货拉拉国际化测试之深度学习实践
一、背景与挑战
随着货拉拉国际化业务市场的飞速扩张和产品的高速迭代,质量保障工作遇到了前所未有的挑战。特别是我们的业务覆盖了13个不同的国家和地区,涉及近20种语言,横跨8个时区,17种支付方式,除了常规的逻辑功能测试之外,错综复杂的‘国际化’因素也大大增加了QA的单一重复性劳动。
1.1 多语言测试挑战
语种数量:受限于熟悉的语种数量,对于陌生的语言,很难分辨APP是否加载了正确的语种。

精准翻译:对于高度相似的翻译,如有个别文字遗漏或者错误,测试人员很难通过肉眼识别。

1.2 多时区测试挑战
时区转换场景多样化:业务的多样性需要不同层级服务对时间做不同的控制转换,大大增加了测试挑战。
跨天业务问题: 如果转化时区后刚好跨天跨月跨年,则以整天整月整年为开始结束条件逻辑可能出现问题。
夏令时问题 : 部分市场有夏/冬令时变化,一旦政策改变,而代码时间没有及时跟进更改,会导致一系列的问题。
多次转换问题 : 国际化的业务链路比较长,服务中还存在时区被多次转换,统一修改特别困难。
1.3 历史工具的局限性
随着业务场景的复杂化,之前针对单个场景开发的数据对比式工具,其局限性就暴露的越来越明显了,例如:
部署复杂: 后端翻译文件对比是一个GUI工具,需要在Window和macOS上独立安装,且依赖较多。
易用性差: 接口级别翻译对比工具,每次需要review代码,找到需要测试的字段key和value值。
依赖性强: App前端翻译强依赖于UI自动化,而UI自动化经常变动,维护工作量很大。
覆盖面低: 时区校验工具只能覆盖一部分后端接口的时区转换检查。
扩展性差: 大部分工具只能解决单一场景,很难通过简单升级解决更复杂的业务场景。
二、整体解决方案
2.1 平台架构
受制于上述工具的局限性,我们急需一套更完整的高扩展性方案来统一解决上述问题。注意到深度学习技术在各行各业得到了创新应用,我们也尝试引入深度学习并不断实践,为国际化AI智能全测平台提供基础的机器学习能力,进而为上层业务场景提供不同的测试解决方案。

平台共分为3大层:客户端、业务层、AI层(AI+底层支持)
客户端: 平台的入口,直接面向用户,主要分为两大块,包括时区工具、多语言工具,以及配套使用的接口录制、定时配置、多语言数据同步等功能,并且可以支持第三方平台的数据同步。
业务层: 平台中层逻辑处理层,连接客户端和AI层的重要模块。包括各数据中心单独预处理的时区、多语言数据的数据格式化、数据特征处理,将处理好的数据提交到AI层,接受AI返回的识别结果并生成报表,以及整体的正确率统计 、 统计报告,并且有专门的噪音优化功能,用以降低人工维护成本,最后提交问题给到对应的开发和测试人员。
AI层: 平台的最核心层,主要用于识别时间字段,时间检查,语言,语言检错等,并且将结果反馈到业务层,能够随时接收数据的正向传播,以及修正结果的反向传播的模块。
2.2 底层实现
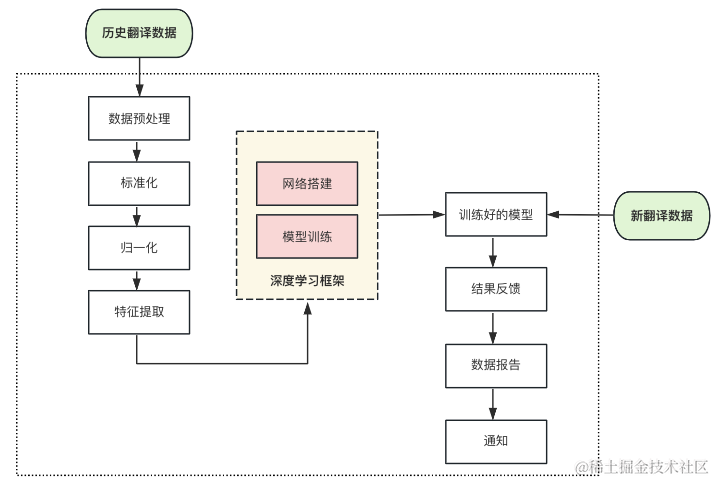
AI底层由深度学习模型支撑,其基本流程就是借助编码器 - 解码器神经网络结构,以词语序列或时区因子等作为训练集输入,结合注意力机制进行网络训练,然后用测试集上的误差作为最终模型在应对现实场景中的泛化误差,不断获得泛化能力更强的网络模型,再通过对误差因子阈值的调整决定模型判定结果,最终输出翻译及时区判定结果,整体的网络结构示意图如下:

三、应用之多语言测试
3.1 解决方案
3.1.1 数据集
在国际化,语言翻译预期结果维护在Crowdin平台上,因此对于多语言翻译数据集,主要由以往需求的已翻译文案及其存放于Crowdin的预期结果构成,并按照8:2比例划分为训练集以及测试集。
比如将“You already have an ongoing order. ”翻译成中文,翻译好的句子分别为“您已有一张进行中订单” 和“您已有一张订单” 和“我进行中订单”,将其组合成三种数据,其中1表示翻译正确,0表示翻译错误:
"You already have an ongoing order. "-“您已有一张进行中订单”:1
"You already have an ongoing order. "-“您已有一张订单”:0
"You already have an ongoing order. "-“我进行中订单”:0
具体的数据预处理步骤为:
导入测试apk,如果该apk是第一次进行语种分类检测,需先获取源码master分支或使用上一版本的apk进行模型训练。如果已有模型数据,反编译该测试apk获取翻译文件数据,然后对比上一版本的翻译文件,获取有变更或者新增的翻译内容,即为检测数据。
对检测数据进行格式化,去掉噪音数据,例如取值符号($),百分号(%),颜色编码(F16622)等与语种无关数据,提高训练数据质量。
对降噪后的训练数据进行分词,以获得量级更大数量更充分的特征词。由于不同语种的差异,例如中文、日语等语种有大量的不重复单个字符,且和其他语种的重复率不高,切分单个词作为特征词就可以作为特征词进行训练。但如果是同一个语系,不同语种使用的单个字符重复率很高,使用单个字符进行分词提取分类的准确率就不太理想,这个时候可以使用二元字符组合作为特征词,这样可以有效的区分同语系不同语种,且能使得特征词的数量增加许多。
3.1.2 模型机制
模型训练:借助于网络分类器能力,选出最有可能的类别,即该类别在当前特征变量的条件概率和先验概率下,后验概率最大。对于本方案,就是计算提取导入的翻译文本进行向量化后,根据模型的特征词和条件概率获取特征变量,再结合每个语种的先验概率,计算该翻译文本的各个语种在条件依赖于当前特征向量的后验概率,后验概率最大的语种类别,即为检测的语种分类结果。
模型预测:使用之前训练好的分类器模型进行语种检测,如果检测数据中有和目标语种不符的数据,输出对应的key-value,在开发人员修正错误后,使用正确的数据通过调整注意力等权重因子重新训练模型,如果没有语种分类不符合预期的数据,检测完毕后直接用新的翻译文件再次训练模型,从而保证模型的不断优化。
3.2 收益
测试流程简洁:无需代码侧介入,通过反编译apk获取翻译文件,无需获取app源码,省去鉴权过程,除此之外,通过上传apk反编译测试,可直接测试目标app,如果在源码侧检测,还需确认分支,简化了测试过程。
测试效率高:高效地完成自动化语种分类检测,覆盖各个语种,人力投入小,且只对更新或者增量的内容进行检测,避免了重复检测。
准确率高:分类器模型基于apk原本的翻译文件数据不断优化,从而保证语种检测较高的准确率。
维护成本低:模型在每次训练优化后自动存储,模型稳定,无需手动跟随需求迭代更新。
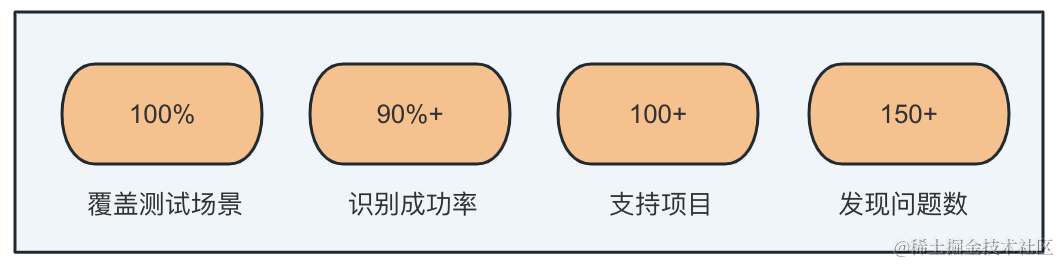
覆盖面广:平台结合机器学习,不需要人工识别多地区语言翻译,能够100%覆盖前后端翻译场景,识别成功率90%+,目前已服务项目100+,发现翻译缺失或者错误问题150+。
四、应用之多时区测试
4.1 解决方案

4.1.1 数据集
在国际化,时区接口中会有多个因子如cityid、marketid、hlang、时间字段、时间戳等(例如:yyyy-MM-dd HH:mm:SS、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS、yyyy-MM-dd HH:mm:ss.SSS、yyyy-MM-dd、yyyy-MM,yyyy/MM/dd等),在实际测试中,我们通过结合多个因子判断出相关该场景对应的时区,这一部分工作,同样可以交给深度学习模型,让深度学习模型从接口提供的多个因子中判断当前场景会应用的时区。具体的数据集构造操作如下:
实时获取最新的时区数据库,获取数据库中各地时区、夏令时的政策,可以解决各地政策变化时,代码未及时调整,导致的时间不准确问题。
将时区因子打散随机组合,按照key-value格式构造时区因子数据集,如:
51001+正确的hlang:西三区
51001+错误的hlang:西三区
61001+正确的hlang:西六区
为提高数据质量更好地进行网络训练,对数据集进行预处理,进行归一化、标准化等降噪操作。
4.1.2 模型机制
模型训练:将时区因子及其预期结果输入到网络模型中,通过由RNN构造的编码器和解码器,逐层训练调整学习因子及注意力因子等,对网络模型进行充分的正向及反向训练,最终泛化得到误差符合预期的网络模型。
模型预测:使用之前训练好的深度模型进行时区判定检测,如果检测结果出现时区误判的数据,同样输出对应的key-value,调整修改该数据集,重新训练优化网络模型。
4.2 收益
维护成本低: 一次录入,重复使用。如果有业务改动时,仅需改动少量参数即可重新运行。
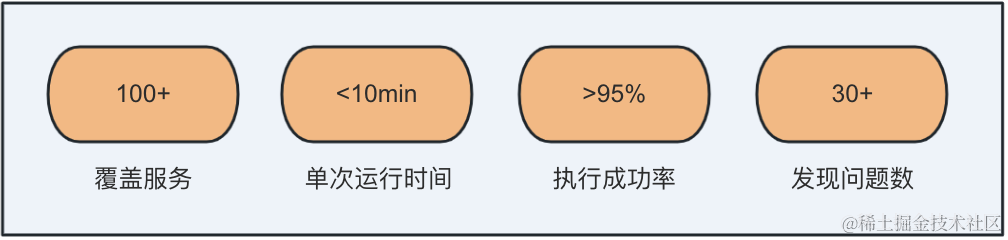
执行效率高: 一次运行时间不超过10min,极大的降低版本频繁迭代导致的人力不足的情况。
发现问题准: 识别时区问题准确率很高,基本不会有误报。
覆盖面积广: 已经覆盖国际化8个时区,覆盖服务100+。
减少潜在资损: 提前发现时区处理错误造成的派券、用券时长超过预期时长,而这些有可能进一步导致超发、超用等潜在资损问题。
五、未来展望
未来,我们将继续利用深度学习能力,进一步帮助技术团队提升业务迭代效率:
提测前,基于深度学习方法如ATLAS等为程序生成单测用例断言,更快地帮助开发验证软件基本模块的准确性,提高冒烟测试的通过率。
测试阶段,借助深度学习网络框架的图文识别能力,基于自然语言的处理解析测试用例,基于网络图像识别的能力和底层引擎驱动完成用例的执行,从而更好地助力UI 自动化测试。
利用深度学习能力解决更多国际化特有的测试难题,比如多支付方式等。

