一文看懂Gen AI浪潮下数据中心的新机遇
随着生成式AI出现突破性进展,数据中心行业目前正在经历飞速的跨越式发展,在未来经济增长和国家安全中有着举足轻重的地位。
Nvidia 的 GB200 系列需要直接对芯片进行液冷,机架功率密度高达 130kW。在性能上,GB200 相比 H100 推理性能提升了约 9 倍,训练性能提升约 3 倍。
因此,那些无法提供更高功率密度的数据中心将错失为其客户提供巨大的性能 TCO 改进的市场机遇,并将在生成式 AI 军备竞赛中落后。
AI需求的驱动促使数据中心设计向适应高功率密度转变。例如,Meta拆除了一整栋在建建筑,因为这是他们多年来一直使用的低功率密度的旧数据中心设计。相反,他们用全新的 AI-Ready 设计取而代之。

变化之下往往潜藏着机遇。
日前,SemiAnalysis发布了一篇深度报告,深入探讨了【AI时代下数据中心的投资机遇】,干货满满。本文将解读一下这篇长文的精华内容,报告链接放在文末,欢迎感兴趣的朋友去看原文。
在正式展开之前,我先把主要结论列出来:
随着Gen AI的发展,数据中心的设计更注重提高功率密度和计算密度,全新的设计理念蕴藏着新的机会。
按关键IT功率,可以将数据中心分为零售数据中心、批发数据中心、超大规模数据中心这三类。
数据中心的关键电气设备包括:高压电压器、中压开关柜、柴油发电机、不间断电源(UPS)等。
电气设备往往形成寡头垄断的市场格局,在AI需求驱动下有望大幅提升收入规模和利润率。
值得关注的电气设备供应商包括:Schneider、ABB、CAT、VERTIV、EAT-N等。
下面我们正式开始。文章有点硬核,建议耐心阅读哈。
一、从“配备空调的办公楼”开始
数据中心旨在以高效、安全的方式为 IT 设备供电,并在 IT 硬件的使用寿命内实现最低的总拥有成本(TCO)。
IT 设备通常布置在装有服务器、交换机和存储设备的机架中,运行这些设备需要大量电力并产生大量热量。
30 年前的数据中心就像是配有空调的办公楼。但如今,随着消费者每天观看数十亿小时的 YouTube、Netflix和Instagram,数据中心的规模已大幅扩大。
现代数据中心每平方英尺所需的电量可能是办公楼的 50 倍以上,为这些服务器散热则需要完全不同的冷却设备,这引发了数据中心建设方式的深刻变化。

在这种规模下,数据中心的任何故障都会造成重大损失,这就需要数据中心内部拥有可靠的电气和冷却系统。
电气故障虽然更常见,但往往具有较小的“爆炸半径”。而冷却故障一旦发生,造成的破坏性会很大。
根据Uptime Institute以及ANSI/TIA-942标准,可以将数据中心按“预期停机时间”和“冗余度”进行分层评估,如下图所示。
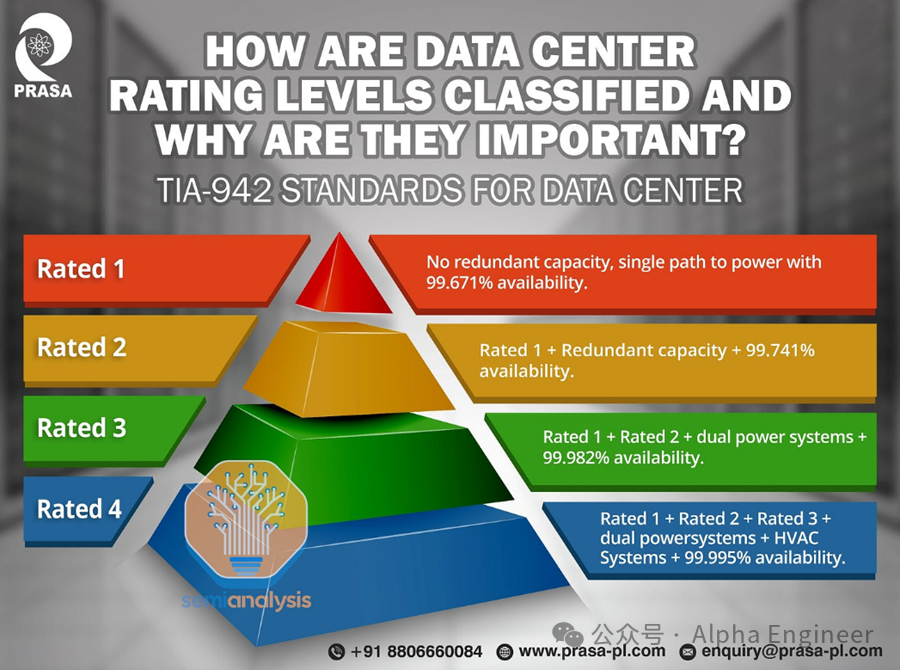
其中,Tier 3级在全球大型数据中心中最为常见。
当我们谈到“冗余度”时,通常使用“N”、“N+1”或“2N”等术语。例如,如果一个数据中心需要 10 个变压器,N+1 的冗余度表示总共需要储备 11 个变压器,其中 10 个可运行,1个冗余,而 2N 则需要购买 20 个变压器。
一个Tier 3级数据中心,通常要求变压器和发电机等组件具有 N+1 冗余,配电组件(不间断电源 UPS和配电单元 PDU)具有 2N 冗余。
Tier 4级数据中心不太常见,通常用于政府或国防领域。
二、数据中心的核心参数:Critical IT Power
数据中心的规模和设计各异,我们通常根据其关键 IT 功率容量(Critical IT Power Capacity)对它们进行分类。这是因为在主机托管业务中,运营商会租赁空机架并按“IT 千瓦/月”定价,数据中心的空间成本远低于电气和冷却设备的成本。
关键IT功率是指IT设备的最大功率,而电网的实际消耗也包括非IT负载,例如冷却和照明。这就涉及到“利用率”的概念,通常来说云计算的电力利用率通常为 50-60%,而 AI 训练的电力利用率则超过 80%。
根据关键IT功率的差异,我们可以将数据中心分为以下三个类别。
零售数据中心(Retail Datacenters)
零售数据中心通常规模较小,功率容量较低 ,最多几兆瓦,通常位于城市内。
他们通常有许多小租户,这些租户只租用几个机架(即几千瓦)。
零售数据中心的主要价值在于“位置、位置、位置”,其运营模式更类似传统的房地产公司。

批发数据中心(Wholesale Datacenters)
相比零售批发中心,批发数据中心的规模更大,通常可以提供10-30MW的关键IT功率。
其客户通常会租赁更大的区域,即一整排或多排,并可选择进一步扩展。
与零售数据中心相比,其价值主张是部署更大的容量并具有可扩展性。

超大规模数据中心(Hyperscale Datacenters)
超大规模数据中心通常由Hyperscalers自行建造,供自己专用。
这些数据中心通常构成一个大型园区,园区内有多栋相互连接的建筑。这些园区的额定功率通常高达数百MW,其中每栋建筑的功率约为40-100MW。
例如下图所示,Google的超大规模数据中心功率接近 300MW。
大型科技公司还可以请服务商为其定制数据中心,然后出租给他们,今年以来100MW 以上的定制租赁越来越常见。

为了让大家对Hyperscale Datacenter Campus的电力需求有个直观的感受,我们来做一个比较。
美国一户普通家庭的平均电力消耗是 1.2 kW,因此一个 300MW 数据中心园区的年用电量相当于约 200,000 个家庭的用电量。
从另一个角度看,20,840 个 Nvidia H100 集群需要一个具有约 25.9MW 关键 IT 电力容量的数据中心。随着Hyperscalers开始构建 100,000 个 H100 集群,对数据中心关键IT功率将有着显著更高的需求。
三、数据中心中的电力传输路径
让我们从一个最简单的布局开始,理解数据中心的设计方式。
数据中心的设计目标是将大量电力输送到装满IT设备的机架上,这些机架位于被称为数据大厅(Data Halls)的房间中。
为了最大限度地减少配电损耗,需要将电压保持在尽可能高的水平。这是因为电压越高意味着电流越低,功率损耗与电流的平方成正比(Ploss= I2R)。
但是高压是很危险的,需要更多的绝缘措施。越靠近终端设备,电压就要越低。
因此,向建筑物输送电力的首选方法是中压,如11kV 或 25kV 或 33kV。而当我们从建筑物内将电力输送进入数据大厅时,需要再次将电压降低至低压,如美国的415V三相。
从外到内,电力传输遵循以下路径:
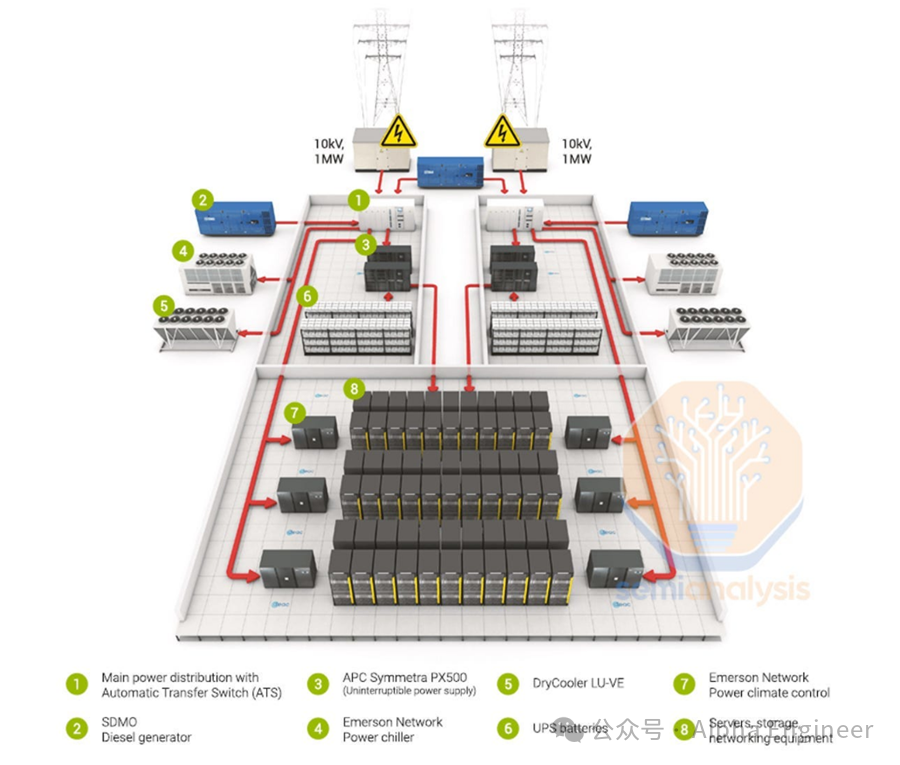
电力公司一般提供的是高压电力(>100 kV),因此需要使用on-site变电站和变压器来将其降低至中压(MV)。
然后,中压电力将使用 MV 开关设备安全地分配到一个位于数据大厅附近的变压器,将电压降至低压 (415V)。
与变压器配对的是柴油发电机,其输出也是 415V 交流电。如果电力公司突然停电,自动转换开关 (ATS) 可以自动将电源切换到发电机,确保持续供电。
电力进入数据大厅后,开始分成两条传输路径:一条通向IT设备,一条通向冷却设备。我们重点来看IT设备的电力传输路径。
首先,电力流经 UPS 系统,通过配电单元(PDU)将电力输送给IT设备。
该系统连接到一组电池,通常有 5-10 分钟的电池存储时间,足够发电机启动并避免暂时停电。
随后通过电源单元 (PSU) 和稳压器模块 (VRM) 向芯片进行供电。
当然,这张电力输送图会随着数据中心容量的不同而形成很大差异,但是整体的思路和电力流向是相似的。
四、数据中心中的核心电气设备:高压变压器
现代超大规模数据中心往往在现场设有高压变电站,例如下图中Microsoft的站点。
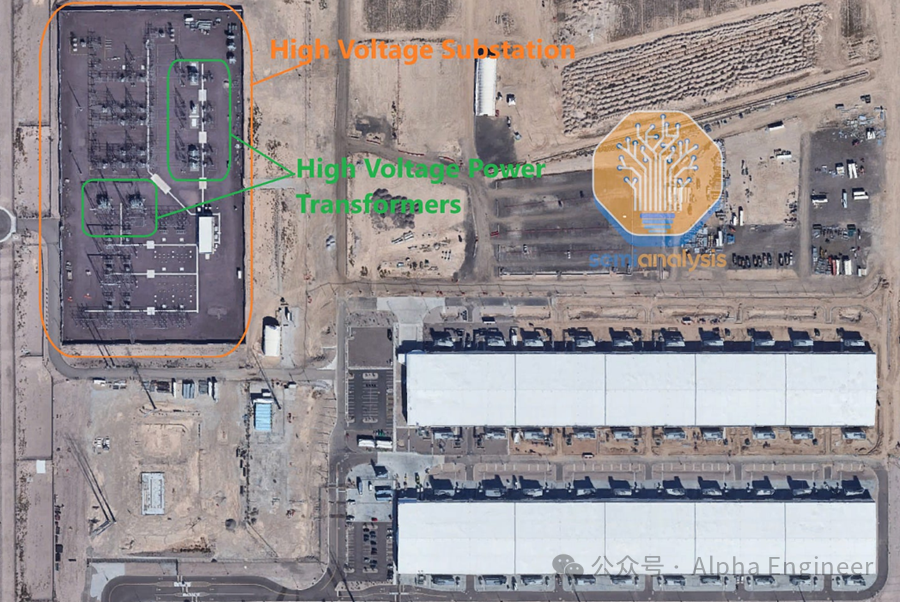
这些设施通常会被放置在高压 (HV) 输电线路(138kV 或230kV 或 345kV)附近。
这些变压器的额定功率以 MVA 为单位。MVA 大致相当于MW,但 MVA 是“视在功率(Apparent Power)”(就是电压 * 电流),而 MW 是“实际”功率。通常来说,MW会比MVA低5-10%。
高压变压器额定容量通常在 50 MVA 和 100 MVA 之间。例如,需要 150MW 峰值功率的数据中心园区可以使用两个 80 MVA 变压器,或三个变压器以实现 N+1 冗余以应对可能的故障。
每个变压器将电压从 230kV 降至 33kV,将电流从~350 安培增加到 ~2500 安培。在这样的 N+1 配置中,所有三个变压器将共享负载,但以额定容量的 2/3 运行。
值得注意的是,高压变压器通常是定制的,因为每条输电线路都有自己的特点,因此往往需要较长的交货时间(>12 个月)。为了缓解建设瓶颈,数据中心运营商一般在规划阶段就开始预订高压变压器。
尽管变压器是数据中心中电力传输系统的核心组件,它其实是一种非常简单的设备,即将交流电 (AC) 的电压和电流从一个级别转换为另一个级别。
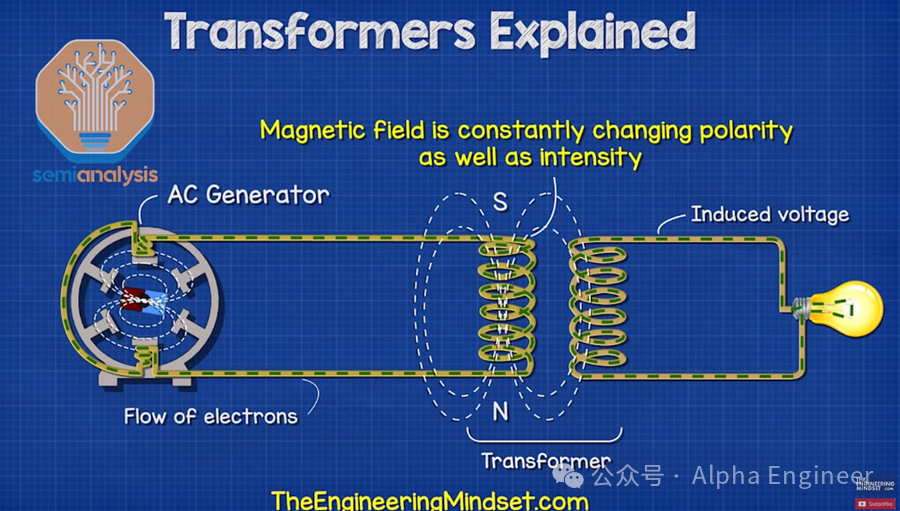
变压器的基本原理是电磁感应。我们把两个铜线圈并排放置,其中一个线圈通上交流电,通过电磁感应,该线圈上的电力就可以传输到另一个线圈上。
在此过程中总功率保持不变,我们可以通过改变电线的特性来产生自己想要的电压和电流。
例如当次级线圈的匝数少于主线圈,则电力将以较低的电压和较高的电流传输,这是降压变压器的原理。
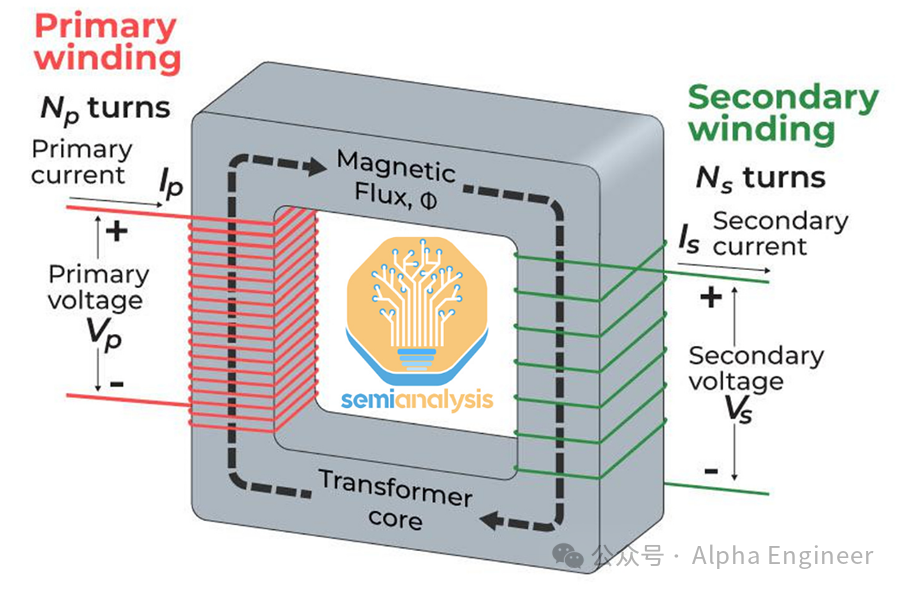
变压器的两个主要组件是线圈用的铜和“变压器铁芯”用的钢。为了提升变压器的传输性能,其铁芯通常需要一种称为 GOES(晶粒取向电工钢)的特种钢,这种钢的制造商数量有限。
五、发电机、中压变压器、配电器
在高压变压器的帮助下,我们将高压(即 115kV 或 230kV 等)降至中压 (MV)(即 33kV、22kV 或 11kV 等),下一步需要做的是使用中压开关设备将中压电力分配到各个数据大厅附近。
服务器和交换机等典型的 IT 设备无法在 11kV 下运行,因此在数据大厅通电之前,我们需要另一组中压 (MV) 变压器,通常为 2.5 MVA 或 3 MVA,将 MV(11kV/25kV/33kV)降至 LV(415V,美国常见电压)。
下图把这个中压变压和配电过程展示得比较清晰。
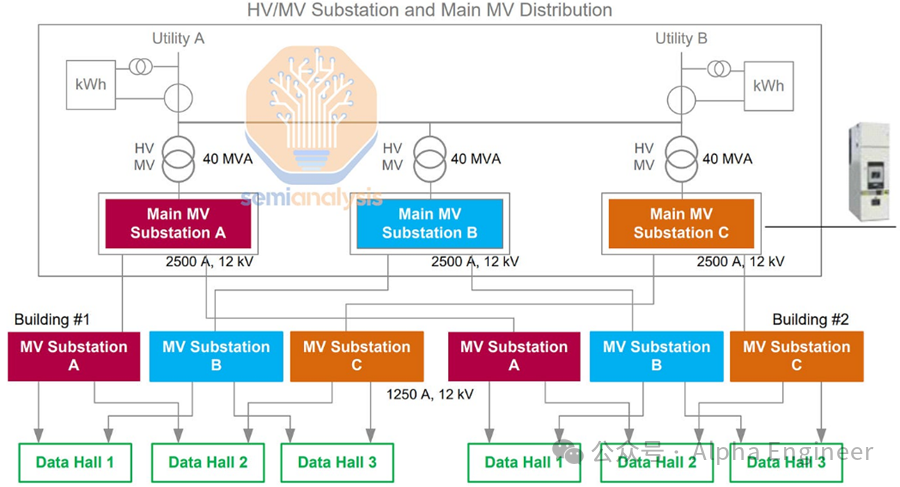
每个LV 变压器旁边都有一个与变压器额定功率相匹配的发电机,如果变压器或变压器上游的电源发生故障,发电机将自动介入。
自动转换开关 (ATS) 通常是 LV 开关设备的组件,用于在发生这种情况时自动切换到发电机,将其作为主电源。
举个例子,一台 3 兆瓦发电机的马力超过 4,000,与火车头的发动机类似。在超大规模数据中心中,通常有 20 台或更多这样的发电机。
这些发电机通常使用柴油。数据中心在满负荷情况下通常可储存 24 到 48 小时的燃料,而柴油的运输和储存便利性使其成为首选。柴油也更节能,但污染更严重。由于监管限制,柴油发电机往往更昂贵,因为需要特定设备来减少环境污染。

自动转换开关 (ATS) 的下游是一套不间断电源 (UPS) 系统,用于确保电源永不中断。
发电机通常需要约 60 秒才能启动并达到满负荷,但就像汽车发动机一样,它们有时不会在第一次启动时启动。UPS系统的作用是填补这一空白,因为它们的响应时间通常低于 10 毫秒。
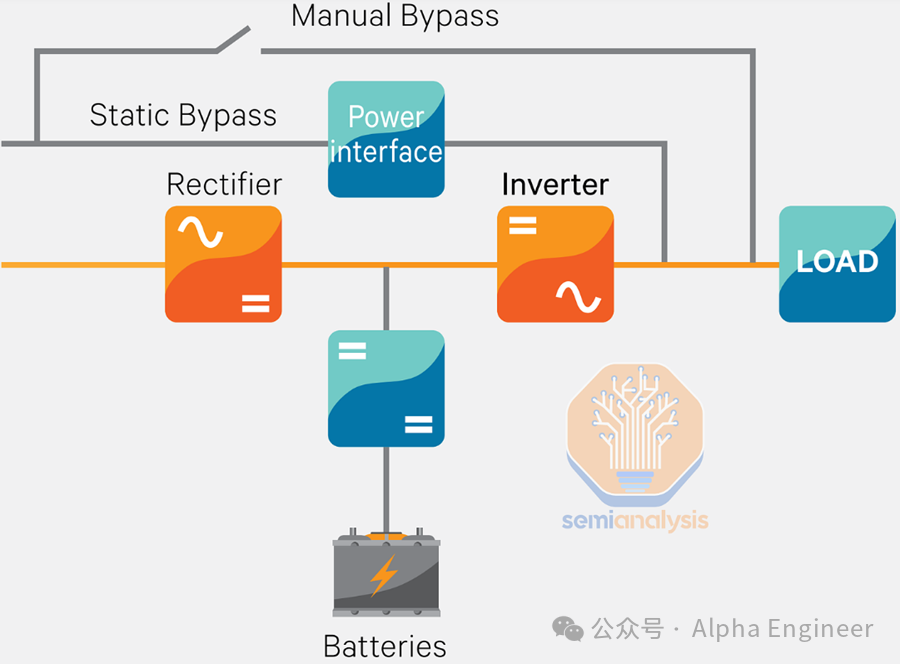
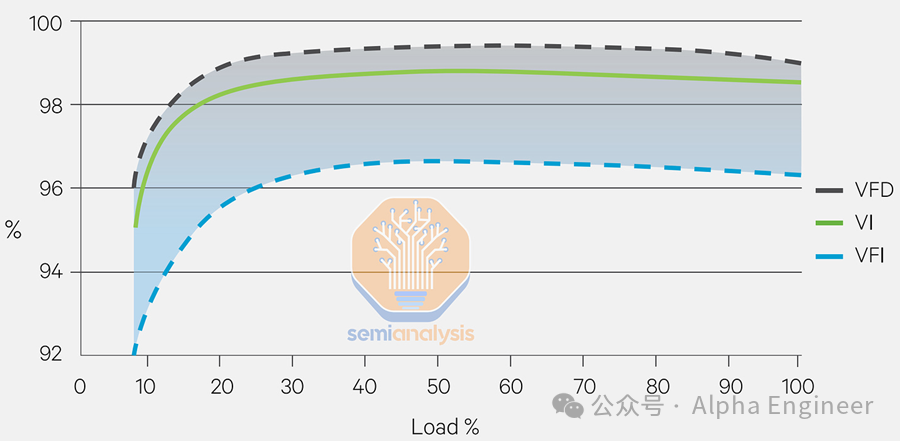
UPS 通常会带来3-5%的损耗,当负载较低时损耗会进一步加剧。现代设备可以通过待机模式(VFD)或者通过绕过 AC-DC-AC 的转换,将效率提高到 99% 以上,但这会使转换时间增加几毫秒 (ms),并带来短暂断电的风险。
六、突破传统数据中心的极限:更高的机架密度
生成式AI带来了新的大规模计算需求,从而显著改变了数据中心的设计和规划。
一个显著的变化是计算密度。网络是增加集群规模的关键因素,是资本支出中的重要组成部分。一个设计不良的网络会显著降低 GPU 利用率,大幅提高成本。
在大型集群中,我们希望尽可能多地使用铜线。使用铜电缆进行通信而非光纤收发器,是因为光纤收发器成本高、耗电高、延迟高。
但是,铜线高速传输的覆盖范围通常最多只有几米。因此,为了通过铜线进行通信,GPU 之间必须尽可能靠近彼此。
计算密度在Nvidia最新的GB200系列中体现得淋漓尽致。NVL72 是一个由 72 个 GPU 组成的机架,总功率超过 130kW。所有 GPU 都通过NVLink 互连,与 H100 相比吞吐量提高了 9 倍。
从数据中心的视角来看,这里面最关键的参数是每个机架130 kW+的电力供给。
这与过去有何不同?让我们看看下面的图表:平均机架电力密度在2023年之前一直低于10kW,而Omdia 预计到 2030 年这个数字将上升到 14.8kW。
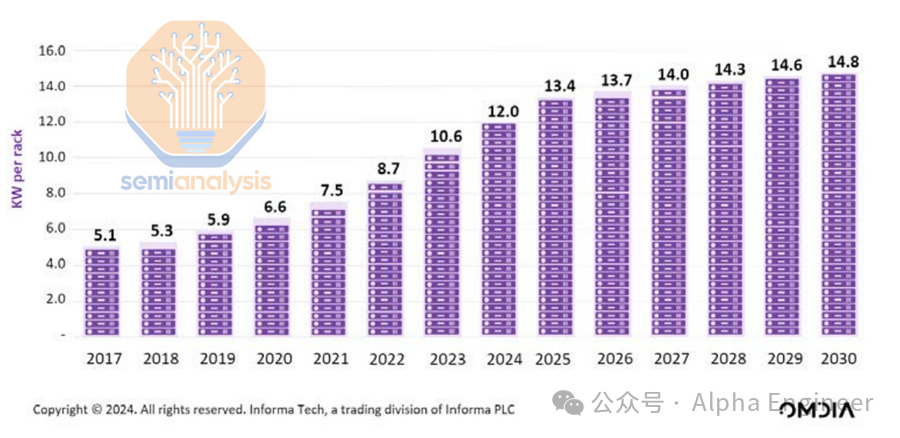
Hyperscaler数据中心的机架密度往往千差万别。按照目前的数据来看,Meta 的机架密度最低,约10+千瓦,而 Google 的机架密度最高,通常超过 40 千瓦。
从这个角度来看,我们就不难理解为什么Meta要拆掉自己的旧数据中心,按全新的设计方案来重新建设了。

Meta原先的设计方案是“H型”的建筑,功率密度太低了。在比较功率密度时,Google 的每平方英尺千瓦密度比 Meta 高 3 倍以上。
虽然“H”也有自身的优点,但在AI时代最关键的计算密度上却表现欠佳,如果不进行改建的话,将成为GenAI军备竞赛中的一个关键的竞争劣势。
七、构建下一代Blackwell数据中心的核心玩家
电力需求的大幅增加将导致电气设备供应商的产销量大幅增加,这可能会进一步收紧供应链,并导致价格上涨。
增加功率密度的需求将与总电力需求一样具有强大的驱动力。无论设备的外形尺寸或占地面积如何,电力设备的成本都将与提供的千瓦数成比例增加。
一个可以稍微抵消需求大幅增长的因素是,越来越多的Hyperscalers开始接受较低的冗余度。
在大规模AI训练中,GPU 节点的高故障率使得着训练框架在某种程度上已经能够应对节点故障,这意味着数据中心方面可以接受较低的冗余度。
在数据中心的设计方案中,高密度化正成为首选方案。为了增加密度并缩短网络距离,Hyperscalers和主机托管运营商正在建设多层数据中心,例如 Applied Digital Ellendale,它有三层楼和两个 50MW 数据大厅。微软和 QTS 也在这个方向上大举进军。

电气设备大多是标准化的,而且电气公司可以通过与当地安装人员、电工、公用事业公司建立长期关系,从而形成一定规模的网络效应,保护它们免受竞争,这导致了电气行业出现了寡头垄断的市场结构。
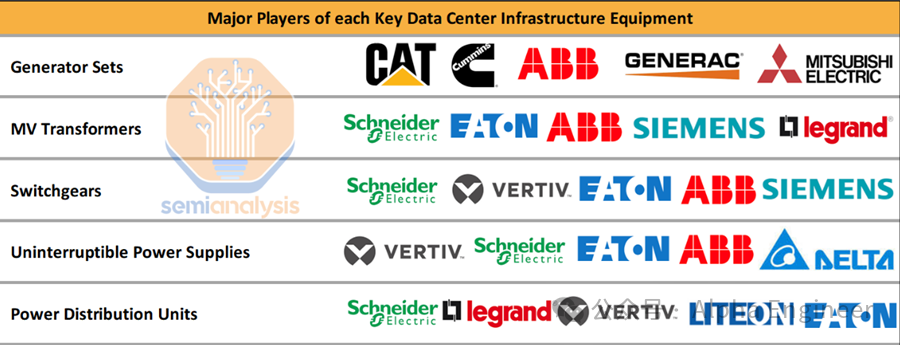
这些主要供应商包括:
发电机组(如CAT、ABB、GENERAC等)
中压变压器(如Schneider、ABB、SIEMENS等)
开关柜(如Schneider、VERTIV、EAT - N等)
不间断电源(如EAT - N、ABB、VERTIV等)
配电单元(如Schneider、legrand、VERTIV等)
随着Nvidia 大力推广全新的超高密度设计,我们认为许多运营商尚未做好准备,机电工程人才的需求可能会骤增。
过去几年来,施耐德和 Vertiv 等一些供应商投入了大量资金来构建自己的数据中心设计能力,现在正与Nvidia 合作构建 AI-ready蓝图。
在AI时代,快速变化和快速上市意味着数据中心运营商必须依靠施耐德和 Vertiv 等解决方案提供商来推动设计和部署。
这意味着电气设备提供商将在AI时代获得更大的议价能力、更大的市场空间、以及更高的利润率。

