Apache Gravitino 在B站的优秀实践
导读
在传统的大数据元数据管理系统中,以 HiveMetaStore 为核心的架构存在诸多问题和挑战。随着数据湖大规模应用、AI 数据大量增长、数据安全与数据治理被更加被重视,我们难以基于原有的架构或组件实现一套统一的元数据管理系统,进而解决数据孤岛、统一权限,多维度数据治理等问题。因此,在 B 站 我们引入了 Gravitino,本次分享将介绍 Gravitino 在 b 站的优秀实践。其中包括了统一了多种数据源的元数据视图,统一跨数据源任务的 schema 信息,并且基于其中的 Fileset 概念对非结构化数据进行管理与数据治理,取得了可观的收益。
01 元数据管理痛点剖析
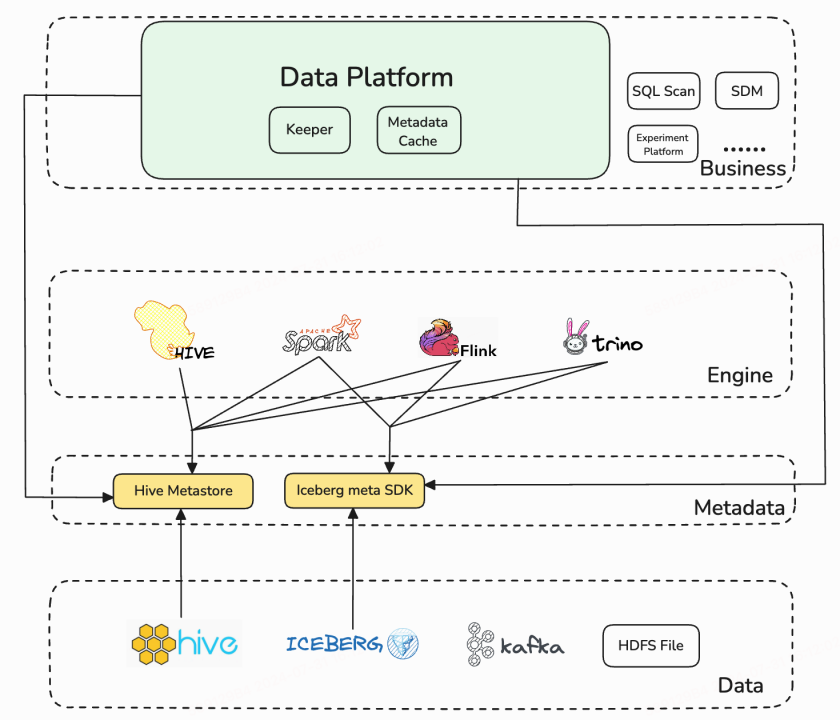
上图是我们在引入 Gravitino 之前的数据系统架构图。我们的元数据最大的使用方为数据平台,也包括了其它一些数据服务,如 SQL Scan,用于对 SQL 进行预检查,以及 SDM 数据智能编排服务等。除此之外,其它一些引擎也需要获取、增加、删除和查询元数据信息。
从图中可以看出,这一架构存在诸多问题:
业务侧耦合度过高:元数据的使用方调用异构数据源的方式多种多样。
数据治理能力有限:没有提供中心化的元数据管理服务,因此无法提供统一的审计、权限管理和调度能力。
对于半结构化和非结构化数据缺乏有效的管理,例如Kafka的schema和HDFS的文件等,还没有进行系统的管理。
跨源数据schema的维护成本较高。
02 Apache Gravitino 背景概览
1.元数据管理中心化
基于以上痛点,我们想引入一个中心化的元数据管理组件。需要实现以下几点,以达到理想的效果:
① 解耦元数据的使用方和各种组件,以降低元数据的使用成本。
② 跨源数据统一维护 Schema,降低跨源数据使用成本。
③ 提供统一的审计、TTL特性,HDFS EC 通过数据治理实现降本。
④ 集中管理和治理AI的数据资产。
⑤ 建立统一的权限管控机制,提高数据安全性。
2.元数据管理组件对比
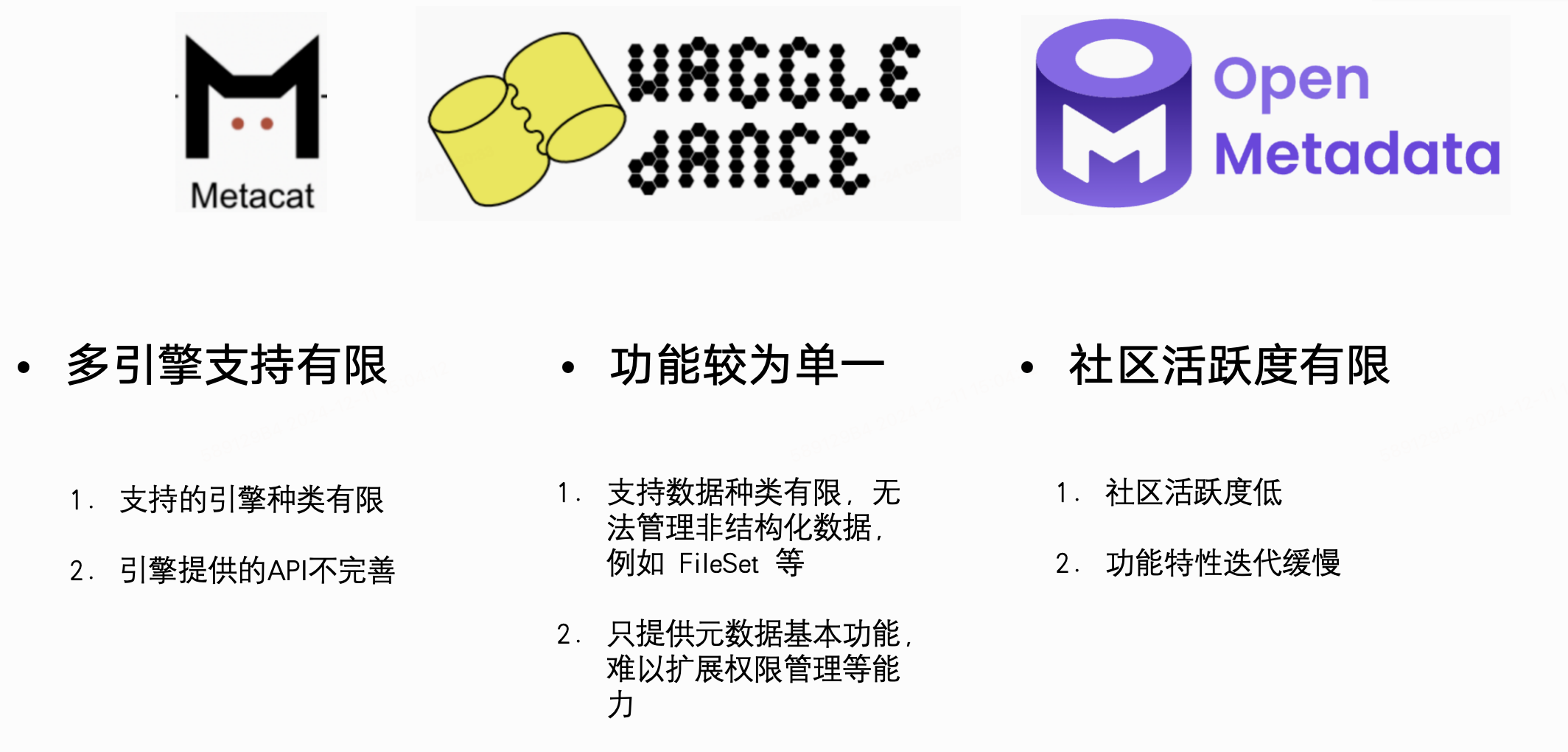
我们调研了主流的开源元数据管理组件,包括 Metacat、WaggleDance 和 Open Metadata。这些组件存在以下缺点:它们对多引擎的支持有限,功能相对单一,仅提供了基本的元数据功能,难以扩展,社区活跃度有限,可能没有大版本更新和迭代计划。
3.What is Gravitino?
基于以上调研,我们发现了 Apache Gravitino。它是一个高性能的元数据管理平台,可以处理不同类型的元数据和来自不同来源的数据信息。此外,它还提供 AI 数据资产管理能力。以下是 Gravitino 的整体架构图,它满足了我们对统一元数据的期望。

第一层是数据应用层,包括数据平台、B 站等数据应用组件以及引擎,都通过这一层接入。
第二层是接口层,目前 Gravitino 提供了 REST 统一接口,对外提供元数据的访问能力,并且还提供了 Thrift 和 JDBC 接口,供引擎进行具体接入。
第三层是 Gravitino 的核心组件,其数据分类基于 Catalog 进行管理。不同数据源具有不同的 Catalog。整个层级架构基于 MetalLake Catalog Schema 和 Table 的概念。Schema 是我们通常理解中的数据库概念。对于 FileSet,文件管理也基于 Catalog。例如,Hive 是一个 HiveCatalog。Fileset 代表一个独立的文件系统的目录, 也可以理解为一个文件集,则对应 FilesetCatalog
最底层是连接层,它连接了不同的数据源。例如,对于 Hive 表,其背后是 Hive MetaStore;对于 Iceberg 表,则是提供的统一 REST Catalog。此外,Gravitino 内部还维护了一套自己的存储系统。不过,需要注意的是,Gravitino 本身并不存储元数据,这部分主要用于维护 Gravitino 内部的一些数据,如 Catalog 和 Meter Lake 等信息。
Gravitino 能够做到以下五点:
能够为多种数据源提供统一的元数据视图;
能够支持统一的元数据管理等特性;
支持多种数据源,包括半结构化和非结构化数据源,如 HDFS 文件、AI 文件和 Kafka schema;
能够支持多种计算引擎,目前支持的引擎包括 Trino,Spark 和 Flink;
开源社区的活跃度非常高。
虽然它还处于项目早期阶段,但我们提到的很多问题都能得到社区的积极回应,而且越来越多的开发者加入了 Gravitino 的开发。
4.Gravitino FileSet

FileSet 是一个包含多个 HDFS 文件的目录和集合,可以理解为一个文件集。用户使用 FileSet 来管理非表格数据,特别是在生产环境中,主要是 HDFS 文件。FileSet 映射到文件系统上的具体目录,从右图中可以看出,它遵循了 Gravitino 的标准架构,包括 MetaLake、Catalog、Schema 和具体 FileSet。每个 FileSet 都有具体的 HDFS 存储路径,还包括其他维护的 FileSet 元数据信息,如大小、文件数量、创建时间等。
Gravitino 管理的 FileSet 将非表数据结构和表结构数据以统一的资产方式进行管理。用户可以通过 FileSet 轻松访问文件和目录,无需通过实际物理路径访问数据文件集。
03 Apache Gravitino 生产实践
接下来,我们将介绍在B站上引入Apache Gravitino的具体生产实践及其带来的收益。
1.OneMeta:统一的元数据管理服务
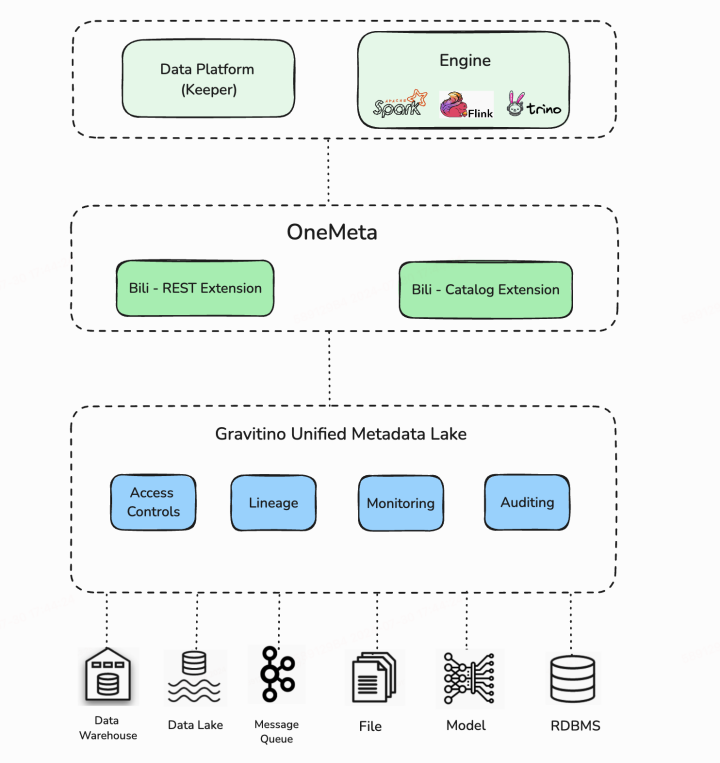
首先,我们基于 Gravitino 搭建了内部组件 OneMeta。它对外提供了统一的元数据管理服务,底层仍然基于 Gravitino 实现。在之后的部分谈到 OneMeta 时,可以理解为与 Gravitino 等价。我们在 Gravitino 的 REST 和 REST 层接口上进行了扩展,并满足了用户的定制化需求。
第二,我们对 catalog 进行扩展,包括定制化接口和下钻功能。实现了社区尚未提供的接口,例如根据用户的筛选条件筛选分区并加载文件及其具体元数据信息。此外,我们还支持批量查询等接口。虽然社区目前只支持管理到 FileSet 这一层级,但我们在此层级上做了下钻,支持浏览 fileset 所代表的文件系统目录下的相关文件信息
第三,OneMeta 针对B站特有的接口改造和 Gravitino 内核代码完全解耦,遵循开闭原则,将未来升级社区版本过程中的改造成本降到最低
2.元数据管理架构演进
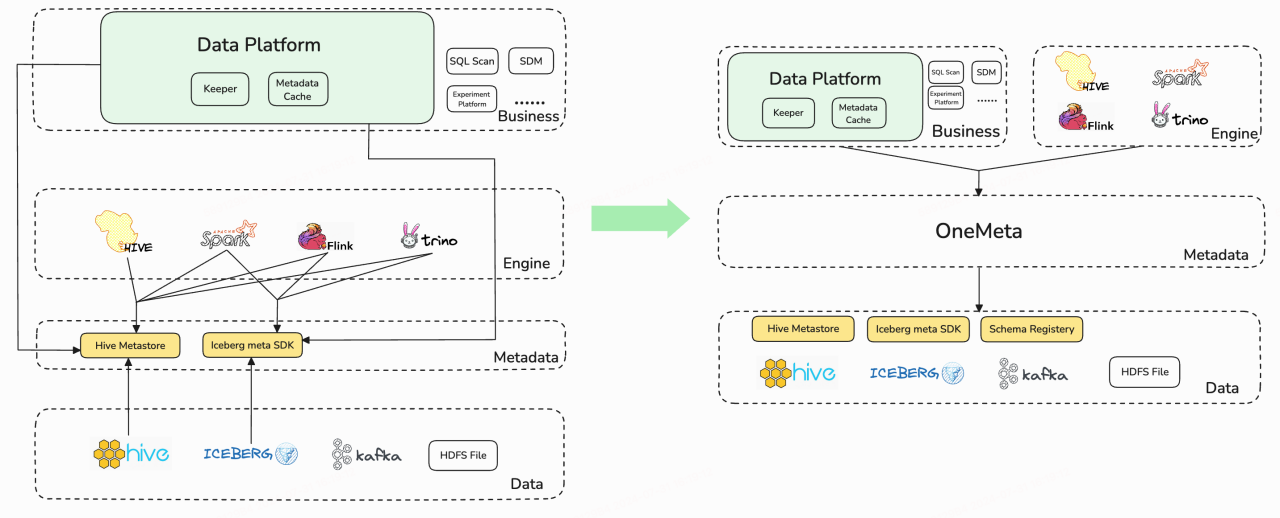
元数据架构管理演进带来的收入有如下三点:
(1)降低了元数据的使用成本。当前架构中,各业务组件(如数据平台、治理工具、SQL Scan、SDM 等)获取元数据的方式复杂且不统一,有的通过引擎获取,有的依赖 Hive Metastore 或 Iceberg SDK,调用方式因数据源不同而异,同时需要对不同数据源的元数据进行统一视图处理。此外,底层元数据源的版本变更会影响上层使用,导致用户使用成本高。而引入 Gravitino 后,所有用户的元数据统一从 OneMeta 获取,解耦了用户与底层数据源的复杂依赖,大幅降低了元数据使用成本。
(2)解决了由于引擎和数据源之间的差异导致的元数据不一致问题。我们曾在生产中遇到过一些案例,例如,用户使用Iceberg表,其中一部分元数据信息存储在Hive元数据仓库中,而另一部分则由Iceberg自己维护。因此,用户需要从两个不同的地方获取两份数据。现在,用户只需从一个地方获取相应的元数据信息即可,还能避免数据不一致的问题。
(3)解决了Hive MetaStore 部分造成的性能瓶颈。
当删除大表时,如分区数过多,有些表会无法删除;二是在线上遇到几十万张、几十万个分区的表时,直接使用metastore API删除会失败。我们的解决方案是先将所有分区删除,然后再删除整个表。
对于我们使用的元数据平台,每天都会用定时任务发起getTable请求获取线上全量表的数据结构。Gravitino在对Hive MetaStore的连接上中有池化和并发处理,连接Hive MetaStore的速度非常快。我们的数据平台替换为从Onemeta获取元数据后,接口响应时间大约降低了70%。
3.跨数据源Schema管理
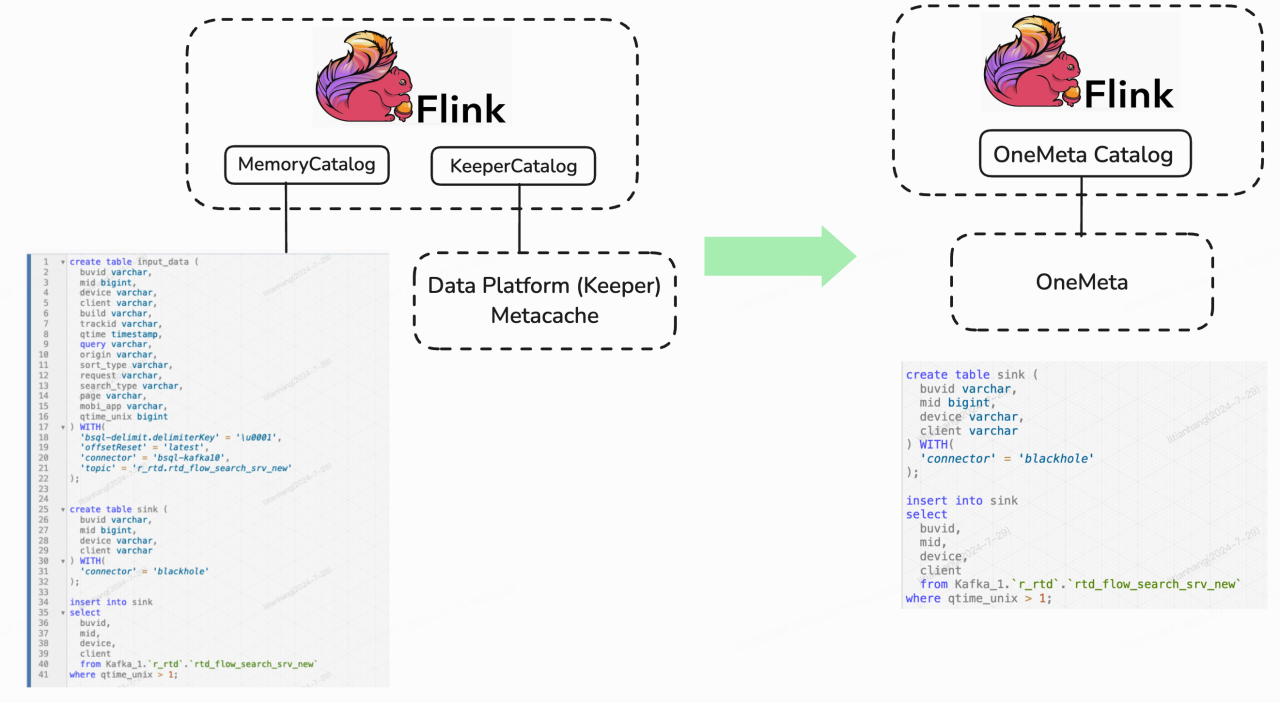
在引入 OneMeta(Gravitino)前,用户可以通过两种方式管理跨数据源 Schema:
使用 memory-catalog,需要手动编写 DDL 进行加载,并指定具体的 schema 形态和 Kafka 连接信息;使用 keeper-Catalog,可以加载缓存在上层的元数据信息。但存在缺陷,如用户需要注明 Kafka 的集群链接、schema 维护成本较高,并且整个系统也产生了反向依赖,还容易出现上下游 schema 不一致的情况,导致任务无法成功运行。
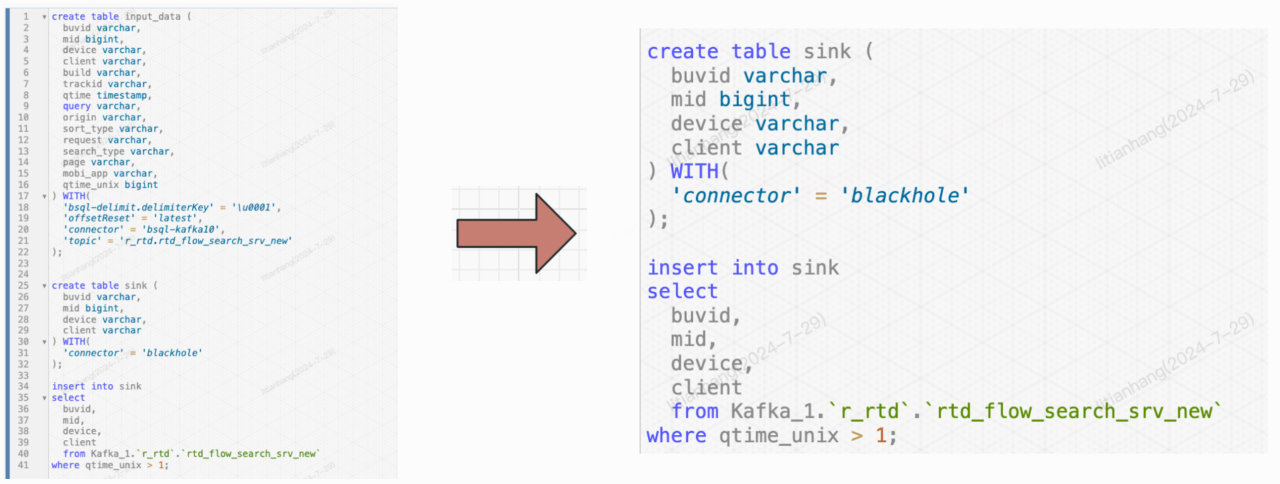
我们希望用户不再需要手动编写 DDL 和指定 Kafka 的连接信息,只需指定一个具体的 Kafka topic name 即可启动 Flink 任务。Flink 会在启动时通过 catalog 向 meta 读取相关信息。
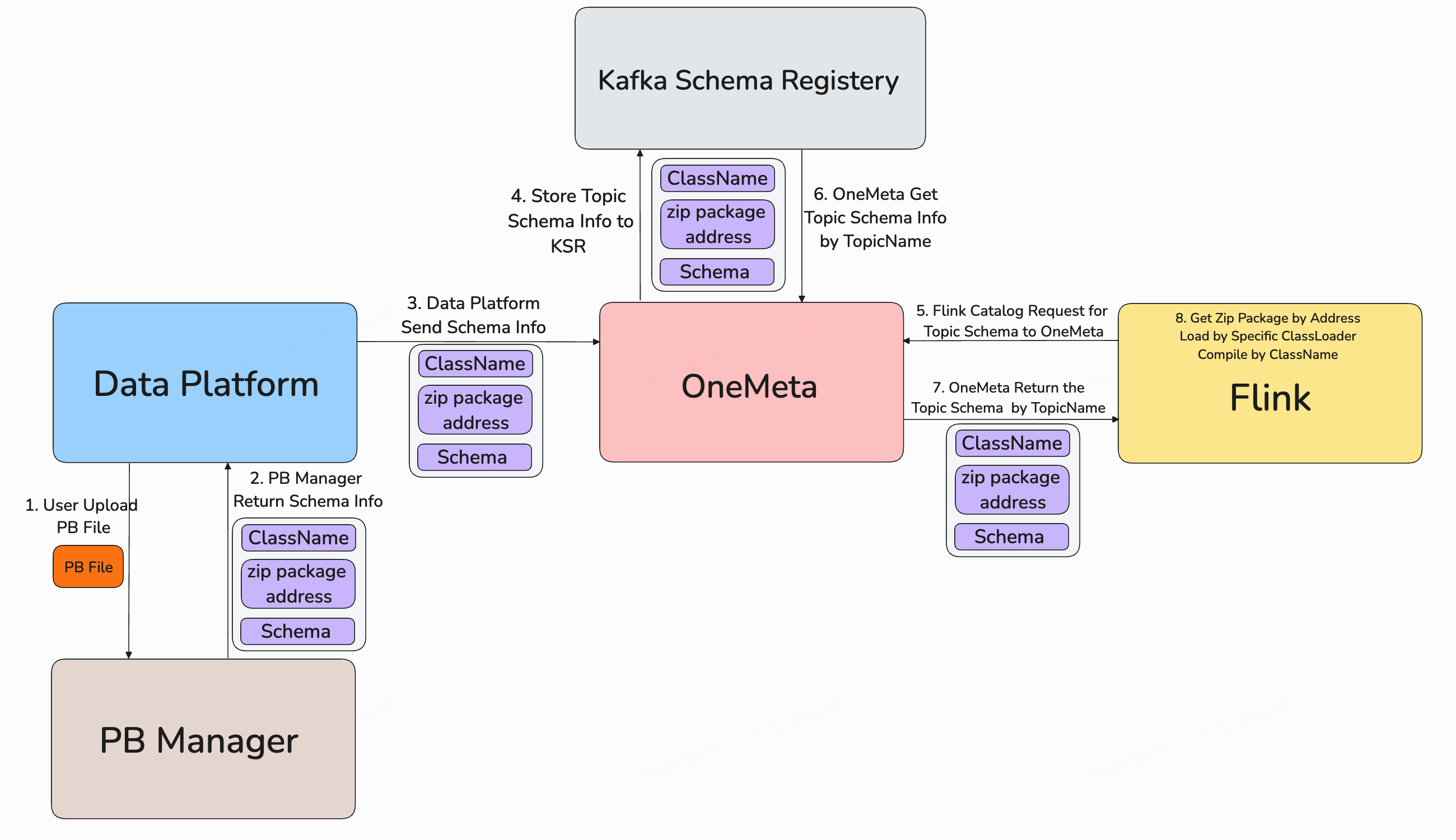
我们将以 PB 格式为例,介绍如何进行基于 Gravitino 的 Kafka 去 DDL 生产实践。目前,我们在生产中支持 Kafka 的消息格式,包括 JSON、分隔符和 PB。
以 PB 格式为例,我们实现了基于 PB 打包编译全闭环的跨域 schema 管理。具体流程是:
(1)第一个实践
(2)Flink 启动新任务时,需要根据 topic name 获取该 topic 的具体 schema 信息,OneMeta 从Kafka Schema Registry存储中获取具体产物信息并返回给 Flink。
(3)Flink 使用类加载器进行解析编译好的schema。基于 Flink 团队实现的独立的类加载器, 下载 HDFS 上编译好的PB文件和相关依赖包,实现非结构类型的动态schema解析
跨源 schema 管理优化带来了以下收益:
(1)实现了中心化的 Kafka 原始信息管理,避免了数据不一致性的问题;
(2)降低了用户使用 Kafka 的消息成本;
(3)降低了任务维护成本,提高了 Flink 任务的上线效率。
4.HDFS文件治理现状

B 站内部 HDFS 文件治理数据量达到了 EB 级别,其中非表路径占总存储的 30%,在 AI 商业场景下,HDFS 存储量的增长较高,存在大量未被规范管理的 HDFS 路径。用户需要将 Airflow 原来的路径管理逻辑迁移到我们的大数据平台上。目前我们对 Hive 路径进行了 EC 和 TTL 操作,非表路径存在大量 EC 和 TTL 治理需求。
5.Fileset文件管理
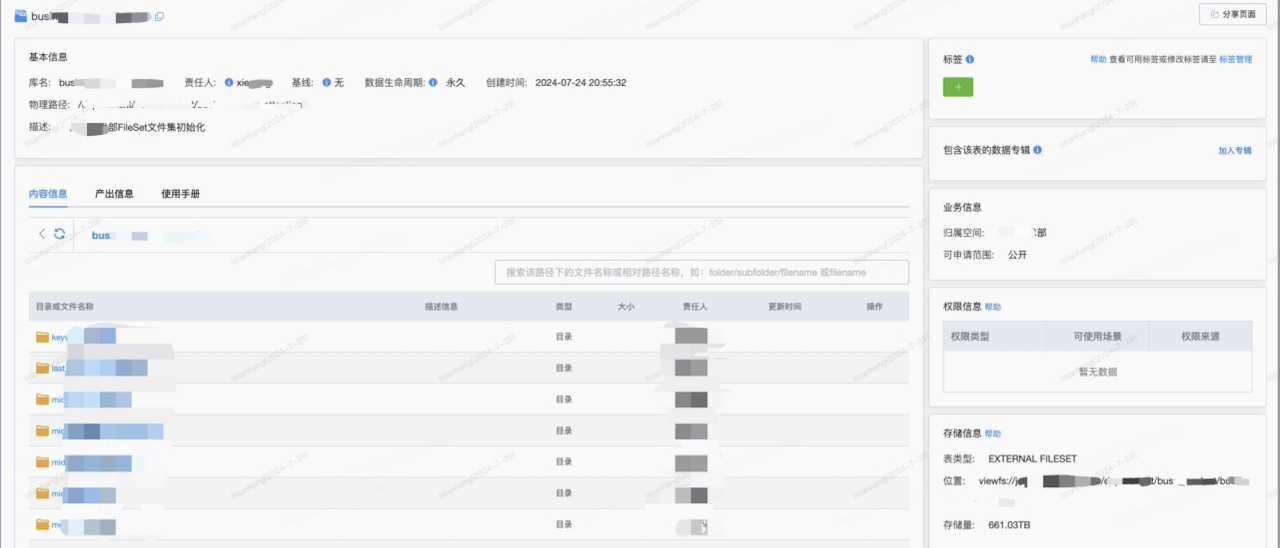
FileSet是文件集的概念,是我们内部大数据平台管理页面的基础。这个页面直接面向各种数据分析、AI和商业数据分析师使用。图中是基于FileSet的管理页面,用户不断向下点击以获取子目录或子目录下的特定文件,支持对FileSet等进行模糊查询等功能。
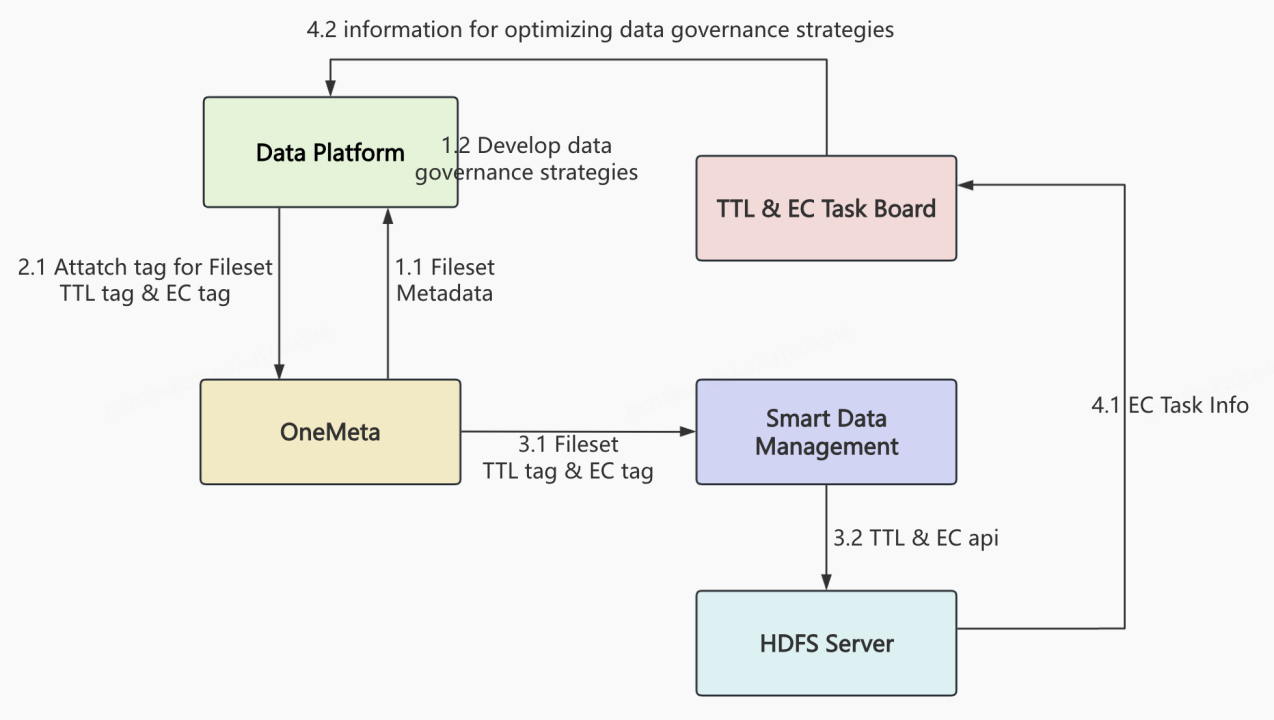
我们已经使用 Fileset 将 HDFS 文件管理起来,因此我们希望能够基于 FileSet 对 HDFS 进行具体文件治理,以达到降本增效的效果并获得收益。以下是基于 FileSet 文件治理的主要流程图。FileSet 文件治理主要分为两个部分,即 EC 和 TTL,它们的实现逻辑和架构都类似。
首先,我们可以看到左边的流程图展示了整个过程:
(1)数据治理平台制定治理策略;
(2)通过 OneMeta 对相应 FileSet 进行 TTL 和 EC 打标;
(3)SDM(智能数据管理)读取 OneMeta tag,向 HDFS Server 发送 TTL 和 EC 指令;
(4)数据治理工程师根据看板进行治理优化。
目前我们正在推进和建设 HDFS EC,预计可以减少约 100PB 的存储成本。对于基于 FileSet 对 HDFS 文件进行的 TTL,我们可以减少约 300PB 的存储成本。
接下将介绍 FileSet 在 AI 文件管理中的具体应用,这里的 VIEWFS 对应的是 Gravitino 社区的 GVFS 概念。FileSet 不仅可以通过前端页面让用户进行管控,还支持用户通过 Spark JAR、Spark SQL 和 Python 客户端进行操作。例如,在 Spark 下,我们可以直接在 Spark 代码中读取和写入 FileSet。用户可以直接使用这种格式,无需引入任何外部依赖或升级 HDFS Client。具体的实现方法将在后续章节中详细介绍,只需将原来依赖的 HDFS 物理路径替换为 FileSet 即可。
对于 Python 客户端,不需要引入任何依赖,只需修改写法即可。用户从物理路径切换到推荐的文件系统非常便捷,一旦接入 FileSet,元数据信息就能得到更好的维护。此外,FileSet 还提供了文件交接和其他信息查看等便利功能。
6. GVFS
为了使用 Gravitino 管理的 Fileset,Gravitino 提供了一个虚拟文件系统层,称为 Gravitino Virtual File System(GVFS):
• 在 Java 中,它基于 Hadoop Compatible File System(HCFS)接口构建。
• 在 Python 中,它基于 fsspec 接口构建。
用户可以在 Spark jar、Spark SQL、Python 客户端等场景使用 Metalake-Catalog-Schema-Fileset 的范式,基于 GVFS 对底层文件集/文件进行访问

接下来我们将详细介绍如何实现 GVFS。
基于 B 站存储团队对外提供的hdfs版本目前会统一访问一层NNproxy 的网关服务, 用户日常使用过程中无需任何改动,无需升级对应 HDFS Client 版本对于所有需要使用FileSet 的用户,须在B站资产管理平台注册Fileset, 然后可以选择保持原生的hdfs文件目录的访问姿势不变, 通过NNproxy 定时地异步加载 OneMeta 的fileset 信息。基于真实传递过来的 HDFS 路径进行 Fileset 的反查,实现例如目文件系统的访问血缘记录, 核心路径读写保护等一系列的增强功能。另外如果用户希望在访问文件的作业上提高可读性和可维护性,我们推荐用户使用 Gravitino 官方推荐的三段式(catalog/schema/fileset)的写法并且保持协议不变(viewfs)的基础上进行规范的文件访问

7.Iceberg branch 的支持
在b站的大数据架构中,以Iceberg 为代表的湖式数据源被广泛使用。我们发现,基于iceberg 的新特性 —— 表级别的branch 功能能够在多种场景下起到降本增效的作用。以AI场景下的典型 case 为例,在特定数据进行实验,验证其有效性或评估对模型的影响时,用户会以一张Iceberg为底表,建出多个schema 相似,但数据基本一致的表。而如果基于iceberg 表的branch 功能,我们可以以底表为main 分支,建出多个schema 不同的分支而共用一套数据,避免重复建表,大量节约存储资源,以下是基于OneMeta实现的branch的部分管理页面
从用户视角来看,用户可以对已存在的表进行 branch 的管理功能:所有的 iceberg 表默认均为 main 分支,用户可基于任意已有的 base 分支新创建分支,新建的分支基于在 base 分支进行元数据的编辑(包含表字段信息,分支有效期,责任人等),新分支与 base 分支的元数据完全独立,可由不同的负责人使用并维护。


04 Apache Gravitino 规划展望
在基于 Gravitino 进行生产落地后,我们取得了显著的收益:
• 降低了元数据使用成本:通过统一的元数据管理,解耦了用户与底层数据源的复杂依赖,大幅降低用户使用元数据的成本。
• 解决了元数据不一致性问题:解决了 Iceberg SDK与 Hive MetaStore 维护的元数据不一致问题,提升了数据一致性和用户体验。
• 优化了 HDFS 文件治理:通过 EC 和 TTL 策略,显著降低了存储成本,预计节省超过几百 PB 的存储。
• 提升了任务效率:通过跨源 Schema 管理和 Fileset 管理,简化了用户操作,减少了任务的开发和维护成本。
• 为用户提供了更丰富的功能:通过想用户提供 iceberg branch 能力,丰富了用户对 iceberg 表的使用方式,同时也降低了数据存储成本
基于这些成果,我们对 Gravitino 未来的发展做出了以下规划,每个方向均针对当前痛点和进一步优化需求提出了解决思路:
1. 基于 Gravitino 的统一权限管理
• 当前数据权限管理存在分散且复杂的现状,不同数据源和应用场景使用不同的权限体系,导致管理成本高、审计复杂。我们希望通过 Gravitino 实现跨数据源的一体化权限管控,提供统一的用户认证、权限分配和审计能力,从而增强数据安全性并简化运维。
2. 扩展 UDF 数据资源的管理能力
• 在 AI 和数据分析场景中,UDF(用户自定义函数)是重要的计算资产。然而,UDF 的管理和版本控制目前缺乏标准化手段。我们计划通过 Gravitino 的扩展,为 UDF 提供统一的元数据管理和资源管控能力,方便用户维护和复用 UDF,并降低使用门槛。
3. 接入更多内部数据源,实现统一管理
• 当前 Gravitino 已公司内大部分大数据场景下的数据源,但尚有部分内部数据源未被纳入统一管理体系。通过全面接入所有数据源,能够进一步提升数据治理能力,为用户提供更完整的全域数据视图。
4. OneMeta 对接所有引擎,统一访问范式
• 目前不同计算引擎(如 Spark、Flink、Trino 等)在访问元数据时使用不同的方式。我们计划通过 OneMeta 提供统一的访问接口,使所有引擎能够采用一致的访问模式,减少开发工作量,同时提高系统的兼容性和稳定性。
5. 完善 AI 场景下的数据治理(如模型版本管理)
• 随着 AI 的普及,模型版本管理和数据治理的重要性日益凸显。我们计划通过 Gravitino 对 AI 模型及其数据资产进行全生命周期管理,包括模型的版本控制、评估与溯源,从而提升 AI 项目的可靠性和可维护性。
6. Fileset 对接对象存储,打通文件系统与流/批/OLAP 引擎
• 目前 Fileset 主要应用于 HDFS 文件管理。我们计划扩展 Fileset 支持对象存储,并与流处理、批处理、OLAP 等引擎深度集成,实现数据全链路血缘的可视化和访问日志记录,进一步提高数据治理的透明度与效率。

