01 摘要
大语言模型(Large Language Model,LLM)经过近些年发展,已展现出强大的对人类语言表达的信息输入的理解、联想和逻辑推理能力,并具备世界知识中的语言语义能力(Language Semantics)。腾讯广告推荐大模型基于用户在广告域和内容域的丰富行为,挖掘协同语义(Collaborative Semantics)实现广告推荐效果的提升。将大语言模型的自然语言语义与广告推荐大模型的协同语义深入结合,应用于广告系统,有广阔的想象空间。广告系统采用召回、粗排、精排的漏斗架构,召回作为漏斗的最上游,肩负着避免信息茧房、破圈广告自闭环和选择用户感兴趣广告集合的作用,适合作为首先入手的环节。业界在搜索广告生成式召回有所落地,但展示广告生成式召回落地面临着3个问题:
1,如何有效捕获用户意图:展示广告触达用户的途径往往不涉及到用户主动查询,因此没有query来显式表达强意图,如何为基于大语言模型的生成式召回提供准确、全面的“提示”作为输入?
2,如何让大语言模型在广告领域对齐:预训练大语言模型通常是在基于网络数据构建的语料库上训练的,和广告域之间存在“隔阂”,如何让大语言模型的自然语言语义空间与广告推荐协同语义空间对齐,使得生成结果具备广告场景真实含义?
3,如何设计高性能平台与工程架构,满足ROI约束:大语言模型训练和推理成本高昂、延迟大,而广告推荐对延迟和ROI都非常敏感,如何设计与实现高性能的训练、推理平台、工程的解决方案,在满足ROI约束的前提下,让大语言模型在广告推荐的核心链路落地?
接下来我们将围绕这三大问题,介绍腾讯广告基于混元大模型的生成式召回落地实践,该工作是业界首个落地的展示广告场景生成式召回,已经应用在腾讯广告新广告投放(3.0)当中,助力广告主的竞价投放。以微信视频号场景为例,该落地应用提升GMV normal指标0.69%,提升曝光转化率0.52%。
● 腾讯广告推荐技术团队:李毅,刘越,周超,王源,邓小翔,李丰欣,薛伟,刘大鹏
● 腾讯TEG机器学习平台团队:伍海洋,邓超,赵琳,徐胜,郭朝楠,杨月奎
● 腾讯TEG广告工程团队:林立伟,胡璁,赵超越,陈绪东,李锐
02 整体架构
基于混元大模型的生成式召回的整体架构如图1所示,分为三个关键环节。第一个环节是基于用户行为和广告反馈的意图捕获,该环节应用上会采用Prompt Engineering(提示工程)、SFT(Supervised Fine-Tuning,有监督参数精调)、DPO(Direct Perference Optimization,直接偏好优化)等技术,在混元大模型基座基础上精调广告生成式召回LLM,实现世界知识和广告域知识的融合。第二个环节围绕广告系统3.0的核心概念“营销对象”设计结构化文本表达,引入语义ID(Semantic IDs)实现营销对象的语义索引,并使用限制性解码和多样性策略使生成结果命中广告库在投放营销对象集合。第三个环节是在广告推荐的低时延、高QPS以及ROI要求的挑战下,支撑算法落地的基础能力,包括高性能模型平台与工程架构。
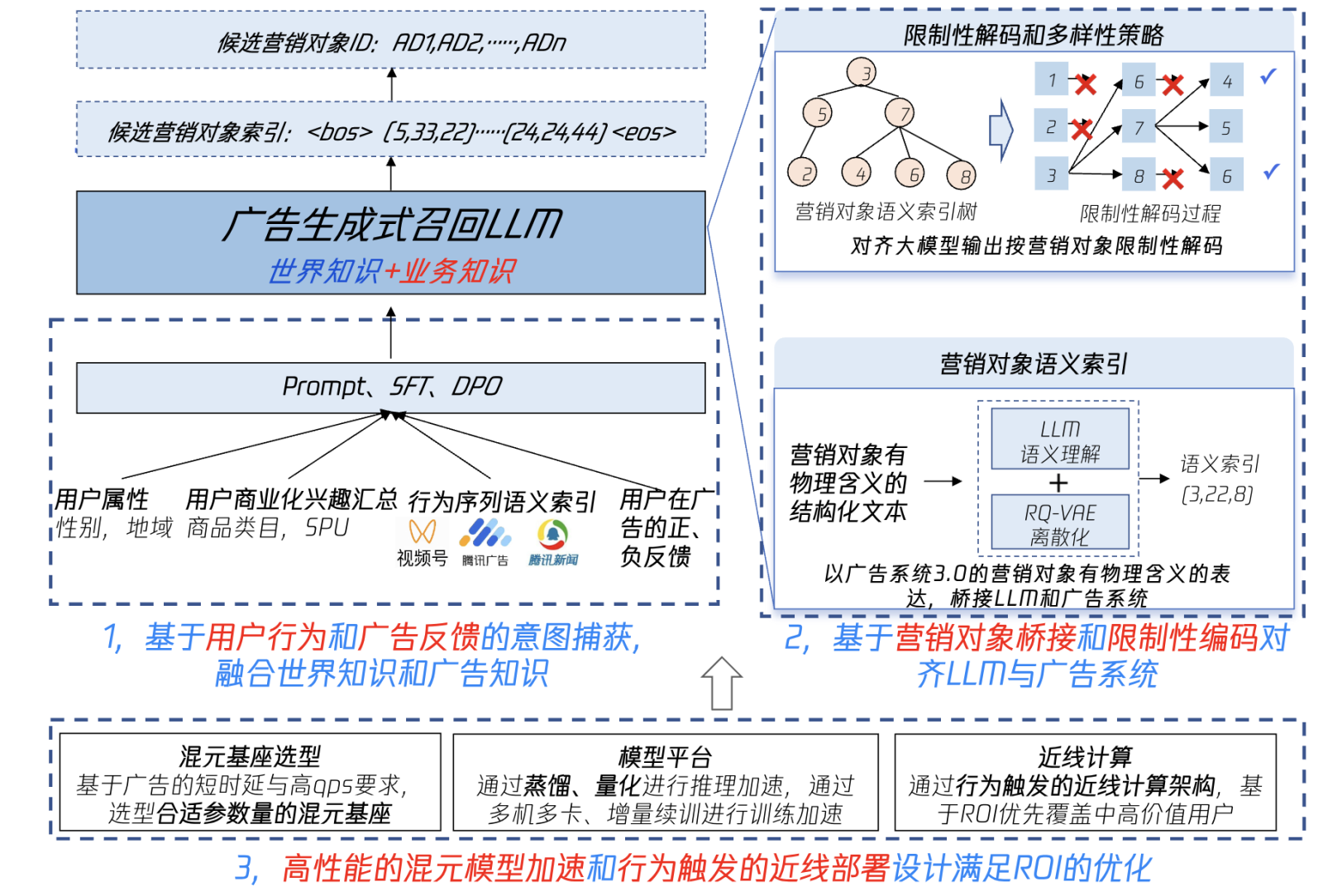
图1:基于混元大模型的生成式召回架构图
03 基于用户行为和广告反馈的意图捕获
在展示广告的场景下,没有显式的query来表达用户意图,因此缺乏自然的生成式召回prompt,而对于LLM来说,序列化的tokens输入是必备的环节。因此,我们探索了面向展示广告生成式召回的的设计范式,并通过离线特性增益分析验证了Prompt中各部分的有效性。在精调模型过程中,我们还实践了SFT的主任务与辅助任务的训练策略,证明了引入辅助任务的有效性。最后,为了让生成的结果更具商业价值,我们通过多种DPO方式引入商业价值偏好、用户兴趣度偏好。
3.1. 广告Prompt Engineering与SFT
我们在Prompt中引入用户基础属性、用户兴趣摘要、用户在广告域和内容域的商业行为序列来表达用户意图,在Response中使用用户接下来的广告点击/转化行为,如下图所示:

图2:Prompt特征数据构成示意图
表1详细介绍了一种具体配置:以序列中最后1条点击/转化为样本/Response的情况下,Prompt中各部分指令构成的设计。
表1:精调指令设计

为了调研构成指令的各部分对最终效果的影响,我们开展了离线特性增益分析,我们采用的评估指标是HitRatio@K,该指标的计算方式如下:

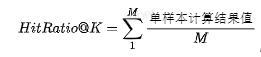 ,M为测试集合的样本量。
,M为测试集合的样本量。
部分指令构成部分的离线特性增益分析结果如下:
表2:Prompt Engineering离线特性增益分析结果

对于在广告域活跃的用户,用户在序列中会出现多次点击、转化的行为,我们将用户广告序列中的后N个点击、转化行为拆成多个Response,让大模型理解用户序列中的多次点击、转化行为,可在离线HitRatio@8指标+5.96%。此外,我们对用户的行为序列也做了清洗和过滤,例如:转化归因点击、重复点击去重等,一来信息表达更加清晰;二来缩短了Prompt长度以提升训练和推理性能。
表3:语义-文本空间对齐任务

混元大模型在经过广告数据的SFT精调后,可从SFT所用用户行为语料中学到用户的偏好,但是缺少对广告的商业价值的感知。我们借助精排的ecpm值,构建<用户,高ecpm广告>的Chosen Pair对与<用户,低ecpm广告>的Reject Pair对,通过Direct Preference Optimization(DPO)的方式开展优化,让生成式召回能感知商业价值,驱使生成的结果综合考虑用户个性化偏好的相关性与广告商业价值。
04 大语言模型在广告领域对齐
4.1. 营销对象桥接LLM和广告系统
腾讯广告3.0投放系统引入了营销对象的概念,广告主在投放广告时,需要将推广对象关联到营销对象,并设定物理世界有真实含义的属性,从而使得营销对象包含关于广告的重要结构化信息。以某旅游行业营销对象为例,如图3所示为该广告对应的营销对象的结构化信息:

图3:营销对象案例
我们选用营销对象作为桥接LLM和广告系统的标的,原因有两方面:(1)营销对象是广告系统3.0中每条广告都有的,具有粒度粗细合适、生命周期长、物理含义稳定的特点;(2)营销对象包含结构化的文本信息。我们结合营销对象的业务逻辑,通过数据预处理拼接出营销对象的结构化文本描述作为混元文本embedding的输入,通过混元抽取营销对象的文本表征,图4说明了数据处理的全流程。

图4:营销对象的文本表征
我们对比了混元Embedding服务与E5 large instruct、beg-m3、BERT等多个模型的效果,我们以embedding召回距离最近营销对象同产品库的占比来评估:

混元文本embedding表征在评估指标上处于前列。
4.2. 语义ID索引
有了营销对象的文本表征后,我们引入语义ID索引[9]来将营销对象embedding进行语义编码。我们用四层码表编码腾讯广告3.0系统里所有的营销对象,每层256个编码节点,不同营销对象的碰撞率为4.06%,碰撞的冲突解决通过扩展末层语义编码进行区分。
引入语义ID的好处在于:
● 缩小token空间,提升模型学习稳定性和检索效率。
● 学习到先验知识,相似营销对象存在语义前缀共享,同时不共享的语义ID又表达了区分度。
● 缩短Prompt和Response长度,提升训练和推理性能。
模型采用RQ-VAE结构[7],如图5所示,整体为encoder-decoder结构,通过多层codebook对输入Embedding做量化。Encoder先将输入Embedding做变换,然后找到codebook1中距离最近的Embedding,图5中为序号1,然后计算残差,残差继续从codebook2中找距离最近的Embedding,图5中为序号4,再计算残差,依次按此逻辑计算。最终得到语义ID[,,,],4个codebook中最近的Embedding加和作为decoder的输入,模型的学习目标为让decoder输出embedding尽量还原encoder输入embedding。

图5:RQ-VAE示意
以下为使用4层语义编码结构,其中前3层语义编码相同的营销对象示例:
表4:语义编码前缀相同的营销对象示例

营销对象的语义ID结果,可组织为前缀树(Trie Tree)形态,图6展示了基于营销对象语义ID的前缀树。

图6:营销对象语义ID的前缀树Trie Tree
4.3. 限制性解码与多样性策略
在生成任务中,模型通常会从一个起始状态开始一步步生成下一个token,直到生成一个完整的句子或序列。每一步生成的决策基于之前生成的内容和当前的上下文。由于可能的生成路径(即序列)的数量是指数级增长的,穷举所有可能的序列几乎是不可能的,因此需要一种高效的搜索策略来找到更优解。限制性解码(Constrained Beam Search)是一种广泛应用于自然语言处理(NLP)任务中的搜索算法,特别是在生成任务中,它是一种启发式搜索策略,旨在通过有限的计算资源找到更优的输出序列。
在基于混元大模型的广告生成式召回场景下,区别于LLM问答场景,需要通过推理输出不止一个生成结果,以满足广告召回的多样性要求;同时还要求生成的结果命中广告库中在投的营销对象,以确保其真实可用。因此我们基于营销对象语义ID索引前缀树,开展限制性解码,以达到大模型的输出结果都是有效的广告营销对象的目的。

图7:基于营销对象语义ID索引前缀树的限制性解码
05 平台与工程
在广告推荐的低时延、高QPS以及ROI要求的挑战下,本章节介绍支撑算法落地的基础能力,包括高性能模型平台与工程架构。
5.1. 大模型推理服务
大模型计算复杂度比传统推荐模型高出2到3个数量级,广告场景请求量大,服务时延要求高,所以我们必须要对大模型推理做极致的性能优化,才能满足业务场景应用需求。接下来分别从Kernel优化、LLM量化推理以及推理服务调度优化来介绍我们在推理性能上的优化方案:
1) TensorRT-LLM kernel优化
softmax kernel 优化:受限解码中耗时最长的 kernel 是计算 softmax 的 kernel,大概占整个解码耗时的 80% 以上。经过分析,该 kernel 主要是访存操作,是典型的访存瓶颈。我们使用了 float4 代替 float 进行向量化访存操作,有效降低访存带宽。优化后的 kernel 性能翻倍,端到端耗时降低5%左右。在 prefill step 中,logits 是按照 beam width tile 而来,在计算 softmax 的时候,只需要对 beam 0 计算,我们加入了 ComputeMode 来区分 prefill 和 generate,应用此优化,在 prefill 阶段,softmax kernel 的性能可以再提升3-4倍。
finalize Kernel 优化:finalize kernel 是 beam search 场景需要的 kernel,其作用是在请求输出之前,根据每个 beam 的 parent beam 递归出最终的 token ids。原本的 finalize kernel 只使用单 block 单 thread 计算,无法充分利用 GPU 的 SM 资源,我们使用 beam width 个 block 计算,性能提升50多倍,端到端延迟降低10%左右。
2) TensorRT-LLM 量化
大模型的推理分为两步,prefill 和 generate,通常情况下认为,prefill 是计算瓶颈,generate 是访存瓶颈。但在广告场景中,因为使用了很大的 beam width,加上推理引擎支持的 batching 功能,generate 阶段也是计算瓶颈。因此,在量化方案的选择上,我们更偏向于使用对激活值量化的方案,分别是 smooth quant w8a8c8 和 fp8 w8a8c8。
smooth quant w8a8c8 量化
我们实现了 smooth quant w8a8c8 量化,weight,activate int8 量化,可以让 tensor core 在 int8 精度下进行计算,对于矩阵乘等计算密集型算子,算力翻倍。使用 smooth quant 量化,搜索广告场景有 50% 的性能提升。
fp8 w8a8c8 量化
smooth quant 需要更多的精度调优,fp8 相对来说效果更佳,应用 fp8 w8a8c8 量化,在保持精度的情况下,在 H20 显卡可以实现和 smooth quant 相同的性能。
proxy全局负载均衡
前面的优化更多是提升单GPU的能力,为了提升多GPU整体的利用率,我们需要对调度策略做一些优化才能把GPU能力更好的利用起来。在我们系统中,Proxy和大模型推理服务(TensorRT-LLM)是多对多的关系,proxy之间不感知其他实例把当前流量分配给了哪个TensorRT-LLM,这会使得多个proxy某个时刻将请求给了同一个TensorRT-LLM,从而导致每个TensorRT-LLM 接收到请求不够均匀,加之TensorRT-LLM对QPS及其敏感,某个实例比其他实例多处理2个请求都会导致该实例成为集群吞吐的短板。proxy通过引入redis全局计数的方式统一分配请求,实现proxy向TensorRT-LLM分配请求的完全均衡。使得TensorRT-LLM集群负载达到理论负载90%以上。

图8:大模型全局负载均衡调度
5.2. 大模型训练平台
由于语义索引的引入,为了让语义索引在分词时不被分开,在大模型微调时,需要对大模型词表进行扩展,扩展之后整个大模型词表既存在已经预训练之后的tokens,也存在新增的随机初始化的tokens,这种不一致会影响大模型的微调效果。为了解决这个问题,我们支持新增tokens能进行单独微调功能。

图9:生成式召回SFT词表处理流程图
具体来说,我们对原始词表以及新增的语义索引词表的embedding table进行了分表管理,在训练初始阶段可以通过配置化的方式,冻结原始词表embedding和Transformer部分的参数,只更新新增词表embedding;当新增词表embedding学习充分之后,我们再进行第二阶段微调,第二阶段微调会放开所有模型参数;通过这种两阶段的方式可以有效防止新增词表微调时对Transformer参数的影响,提升了最终模型效果。
5.3. 近线推理与离线训练工程

图10:近线推理、离线训练工程架构图
不同于广告现有召粗精排模型的 ms 级耗时,LLM 推理的在线耗时通常在 50-500ms 量级、不适合作为在线的实时推理,因此工程上我们建设近线推理的方式,近线预估用户感兴趣的营销对象,在用户下次请求广告系统时做对应推荐。另一方面,即使是近线推理,由于 GPU 推理资源相对珍贵和受限,也不适合对全量请求进行推理,因此我们也建设一些方式如对用户ARPU价值分层、对用户行为价值分档、组合策略触发和数据平滑等,优先对高价值用户、高价值行为进行 GPU 推理,尽量最大化 GPU 推理资源的效能,同时能多实验并行,帮助算法团队提升效率 7.5 倍以上。
在特征的选择和使用上,LLM 采用纯文本的自然语言构造 Prompt,这与经典机器学习里的比特特征表达(如 1 代表男,2 代表女)有很大不同。如果按照传统方式组织自然语言特征,由样本直接关联文本特征,就需要按照用户和广告等维度重新生产文本特征,而这将带来比特和文本的两份重复特征生产工作,以及非常大的存储开销(通常文本比比特要大好几倍)。因此我们在考虑到原始特征与文本特征多为有限集合映射的条件下,落地了另外一种方案、即新增原始特征到文本表达的关联流程。这种方案里,要考虑和优化扇出问题(长度为 L 的序列特征,会扇出 L 次查询量)、要考虑监控和优化文本覆盖度、要考虑监控和优化文本质量(文本质量通常是迭代好几版才比较好)等。我们落地和支持了比较高的文本特征探索效率,已将 200+ 文本特征用于现网或实验验证。
最后,对于 LLM 的新推理范式,算法工程师去理解推理过程和结果非常重要和有效,诊断分析非常重要和有效,看 case 非常重要和有效。我们建设产品化的 Web 数据诊断分析工具、迭代 10+ 个版本。在产生一次新的推理结果后,将不同用户、不同实验的 Prompt 及营销对象推荐结果实时在页面展示,同时将其中的语义 ID 等各种编码信息做二次关联、映射为人可理解的文本语言,拓展营销对象的文本描述和属性信息,便于算法团队快速判断合理性并作对应调优。而且另一个非常重要的实践,是在推理过程中做比较多的埋点信息记录、同时在产品化平台上收集和展示,在需要的时候可进一步展开、理解推理过程。
06 总结与展望
本文阶段性总结了基于混元大模型的生成式召回技术在腾讯广告业务中的落地实践和效果提升。后续我们将继续深化基于混元大模型的生成式推荐技术研究与应用,尤其是从召回拓展到排序环节的全链路应用。

