全国首发 AMD Shanghai/上海性能评测
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
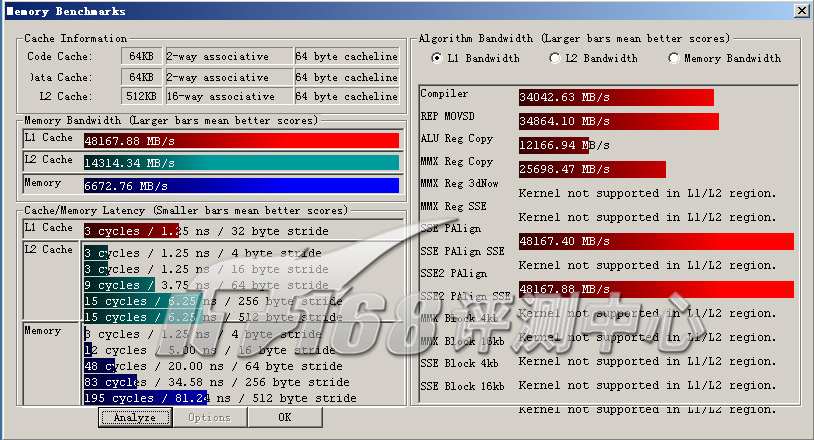
ScienceMark v2.0 Membench L1测试成绩
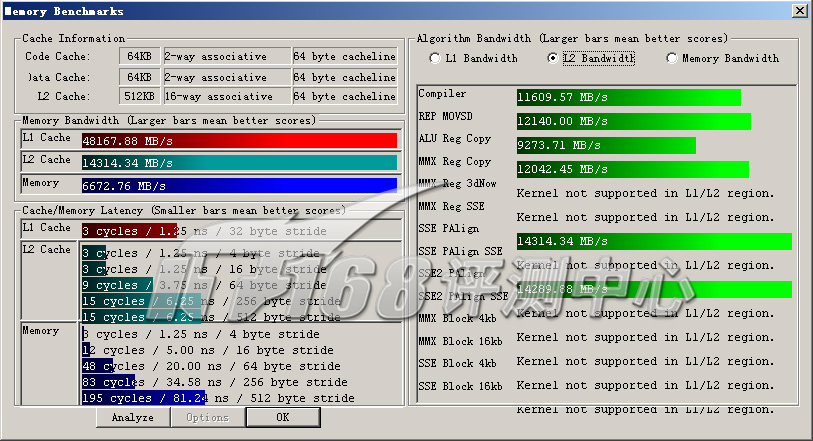
ScienceMark v2.0 Membench L2测试成绩
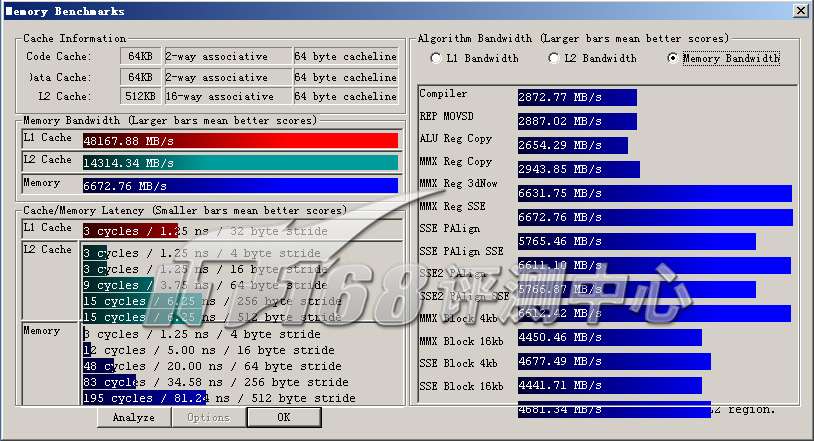
ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是——当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
ScienceMark Membench | |||
| 厂商 | Dawning | Dawning | DELL |
| 产品型号 | AS650 AMD Shanghai Opteron 2378 2.4GHz | AS650 AMD Barcelona Opteron 2350 2.0GHz | PowerEdge 2900 III Intel Harptown Xeon E5430 2.66GHz |
| 内存技术参数 | 2GB R-ECC DDR2-667 SDRAM x4 | 2GB R-ECC DDR2-667 SDRAM x4 | 2GB FBD-ECC DDR2-667 SDRAM x4 |
| L1带宽(MB/s) | 48167.88 | 37069.97 | 55376.16 |
| L2带宽(MB/s) | 14314.34 | 11523.46 | 16757.55 |
| 内存带宽(MB/s) | 6672.76 | 5144.71 | 4485.09 |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 1.25 | 1.50 | 1.13 |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 34042.63 | 28354.58 | 25201.968 |
| REP MOVSD | 34864.10 | 28986.14 | 25467.15 |
| ALU Reg Copy | 12166.94 | 10804.26 | 13093.65 |
| MMX Reg Copy | 25698.47 | 20285.37 | 25242.19 |
| SSE PAlign | 48167.40 | 37003.99 | 52826.21 |
| SSE2 PAlign | 48167.88 | 37069.97 | 55376.16 |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 1.25 | 1.13 | 1.13 |
| 16 Bytes Stride | 1.25 | 1.50 | 1.50 |
| 64 Bytes Stride | 3.75 | 4.51 | 4.51 |
| 256 Bytes Stride | 6.25 | 4.51 | 4.51 |
| 512 Bytes Stride | 6.25 | 4.89 | 4.89 |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 11609.57 | 8830.23 | 118800.48 |
| REP MOVSD | 12140.00 | 9964.34 | 12536.88 |
| ALU Reg Copy | 9273.71 | 7660.43 | 8577.86 |
| MMX Reg Copy | 12042.45 | 9754.61 | 13408.31 |
| SSE PAlign | 14314.34 | 11523.46 | 16719.97 |
| SSE2 PAlign | 14289.88 | 11502.38 | 16757.55 |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 1.67 | 2.00 | 1.13 |
| 16 Bytes Stride | 5.00 | 8.00 | 4.89 |
| 64 Bytes Stride | 20.00 | 31.00 | 19.17 |
| 256 Bytes Stride | 34.58 | 97.49 | 59.77 |
| 512 Bytes Stride | 81.24 | 107.99 | 68.04 |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 2872.77 | 1826.24 | 3178.45 |
| REP MOVSD | 2887.02 | 1851.43 | 3220.23 |
| ALU Reg Copy | 2654.29 | 1606.58 | 2789.34 |
| MMX Reg Copy | 2943.85 | 1882.10 | 2972.91 |
| MMX Reg 3dNow | 6631.75 | 5028.88 | - |
| MMX Reg SSE | 6672.76 | 5106.97 | 3978.53 |
| SSE PAlign | 5765.46 | 4720.15 | 4128.59 |
| SSE PAlign SSE | 6611.10 | 5144.71 | 4390.48 |
| SSE2 PAlign | 5766.87 | 4721.73 | 4326.42 |
| SSE2 PAlign SSE | 6612.42 | 5144.15 | 4441.71 |
| MMX Block 4kb | 4450.46 | 2940.43 | 4063.30 |
| MMX Block 16kb | 4677.49 | 3201.03 | 4479.88 |
| SSE Block 4kb | 4441.71 | 3087.78 | 4074.79 |
| SSE Block 16kb | 4681.34 | 3245.74 | 4485.09 |

AMD 45nm Shanghai Opteron 2378的缓存架构,L3基于48路集合关联
AMD 45nm Shanghai Opteron 2378的缓存架构,L3基于32路集合关联,并且容量只有2MB
Intel 45nm Harptertown Xeon E5430的缓存架构,L3基于24路集合关联
基本上,与处理器结合最紧密的L1,或L2(在有L3的情况下)的延迟总是跟处理器频率密集相关的(这让笔者想起了一个有趣的故事:有些时候Prescott的寄存器存取延迟甚至不如L1/L2的延迟),从总体测试结果来看,Shanghai的L1、L2设计要比Barcelona进步多了,同时其效能也比Intel的Harptertown要高,内存带宽方面,Shanghai处理器明显要比Barcelona要高出30~40%左右,刨去频率上的差异,同频Shanghai的缓存/内存性能要比Barcelona强约10%/20%,也比Intel Harptertown要强。从处理器架构上说,只有Nehalem才是Shanghai设计的对手。

