抖音集团实验平台的边界拓展
随着抖音集团公司业务的持续拓展,渐趋复杂化、多元化的场景为抖音集团实验平台提出了新的挑战。在此背景下,沿用传统的假设检验框架,则已无法解决难题。
本篇聚焦实验平台主要面临的边际收益、干涉效应、自动实验配置与随机实验盲区四项挑战,详解实验平台应对挑战、拓展边界的研究进展与现阶段实践。
01 实验平台面临的问题
抖音集团的实验平台历史悠久,基本伴随公司一起成长,迄今已有十多年发展历程。目前,实验平台运转规模已经相当庞大。
从去年数据来看,平台上的日新增实验超4,000个,同时在线运行的实验超过50,000个。在数据驱动下,实验平台推动了抖音集团全公司多条业务线的孵化和高速增长。
实验平台取得巨大成功,也为抖音集团公司的成长带来了强大驱动。然而,随着公司规模的不断扩大和各种场景的日益复杂,实验平台面临着一些问题,以下选取四个方面来简单介绍:
● 边际收益:随着公司业务成长,新策略的真实平均收益逐渐收窄至边际,这对实验平台的度量灵敏度提出了更高的挑战。
● 干涉效应:实验的一大假设是参与实验的个体之间需要相互独立,从而保证自身结果只受自身策略的影响(与他人无关)。然而互联网时代人和人之间的交互越来越密切,实验中无法保障参与个体之间相互独立的情况也越来越多。这就对实验开设和分析提出了更高的要求。
● 自动配置:实验是对不同版本间的比较,然而在某些场景,选择合适的版本进行比较也非一件易事。例如,颇具声誉的字节推荐算法的迭代是一个在庞杂参数空间里不断精调的过程。鉴于实验的成本,我们无法去尝试每一种参数配置方案。那么,如何自动化地找到更加有潜力的方案进行实验就成为一个重要问题。
● 实验盲区:虽然抖音集团具有强烈的实验文化,但由于公司体量非常大,实际业务中,仍有很多场景无法或者不适合用A/B实验来解决。这就依赖于一些诸如观察因果的方法来对盲区进行填补。
下文将逐一更加详细地介绍上述四项挑战,并提出实验平台相应的一些解决思路及尝试实践。
02 挑战一:边际收益
业务发展至成熟期后,上新策略的真实效应往往较低,但这并不意味着公司不关注这些真实效应较低的新策略。
原因也很简单,成熟期业务往往拥有庞大的用户群体,即使真实效应仅为千分位或万分位,乘以数亿的基数后,也会为公司带来可观的价值收益,所以仍需想办法准确地度量它。
/ 提升灵敏度
最小侦测效应(Minimum Detectable Effect,简称MDE)刻画了实验的灵敏度,代表在给定样本量及各类错误阈值(如一类错误5%,二类错误20%)的情况下,实验能准确度量的最小真实效应。若真实效应比MDE还小,则此时发生错误的概率是不可接受的情况。
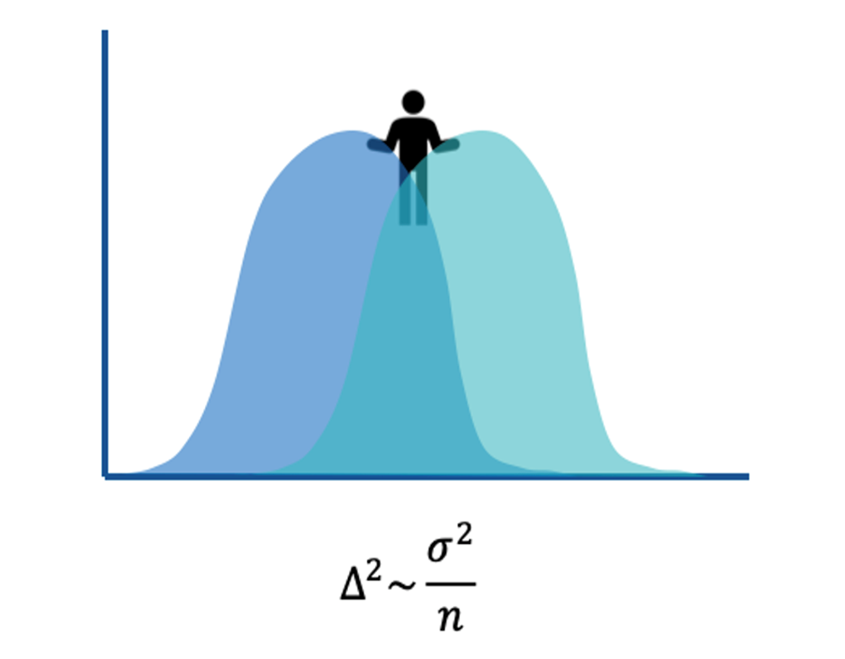
灵敏度MDE(上图中$$\Delta$$)与两个因素有关,一个是总体样本量$$n$$,处于分母位置;另一个是样本方差$$\sigma^2$$,处于分子位置。因此,要提高灵敏度,一条途径便是增大样本量。
但这个方法总会有一个上限。
以抖音为例,用户数量最多达到14 亿的全国人口总量,这就是上限。此外,增大样本量对于承载大规模数据的工程压力以及互斥域下并行实验数量都提出了新的挑战。
因此,扩大样本量绝非全能解。分母上没文章可做,那分子呢,这就涉及到下文提到的样本方差缩减。
抖音集团使用的最经典的方案是 CUPED (Controlled-experiment Using Pre-Experiment Data)。
它已经有十几年的历史,最初是由 Alex Deng 在微软时提出。其基本理论很直观,就是利用实验前数据和实验中数据的相关性,排除那些与treatment本身因果关系不大,但会影响outcome的额外方差信号,达到新构造的CUPED指标样本方差大幅缩减的目的。
然而,CUPED 也有其局限性,它假设实验前数据和实验中数据的相关性可以用简单的线性关系来描述。在实际应用中,数据的生成过程往往是复杂的,实验前数据和实验中数据的相关性并不能由简单的线性关系来刻画。
那么,如何更好地挖掘实验数据的相关性呢?抖音集团实验平台提出了一套增强版CUPED方法,即持续残差方推断方法(Inference on Temporal Residual,简称ITR)。
/ 增强版CUPED方法
对比ITR与CUPED,最大区别在于两点:
其一,ITR需要兼容各种复杂程度的因果链路。因此,推断实验前和实验中数据的相关性关系时,需要使用不同复杂程度的预测模型。
其二,不同复杂程度的模型,可能会给出截然不同的实验前数据和实验中数据相关性结果。这个时候如何取舍不同模型的结果,便是关键。这里,我们借鉴了机器学习中的常用的堆栈技术(stacking)。
ITR针对上面两点,可以大致分为两个阶段:
第一阶段,ITR会使用多种不同复杂程度的模型,包括简单的线性模型、中等复杂程度的决策树模型以及非常复杂的神经网络模型。
在不同的复杂程度下,学习原始数据下实验前后数据的相关性。我们的最终目标是对实验中的结果进行预测,为此,每个模型都生成了一个由实验前数据“预测”的实验中数据预测结果。
第二阶段,是堆栈过程。即使用第一阶段的预测结果来学习实验中数据,来优化不同模型结果在第二阶段预测中的权重。
从而有更高的概率为能够准确描述真实数据生成过程的模型增加权重,达到提升总体预测准确度的目的。
- 实践收益
以抖音集团内部的一条业务线为例,我们随机挑选10个重要指标,分别计算了CUPED和ITR方法对样本方差的缩减比例。出于数据敏感性与安全的考虑,下图所示的数据进行了一定模糊处理,但量级上的数字大小仍具有参考价值。
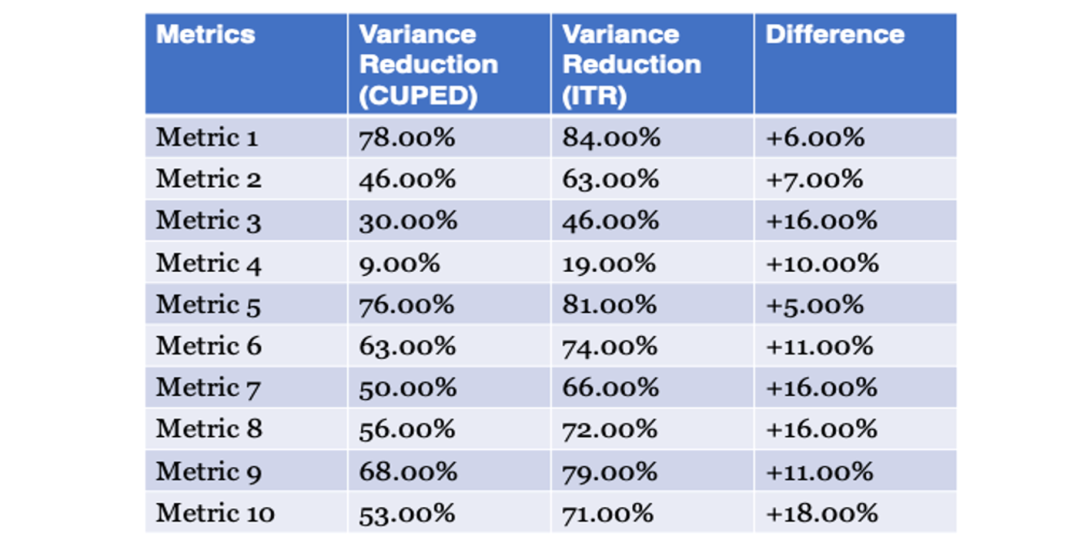
总体而言,在10个重要指标中,相较于传统的 CUPED方法,ITR 方法都有更多方差缩减和灵敏度提升收益,收益最高时可接近 20%。
换言之,在相同样本量下,它可以更准确地度量出一个比CUPED还要小20%的真实效应。这对于很多处于边际收益的业务线是非常有助益的。
03 挑战二:干涉效应
/ 人群互动
干涉效应,指在实验中由于人群互动对实验结果产生影响的因素。
例如,假设有3个群聊组,每个组有若干个用户。如果想测试一个和群聊功能相关的策略并检验该策略对用户对话数的提升效果,经典的A/B测试会按照用户粒度进行随机的策略分配。
每个群聊组中,既有进入实验组的用户(如下图黑色填色图标所示),也有进入对照组的用户(如下图未填色图标所示),他们分散在不同的群聊组中。
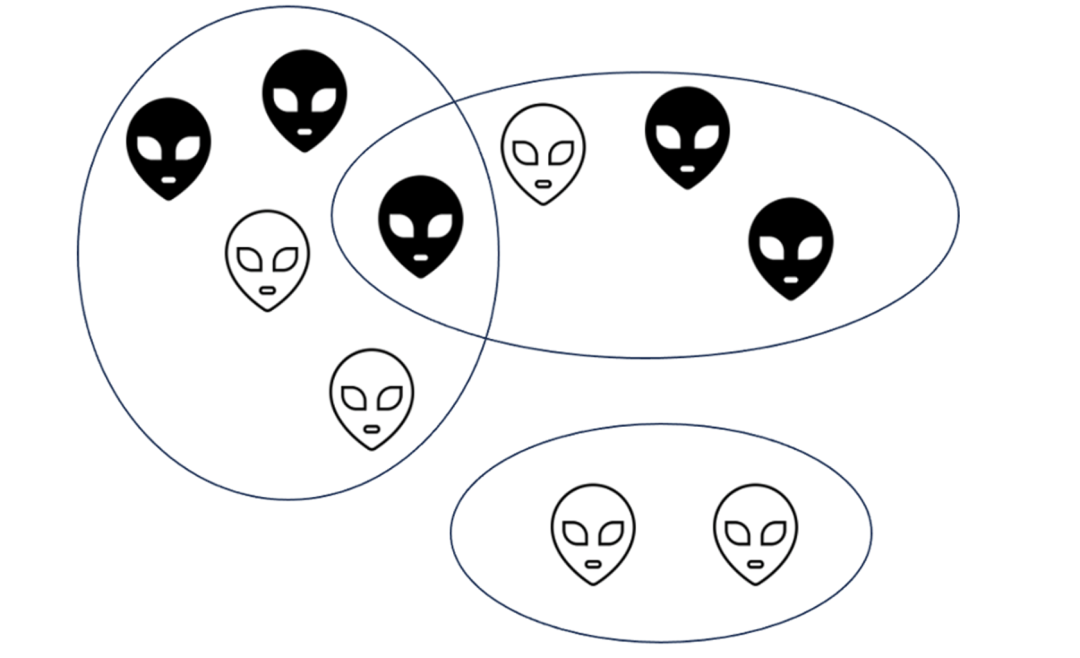
如果该测试功能能够显著提升实验组用户在群聊中的活跃程度,那么对照组用户即使没有受到测试功能的直接影响,也因为同在群聊中的其他实验组好友群聊活跃度的提升,带动了整个群聊组的活跃氛围,从而间接拉动了对照组用户的活跃度。
两组间活跃度差异被低估,策略的真实效应也被低估。这种在同一社交环境下对照组用户与实验组用户互动,导致实验组的策略溢出渗透(spill-over)到对照组的情况被称为直接干涉。
还有一类干涉,是指实验组和对照组的互动来自他们对于共有资源的竞争(如双边市场中不同买家在竞争商家提供的有限资源),而非直接接触。
这一类的干涉也被称为间接干涉。此时,真实的策略效应往往被高估。
无论是直接干涉效应,还是间接干涉效应,都源于人和人之间存在的互动。此时,单一个体的实验结果不再由该个体本身的策略状态所决定,而是同时受到其他人策略状态的影响。这是和普通AB实验最大的差别。
普通AB实验会假设结果的差异完全来自于自身策略的差异,对于单一个体而言,她/他只存在对应于0-1策略的两种潜在结果(potential outcome),我们可以通过策略的随机分配,准确地观察到这两种潜在结果;
而在干涉效应存在的情况下,她/他的潜在结果还受制于其他人的策略状态,因而会呈现出非常多的可能性,我们观察到的只会是当中很小的一部分,其间,对于未观察到的潜在结果的插值便会引入偏差。
理论证明,这种偏差可以达到与真实效应相当的量级。
解决上述问题的思路大致有两种,一是实验设计,二是统计调整。
/ 基于社交网络的聚类分流
在实验设计中,最常见、历史也相对悠久的方法便是是基于社交网络的聚类分流(cluster randomization)。
该方法的思路很简单,就是根据实验开启前一段时间内用户较为稳定的社交关系状况,将他们分割为若干个互不重叠的聚类(cluster,每个cluster相当于一个disjoint set),使得用户间的社交互动活动绝大部分处于聚类内部,而不是聚类之间。
此时,策略的随机分配的粒度是在聚类上的,而非用户个体。
在这个例子中,我们按照群聊组的关系,大致分割出了如下图所示的三个区块。左侧群组对应的聚类全上了策略,而另外两个群组对应的聚类则没上策略。
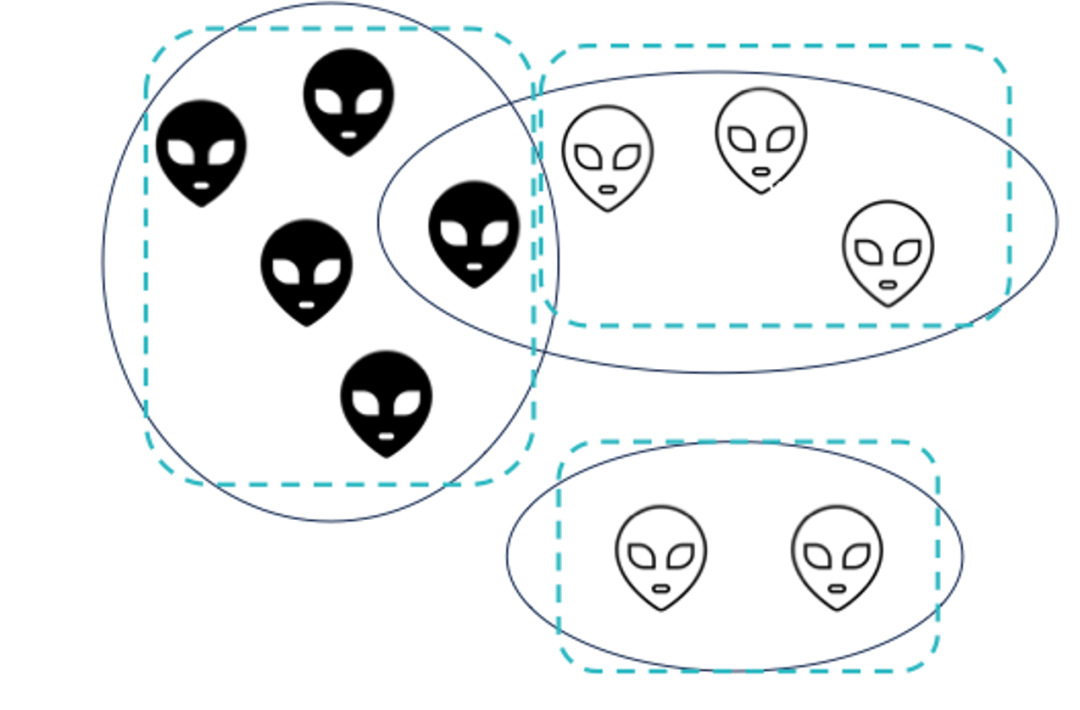
如果假设每个群聊群组,需要超过一半的用户进入实验组才能将群组中的其他对照组用户带偏到近似于实验组的状态(类似于感染contagion),那么在上面的例子中,分入对照组的两个聚类都因不满足要求而保留着对照组该有的状态,社交溢出没有发生。
此时,类似于传统AB实验,我们可以近似认为不同聚类间满足相互独立,潜在结果也只有两个,并能通过实验组-对照组分别观察到。
这个想法看似直观简单,但实际操作起来却仍存在一些难题,比如:
● 效率问题
首先,社交实验通常面对的是庞大的用户群体,即超大超复杂且较为动态的社交关系图。工程上如何准确快速拿到社群划分结果,便是很大的挑战。
● 灵敏度问题
聚类分流实验通过在聚类粒度上完成分析来实现对社交溢出的隔离,减小干涉效应带来的偏差。
但随着分析粒度从个体粗化到聚类,样本量也同时在锐减,导致实验灵敏度的巨大损失。其本质上是一种bias-variance的对冲。一个好的聚类实验的设计,在于科学地找到bias-variance之间的平衡点。
针对上述两个问题,抖音集团实验平台分别给出了一些初步解决方案。
● Parleiden
目前,抖音集团图平台提出了一套并行的Leiden算法,简称Parleiden。该算法既保留了传统Leiden算法相较于Louvian算法不产生断链的优势,同时巧妙地解决了传统Leiden算法并行化的难题。
相比于非并行化的传统Leiden算法,并行化的Parleiden快了约 10 倍,能对一个拥有约 1 亿个节点和约 300 亿条边的超大社交网络图在几个小时内完成满足隔离度要求的社区划分,有效解决了效率问题。
灵敏度方面,Parleiden也可以通过设置每个社区单元中用户数量的上限,在一定程度上保证样本量。
● CUPED
CUPED在很多场合,可以有效缓解聚类粒度分析带来的样本方差放大。实践表明,通过CUPED方法加工的社群实验指标的样本方差可以和普通AB实验的非CUPED指标保持相当的量级。
● 父子实验
父子实验实现了对一个实验同时进行个体粒度分流和社群粒度分流。
当社交溢出不是特别强的时候,干涉效应带来的偏差可能比较低,因而个体粒度分流的子实验结果和社群粒度分流的子实验结果会比较接近,这时候使用个体粒度分流的子实验作为分析对象,可以大大提升灵敏度。
● Trigger Analysis
类似于传统AB实验,使用命中活跃用户进行分析,由于用户间更高的同质性,可以有效降低样本方差。但同样也会带来复原大盘的外部有效性问题。
- 实践收益
举一个抖音社交的例子。用户可以通过私信来分享自己感兴趣的视频,有些视频会更容易触发用户的分享欲望,拉动私信功能的使用量;而有些视频则不会。
如何优化推荐系统更准确地定位这些视频,便是提升私信功能活跃度的关键。
我们在一个实验中要度量推荐系统的优化方案是否真的能提升私信活跃度时,就无法回避私信两端用户互动带来的干涉效应。
如果按照传统AB实验的个体粒度分流。那么统计私信两端的用户情况会发现,有一半的私信发生在组内(即对照组与对照组用户之间或实验组与实验组之间),还有一半的私信发生在组间(即实验组用户与对照组用户之间)。
后者会带来强烈的社交溢出,导致因果效应估计的偏差。但如果使用基于社交网络的聚类分流实验,99%的私信只会发生在组内,而组间私信会锐减到总量的1%,大大缓解了干涉效应给实验带来的风险。
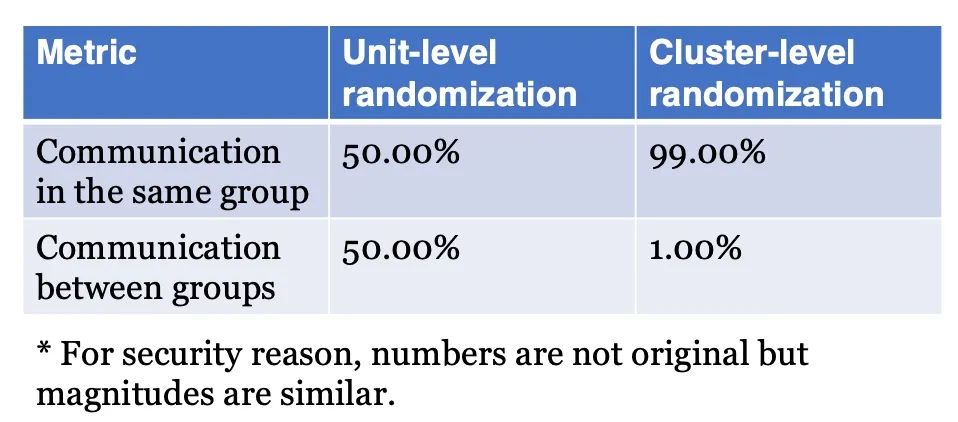
后续分析也发现,进行社群分流与不进行社群分流之间的因果效应估计存在显著差异。某些指标的差异甚至可以达到 70%,符合理论上同量级水平的预测。Meta 也做过类似的分析,结果也在40%左右。
/ 统计调整
实验设计外,解决干涉问题的第二路径便是统计调整(post experiment analysis)。
统计调整类方法纠正干涉效应偏差,但基于某些假设,统计调整方法通过构造新的统计量,来对干涉效应引入的偏差进行修正。
统计调整的具体方法有很多,这里着重介绍一下抖音集团实验平台在2023年与麻省理工大学、哥伦比亚大学和英属哥伦比亚大学合作的项目(参考链接:https://arxiv.org/abs/2305.02542)。
该方法基于马尔科夫决策过程(Markovian Decision Process,简称MDP),利用强化学习,来对干涉效应偏差进行修正,主要用于解决双边市场关系等间接干涉场景。
间接干涉场景下的核心是有限的资源位,实验组由于策略的刺激过度挤占了与对照组共享的资源位导致对照组指标水平下降因而高估真实的因果效应。
解决这类问题的关键是对供需关系的准确描述。
MDP可以很好地描述资源位在空置和被占用不同状态间的转换过程,其转移矩阵的稳态分布$$\rho$$指代了供需关系平衡条件下占据到和未占据到资源位的两种状态(state)各自的概率分布。
同时,不同状态对应了不同的指标水平(即状态下的激励 rewards $$r$$),其平均收益是各个状态下收益的期望(即$$r\rho$$)。
实验中旧策略向新策略的变化对应了供需关系的调整,无论是稳态分布$$\rho$$,还是相应激励$$r$$,都会调整到新的平衡状态,即$$\rho_0\rightarrow\rho_1$$,$$r_0\rightarrow r_1$$。
理想的反事实情况下,我们会比较所有人都上策略对比所有人都不上策略之间的平均收益差异$$\tau=r_1\rho_1-r_0\rho_0$$,即我们想得到的“真实”策略效应。

然而在传统AB实验中,我们观察到的其实是随机把一半人放入实验组,把另一半人放入对照组对应的供需平衡稳态分布$$\rho_{1/2}$$($$\rho_{1/2}\neq\rho_0\neq\rho_1$$)。
假设激励$$r$$本身不会受到供需平衡分布$$\rho$$的影响,那么,我们实际通过传统AB实验使用difference of mean统计量观察到的效应可以近似为$$\tau_{NV} = r_1\rho_{1/2}-r_0\rho_{1/2}$$。
可以证明,这个实验度量效应$$\tau_{NV}$$与真实效应$$\tau$$之间的偏差与真实效应其实是同等量级。
由上我们可以知道,干涉效应在传统AB实验中引入偏差的关键在于我们错误在用观察到的一个稳态分布$$\rho_{1/2}$$来代表实验组和对照组中本该存在的两个稳态分布$$\rho_0$$和$$\rho_1$$。
但我们同时观察到$$\rho_0$$和$$\rho_1$$是不可能的(即用户不可能同时在实验组和对照组里)。
既然不好在稳态分布$$\rho$$上做文章,那我们把焦点放在同样贡献因果效应估计的激励$$r$$上。
我们通过将即时激励$$r$$替换为其接下来的累积期望$$Q$$(也就是强化学习里的行为价值函数),便可以在不改变稳态分布的情况下,对激励的部分进行调整,从而达到修正平均收益估计的目的。
这种方法被称为Difference in Q 估计量(简称DQ)。理论可以证明,采用DQ估计量,相当于对真实效应$$\tau$$进行了二阶泰勒展开,因此偏差在二阶程度上得到了控制。
- 实践收益
以抖音为例,假定用户观看视频的时间限制于手机电量。在抖音推送的视频中,用户被随机推送观看高清或标清视频。高清视频会提高用户单个视频的观看时长,但耗电速率却更快,总观看时长甚至会下降。
反之,观看标清视频时,单个视频的滞留意愿会下降,但电池电量的损耗可能会小一些,有概率看到更多的视频。我们希望度量推送高清视频对用户观看时长的影响。
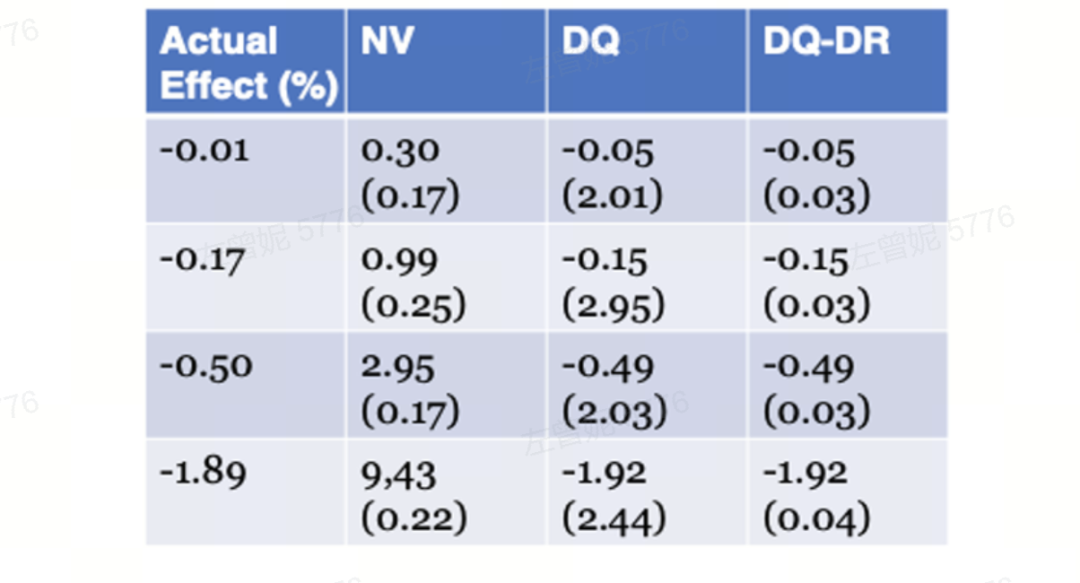
基于这个简单的模型进行仿真模拟。结果显示,传统AB实验下Naive Estimator $$\tau_{NV}$$会严重高估仿真时预设的真实策略策略效应。
例如,当真实效应为高清视频反而会拉低用户观看时长0.5%时,$$\tau_{NV}$$则估计会提升2.95%。
使用DQ统计量则预估效应为下降-0.49%,高度还原了真实效应。如果再配合上一些降方差的双稳健手段(DQ-Doubly Robust,简称DQ-DR),我们可以进一步大幅缩减预估时的方差,加大结论显著置信的几率。
04 挑战三:自动实验配置
/ 选择困难
以推荐系统场景为例,一套推荐系统里有非常多的超参数。
为了优化推荐系统,很多参数需要在连续的维度上进行调整,故而会存在非常多的备选策略,就像站在十字路口,不知哪条道路通向想要的优化方案。一个一个尝试实在效率太低,甚至无法实现。
这种情况下,基于贝叶斯框架的黑盒搜参便是提高搜索效率的重要手段。
/ 贝叶斯黑盒调参
贝叶斯优化的过程主要分为三个阶段。
1. 首先是观测系统(observation)。
我们输入一个测试策略$$X$$,然后观察相应优化目标的结果$$y$$。$$X$$和$$y$$之间的映射关系可以描述为$$y=f(X)$$,但映射关系$$f$$的全貌我们是不知道的(黑盒),我们只能通过观测系统看到有限的几组$$X$$-$$y$$映射。
而我们的终极目标其实是通过贝叶斯黑盒调参找到合适的$$X$$来优化$$y$$的表现,如找到$$\max(y)$$或$$\min(y)$$对应的$$X$$。
2. 其次是替代模型(surrogate model)。
在完成几组$$X$$-$$y$$映射观察之后,我们下一步就是去猜$$f$$。我们虽然不知道真实的$$f$$,但可以通过替代模型来近似背后的数据生成过程。
在贝叶斯框架内,结合先验分布,以及观察对应的“likelihood function”,我们可以迭代出后验分布(Posterior),即在现有观测基础上,$$f$$在任意节点$$x$$对应$$y$$的概率分布。业界常用的替代模型是高斯过程(Gaussian Process)。
3. 最终是收益函数(acquisition function)。
在得到后验分布之后,我们其实是通过观测迭代了$$f$$的认知,下一步则是需要根据这个新的认知来选择下一个需要尝试的节点$$X$$。然而,每个节点此时对应的是一个后验分布,不利于便捷决策。
此时,我们就需要依赖收益函数,将每个节点上的后验分布总结为一个预期收益值,如常用的收益函数Expected Improvement (EI),方便我们快速找到下一个尝试的节点$$X$$。
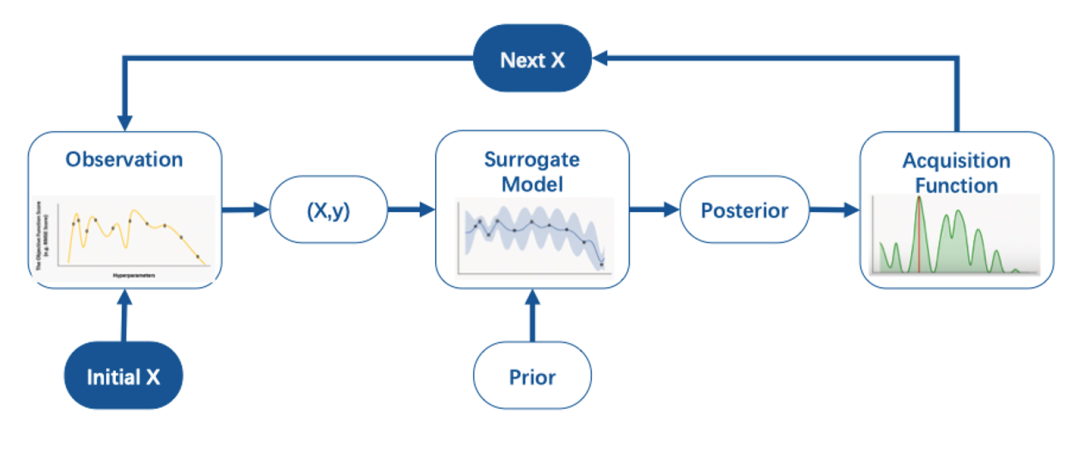
这就形成了一个闭环。
通过不断的迭代,虽然道路可能曲折,但在一定轮数内,通常会得到一个相较初始更好的结果$$y$$以及与之对应的策略$$X$$。
大量实践表明,贝叶斯优化往往能大大提高在复杂参数空间内定位优化方案的效率。
虽然强大,但贝叶斯优化也存在着一些现实问题。最常见的便是冷启动问题,它是指通常情况下初始策略$$X$$是随机生成的。
然而,对于某些任务,比如通过调整配置参数优化Spark任务的内存消耗,如果配置参数完全是随机的,则容易导致 Spark 任务失败。这是非常危险的,不能完全随机。
为此,抖音集团实验平台与北大合作,提出利用迁移学习,来大幅减少贝叶斯优化中可能会遇到的劣化策略问题。(详情可参考:https://arxiv.org/abs/2302.04046。)
/ 迁移学习
以Spark任务内存优化为例,迁移学习的借鉴对象有两类。一类是“专家经验”,另一类是“历史成功案例”。
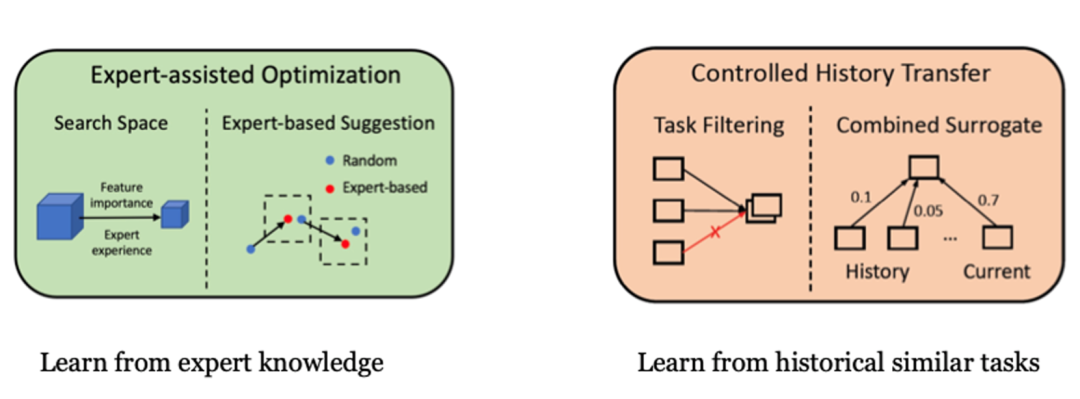
专家经验的迁移学习,我们采用了“专家规则树”。
其本质上是把例如“怎样的Spark任务要配置怎样的任务参数”这类专家知识总结为决策树(Decision Tree)的形式。
例如在冷启动时,原本初始参数配置是一个完全随机的点(左侧图中的蓝点),我们会按照Spark任务的一些基本情况,根据“专家规则树”来调整到更安全的配置(左侧图的红点)。
而历史成功案例的迁移学习,其关键在于如何找到相似的历史任务。
这里我们会引入一个“similarity”的指标,来衡量任务之间的相似度。
一旦发现相似度超过某个阈值,我们会将历史相似任务的配置参数融合进贝叶斯搜参的结果当中,使得新调制的参数配置与之前相近任务的配置参数更加接近。
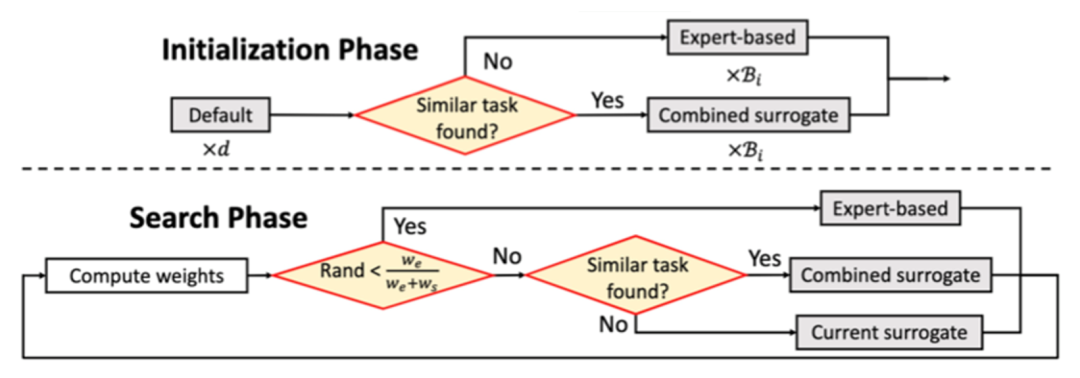
上图展示了迁移学习在冷启动和后续搜参时的具体应用方式。
冷启动阶段,我们会先搜寻有没有相似历史任务。有的话,会和完全随机的方案进行融合;没有的话,会使用“专家规则树”,来调整初始参数配置方案。
而在后续搜参阶段,我们会根据一定方式分别计算“专家规则树”和“贝叶斯黑盒优化”的潜在权重,并原则上保障随着迭代轮数的增加,“专家规则树”的权重$$w_e$$逐渐下降,“贝叶斯黑盒优化”的权重$$w_s$$逐渐上升(我们越来越相信后者能给出更优方案)。
两者的权重比在概率上决定了我们是借鉴“专家规则树”产生下一轮参数配置,还是更倚重“贝叶斯黑盒优化”的结果。
需要注意的是,后者如果存在相似历史任务,也会借鉴过往参数配置进行融合。
- 实践收益
截至2023年末,大约执行了 12,000 个任务,总体内存收益率约为 50%,非常可观。其中,76.2%的任务的内存收益率超过了 60%。目前,调参覆盖的Spark任务规模还在不断扩大,远超出 12,000 个任务。
05 挑战四:随机试验的盲区
并不是所有场景都适合开展随机实验。
例如,随机实验在理论上需要保障策略的分发是随机的,但当对照组用户发现自己没有被分发到新策略并享受新策略可能会给自己带来的潜在收益时,就有可能会引发对照组用户对于服务公平性的不满与投诉。
因此,在当法律、道德、公平性以及强制性等方面无法完全满足时,随机实验只好黯然退出。
此时,基于观察数据的因果推断(observational causal inference)就成为了一个非常好的替代方案。
/ 观察因果推断
对比传统 A/B 实验和观察因果推断,会发现以下不同。
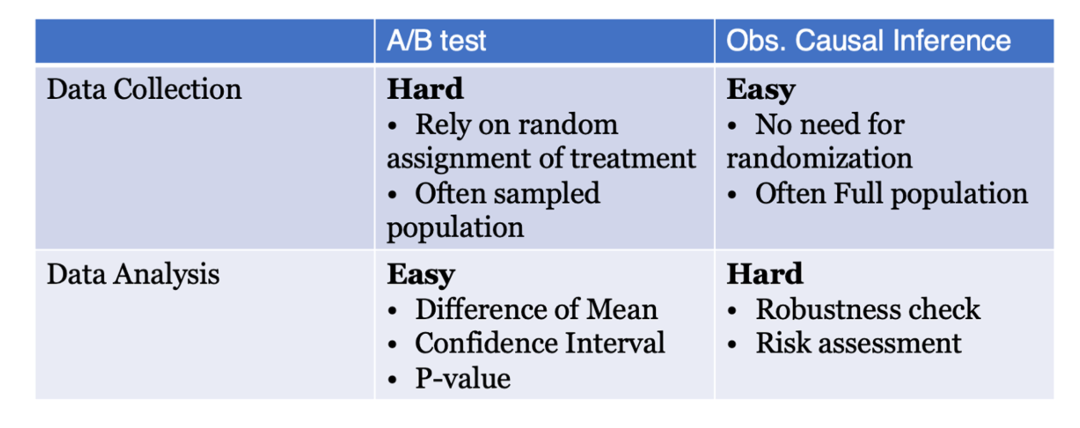
传统A/B实验的数据采集过程相对困难,因为它需要进行随机分流,以及完善的大数据基础设施和配套,前期要投入大量成本。
而且,基于成本考量,A/B实验通常只会获取采样数据。基于采样数据结论的外部有效性(external validity)则可能无法得到保障。
相比之下,观察因果推断的数据收集则容易很多,成本也较低,只需实施策略,并观察一段时间即可。此外,观察因果推断的另一个优势是其通常为全量数据,无需进行采样,外部有效性的问题大减。
然而在分析层面,A/B实验与观察因果推断的难易程度却截然反转。
A/B实验的分析相对简单,解读的成本也较低。通过一些简单的统计方法,如Difference in Means、置信区间和 p 值,这些方法都是相对直观且容易沟通的。更重要的是,A/B实验的结论至少在采样范围内是准确的金标准。
相反,观察因果推断后期的分析受限于很多可能无法被证实的假设,因此结论稳健性以及连带的风险评估大大增加了沟通成本。这一块也成了抖音集团实验平台推出自己观察因果推断产品的发力点。
/ 稳健性分析
以经典的“倾向分匹配”算法(Propensity Score Matching)为例,该算法需要从多维度进行稳健性的判断,诸如匹配质量,模型稳健,未观测混杂以及合理控制。
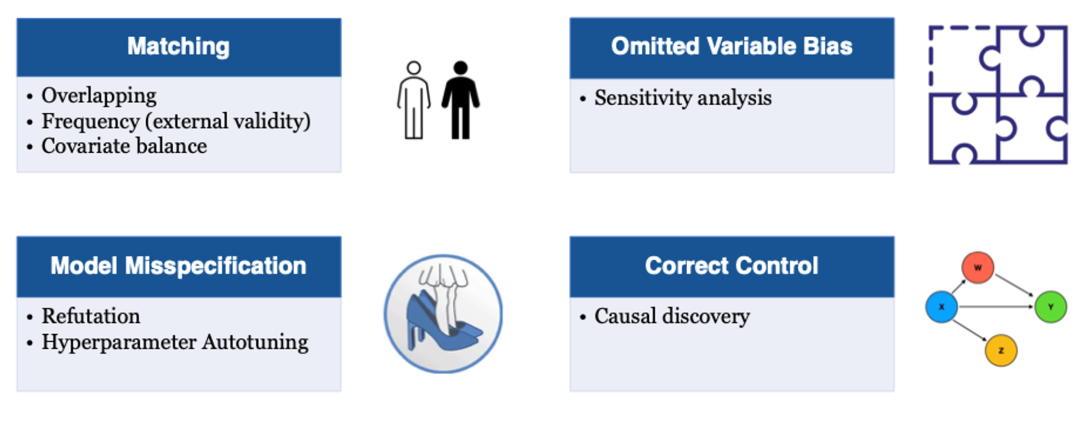
● 匹配质量方面,我们会查看匹配前实验/对照两组倾向分分布的共同支撑集。只有共同支撑集足够大,才能保障优质反事实配对的比例。
同时,我们会校验被匹配频率。如果大量实验组个体都匹配上了同一个对照组个体,那么说明该对照组个体有嫌疑被过度代表。最终,我们会考察匹配后的平衡性问题,检验匹配后的实验组-对照组在观察到的控制变量维度上是否足够相似。
● 模型稳健方面,由于倾向分匹配高度依赖倾向分预估模型的准确性,我们需要对于倾向分模型的稳健程度做评估。
抖音集团实验平台下的因果推断平台,采用反驳式检验的方式,给予原始数据一些预设的扰动,来查看当前倾向分模型是否会受到比较大的干扰。
如果出现较大波动,如我们把原分析安排在一个数据子集上进行时发现新估计和原估计差异显著,则暗示倾向分预估模型可能存在过拟合的现象。
此时,借助于实验平台的离线贝叶斯调参能力,我们能为倾向分预估模型找到更为合理的超参数配置,缓解过拟合的风险。
● 未观测混杂方面,牵涉到倾向分匹配这类方法的一个基本假设:在我们的观察体系中,所有可能导致偏差的混杂变量都已被考虑。
然而现实中,我们不可能观察到所有变量,这些未被观察的变量中存在混杂变量的概率是极高的,因此存在偏差基本上不可避免。但我们依然想了解偏差的程度。
此时,我们可以采用敏感性分析方法,通过不断引入更重要的“假想”未观测混杂变量,衡量它们对评估结果的影响程度。
当超过一定阈值时,我们依据业务理解来评估这样强度的混杂变量是否真实存在来反向推论我们是否有效地控制了混杂变量。
● 合理控制方面,倾向分匹配这类方法成功的关键是在于有效地控制住了能引入额外偏差的混杂变量,但不是所有观察到的变量都是混杂变量。
尤其是当这些观察到的协变量和策略同期时,我们可能无法确定到底是这些协变量影响了策略,还是策略影响了协变量,从而无法判断它们具体是混杂变量,还是其它类型的变量(如对撞、中介变量)。
错误地控制这些非混杂变量,可能会适得其反,为因果效应估计引入更多的偏差。
为了帮助解决这个问题,抖音集团实验平台引入了“因果发现”算法,来辅助用户判断不同观察变量之间的因果结构,从而判断这些变量当中哪些是需要控制的混杂变量,而哪些是不需要控制的非混杂变量。
- 风险评估
由于观察因果推断在分析层面的复杂性,风险评估不能只依赖一些具备标准的自动化检测,也依赖业务经验的输入,包括许多相对主观的评估。
为了将风险降到最低,我们需要从端到端回顾一遍整个因果推断流程的细节,讨论可能存在的雷区,如问题的定义是否清晰,数据采集是否存在问题,是否需要避开重大活动项目、是否需要保持稳态等。
我们还需要评估因果推断结果是否符合预期,协变量选择是否正确以及稳健性水平如何。
如前所述,整个风险评估流程可以融入一些自动化检验,但最终仍然需要人为参与。我们产品化风险评估的思路主要在于:如何进一步降低人为参与的成本。
我们的目标是将整个分析流程工具化,以快速、便捷的方式提交给用户,从而帮助用户减少整理思路的过程。
- 实践收益:中小型商业的乐土
抖音集团实验平台的观察因果推断模块从0组建到如今大概1年多时间,运行了大概4,000多个任务,覆盖了50多条内部业务线。
我们发现,因果推断的重要发力点是在于中小业务。
当业务脱离高速成长期,新阶段的策略真实收益相对较弱,但业务用户基数还没成长到能够为这些边际真实收益在随机实验中提供足够的统计功效,实验结果很可能不显著。
此时,因果推断是一个很好的替代方案。在实践中,约 70%的案例与中小型业务相关,包括游戏、本地生活、电商以及一些互娱体验等。

