B站票务抢购下单流程演进
1. 背景
bilibili 会员购票务从2017年从0-1开始,目前业务覆盖全国绝大部分2次元及2.5次元的展览、演出等项目。比如展览方面,有B站自己主办的BiliBili World(简称BW),Bilibili Macro Link(简称BML),和各种协作承办的漫展等。目前会员购票务在漫展垂直的市场率在行业中处于TOP级领先地位。
bilibili 会员购票务提供多种业务形态,包括:
抢票功能:帮助用户抢购热门活动票,避免黄牛抢购风险场景发生。
电影票:提供便捷的电影票购买通道,接通站内电影营销。
选座功能:支持用户自主选择座位。
检票工具:提升现场入场效率,体现平台服务独特性
结算:业内高效、快速对账结算体系。
这些服务为用户提供便捷的票务体验,涵盖了从购票到入场到结算全流程需求。
项目列表 ➡️ 项目详情 ➡️ 结算页 ➡️ 订单详情
由于近年来漫展、电影等文化产业的消费力复苏,系统频繁承载高并发抢购场景(如漫展门票)。然而,热门项目库存远低于市场需求,传统架构在高并发场景下面临性能瓶颈。如何保障系统稳定性与用户体验,成为核心挑战。
2. 演进目标
对于一个热门的抢购项目,用户的基本访问链路为:项目列表/收藏 -> 商详 -> 选中对应的场次已经票种 -> 结算页补充下单信息 -> 下单。在上述链路中,其中商详以及项目列表基本都是一些固定的信息(商详页面的是否售罄用户也可以接受短期的延迟),所以这部分流程基本可以通过缓存去做处理,而大部分用户在结算页补充完个人信息之后,会对于创单接口进行多次且频繁的访问。下单接口流量大、实时性要求高,且直接影响交易收入转化,所以保障下单接口稳定成为重中之重。
围绕流量峰值承载、数据库压力优化、用户等待时长缩短三大核心目标,我们对下单链路进行了三阶段迭代。
3. 演进进程
随着会员购票务在漫展市场占比逐渐增加,票务的下单接口也经历过了以下三个阶段:
3.1 初始版本 - 同步事务处理
一:背景
在票务从0-1的过程中,为了增加市场的占有率,需要实现功能的快速迭代,这个过程中对于方案的考虑基本以实现基础功能为主。
二:方案
流程逻辑:用户请求实时同步处理库存扣减与订单写入。

三:效果
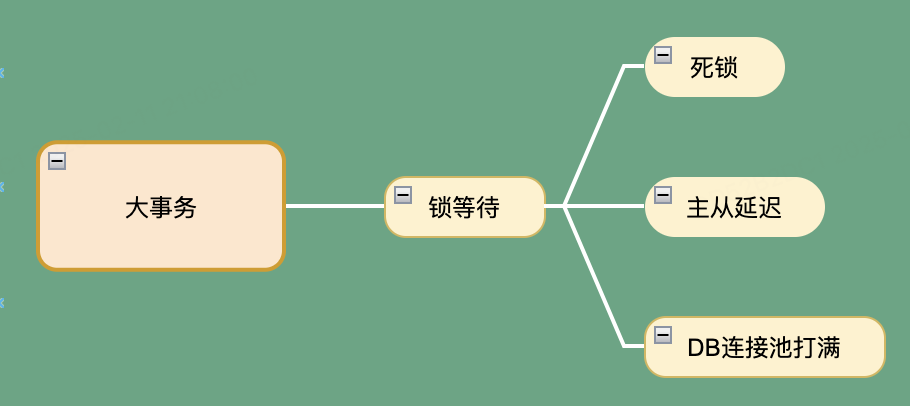
初始版本过程中,足以应对普通流量下的用户下单需求,然而当出现抢购的场景是,大事务以及库存DB的单行扣减问题的会影响到接口的性能以及接口响应时间,甚至出现库存死锁等问题。从而导致服务的雪崩。
痛点分析:
✅ 高并发下大事务阻塞——DB连接池耗尽,响应延迟飙升。
✅ 单行库存热点——InnoDB行锁竞争引发死锁,扣减失败率超30%。
✅ 无弹性扩展能力——服务雪崩风险显著。
3.2 异步下单 - 异步削峰,
降低响应时长以及DB压力
一:背景
针对于抢购的场景,为了避免出现因为库存以及大事务场景下影响用户下单,为了解决这种情况,衍生出了异步下单的版本:
二:方案
流程逻辑:解耦请求接收与事务执行,引入异步分批处理。
🔹前端交互:
用户获取下单Token,轮询查询结果(平均等待5-8秒)。
🔹后端处理:
✅ 库存批量冻结:合并SQL减少DB操作频次。
✅ 优惠券并行校验:拆分耦合模块提升吞吐量。
针对于用户下单接口中的容易导致DB出现异常的模块,进行异步削峰处理,将用户下单请求以及实际下单接口,拆分为两个模块处理,并且将下单批量化处理,减少DB的操作次数,降低DB的风险。
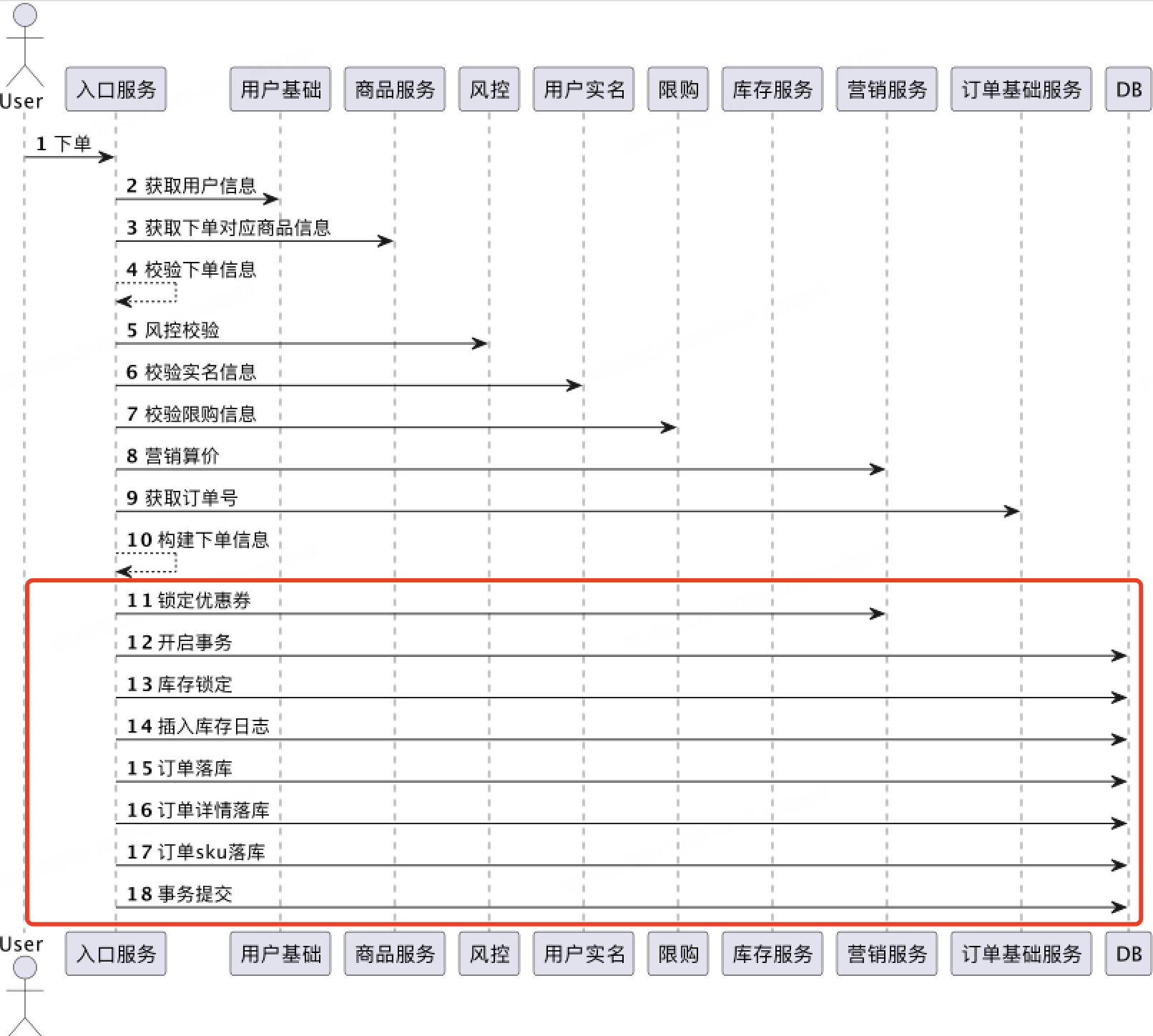
此时用户下单分成了三个步骤:
1. 用户下单,获取下单标识(唯一token)
2. 定时任务,批量下单,将之前的单条库存扣减、订单插入修改为进行批量冻结库存,并行冻结优惠券,批量合并sql插入数据库,最大限度上减少性能消耗
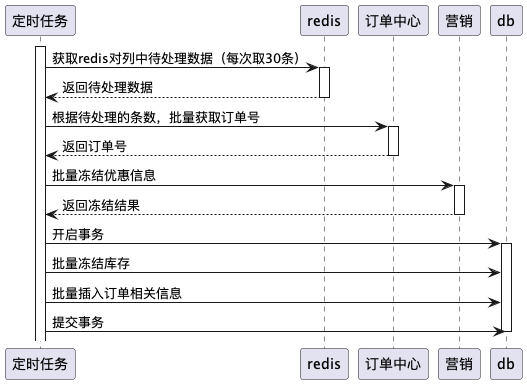
3. C端在下单页新增轮询接口根据唯一token轮询下单结果
三:效果
此方法很大程度上解决了数据库压力问题,但用户体验因轮询等待下降。
3.3 redis缓存扣减库存下单
一:背景
异步下单已经能够解决大部分的热门项目的抢购问题,但是自从2022年之后,漫展的市场热度出现了巨大的变化,上海CP的项目抢购打了我们一个措手不及。在抢购之前预估流量为平时流量的2倍,然而实际结果是比预估的流量大了10倍不止,紧随其后的BW的抢购更是说明了异步下单已经不能保证一些热门项目的抢购, 对于下单接口需要进一步的改造。
在之前的异步下单链路中还是存在几个问题
前端用户体验,前端轮询下单结果,会有一个较长时间的等待。
支付回调流量不可把控,如果支付回调QPS过高,也会导致库存单行扣减压力
整个流程都是串行处理,如果下游接口响应耗时过高,会导致服务雪崩问题。
所以还需要对下单链路进行处理
库存单行扣减优化
接口部分调用串行转成并行处理,降低接口响应耗时,提升服务处理速度
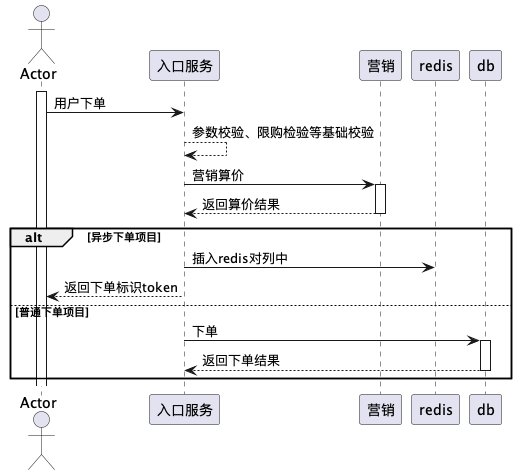
二:方案
架构升级:
🔹 库存分层设计:
Redis预扣(90%库存):通过Lua脚本保证原子扣减,提升下单库存性能
DB兜底(10%库存):故障熔断时启用,结合库存校准机制防超卖(日志回溯+定时校准)。
🔹 支付回调异步化:
临时表削峰:支付成功后写入待扣减记录,定时任务批量处理DB库存。
并行化链路:优惠券核销、积分计算等模块异步执行,接口响应下降。
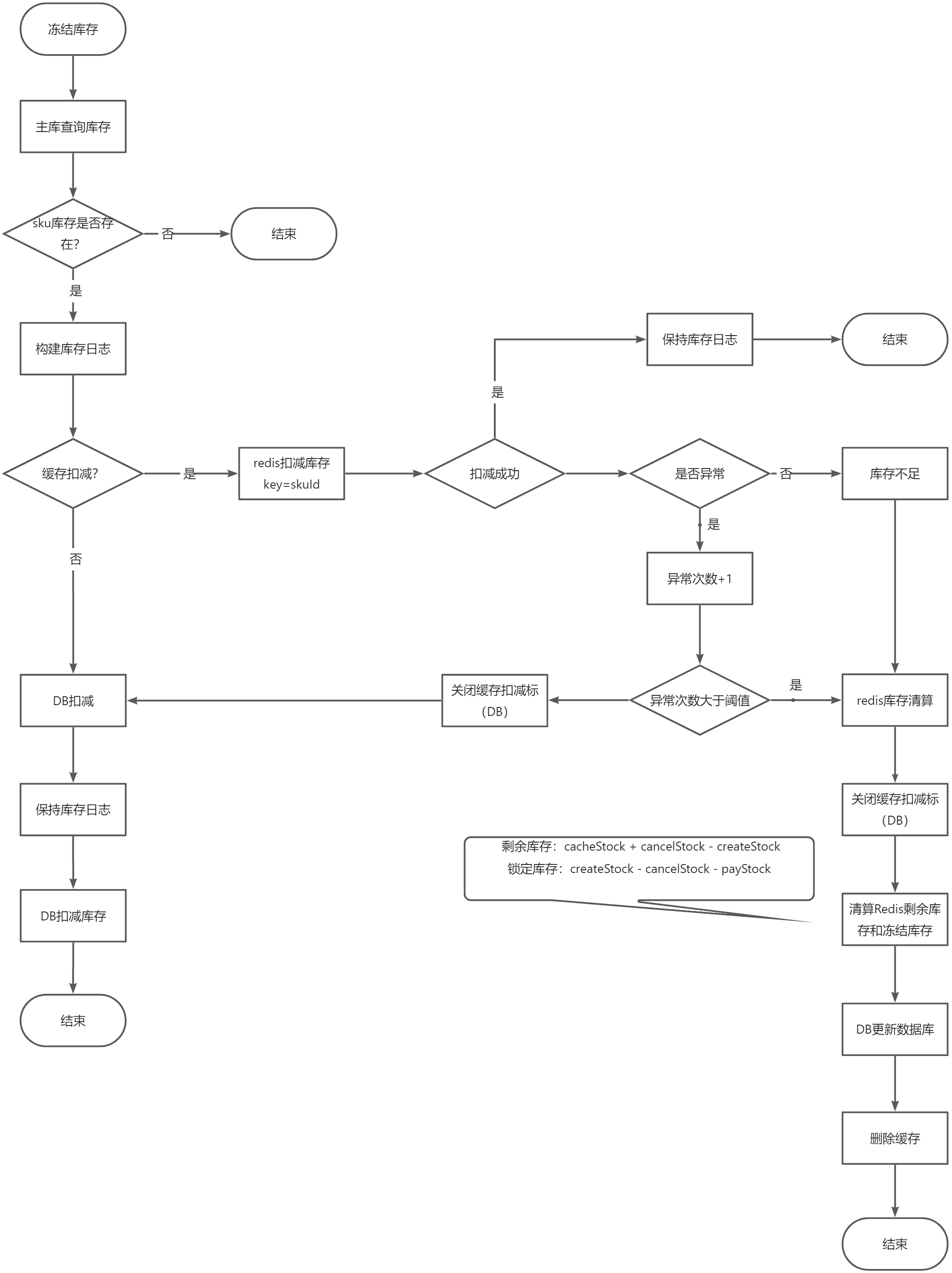
对于库存的扣减优化,主要有两点:
1. 下单扣减库存从DB扣改为redis扣,具体处理方式为:
a. 下单减库存,取全量库存的90%放入Redis进行扣减,这样做的目的是在Redis出现不可用的情况下,可以有部分数据库库存承接一定的流量等待库存校准完成。
b. Redis扣减失败会通过数据库进行扣减,失败达到阈值触发库存校准,并关闭热点标。
c. 库存校准:每次缓存库存操作会记录日志,用于校准数据库库存,避免因Redis超时重试等情况产生的超卖少卖。
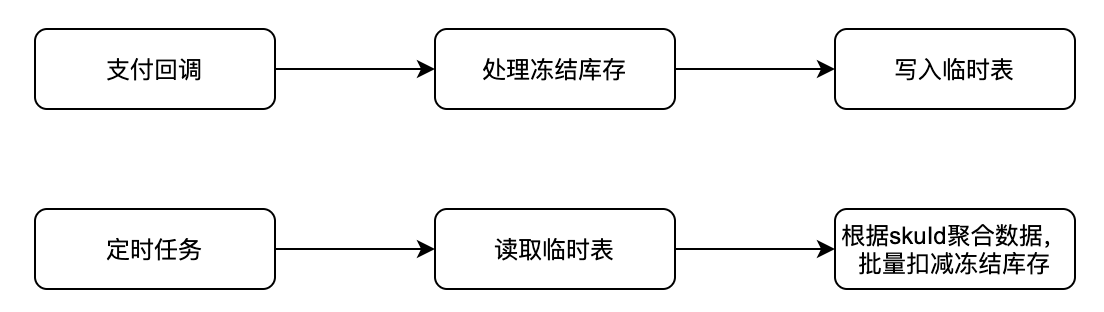
2. 支付回调后扣减进入临时表缓冲
支付回调存在了QPS不稳定的风险,并且因为涉及到订单状态的变更,也不能进行限流操作,但是因为此处库存不影响前台项目的销售,所以接受一定程度的延迟,在支付回调过程中,将需要扣减的冻结库存暂时写入到一张临时表中,通过定时任务的方式做批量化处理,既起到了削峰的作用,也降低了库存的操作频次,大大降低了DB的热点数据问题。
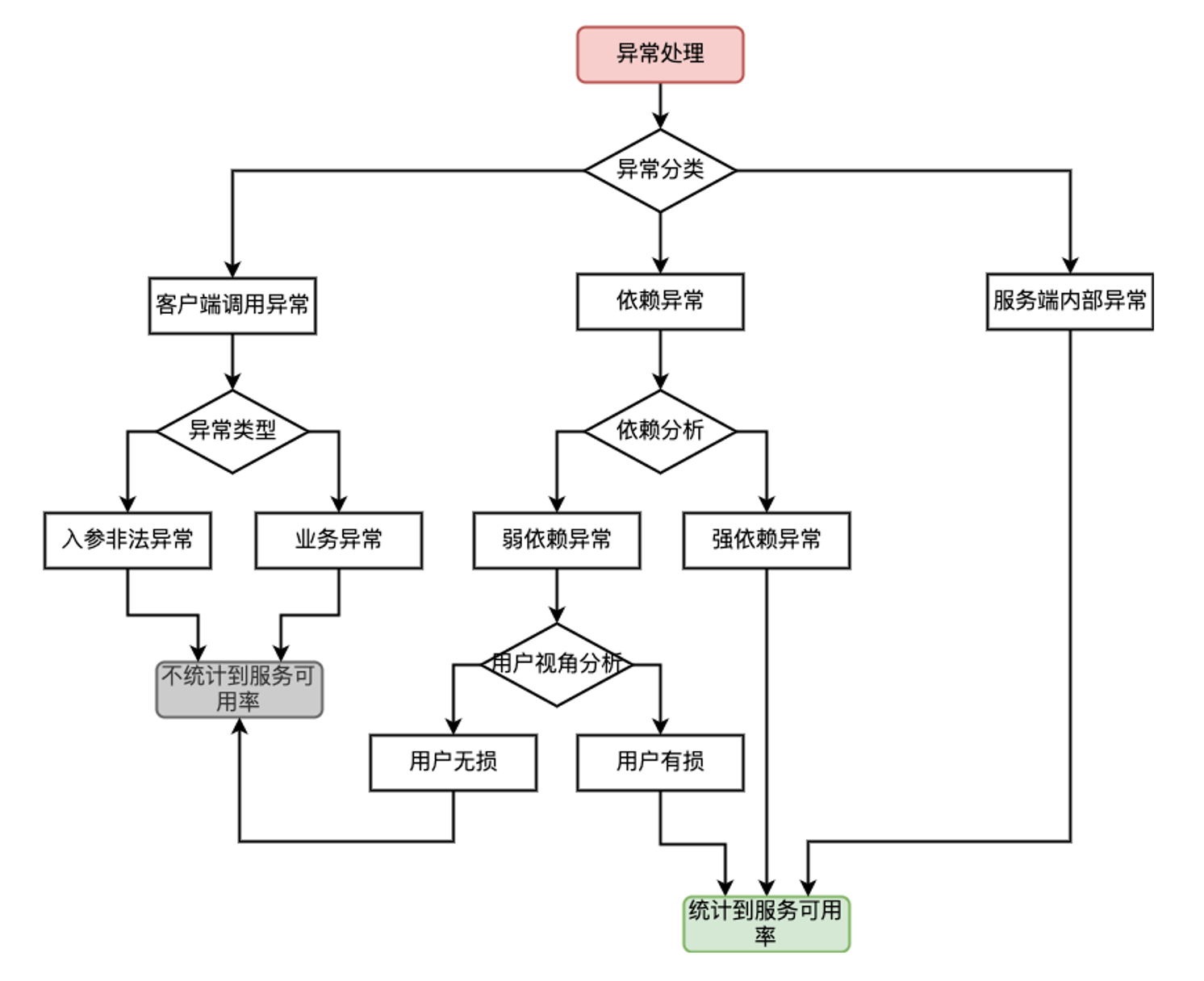
同时,为了系统性地提高整体的读写并发度,我们做了如下梳理和优化
1. 应用节点(链路)过长
强弱依赖梳理,提供降级开关
缩短RT时长,提升下单链路的各个接口性能
规整服务告警和异常处理机制,尽量收缩核心链路范围,保证爆发期主链路的服务可用率达到SLA(下图是focus主链路异常处理和SLA监控的梳理逻辑)
2. 数据库
sql慢查询优化
DB主从数据同步延迟:下单链路查主库
数据库表优化:合表减少减少查表次数等
大事务:将数据库查询工作和rpc调用移除事务
扫描资源消耗过大的定时任务做提前预案,抢票时提前降级:改用databus消费
锁等待:避免非抢票相关的链路导致数据库加锁
数据库隔离级别:RR改为RC
此处增加一些细节阐述数据库事务模式RR和RC的区别,以及为什么在高并发场景下使用RC更合适
RR和RC的区别
一致性读
一致性读,又称为快照读。快照即当前行数据之前的历史版本。快照读就是使用快照信息显示基于某个时间点的查询结果,而不考虑与此同时运行的其他事务所执行的更改。
在MySQL 中,只有READ COMMITTED 和 REPEATABLE READ这两种事务隔离级别才会使用一致性读。
在 RC 中,每次读取都会重新生成一个快照,总是读取行的最新版本。
在 RR 中,快照会在事务中第一次SELECT语句执行时生成,只有在本事务中对数据进行更改才会更新快照。
在数据库的 RC 这种隔离级别中,还支持"半一致读" ,一条update语句,如果 where 条件匹配到的记录已经加锁,那么InnoDB会返回记录最近提交的版本,由MySQL上层判断此是否需要真的加锁。
锁机制
数据库的锁,在不同的事务隔离级别下,是采用了不同的机制的。在 MySQL 中,有三种类型的锁,分别是Record Lock、Gap Lock和 Next-Key Lock。
Record Lock表示记录锁,锁的是索引记录。
Gap Lock是间隙锁,锁的是索引记录之间的间隙。
Next-Key Lock是Record Lock和Gap Lock的组合,同时锁索引记录和间隙。他的范围是左开右闭的。
在 RC 中,只会对索引增加Record Lock,不会添加Gap Lock和Next-Key Lock。
在 RR 中,为了解决幻读的问题,在支持Record Lock的同时,还支持Gap Lock和Next-Key Lock;
主从同步
在数据主从同步时,不同格式的 binlog 也对事务隔离级别有要求。
MySQL的binlog主要支持三种格式,分别是statement、row以及mixed,但是,RC 隔离级别只支持row格式的binlog。如果指定了mixed作为 binlog 格式,那么如果使用RC,服务器会自动使用基于row 格式的日志记录。
而 RR 的隔离级别同时支持statement、row以及mixed三种。
为什么选择使用RC
首先,RC 在加锁的过程中,是不需要添加Gap Lock和 Next-Key Lock 的,只对要修改的记录添加行级锁就行了。
这就使得并发度要比 RR 高很多。
另外,因为 RC 还支持"半一致读",可以大大的减少了更新语句时行锁的冲突;对于不满足更新条件的记录,可以提前释放锁,提升并发度。
减少死锁
因为RR这种事务隔离级别会增加Gap Lock和 Next-Key Lock,这就使得锁的粒度变大,那么就会使得死锁的概率增大。
带来的问题
首先使用 RC 之后,就需要自己解决幻读的问题。还有就是使用 RC 的时候,不能使用statement格式的 binlog,这种影响其实可以忽略不计了,因为MySQL是在5.1.5版本开始支持row的、在5.1.8版本中开始支持mixed,后面这两种可以代替 statement格式。
RR和RC在限购流程中的影响

如何通过“RC+显示锁”强制避免幻读
尽管RC级别不自动防幻读,但可通过 业务层加锁控制 来弥补。常用方案:
方案1:显式加行锁
-- 事务ABEGIN;SELECT * FROM orders WHERE user_id=1 AND product_id=100 FOR UPDATE; -- 对已有行加行锁(假设当前无历史订单,此查询无数据,无法锁定任何行)
-- 此时加锁失败,其他事务仍可插入相同条件的订单
缺陷:若当前无符合条件的记录(如首次购买),SELECT ... FOR UPDATE 无法锁定未存在的行或范围,锁机制失效。
方案2:唯一索引强行约束
通过数据库唯一索引作为兜底:
ALTER TABLE orders ADD UNIQUE INDEX idx_user_product (user_id, product_id);
当并发INSERT触发唯一键冲突时,第二个事务会直接报错,业务代码需对这些错误重试或拦截。
优点:绝对安全,数据库层物理拦截;
缺点:
仅适用于“单对象严格唯一性”场景(如一人一商品限购一次);
若限购规则是N次(N>1),需改用计数器模式(如Redis原子操作)。
方案3:分布式锁 + 内存计数器
使用Redis或其他分布式协调服务(如ZooKeeper)执行原子操作:
-- Lua脚本实现原子化操作(示例)local key = "limit:user_1:product_100"local limit = 2local current = redis.call('GET', key) or 0if tonumber(current) < limit then redis.call('INCR', key) return "OK"else return "EXCEED_LIMIT"end
由以上分析可知,无论选择RC、RR级别事务模式,都无法只通过数据库实现多条件动态限购,必须额外通过 显式分布式锁或缓存计数 确保逻辑原子性——将并发冲突拦截在业务层。
3. 此外,我们还从以下三个方面做了一些优化,以期尽可能提高Redis缓存命中率和性能,从而增加整体的读写并发度
a. 缓存击穿/穿透/连接等待的深度优化
缓存击穿
问题本质:热点Key失效瞬间的高并发穿透
解决方案:
逻辑过期时间:
存储数据时附加过期时间戳,异步更新缓存
多级缓存架构
L1本地缓存(Caffeine) + L2 Redis缓存 + DB
缓存穿透
问题本质:恶意/异常请求不存在的数据
解决方案:
布隆过滤器
// 初始化布隆过滤器BloomFilter<String> bloomFilter = BloomFilter.create( Funnels.stringFunnel(Charset.forName("UTF-8")), 1000000, 0.01);
// 查询流程if (!bloomFilter.mightContain(key)) { return null; // 直接拦截}
空值缓存:设置短TTL的null值(建议5-30秒)
请求校验:业务层增加参数合法性校验
连接等待优化
问题本质:连接池资源竞争导致延迟
优化方案:
# Lettuce连接池配置示例spring.redis.lettuce.pool: max-active: 20 # 根据QPS计算:(平均请求耗时(ms) * 峰值QPS) / 1000 max-idle: 10 min-idle: 5 max-wait: 50ms # 超过阈值触发扩容 test-while-idle: true time-between-eviction-runs: 60s
监控指标:
连接获取时间(redis.pool.wait.duration)
活跃连接数(redis.pool.active)
等待线程数(redis.pool.queued-threads)
b.大key按片水平拆分
大key识别标准
String类型:Value > 10KB
Hash/List/Set/Zset:元素数量 > 5000 或 总大小 > 10MB
拆分策略:水平拆分
// 基于哈希分片int shard = Math.abs(key.hashCode()) % 1024;String shardKey = "user:" + shard + ":" + userId;
// 基于范围分片String shardKey = "order:" + (orderId >> 16) + ":" + orderId;
c.热key
延长非高频变Key的过期时间
多级缓存保证命中率,例如ProjectInfo存在本地缓存,查询顺序:本地缓存>redis缓存->db,添加降级缓存做兜底
后置校验的方式控制数据不一致风险:提前预热/更新redis缓存
d.综合性能优化矩阵
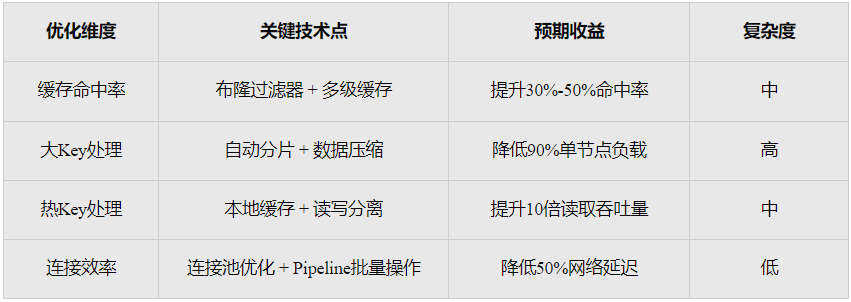
通过以上系统性优化方案,可以在保证数据一致性的前提下,将Redis缓存命中率提升至90%以上,同时显著降低数据库负载和响应延迟。
4. 除了尽可能提高系统的读写并发度,我们也尽可能为每个接口配置了兜底的限流策略,防止流量过载情况下对系统的雪崩型打击:
网关集群限流
业务单机限流:Guava RateLimiter,这里可以额外介绍集中生产级限流器的特性
预热机制:
// Guava RateLimiter的预热实现RateLimiter.create(permitsPerSecond, warmupPeriod, timeUnit);
动态配置:
支持运行时调整速率阈值
基于QPS自动弹性扩缩
分级降级:
请求量区间 策略---------------|-----------------< 50%阈值 | 正常处理50%-80%阈值 | 延迟响应80%-100%阈值 | 返回缓存数据> 100%阈值 | 直接拒绝
流量染色:
对通过/拒绝的请求添加标记头
实现全链路限流控制
三:效果
经过对于接口的优化处理、以及库存扣减避免缓存热点之后,目前已经可以支持绝大部分的项目抢购。在24年BW项目抢购中,我们承接了93w/s的WEBCDN峰值流量,30w/s +服务峰值流量,并顺利保障了BW票务销售的稳定和业务目标的达成。
4. 总结
我们进行的几次链路优化、异步下单改造、库存缓存扣减等措施上线后,票务系统的下单吞吐量和稳定性都得到了较大的提升,也逐渐可以承接更大型规模项目的抢票需求。然而还存在着较多的优化点,我们将持续改造,为用户提供更好的购票体验。

