直联架构的威力 Nehalem-EP处理器解析
【IT168评测中心】2008年11月17日,Nehalem处理器架构随着Core i7(代号Bloomfield)的发布而正式走到前台。Nehalem架构是一个大家族,包含了从移动计算到高端服务器领域,按照计划,紧跟着Core i7后面发布的,就是面向二路及二路以下服务器市场的Nehalem-EP处理器,代号为Gainestown。Gainestown处理器将会使用Xeon 5500的系列名称。
 |
| Nehalem平台——Core i7 920与搭档Intel X58主板 |

Nehalem-EP Xeon E5540(左)与Core i7 920(右):这两个处理器很相像
几天前,我们曝光了Nehalem-EP处理器——Xeon E5540的实物,并给出了基于X58主板的上机图,我们发现Nehalem-EP和Core i7非常之相像——基于同样的架构、外观。业界对Nehalem的架构已经非常了解了,然而Gainestown相对于Bloomfield仍然有一些细节上的不同,此外,相对于上一代基于45nm Penryn架构的Harpertown(Xeon 5400系列处理器),还有不少人不太清楚其具体的区别。因此我们感到有必要对它们的架构进行一个对比分析。
要了解一款处理器,可以先看它的规格表。在Nehalem-EP 新Xeon 5500处理器首度曝光中我们已经有了一个简单的表格介绍Nehalem-EP/Gainestown处理器的规格,不过这个规格表不是非常完善,而且只有Nehalem-EP部分的数据,因此我们整理了以下表格,包括了Core i7/Bloomfield、Xeon Harptown和Nehalem-EP/Gainestown的完整处理器资料:
Intel Core i7/Bloomfield规格表 | ||||
名称 | Core i7 920 | Core i7 940 | Core i7 Extreme 965 | Core i7 Extreme 975 |
| 系列 | Nehalem/Core i7 | Nehalem/Core i7 Extreme | ||
| 每系统数 | 1 | |||
| 频率 | 2.66GHz | 2.93GHz | 3.20GHz | 3.33GHz |
| QPI速率 | 4.80GT/s | 6.40GT/s | ||
| Turbo Boost | ○ | |||
HTT(SMT) | ○ | |||
核心/线程 | 4/8 | |||
L2缓存 | 4 x 256KB | |||
L3缓存 | 8MB | |||
| TDP | 130W | |||
普通的Core i7和Core i7 Extreme的区别就在于主频,以及QPI总线规格。

45nm Harpertown Xeon的型号众多,可以按照FSB分为1333MHz(5400)和1600MHz(5402),或者分为低电压版和普通版。不同型号的差别只是在于主频、FSB总线和TDP。
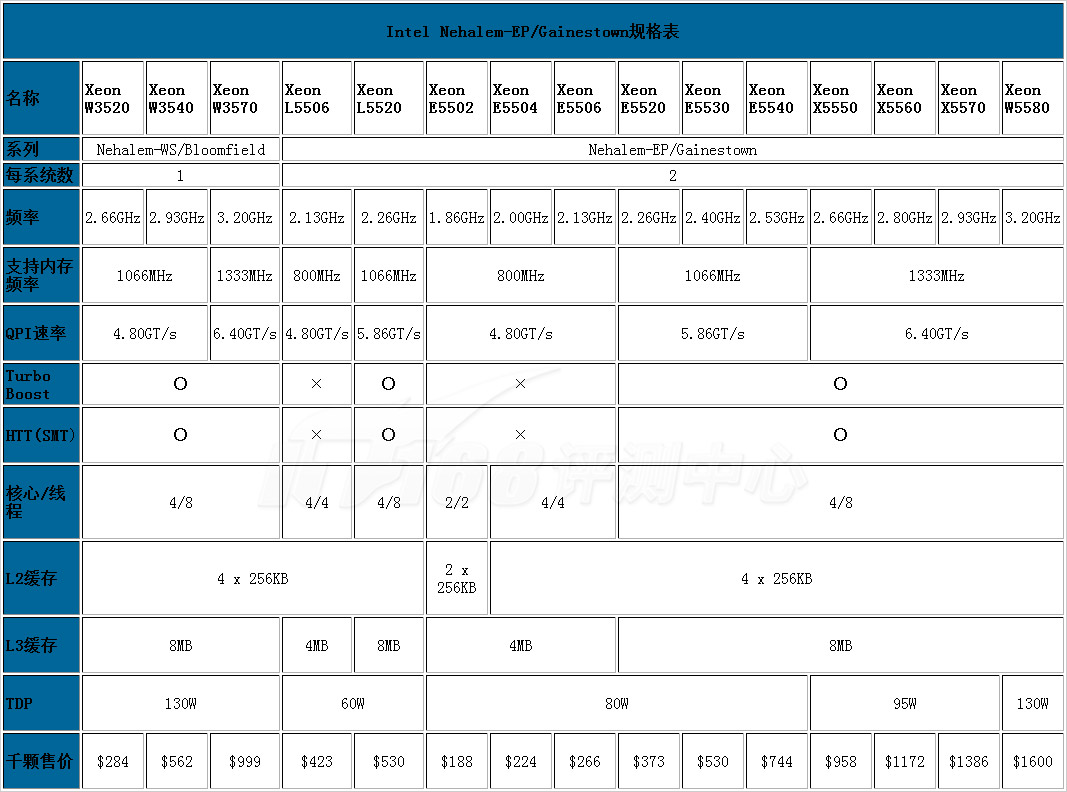
上表除包括了Nehalem-EP/Gainestown之外,还包括了Nehalem-WS——这一系列CPU也属于Bloomfield,不过是面向Workstation市场,它们和Nehalem-EP的区别就是它们只支持一路处理器系统。不同型号的差别在于主频、QPI总线(有三种)、L3容量(有两种)和TDP(有四种)。Nehalem-EP也提供了两款低电压版型号。Nehalem-EP还提供了一款双核的型号,此外并不是所有的Nehalem-EP都搭载了HTT超线程技术(同时和Turbo Boost技术)。
我们都知道了,Nehalem和Intel以往处理器相比最大的特点就是直联架构——包括两个方面:处理器直联以及内存直联,前者就是依靠QPI总线的实现,后者则是由于处理器内置了内存控制器(IMC,Integrated Memory Controller)。
Nehalem采用直联架构已经不是新闻了,不过,为什么直联架构会带来性能上的飞跃呢?相信这一点大家可能三就不是很了解了。

Nehalem的直联架构

旧的Xeon的架构
很久很久以前,在一个记忆体短缺的时代——不仅仅处理器外面记忆体很少,处理器里面也是。使用了CISC架构的x86处理器里面只有8个GPR通用寄存器(一般的RISC处理器有32个以上的通用寄存器,现在的x86-64有16个通用寄存器),由于通用寄存器数量上的短缺,因此不像RISC处理器那样,CISC的x86处理器使用了堆叠运算指令。堆叠运算也就是将运算结果保存在源寄存器上的,如ADD AX, BX指令会将AX寄存器与BX寄存器的内容相加,并将结果保存到AX上——这样对比于使用三个寄存器做同一运算的非堆叠指令RISC架构就节约了一个寄存器,然而相应地源寄存器的内存就销毁了。x86架构需要执行大量的Load/Store微指令(Pentium Pro开始具备)来进行寄存器-寄存器或寄存器-内存之间的数据搬运操作。RISC处理器当中,Load/Store操作也很频繁。
2006年进行的一个研究当中表示,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
mov、push、pop都是和load/store直接相关的,add、cmp等则间接相关
顺便:
75%的x86指令短于4 bytes,也就是小于32 bits。不过这些短指令只占代码大小的53%——有一些指令非常长
单操作数指令占37%,双操作数指令占60%
双操作数指令中,直接数操作20%,寄存器操作数56%,绝对寻址操作数1%,间接寻址操作数23%
现在来看这样的设计简直是无法想象,不过这样脑残的设计不仅仅用到了今天,而且还加速到了一个不可思议的境界……在与各种RISC架构处理器的交锋也不落下风……回到架构上,由于x86架构实际上是通过耗费寄存器带宽及缓存-内存带宽来节约处理器内部寄存器数量,大量的Load/Store操作(Load操作占据了x86 uops当中的约30%),对缓存乃至内存的性能非常依赖。
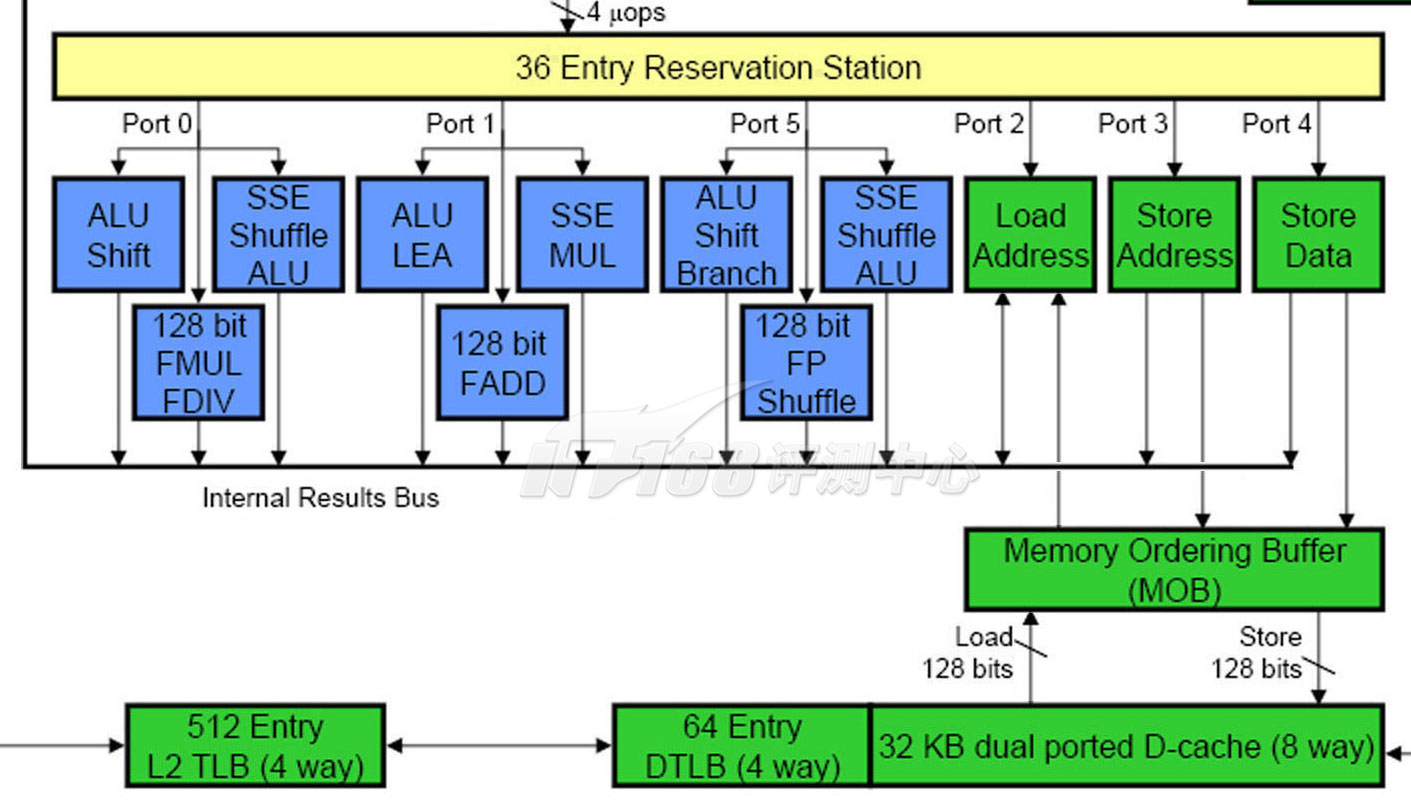
Nehalem具有三个Load/Store单元以及一个MOB架构,并支持内存数据相依性预测功能,缓存性能非常出色
缘此,x86架构在缓存-内存上的提升是不遗余力,不提2008年度评测报告:深入Nehalem微架构中说到的内存数据相依性预测功能(Memory Disambiguation),对于Nehalem而言,这方面最大的改进就是直联架构带来的IMC集成内存控制器,它使CPU到内存的路径更短,大幅度降低了内存的延迟,同时每一个CPU都具有自己专有的内存带宽。这一点在数据库应用中表现非常显著,数据库应用对存储器的延迟很敏感。
AMD使用了集成内存控制器的Operton在推出之后,立刻占据了不小的市场份额。Operton自然也属于x86架构的处理器,因而可见存储子系统对x86架构影响之巨大。
直联架构还隐含的一点是,去掉了FSB(或类似总线)对内存存取的限制,FSB时代,存取内存需要处理器经过FSB总线访问MCH,再访问内存——而FSB总线已经限制了内存带宽的提升。在使用IMC之后,Nehalem的内存控制器立刻提升为三通道(每处理器),同时不同的处理器都具有独立的内存带宽。
多FSB总线上存在的Snoop Filter(探听过滤器)目的是为了降低FSB总线的拥挤程度
直联架构不仅仅意味着处理器与内存直接相连,还让处理器之间也直接联系起来。Hyper-Transport总线的使用让Operton进入了高性能计算市场,QPI所作的事情是一样的。通过QPI总线,处理器之间可以直接相连,不再需要经过拥挤、低带宽的FSB共享总线,多处理器系统运行效率大为提升。 对于多处理器系统而言,QPI提供的巨大带宽对性能提升很有作用。
QPI vs. FSB | ||
名称 | Intel FSB(Front Side Bus) | Intel QuickPath Interconnect(QPI) |
| 拓扑 | 共享总线 | 点对点连接 |
| 物理总线宽度(bits) | 64 | 20 x 2(双向) |
| 数据总线宽度(bits) | 64 | 16 x 2(双向) |
| 传输速率 | 1.333GT/s 10.6GB/s | 6.4GT/s 12.8GB/s 25.6GB/s(双向) |
| 需要边带信号 | 是 | 否 |
| 引脚数 | 150 | 84 |
时钟数 | 1 | 1 |
集成时钟 | 否 | 否 |
总线传输方向 | 双向 | 单向 |
HTT超线程技术出自Intel位于Oregen俄勒冈州的Hillsboro研发中心。Pentium Pro、Pentium 4、Nehalem架构都是出自这个Hillsboro研发中心。Pentium 4和Nehalem搭载的HTT超线程都是同一个东西,都是让处理器可以同时运行多条指令,实际上,它们属于多线程技术中的一个分类:SMT同步多线程。起先,Intel在资料中使用SMT来称呼Nehalem的HT技术,然而SMT实是一个专有名词,并不仅仅Nehalem有采用,于是Intel又改变了主意,又将其称作为HTT超线程。各种典故可以看这里:机密揭露:Intel超线程技术有多少种?。
|
Nehalem的超线程技术就是NetBurst超线程技术的升级版本,和Atom和Itanium的超线程技术都不同
并不是所有的Nehalem处理器都提供了超线程技术,在Nehalem-EP当中,只有末尾是0的型号才具有,是其他数字的就不具备HTT。如L5502是一款双核的、不搭载超线程技术的Nehalem-EP处理器,千颗售价$188,非常便宜。当然值不值得又是另外一回事了。
|
超线程技术可以通过很少的代价提升并行应用的性能,特别是在服务器领域,因此Nehalem在服务器领域的能力将会再一次得到提升。AMD目前并没有类似的技术,因此在未来的对阵当中,Nehalem更被看好些。
虚拟化作为Intel架构的重点,一直是Intel处理器的重要特性,每次处理器架构的更新,都会得到更多的支持。在2008年度评测报告:深入Nehalem微架构当中我们已经提到过:Nehalem的虚拟化改进包括两个部分——EPT扩展页表和VPID虚拟处理器ID,其中前者消灭了当前存在的虚拟机内存操作中存在的大量内存地址转换(以前使用软件来模拟EPT的功能,现在用硬件实现了,据说虚拟化延迟比Penryn降低了33%),后者则减少了对TLB的无效操作,这些都明显提升了虚拟机的性能。
|
|
以往VT-d技术集成在北桥MCH内,和内存控制器的关系非浅
Intel的虚拟化平台包含了三个部分,除了EPT/VPID属于的VT-x虚拟化之外,还有关键的I/O虚拟化VT-d,用于解决I/O设备与虚拟机数据交换的问题,而这部分主要相关的是DMA直接内存存取,以及IRQ中断请求。在以前,Intel提供的设备虚拟化技术(VT-d,VT是Virtualization Technology虚拟化技术,d是device设备的意思)是集成在MCH芯片上面的,现在Nehalem集成了内存控制器,因此其部分功能也就相应地进驻处理器当中——剩下一部分则仍然留在了新的Tylersburg芯片组当中,并且得到了进一步的提升。
Intel 82576EB千兆网络芯片,支持VMDq,支持VT-c
Intel虚拟化平台策略的第三个部分是连接虚拟化VT-c(c是connetive的意思),在Nehalem-EP + Tylersburg平台上,这一点也得到了体现。关于VT-c技术,将另有专文介绍(计划中)。
最后,Nehalem-EP的超线程也是和虚拟化紧密相关的部分:多了一倍的逻辑处理器,可以支持更多的虚拟客户机数,而且,硬件实现的逻辑处理器,要比虚拟机软件虚拟出来的效果要好的多了。
【IT168评测中心】从前面种种可以看出,Nehalem架构最大的特点是实现了直联架构,直接存取内存让x86架构的内存性能再一次得到了飞跃,也让使用x86这种奇怪的指令集的处理器继续生存下去,并进一步加速。直联架构明显提升了Nehalem在服务器市场的竞争力。

Nehalem-EP Xeon E5540处理器

两个Nehalem-EP Xeon E5540处理器
超线程的存在亦然,在竞争对手没有类似技术的情况下,可以大幅度提高服务器应用性能的超线程技术就成为了一个厉害无比的武器。特别是配合虚拟化应用的情况下。
Intel Nehalem/Bloomfield、Intel Nehalem-EP/Gainestown、Intel Nehalem-EX/Beckton | |||||
| Intel Nehalem | Intel Nehalem-EP | Intel Nehalem-EX | ||
工艺 | 45nm | 45nm | 45nm | ||
晶体管数量 | 7.31亿 | 7.81亿 | 23亿 | ||
核心数量 | 4核 | 4核 | 8核 | ||
核心尺寸(宽x高) | 13.0mm x 18.9mm | 13.0mm x 18.9mm | ~20.5mm x ~29.3mm | ||
核心面积 | 246mm2 | 246mm2 | ~600mm2 | ||
每核心面积(不包括L2) | ~24.4mm2 | ~24.4mm2 | ~24.4mm2 | ||
L2缓存 | 4 x 256 KB | 4 x 256 KB | 8 x 256 KB | ||
L2缓存面积 | 4 x 1.78mm2 | 4 x 1.78mm2 | 8 x 1.78mm2 | ||
L3缓存 | 8MB | 8MB | 24MB | ||
L3缓存面积(不包括Tag) | 45.6mm2 | 45.6mm2 | ~136.8mm2 | ||
内存控制器 | 三通道DDR3 | 三通道DDR3 | 四通道DDR3 | ||
IO总线 | 1 x QPI | 2 x QPI | 4 x QPI | ||
Bloomfield和Nehalem-EP的区别在于市场定位——Nehalem-EP定位于服务器市场,因此它可以组建二路多处理器,Bloomfield则不可以,和以前的Pentium III情况不同,并不仅仅是使用线路限制Bloomfield的多处理器能力这么简单,Bloomfield还缺乏Nehalem多处理系统必须的QPI总线:它只有一个,Nehalem-EP则具备两个,因此它们硬件上是有一些不同的,多一个QPI总线让Nehalem-EP的晶体管数量也多一些,达到了7.81亿。除此之外,Bloomfield和Nehalem-EP只是一些细节上的不同,如QPI总线的带宽等。欲知Nehalem-EP性能如何,请继续关注IT168评测中心。

