云音乐服务监控系统(代号:Pylon APM)为业务提供服务监控、链路追踪、治理分析、问题诊断等能力,本文介绍了平台建设中的一些实践经验。
一、背景介绍
云音乐服务端原有的服务端应用监控体系,存在很多痛点和问题,导致出现线上问题时,定位的效率不太理想。服务端应用监控体系主要存在以下几个问题:
Trace链路完整性问题:老的trace是通过组件sdk埋点的形式,进行trace的记录与输出,导致了trace的完整性依赖埋点逻辑,如果链路埋点处理不正确,会出现上下文异步透传丢失,trace数据冲突混乱的问题。同时,对于异常的非采样链路,在采集时,无法回溯上游来源,经常出现定位信息不足的问题。
Trace与Metric割裂问题:trace与metric之间缺少数据关联,metric服务监控数据依赖其他平台,导致慢请求,慢sql之类的问题场景定位时,找不到具体发生问题的trace。线上发生异常错误指标报警时,很难找到对应的错误链路,定位问题效率低下。
Trace与日志联动问题:业务服务产生ERROR日志时,有追溯异常调用的来源的需求。低采样率的线上场景,只能找到日志,而找不到请求的具体链路,对问题排查帮助很小。
版本升级迭代困难:版本升级依赖业务服务升级sdk,推进困难,功能迭代效率低。
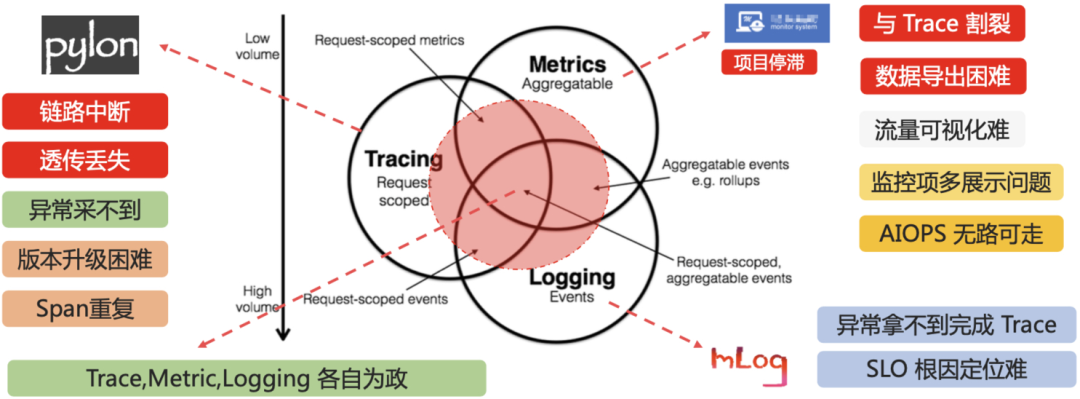
开源项目中Pinpoint和SkyWalking都是目前比较成熟的链路追踪方案,两者各有优劣,在对比中,我们发现Pinpoint与云音乐的链路模型更加接近,插件开发也更加友好,并且国内有多个基于Pinpoint的商业化落地项目,稳定性有保障。
最终我们选择基于Pinpoint开源方案,进行了深度的自研改造和优化,希望达成以下目标:
业务服务解耦:Java Agent形式实现应用监控功能,与服务代码完全解耦,业务无感知接入,无感知升级。插件化实现,能够在管控平台通过开关动态控制细粒度功能的开关。
保证链路完整性:通过异步上下文管理无感知解决了链路异步透传的问题,保证trace透传的完整性。同时通过TailBased方案,实现了异常错误链路完整采样的能力,最大限度的保证链路问题定位有效性。
集成Metric能力:通过集成prometheus组件,实现了应用服务监控的能力,开发相比哨兵监控项更加简单。同时实现了Metric监控联通Trace的能力,对于指定监控指标,能够根据监控值检索对应Trace。
问题快速诊断:不论是异常日志,还是错误、长耗时调用,都能通过元数据或监控数据关联到完整的链路,在平台快速下钻,提升问题定位效率。
问题诊断工具:提供自动异常现场采集能力,集成白屏化诊断工具,完善问题分析能力。
二、项目思路与方案
1.项目整体架构
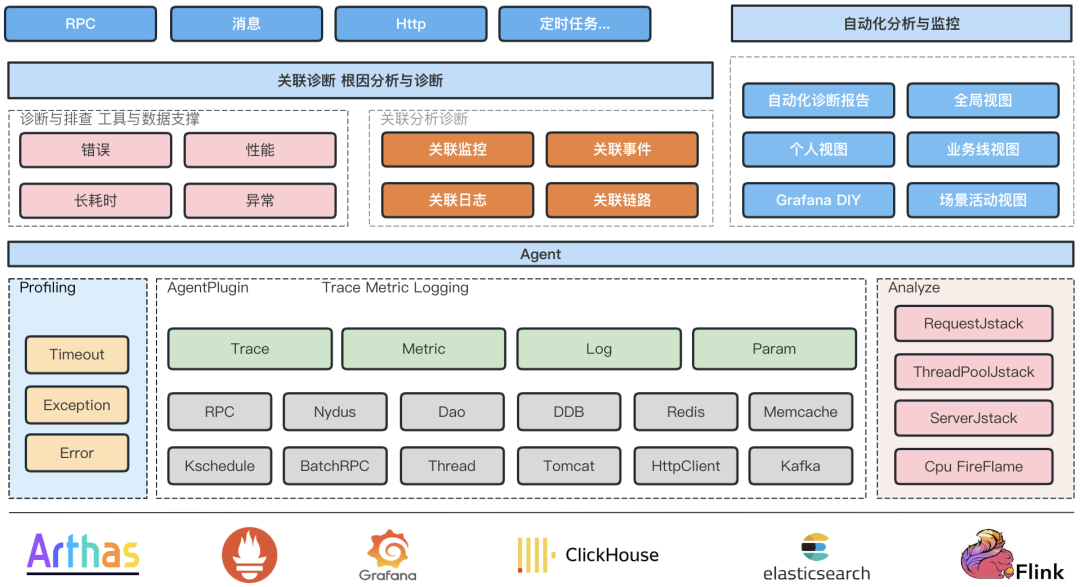
主要分为Agent和Console两个部分,Agent主要负责Trace生成与传递,Metric记录与上报,实现了一套字节码注入工具,以及数据处理框架,再通过插件化的形式,实现不同组件的trace与metric能力。Console主要负责数据的收集与存储,分析与展示,将Trace,metric,log联动的数据模型,通过链路问题定位能力串联起来,实现快速的问题诊断。
2.基于Pinpoint开发的Java Agent
开源的Pinpoint实现了插件化的Trace能力,并且实现了很多常用的中间件的插件,但是开源Pinpoint Agent依旧存在以下问题:
Trace模型过于简单,对于部分Trace使用场景无法很好支持(比如消息队列多个消费者的场景,消费者之间无法区分),支持的链路类型有限,元数据管理不方便。
上下文透传能力支持不足,Trace上下文因为支持透传,很多时候业务上下文,可以复用这部分能力,不需要重复开发,Pinpoint这块支持不足。
异常链路回溯采样不完整,对于非采样链路,出现异常时,无法回溯采集上游,定位效率会大打折扣。
不支持Metric能力,无法关联监控数据,浪费了切面中的数据与状态结果。
1)扩展Trace数据模型
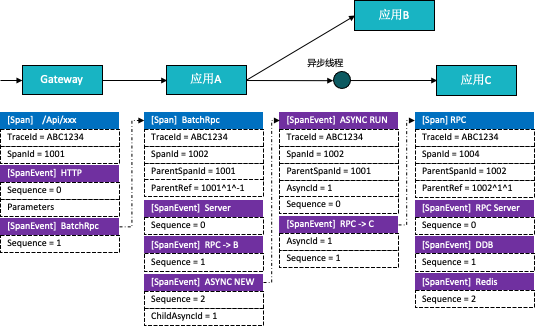
基于Pinpoint Trace-Span-SpanEvent的模型,扩展了部分关联字段和透传字段,使得Trace能够支持多下游关联,异步下游关联,异步回调关联等能力。在上下文透传上,支持进程内字段透传,跨进程字段透传,跨进程字段反向透传,并提供专门的透传sdk供接入方使用。
2)异常链路后置采样
链路上发生单点异常时,如果只是把异常点及其下游链路采集上来是比较容易的,但是这样带来的问题定位收益并不高,很多时候不知道上游来源的话,问题定位无法继续下去。为了解决异常链路完整采样的问题,我们实现了一套TailBased的异常链路采集能力。具体方案示意如下图:
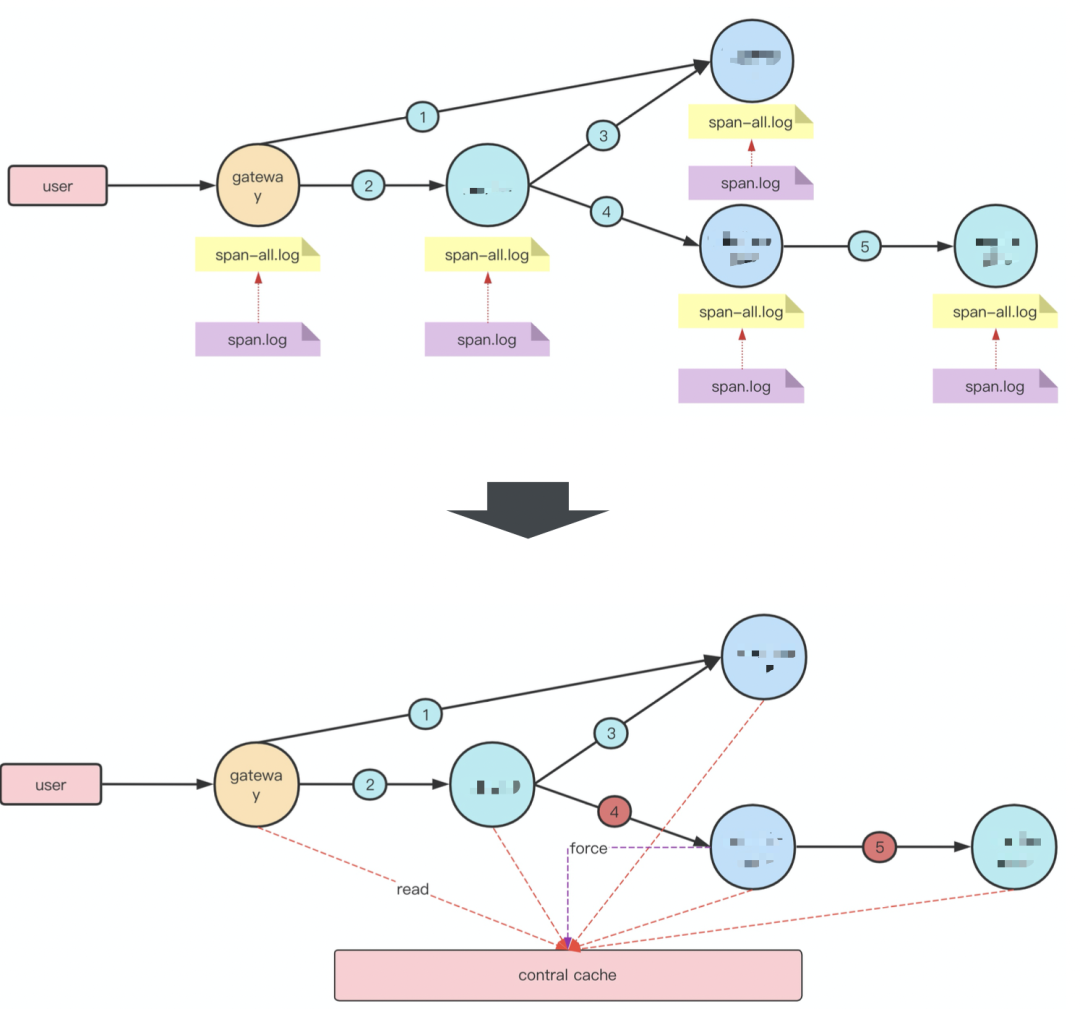
每个服务节点上,对于短时间内的Trace,会先全量输出到一个全量日志中,当链路上发生异常时,对应服务的Agent会将异常TraceId写入到中心化缓存中,并在Trace上下文信息中带上标记。独立的Tail线程会以一个稳定的延迟(30s~1min),扫描全量日志中的trace数据,发现存在于缓存中的异常TraceId后,将该TraceId关联的链路数据写入到最终的采集日志中,实现完整的链路采集。
3)Prometheus监控集成
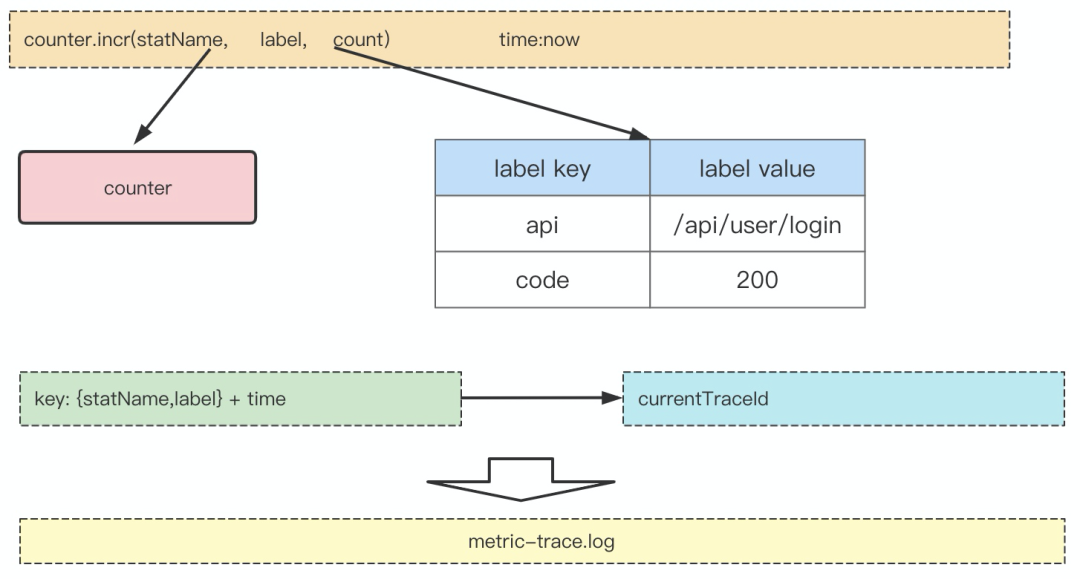
我们在Agent端集成Prometheus sdk,用以记录和输出监控数据,服务端通过Pull请求定时拉取每台服务上的监控数据,进行数据的预聚合,最终写入到vm storage存储中。监控数据在记录过程中,还会与当前TraceId进行关联,输出到关联日志中,保证每项监控数据,都有一定的Trace链路数据进行关联定位与分析。关联示意图如下所示:
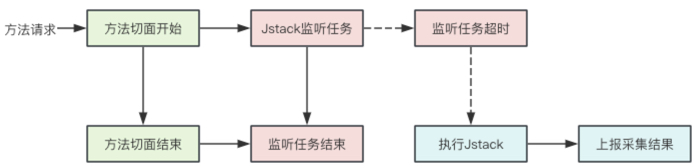
4)自动Jstack采集
线上服务在发生问题时,经常要面对抓不到现场的情况。我们对于有可能出现服务阻塞的场景,启动了异步监听任务。当调用方法执行时间超出设定阈值时,对当前线程执行一次Jstack堆栈采集,将当前的执行现场保存下来,同时关联TraceId和方法监控指标,便于追溯。流程示意图如下:
3.APM产品设计
开源的Pinpoint自带了pinpoint-web管控界面并不能满足我们的需求,我们重新开发了一套APM平台,以应用为中心视角,划分不同维度的监控指标,再到不同监控视角下,通过Trace,Metric,Log联动,来帮助快速定位线上问题,APM平台主要具备以下几个能力。
1)链路详情诊断
完整的展示从请求入口到下游所有节点的调用拓扑关系,以及请求耗时分布信息,是链路详情的基本功能。为了定位关键透传字段丢失的情况,验证链路上下文正确与否,平台链路详情中还包含透传字段以及部分请求参数,使用者可以选择全局视角或进程视角查看调用栈,状态参数帮助快速定位到异常节点。
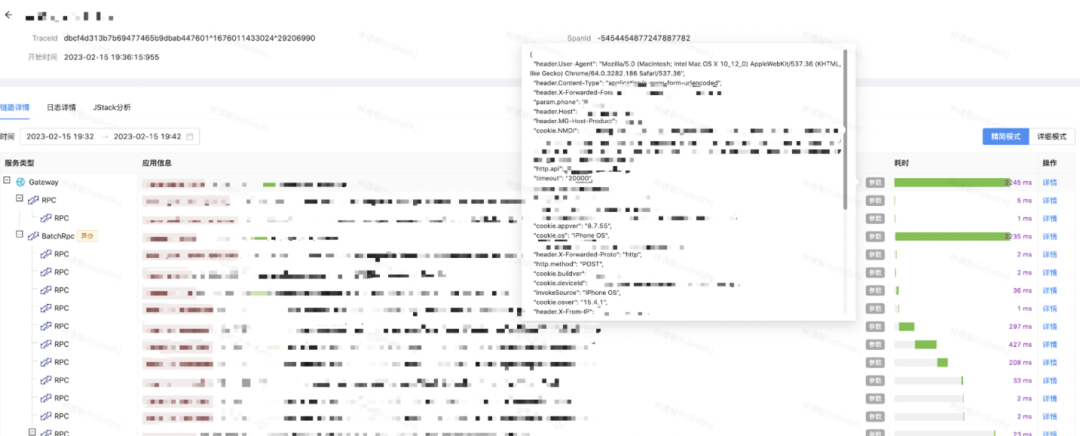
在链路详情页可以查看关联的日志信息,实现与日志联动定位问题。

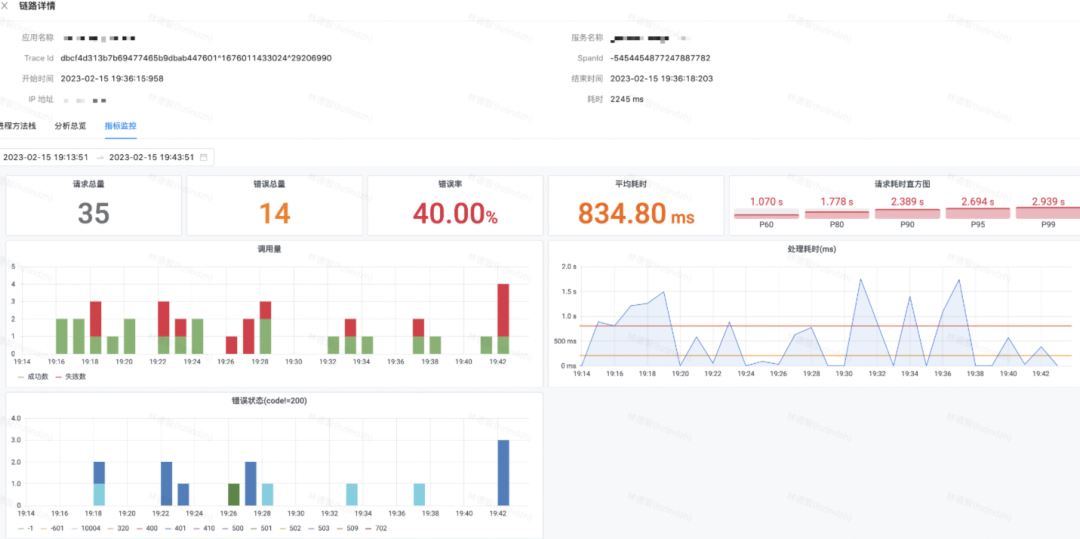
单个调用接口的详情页中,除了进程内调用栈,还有监控信息联动。
2)应用监控图表
平台以应用视角为中心,利用Agent集成的监控数据采集,构建了监控图表大盘,通过不同的元数据分类,平台支持HTTP,RPC,消息,数据库,缓存等各个独立视角的监控数据,以大盘曲线结合表格下钻的形式展现。
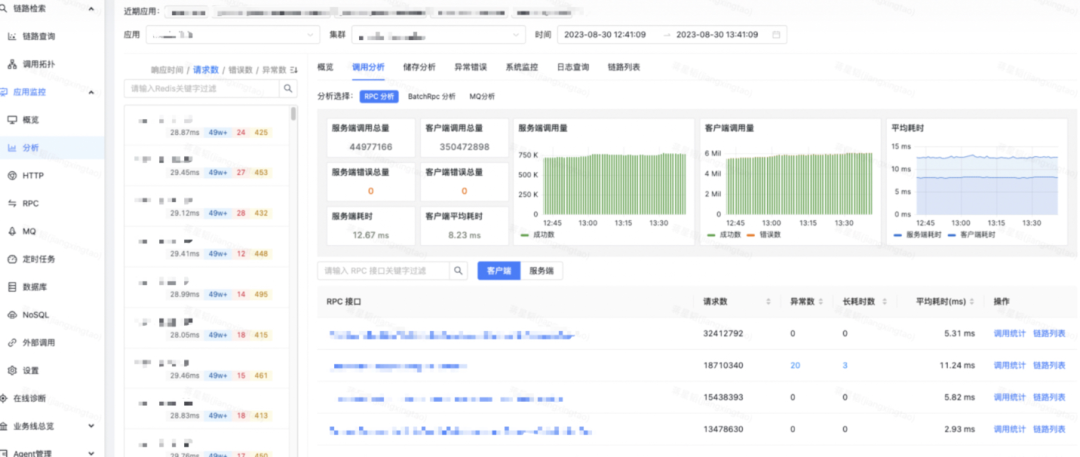
大盘图表在Grafana基础上,做了二次开发,支持同环比分析,多实例比较等实用的数据分析功能。
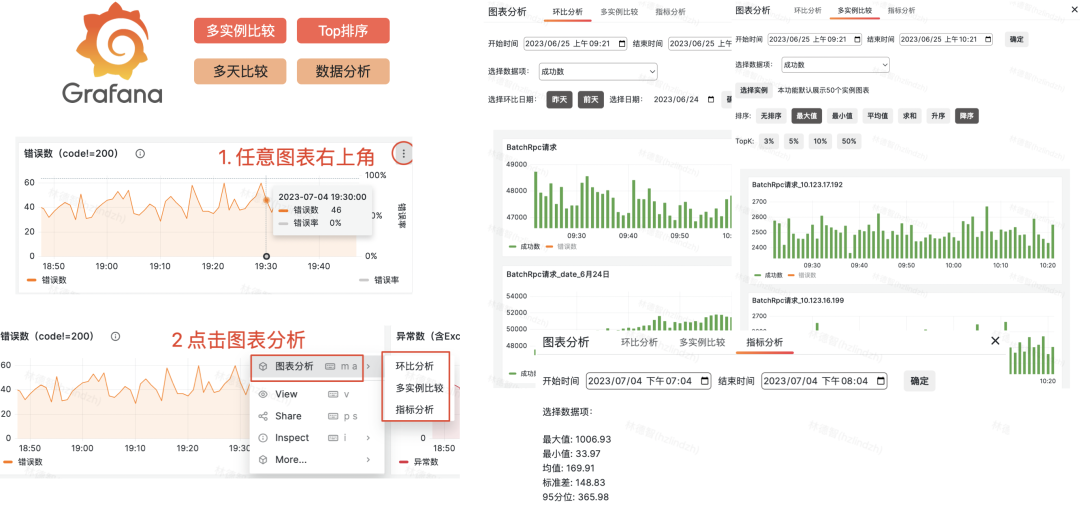
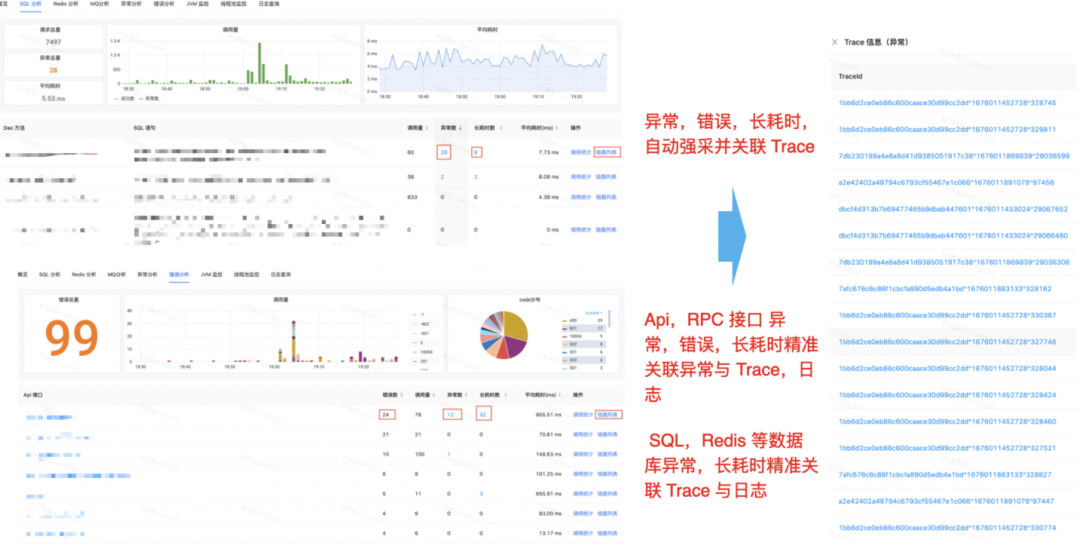
3)异常错误长耗时关联分析
为了解决目前查找异常监控点相关链路时,找不到可用链路,导致问题定位进展困难的问题。我们平台打通了监控数据与关联的TraceId,让使用方能够快速的找到关联链路,推进问题定位。平台提供了监控大盘图表,以及相关的下钻链路检索,用户可以在界面上定向检索关联的异常链路TraceId,每个TraceId下钻后,会到达详细的Trace详情页。
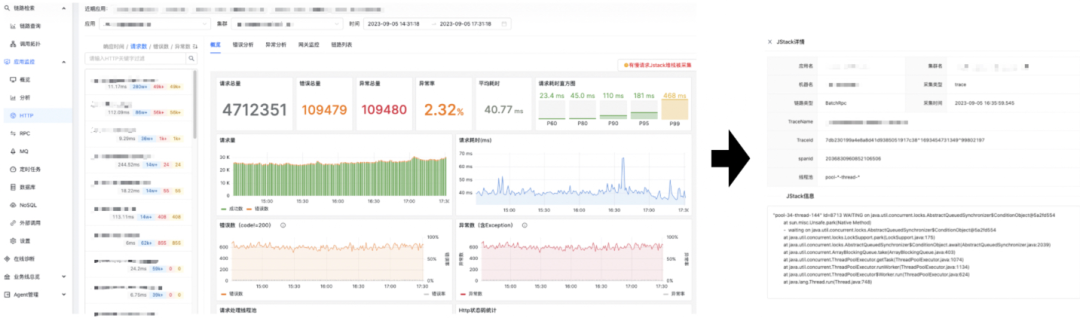
4)耗时请求Jstack追踪
触发了自动Jstack采集的方法,在平台上会给出提示文案。每个具体的Jstack采集结果,有详细的堆栈信息,关联的Trace上下文信息以及线程池信息。除开自动Jstack采集,平台还支持主动下发Jstack请求,主动抓取现场。
5)Arthas在线诊断
平台还集成了Jstack,Arthas等使用频率较高的定位工具。通过Agent连接,用户可以在平台上使用工具直接对服务进行信息采集。采集结果被收集后,平台提供更友好的展示和进一步分析的能力。

三、项目总结
在项目的开发学习过程中,我们积累沉淀了一些线上问题定位的方法论,总结了很多针对服务端问题定位的流程与工具。我们希望能够将这部分经验通过产品的形式呈现出来,来帮助面对问题无从下手的同学,通过路径引导快速得到问题信息。对于有一定问题定位经验同学,提供更加易用,更加高效定位工具,打通定位流程上的各个环节。最终达到快速定位发现线上问题,快速止血的目标。
当然,线上服务治理不是光靠单一平台就能完全覆盖的,Pylon大平台下还提供了业务日志、监控分析、告警治理、场景事件等多个子平台,来帮助我们更好地进行线上服务治理。我们会在后续的文章中,逐一介绍这些平台的建设实践。

