Intel 32nm Westmere-EP处理器首发评测
【IT168评测中心】近一年前,2009年3月31号,Intel发布了Nehalem处理器架构的双路服务器版本Nehalem-EP(代号Gainestown),时至今日,Intel发布了Nehalem-EP处理器的继任者Westmere-EP。这次Intel确实未提及Westmere-EP的代号,桌面版本对应的则明确为Gulftown。Nehalem-EP对应Xeon 5500(至强5500)家族,而Westmere-EP则对应Xeon 5600(至强5600)家族。

Xeon 5600:Westmere-EP
32nm 六核心:Intel Westmere-EP晶圆图
我们手上的目前最高端的两个Westmere-EP型号:Xeon X5680和Xeon X5670,主频分别为3.33GHz/2.93GHz
Westmere的特点就是六核心。早在数天前,型号为Core i7 980X的Gulftown发布了,这是最高端的也是唯一的一款桌面六核心Westmere,而今日发布的Westmere-EP则不同,Westmere-EP家族同时发布了多款款处理器,其中有8款属于六核心,再一次印证了企业级产品才是Nehalem处理器架构的集中体现的观点——Westmere-EP正是Nehalem架构的32nm版本(注,同时发布的还有一款单路的Xeon W3680,也是六核心的Westmere,此外,还同时发布三款新型号的Nehalem-EP)。
家族:45nm Xeon 5500(Nehalem-EP)与32nm Xeon 5600(Westmere-EP)
根据我们熟知的Tick-Tock策略,Westmere-EP是Nehalem微架构的工艺改进版本,将Nehalem-EP从45nm进化为32nm,其他方面变动不大,因此,我们仍然可以使用原有的平台,只需要经过一个BIOS升级就可以支持新的处理器。

在两个星期前我们IT168评测中心收到了Intel发出的第一批Westmere-EP测试样品,不过由于NDA的关系我们只能闷头测试,现在我们终于可以将其发布出来了,下面我们就来看看Westmere-EP究竟是个什么东东,具有什么样独到之处?
2007.11,45nm Penryn Xeon发布:
45纳米处理器性能突破 浪潮NF290D评测
性能提升 功耗剧降 45nm至强处理器测试
2008.08/2008.10,45nm Nehalem Core i7发布:
再攀性能之巅 Intel全新酷睿i7深度评测
2009.03,45nm Nehalem Xeon发布:
Intel Nehalem-EP处理器首发深度评测
曙光Nehalem-EP服务器I620r-G深度评测
2010.03,32nm Westmere Core i7发布:
"芯"酷睿性能巅峰 六核i7-980X首发评测
2010.03,32nm Westmere Xeon发布:
Intel 32nm Westmere-EP处理器首发评测
简而言之,Intel的Tick-Tock策略就是两年分别改进一次处理器微架构以及改进一次处理器工艺、交替进行的一种战略,每一年就会有一次微架构改进或者工艺改进:

Tick-Tock:Merom跟着Penryn,然后Nehalem后面是Westmere,后面是Sandy Bridge,再往后是Ivy Bridge,再之后是Haswell
45nm 四核心:Intel Nehalem-EP晶圆图

32nm 六核心:Intel Westmere-EP晶圆图
Tick-Tock其实是一个很严格的要求:Intel自己给自己制定了严格的时间表,如果不能顺利达到,那么对自己对广大合作伙伴都是一个沉重的打击。然而只要能按照时间表推出新品,那么Intel就能牢牢走在微处理器工艺、技术的尖端,令对手们只能被动跟随。Westmere属于Tick-Tock中的Tick。

IDF2009上的Westmere-EP平台
显然,Nehalem-EP处理器非常成功——在其发布的时候,Lucifer就测试结果分析称其为“独孤求败”,其后推出的Westmere-EP又会具有怎么样的表现呢?

更强的性能/更低的耗电/更安全
在新工艺的帮助下,Westmere-EP可以在同样的功耗下提供更高的性能,或者在同样的性能下获得更低的功耗,当然,两者各得一点也不无可能。最后,在处理器指令集方面的一些改进,让Westmere-EP可以提供更先进的安全特性。Westmere-EP在Nehalem-EP成功的基础上再次跨进了一步。


双核和六核Westmere晶圆图
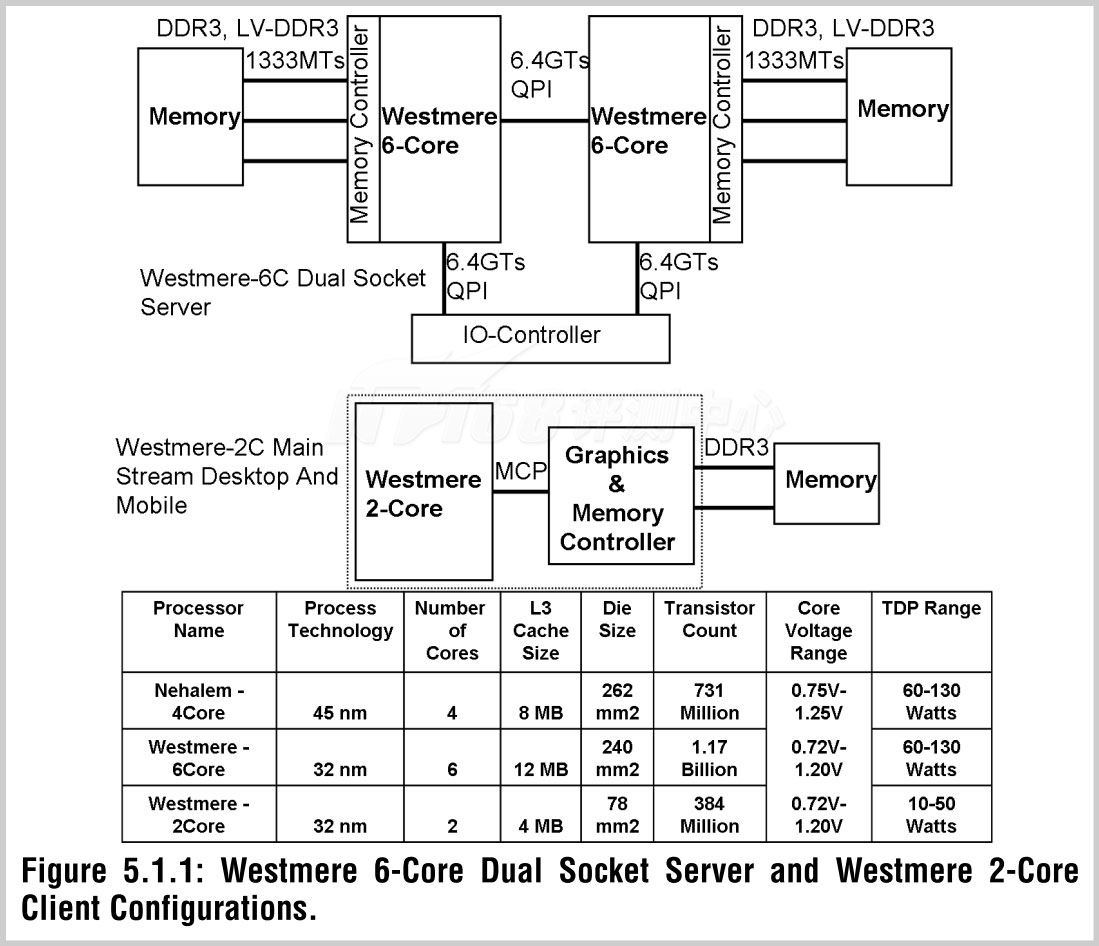
双路六核服务器版本和双核客户版本Westmere处理器配置
一眼看上去,Westmere-EP晶圆最大的特点就是最高集成了6个处理器核心,包括12MB L3缓存,一共多达11.7亿晶体管,四核心的Nehalem-EP包括8MB L3缓存则只有7.31亿晶体管,而Westmere-EP的核心面积只有240mm2(有一个数据说是248mm2),Nehalem-EP则达到了262mm2,晶体管多出60%的Westmere-EP核心面积还要小了8.4%,密度整整提升了74.7%,这些都要归功于先进的32nm工艺。
代号P1268的32nm CPU制造工艺

70亿美元,是Intel花在32nm晶圆厂上的钱,钱不够的话,这个半导体,一不小心就会做成半倒体
目前Intel的四个32nm工厂:位于Oregon俄勒冈州的D1D和D1C已经完成了32nm制造工艺的转产工作,而位于Arizona亚利桑那州和New Mexico新墨西哥州的Fab 32和Fab 11X将会很快完成转产工作。
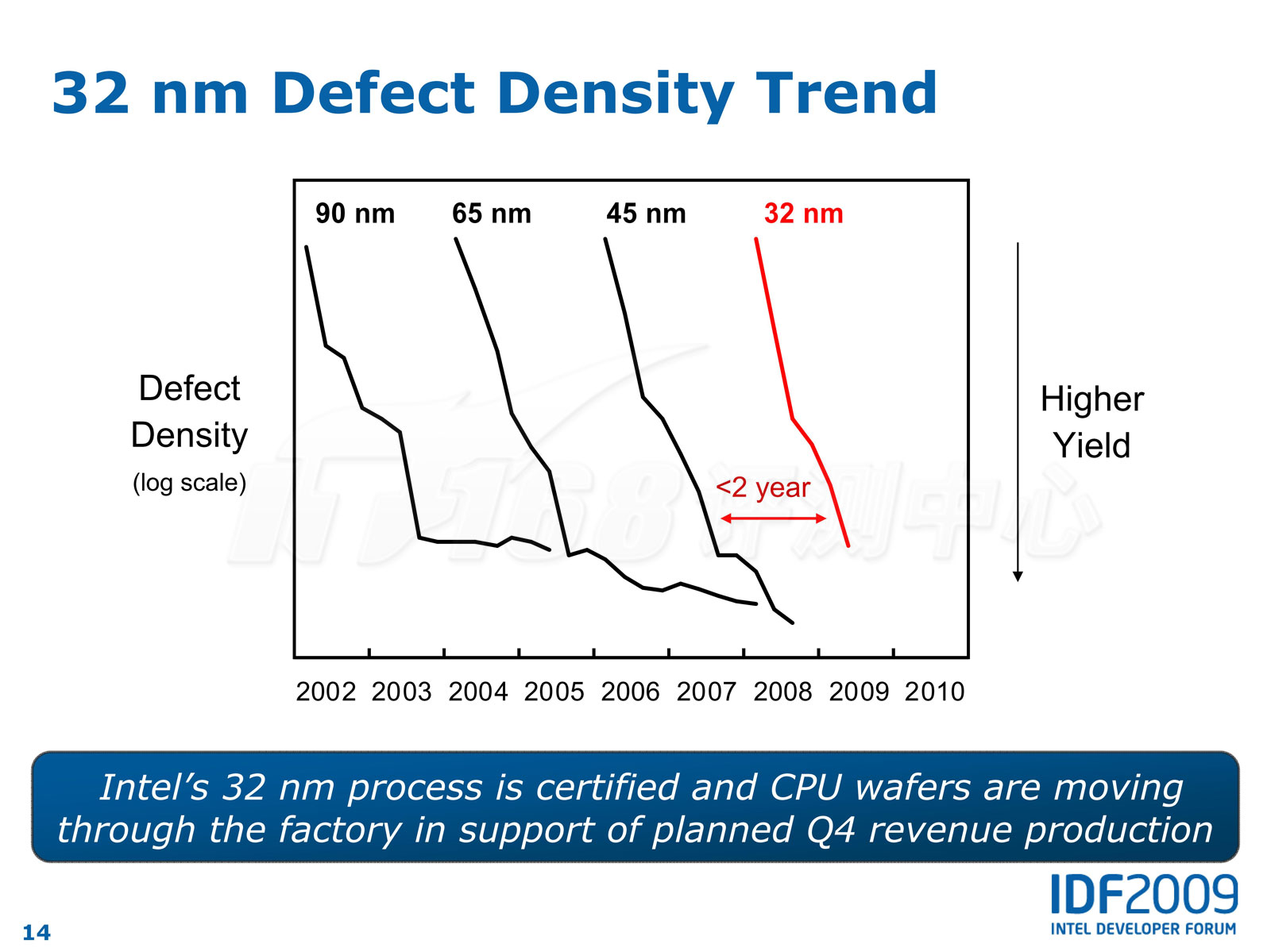
幸好,Intel的32nm工艺进展良好,最终Intel在09年第四季度发布了数款32nm芯片(图上纵坐标为缺陷密度/反过来就意味着成品率)
花了这么多钱的32nm有什么好处了?自然是更低的功耗和更好的性能了。
Intel High-k Metal Gate晶体管,这两个技术都是为了增强晶体管的场效应和降低其漏电
Intel代号P1268的32nm CPU制造工艺仍然是基于High-κ(这个希腊字母有时贪图快捷的话也写作英文字母的K)和Metal Gate技术,只是High-κ介质层的厚度已经从45nm工艺的1nm降低到0.9nm,Metal Gate金属栅极间距也缩小到上一代的70%,因此32nm上的High-k Metal Gate工艺被称为第二代 High-k Metal Gate工艺。Intel 32nm工艺提供了112.5nm的晶体管金属栅极宽度,是已知相同制造工艺中的最尖端水平。

Intel 32纳米制造工艺技术特性,在重要的金属层上,Intel使用了浸没式光刻技术(可以矫正折射率方面的影响)

晶体管密度的提升:晶体管数量增加——更多的核心、更大的缓存
晶体管性能方面,如下图所示,Intel 32nm工艺可以在同样IOFF(漏电流)情况下让ION(驱动电流)提升14%(NMOS晶体管)或22%(PMOS晶体管),或者在同样ION情况下让IOFF降低到原来的1/5(NMOS)或者1/10(PMOS),要功耗还是要性能?任君选择,当然更现实的是一样来一点。(注:下图老外用的是:NMOS降低超过5x、PMOS降低超过10x,但是汉语上来说,没有“降低X倍”这种说法)
32nm晶体管对45nm的性能提升
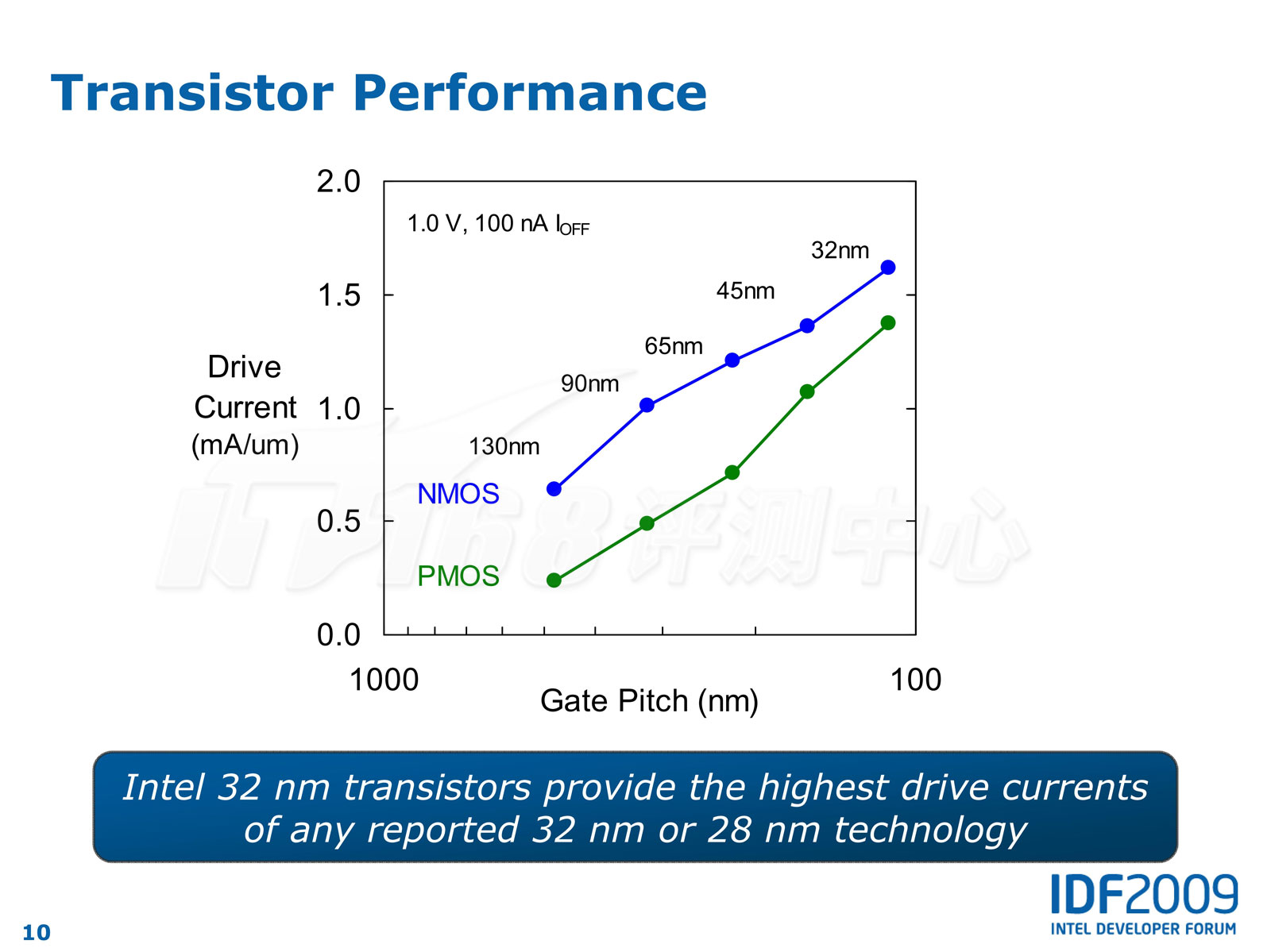
32nm晶体管对45nm的性能提升
此外,Intel 32nm工艺还应用了第四代应变硅材料。最后,还有Low-K介质和铜互联技术,已经成为了一种基本的工艺技术。这些工艺都可以降低功耗、提升性能。
在ISSCC(International Solid-State Circuits Conference,国际固体电路会议)上,Intel的《Westmere: A Family of 32nm IA Processors》还披露了更多关于Westmere处理器技术——前面的32nm工艺更接近于物理技术,而ISSCC这篇论文更接近于半倒体电路技术。概括起来,本页值得关注的特性有三点:
1、Westmere扩展的Power Gating功率门限技术可以应用到Uncore/L3上,降低了功耗
2、Westmere的L3使用了DECTED(三位错误检测-双位错误恢复)ECC技术,提高了成品率(Yield)和可靠性(Reliability)
3、Westmere新的内存驱动单元可以支持1.50V/1.35V的低电压内存,同时降低CPU以及内存子系统的功耗

Westmere-EP晶圆图
Westmere-EP晶圆图
首先,和Nehalem相比,Westmere改进了Power Gates技术,Westmere的Power Gates不仅仅限于关闭处理器核心,它还扩展到了可以关闭L3缓存以及Uncore上的全局队列(Westmere晶圆上正中央下方的部分)。在所有核心都被Power Gate之后,L3缓存将会被部分刷新并且Uncore部分的供电将会线形地降低,L3/Uncore的漏电楼将得到降低。在最限制的情况下,L3缓存和全局队列将会全部刷新并Power Gated关闭,只有一块附属于L3的SRAM会用来保持所有核心的关键状态。
和Nehalem一样,Westmere也使用了Long-Le晶体管(Long Channel长沟道晶体管)技术,Nehalem-EX和Dunnington也有使用,只是“分量”有些不同。Westmere有60%的核心部分使用了长沟道晶体管,Uncore部分则同时使用了超低漏电晶体管和长沟道晶体管。Nehalem则是58%的核心部分使用了长沟道晶体管。Westmere的漏电功耗大约是总功耗的23%。Nehalem上这个数值是16%。
样表:沟道长度(横坐标)与漏电流(纵坐标)的关系,请自行理解(越低的延迟,越高的漏电电流)
长沟道晶体管:在IC设计当中通常需要根据不同的情况使用不同沟道长度的晶体管,非时序关键(non-timing-critical)的线路可以使用性能略差的长沟道MOSFET晶体管以减少亚阈值漏电。亚阈值漏电:subthreshold leakage,MOSFET的subthreshold亚阈值特性被广泛利用在低电压线路上。

封装和我们平常用的LGA 1136处理器完全一样
同针脚的Westmere的外观和Nehalem没什么两样, 封装技术也一样。Westmere处理器使用了使用了14层基板(5-4-5)的flip-chip(C4)翻转封装,基于树脂的基板厚度40mil(1密耳=千分之一英寸,40mil=1.016mm),最后加上一个金属散热盖组成了常见的LGA(land-grid-array,连接格阵)封装。处理器背面的矩形方腔放置了Core、Uncore和IO的去耦电容,部分IO使用了片内去耦电容。为了防止击穿,片内DDR IO去耦使用了堆叠电容。为了降低Jitter抖动,DDR时钟驱动单元由片内LC滤波器组成的电源供电。

IO反谐振电路
为了达到QPI总线需求的严格电源噪声标准,处理器模拟电源和数字电源是独立输入的,并使用了一个反谐振电路(Anti-resonant Circuit)来实现两个恒定、独立的QPI供电。
双核和六核Westmere晶圆图,并根据供电标注了区域
Core与Uncore部分分成了独立的供电区域,因为Core部分工作在较低的电压并且电压和频率都会根据负载调整,而Uncore部分则是工作在相对较为固定的电压。每核心独享的256KB L2缓存由0.275um2密度的6T晶体管SRAM单元组成,Active Vmin是700mV,所有核心共享的12MB L3缓存则由0.171um2密度的6T晶体管SRAM单元组成,Active Vmin是900mV,极限保留至和Uncore协同的700mV。除了一个全局的Power Gating FET控制Core部分和对应的L3-Uncore部分之外,L3内的解码器(decoders)和子阵列(sub-arrays)还拥有本地Power Gates用来进一步降低主动功耗。L3的SRAM单元在空闲时还会将电压降低到750mV以降低漏电功耗。
根据L3存取粒度的不同,本地Power Gates会具有显著的效果。在12MB L3的情况下,每一个L3存取仅会激活2%的解码器和0.5%的SRAM单元。Uncore的全局Power Gate同时还像一个线形调压器一样可以将Uncore部分的工作电压线形调节最低至750mV。

纵坐标:良率减损,不使用任何修复方法制造无缺陷的大容量缓存是不可能的
Westmere的L3使用了DECTED(double-error-correcting triple-error-detecting,三位错误检测-双位错误恢复)ECC技术来提高成品率(Yield)和可靠性(Reliability),顾名思义,DECTED可以检测到一个缓存线(cache line,64位)中出现的三位错误并可以恢复二位的错误。上图展示了传统的冗余修复方法和DECTED ECC的对比。对于正常工作时的软错误,DECTED ECC也提供了数量级级别的提升。换句话说,Westmere的L3将会非常稳定。
在时钟信号方面,和前任相似,Westmere使用了一个外部的133MHz时钟,并使用FPLL倍频至266MHz和533MHz发送至四个PLL产生各种高参考时钟频率。高参考时钟频率允许高频率的交换并降低了跨域时钟脉冲相位差和远距Jitter因而降低了FIFO队列的延迟。为了对抗电压跌落,PLL实现了一个AFS(adaptive frequency system,适应性频率系统)以保持频率的稳定,并使用DCC(Duty-Cycle corrector,占空比校正)来对抗工艺波动和老化引起的退化。
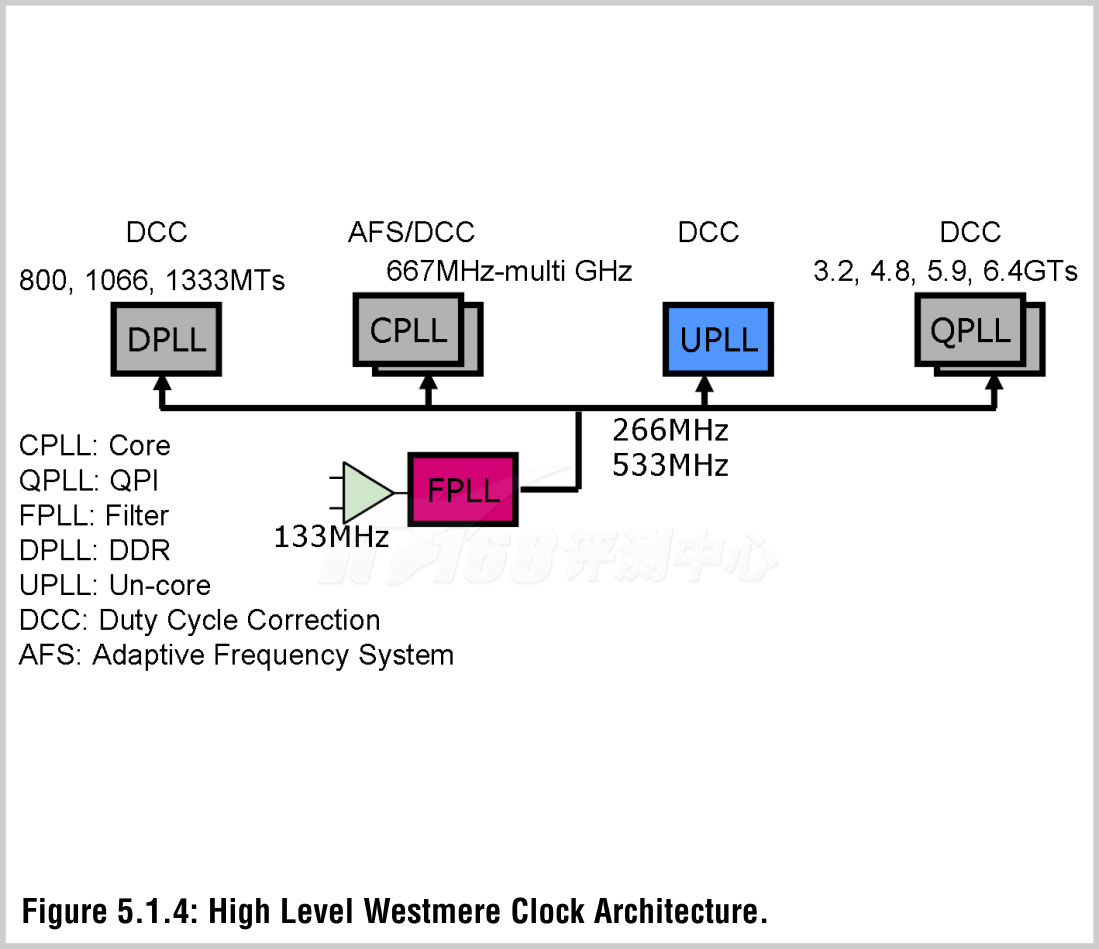
Westmere的分布时钟使用了多种方式来平衡性能和功耗。Core时钟是虚拟格栅水平/垂直脊柱拓扑(pseudo-grid horizontal/vertical spines topology),Uncore时钟则将点对点H-tree(point-point H-tree)用于轻负荷区域,将脊柱拓扑(spine topology)用于中/重负荷区域。QPI发送时钟是虚拟差分(pseudo-differential)而接收时钟是低摆幅全差分(low-swing fully differential),为了获得更健壮的QPI/DDR时钟还使用了如抖动抑制(jitter-attenuating)DLL等技术。
和2.5V的DDR2工作电压相比,DDR3的工作电压已经降低到了1.65V,Westmere进一步引入了对DDR3-LV(low voltage)的支持,低压DDR3需要内存控制器支持1.5V/1.35V的低工作电压,这进一步降低了CPU和内存的功耗。同时也能支持上一代Nehalem所支持的1.65V标准DDR3。

使用了一个推挽电压模式驱动器(push-pull voltage-mode driver)的DDR3输出驱动单元
QPI的实现包括了一个适应性电路架构来应对工艺上的挑战。QPI发送器包括了一个支持500mV到150mV Tx电压摆幅的电流源线路驱动器,在全局范围的终端电阻和线路驱动器上通过一个闭环补偿单元来应对工艺波动,在接收器局部,每一个lane信道都具有独立的闭环补偿单元来应对设备工作波动。
总的来说,处理器当中有许多电路用来对应日常的软错误,可以经受住电压、温度波动乃至年月老化的考验,一个计算机中正常使用最不容易坏的电子部件大概就是CPU了。对工艺和电路技术的介绍就到这里,下面开始将是正宗的处理器特性介绍:)

Westmere-EP晶圆图
滴答哲学:在上一代上基础上改进
自然,Westmere-EP主要的特色就是32nm、六核心,带来更低的功耗或者更高的性能,除此之外,还引入了一些新的特性,如下所示:

四个改进:新的指令集和PCID、APIC Timer、1GB Pages
里面包括了一个指令集改进和三个处理器特性增加,我们先来看看一个重要的指令集改进:AES NI。NI就是New Instructions(新指令集)的意思。
所有看到这个文章的人都应该知道HTTP是什么,通常,HTTP(Hyper Text Transfer Protocol,超文本传输协议)上传输的大多数数据都是以不安全的明文方式进行传输的。然而,在如在线电子邮箱(笔者使用的gmail)、在线文档(google docs)以及在线银行等领域上需要加密传输,我们需要使用HTTPS,即通过HTTP之上的安全套接字层(SSL)。
HTTP位于TCP/IP协议栈的应用层,SSL(Secure Sockets Layer ,安全套接字层)以及后来的TLS (Transport Layer Security,传输层安全)都是应用层上的安全技术,提供了一个安全传输私有数据的方案。显然,随着云计算让人们可以在任何地点通过各种设备访问他们的私有信息,今日任何基于HTTP的应用明天都可能会变成基于HTTPS,包括SSL和HTTPS在内的安全/加密技术毫无疑问将会变得越来越重要。
SSL握手过程
对于SSL而言,其核心部分与密码算法相关:包括使用对称密钥进行包加密、提供消息认证支持以及通过RSA算法建立会话。为了加速包括SSL在内的应用,Intel在Westmere中新增加了AES NI指令集。

AES NI是6条AES指令和1条通用加解密指令的集结,前面6条可以加速使用AES算法的SSL
AES算法
AES(Advanced Encryption Standard,高级加密标准)是美国政府的对称加密算法标准,它定义在FIPS(美国联邦信息处理标准)出版物第#197 (2001) 中并得到了广泛的应用。在HTTPS中,它可用于为因特网上传输的信息提供机密性。AES是一个对称加密算法,也意味着在加密和解密消息的时候,使用的是相同的密钥:
AES结构
AES加密处理对输入的128位明文,使用加密的密钥通过有限次的迭代运算(每一次称为一轮:round)最终得到128位的加密块。解密遵循相反的过程,迭代次数一样,但是需要“解密密钥”而不是加密的“密钥”。在每一轮加密解密中都使用不同的阶段密钥,由原始密钥通过密钥序列算法生成。AES的标准密钥分为128,192和256位,各自对应的迭代次数为10、12和14轮。AES中使用了基于GF(28)的有限域算法以及仿射变换。
RSA算法
RSA(Rivest Shamir Adleman,三个作者的名字)是一种公钥密码算法设计。公钥算法背后的主要想法是加密技术可以有后门的存在。后门的意思是指,密码只需要交互的一方知道,这样可以简化加密流程。在公钥算法中,消息通过公钥加密,而一个公钥对应一个私钥。在不知道私钥的情况下,很难解密消息,类似地,攻击者也很难发现信息原文。
RSA的典型实现使用中国剩余理论,它可以将一个模数的取幂运算减低为长度为原先一半的两个数的取幂运算,依次类推,通过使用平方乘的技术可以将取幂操作化解成模数平方及模式乘运算的序列。平方乘运算还可以优化,并使用某些视窗法降低模数乘运算的次数。最后,模数平方和乘运算可以通过如Montgomery或Barrett这样的简约算法简化成大数的乘法运算。
Westmere的AES NI指令集包括了下面分成两部分的7条指令,来加速AES的计算(RSA的计算虽然不能直接加速,不过却可以从Intel的超线程技术获益),这些操作用软件实现需要消耗非常多的时间和内存,而用电路实现时可以很快并且显得更为节能:
Carry-less Multiplication Instruction(无进位乘法指令):
一条单独的无进位乘法指令(Carry-less Multiplication):PCLMULQDQ,PCLMULQDQ指令一次可以处理两个64位宽度的数据
无进位乘法又称为Galois域(GF)乘法,该操作中对两个数进行相乘时不产生以及传递进位。在标准的整数乘法中,第一个操作数移位的次数等于第二个操作数中值为1的比特位的个数,每次移动的距离就是1在第二个操作数中的位置。两个数的执行结果由所有移动后的第一个操作数相加而来的。在无进位乘法中,过程依然相同,但是相加时不产生进位也不传递进位。这样,比特加操作就相当于逻辑操作中的异或(XOR)。
无进位乘法是很多系统和标准(包括时钟冗余校验,CRC,Galois/计数模型,GCM和二进制椭圆曲线等)的计算的一个非常重要的组件,该操作在当今处理器上用软件实现时效率极为低下。所以,加速无进位乘法的指令对于GCM和所有依赖于它的交互协议来说相当重要。
GCM 是对称加密算法分组密码的一种工作模式。分组密码工作模式可以分为加密模式、认证模式和认证加密模式等。GCM模式为认证模式的一种,提供认证和加密两种功能。GCM在IEEE 802.1ae标准、IPsec(RFC 4106)、P1619存储标准和SPoFC(Security Protocols over Fiber Channel,ISO-T11的一个标准)中都有应用。
花絮:Lucifer在IDF09期间翻译Carry-less Multiplication时也犹豫了很久,叫“无进位”还是“不进位”呢?“无”适合描述现象,而“不”更适合于描述操作;最终Lucifer使用了更为常见的“无进位”。
AES Extension Instructions(AES扩展指令):
两条AES加密迭代加速:AESENC和AESENCLAST
两条AES解密迭代加速:AESDEC和AESDECLAST
两条密钥序列生成:AESIMC和AESKEYGENASSIST
AES NI的效果,数据来源:Intel

IDF09上的展示,Westmere-EP的RSA加密性能具有41%的提高,而AES加密性能则具有12倍的提升
AES NI不仅仅可用于AES算法,如SHA等中也可以使用。后面可以看到,AES NI对应用的加速效果非常明显。
凭着新的架构,Nehalem-EP确实非常成功……比上一代性能上有着一到两倍的增长,笔者曾经用过“独孤求败”的词语来形容,不过,Nehalem-EP也并非完美,至少在某些方面上如此……

Nehalem TLB架构,深入Nehalem微架构:缓存子系统
TLB:Translation Lookaside Buffer,旁路转换缓冲,或称为页表缓冲,有时也译做快表;TLB里面存放的是一些页表文件,亦即是虚拟地址到物理地址的转换表。TLB和L1/L2/L3 Cache没有什么本质的区别,只是前者缓存页表数据,后者缓存实际页面数据而已。当CPU在处理应用程序的页表请求时,要先到TLB中查找虚拟地址相应的物理页表数据,如果TLB中正好存放着所需的页表,则称为TLB命中(TLB Hit),接下来CPU再依次看TLB中页表所对应的物理内存地址中的数据是否在L1/L2/L3等缓存中,若没有的话则需要到内存中存取相应的页面。
那么,TLB和Nehalem的弱点有什么关系呢?我们先来看看下面这个表:
CPU TLB Entry Comparison | |||
| CPU | AMD Shanghai Opteron | Intel Penryn Xeon | Intel Nehalem Xeon |
| L1I TLB(4kB) | 48 | 128 | 128 |
| L1I TLB(large) | 48 | 8 | 7+7 (HTT) |
| L1D TLB(4kB) | 48 | 16 | 64 |
| L1D TLB(large) | 48 | 16 | 32 |
| L2 TLB(4kB) | 512 | 256 | 512 |
| L2 TLB(large) | 128 | 32 | 0 |
所谓的large就是指相对于一般的4kB页面,large页面为2M/4MB大小。这个表格说明了什么?它表明了Intel的处理器具有大量的小的TLB项,但是大的TLB项很少,并且这些表项要在两个超线程逻辑CPU中共享(或者分割)。Intel的处理器相对来说不适合大规模内存下的应用(如大型数据库和大型虚拟机)。
四个改进:新的指令集和PCID、APIC Timer、1GB Pages
多少地,为了解决这个问题,Westmere做出了改进,增加TLB数量属于微架构变动的范围不大适合现在做,因此Westmere采用了另一种做法:大页面支持,现在Westmere可以支持1GB的大页面,对比之前的2M/4MB,现在的Nehalem可以通过较少的大页面TLB也能覆盖很大的内存范围了,算是一个补救方案。
PCID(Processor Context ID,处理器上下文ID)也是一个和TLB有关的改进,和大页面不同,PCID更倾向于提升多进程或者大量小规模虚拟机的环境。PCID通过Tag TLB(标记TLB)项保存CR3寄存器的值,以降低硬页面漫游造成的影响。CR3寄存器保存着当前表对物理地址转换的一部分,大页面需要3次CR3存取才能将虚拟地址翻译为物理地址。在进程切换或者虚拟机切换的时候,CR3的改写非常频繁,在它成为瓶颈的时候,CPU使用硬件辅助虚拟化的EPT/NPT技术甚至还不如使用软件虚拟化的二进制翻译技术来的要快!PCID的出现改变了这个情况,它需要操作系统或者VMM的支持才能工作。

搭配大页面支持、PCID技术之外,Westmere还提供了如PAUSE-loop exiting、Real Mode支持等特地为虚拟化应用而做的改进,总的来说,虚拟机切换的时间比起Nehalem来,降低了12%。在大负荷的虚拟化环境,提升将会非常明显。笔者这几天的应用中就很有感受。
在系统平台方面,Westmere-EP相比Nehalem-EP也有了不少的改进,这并不是说搭配的Tylersburg-EP芯片组在用上Westmre-EP就比不用的时候要更先进。整个系统平台的进步仍然是基于Westmere处理器的变化。

Tylersburg-EP平台可以继续支持Westmere-EP处理器


整个平台在内存方面具有四个改进,这些都可以提升性能或者降低功耗:
1、Westmere-EP现在支持低电压DDR3,电压值从原来的1.65V降低到1.50V乃至1.35V
2、Westmere-EP现在支持每个内存通道具有两个DIMM运行在1333MHz,而Nehalem-EP只支持一条,插更多内存会让内存降速
3、Westmere-EP对内存规格的支持总体上提升了,所有型号最低都支持DDR3-1066,而Nehalem-EP最低的支持到DDR3-800
4、Westmere-EP现在支持单条16GB的内存条,总内存容量增加了一倍,达到了288GB

双5520芯片组配置,不过和本文似乎没有什么必然关系……
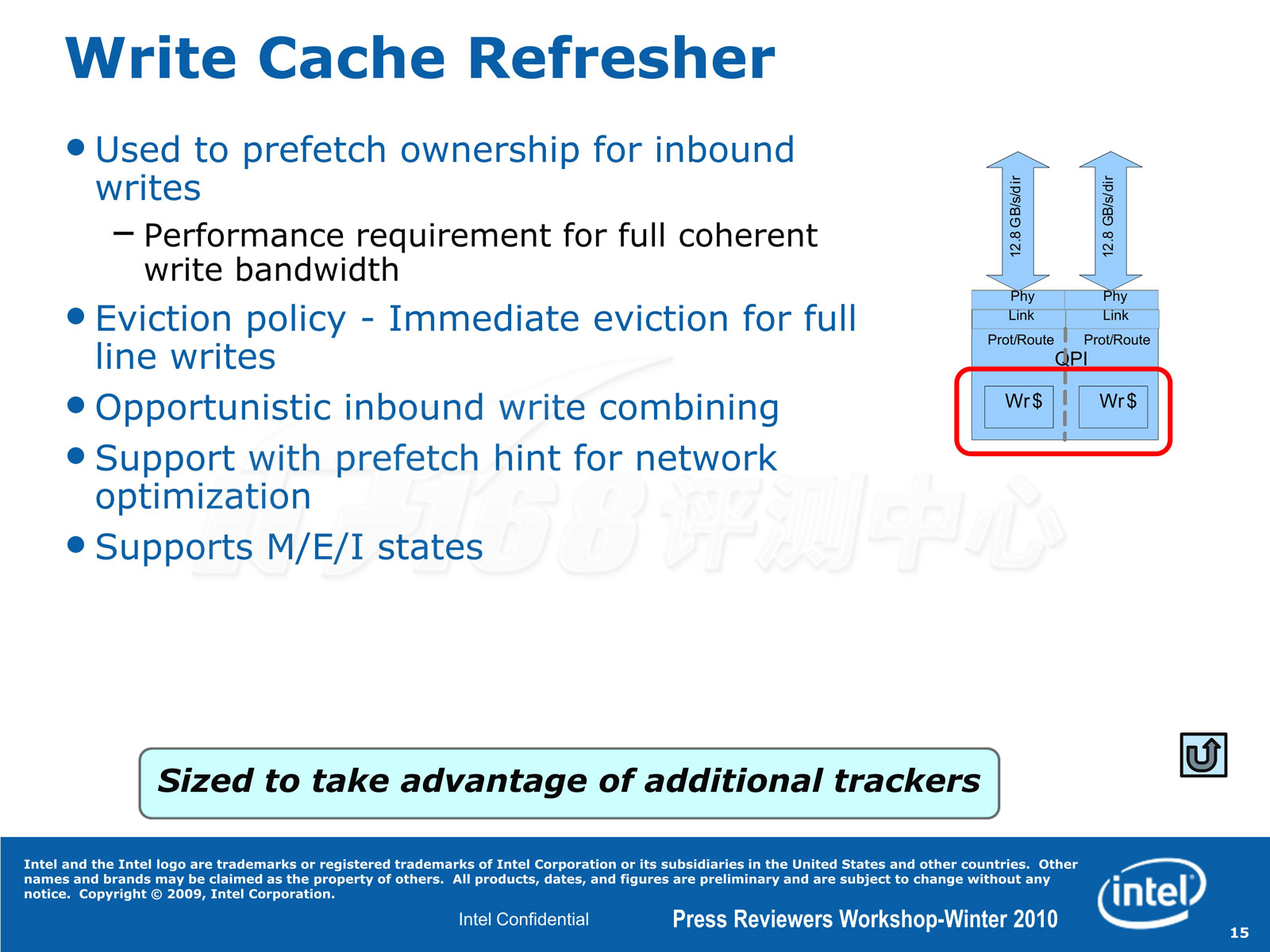
Westmere处理器的trackers数量也增加了

最后,Westmere处理器增加了QPI总线的tracker的容量,提升了总的系统IO带宽。
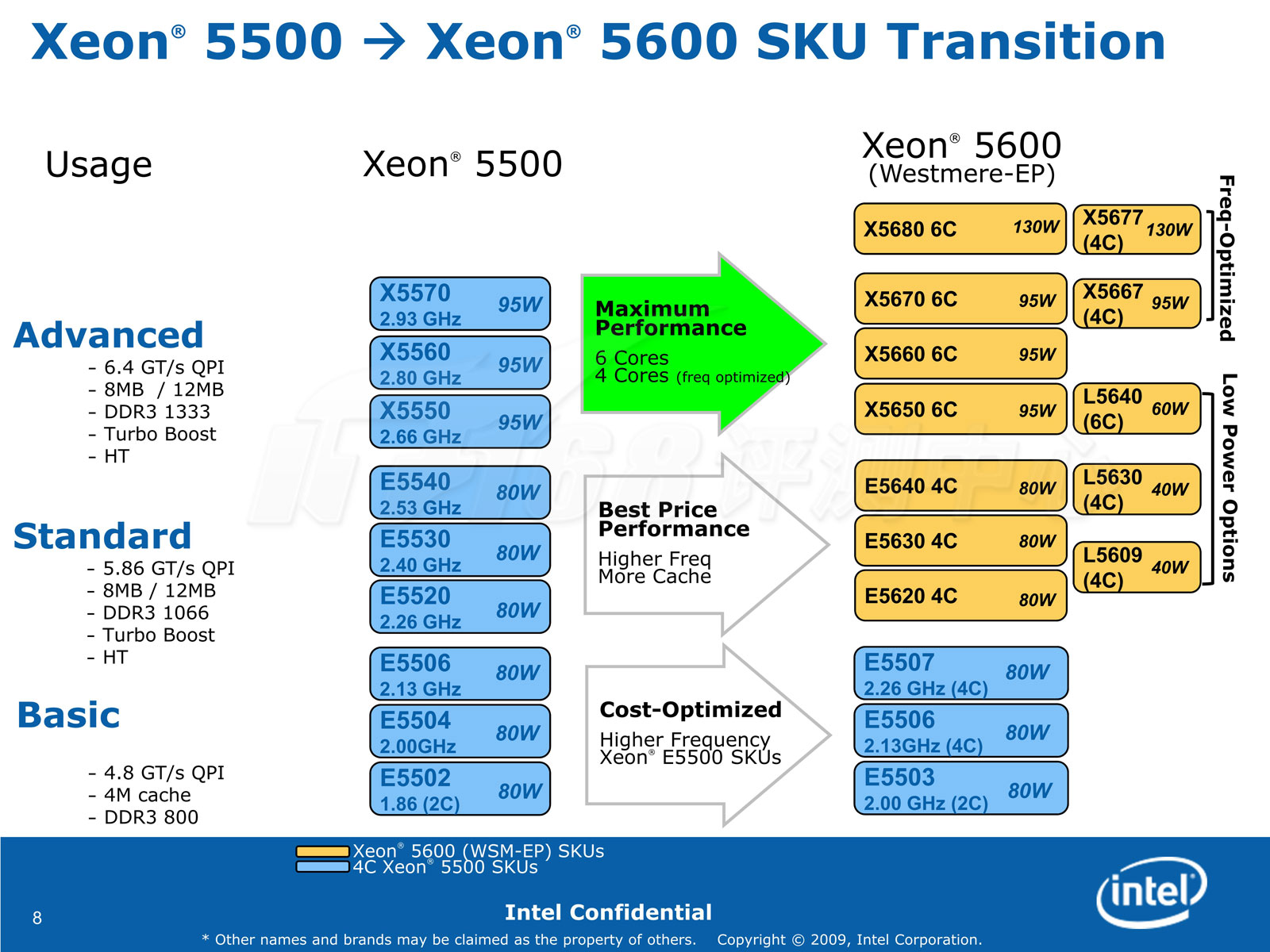
家族:45nm Xeon 5500(Nehalem-EP)与32nm Xeon 5600(Westmere-EP)
在上图中我们可以看到Xeon 5500(Nehalem-EP)和Xeon 5600(Westmere-EP)两个家族都有哪些成员,当然,这些都是双路版本。Intel也会推出单路版本的Xeon 5600,目前只有一款W5680,和双路版本的X5680就出了处理器路数不同之外,其他都一样。最后的规格表如下:
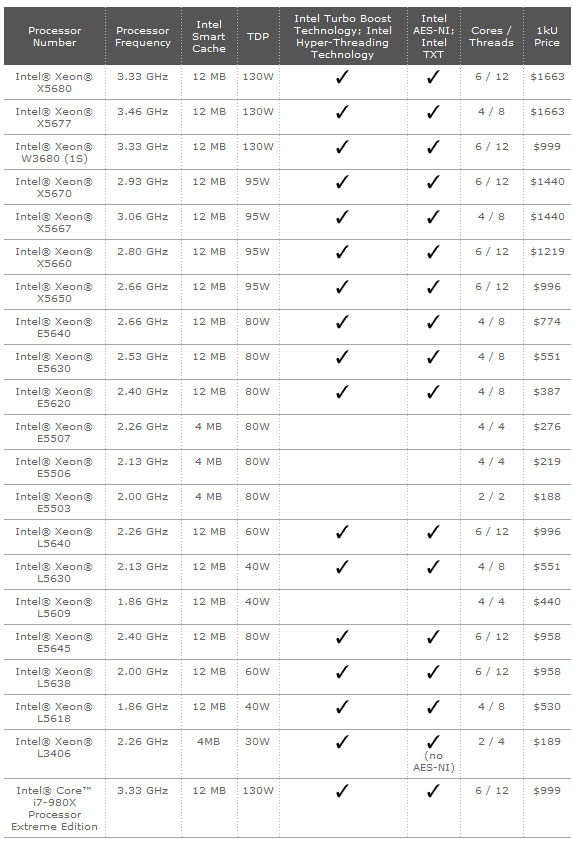
其中数款550x处理器属于Nehalem家族
最高型号是X5680,TDP为130W,6核心12线程,频率达到了3.33GHz,和上一代的顶端产品W5590频率一致,但是X5680支持Turbo Boost睿频技术,工作时频率可以达到3.47GHz,比W5590要高。最低功耗的型号TDP低到了40W,包括一款带睿频和超线程的L5630和不带的L5609。(表上的Xeon L3406是45nm Nehalem架构产品)
实际上,笔者现在就在工作用机上使用着X5680,确实很强劲。
最后,从表中我们还可以看到,Xeon 5600系列中最低支持的内存规格都是DDR3-1066,比上一代的DDR3-800要更高。

美国总部统一发出的套装

层层保护

这个U盘放着支持Westmere-EP所必要的主板BIOS升级文件

切了一截的CPU盒子

一共四个CPU,如果是正式版的话,这里就要几万块钱了

两对:一对X5680,一对X5670,为什么选择了这两款呢?

这是因为X5680是最高端的型号,而X5670是95W TDP中最高端的型号,此外X5670的频率规格和官方测试样机配置的X5570一致;当然,笔者更喜欢看到X5677这样奇怪的型号

X5680的频率是3.33GHz,可以Turbo Boost到3.46GHz,TDP 130W
X5670的频率是2.93GHz,可以Turbo Boost到3.20GHz,TDP 95W
关于它们的Turbo Boost特性,还有待专门阐述
显然,所有的处理器都在同样的机器上进行测试。我们进行的只是多个和处理器相关的测试,一些耗时很长的测试将会以后陆续提供。
测试平台、测试环境 | ||||||
| 测试分组 | ||||||
类别 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 | |||
| 处理器子系统 | ||||||
| 处理器 | 双路Intel Xeon X5570 | 双路Intel Xeon X5670 | 双路Intel Xeon X5680 | |||
| 处理器架构 | Intel 45nm Nehalem | Intel 32nm Westmere-EP | Intel 32nm Westmere-EP | |||
| 处理器代号 | Gainestown (Nehalem-EP) | ? (Westmere-EP) | ? (Westmere-EP) | |||
| 处理器封装 | Socket 1366 LGA | Socket 1366 LGA | Socket 1366 LGA | |||
| 处理器规格 | 四核 | 六核 | 六核 | |||
| 处理器指令集 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT AES | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT AES | |||
| 主频 | 2.93GHz | 2.93GHz | 3.33GHz | |||
| Turbo Boost主频 (多核) | 3.20GHz(+266MHz) | 3.20GHz(+266MHz) | 3.46GHz(+133MHz) | |||
| Turbo Boost 主频 (单/双核) | 3.333GHz(+400MHz) | 3.333GHz(+400MHz) | 3.46GHz(+133MHz) | |||
| 处理器外部总线 | 2x QPI 3200MHz 6.40GT/s 单向12.8GB/s(每QPI) 双向25.6GB/s(每QPI) | 2x QPI 3200MHz 6.40GT/s 单向12.8GB/s(每QPI) 双向25.6GB/s(每QPI) | 2x QPI 3200MHz 6.40GT/s 单向12.8GB/s(每QPI) 双向25.6GB/s(每QPI) | |||
| L1 D-Cache | 4x 32KB 8路集合关联 | 6x 32KB 8路集合关联 | 6x 32KB 8路集合关联 | |||
| L1 I-Cache | 4x 32KB 4路集合关联 | 6x 32KB 4路集合关联 | 6x 32KB 4路集合关联 | |||
| L2 Cache | 4x 256KB 8路集合关联 | 6x 256KB 8路集合关联 | 6x 256KB 8路集合关联 | |||
| L3 Cache | 8MB @ 2668.7MHz 16路集合关联 | 12MB @ 2668.7MHz 16路集合关联 | 12MB @ 2668.7MHz 16路集合关联 | |||
| 主板 | ||||||
| 主板型号 | ASUS Z8PS-D12-1U | ASUS Z8PS-D12-1U | ASUS Z8PS-D12-1U | |||
| 芯片组 | Intel Tylersburg-EP IOH:Intel 5520(Tylersburg-36D) ICH:Intel 82801JR(ICH10R) | Intel Tylersburg-EP IOH:Intel 5520(Tylersburg-36D) ICH:Intel 82801JR(ICH10R) | Intel Tylersburg-EP IOH:Intel 5520(Tylersburg-36D) ICH:Intel 82801JR(ICH10R) | |||
| 芯片特性 | 2x QPI 36 PCI Express Gen2 Lanes VT-d Gen 2 | 2x QPI 36 PCI Express Gen2 Lanes VT-d Gen 2 | 2x QPI 36 PCI Express Gen2 Lanes VT-d Gen 2 | |||
| 内存控制器 | 每CPU集成三通道R-ECC DDR3 1333 | 每CPU集成三通道R-ECC DDR3 1333 | 每CPU集成三通道R-ECC DDR3 1333 | |||
| 内存 | 4GB R-ECC DDR3 1333 SDRAM x6 | 4GB R-ECC DDR3 1333 SDRAM x6 | 4GB R-ECC DDR3 1333 SDRAM x6 | |||
| 软件环境 | ||||||
| 操作系统 | Microsoft Windows Server 2008 R2 Datacenter Edition | Microsoft Windows Server 2008 R2 Datacenter Edition | Microsoft Windows Server 2008 R2 Datacenter Edition | |||
需要注意的是,虽然这三个处理器都提供了Turbo Boost功能,然而在测试中我们均未打开。这样可以测试它们在默认规格下的性能。打开Turbo Boost的性能表现,我们也会在之后再献上。
首先不能缺少的是系统的任务管理器!看着一排排的CPU,实在是爽:
进行测试的时候,图上的48GB 1.35V DDR3-1333内存还没有抵达
Nehalem-EP X5570
Westmere-EP X5670
Westmere-EP X5680
可见,所有的处理器在闲置的时候都运行在1.6GHz下。处理器的家族都为6,不过Model从A变化到了C,Ext. Model从1A变化到了2C。
Nehalem-EP平台使用0816原始BIOS
Westmere-EP的新BIOS……0701,怎么数字还变小了?不得其解
X5670和X5680的Uncore频率仍然运行在2.667GHz(图上的NB Frequency)
一开始测试使用的是5.30.2043 Beta,不过日前5.30.3000正式版发布了,因此我们又换了这个版本进行检测。后面还有用其进行的性能测试。




这里可以看到处理器的TDP规格以及Turbo Boost在多少个核心下会具有多少的倍频
这里也提示处理器支持AES扩展指令集
“其他特性”后面的第一项就是1GB Page Size,1GB的页面大小,Nehalem-EP和之前的处理器都是不支持的
支持Turbo Boost
X5680除了TDP为130W之外,其他指令集之类的完全一样
SiSoftware Sandra是一款可运行在32bit和64bit Windows操作系统上的分析软件,它可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台。我们使用了其最新的2010版本。
SiSoftware Sandra Pro Business 2010 | |||
|---|---|---|---|
测试对象 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
Processor Arithmetic Benchmark 处理器算术性能测试 | |||
Aggregate Arithmetic Performance | 147.17GOPS | 218.69GOPS | 249.2GOPS |
Aggregate Arithmetic Performance vs SPEED | 50.16MOPS/MHz | 74.53MOPS/MHz | 74.75MOPS/MHz |
Dhrystone iSSE4.2 | 172.5GIPS | 257GIPS | 291.36GIPS |
Dhrystone iSSE4.2 vs SPEED | 58.79MIPS/MHz | 87.58MIPS/MHz | 87.39MIPS/MHz |
Whetstone iSSE3 | 121.84GFLOPS | 180.41GFLOPS | 207GFLOPS |
Dhrystone iSSE3 vs SPEED | 41.53MFLOPS/MHz | 61.49MFLOPS/MHz | 62.10MFLOPS/MHz |
Processor Multi-Media Benchmark 处理器多媒体性能测试 | |||
Multi-Media Int x16 iSSE4.1 | 317.13MPixel/s | 470.51MPixel/s | 534.13MPixel/s |
Multi-Media Int x16 iSSE4.1 vs SPEED | 108.09kPixels/s/MHz | 160.37kPixels/s/MHz | 160.21kPixels/s/MHz |
Multi-Media Float x8 iSSE2 | 237MPixel/s | 350.2MPixel/s | 397.47MPixel/s |
Multi-Media Float x8 iSSE2 vs SPEED | 80.79kPixels/s/MHz | 119.36kPixels/s/MHz | 119.22kPixels/s/MHz |
Multi-Media Double x4 iSSE2 | 128.62MPixel/s | 190.87MPixel/s | 216.17MPixel/s |
Multi-Media Double x4 iSSE2 vs SPEED | 43.84kPixels/s/MHz | 65.05kPixels/s/MHz | 64.84kPixels/s/MHz |
Multi-Core Efficiency Benchmark 多核效率测试 | |||
Inter-Core Bandwidth | 71.15GB/s | 80.7GB/s | 84GB/s |
Inter-Core Bandwidth vs SPEED | 24.83MB/s/MHz | 28.17MB/s/MHz | 25.79MB/s/MHz |
Inter-Core Latency (越小越好) | 18ns | 18ns | 16ns |
Inter-Core Latency vs SPEED (越小越好) | 0.01ns/MHz | 0.01ns/MHz | 0.00ns/MHz |
.NET Arithmetic Benchmark .NET算术性能测试 | |||
Dhrystone .NET | 32.11GIPS | 32.2GIPS | 37GIPS |
Dhrystone .NET vs SPEED | 10.95MIPS/MHz | 25.08MOPS/MHz | 24.06MOPS/MHz |
Whetstone .NET | 79.56GFLOPS | 115GFLOPS | 123.43GFLOPS |
Whetstone .NET vs SPEED | 27.12MFLOPS/MHz | 39.19MFLOPS/MHz | 37.02MFLOPS/MHz |
.NET Multi-Media Benchmark .NET多媒体性能测试 | |||
Multi-Media Int x1 .NET | 59MPixel/s | 88.64MPixel/s | 100.36MPixel/s |
Multi-Media Int x1 .NET vs SPEED | 20.12kPixels/s/MHz | 30.21kPixels/s/MHz | 30.10kPixels/s/MHz |
Multi-Media Float x1 .NET | 25.22MPixel/s | 37.73MPixel/s | 42.42MPixel/s |
Multi-Media Float x1 .NET vs SPEED | 8.60kPixels/s/MHz | 12.86kPixels/s/MHz | 12.72kPixels/s/MHz |
Multi-Media Double x1 .NET | 48.3MPixel/s | 68.45MPixel/s | 78.48MPixel/s |
Multi-Media Double x1 .NET vs SPEED | 16.46kPixels/s/MHz | 23.33kPixels/s/MHz | 23.54kPixels/s/MHz |
毫无疑问,Sandra是一个偏向理论值的测试程序,Westmere-EP凭着多出来的两个核心,在多个测试中表现非凡。
SiSoftware Sandra的缓存内存性能测试也比较有参考价值:
SiSoftware Sandra Pro Business 2010 | |||
|---|---|---|---|
测试对象 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
Memory Bandwidth Benchmark 内存带宽测试 | |||
Int Buff'd iSSE2 Memory Bandwidth | 38GB/s | 35GB/s | 35.2GB/s |
Float Buff'd iSSE2 Memory Bandwidth | 38GB/s | 35GB/s | 35.18GB/s |
Memory Latency Benchmark(Random) 内存延迟测试(随机) | |||
Memory(Random Access) Latency (越小越好) | 80ns | 83ns | 82ns |
Speed Factor (越小越好) | 55.50 | 57.00 | 64.60 |
Internal Data Cache | 4clocks | 4clocks | 4clocks |
L2 On-board Cache | 11clocks | 10clocks | 10clocks |
L3 On-board Cache | 49clocks | 57clocks | 60clocks |
Memory Latency Benchmark(Linear) 内存延迟测试(线性) | |||
Memory(Linear Access) Latency (越小越好) | 7ns | 7ns | 7ns |
Speed Factor (越小越好) | 4.80 | 5.10 | 5.50 |
Internal Data Cache | 4clocks | 4clocks | 4clocks |
L2 On-board Cache | 10clocks | 11clocks | 11clocks |
L3 On-board Cache | 13clocks | 13clocks | 13clocks |
Cache and Memory Benchmark 缓存及内存测试 | |||
Cache/Memory Bandwidth | 142GB/s | 183.26GB/s | 195.6GB/s |
Cache/Memory Bandwidth vs SPEED | 49.57MB/s/MHz | 63.96MB/s/MHz | 60.07MB/s/MHz |
Speed Factor (越小越好) | 21.20 | 31.00 | 35.20 |
Internal Data Cache | 471GB/s | 663.51GB/s | 744.49GB/s |
L2 On-board Cache | 295.4GB/s | 537.88GB/s | 611GB/s |
不出意外的是,Westmere-EP的内存读写带宽数值反而要低一些——它们的内存存取延迟也要长一点。内存带宽低了约7.4%,内存随机延迟高了2~3ns,L3缓存延迟高了约10个时钟周期。为什么会这样呢?因为Nehalem-EP/Westmere-EP所有的核心都是通过一个交叉开关的结构来连接到L3缓存乃至内存控制器、QPI的,核心数量越多,那么核心访问发生冲突的几率就越大,这导致了其内存潜伏期的提升。在八核心的Nehalem-EX上,为了避免这种情况变得更严重,开始采用了新的总线来代替这个交叉开关,如下所示:
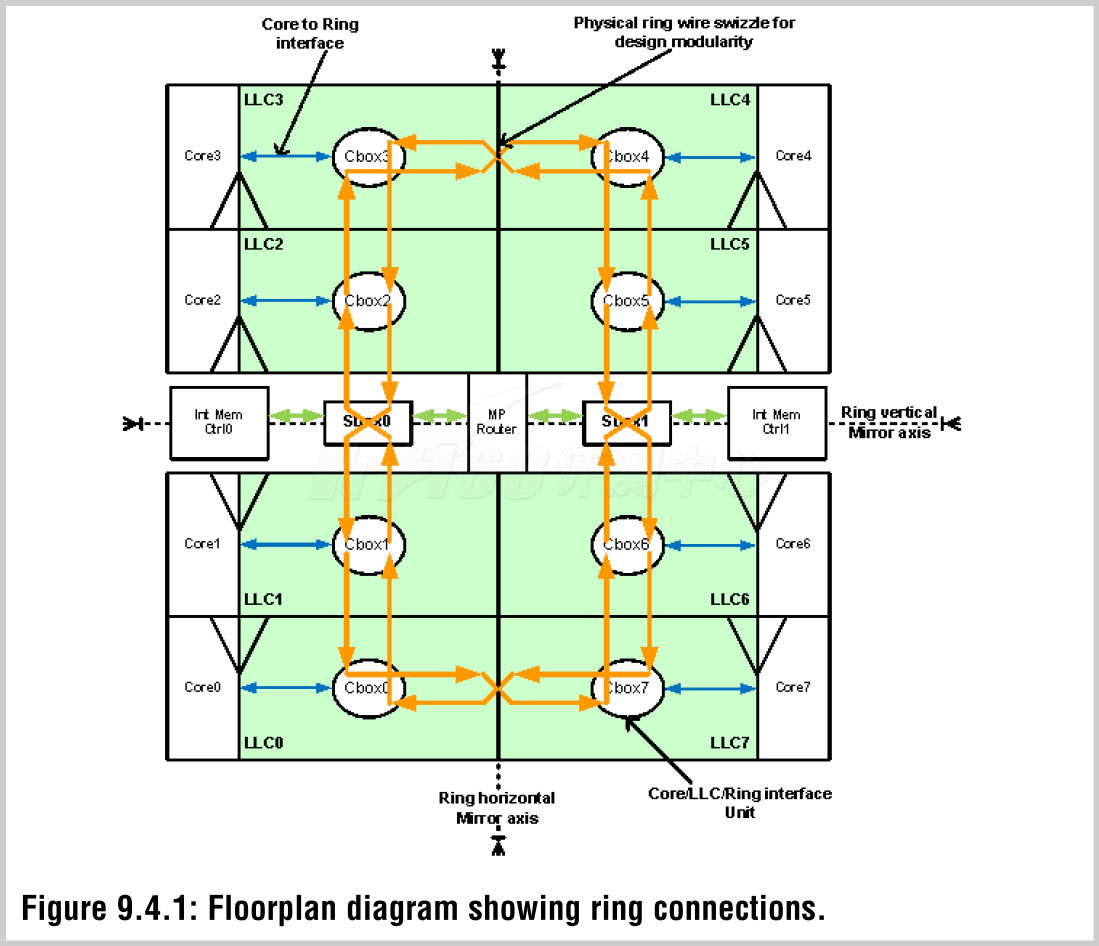
Nehalem-EX:Ring Interconnet
这个总线提供了极高的带宽(一共1.2TB/s)和很低的延迟(5个时钟周期)。在Nehalem-EX的发布文章当中笔者将会继续解析这个结构。
EVEREST也带有CPU和内存的若干项测试项目,也比较经常用来对比处理器的性能:
EVEREST Ultimate Edition 5.30.3000 Benchmark Module 2.4.273.0 | |||
|---|---|---|---|
测试对象 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
内存读取 | 14279 MB/s | 13293 MB/s | 13689 MB/s |
内存写入 | 8865 MB/s | 7526 MB/s | 8324 MB/s |
内存复制 | 11878 MB/s | 10430 MB/s | 10616 MB/s |
内存潜伏 | 64.5 ns | 68.7 ns | 67.0 ns |
CPU Queen | 46138 | 46082 | 52461 |
CPU PhotoWorxx | 58330 | 73372 | 73828 |
CPU ZLib | 193850 KB/s | 282989 KB/s | 319463 KB/s |
CPU AES | 46774 | 849298 | 844363 |
FPU Julia | 22410 | 32730 | 37178 |
FPU Mandel | 12096 | 16349 | 18583 |
FPU SinJulia | 10978 | 16429 | 18706 |
和Sandra结果一样,Westmere-EP的内存读写带宽低了一些(6.9%),内存潜伏期也高一点,约高4.2ns(6.5%)左右,理由和前面一样,都是多个处理器核心争用的缘故。对于一些延迟可能很重要的应用,可以考虑使用4核心的Westmere-EP版本,如X5677等,这些处理器将会(应该)具有比同频Nehalem-EP明显较好的性能。
值得一提的是EVEREST自带的CPU AES,X5670的得分为849298,是X5570的46774分的18.2倍。它确实很有用。
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
在前些日子里CineBench推出了R11.5版本,我们对其和老版本R10都进行了测试。
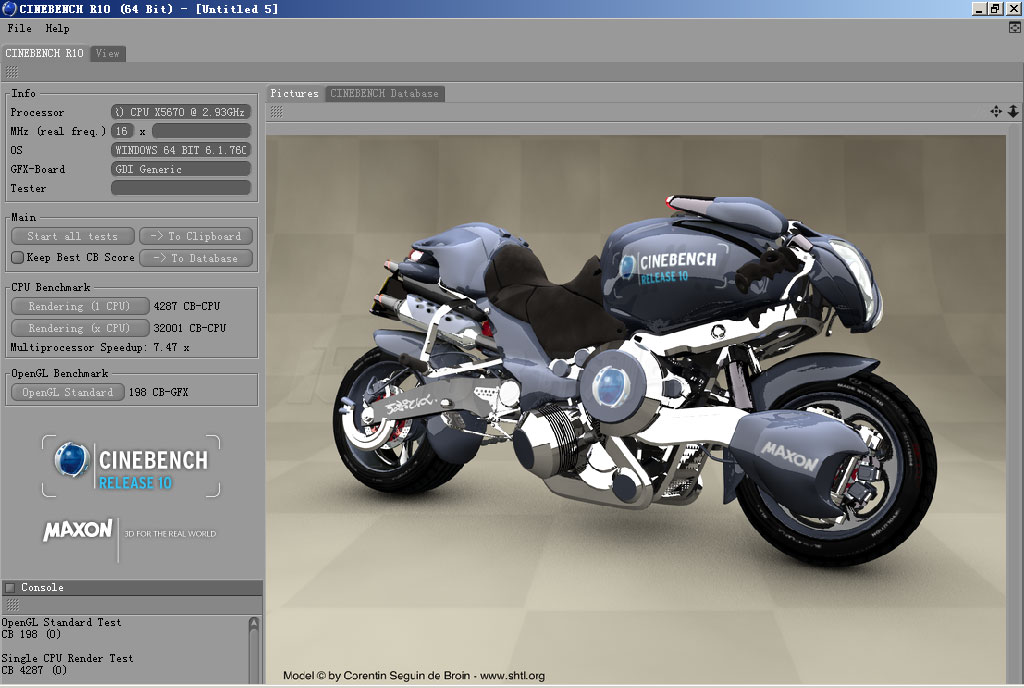
CineBench R10 64bit | |||
| 处理器 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
| 显卡 | - | - | - |
CPU Benchmark | |||
| Rendering (1 CPU) | 4410 CB-CPU | 4287 CB-CPU | 4845 CB-CPU |
| Rendering (x CPU) | 28172 CB-CPU | 32001 CB-CPU | 34800 CB-CPU |
| Multiprocessor Speedup | 6.39x | 7.47x | 7.18x |
OpenGL Benchmark | |||
| OpenGL Standard | 224 CB-GFX | 198 CB-GFX | 217 CB-GFX |
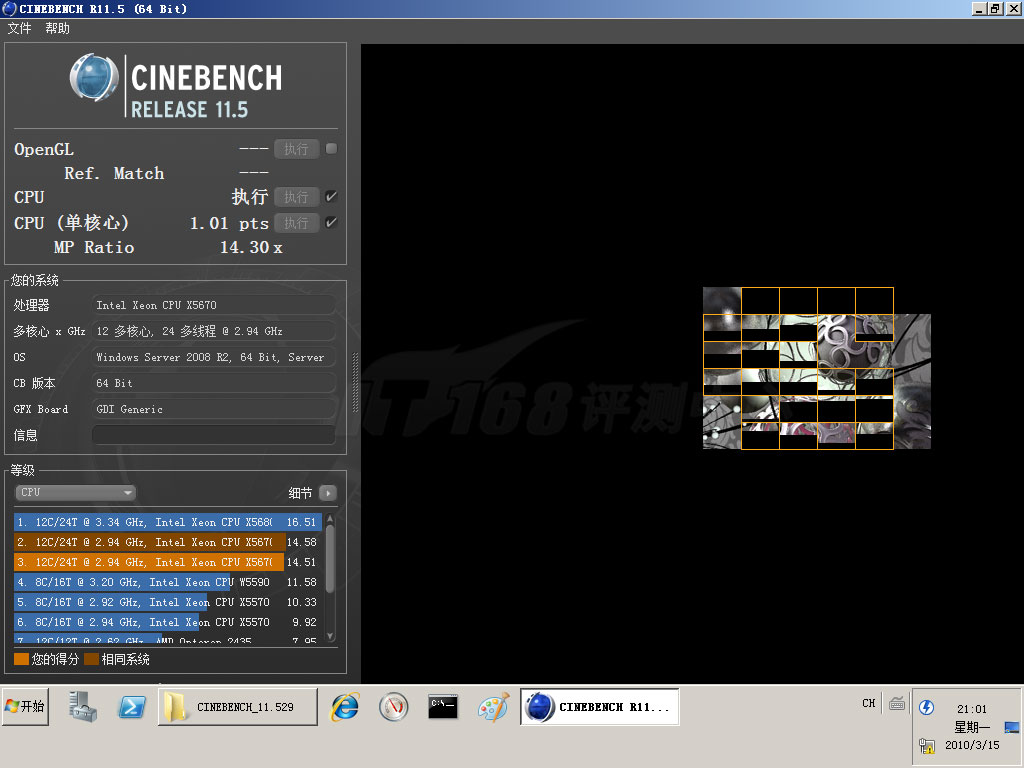
CineBench R11.5测试,它的OpenGL测试需要显卡硬件支持才能进行
最终画面是这样子的
CineBench R11.5 64bit | |||
| 处理器 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
| 显卡 | - | - | - |
CPU Benchmark | |||
| Rendering (1 CPU) | 1.02 pts | 1.02 pts | 1.16 pts |
| Rendering (x CPU) | 9.92 pts | 14.58 pts | 16.40 pts |
| Multiprocessor Speedup | 9.68x | 14.33x | 14.18x |
可以看到,CPU主频影响着单CPU渲染能力,而处理器核心数量则影响到多CPU渲染的性能,有一点是很明显的,就是核心数量越多,那么多处理器的性能提升系数就越小,同样是由于前面所说的,多个核心竞争总线的缘故。要提升它们的效率,就要提升Uncore的频率,或者使用新的拓扑架构。
这三个测试是Intel推荐的项目之一,因此笔者也使用其进行了测试:
MMM - Matrix-Matrix Multiplicaion Benchmark | |||
| 处理器 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
| 单位 | GFLOPS | GFLOPS | GFLOPS |
Threads 1 | |||
| 5000 step | 7.821975 | 7.842319 | 8.877563 |
| 10000 step | 7.890761 | 7.840417 | 8.883291 |
| 15000 step | 7.888751 | 7.845479 | 8.881528 |
Threads 2 | |||
| 5000 step | 15.59136 | 15.62796 | 17.5891 |
| 10000 step | 15.7544 | 15.66469 | 17.73566 |
| 15000 step | 15.7445 | 15.64657 | 17.67208 |
Threads 4 | |||
| 5000 step | 30.69218 | 29.99696 | 34.85343 |
| 10000 step | 31.02227 | 29.75883 | 34.90105 |
| 15000 step | 31.04954 | 30.55926 | 34.92557 |
Threads 8 | |||
| 5000 step | 36.2252 | 49.03697 | 45.99856 |
| 10000 step | 38.21083 | 50.30305 | 45.99856 |
| 15000 step | 40.71236 | 56.00031 | 47.74417 |
Threads 16 | |||
| 5000 step | 59.38371 | 64.04222 | 66.10022 |
| 10000 step | 61.44583 | 62.42291 | 72.38159 |
| 15000 step | 61.83442 | 64.3761 | 73.2495 |
Threads 24 | |||
| 5000 step | 54.82514 | 84.13599 | 89.09254 |
| 10000 step | 54.82514 | 88.58685 | 96.85071 |
| 15000 step | 59.18915 | 90.12297 | 99.22003 |
MMM是一个类似矩阵乘法基准测试软件,得到的结果单位是GFLOPS,也就是说它是一个浮点测试。我们可以看到MMM测试采用的线程数量要和CPU的核心数量吻合,超出的话将会导致性能降低。Nehalem-EP X5570在16个线程下得到的峰值是61.83GFLOPS,而Westmere-EP X5670在24个线程下得到的峰值是90.12GFLOPS,极为符合核心数量多出50%的参数。它和Linpack一样,都能充分地利用CPU运算核心的能力,因此它实际上建议关闭超线程来测试。我们以后会单独列出这个测试。
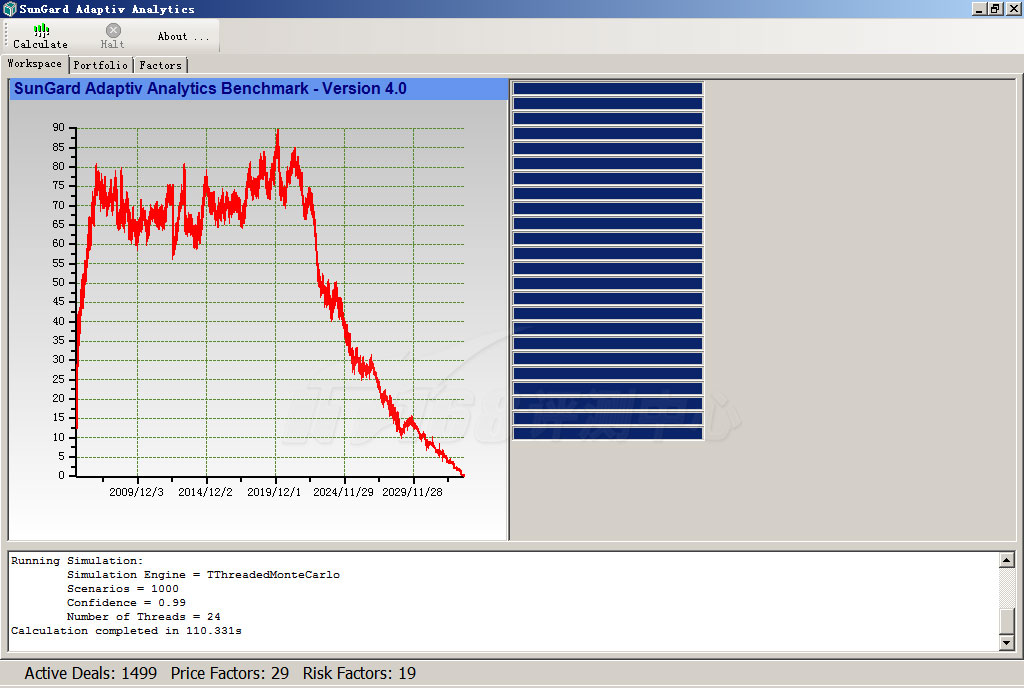
SunGard Adaptiv Analytics Benchmark v4.0
SunGard Adaptiv Analytics Benchmark v4.0 | |||
| 处理器 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
| Threads | 16 | 24 | 24 |
| Time (lower is better) | 138.076s | 110.331s | 94.911s |
这个测试程序是SunGard风险分析管理套件的一个部分,X5670的性能表现比X5570要高25%,X5680则又比X5670高16.2%。
black_scholes | |||
| 处理器 | 双路Intel Nehalem-EP Xeon X5570 | 双路Intel Westmere-EP Xeon X5670 | 双路Intel Westmere-EP Xeon X5680 |
| Threads | 16 | 24 | 24 |
| Time (lower is better) | 9.17s | 6.16s | 5.51s |
black_scholes是对布莱克-肖尔斯期权定价模型进行计算的一个程序,布莱克-肖尔斯期权定价模型是由1997诺贝尔经济学奖的两个获得者创立和发展的模型。测试结果上,X5670比X5570快48.9%(可见其对多核心的支持比较好),X5680比X5570快11.8%。
我们利用新添置的Aitek AWE2101数字功率计和配套的软件测试了整个服务器平台在几种不同的状态下的功耗,AWE2101是一个高精度的数字功耗测试仪:

5位数字精度
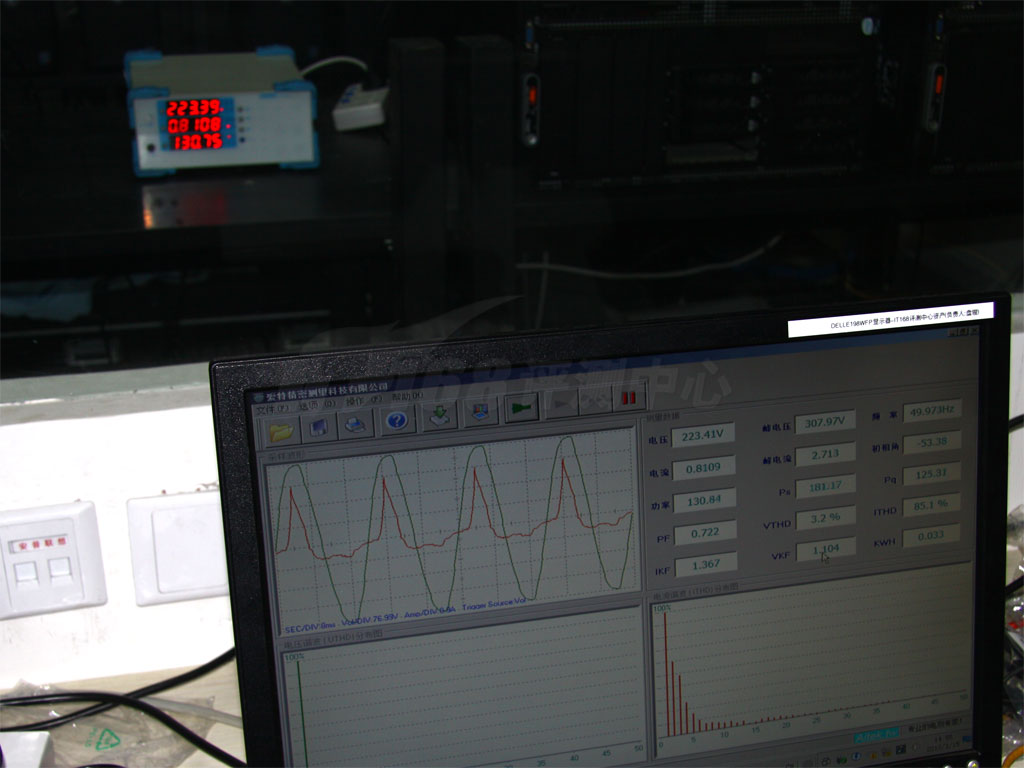
输出到计算机上
测试方法上,也和以往的略有不同,这次使用了常用的烤机Prime95软件,它并不代表着实际工作中Westmere的情况,而只能代表着集中极限情况:
Prime95是一个大质数寻找、验证软件,它能很充分地利用处理器的各种运算单元。它具有三种预设的测试方式:Small FFTs(CPU压力测试,不使用内存)、In-place large FFTs(使用一些内存)、Blend(使用较多的内存),我们对这三种方式分别作了测试。在Blend模式上,使用内存和不使用内存的功率表现是不同的,这也可以部分地看出平台内存功耗占用:
在闲置但是未进入睡眠/待机的情况下,六核Westmere-EP和四核Nehalem-EP具有非常接近的功耗,这表现了Westmere-EP的Power Gating技术表现不错。
Nehalem-EP X5570:0.896V
Westmere-EP X5670:0.912V
Westmere-EP X5680:0.944V
在Small FFT测试(对CPU压力最大,不测试内存)下,不同的处理器立刻显示出差距来,其中X5680达到了不可思议的540W,归根到底是因为多出来两个核心以及比其他处理器更高的核心电压。X5670则功耗和X5570很相近。
这个结果也揭示了X5680和X5670的一个很明显的不同:它们TDP分别为130W和95W,TDP是热设计功耗,并不意味着实际功耗。不过它通常会具有更高的运行功耗(因为通常工作电压会更高)。总的来说,Westmere-EP的功耗控制很不错,其中我们建议使用X5670这款性能、功耗都适中的处理器。
【IT168评测中心】抛去参数截然不同的X5680不谈,Intel 32nm Westmere-EP X5670和频率一致的45nm Nehalem-EP X5570相比在不同的测试当中具有着约25%~50%的性能提升,而功耗只是略微增加(每个处理器约10W左右),这个表现比起Nehalem-EP相对Penryn Xeon的提升(一到两倍)确实显得不那么显眼。
32nm 六核心:Intel Westmere-EP晶圆图
X5680是最高端的型号,而X5670是95W TDP中最高端的型号
不过这个性能提升对于很多应用来说也非常足够了。更多的核心除了带来更好的性能之外,它还提供了更多的选择,例如你可以选择用四核心的Westmere-EP型号,那么在性能比Nehalem-EP高一点(四核心Westmere-EP也配置了12MB L3缓存)的情况下,功耗将会更低。促使一些人群选择四核心Westmere-EP可能还因为一个因素:核心竞争L3/内存控制器/QPI,它导致了一些应用的性能提升幅度低下。我们期待不远的将来可以对这些型号进行测试。
内存支持方面也是Westmere-EP的一个明显增强的地方,它具有以下四点进步:
1、Westmere-EP现在支持低电压DDR3,电压值从原来的1.65V降低到1.50V乃至1.35V
2、Westmere-EP现在支持每个内存通道具有两个DIMM运行在1333MHz,而Nehalem-EP只支持一条,插更多内存会让内存降速
3、Westmere-EP对内存规格的支持总体上提升了,所有型号最低都支持DDR3-1066,而Nehalem-EP最低的支持到DDR3-800
4、Westmere-EP现在支持单条16GB的内存条,总内存容量增加了一倍,达到了288GB
相信对不少人具有不错的吸引力。笔者为了进行SPEC CPU 2006测试特地借来的48GB 1.35V DDR3-1333内存符合了其中的多项要素,测试也正在进行中,稍过一段时间大家讲可以看到Westmere-EP的SPEC CPU性能表现以及1.35V低电压DDR3的功耗表现。
AES NI的效果,数据来源:Intel
此外,AES新指令集的效果不得不提,它确实非常明显,我们进行的EVEREST CPU AES基准测试具有17倍的性能提升。此外,虚拟化方面也明显感到进步不少(1GB大页面、12%降低的虚拟机切换时间),总的来说,Westmere-EP对不少的人来说都很有吸引力,它将会是Nehalem-EP的一个很成功的继任者。
其他厂商的情况如何?
在Westmere-EP通过1GB大页面等的支持来弥补大页面TLB表过少的缺陷的同时,AMD也在弥补它们的弱项:整数流水线过弱。整数操作是大部分日常应用的基础,在对四路六核心Istanbul的测试中我们发现它的单CPU同频整数性能和四核心Nehalem-EP差不多(AMD六核Istanbul 曙光四路服务器评测),而六核Westmere-EP的出现将会继续拉开这个距离。AMD提升整数性能目前的做法有两个:一是在Magny-Cours这样的芯片中增加一倍的核心数量达到十二核并顺便提升了浮点性能,二是干脆在AMD Bulldozer这样的新架构中将整数管线翻倍(双线程还是双核?AMD推土机处理器简析)。

Nehalem Microarchitecture
归根到底,唯有处理器微架构上的设计才是基本,Intel Nehalem处理器具有着优美的微架构(除了大页面TLB有点少之外)和经过千锤百炼的执行管线,以及可以将其性能充分发挥出来的超线程技术,这些才是Intel处理器的核心竞争力。Westmere-EP在强劲的Nehalem微架构的基础上,轻松地发展工艺、增加核心并改良缺陷,提升性能并降低功耗,它代表了目前最强有力的x86处理器(除了稍迟推出的Nehalem-EX之外)。下一个阶段,Lucifer将会带大家观看真正的高端对决:Nehalem-EX VS POWER7,以及Intel的下一代微架构Sandy Bridge,敬请期待。

