龙芯2/Nehalem处理器架构深度对比分析
【IT168评测中心】相信大家都有听说过龙芯的名字,作为中科院计算所(Institute of Computing Technology, Chinese Academy of Sciences)设计实现的基于MIPS指令集的处理器,从2002年开始,龙芯已经推出了两代(龙芯三目前仍未出现市场)。目前最新的市售型号为龙芯2F,主频达到了1GHz。

Godson-1A,龙芯以数字+字母作为型号
龙芯一开始的英文名叫做Godson(翻译为中文是天之子?),早期内部人员爱称为狗剩(音译……),在06年11月,龙芯的英文名定为Loongson(中文名音译过去……),在学术界则仍然使用Godson的名字。
意法半导体生产的龙芯2E,处理器表面有Loongson、ST和ICT的标志
作为一款通用处理器,理论上我们可以在PC/笔记本/服务器/网络设备等各个领域上都见到它的身影,实际上也已经有少量的龙芯笔记本。我们IT168评测中心对龙芯处理器做了微架构上的简析。
在谈到MIPS的时候,它意味着一种RISC(Reduced Instruction Set Computing,精简指令集)处理器,一种指令集,同时,MIPS又是一间公司。MIPS处理器是一种很流行的RISC处理器,而MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without Interlocked Piped Stages),其机制是尽量避免流水线中的数据相关导致的互锁问题。它最早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。
MIPS 79R4400MC处理器,顶盖上的积分符号显得极具学院气息
龙芯一开始是一款MIPS-like(类MIPS)处理器,这个后缀like是非常重要的,在2005年(龙芯2C之前),ICT(计算所)并没有MIPS公司的许可证,因此有4条被专利保护的指令不能实现,因此只能称为MIPS-like处理器,换一种方式叫做95% MIPS Compatible(95% MIPS兼容)。这四条指令是lwl, lwr, swl, swr,属于访存地址不对齐(Unaligned Memory Access)的指令(32位模式为4条,64位模式为8条),这些指令的美国专利保护在2006年到期。龙芯1是32位处理器,龙芯2是64位处理器。
Sony PS2上的EmotionEngine可能是最为一般人熟知的MIPS处理器
2007年,ICT通过ST意法半导体获得了MIPS的授权,龙芯2成为了MIPS-compatible(MIPS兼容)的处理器(就像AMD等厂商的处理器叫做x86兼容处理器一样),目前的龙芯2F指令系统主要由以下四个部分组成:
(1)MIPS III指令集;
(2)独有的普通用户态指令,如乘累加指令(MIPS IV中定义了乘加指令,但龙芯2号没有采用)等;
(3)部分与处理器结构紧密相关的核心态指令,如对Cache或TLB操作的指令(这些指令一般随结构的不同而不同,即使在MIPS的不同处理器中也是如此)以及在未来的龙芯3号中进行多核之间同步和通信的指令等;
(4)龙芯独有的多媒体指令。
在实现上,龙芯指令集也和一般的RISC不同,实际上,和最近的x86 CISC倒有些不谋而合:采用了微代码设计,也就是说,处理器基于的指令集和内部微架构运行的指令并不不相同,它们需要经过一个解码阶段。下面就大致从指令拾取开始介绍龙芯2的微架构,并对比着Intel的最新CISC x86指令集处理器:Nehalem处理器对比,相信更容易理解一些。和以前所说的一样,这些内容就经过了笔者的多方面查证以确保具有较高的准确性,然而由于内容太多,错漏难以避免,欢迎读者们一一指出。
(最新版本)
Intel Nehalem-EP处理器首发深度评测
(上文的原始版本)
2008年度评测报告:深入Nehalem微架构
首先我们需要清楚地知道,和Nehalem一样,Godson2是一款OOOE(Out of Order Execute)乱序执行的Superscaler超标量处理器,不同的是Nehalem是CISC架构而Godson2是RISC架构。一般而言,由于RISC架构指令集比较简单,因此设计比较简洁,可以达到相对较高的频率(如,IBM的PowerPC 6+可以达到5GHz以上的频率),Godson2的流水线深度为9级,比一般的RISC处理器略高,它们依次是:fetch拾取、pre-decode预解码、decode解码、register rename寄存器重命名、dispatch分发、issue发射、register read读寄存器、execution执行、commit提交。大致上,它们可以分为取指(Instruction Fetch)、解码(Decode)、执行(Execute)、串行顺序回退(Retire)这四个阶段。
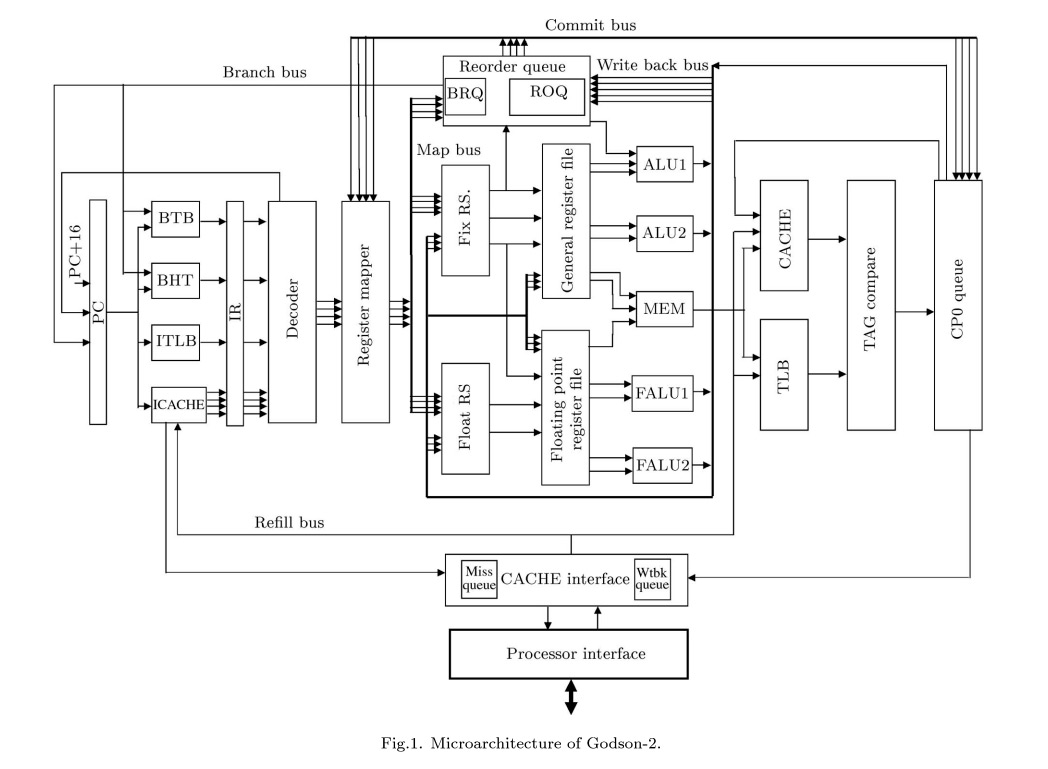
Godson-2 Microarchitecture
注:通过类RISC架构和深流水线,CISC处理器也可以达到很高的频率,如Pentium 4。为什么深长的流水线可以达到更高的频率呢?如果流水线短的话,电信号在单位时间内需要传输经过的元部件相对要更多、更远,所要求的元件延迟要更低、频率更高。深长流水线则反之。代价就是晶体管数量的增多,导致功耗增加,并且流水线堵塞的话,清空流水线带来的代价较大。

Nehalem Microarchitecture,经笔者整理
可以发现,它们是有不少相似之处的。龙芯2借鉴、集成了大多数现代处理器的典性架构设计。需要特别说明的一点是,一般的RISC用Big-Endian架构比较多,所有的x86处理器都是Little-Endian架构。Big-Endian和Little-Eendian这两个术语来自Jonathan Swift在十八世纪的嘲讽作品《Gulliver's Travels》(《格列佛游记》),书中Blefuscu帝国的国民被根据吃鸡蛋的方式划分为两个部分:一部分在吃鸡蛋的时候从鸡蛋的大端(big end)开始,而另一部分则从鸡蛋的小端(little end)开始,并因意见不同而引发了六次内战。我们一般将endian翻译成“字节序”,将big-endian和little-endian称作“大尾”和“小尾”。
大尾和小尾有什么用呢?在设计计算机系统的时候,有两种处理内存中数据的方法。叫作little-endian小尾段的方法中存放在内存中最低位的数值是来自数据的最右边部分(也就是数据的最低位部分),大尾段则相反。x86的CPU使用的LE被Windows中称为“主机字节序”。网络传输使用BE,因此BE也常被成为“网络字节序”。和一般的RISC处理器不同,MIPS兼容架构同时支持两种字节序,并具备BE和LE的切换指令。龙芯2实现了Little-endian数据架构。
Fetch & Prefetch
拾取与预解码
处理器在执行指令之前,必须先装载指令,这就是Fetch阶段,通常是流水线的第1级。指令会先保存在L1缓存的I-cache(Instruction-cache)指令缓存当中,Godson2的L1 I-cache容量为64KB(D-cache同样为64KB),比Nehalem大一倍。和Nehalem一样,Godson的指令拾取单元使用128bit带宽的通道从I-cache中读取指令——一次可以读取4条指令(也和Nehalem一样)。Godson2的I-cache采用和Nehalem的I-cache一样都采用了4路集合关联(不同的是Nehalem的D-cache是8路集合,Godson2 D-cache仍然为4路),我们知道Nehalem这种比Core更少的集合关联数量是为了降低延迟。
Godson-2 Microarchitecture
通过PC(Program Counter,程序指针)拾取到指令之后,指令被发往Instruction Register指令寄存器,并进入下一个阶段:pre-decode,这个阶段的存在是为了实现分支预测功能,分支预测是为了充分发挥乱序执行效能而出现的功能,通过预测如if then这样的语句的将来走向,提前读取相关的指令并执行的技术,可以明显地提升性能。
龙芯2具有16个条目的BTB(Branch Target Buffer,分支目标缓冲区)和4K条目的BHT(Branch History Table,分支历史表),BTB用来保存预测指令的地址,BHT则统计历史分支。Nehalem具有两层BTB结构,不过细节不详。BHT包括了一个9位的GHR(Global History Register,全局历史寄存器)和实际保存4K条目内容的PHT(Pattern History Table,原历史表)。

Nehalem RSB:重命名的返回堆栈缓冲器
在Nehalem上,与BTB相对的是RSB(Return Stack Buffer,返回堆栈缓冲区),而MIPS指令集并没有Call和Return指令,分支由通常的Branch/Jump/Link以及jump register 31指令来实现,然而龙芯2上通过特别的方法也实现了和RSB对应的RAS(Return Address Stack,返回地址堆栈),它在预解码到Branch/Link就将PC+8压入RAS,预解码到jump register 31指令就将RAS弹出到PC,从而实现了类似的功能。RAS容量为4个条目,不算多。

Nehalem: Fetch
指令拾取单元使用预测指令的地址来拾取指令,它通过访问L1 ITLB里的索引来继续访问L1I Cache,龙芯2具有16条目的ITLB,Nehalem具有两层TLB:L1具有128条目的小页面ITLB(按照两个线程静态分区)和7条目的全关联(Full Associativity)大页面ITLB,这些TLB用于访问2M/4M的大容量页面;L2 TLB则和L2缓存一样,指令/数据共用。
预解码结束之后将会被送往下一个流水线阶段:解码。
Decode
解码
解码是很有意思的一项设计,通常是类RISC处理器才有的一项设计,从Pentium Pro开始在IA架构出现,基本上,它是x86处理器独有的产品。
RISC架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过流水线设计来达到很高的频率(例如内部类RISC设计31级流水线的Pentium 4处理器……当然Pentium 4要超过5GHz的屏障需要付出巨大的功耗代价),IBM的Power6就可以轻松地达到4.7GHz的起步频率。关于Power6的架构的非常简单的介绍可以看《机密揭露:Intel超线程技术有多少种?》。和RISC相反,CISC指令的长度不固定,执行时间也不固定,这样设计的流水线效率就不会高,因此Intel就实现了一个RISC/CISC混合处理器架构:通过解码器将x86指令翻译为类似RISC的指令,按照RISC的方式设计和运行,从而获得RISC架构的长处,提升内部执行效率。
通常的RISC指令由于简单,因此都是直接运行而不需要进行解码(通常其标明“解码”的阶段其实是上一页“预解码”的工作:确定分支指令/提取参数/指令依赖性检测),然而龙芯2不同:它具备一个真正的解码阶段将MIPS指令翻译为龙芯2的内部指令(后面用微指令来指代),这一点看起来和现在的CISC处理器很相似。Intel的内部指令称为Micro Operation——micro-op,或者写为µ-op,一般用比较方便的写法来替代掉希腊字母:u-op或者uop。相对地,一条一条的x86指令Intel就称之为Macro Operation,或macro-op。
Godson-2 Microarchitecture
类似地,AMD的处理器也通过解码器将x86指令翻译为自己的内部指令,并且和Intel的不相同。内部指令集的选取和微架构息息相关,如何实现足见体现出设计团队的功力。内部指令的存在也让不停增加新的指令更为方面,只需要更新解码器的解码表即可。然而,解码器的存在无疑增加了新的流水级,并且很容易成为瓶颈——x86架构上解码器一直都是瓶颈,因为复杂的x86指令可以解码出非常多的微指令来(当然,将以前无解码器时的微架构设计上的困难集中转移到解码器上确实是一个进步)。
Nehalem的解码器是4个:3个简单解码器加1个复杂解码器,AMD K8则具有三个复杂解码器,龙芯2的数量看起来是四个。为了简化分支管理,每一个时钟周期内只可以解码一条分支指令,整数乘/除指令会被解码成两条微指令。解码是龙芯流水线的第3级。
对于Nehalem的解码器而言,简单解码器可以将一条x86指令(包括大部分SSE指令在内)翻译为一条uop,而复杂解码器则将一些特别的(单条)x86指令翻译为1~4条uops——在极少数的情况下,某些指令需要通过额外的可编程 microcode解码器解码为更多的uops(有些时候甚至可以达到几百个,因为一些IA指令很复杂,并且可以带有很多的前缀/修改量,当然这种情况很少见),下图Complex Decoder左方的ucode方块就是这个解码器,这个解码器可以通过一些途径进行升级或者扩展,实际上就是通过主板Firmware里面的Microcode ROM部分。由于复杂解码器只有一个,因此在碰到复杂指令比较多的时候,Intel的处理器解码效率会下降。
2006年进行的一个研究当中表示,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
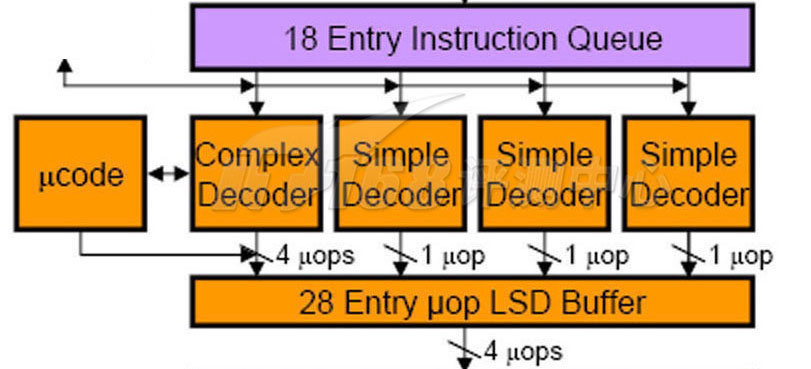
Nehalem: Decode
对x86而言,解码器十分重要。在解码器上,Nehalem做了不少优化,如将多条Macro Ops(就是x86指令)聚合的Macro Fusion和将多条uops聚合的Micro Fusion功能,总的来说是用于降低uop的数量。此外,在各种Fusion之后,Nehalem还会做循环检测,剩下相关指令的、取指、分支预测和解码工作。
Register Rename
寄存器重命名
OOOE——Out-of-Order Execution乱序执行是现代超标量处理器的常用设计(和其相对的是IOE——In-Order Execution顺序执行,典型的如如Pentium和Atom处理器),它有些类似于多线程的概念,这些在《机密揭露:Intel超线程技术有多少种?》里面可以看到相关的介绍。乱序执行是为了直接提升ILP(Instruction Level Parallelism)指令级并行化的设计,在多个执行单元的超标量设计当中,一系列的执行单元可以同时运行一些没有数据关联性的若干指令,只有需要等待其他指令运算结果的数据会按照顺序执行,从而总体提升了运行效率。乱序执行引擎是一个很重要的部分,需要进行复杂的调度管理。
首先,在乱序执行架构中,不同的指令可能都会需要用到相同的通用寄存器(GPR,General Purpose Registers),特别是在指令需要改写该通用寄存器的情况下——为了让这些指令们能并行工作,处理器需要准备解决方法。常见的就是引入重命名寄存器(Rename Register),不同的指令可以通过具有名字相同但实际不同的寄存器来解决,相应地加入流水线的一级就叫做Register Rename,或者Register Renaming。在龙芯2上,这是流水线的第4级。
Godson-2 Microarchitecture
通常,寄存器重命名有两种实现方式:虚拟寄存器(称为Architectural Register或Logical Register)与重名名寄存器独立,或者混合,龙芯2和Nehalem都采用了第二种,它们将虚拟寄存器和重命名寄存器混合在一起,使用一个独立的表来建立重命名寄存器与物理寄存器之间的联系,Nehalem的这个表叫做RAT(Register Alias Table,寄存器别名表),龙芯2的这个表叫做PRMT(Physical Register-Mapping Table,物理寄存器映射表),两个平台上都包含了两个这样的表,不过,用途却不相同,Nehalem的两个表是为了超线程的两个线程而准备,而龙芯2的两个表则是分别用于整数和浮点——它们是分开处理的。
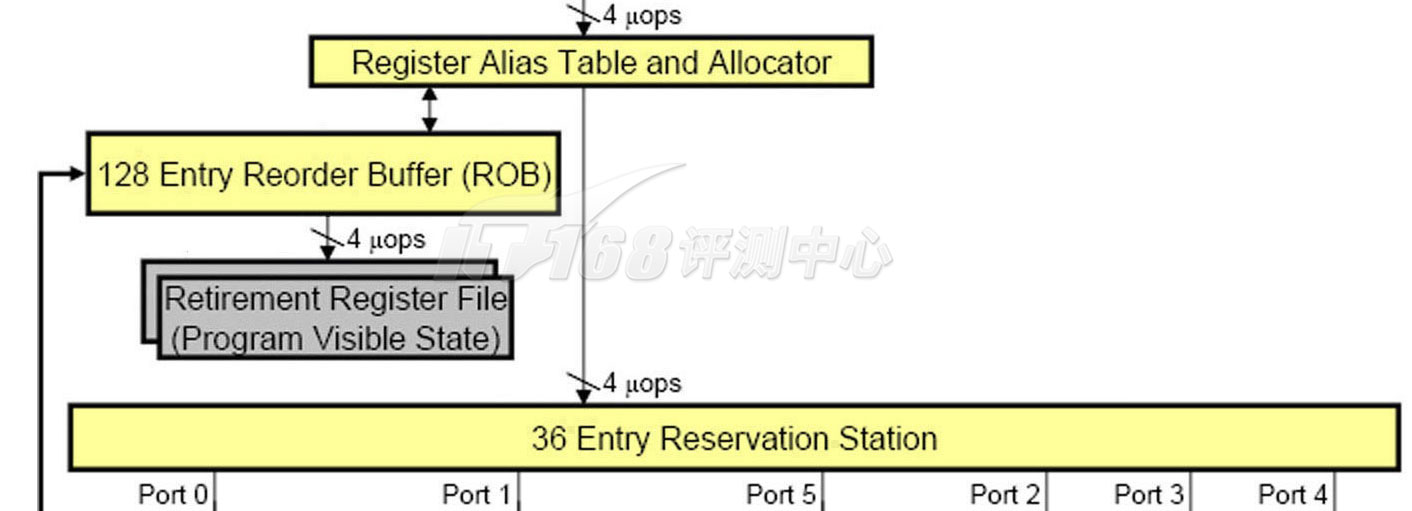
Nehalem: Register Rename(RAT, ROB, RRF)
物理寄存器文件存放的位置也不太一样,Nehalem将其放在ROB附近,龙芯则将其放在Reservation Station(保留站)和执行单元之间。Nehalem的每份RAT包含了128个重命名寄存器,而龙芯2的整数PRMT+浮点PRMT合起来也是128个条目。
Dispatch
分发
在经过寄存器重命名之后,指令们将会被分发到ROB(在龙芯上,对应的部件叫做ROQ——ReOrder Queue),同时发送到保留站,这个阶段叫做Dispatch分发,在龙芯2上是第5流水线级。和Nehalem不同,龙芯2的Dispatch需要按照指令的种类选择发送到整数还是浮点的保留站,而Nehalem具有一个统一的保留站。
Nehalem: Unified Reservation Station
ROB(Re-Order Buffer,重排序缓冲区)是一个非常重要的部件,它是将乱序执行完毕的指令们按照程序编程的原始顺序重新排序的一个队列,以保证所有的指令都能够逻辑上实现正确的因果关系。打乱了次序的指令们依次插入这个队列,当一条指令通过RAT发往下一个阶段确实执行的时候这条指令(包括寄存器状态在内)将被加入ROB队列的一端,执行完毕的指令(包括寄存器状态)将从ROB队列的另一端移除(期间这些指令的数据可以被一些中间计算结果刷新),因为调度器是In-Order顺序的,这个队列也就是顺序的。从ROB中移出一条指令就意味着指令执行完毕了,这个阶段叫做Retire回退,相应地ROB往往也叫做Retirement Unit(回退单元),并将其画为流水线的最后一部分。
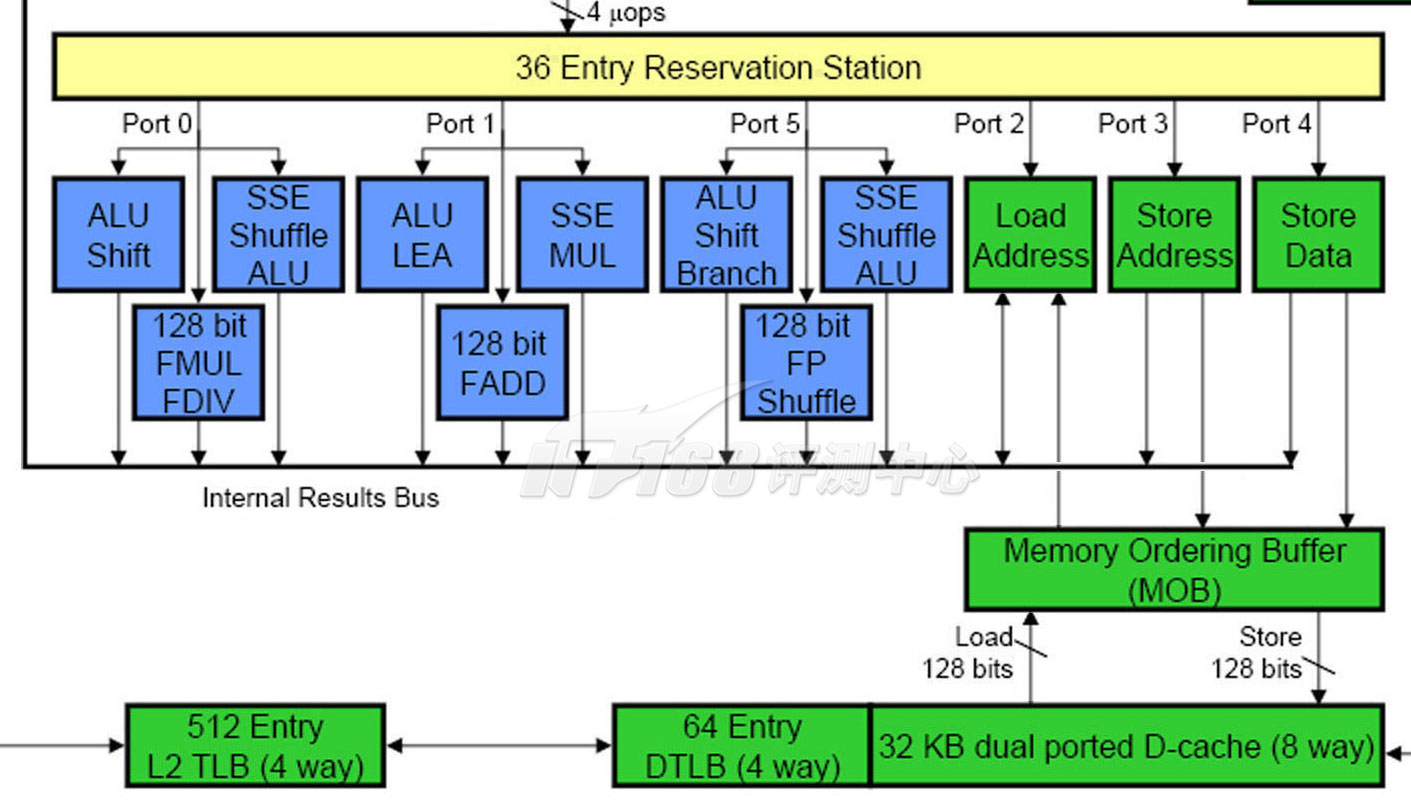
在一些超标量设计中,Retire阶段会将ROB的数据写入L1D缓存,而在另一些设计里,写入L1D缓存由另外的队列完成。例如,Core/Nehalem的这个操作就由MOB(Memory Order Buffer,内存重排序缓冲区)来完成。
Godson-2 Microarchitecture
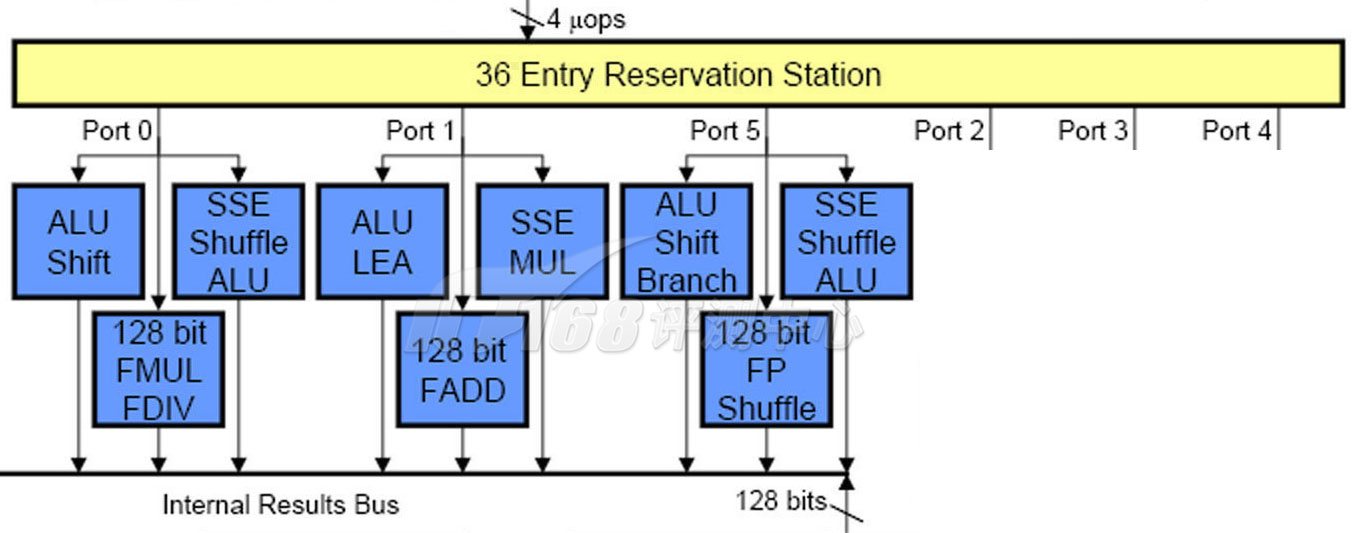
RS(Reservation Station,中继站,Intel文档翻译为保留站)上保存了所有等待执行的指令,Nehalem具有36条目的统一保留站,龙芯2则具有16条目的整数和16条目的浮点保留站,从管理上看,统一的保留站更为复杂些,不过灵活性要更好。
除了存放指令之外,保留站的作用是监听内部结果总线上是否有保留站内指令所需要的参数果。需要读取L1/L2缓存乃至内存的指令或者需要等待其他指令结果的指令必须在此等待。
Issue
发射
Godson-2
所有指令都在Reservation Station中等待执行,龙芯2可以Issue发射最多5条已准备好参数的指令到5个功能单元,而Nehalem则具有6个功能单元。虽然如此,然而龙芯2的每一个Reservation Station每时钟周期只能接受4条指令——而唯一的分发器每时钟周期只能分发出4条指令,因此龙芯2是四发射的处理器。Nehalem也是如此。
现代RISC(类RISC)架构都使用了独立的Load/Store指令来进行内存访问操作,现代x86处理器也是这样。然而MIPS架构具有一些特别的指令需要保持顺序(如CP0等指令),因此MIPS处理器需要在乱序引擎中实现需要的顺序执行功能。和MIPS R10000具有一个独立的In-Order顺序内存操作保留站不同,Nehalem的内存操作使用了统一的保留站,而龙芯2则将内存访问指令发射到整数运算保留站(Fixed RS),它在内部实现了两种顺序关系:wait issue和stall issue,等待发射和堵塞发射。只有特别的指令会具有这两种状态。
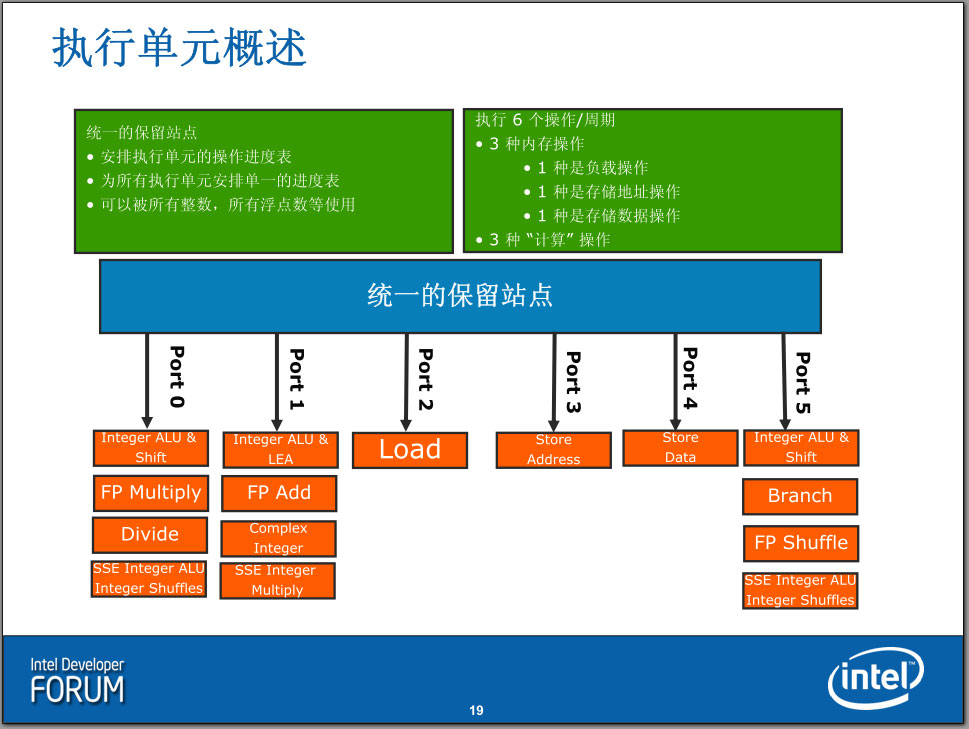
Nehalem: Reservation Station & Load/Store Unit
Register Read
读寄存器
Godson-2
龙芯2具有两个物理寄存器文件:浮点和整数,大小均为64 x 64(64个GPR),发射的指令需要先从寄存器文件读取所需要的参数才能进入执行单元。整数寄存器文件具有6个读取端口和3个写入端口,浮点寄存器文件具有5个读取端口和3个写入端口:因为内存存取指令也使用整数运算保留站,龙芯2拥有一个内存存取单元,同时占用整数/浮点寄存器文件的2个读取端口和1个写入端口,整数和浮点单元分别两个,每个占用对应寄存器文件的2个读取端口和1个写入端口(读取总是要比写入频繁)。在以往,Pentium 4上内存存取操作也部分地由整数单元完成,现在的Nehalem则具有独立的内存操作单元。Intel的浮点和整数寄存器都是用一个寄存器文件,而AMD K8则和龙芯2一样使用分开的寄存器文件。
Nehalem: Reservation Station & Load/Store Unit
Execution
执行
在读取好参数之后,指令们就可以送入执行单元执行了,龙芯2具有两个整数执行单元和两个浮点执行单元,Nehalem则具有三个通用执行端口,每个执行端口都可以进入整数或者浮点指令;AMD K8架构则和龙芯2一样,整数单元和浮点单元具有不同的入口,并使用不同的寄存器文件。
Godson-2:执行单元
整数执行单元包括两个:ALU1和ALU2,浮点执行单元也是两个:FALU1和FALU2,它们的实现细节分别如下(基于2005年的文档):
ALU1:执行整数加/减,逻辑/移位,比较/陷阱以及分支指令,所有的指令都能在1个时钟周期内完成。
ALU2:执行整数加/减/乘/除,逻辑/移位/比较,整数乘使用全流水线设计,执行需要4个时钟周期;整数除使用了非全流水线设计的SRT(以斯维尼、罗伯逊、托克尔三个独立提出算法的人命名)迭代算法,执行延迟从4个到37个时钟周期不等。
FALU1:执行浮点加/减/绝对值/反值/转换/比较以及分支,加/减/转换指令需要4个时钟周期,其它的指需要2个时钟周期。
FALU2:执行浮点乘/除以及平方根,浮点乘采用了全流水线两位Booth编码Wallace树算法,执行需要5个时钟周期。浮点除和平方根都使用非全流水线的SRT算法(和ALU中的一样),执行延迟是4-10个时钟周期(单精度浮点除)或者4-17个时钟周期(双精度浮点除)、4-16个时钟周期(单精度浮点平方根)或4-31个时钟周期(双精度浮点平方根)。
执行单元的算法影响着处理器的性能,特别是需要相对较长执行时间的浮点运算,这方面也比较考验设计团队的实力。据说,龙芯2F还实现了一个SIMD单元。龙芯2F之前通过浮点单元来执行一种龙芯独有的双单精度浮点指令来完成一次计算两个双精度计算。
Nehalem:Superscalar Execution Unit超标量执行单元
Nehalem: "Computional" Unit
Execution
执行
在龙芯2中,浮点寄存器文件和整数寄存器文件之间的移动指令(MTC1、DMTC1等)使用内存存取单元执行。而其它的内存操作则由独立的MEM单元来完成。
Godson-2:一个内存存取单元
Load/Store操作十分频繁,约占所有指令的1/3,因此它的实现非常影响到性能——特别是x86这样GPR比较少的架构中。相比之下GPR数目比较多的RISC结构会好一些,不过龙芯2只有一个内存操作单元显得略少。就大体算法上,它们没有太大的不同。
Nehalem: 三个内存存取单元
它们都使用了预先载入、内存数据相依性预测功能来实现乱序内存操作,下面是Intel的实现例子:
 |
| 数据乱序操作的困境:Load/Store依赖性 |
如上图所示,第一条ALU指令的运算结果要Store在地址Y(第二条指令),而第九条指令是从地址Y Load数据,显然在第二条指令执行完毕之前,无法移动第九条指令,否则将会产生错误的结果。同样,如果CPU也不知道第五条指令会使用什么地址,所以它也无法确定是否可以把第九条指令移动到第五条指令附近。
内存数据相依性预测功能(Memory Disambiguation)
内存数据相依性预测功能(Memory Disambiguation)可以预测哪些指令是具有依赖性的或者使用相关的地址(地址混淆,Alias),从而决定哪些Load/Store指令是可以提前的,哪些是不可以提前的。可以提前的指令在其后继指令需要数据之前就开始执行、读取数据到ROB当中,这样后继指令就可以直接从中使用数据,从而避免访问了无法提前 Load/Store时访问L1缓存带来的延迟(3~4个时钟周期)。
不过,为了要判断一个Load指令所操作的地址没有问题,缓存系统需要检查处于in-flight状态(处理器流水线中所有未执行的指令)的Store操作,这是一个颇耗费资源的过程。在NetBurst微架构中,通过把一条Store指令分解为两个uops——一个用于计算地址、一个用于真正的存储数据,这种方式可以提前预知Store指令所操作的地址,初步的解决了数据相依性问题。在NetBurst微架构中,Load/Store乱序操作的算法遵循以下几条原则:
- 如果一个对于未知地址进行操作的Store指令处于in-flight状态,那么所有的Load指令都要被延迟
- 在操作相同地址的Store指令之前Load指令不能继续执行
- 一个Store指令不能移动到另外一个Store指令之前
这种原则下的问题也很明显,比如第一条原则会在一条处于等待状态的Store指令所操作的地址未确定之前,就延迟所有的Load操作,显然过于保守了。实际上,地址冲突问题是极少发生的。根据某些机构的研究,在一个Alpha EV6处理器中最多可以允许512条指令处于in-flight状态,但是其中的97%以上的Load和Store指令都不会存在地址冲突问题。
基于这种理念,Core微架构采用了大胆的做法,它令Load指令总是提前进行,除非新加入的动态混淆预测器(Dynamic Alias Predictor)预测到了该Load指令不能被移动到Store指令附近。这个预测是根据历史行为来进行的,据说准确率超过90%。
在执行了预Load之后,一个冲突监测器会扫描MOB的Store队列,检查该是否有Store操作与该Load冲突。在很不幸的情况下(1%~2 %),发现了冲突,那么该Load操作作废、流水线清除并重新进行Load操作。这样大约会损失20个时钟周期的时间,然而从整体上看,Core微架构的激进Load/Store乱序策略确实很有效地提升了性能,因为Load操作占据了通常程序的1/3左右,并且Load操作可能会导致巨大的延迟(在命中的情况下,Core的L1D Cache延迟为3个时钟周期,Nehalem则为4个。L1未命中时则会访问L2缓存,一般为10~12个时钟周期。访问L3通常需要30~40个时钟周期,访问主内存则可以达到最多约100个时钟周期)。Store操作并不重要,什么时候写入到L1乃至主内存并不会影响到执行性能。
|
| 图9:数据相依性预测机制的优势 |
如上图所示,我们需要载入地址X的数据,加1之后保存结果;载入地址Y的数据,加1之后保存结果;载入地址Z的数据,加1之后保存结果。如果根据Netburst的基本准则,在第三条指令未决定要存储在什么地址之前,处理器是不能移动第四条指令和第七条指令的。实际上,它们之间并没有依赖性。因此,Core微架构中则“大胆”的将第四条指令和第七条指令分别移动到第二和第三指令的并行位置,这种行为是基于一定的猜测的基础上的“投机”行为,如果猜测的对的话(几率在90%以上),完成所有的运算只要5个周期,相比之前的9个周期几乎快了一倍。
Commit
提交
Commit提交是流水线的最后一级,在这一级,要把指令们造成的数据变化反映到寄存器/内存上来。和为了顺序提交到寄存器而需要ROB重排序缓冲区的存在一样,在乱序架构中,多个打乱了顺序的Load操作和Store操作也需要按顺序提交到内存,MOB(Memory Reorder Buffer,内存重排序缓冲区)就是起到这样一个作用的重排序缓冲区,ROB和MOB一起形成了一个分布式的Order Buffer结构,有些处理器上只存在ROB,兼备了MOB的功能。
在龙芯2上,ROB和MOB就是架构图上最上方的部分,龙芯2的ROB叫做ROQ(ReOrder Queue,重排序队列),最多可以同时保存32条指令,每时钟周期可以接受4条指令。龙芯2的MOB没有单独的名称,它的容量是16条目。
此外,龙芯2还有一个BRQ(Branch Reorder Queue,分支重排序队列)来管理分支跳转被取消后的重排序。
Godson-2 Microarchitecture
Nehalem:Memory Ordering Buffer
Cache
缓存
Godson-2 Microarchitecture
龙芯2具有128KB的L1缓存(Intel方则一直为64KB,AMD的则多为128KB),分为64KB指令和64KB数据,四路集合关联。它们分别64个条目的数据TLB和16条目的指令TLB。早期的龙芯2支持类似MIPS R5000这样的外部L2缓存,容量从256KB到8KB;龙芯2F集成512KB L2,四路集合关联。
绿色部分都属于缓存相关部分
Nehalem/Core的L1I Cache(L1指令缓存)和L1D Cache(L1数据缓存)都是32KB,不过Nehalem的L1I Cache从以往的8路集合关联降低到了4路集合关联,L1 DTLB也从以往的256条目降低到64条目(64个小页面TLB,32个大页面TLB),并且L1 DTLB是在两个多线程之间动态共享的(L1 ITLB的小页面部分则是静态分区,也就是64条目每线程,是Core 2每线程128条目的一半;每个线程还具有7个大页面L1I TLB)。Nehalem还具有256KB的独享L2 Cache和最多达8MB的共享L3 Cache。
Memory
内存
Godson-2 Microarchitecture
龙芯2是一个64位MIPS兼容处理器,不过64位的内存寻址几乎很少用到,因此龙芯2实现了40位虚拟寻址和36位物理寻址,36位物理寻址就和x86的PAE模式一样,最大内存支持是64GB,不算高,不过够用了。龙芯2F实现了集成DDR2内存控制器。
Nehalem:集成内存控制器
Nehalem实现了三通道DDR3 1333(Nehalem-EX是四通道)集成内存控制器,必须说,这部分包括在架构上的东西是明显影响的存在,虽然x86更渴求内存带宽,不过内存存取无论对哪些架构来说都是至关重要的,这部分上龙芯2还有一大段路要走。
【IT168评测中心】从微架构和架构来看,龙芯2是可圈可点。龙芯2是一个64位、4发射的乱序执行的MIPS兼容RISC处理器,龙芯2F型采用了90nm制作工艺(更早期型号使用了0.18um/0.13um工艺),晶体管数量达到了5100万个(集成DDR2-667内存控制器),功耗很低,1GHz时为4W。
Godson-2F,可见看见远方的AMD南桥
作为一款通用处理器,有足够的出货量才能形成一个良性循环(半导体与半倒体:有量才能生存的世界),从这点来看,广泛的应用是必须的。龙芯2就缺乏应用性,而桎梏龙芯广泛应用的最大问题就是软件问题(软件:生态环境的重要性)。就上网本和笔记本市场而言,龙芯2前景不算广大(Linux系统),它应该将目标放在如路由器这样的嵌入式市场上,或者,一些低功耗服务器。据说未来的龙芯3可以支持x86虚拟化,假如实现的话,将可以应用Windows系统,如此其应用程度应该会有较大的提升。

