云认证的可观测性体系建设
01 导读
可观测性最早源于控制理论,是衡量一个系统从其外部输出中推断系统内部状态的一种度量,后被引申到计算机领域,用于表达系统故障的可观测性。一般来说, 可观测性有三大支柱:日志、链路和指标,这三部分各有侧重,相互交叉但又相对独立,它们一起组成了可观测性的基石。
日志(Log):记录离散事件,并以此来分析出程序的行为。
链路(Trace):一般指分布式追踪数据,用于构建出用户完整的分布式调用堆栈信息。链路的主要目的是排查故障,如分析调用链的哪个方法超时或错误,输入输出是否符合预期等。
指标(Metrics):指对系统某一类信息的统计聚合。通过多维度、可视化工具的展示,可以帮助管理人员快速了解系统的运行状态。
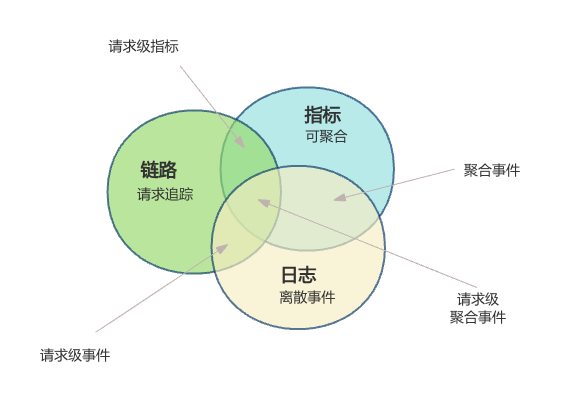
图1:可观测性三大支柱关联图
与之前传统的监控和日志相比,可观测性不仅能告诉我们系统哪里有问题,更重要的价值在于告诉我们系统为什么出故障以及如何解决,即快速排障。本文主要以58集团云认证业务为例,带大家深入了解云认证在建设可观测性体系中的一系列挑战和实践。
02 背景
云认证为58集团各业务线提供用户准入门槛,通过人脸认证、银行卡认证、企业法人认证等形式确定一个自然人与账号的对应关系,是集团重要的安全准入业务之一。
随着业务的发展,我们在服务监控方面遇到了一些问题:
排错困难:部分认证方式流程长,跨越服务众多,当遇到问题时难以定位根源服务,排查主要依赖当值人员的个人经验,很难形成较为完整的思路体系,快速准确定位问题。
告警存在误报:告警精确率差,常因流量抖动或用户错误重试导致告警,消耗值班人员精力,以致对告警麻木,忽视真正告警信息。
缺乏全局性视角:对系统整体表现如何缺乏全局性的认知,例如最近一段时间系统表现如何,怎样优化等很难直观描述出来。以成功率或失败量衡量有些片面,一直处于问题来了就解决的被动状态,不利于业务的长期发展。
针对这些问题,我们将可观测性的概念引入到云认证里,并结合自身情况,构建了云认证的可观测体系。下面就以这些问题为导向,向大家介绍云认证的可观测性体系。
03 如何排错
快速排错是可观测性的核心目标,也是我们引入可观测性的最大动力,相信大家都有一个case排查半天无果的糟糕经历,在引入可观测性之前,云认证的日常的case排错流程如下:
通过ELK体系搜集到各认证服务日志,在kibana通过关键词查找目标日志,如果找到则据此分析,若找不到或分析未果,则需要去各服务查看机器日志,此时的排查将变得费时耗力。
当出现异常报警后,一般还需要查询监控日志和服务日志,定位时间长,很难仅通过告警信息确定问题原因,不符合紧急定位的要求。
如何更加快速的定位问题,我们的解决思路如下:
3.1 优化日志
首先需要做的就是优化日志,在改造前,日志的主链路埋点不充分,日志体系较为繁杂,各服务或多或少都存在2-4套日志体系,部分日志职责相互重叠且格式各异,不利于日志排查和后续处理。因此我们重新梳理并设计了新的日志格式,将日志分类为监控日志、hive日志和集群日志,并用新的客户端统一记录日志。
监控日志:主链路以及所有异常日志,是排查问题的重要信息,对涉及到的日志“应埋尽埋”,日志通过ELK体系流入kibana。
hive日志:围绕主链路的一些状态变更、入库操作等相关辅助信息日志,这些日志经flume收集入HDFS,最终可通过hive表的形式查询。
集群日志:即通常说的机器日志,一般用于调试,特殊情况下可辅助问题排查。
上述日志均有一定格式要求,如日志事由、链路id、请求出入参等。这里重点说说结果标识的设计,结果标识使用了两个字段表示:res_code和biz_code,res_code表示本次请求的总体结果,biz_code表示业务上的请求结果,相关组合如下:
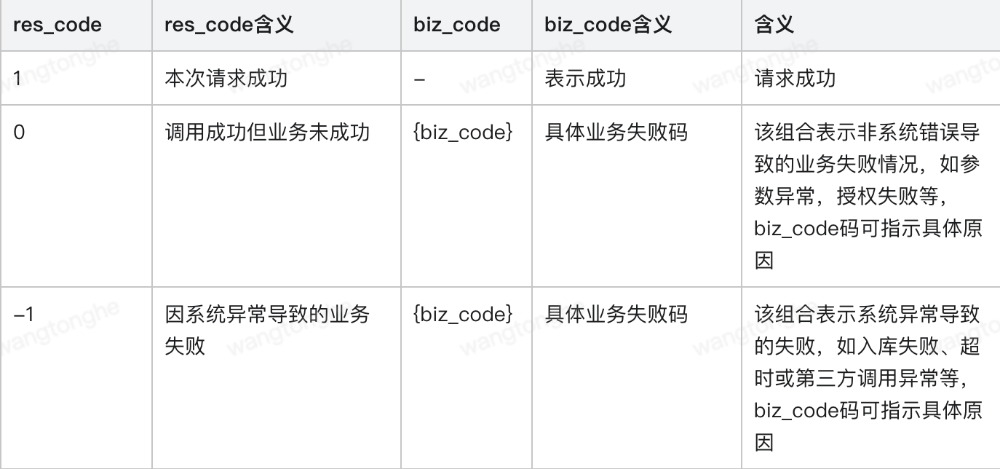
图2:错误码设计说明
这套组合码的不同之处在于:区分出了是因自身原因还是外部传参导致的问题,可以快速反映出系统本身的稳定性,这在统计影响范围时特别有效。除此之外,这套错误码也应用在告警方面,避免非系统原因导致误报,这部分会在“解决误报警-燃烧率告警”章节再次说明,这里就不赘述了。
3.2 使用链路追踪
单单优化日志还不足以快速定位问题,一是日志无法做到全流程全链路埋点(成本太高也不现实),二是日志只能帮我们还原本层业务流程,无法串联起如上下游全流程的请求链路,如遇到埋点不足或上下游出问题的场景,日志很难有所发挥。
因此,我们引入了链路追踪工具wtrace(公司内部分布式链路追踪服务),同其他链路追踪一样,wtrace可实现链路追踪、性能剖析等多种功能。
在日志收集阶段,将收集到的日志和链路追踪通过traceId打通,可以更加全面的了解请求的整个过程,包括接口入参、耗时以及可能的异常栈,再结合日志来看,做到对调用的细节了如指掌的地步。
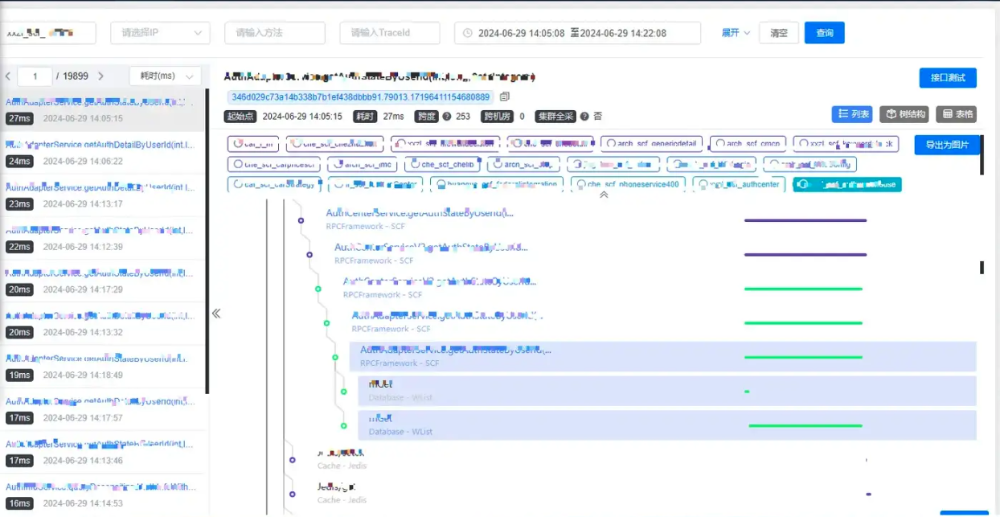
图3:wtrace页面功能展示
3.3 优化监控指标
针对出现告警后不能快速定位的问题,促使我们丰富监控指标,总体上将指标分为两类:SLI/SLO指标和辅助指标。SLI/SLO指标为核心指标,关联告警,辅助指标则围绕核心指标建设,用来描述SLI/SLO该指标。
如某个核心指标为认证成功率,则辅助指标为导致认证成功率降低的各项指标,如下表所示:
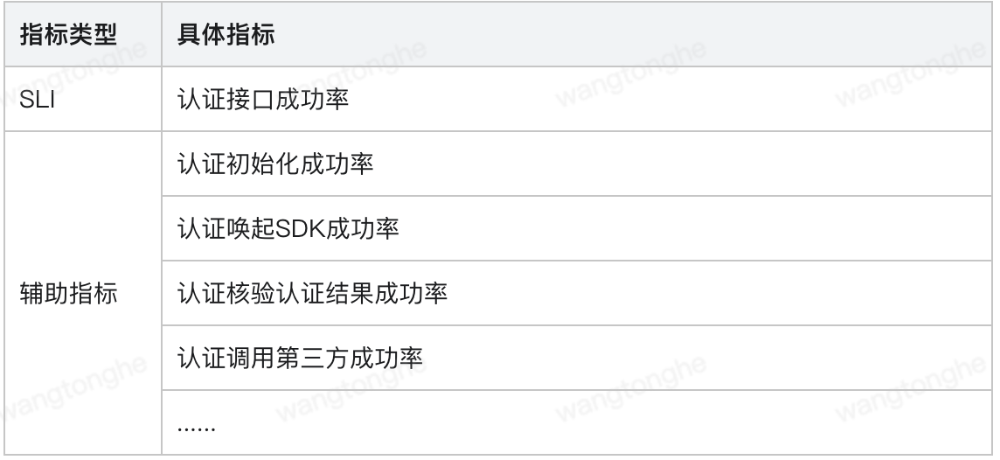
图4:监控指标示例
用一句话概括就是:SLO指标尽量精简,辅助指标尽量全面,当某个SLO发出告警后,查看其辅助指标即可了解异常原因,即可快速定位。
04 解决错误警告
误告警向来是告警的难点,再碰上云认证这种业务周期长,埋点复杂的业务更是雪上加霜。目前的监控告警为统计短时间的成功率,这种模式更是加剧了误报现象。经分析,导致误报的原因主要有两个:流量抖动和低流量。
流量抖动包括网络抖动、单个账号频繁重试或其他无关紧要的原因导致的短时错误量上升,这种情况的特点是短时间可恢复,很难影响服务的SLO目标,却不得不因为报警而高度紧张。假设一个服务的可靠性目标设定为99.9%,告警窗口为10分钟。那么在这10分钟内,只要错误率达到0.1%就会触发告警,一天内极端情况甚至会出现144次告警,而即便忽略这些告警,服务的稳定性依然可能是达标的,低流量导致的误报更是如此。
这种情况下告警的查全率(所有重大事件都检测出来的比例)固然很高,但精准率(所有检测事件中确定是重大事件的比例)却很差,违背了监控告警的初衷。
受google SRE思想启发,我们引入了燃烧率告警来解决因抖动而导致的误报。燃烧率告警和SLO息息相关,在介绍燃烧率告警之前,有必要重新认识下SLO。
4.1 制定SLO指标
SLI/SLO指标我们一直在用,最开始只是将其当做一个告警的阈值而已,经过本次调整,我们将SLO提升到监控告警的中心位置,明确了以下共识:
100%可靠性的系统是不存在的,SLO则是衡量系统是否满足预期的关键指标,监控告警以及服务优化均以SLO为中心制定。
当服务不满足SLO时,需要采取如持续优化、减少更新等补救措施,具体依服务及现状确定,但是要有行动,避免SLO流于表面。
SLO不是越多越好,一个服务(在云认证场景中为认证类型)以2-4个为宜,最多不超过5个。
触发的告警必须是能够影响服务SLO指标的重大事件,尽量避免无效告警。
在实践中,云认证核心服务都为请求驱动型,结合业务特点,我们将SLO的类型分为三类:成功率、耗时和流量监控。再围绕该SLO制定一系列辅助指标,用于监控大盘,如下是某类认证的SLO相关指标:
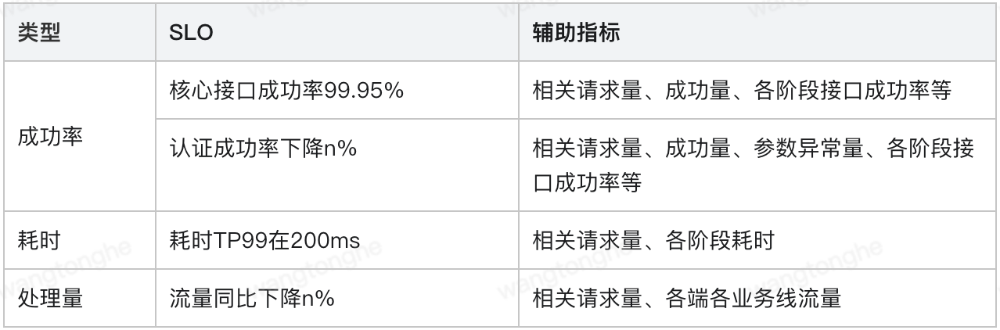
图5:SLO类型说明
核心接口成功率表示认证各关键节点接口调用是否异常,是衡量一个系统是否稳定的关键指标,而认证成功率则表示认证从发起到认证成功的完成率,受用户影响较大,如用户中途放弃认证、填写信息有误都会影响该指标,因此在SLO的制定上该指标使用了下降n%的表述方式,在实践中,一般以指标下降30-50%作为告警阈值。
4.2 燃烧率告警
采用燃烧率告警主要解决误报问题,即提升告警的精准率,使精准率和查全率都保持在合理的区间。
燃烧率的告警模式是基于错误预算的,所谓错误预算,即系统在不产生约定后果的情况下可以出现故障的最长时间。一般以1个月为时间窗口,比如设置系统的SLO在4个9,则一个月内系统最多允许(1-0.9999)*24*30*60=4.32分钟的服务不可用。
而燃烧率的含义是相对于SLO,服务消耗错误预算的速度,等于当前错误率和期望的最大错误率的比值,其公式为 燃烧率=错误率/(1-SLO)。当燃烧率为1时,错误率等于期望错误率,表示按当前的错误率消耗错误预算,到时间窗口(如一个月)结束时,错误预算恰好为0。同理,当燃烧率为2时,错误率为期望错误率的两倍,在15天即可消耗完整月错误预算。
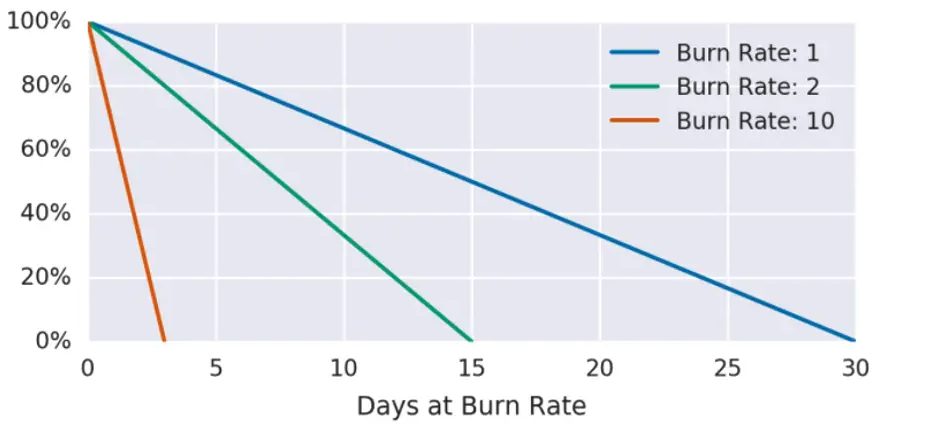
图6:燃烧率与错误预算关系
对于基于燃烧率的告警,检测用时(即发出告警所需的时间)为:
检测用时 = ((1-SLO)/error_ratio)) * 告警窗口 * 燃烧率
告警时消耗的错误预算为:
错误预算 =(燃烧率 * 告警窗口)/ 时间窗口
对于确定的SLO来说,错误预算也是确定的,因此燃烧率成为最直接反馈服务是否达标的关键指标,如下图常见的燃烧率告警阈值:
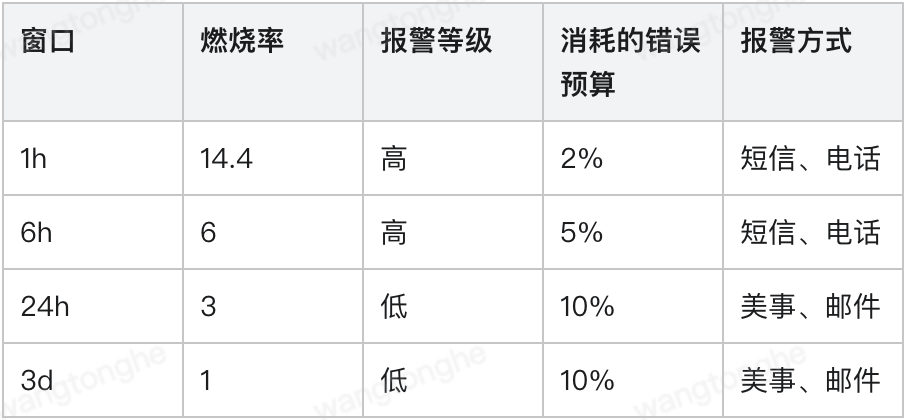
图7:常见燃烧率告警阈值
上述图表的含义为在1h内,如果消耗了2%的错误预算,即燃烧率高达14.4时会触发高危告警,其他行含义类似。在实际使用中,一般会另加一个短窗口,用于检查在触发告警时错误预算仍处于消耗中,如下图所示:
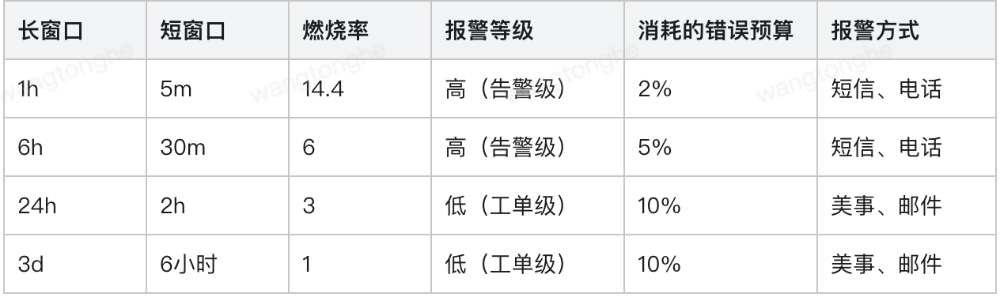
图8:常见燃烧率长短窗口告警阈值
此时触发告警的条件为:在过去1h和过去5m内,燃烧率都超过14.4后,才会发出告警。在问题解决后,告警会在5m内停下来,而不是等到1h后才停,告警表达式如下:
( error_ratio_rate1h > 14.4 and error_ratio_rate5m > 14.4 )or ( error_ratio_rate6h > 6 and error_ratio_rate30m > 6 ) or ......
燃烧率可以有效解决流量抖动导致的误报问题,然而并不能解决低流量导致的误报,试想这样一个极端场景,某业务夜间流量低至每小时10个,那么每失败一个请求就会导致10%的错误率,很容易就触发告警。
针对这种情况,业内也有几种应对方案,如模拟人工流量,让流量一直保持在一定水平,将多个服务流量合并统计等等。我们结合实际情况,根据请求量采取了两套燃烧率:
当请求量低于流量阈值时,采用更高的燃烧率,如流量阈值在100以下时,燃烧率设置200,以3个9为SLO为例,表示在1小时内,错误率高于20%才会告警。
当请求量高于流量阈值时,采用上述正常燃烧率。
另外,在上报的监控指标中,明确区分了系统内部异常和外部调用异常,可避免因外部原因导致的误报,除此之外还在客户端添加重试机制,避免偶然抖动导致的告警。
4.3 告警管理
公司内部的告警管理平台Algalon(奥尔加隆)集成了SLO指标管理、燃烧率告警配置等众多繁琐配置,支持对监控告警的全流程管理,包括接入服务管理、SLO管理、告警及后续工单处理等,如下图是流程示意图:
经上述改造后,我们的某项业务在2周的告警数量由445次降低到了3次,召回率降低了99%,同时召回量的降低使得准确率由不到1%提升到了95%以上。
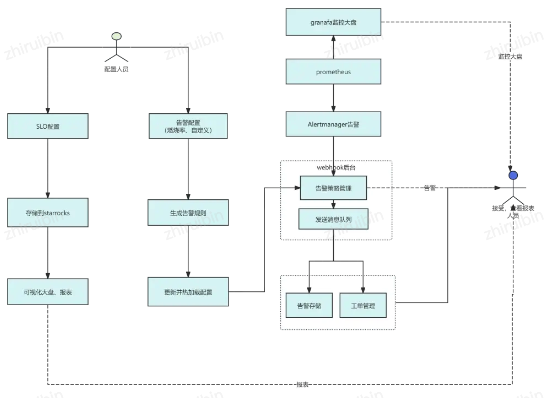
图9:公司内部告警平台流程图
05 掌控全局
一直以来,云认证缺少一目了然的业务大盘,目前的报表和大盘只会告诉我们今天的请求量是多少,认证了多少用户,过去一段时间的成功失败率等等,很难直观告诉我们今天云认证整体表现如何,近期表现如何,有无影响稳定性的因素出现这些全局性的答案。
如果说之前评估系统稳定性有不同角度的话,那在引入可观测性以及SLO之后,围绕SLO满足率和错误预算设计仪表盘则是一个简单且有效的办法。
如下是SLO满足率的报表示例:
监控主体为服务,时间单位为月(可以根据情况调整),各表格的n/m表示该服务包含的m项SLO指标该月满足n个,以下列表展示了6-8月各服务的SLO满足情况:

图10:阅读SLO满足率一览图
如下是错误预算仪表盘示例:
监控主体为各SLO指标,该表表示某指标上月及本月的错误预算消耗情况
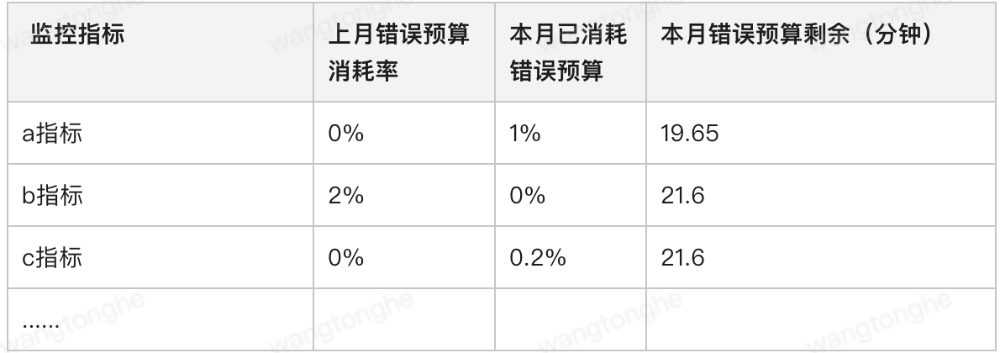
图11:各指标错误预算消耗趋势
或者具体到天的剩余错误预算趋势图:
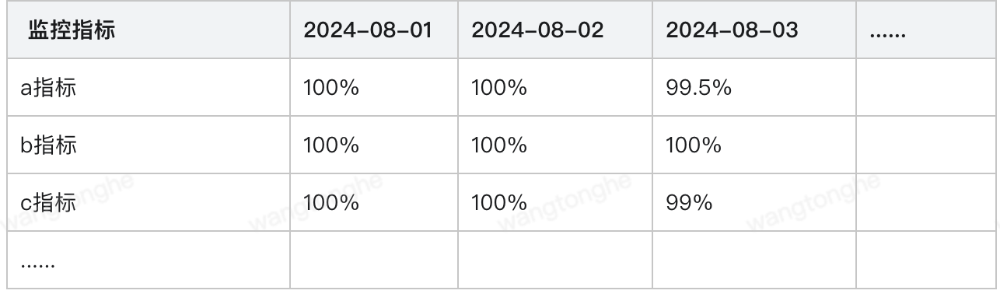
图12:各指标每日错误预算消耗
除此之外,还可以设计SLI告警数量趋势图、工单趋势图等各种维度报表大盘展现系统整体情况,这里就不一一赘述了。
06 整体总结
上面篇章以问题为导向,向大家介绍了云认证的可观测性体系建设,现在就以可观测性的角度做一个总结吧。
在日志方面,云认证规范了日志标准和埋点,并采用自研日志客户端,以ELK为日志收集展示平台,以HDFS-Hive为备份日志。
在链路方面,使用公司内部wtrace进行分布式追踪,配合日志排查问题。
在指标方面,以SLO为核心搭建告警指标,配合辅助指标快速定位问题。以错误预算、燃烧率等思想解决报警精准率问题,通过监控告警平台Algalon实现对监控指标的全流程管理。
整体的体系建设架构图如下:
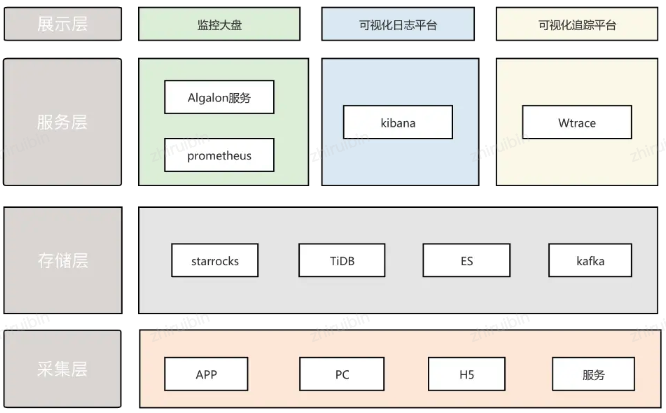
图13:云认证可观测性体系架构图
体系流程图如下:
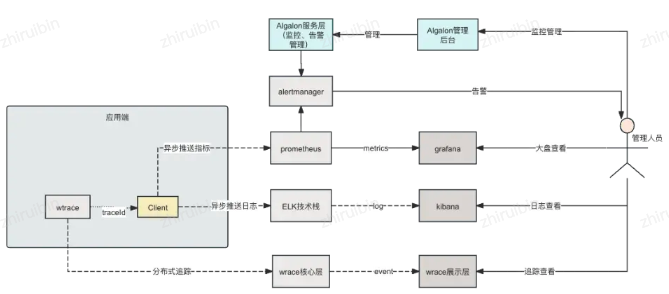
图14:云认证可观测性体系流程图
经过此次可观测性体系建设,云认证的异常感知及排障能力有了很大提升,日常case可通过日志及链路追踪进行排错。当有日常告警时,通过监控大盘即可大致定位问题。
不过,在实际使用中,仍有一些待考虑的问题,如对业务的日志收集仍有较大的侵入性,接入成本偏高,日志收集器仍有较大的优化空间,监控在低流量期间误报有所缓解,但配置流量阈值需人工调整,配置起来并不容易。
总的来说,通过对公司现有资源的整合及利用后,我们建设的可观测性体系还是取得了一定的成果,可观测性不仅是个庞大复杂的工程,也是需要长期建设的生态。对于我们,可观测性的建设也才刚刚开始。

