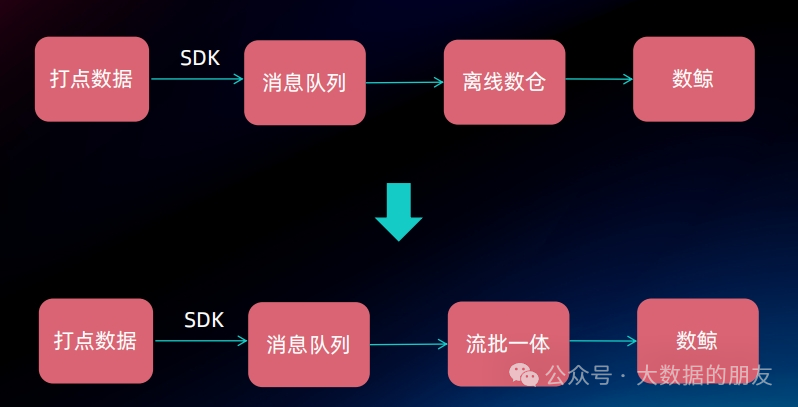
基于数据湖构建近实时数据链路
大数据处理技术,经历了基于Hadop+Hive的离线数据仓库,可以满足大部分场景的需求,数据准确性可以得到保证;但是对于秒级实时需求无法满足,基于此产生了实时处理数仓+离线数仓结合的Lambda架构,实时性和准确性得到了保证,但需要维护两套代码;利用kafka数据重放offset功能产生了Kappa架构,剥离了离线数据处理,实时性得到了保障但准确性无法得到保证;基于数据湖构建的近实时数据链路,牺牲数据实时性,一套代码保证了准确性。
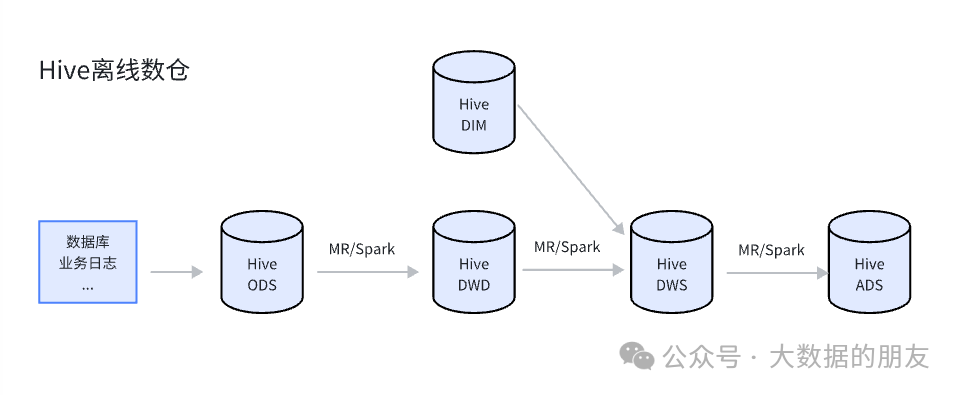
一、Hive离线数仓
传统的Hive离线数仓的优缺点:
保存全量数据;程序稳定性、可靠性高;产出结果准确性高;
T+1延迟,下游数据产出时间不稳定,时效性低;
故障重试代价比较大;
依赖调度系统构建任务依赖关系;
一般在零点出现调度高峰,峰值资源紧张,集群服务压力大;
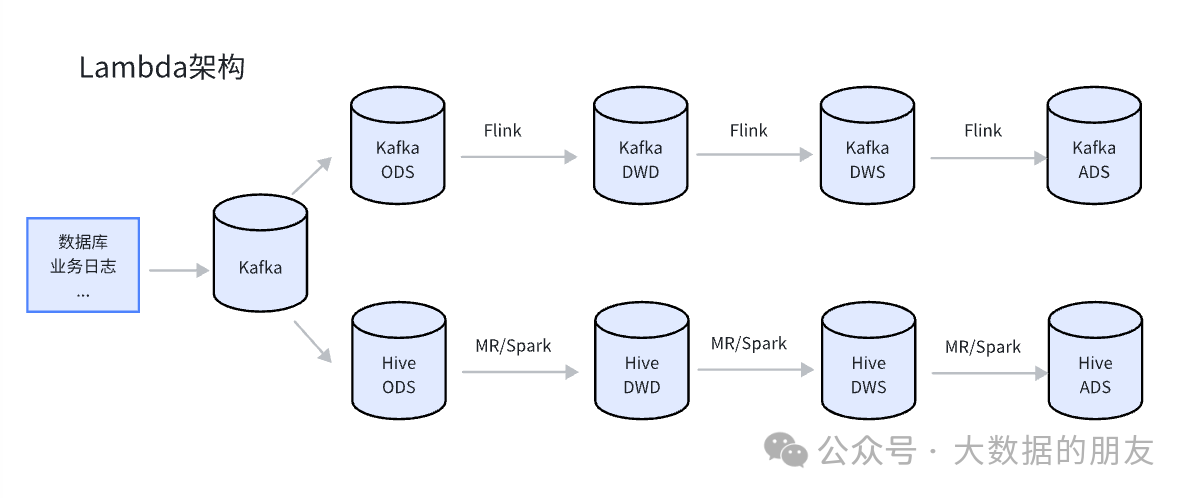
二、Lambda架构
Lambda架构的优缺点:
实时链路提供数据时效性支持;
离线链路保证数据完整性;
支持数据回溯、OLAP查询;
平台维护两套架构,运维成本高;
业务维护两套代码,开发成本高;
两条链路产出结果可能会不一致;
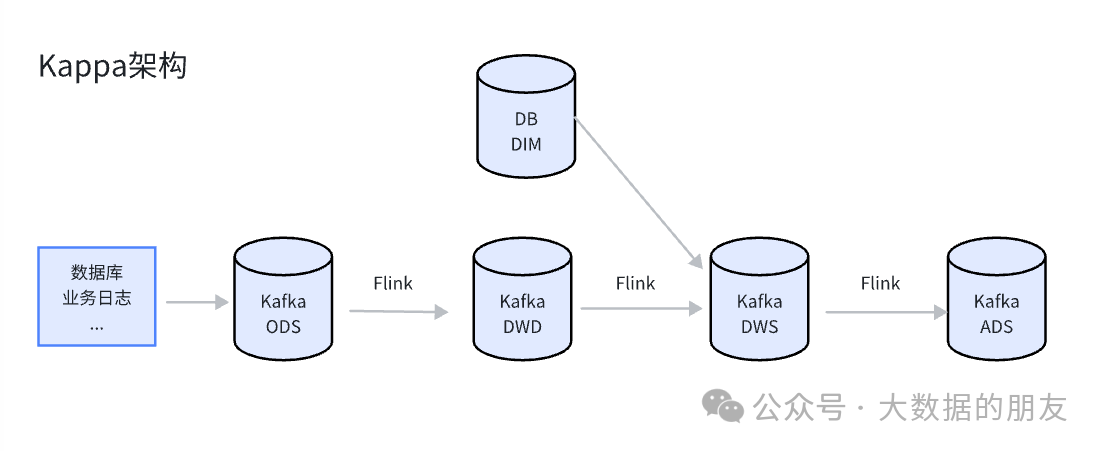
三、Kappa架构
使用不可改变的数据流作为主要的记录源;
可以重放过去的事件;
时效性高;
无法保存全量数据;
无法使用OLAP引擎直接分析;
回溯能力不如离线存储Hive;
产出结果可能不如离线计算准确;
Lambda和Kappa架构的起源可以参考: Lambda和Kappa架构的起源
四、湖仓流批一体架构
小文件合并 -> 避免对HDFS造成存储压力;
CDC(Change Data Capture)增量读取 -> 近实时处理;
计算和存储统一,架构简化,降低了开发维护成本;
兼顾延迟和正确性,同时对OLAP有较好支持;
只能做到分钟级,对于秒级时效性的数据需求,依然依赖Flink+Kafka;
对于延迟敏感的查询需求(特别是面向应用的),依然需要通过ETL导入数仓;
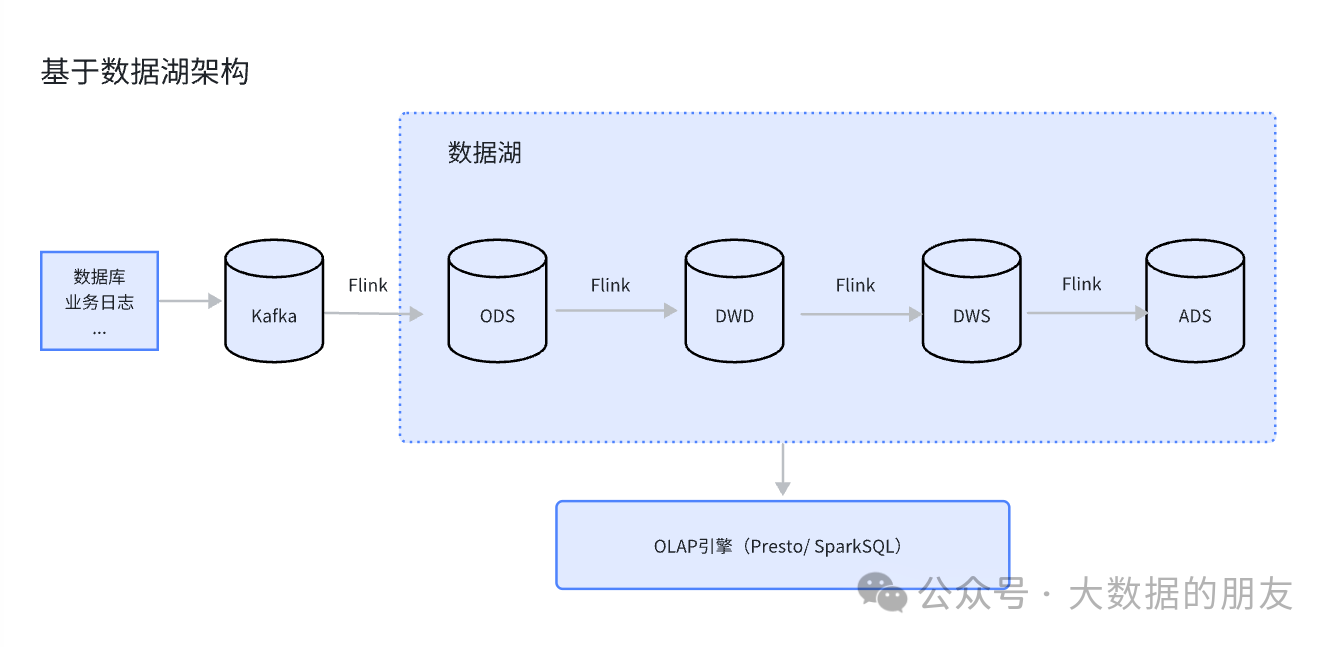
对比天级别延时,无法及时感知到运营、风控策略、A/B实验效果,整体效果其实是比较差的,将数据架构升级为数据湖链路,数据分钟级别延迟,可以快速感知实验效果并调整运营和风控策略,对整体的提效会有较好的效果,并且数据复用性强,维护成本低。

可能有人会问,数据湖相比Hive会更节省存储内存吗,我们以Iceberg为例,从存储格式、数据压缩、数据更新删除和元数据管理方面具体分析下:
数据存储格式
Iceberg:采用列式存储格式,如 Parquet 等,这种格式只读取需要的列数据,避免了不必要的数据读取,从而提高了查询性能,并且在存储上更加紧凑,节省存储空间。例如,在一个包含众多列的宽表中,若查询只涉及其中几列,Iceberg可以只读取相关列的数据,减少了I/O 和内存占用。
Hive:支持多种存储格式,包括文本格式、SequenceFile、RCFile 等,其中一些格式可能相对较为冗余。比如文本格式,数据以文本形式存储,每行记录完整,可能包含大量重复信息,占用较多空间。虽然Hive也可使用列式存储格式,但默认配置下可能不如Iceberg在存储效率上优化得好。
数据压缩
Iceberg:与高效的压缩算法紧密集成,如Snappy、Zstd等,在数据写入时可以自动对数据进行压缩,大大减少了数据的存储空间。例如,使用 Snappy压缩算法可以在不损失太多性能的前提下,将数据压缩到原来的几分之一甚至更小。
Hive:也支持数据压缩,但在配置和使用上可能相对复杂一些,需要用户手动设置相关参数才能充分发挥压缩的优势。如果用户没有进行合理配置,可能导致数据未得到有效压缩,从而占用较多存储内存。
数据更新和删除
Iceberg:支持高效的增量更新和删除操作,通过记录数据的变化而不是直接修改原始数据文件,避免了大量的数据重写,从而节省了存储空间。例如,当需要更新一条记录时,Iceberg 只会记录该记录的更新操作,而不是重新生成整个数据文件。
Hive:在进行数据更新和删除时,通常需要重写整个数据文件或者使用一些复杂的外部工具来处理,这可能导致大量的数据冗余和额外的存储开销。
元数据管理
Iceberg:拥有独立的元数据管理系统,能够更精细地跟踪数据的变化和版本信息,只存储元数据的增量部分,从而减少了元数据的存储空间占用。同时,高效的元数据管理也有助于提高查询性能,避免不必要的数据扫描。
Hive:元数据存储在关系型数据库中,如MySQL等,随着数据量的增加和操作的频繁,元数据可能会变得庞大且复杂,需要更多的存储空间来维护。
总结:从Hive离线数仓 -> Lambda架构 -> Kappa架构 -> 湖仓一体,每个数据架构解决的需求不一样,湖仓一体统一了存储和计算,节省了存储和计算成本,但是秒级实时需求还有待提升。

