用增结算数仓化改造:在/离线调度系统的构建与应用
导读
移动运营推广平台(OPS)承载着百度内部移动应用/移动搜索业务的用户增长预算的全流程结算线上化管控功能,为了解决用增业务发展规模扩大、原有技术架构老旧、无离线数仓系统等一系列的问题,针对全域结算数据启动了整体的架构改造。为了解决业务中存在的问题,本文深入探讨并提出了一类在线、离线结合的任务调度解决方案,完成了结算业务架构更新换代,更好地服务于业务发展。
01 背景简述
1.1 业务/技术背景
移动运营推广平台(OPS)承载着百度内部的移动应用/移动搜索业务的用户增长预算的全流程结算线上化管控功能(包括合作方-渠道信息注册管理、内/外部结算数据接入/展示、预提单/账单计算-审批-结算确认支付等一系列主要流程),已为移动搜索分成、用增推广等业务线提供了十余年的服务。
随着用增业务发展与线上化管控规模的扩大,业务结算量级、结算数据量与审批单量提升,原有数据层技术架构老旧,逐渐承载不住日益增长的结算时效性、准确性要求,导致结算出账数据异常/产出失败,造成实际业务损失。
平台历史上的结算指标、账单数据均通过PHP/Java脚本计算,通过MySQL数据库对储存中间数据与结果数据,无离线数仓,存在易篡改、无留痕等数据审计风险。因此针对用增结算全域结算数据立项,启动了离线任务的数仓化改造。为了解决在线业务与离线结算计算间天然不兼容的问题,综合考虑用增结算运营的灵活性和结算数据计算的准确性,我们提出了一类在线与离线结合的任务调度解决方案,目前已承载了线上亿级别月度结算账单的计算、出账、按时产出和更新。
1.2 名词解释
TDS:Turing Data Studio 是基于图灵(百度内部数据分析平台)的数据建设解决方案,提供 数据开发、数仓管理、监控运维、资源管理等一站式服务的数据开发平台。
BigPipe(现DataHub):百度内部维护的分布式消息系统,可通过Topic或Queue方式使用。
02 技术方案设计
2.1 业务特点分析
用增结算相较于其他业务离线数仓的特点是:业务受外部影响较大,操作和策略的制定较为灵活;业务侧的变更需要及时同步到数据层计算/重算,同时需要保证计算流程的准确合规。经常存在依赖数据的小范围更新case(如个别渠道作弊判定、某个合作方合同信息的修改、出账方案调整等),因此开发的任务都拥有较强的灵活性,相关离线脚本也都支持对单条/指定范围的数据进行计算/更新重算。

原来的离线脚本模块经过长时间的迭代发展,存在以下问题:
数据计算/更新时无法感知非预期的变更。合同更新、反作弊处理等流程作为成熟的业务流程拥有较完善的实时/定时处理机制(针对上游业务数据变更更新对应的下游报表、账单数据),但面对非架构原生、后续迭代新增的功能,只能通过运营/产品侧通过范围标记(指定合作方/结算类型等)手动发起相应的重算,在此过程中可能存在信息丢失/误操作等情况,导致全局上下游不一致;
数据领域划分模糊,存在同一字段由多个线上模块/脚本负责更新的情况,在逻辑冲突时存在潜在的幂等性问题;
脚本服务语言架构旧(PHP+Shell脚本),无可视化界面和运维手段,存在比较严重的单机热点问题/BigPipe API稳定性问题,影响账单计算的准确性/时效性。
为了克服旧架构的缺点,同时保留其灵活响应运营动作的优点,需要对数仓化改造方案以及平台间的衔接控制进行充分设计。
2.2 平台数仓化架构设计和改造思路
架构改造应基于业务特点与合适的设计进行,那么该如何改进现架构,保证功能不损失还有新收益?
由于PHP在我厂早期普遍用于快速开发平台与脚本,因此逻辑在平台与脚本上耦合度很高。平台业务,定时调度,甚至脚本自身都可以调起脚本进程,且平台和离线脚本均直接对线上库进行读写操作。这种架构灵活性很高、有利于功能快速迭代,但两侧逻辑一旦产生差异,就会丢失数据的一致性;相关的中间件也没有统一的状态查询管理界面,消息的堵塞和丢失都会导致问题溯源十分困难。
同时,我们观察到目前的数据逻辑中,很大一部分代码被用于判断状态流转(当前单据/合同是否应被重算),但这部分逻辑对于金额计算是完全无关的,而且对应的查询花销在整个计算过程中的耗时也达到30%以上,存在优化的空间。
为了解决当前逻辑耦合、冗余的问题,我们决定在启动改造时将平台与数仓的逻辑分离:平台专注于业务数据录入和状态流转,数仓专注于结算数据计算如具体的指标和结算金额。把账单计算逻辑沉淀到离线侧,避免计算/修改逻辑分离产生的数据不一致风险,利用数仓层的数据版本控制和血缘追溯等能力,确保结算数据的准确性、一致性和可追溯性,同时将数据任务统一接入TDS等成熟的数据任务管理平台,简化了分散在多个平台上的数据管理和运维工作。
具体的逻辑拆分思路如下:
首先将依赖离线任务产出的数据报表进行字段级领域划分,确认两方职责:数仓层负责产出结算支付相关字段,平台层负责对外展现,同时负责在审批、业务流程中更新状态类字段。
收拢调度入口,例行类和事件触发类调度的底层由分别发送异构BigPipe消息启动改为统一记录业务操作记录,由专门的调度体系统一发起调度。
对当前触发离线计算的事件进行逻辑归因:
业务操作(平台自身的数据变更、数据任务触发的业务变更)驱动的数据变更,计算/重算任务应当由平台主动发起,均通过专门的调度体系统一调度。
外部数据源驱动的数据变更,计算/重算任务应当由数仓主动发起,通过TDS的调度回溯功能进行统一管理。

2.3 在/离线调度系统
在上述思路的基础上,我们设计与实现了一个专门的调度系统来统筹管理离线计算任务:该系统同时兼顾业务上下游依赖关系和数据上下游血缘关系,对计算任务进行有序的调度管理。
对于结算类数据,在数据时效性(操作命令及时产出对应的结算数据)和一致性之间,一致性更重要(每次计算均需要保证结算数据的全量准确性),时效性相对而言是可牺牲的(产出晚好过产出错误的结算账单)。在此假设下,需要设计构建一个能保证结算数据准确性,同时时效性相对不差(发起变更1小时内可完成计算)的结算类任务调度系统。
整体设计
调度系统的整体架构和流程见下图:
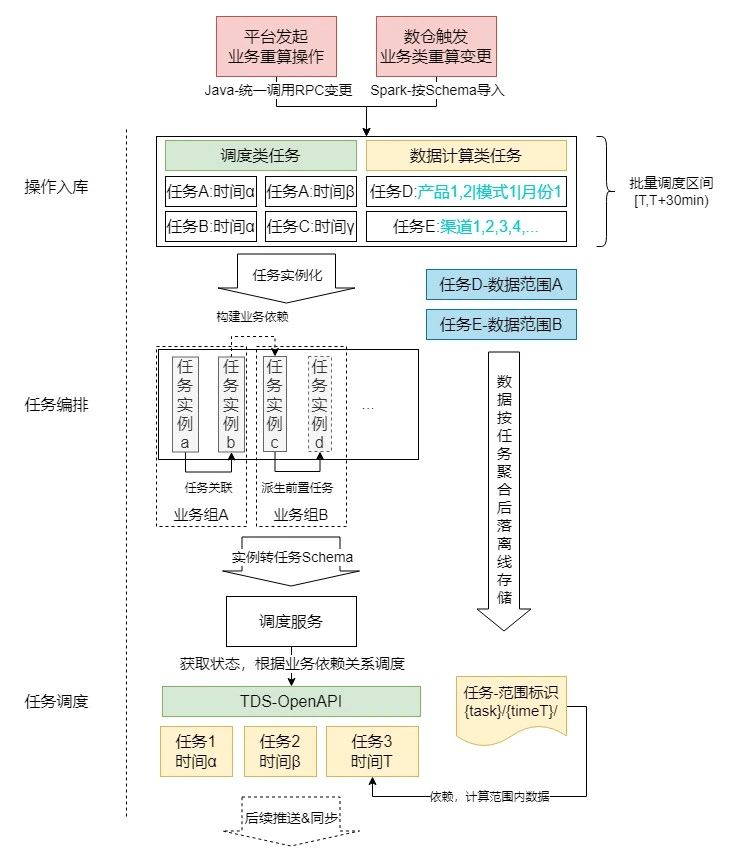
通过以上3个步骤,完成业务层与离线计算层间的交互:
1.操作入库:向操作MySQL表中写入待执行任务如反作弊报表重算、账单重算等;因操作基本按月/日维度执行,绝大部分操作类型的操作数不超过100次/月,故暂不引入缓存等中间件,减少系统复杂度。
2.任务编排:通过批处理的方式,将入库操作中写入的操作进行分析后进行聚合/关联/派生等操作,生成一批待执行任务实例(保存为数据库记录);对于数据结算类任务,还会处理成与任务和批次对应的离线文件,供计算任务调用获取实际需要计算的数据范围。
3.任务调度:将上一步中编排好执行关系的任务实例转为TDS任务Schema后,调用TDS-OpenAPI,在TDS上触发对应的调度,并将对应的任务状态回写到平台侧。可以通过平台进行任务状态的监控和控制。
TDS任务执行完成例行任务/重算任务后,将待更新数据通过算子推送到平台在线库;具体推送的数据取决于不同离线任务的导入配置和业务需求,但每个任务都会将更新写回到数仓,保证数仓中的数据是最新、最准确的版本。
例1:调用例行的数据拉取重算,将每日结算数据重新拉起计算,并同步到在线库中供平台查询;
例2:调用反作弊重算任务,调起对应的任务后,更新数仓结果,并将新老结果中diff部分(更新的数据)同步到在线库中。
操作入库
针对改造前任务启动方式各自成体系、编程语言混杂、难以进行统计和迭代改造的情况,本次改造过程中将任务启动统一优化为两种固定方式:
Java平台侧:通过统一的RPC调用记录操作至数据表。对平台而言,有且仅有该入口用于操作的入库,方便后续的任务审计、切面管理、功能统一迭代升级;
Spark数仓离线侧:通过固定的数据Schema导入至操作表。该类直接写入的操作源于历史任务中存在的离线任务中通过BigPipe消息触发调用下游任务,为简化逻辑重构成本保留已有特性。后续将不再新增此类入库方式,并计划随迭代逐步下线、收拢至平台侧。
任务编排
编排组件周期运行,针对一批待执行的业务操作进行聚合/任务实例化/任务依赖管理,并生成一个全局随时间递增的批次号。主要操作如下:
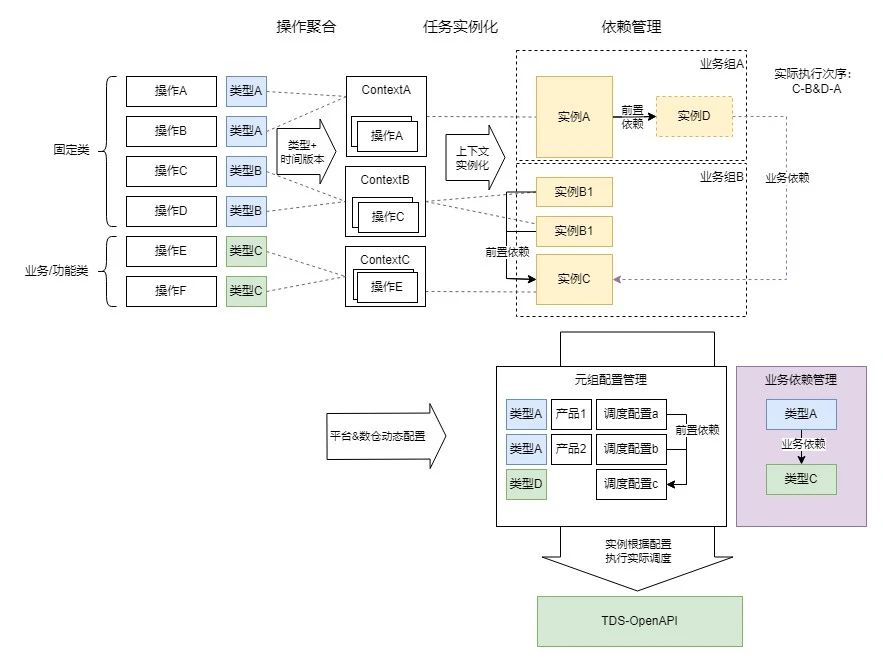
操作聚合
基于发起的业务变更操作进行分析,根据需要操作的数据时间和对应的任务集合(如需要修改x月y日的某业务某类型数据)进行聚合分组;这样做的原因是TDS平台的任务组调度均为基于时间序列的调度,将操作按照任务元(从任务类型映射)-任务执行时间(根据周期类型(月/日/实时)与数据时间转换)分组后,合并/分配到同一个或一组类似的数据任务实例,可以最小化调度资源与执行资源的使用。
任务实例化
操作聚合到任务类型-任务时间后,根据对应的任务上下文(TaskContext)和相应的配置构造需要启动的1~n个任务实例。任务上下文有如下定义:
数据范围:用于确定需要计算的范围条件(如指定某条/批账单、某个日期、某个业务类型等)。
任务类型:包含固定类型、业务/功能类型
固定类型主要用于固定的任务,大部分不需要参考数据范围,如某个表数据的全量同步;同类型下每个任务上下文代表一个独立的任务或功能步骤。
业务/功能类型主要用于需要控制数据范围执行的任务,如某产品线-某数据版本-某个周期的激活数据拉取;同类型下每个任务上下文代表相同功能下不同的数据范围,可精确控制计算维度。
任务元组:用于对接任务调度平台(接口定义,对于TDS包括数据任务组、起始算子、全流程算子),如任务启动和获取任务实例状态,可通过配置MySQL表实现动态热加载。
依赖管理
实际操作中一批数据任务的执行可能是存在先后逻辑关联,不能同时启动的,因此需要组织合理的调度次序保证准确性。为了保证该次序是最优、最简化和容易理解的,我们引入了以下设定:
前置依赖(隐式依赖)关系:发起业务变更时平台侧不关心对应的底层数据逻辑,但隐藏数据逻辑是需要在实际调度中表现的(比如:数据重算发起时,可能需要提前发起一个线上数据同步任务/上游数据拉取任务。任务上游可能因为逻辑、架构迭代而变更,但平台侧并不关心其调整)。任务计划中可能存在业务侧不关心但必须执行的前置任务,此时需要根据依赖关系,自动构建和生成对应的任务实例;若对应的任务实例已存在,则直接进行前置关联。通过该步骤,可以构建出一组相互间无依赖关系的任务依赖树(为避免引入过多依赖管理的逻辑,不允许多依赖,但允许有多下游),将单独的一棵树称为业务组(该业务组执行完成时表明业务对应的数据任务执行完成,前后数据一致且可信)
业务依赖(显式依赖)关系:针对某些业务组间存在前后序关联的情况(如A业务依赖B业务数据,恰巧在同一批次内A、B业务都有操作发起),需要保证执行次序,避免产生后序业务先行计算导致的计算结果错误、异常等情况。
如何建立业务组间串行执行的关系?对于系统而言调度的单位是实例,不存在业务组这样一个动态的实体,因此我们通过上下文映射实例对应的任务类型,通过类型间业务依赖关系配置(从业务动作的角度进行关联),建立任务实例间的树状依赖,进而控制业务组间的执行次序,组成整体的运行拓扑。
为了分离数仓血缘治理问题,保证在/离线调度的业务导向,在编排中不支持多上游依赖,实际存在的多上游依赖通过上下文中的任务元组进行配置,将多个任务抽象集中到单个调度实例中。在这个设计基础上,引入了动态依赖(根据时间版本-数据范围匹配,建立业务功能类任务间的依赖)、依赖链与依赖继承(A-B-C依赖链上业务实例不全时(如仅存在A、C)根据优先级建立实际业务依赖(A-C))等设定,更好地服务于业务逻辑与数据逻辑的衔接。
通过以上三个步骤,我们将业务侧发起的业务请求转换、构建为同批次下的一系列需要执行的数据任务实例以及方便依次处理的执行次序,并交付由调度平台执行。
任务调度
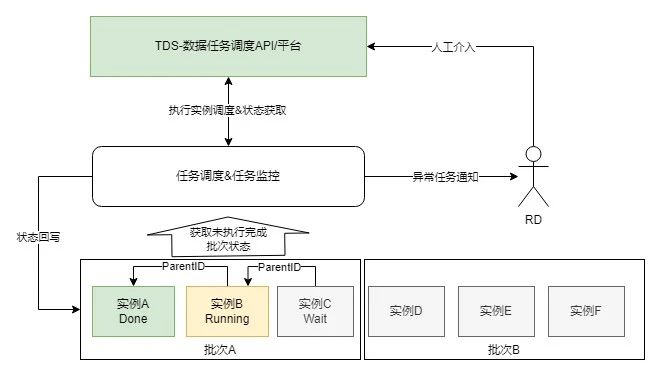
为了保证数据任务的正常执行和处理以及及时反馈进度到平台侧,调度组件包含以下功能:
任务执行&状态同步:根据任务实例记录,转换为TDS平台的任务运行实例,并根据当前状态、依赖任务状态等信息判断是否启动调度平台任务实例或获取对应的任务状态;任务的调度以批次号为单位,当前批次未执行完之前不可执行下一批次,确保全局不出现数据任务的乱序执行。
任务管理:可以通过任务批次、任务状态以及任务管理界面,或利用TDS平台来管理和感知任务的执行情况。
任务监控:对当前批次内未执行&执行中的任务定时巡检,并通过IM/邮件/短信等方式报警,及时感知任务异常,并由RD人工介入修复。
03 总结
用增结算类业务作为内部应用推广对外结算的唯一业务平台,对结算数据的准确性、一致性的要求非常高。
针对平台离线计算历史架构中存在的系统性问题,根据当前业务特点进行分析、设计,进行了整体离线层数据架构的重构,保证结算数据的逻辑解耦、版本管理、准确性时效性提升、进度与异常及时感知、简化接入与降低运营成本。针对在线业务平台与离线数仓架构的衔接方案,设计了一套适用于结算业务的在线/离线调度系统,在保证结算数据计算准确有序的前提下,保留了平台对业务管控的灵活性,同时通过离线任务统一治理减少了数据层运维和排查成本,有效支持用增线上化结算业务的快速发展。

