,并在保证效果的前提下,减少相应的成本。
海外开城翻译现状
传统上,海外开城的翻译工作是在外部平台找人工翻译。但是每次翻译的时间比较长,且翻译效果也无法保证,还需要local业务人员进行二次核验。同时,由于是人工翻译,还会带来一定的经济成本,这些都是我们想解决的问题。
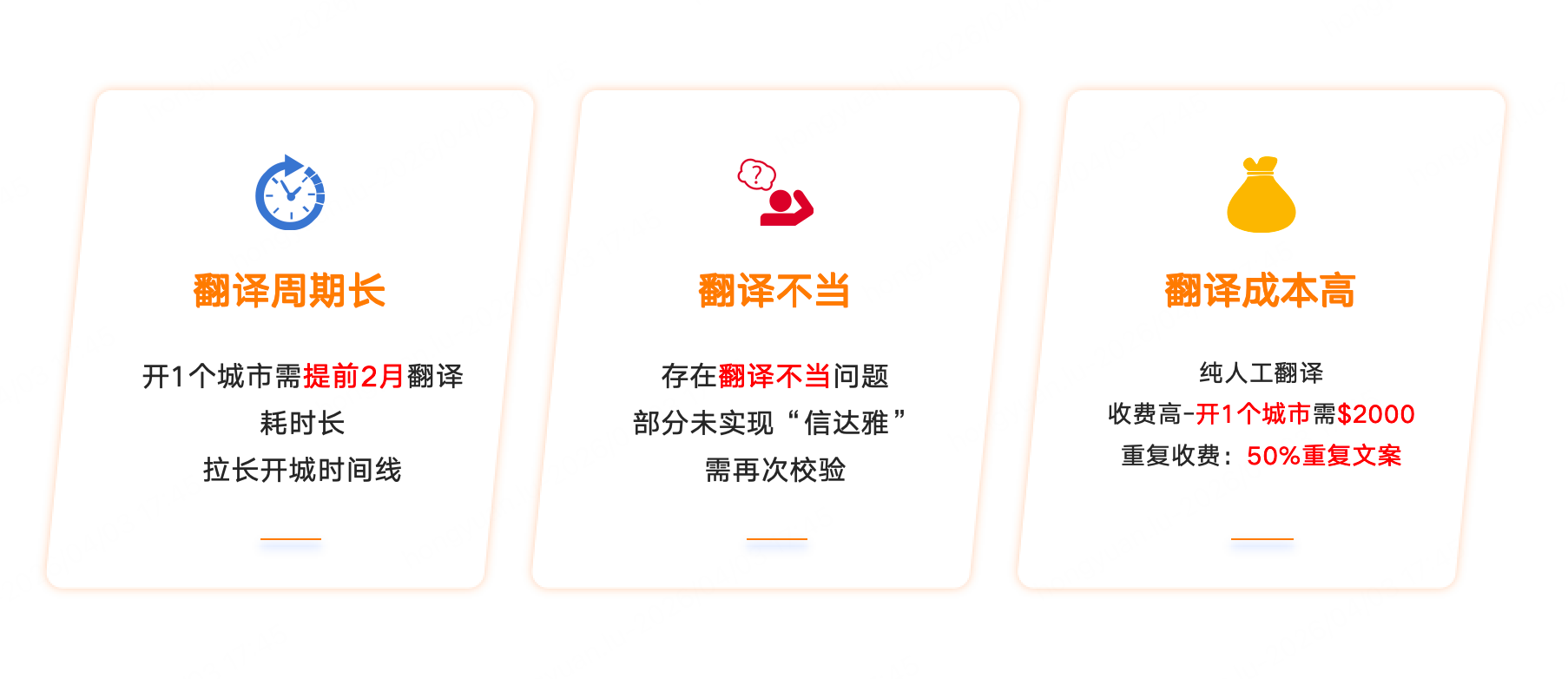
翻译目标
那怎样才能把翻译这件事做好呢?需要做到3个核心点:翻译信达雅、有效的效果评估与安全合规
绕不开的金标准:翻译“信达雅”
“信”就是要准确。UI文案通常极短(如按钮、标签)且缺乏上下文,在一词多义情况下机器无法准确推断词义。
“达”就是要用地道的方式传达给读者。AI翻译容易因为的“翻译腔”,带来沟通的隔阂。
“雅”就是美学的追求。如何让翻译后的文本长度适配界面、让风格前后统一也是一大挑战。
效果评估的矛盾
人工质检总是很昂贵的,且需要大量时间。但如果完全没有质检,质量控制又如同“抽盲盒”。我们需要考虑的是,如何在追求效率的同时,给出客观、标准化的质量评估
安全底线的构筑
LLM的幻觉可能导致它在翻译中凭空捏造信息。在政治、宗教等高度敏感的地带,哪怕是最细微的歧义都可能带来巨大的舆论风险。
面对这些错综复杂的难题,单一的提示词工程显然已经无法满足。我们意识到翻译不应该是一个个孤立的文本处理任务,而应该是一套完整可靠的流程。于是,我们提出了这套多Agent翻译框架。
多agent框架:为什么它更懂“出海”?
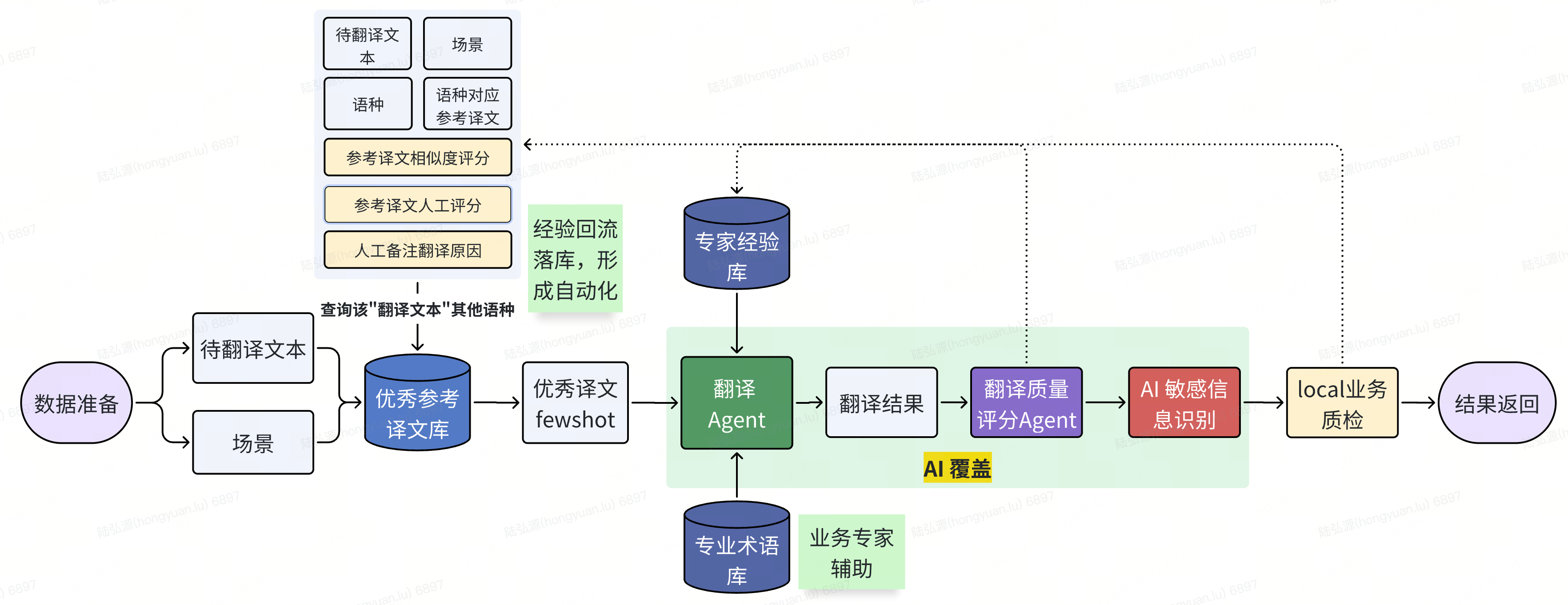
我们开发的这套翻译框架,通过多模块组合来实现从业务使用到后端支持的完整框架。整体上可以分为3层,应用层与业务方、质检方进行交互,中间的核心层依靠悟空平台(货拉拉自研大模型应用平台)桥接后端的各项核心功能,并通过数据层来保存和调用数据。
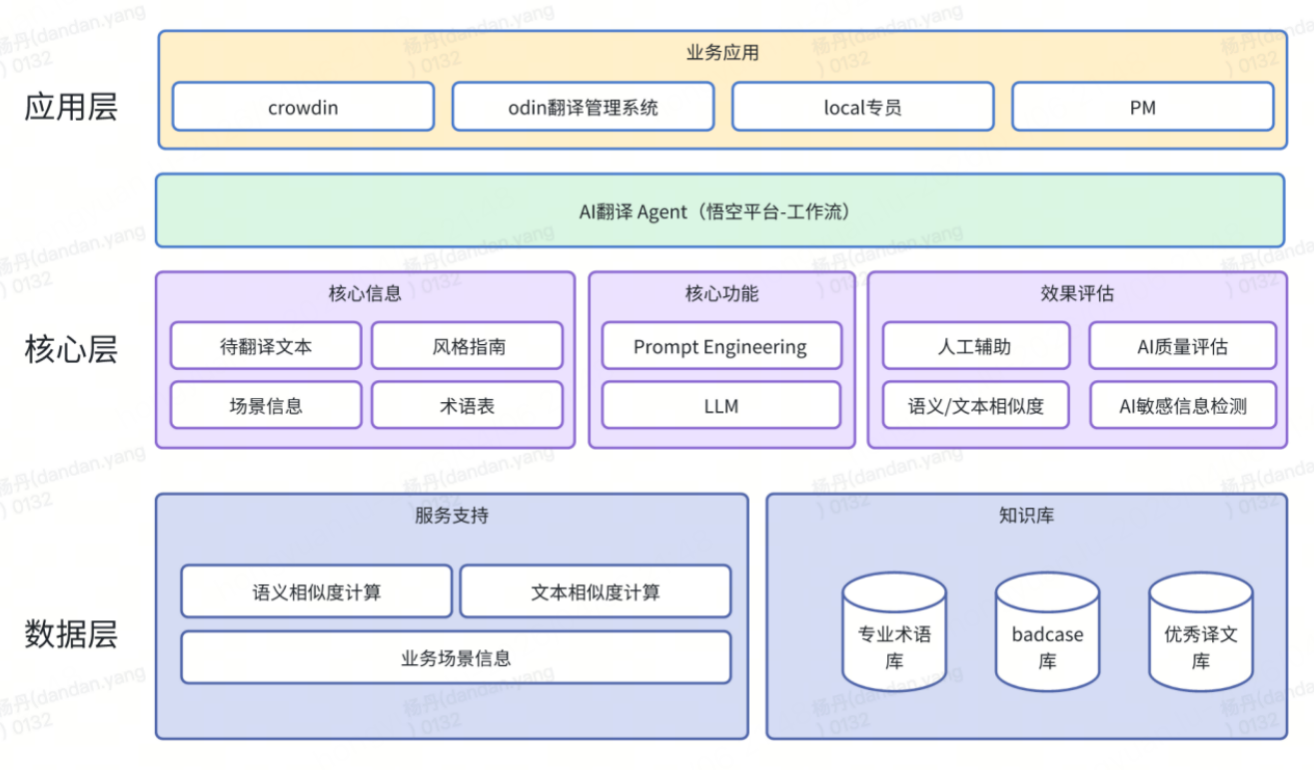
其中,最为核心的是3个Agent:
翻译Agent(资深译员):负责精准的语言转换。
翻译质量评分Agent(专业校对):多维度打分,拦截低质样本,高效避免重大翻译错误。
敏感信息识别Agent(合规审查):扫除政治、宗教及文化禁忌风险。
通过这种分工合作的,我们实现了3大跨越:
快速响应:以LLM为主力,人工仅最低限度进行质检,无需动辄几十天的翻译时间。
表达地道:深度贴合业务场景,拒绝生搬硬套,符合当地用语习惯。
成本骤降:AI 完成 90% 的工作,人工仅需对低分样本进行最终质检,大幅削减人力开支
技术深挖:专业翻译Agent
在翻译Agent中,我们通过「专业术语库」、「优秀参考译文Few-shot」和「上下文注入」这一套组合拳,实现了直追人工的翻译效果。
专业术语库 - 关键信息强约束
针对物流行业“黑话”和专有名词,我们增加了一个轻量知识库来对LLM进行强限定。在翻译时,通过prompt约束模型优先采纳检索出来的标准化翻译,确保特定词汇在所有文本中始终保持一致。
优秀参考译文Few-shot - 让模型“作弊”
每种语言都存在多义词,而这也是翻译时最令人头疼的问题之一。
比如,单词order既可能是命令、指令的意思,也可能是订单的意思。
AI翻译单个词汇时,往往受训练语料影响来选择“最大概率”的词汇,但不一定是最合适的。我们创新性地引入了多语种参照系,通过让Agent参考同语料下其他语种的人工翻译结果(带有权重优先级),以few-shot的方式让模型在语义空间中多维度锁死语义,消除歧义带来的奇葩翻译。
上下文注入 - local业务经验
在 UI 翻译中,缺失上下文是误译的万恶之源。我们的agent放弃了单句输入模式,而是匹配文本使用场景等业务信息来辅助模型推断文字背后的意图,实现情景化翻译。
这样,我们的就从多个维度实现了准确可靠的翻译。

闭环保障:翻译效果评估Agent
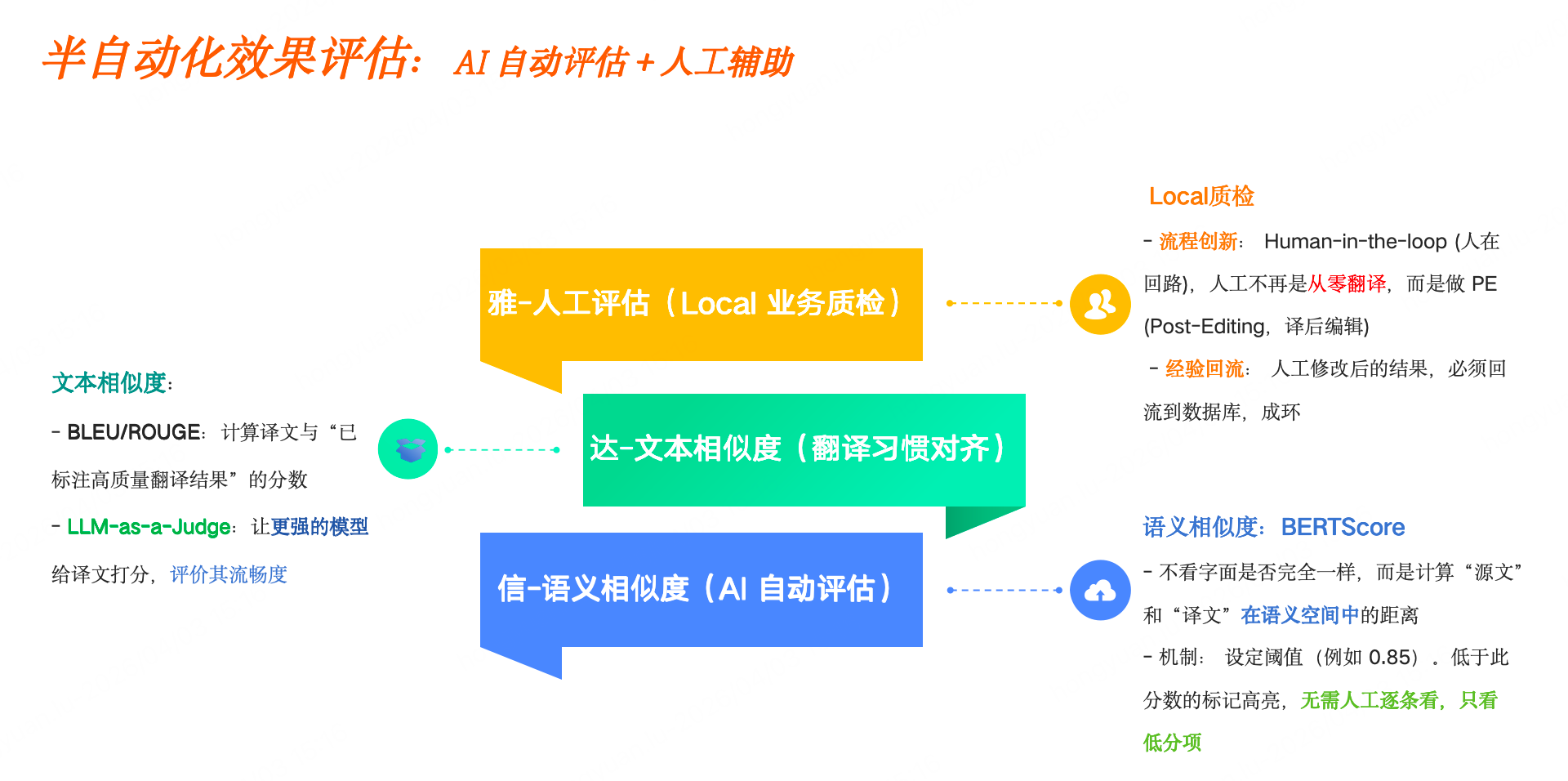
如何评估上述框架的效果呢?这套多agent框架也能进行半自动化的翻译质量评估。评估翻译质量往往比翻译本身更难,我们依靠人机结合,实现了相对较为可靠的快速评估体系。
首先是自动化的指标评估。我们引入了COMET/BERTScore等语义相似度与BLEU等文本相似度的双重打分机制,既看翻译结果在字面上与人工打标的差异,也看与原文在语义空间中的距离,加权综合评估翻译效果。
然后是基于阈值的“低分样本过滤”步骤,系统会根据指标评分自动过滤出需要人工复核的争议样本,把宝贵的人力资源留给机器最难翻译的部分。同时,人工也不再是从零翻译,而是做“译后编辑”,实现了效率与质量的平衡。
风险隔离:敏感信息识别Agent
最后,为了应对敏感信息风险,我们在翻译流程之外独立配置了一个敏感信息识别Agent ,针对不同地区的特定敏感点(如宗教习惯、社会热点)进行二次安全审查。主要包含两个维度:
通用安全扫描: 自动拦截涉及暴力、色情、仇恨言论等全球公认的低俗信息
特定地区合规: 针对目标市场的政治倾向、宗教禁忌、民族政策进行专项对齐。
同样地,所有被安全 Agent 标记为风险的样本,必须经过local业务的复核,确保万无一失。
如此一来,这套框架不仅翻译了文字,也隔绝风险,确保我们的品牌在全球市场稳健前行。

总结
通过翻译、评估、安全三位一体的 Agent 协同,我们在保证安全的前提下成功利用AI砍掉了 90%的成本,并将响应时间从数月缩短到了几天。更重要的是,我们获得了一套垂直场景LLM落地框架,未来可将其应用于各自业务场景。

