多场景多任务统一建模在网易云音乐的算法实践
01 背景介绍
多场景建模是一项与业务紧密结合的算法优化工作,其核心在于思考如何处理多个业务场景之间的差异性和共性。
1. 云音乐推荐场景介绍
云音乐的核心场景包括每日推荐,每天更新 30 首歌曲,以列表形式呈现;还有流式推荐、实时更新,和每日推荐一样都是直接为用户推荐歌曲;此外还有歌单推荐,包括首页推荐歌单以及 MGC 歌单。

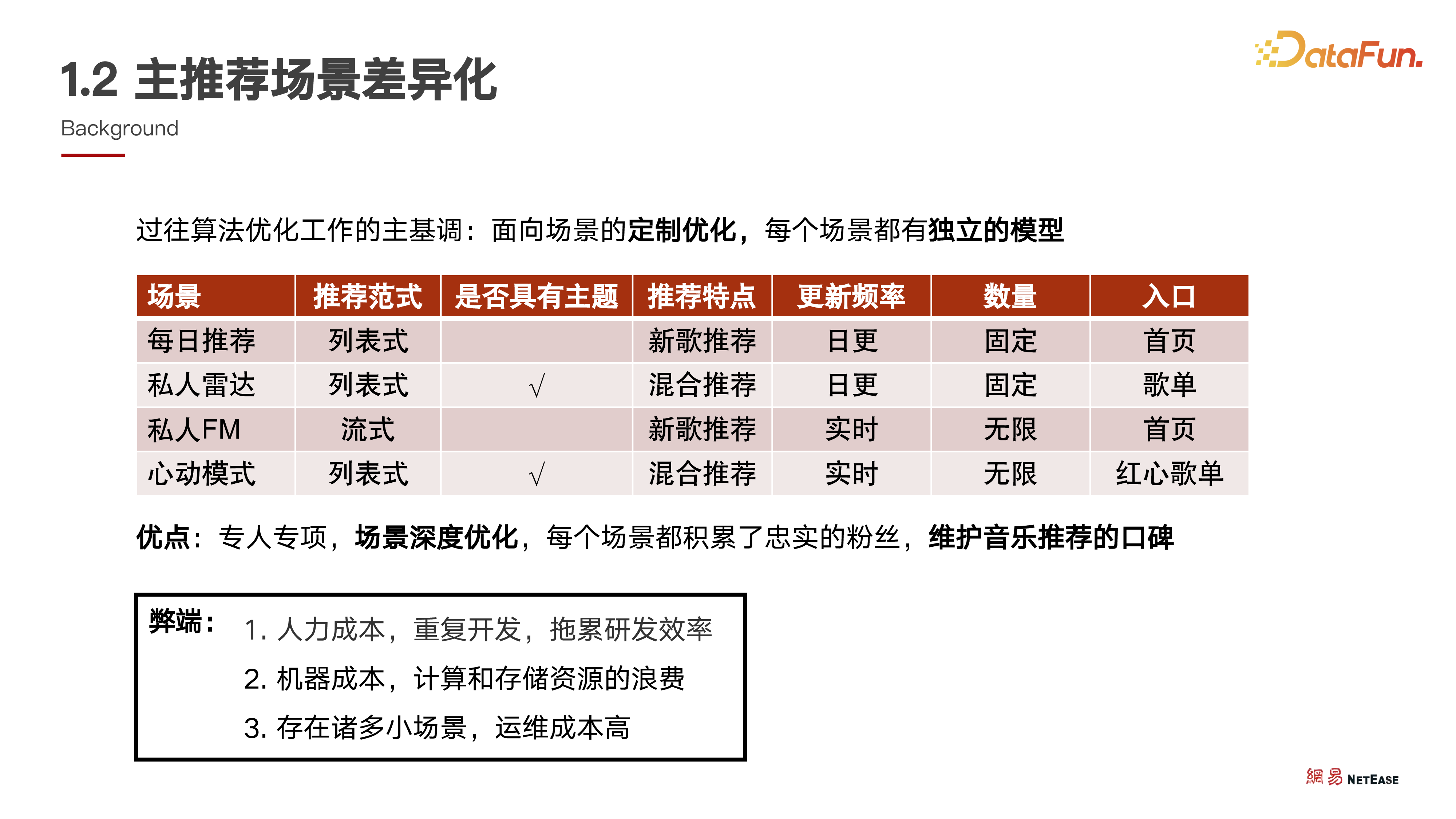
2. 主推荐场景差异化
这些场景特点各异,旨在满足用户不同的个性化推荐需求。可以看到,在过去一段时间,这些场景一直由专人专项持续优化。这样做的优点是能使模型更贴合业务场景和特点,充分发挥模型效果,提升场景忠实用户的体验。
这种做法也存在弊端。其一,长期专人专项优化可能导致技术栈出现较大差异;其二,技术共享和共建节奏会被拖慢。
3. 新增场景愈多
我们面临的挑战不仅是要承接越来越多新的场景,满足更多用户个性化音乐诉求并带来增量,同时还要思考如何更好地承接和持续优化这些新场景。

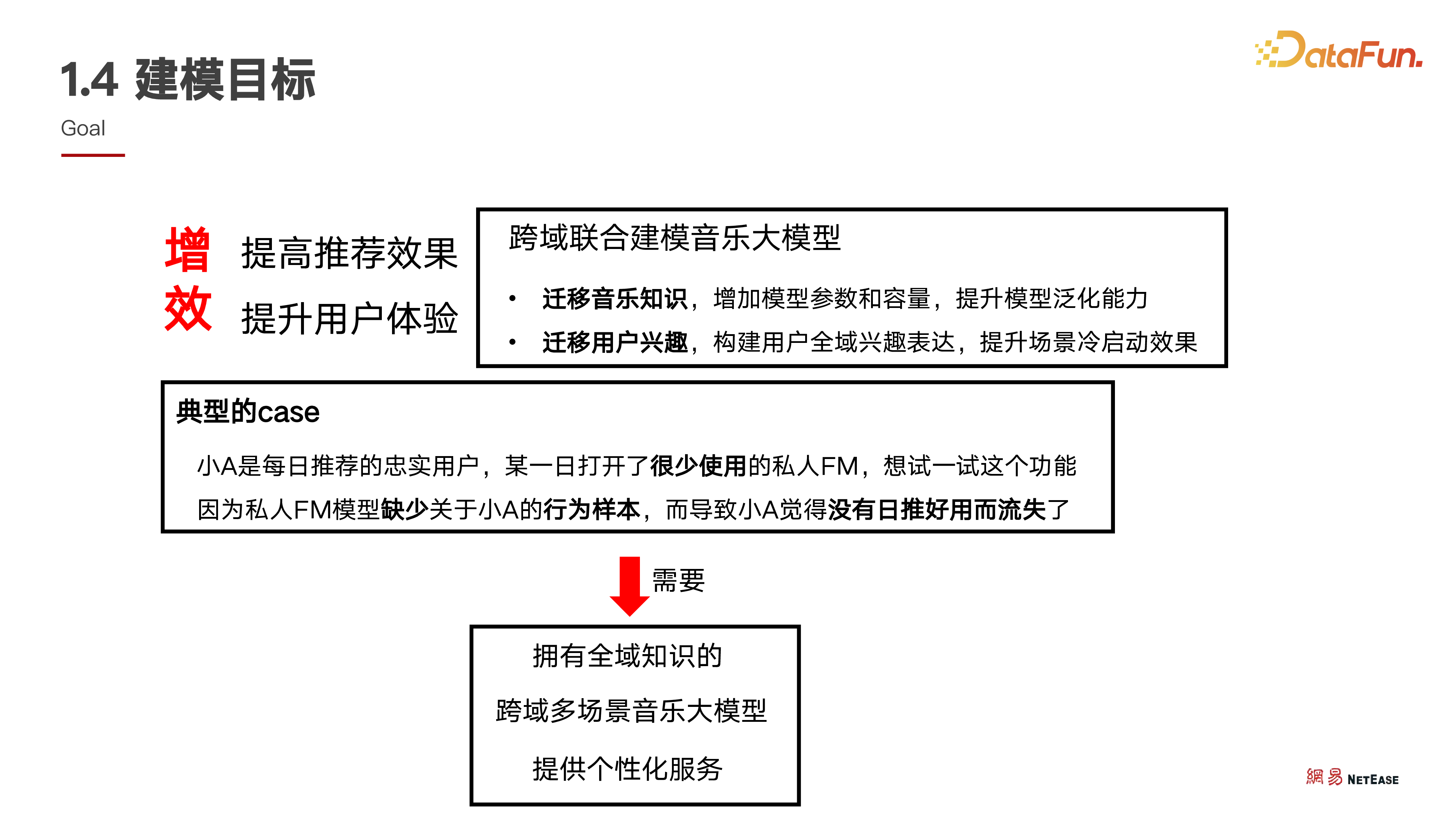
4. 建模目标
开展多场景工作的目标主要有两个:一是用一个模型服务所有推荐场景,取得更好的效果,联合建模用户在任意场景消费后产生的数据,精准建模用户真正感兴趣的底层兴趣表征;二是用一个模型服务所有场景,有效降低机器成本和人力成本,提升研发效率,促进技术共建达到更高水平。
5. 建模难点
第一个难点是双跷跷板问题,由多任务跷跷板和多场景跷跷板构成,两者耦合时平衡难度加大。另一个难点,可用西方故事“格力娅如何战胜大卫”来描述,即如何用一个通用的大模型打败每个场景专有的小模型,其中难点众多,将在后续介绍中详细阐述。

02 整体框架
1. 系统框架
此次虽主要谈及算法层面的多场景建模,但更重要的是,在算法层面之外,我们对从数据层到场景层再到顶层任务的整个系统框架进行了统一构建,摒弃了原先零散、不统一、不规范的技术及相应数据等,在此基础上构建了统一的模型架构。

2. 模型架构
此架构与业界现有的多场景建模整体架构差异不大,但其中融入了音乐场景特有的业务特点以及我们的思考。例如,针对音乐推荐中老歌持续被消费这一强业务特点,我们做了很多长期多兴趣的表征,并与即时性交叉且进行动态更新。同时,我们希望将业务背后沉淀的音乐、公寓知识传递到更顶层,服务于水面之上的多个业务场景。

3. 整体概述
整体架构可以概述为三个关键词:自底向上、求同存异和去伪存真。求同存异是此次分享中最想强调的点,因为多场景工作更多是如何以最小代价固化沉淀真正有价值的共性部分,同时以快速敏捷的方式保留差异部分,两者有机结合才能完成多场景统一大模型的建设。

03 关键模块
1. 统一模型建模
在参考了业界众多已有的多场景建模工作后,我们完成了整体架构的设计。对重要区域进行了分色块标记,方便理解。例如,底层有蓝色和黄色色块,总体遵循公私域分离设计结构。在公域部分,抽取多个场景共享的特征和表达,黄色部分则更多是场景特有的东西。可以看到图中有多个紫塔并联,每个紫塔代表一个场景特有的知识。在其之上是常见的 MMOE 架构,用于多个场景不同目标的多任务学习辅助。

2. 公域网络设计
公域更多表达的是业务场景共有的特性、用户公共的兴趣或其长短期兴趣中不变的部分。那么求同如何实现?这更多考验算法工程师面对零散业务特性和不同逻辑时,如何提取公约数。这里分享四个要点:一是通用的输入结构;二是特征的最大公约数;三是共享共建;四是轻量高效。共享共建和轻量高效可能基于团队文化,强制要求做到更好以服务大模型。在算法层面,更强调保留公共核心特征。这里也列举了一些核心点,比如通过消融实验找出并保留必要核心特征,能砍则砍,尽量减轻构建大模型前的负担。

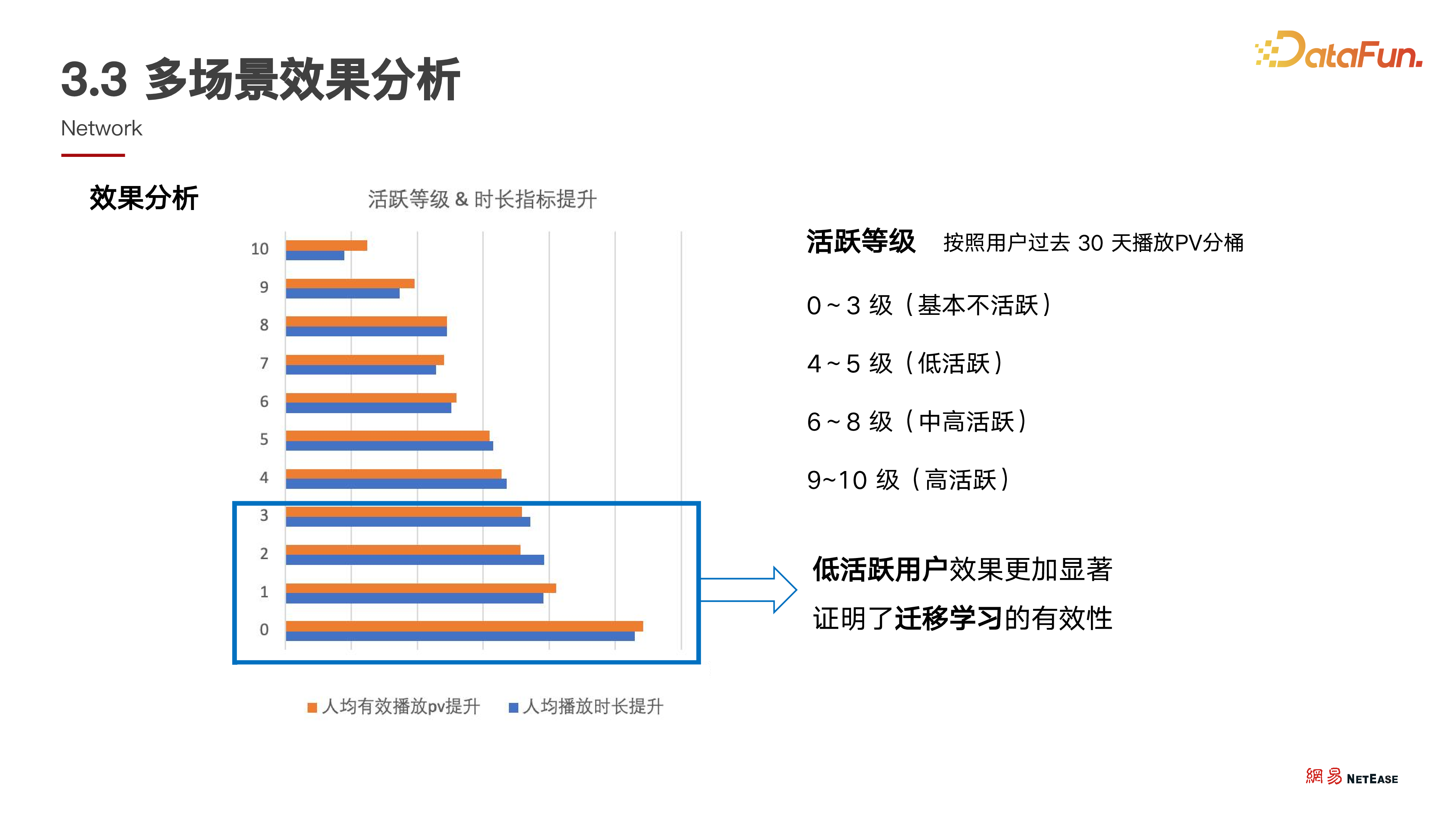
3. 多场景效果分析
基于此思考,我们进行了多次迭代,并及时基于 AB 测试分析以验证公域架构设计的有效性。将用户按活跃等级分为 0 - 10 级共 11 个档次,0 级用户最不活跃,10 级最活跃。从图中可以看出,横轴是各人群对应的提升幅度,0 - 3 级提升幅度明显最大。此数据旨在论证,通过良好的公域结构设计,能有效表达并沉淀用户特征,使低活用户受益更多。
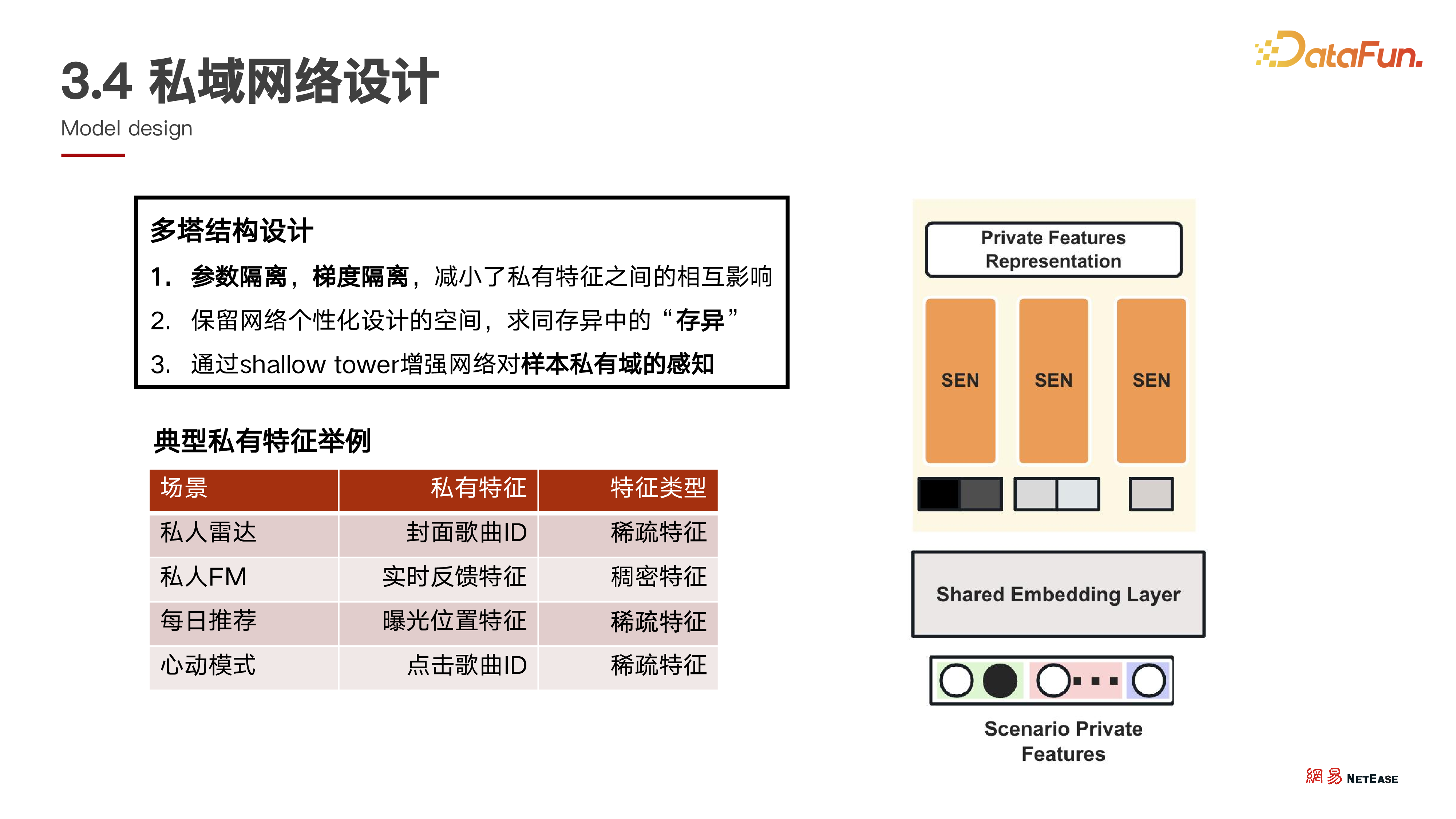
4. 私域网络设计
公域工作相对基础,而私域则较为复杂。私域的核心点在于保留每个场景最特殊、最有价值的部分特征,强调参数隔离、梯度隔离,每个塔相互不干扰,输入特征完全不同。这些特征来源于每个场景特有的特性挖掘,例如某业务场景的封面特征或流式场景基于用户实时反馈产生的信号等。
5. 场景私有网络 SEN
为应对私有场景差异大的问题,设计了 SEN 场景私有网络这一通用逻辑,便于接入新场景和合并老场景时提高复用率和整体迭代效率。求同存异中的求同主要是针对公域网络设计,而存异则是针对私域网络设计,主要体现在:一是私有场景的私有特征是不对齐的;二是某些私有特征很重要但易过拟合;三是存在分布漂移问题。我们参考了 Transformer 类的一些设计,进行组合,来解决这些问题。

6. 跨域多任务模型
接着是双跷跷板问题中的多任务跷跷板,下图中列举了几个核心场景及其面临的任务。
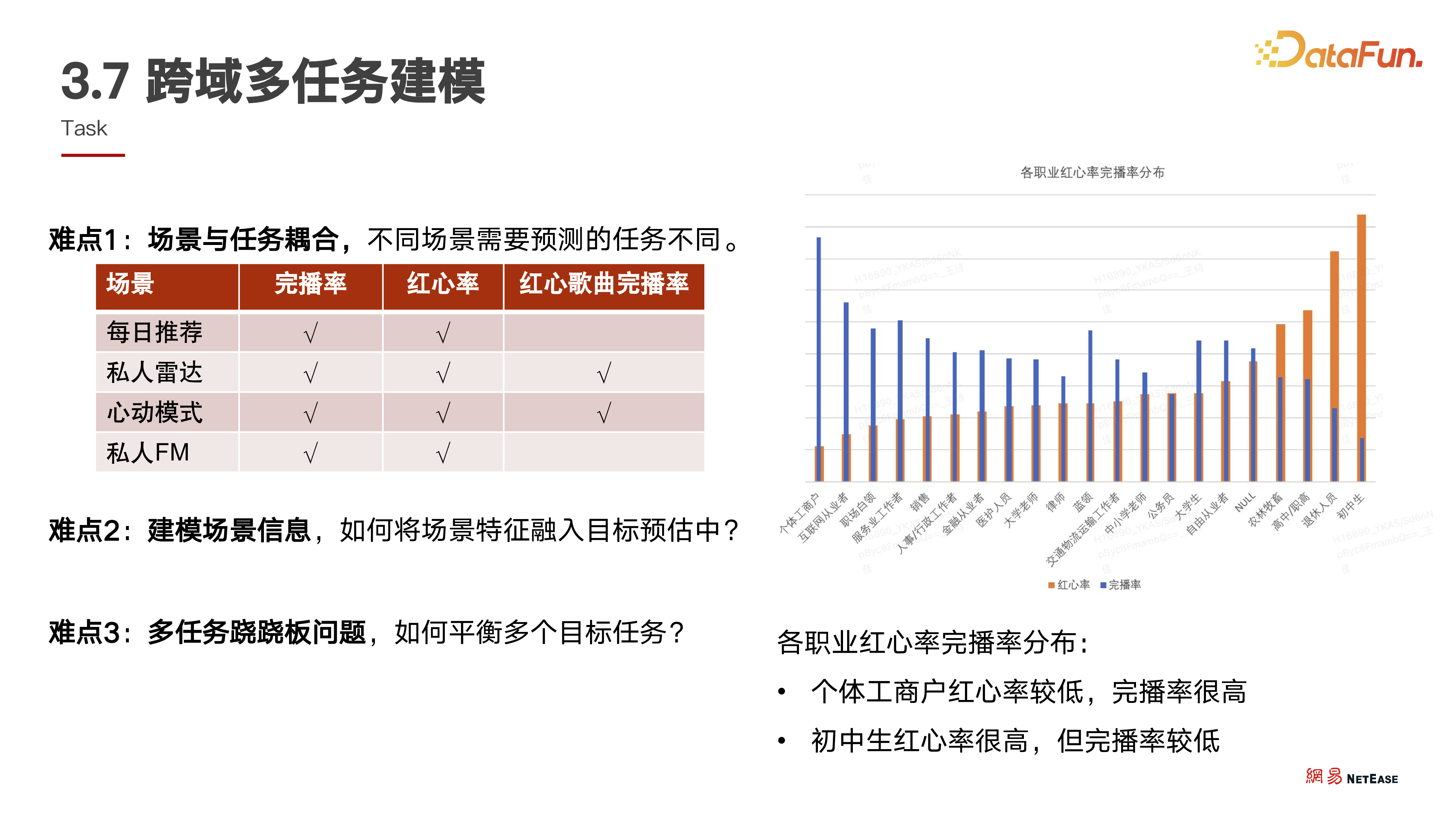
基于场景特有任务,我们设计了 task master 逻辑。对于有任务的场景保留梯度,对于无任务的场景通过 subgradient 方式停止梯度,避免影响对应 SEN 网络的学习。这保证了多场景、多梯度之间,场景与场景、任务与任务以及场景对应特有任务之间尽可能隔离。

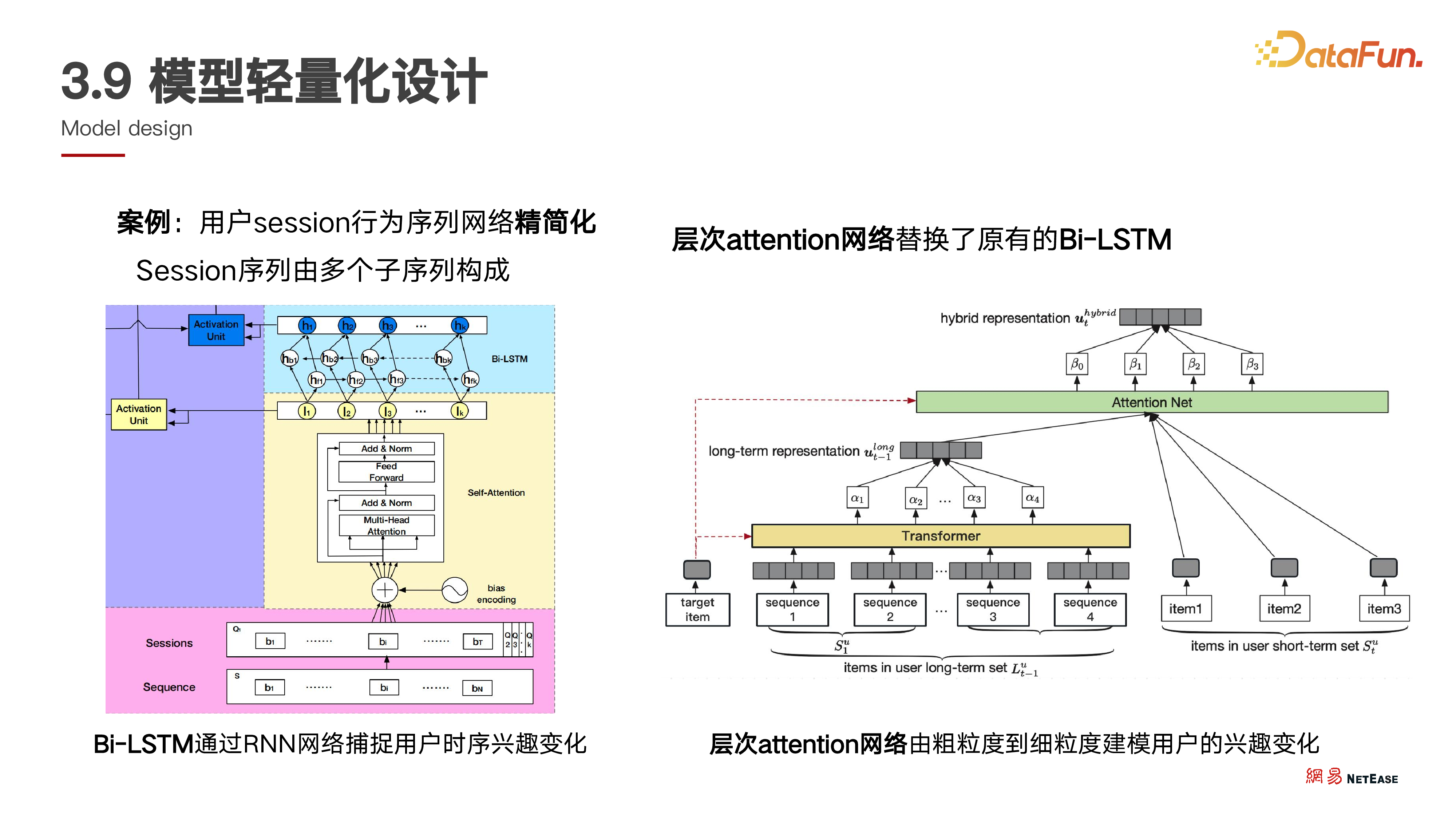
7. 模型轻量化设计
在音乐推荐场景中,用户行为序列特别是长期行为序列非常重要,引入 LSTM 加 session 切分提取用户长期兴趣特征曾带来显著提升,但此特征和对应的网络结构对模型消耗大。在迭代多场景、多任务统一大模型时,我们找到了一个相对更轻量化的方式,即层次 attention 网络。
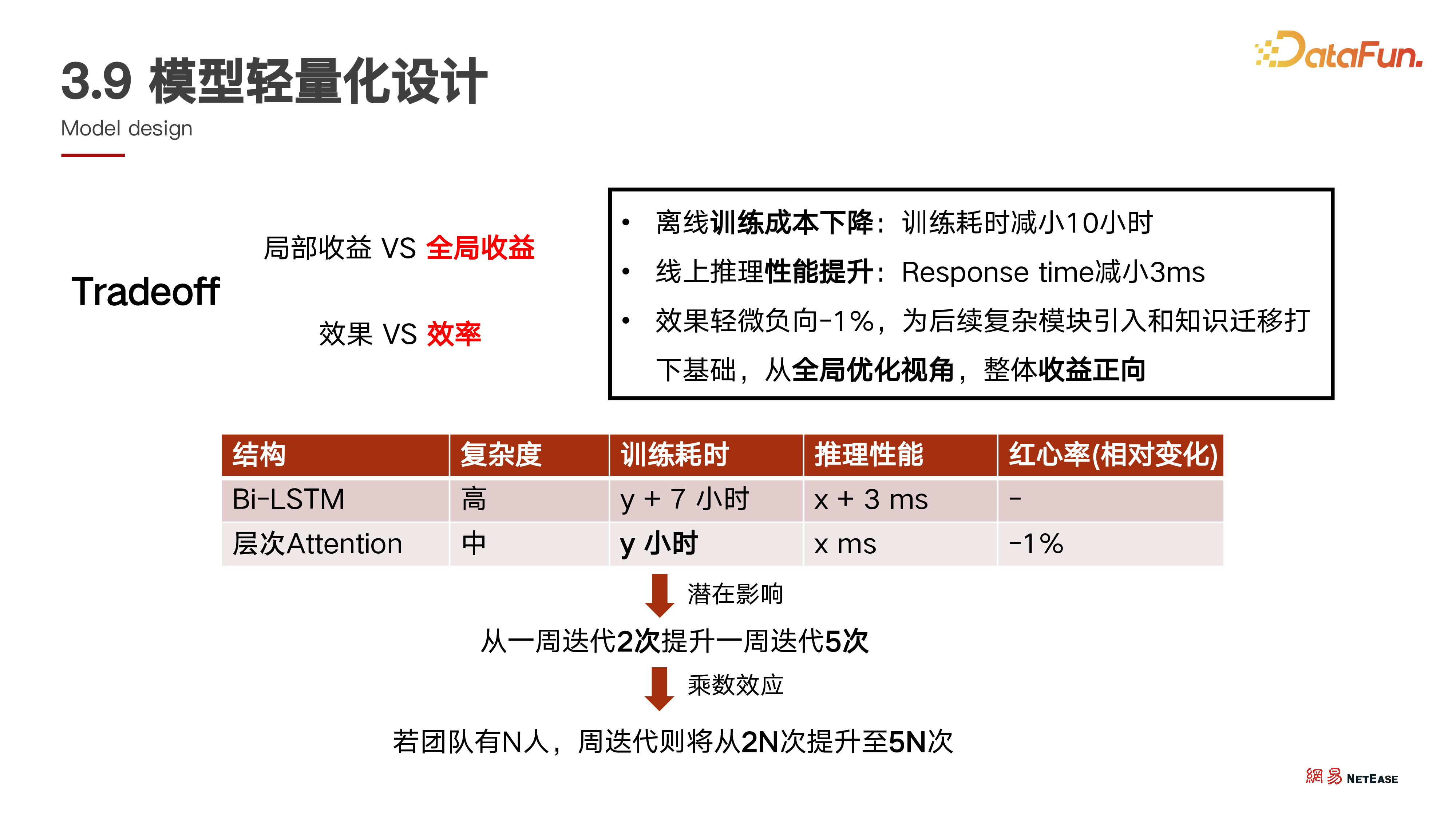
从数据对比来看,虽然层次 attention 在某个核心指标上有轻微负向,但从全局来看是一种权衡,牺牲局部小收益换取未来全局更大的收益,提升了整体的迭代效率。
04 应用效果
模型上线后效果显著,核心推荐场景红心率提升 10% 以上,众多小场景核心指标提升 15% 以上,直接带动次留相对提升 1%。模型还落地到网易集团其他业务,新客绝对值提升 0.2%,次留绝对值提升 0.2%。同时,模型上线后替换了原有的零散和不统一的技术栈,整体效率也有所提升,并节省了资源消耗。

05 展望
在现有整体模型统一的基础上,我们希望将模型进一步复杂化,服务于网易云音乐更多业务线,不仅限于音乐推荐,还包括播客、直播等,以各种合作的形式发挥模型最大效果。


