导读:随着企业数字化转型的深入发展,对用户深层理解的渴望日益迫切。在此背景下,本次分享精心剖析了用户画像标签的精髓及其在多变业务场景中的关键作用。从基础属性标签到策略上的标签,不仅系统性地介绍了各类型标签的构建与应用,还着重强调了在快节奏的数字化时代中,如何通过高效的异常值处理、时间衰减考量及数据区分度提升等手段,确保标签的准确性和实用性。并且深入讨论了如何长期评估和追踪用户画像的内聚性和稳定性,为数据产品经理提供了一把锐利的工具,助力其在激烈的市场竞争中准确把握用户需求,不断提升产品和策略的效能。
01
画像标签介绍
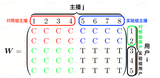
1. 基础属性画像标签
基础属性类画像标签是用户自身属性的标签,通常不与用户在 APP 上的行为挂钩,例如性别、年龄、操作系统、所在城市等。
其建立方式包括:
用户填写:注册时提供的个人信息。
埋点采集:在 APP 上设置埋点收集用户数据。
模型预测:对缺失或采集不到的数据使用模型进行预测和补充。
第三方数据源获取:购买或获取第三方数据源,或是大公司如腾讯、阿里等通过集团内部其他部门获取信息。
基础属性画像标签的应用场景主要包括:
日常分析:用于大致了解用户的属性分布,以及新场景分析、业务发展、异动归因下钻等场景,例如通过标签分析点击率下滑原因,确定是否存在超预期的降幅。
建模用:作为复杂画像的输入特征,用于提高业务操作的精确度。例如搜索排序、用户行为预测等场景。
2. 业务向画像标签
与业务目标(或者说 KPI)强关联的标签,通常基于这样的标签找到业务的目标人群。
可以根据与 KPI 的关联分为两大类:
KPI 强关联(以 MAU 为 KPI 时):高活/低活用户(基于活跃天数),直接反映了用户与 KPI 的关系,如月活跃用户数、首次月活用户、流失用户、沉默用户等。
KPI 弱关联:高中低活跃用户、场景活跃偏好用户(TGI),通过复杂的计算和用户行为的综合评估得出,提供更细致的用户分类。
建设方式包括:
基于 KPI 按照距离目标远近定义用户:直接根据 KPI 的具体要求对用户进行分类。
基于用户行为进行复合计算:综合考虑用户在平台上的多种行为进行用户分类。
使用方式包括:
了解运营目标进度:利用画像标签进行深入分析,了解符合条件的用户数量和接近 KPI 目标的用户。以及通过标签下钻进行 KPI 的预估,并找到实现路径的拆解,帮助预测达成 KPI 的可能性,特别是对难以运营的用户群体进行更深入的分析。
锚定主要的目标人群,便于整体的差异化策略:利用不同的用户群体标签(如高活、中活、低活用户或具有不同购买力的用户)实施差异化运营策略。根据用户特征在搜索结果中展示不同价格的商品,或根据用户活跃偏好将他们引导至不同的场景。
3. 策略向人群
针对特定策略建设⼈群标签,通常能够在 AB 实验中拿到较好的收益。例如:
增益人群:红包敏感的人群,发放红包后 ARPPU 值提升高。
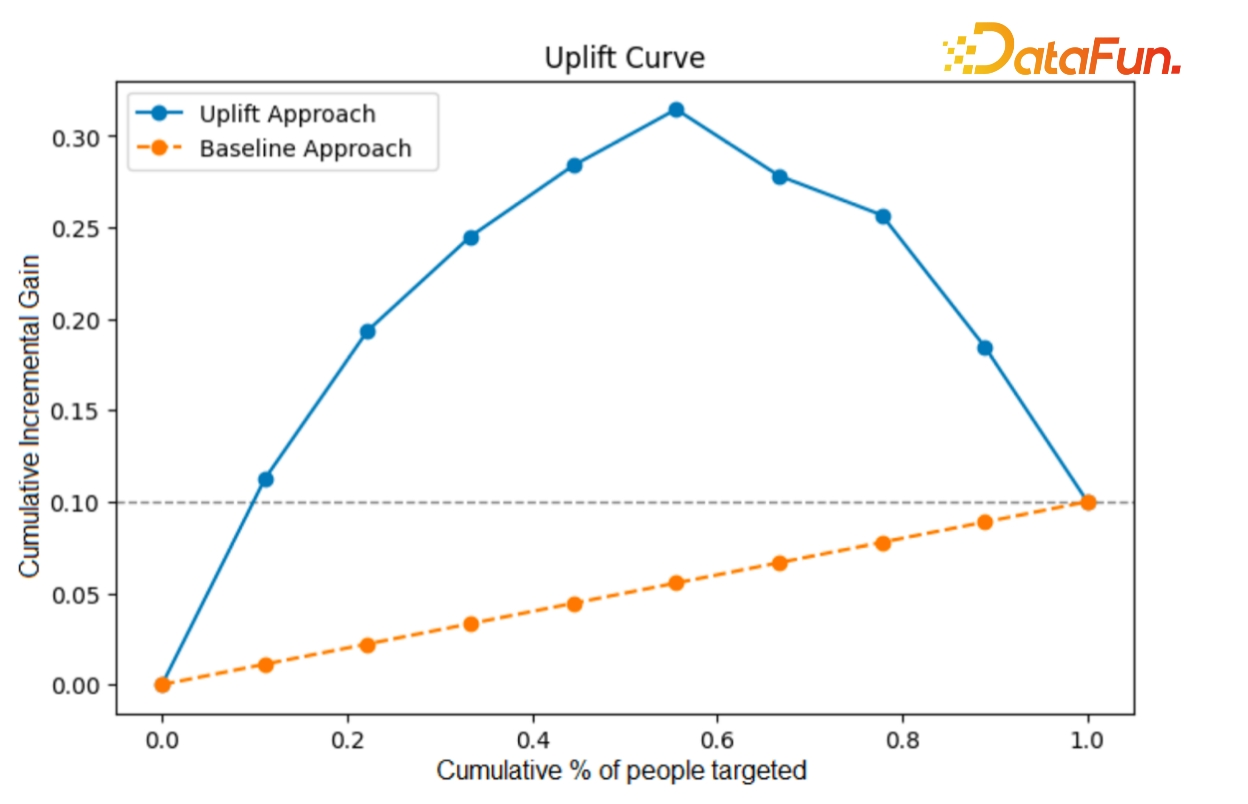
与权益干预相关的标签,可以帮助我们识别那些在接受红包或全域干预后会显示出显著提升的用户群体。通过 AUUC 图的分析,可以预测特定用户群体干预前后的增量以及预期的投资回报率(ROI)。这种预测性的分析可以为策略决策提供坚实的数据支持。
复购人群:在特定类目、特定购买间隔下有高复购倾向的用户。
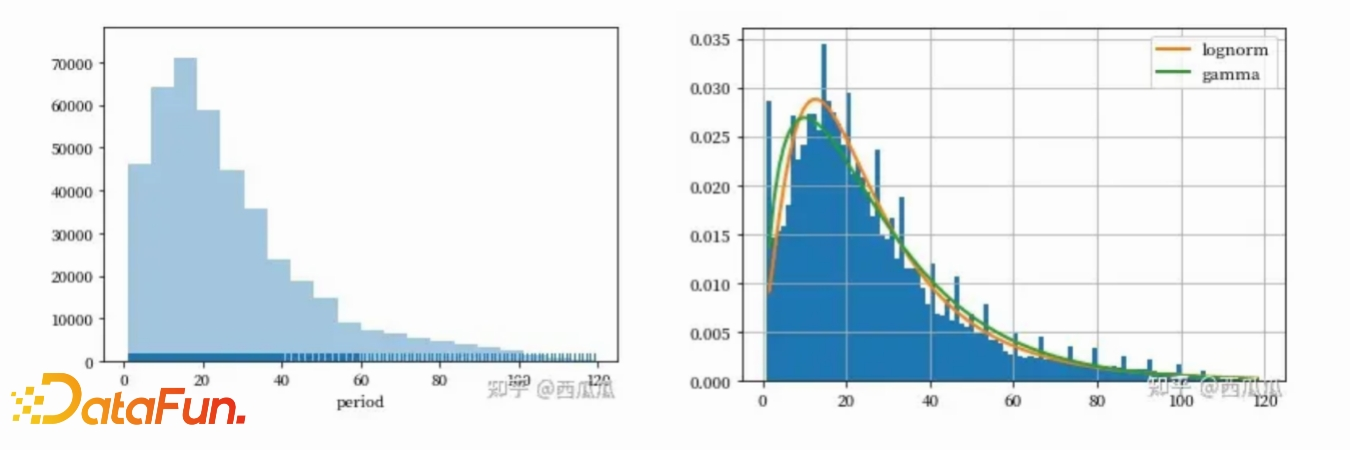
针对电商场景的复购属性用户,会通过分析用户购买某一类目的时间间隔分布,进行统计拟合,预计不同用户的购买间隔。当用户预计的购买间隔接近时,通过适当的引导和干预,可以有效提高用户的复购率。这种策略不仅增加了用户对平台的粘性,还有助于抢占市场份额。
未来预测人群:通过模型预测用户未来的行为/流失概率。
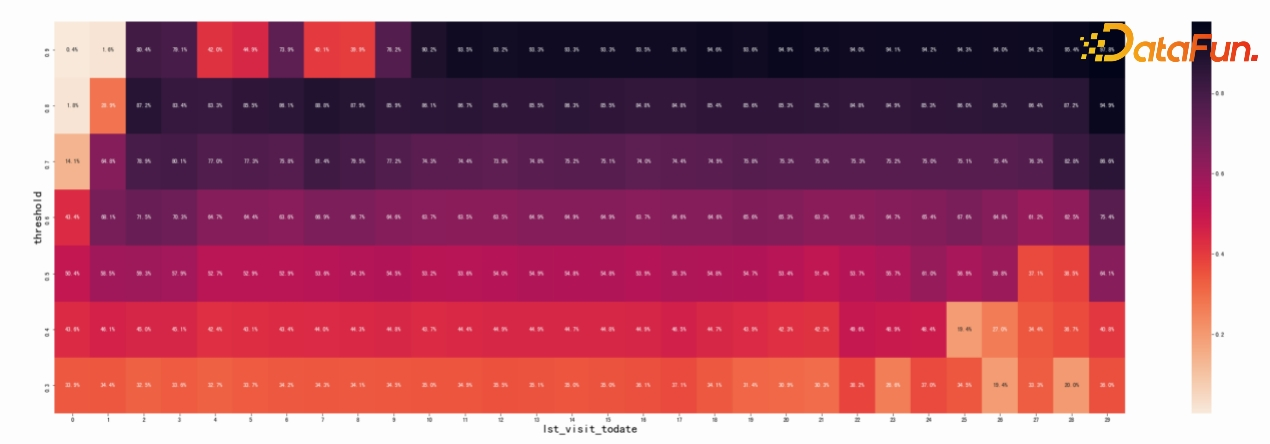
预测类的标签基于用户的历史行为和其他战略特征,预测用户未来的行为模式,如流失或沉默的概率。利用这些信息,可以绘制热力图来表示不同预测分数区间内的用户流失概率和数量。这种方法使我们能够精确地识别出潜在的风险用户群,并对他们实施针对性的运营策略,从而最大化 ROI 和 AB 实验的增量效益。
策略向人群的建设方式包括:uplift 模型、复购周期预测、二分类模型等。
使用方式为:在特定策略(红包/push 干预)下,进行干预的目标⼈群,实现 ROI 的最大化。
02
画像特征的处理与标签的评估
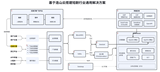
1. 标签特征处理
这里主要介绍一些日常特征处理中容易被忽视的步骤。
(1)数据清洗
异常值检测
这一步骤的重要性常被忽略,但其对提升标签准确性至关重要。检测方法已比较成熟,通常使用箱形图和 AVF,前者主要用于数值型特征,后者主要用于类别型数据。
异常值填充
检测得到的异常值处理方式,一种是丢弃包含异常值的记录,另一种是使用 cap 分位点或 floor 分位点的值替代异常值(例如,用 97% 分位数代替异常大值)。
空值填充
根据指标的定义选择最大值或最小值填充(如 Recency 类指标选择最大值,Frequency 类选择最小值)。
(2)时间衰减处理
用户标签的生成同时参照 RFM 模型中提供的三个维度进行特征构建:
Recency(近度):用户最近一次登录距今天数
Frequency(频率):用户最近 90 天登录天数
Monetary(消费金额,这里引申为强度):用户最近 90 天 APP 内停留时长
处理的目标是让距今更近的行为对分数产生更大的影响。
Frequency 类的指标中有一些代表过去一段时间的累计行为,如过去 90 天的总登录次数,定义按照假如两个用户在这个指标上的数值相同那代表他们的活跃频次是相同的。但需要考虑一个场景,如果用户 A 只在最近 10 天登录了 10 次,用户 B 只在 80 天前登录了 10 次,他们的 F 指标都是 10,可是用户 A 的活跃度直观来看应该更高。如果希望数值上体现这个差异的话,可以对每一天的数据乘以一个权重再进行求和,这个权重是一个随着距今时间增加而衰减的函数。
为了在数值上体现这个差异,可以对每一天的数据乘以一个权重再进行求和,这个权重是一个随着距今时间增加而衰减的函数。公式如下:

(3)平滑处理
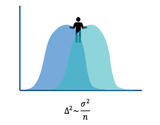
在互联网平台中,用户行为数据通常展现出显著的头部/长尾效应。即绝大多数用户表现出相似的指标特征,而在数据的尾部则存在着很多行为多样的用户群体(数量小但分布广)。此现象导致数据在区分不同用户行为时的能力受限,特别是对于那些行为模式较为独特的用户群体。
因此需要进行平滑处理,其目标是提升数据区分度,以增强模型对用户行为的识别能力。
具体的解决方案为,采用对数函数(log 函数)对原始数据进行平滑处理。对数转换能够减少极端值的影响,使数据分布更加平缓,从而提高数据的区分度。通过对数平滑处理后,数据分布将更加均匀,能够更有效地识别和区分不同用户的行为模式。特别是对于长尾中的小众用户行为,能够更准确地进行识别和分析。
在实施平滑处理时,需注意选择合适的 log 函数以及处理方法,以确保数据转换后能够有效反映用户行为的真实特征,并对模型的预测能力产生积极影响。
通过 log 函数对原数据进行处理,处理前后数据分布对比如下:

2. 画像结果评估
在确定了画像标签后,进行长期的评估或追踪是至关重要的步骤。在特定命题下,可以直接通过 AUC、AUUC、召回等指标准确地评估。但是在非特定命题的情况下,可能无法通过这些指标简单地评估标签质量。日常使用中,通常有两种评估标准,即内聚性和稳定性。
(1)内聚性
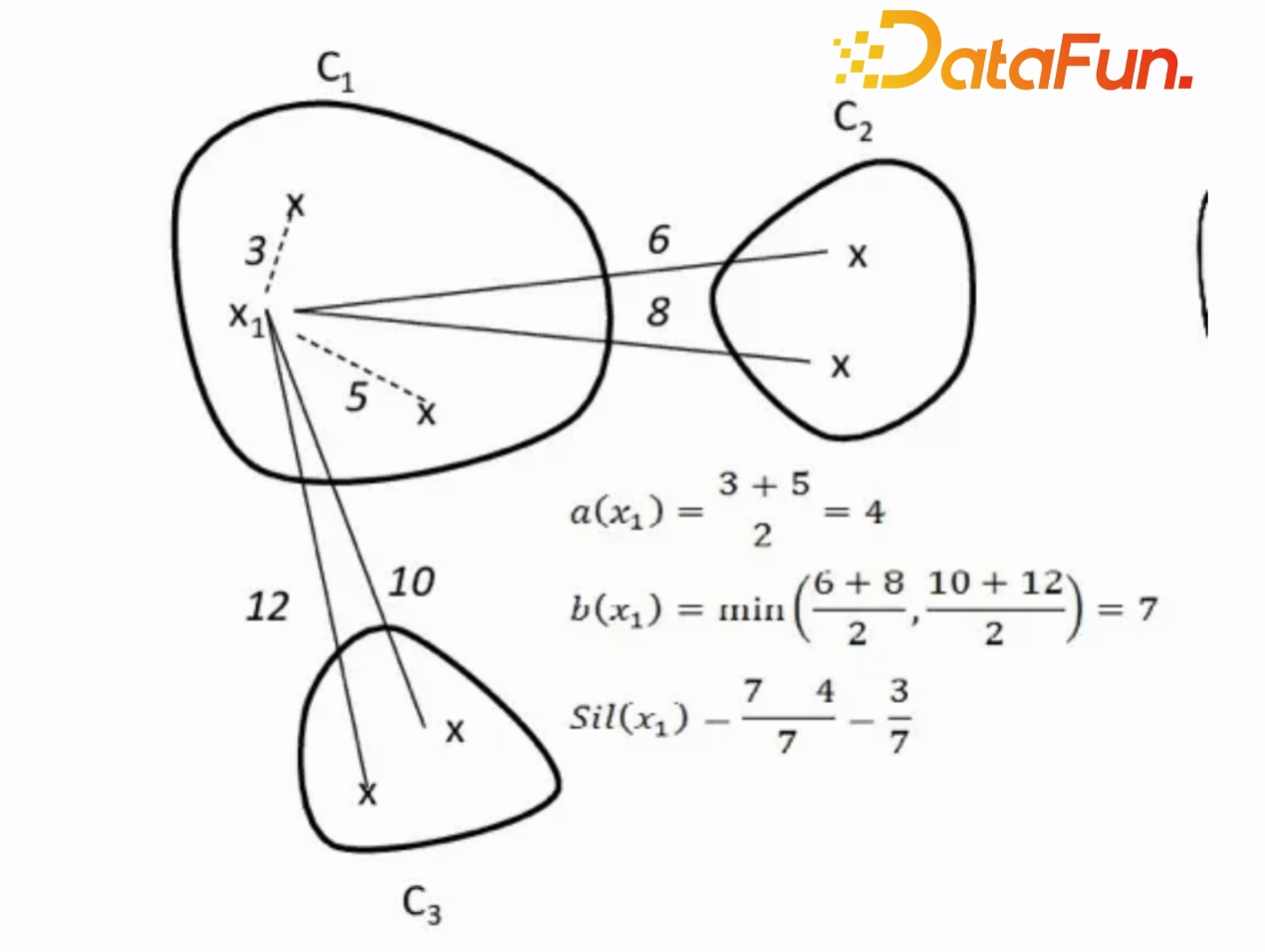
目标:确保同一分层的用户相互间比较相似,而不同分层的用户存在较大的差异,实现高内聚、低耦合的聚类结果。
衡量指标:轮廓系数(Silhouette Coefficient),这个指标能同时衡量类内聚合度和类间分离度。指标越大,表明分层结果越好。
计算方法:对于每一个样本,计算其轮廓系数,然后对所有样本求均值以评估总体的分层结果。这是一个相对指标,适合用于比较两种分层结果的优劣,而不是单一分层的质量绝对评估。

(2)稳定性:
稳定的定义包括两个方面:
分层标准的稳定性:在引入新数据或用户群体增加后,分层标准保持不变,表明分层标准的稳定性。
分层结果的稳定性:不同分层的用户表现应该是稳定的,例如,活跃用户的次留率不存在过大的波动,表明分层结果的稳定性。
稳定性衡量指标:离散系数(Coefficient of Variation),即样本的标准差除以均值。离散系数的值越大,代表波动越大、稳定性越低。
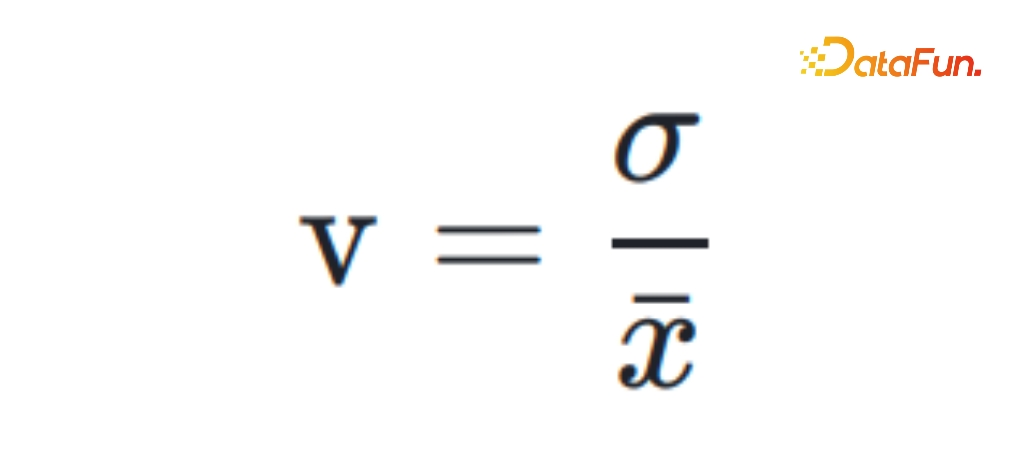
离散系数是一个绝对数值,一般来说,离散系数在 5% 以下时,我们认为这个分层是稳定的。参照稳定性的含义,我们可以基于每个分层用户的表现指标(如次留率)去计算,也可以用分层的边界值计算(如活跃分的 75 分位数)。