01 AB 实验简介
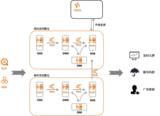
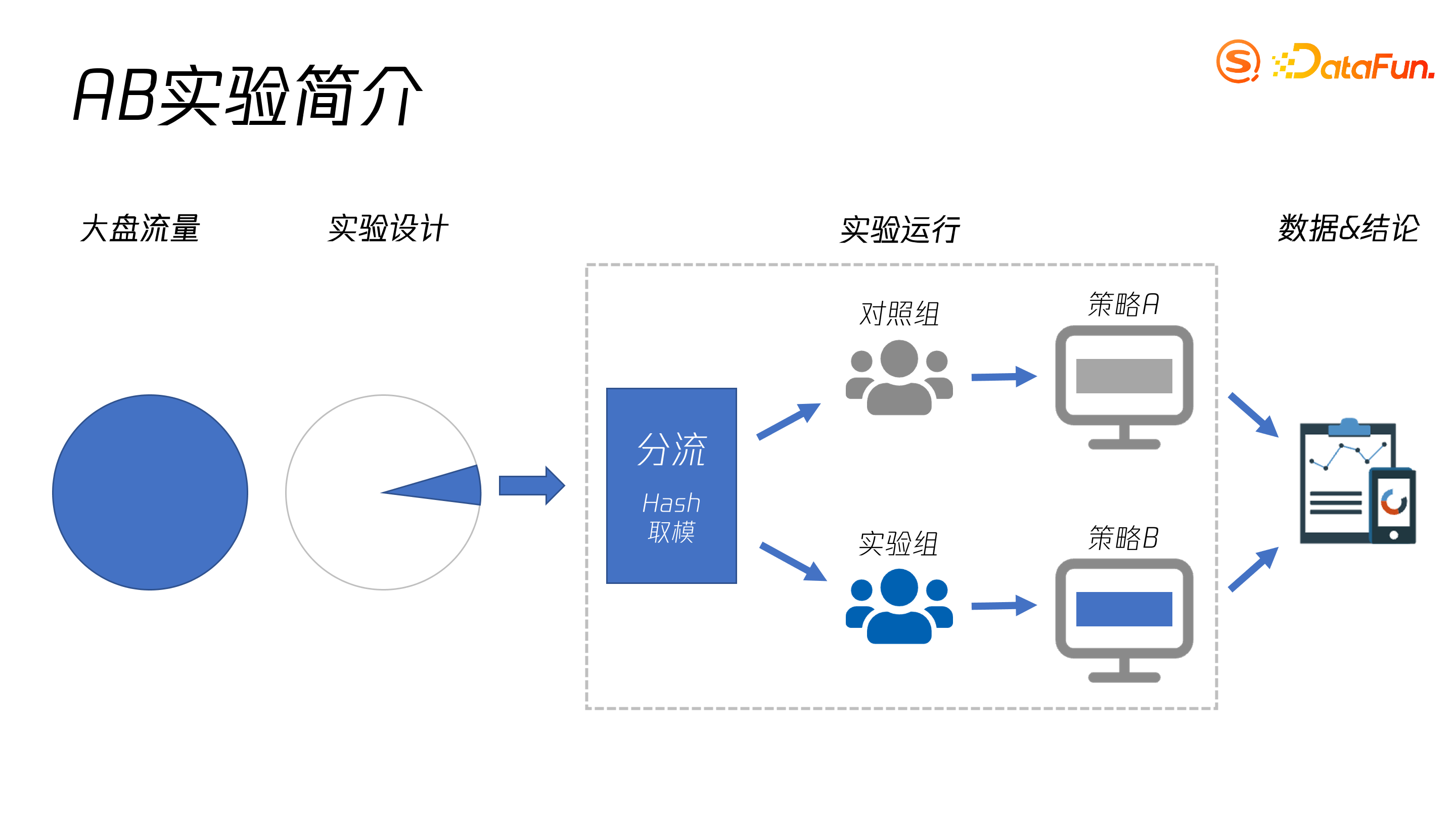
AB 实验又称双盲测试、A/B testing、随机分组实验等,主要目的在于降低风险和准确量化实验结果。其基本思想是从大盘中取出一小部分流量,完全随机地分给对照组和实验组,通过回收不同实验组用户的行为数据,应用统计学方法得出结论。
早期的实验平台只具有单层。单层平台的问题在于若单次实验选取 10% 流量,则该平台最多只能承载 10 个实验,会导致实验流量饥饿问题。为了解决这一问题,目前的实验平台采用了多层的形式。
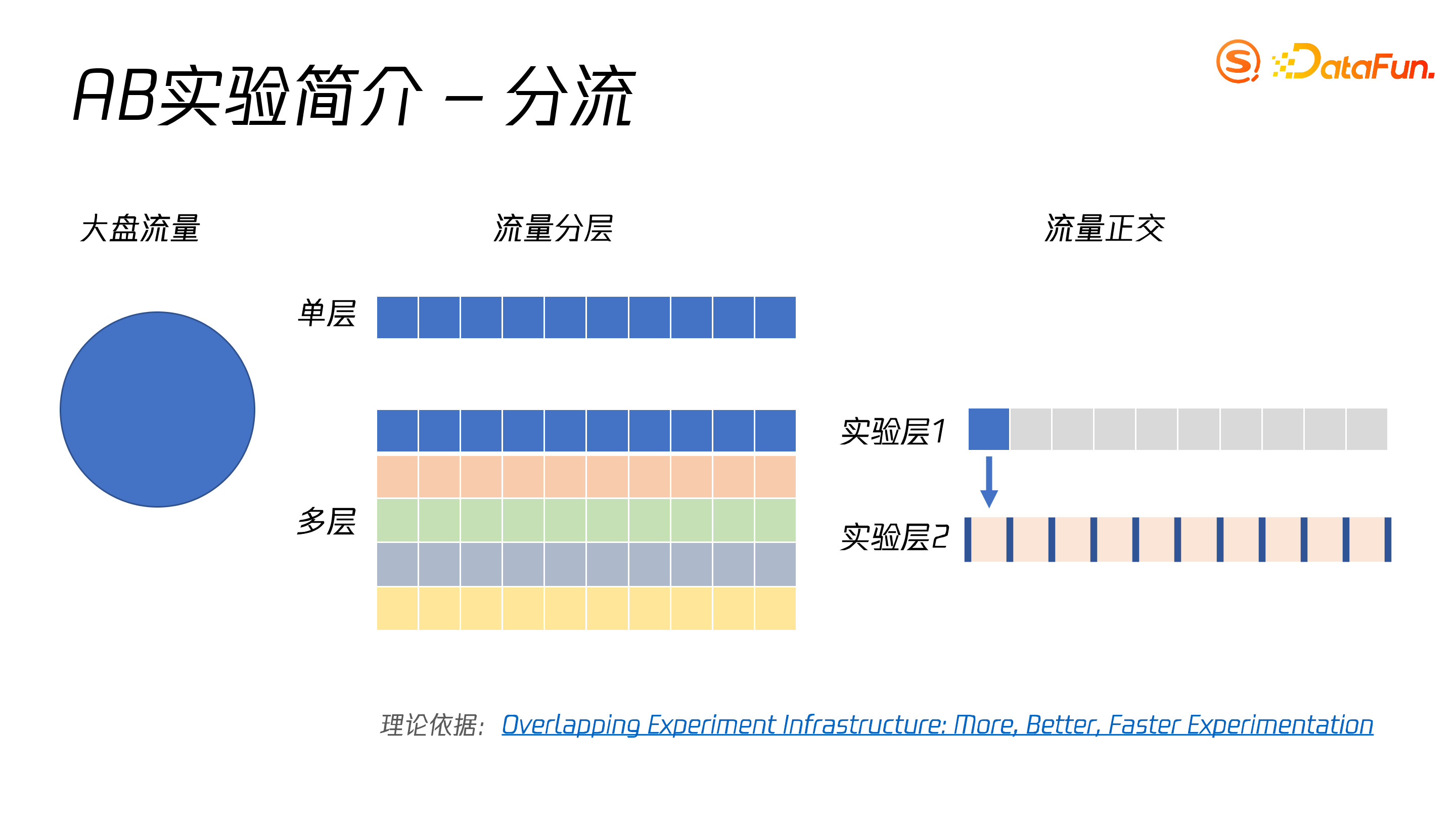
“层+域”,每个实验域下会建一个贯穿层,贯穿层和多层之间互斥,多层之间的流量相互正交,从而保证上层实验的数据可以均匀分散到其他各层中,一个实验层的流量被用完了,在其它层还可以继续创建实验。现有主流的多层域的平台设计大多参考 Google 论文:Overlapping Experiment Infrastructure: More, Better, Faster Experimentation。
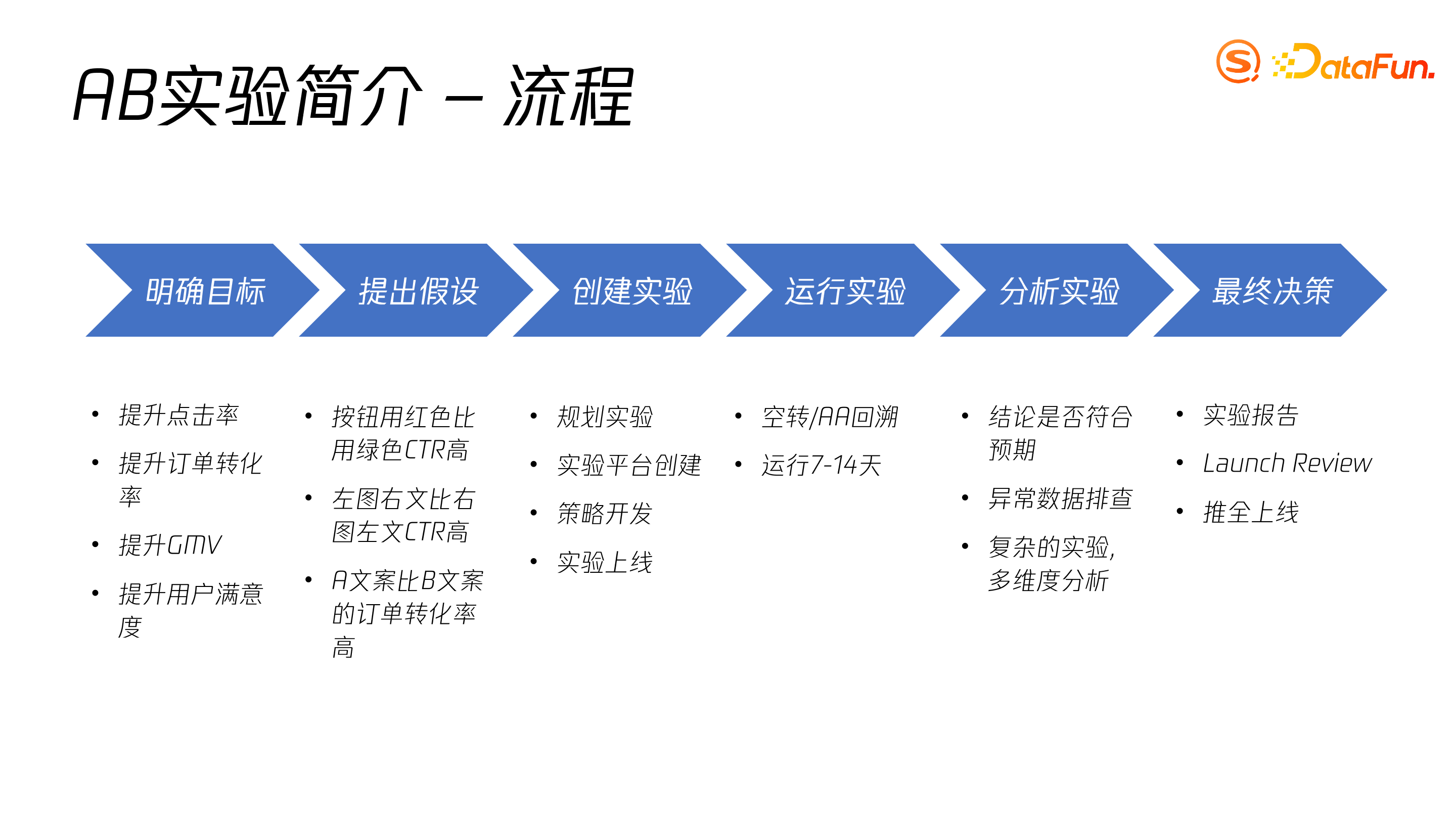
实验流程总体上可分为六部分:明确目标、提出假设、创建实验、运行实验、分析实验和最终决策。
02 各类型搜索实验介绍
搜索场景有一些特有名词,为了更好地理解搜索实验,首先来介绍一下这些名词。

Query:查询词,指在搜索栏中输入的词。
意图判断:指对 query 的目的判断。
结果页:指搜索结果页面,通常由 10 个卡片组成,每个卡片有对应的卡 ID 和位置等信息,卡片与 query 对应。
QV:指 query 访问(查询)次数。
卡影响面:指卡在搜索结果页中的比例。
策略影响面:指策略在大盘中的生效比例,有些策略覆盖多张卡。
卡位置:指卡在搜索结果页中的排序位置。
实验场景主要有以下几类:
搜索结果页改版:包括整体样式、字号调整、圆角方角调整等,影响面广,基本覆盖所有用户。
卡样式改版:包括 UI、排版、数据等,影响面不大,影响部分流量,需求量高。
策略控制排序、卡内容智能展现:影响面小,影响部分流量。
算法控制排序:影响面较小,影响部分流量。
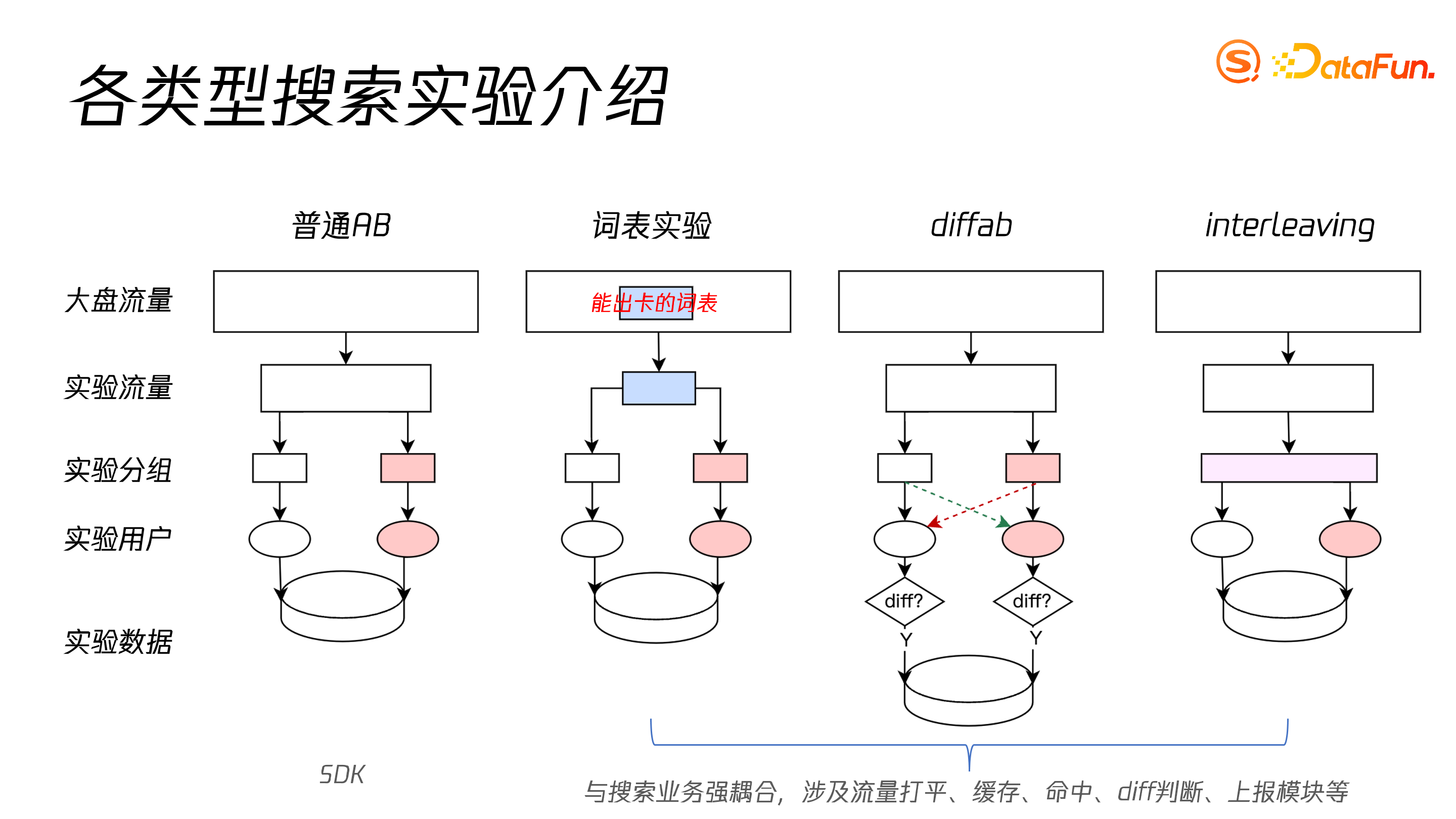
根据不同的实验场景,平台提供了四类实验类型的支持,包括:普通AB实验、词表实验、diffab 实验和 interleaving 实验。
普通 AB 是在大盘中随机选取流量,并随机分配给两个组别,不同组的用户会看到不同的策略,最后收集用户行为数据并得出结论。
词表实验是和卡绑定的,一些特定的 query 才会出卡,因此影响面与卡相关,可大可小。比如一张卡的影响面是千分之一,如果大盘流量是一千万,样本量要达到万级别,就要选大盘的 100%。这样可能会导致流量的浪费,或影响其它实验。
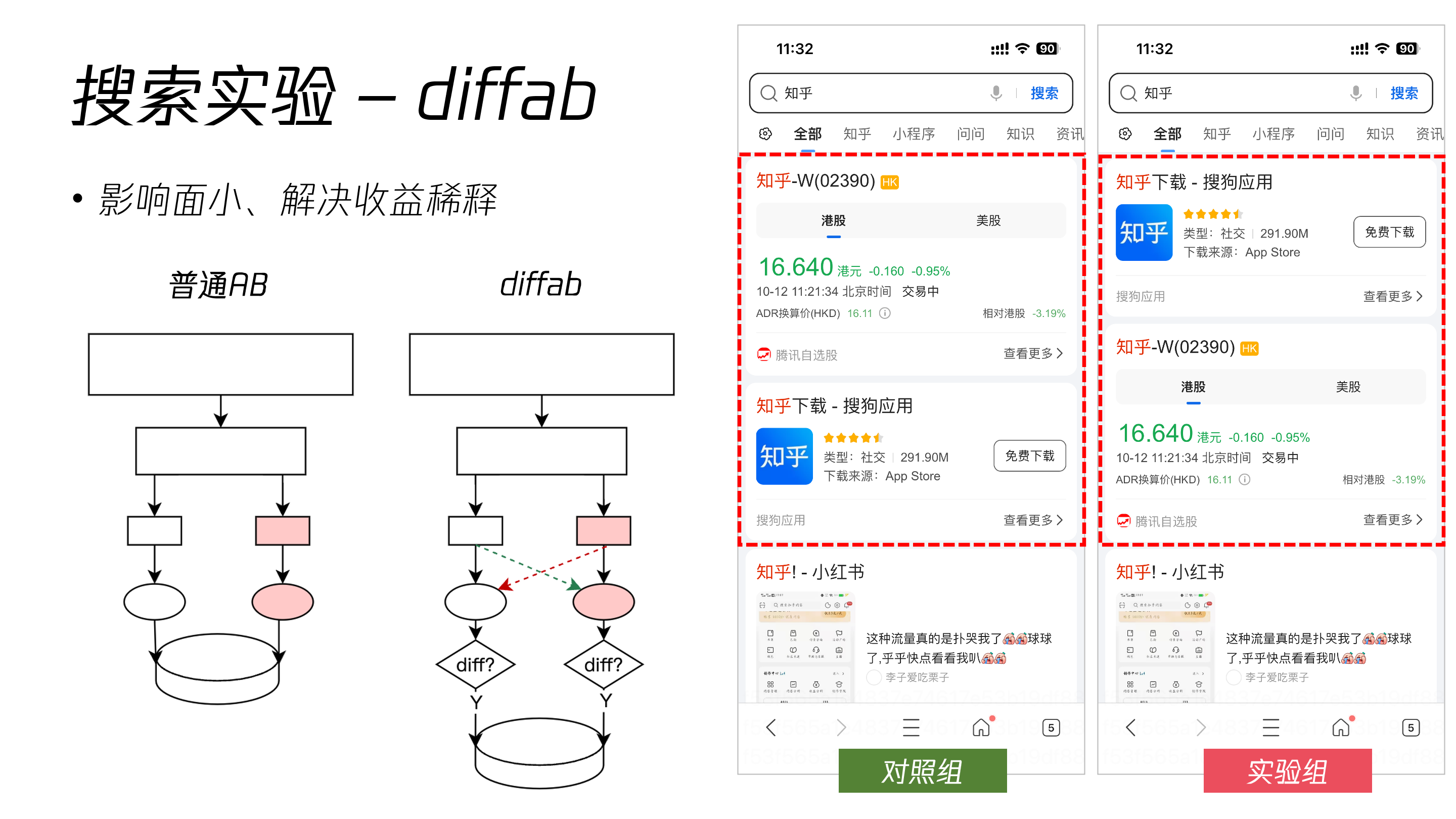
Diffab 实验适用于实验组和对照组区别较小的情况,控制组和对照组将同时下发流量至两个组内用户,并统计其行为之间存在差异的部分,可以解决效果被稀释的问题。
Interleaving 实验是在一个组内,通过两个不同的算法策略随机展现给控制组和对照组用户,计算算法策略的得分和调整策略的结果。
这四种实验分别适用于不同的场景,普通AB实验适用于搜索结果页改版的场景;卡样式改版的场景需要使用词表实验,并且需要绑定卡 ID;策略控制排序和卡内容智能展现的场景,有 diff,影响面小,适合使用 Diffab 实验;算法控制排序,则适合采用 interleaving 实验。
接下来举一些真实的案例。
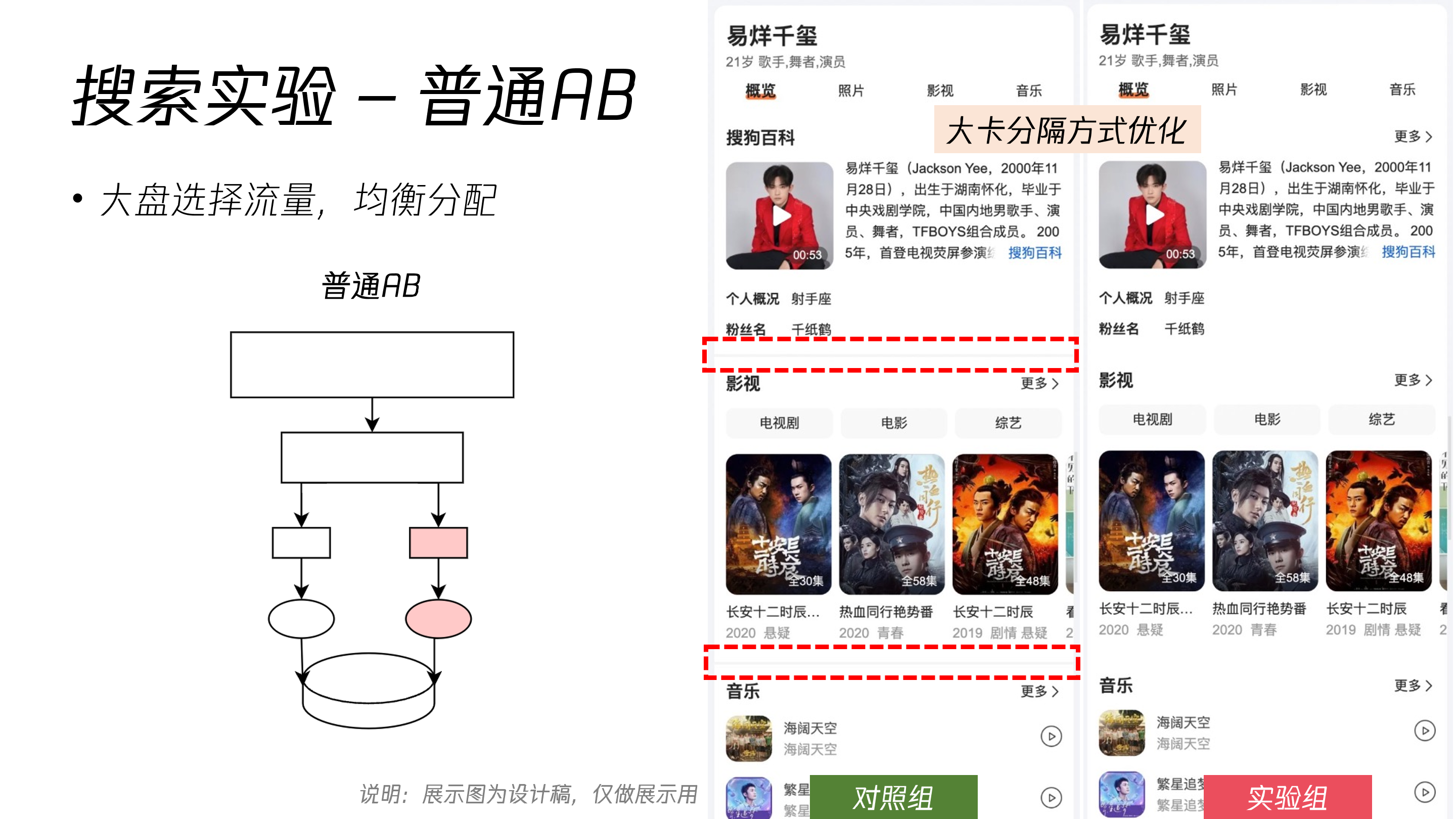
普通AB实验
结果卡优化升级实验中,对于卡片样式进行了调整,由于影响面广,选用大盘1% 甚至更少的流量就可以做出效果,因此选用普通 AB 实验。大盘选择流量,均衡分配。
词表实验
搜索词与卡对应,影响面相对较小,召回流量有限,因此首先将能出卡的词表选取出来,在此基础之上做分流。通过配置词表包+卡 ID,基于词表分流和统计数据,保证该卡用户都能参与实验。如果卡对应的样本量大,可以选择卡对应的一部分用户参与实验;如果卡对应的样本量小,则可将所有用户分至两个组别。

Diffab
实验组和对照组中并非百分之百应用或不应用某项更改策略,在请求对照组时会同时虚拟请求实验组,如果两个请求不一致,则认为其中存在 diff,在数据上报过程中进行标记。最终数据统计时统计存在 diff 的部分。实验组也采取同样的操作。
Interleaving
普通 AB 实验在 hash 取模分流时存在用户活跃度分流不均、重度用户比例不均的问题。Interleaving 在一个组内进行算法混插,再根据用户的行为数据进行统计,实验周期更短,需要样本量更少。
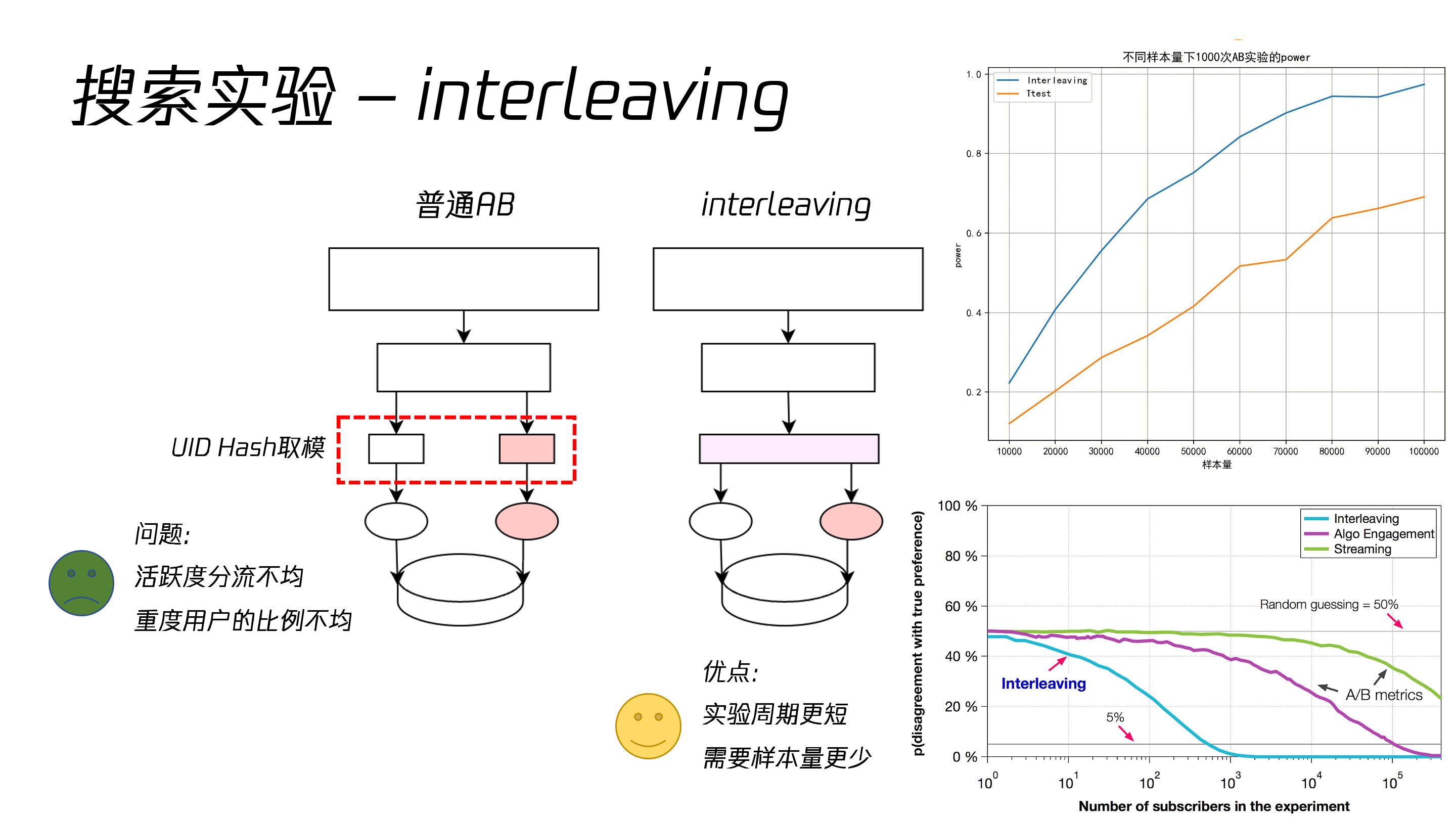
下图中对普通 AB 实验和 Interleaving 实验进行了对比。
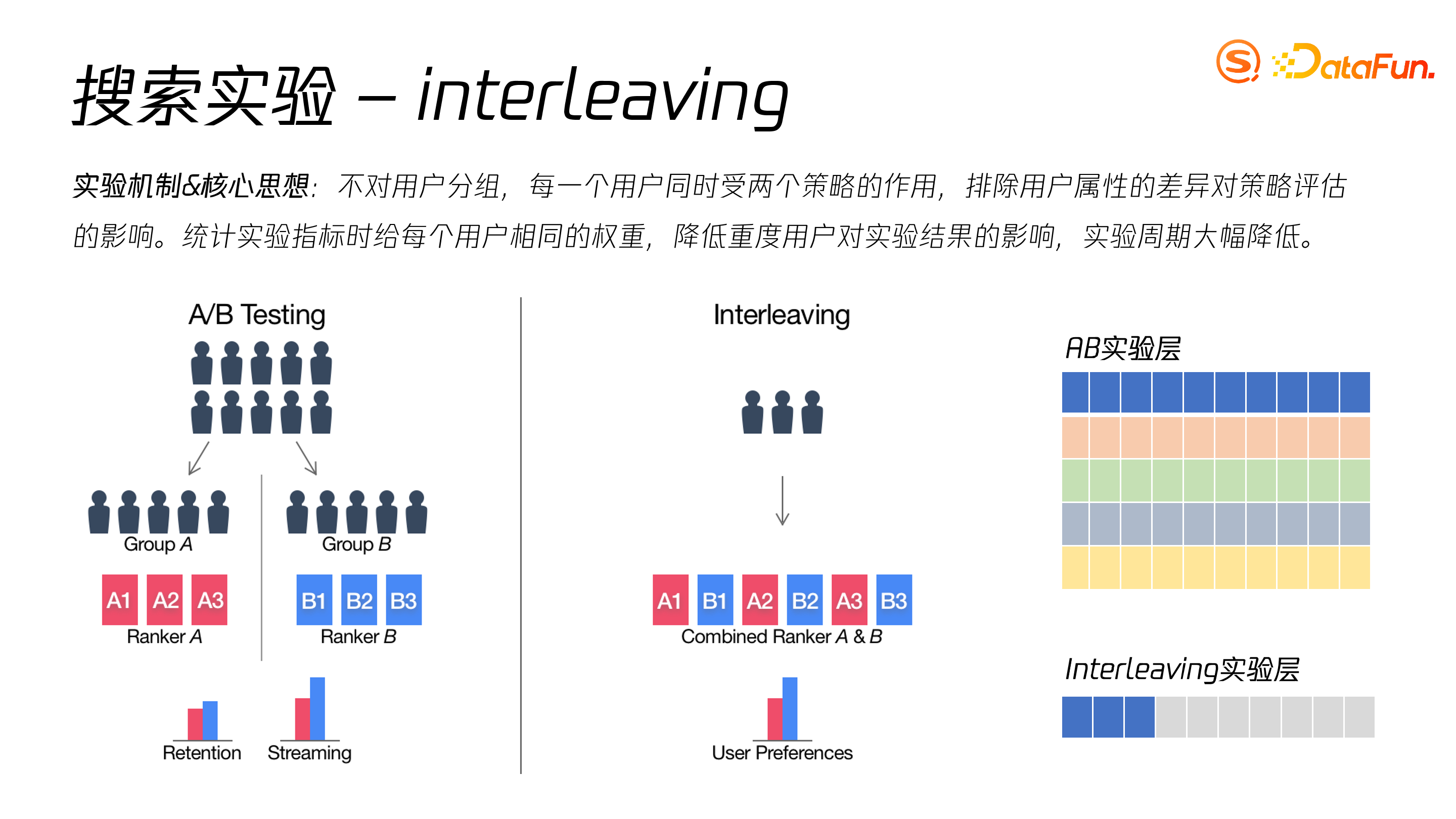
普通 AB 实验是有多层的,每层是正交的;而 interleaving 实验只有单层,在此基础上,我们加入了流量限制。
Interleaving 的核心思想在于,不对用户分组,每一个用户同时受两个策略的作用,排除用户属性的差异对策略评估的影响。统计实验指标时给每个用户相同的权重,降低重度用户对实验结果的影响,实验周期大幅降低。
目前 interleaving 主要使用两种算法:balanced interleaving 和 team-draft interleaving。
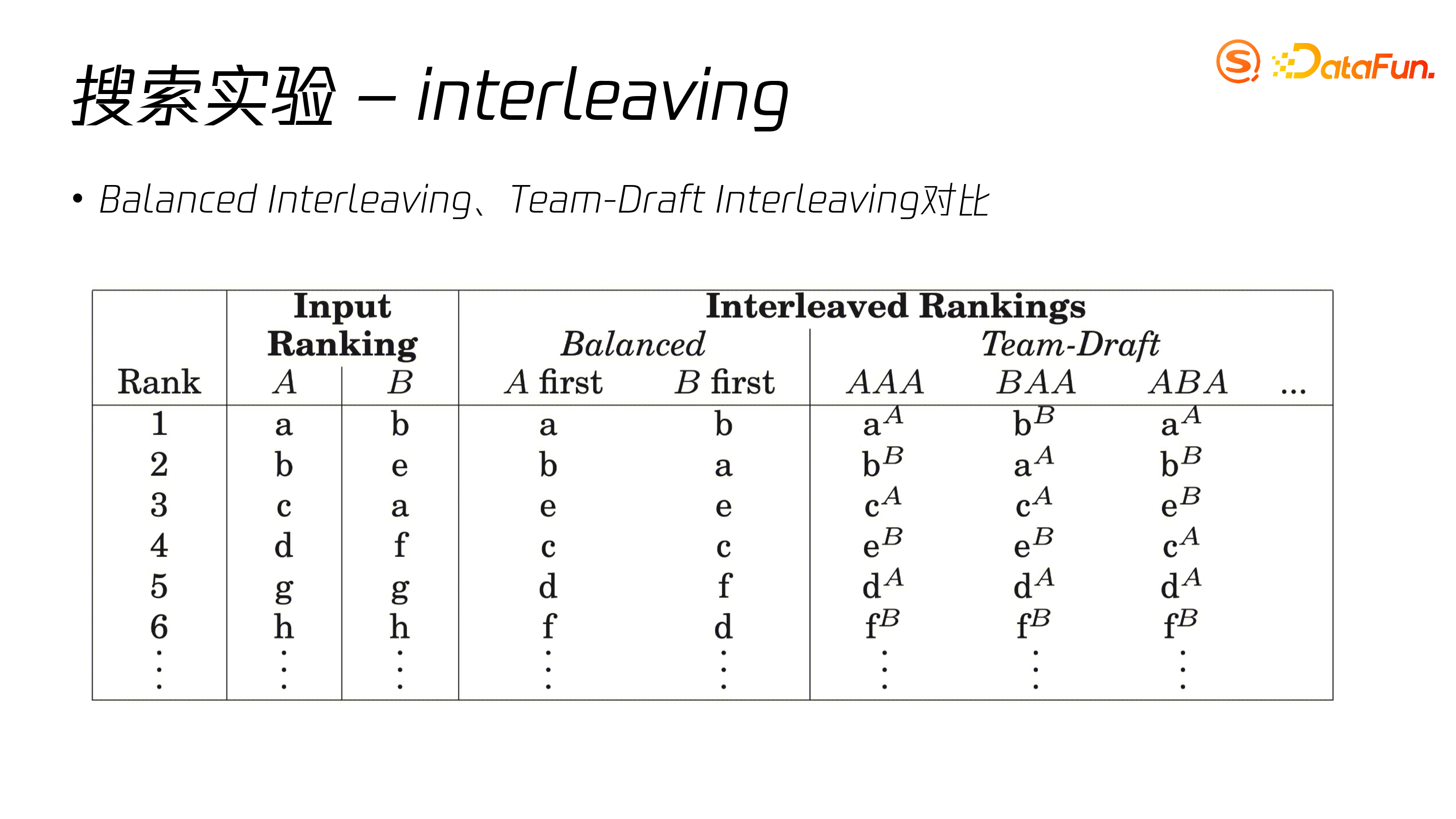
Balanced interleaving 面对两种排序策略,按照排序交替选取搜索卡组成以 A 或 B 优先搜索结果。Team-draft interleaving 则根据采样策略在 AB 两组排序中交替选取,且不存在轮空现象。

其胜出机制为,当用户点击一个结果时,哪个列表对应的位置小,则哪个得分;最终分高的列表获胜,相等则为打平,不得分。
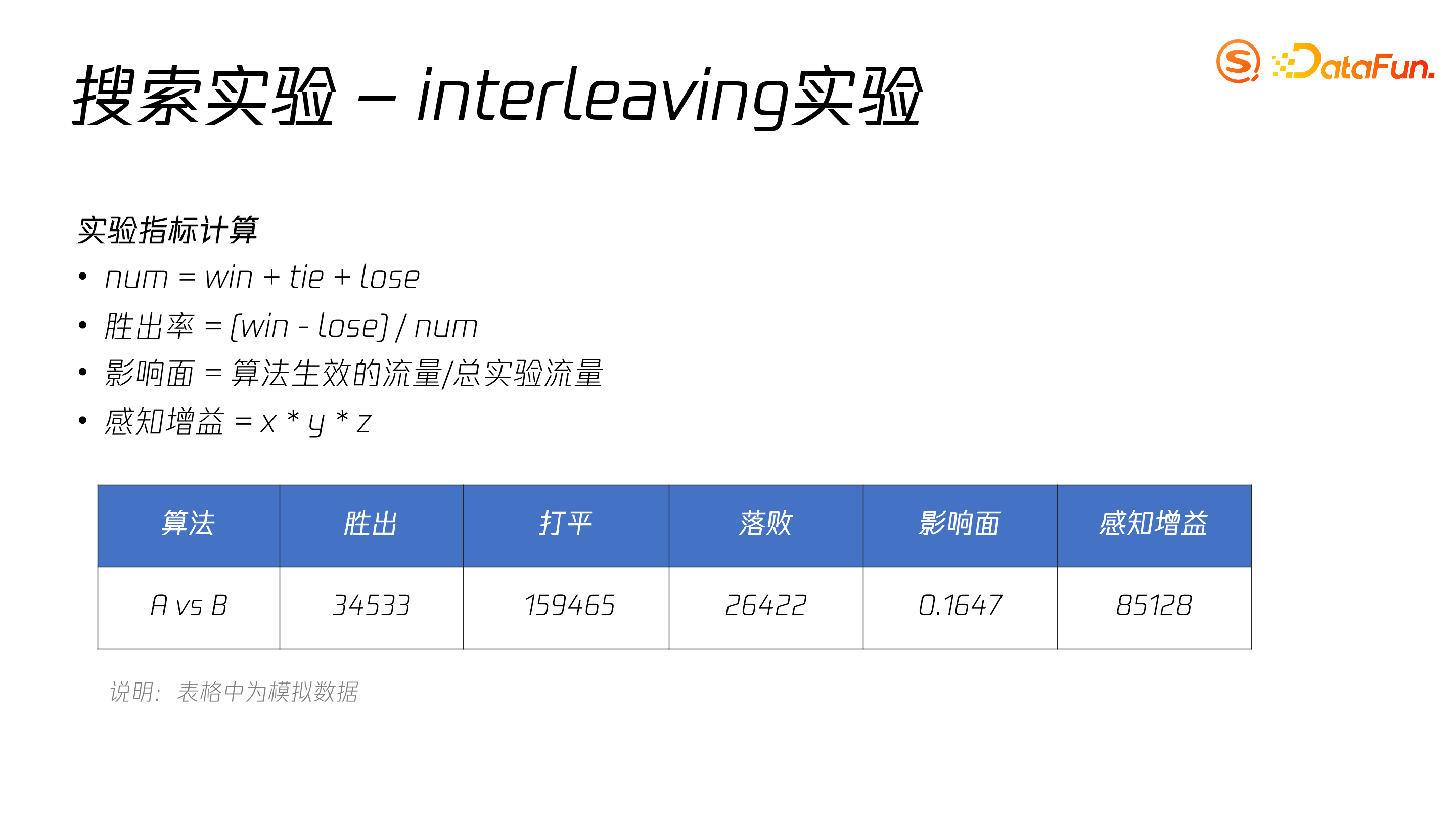
目前较常使用的实验指标包括胜出率、影响面、感知增益等。最终,如果某一指标达到阈值,则该算法胜出,可以上线。
03 搜索实验常见问题
1. 实验组卡片不生效?
搜索场景从用户发起请求到卡展示之间会经历多个环节,每个环节中间涉及到对应的缓存,若缓存没有被击穿,则卡片不会生效。另一种可能的情况是被互斥了,搜索的 query 可能有不同的意图,某些业务会在不同时间情境对不同卡排序进行调整或把别的卡互斥。另外一种可能性是卡开发的过程中存在问题,逻辑有问题不能正常召回,这时需要借助 debug 去排查问题。
2. 实验期流量不均衡?
可以观察空跑期流量是否均衡,或在实验期间进行 AA 回溯,定位流量不均衡问题是否为空跑期用户行为不均衡导致的,若空跑期不均衡,则需要重建实验。如果空跑期是均衡的,再检查实验组和对照组之间出卡率是否相同。若实验组有 5000 个词可以出卡,对照组只有 2000 个词,则两组在召回层面就存在区别从而导致流量不均衡。另外,流量不均衡也有可能是流量固化问题导致的,通常是因为实验 ID 长期不变动导致用户行为出现分化。
3. 影响面极小,难以拿到大盘收益(例如留存类指标)?
如卡片摘要信息改动等策略调整,其收益可以在卡片层面上被观测到,然而对大盘用户留存是否有影响在短期内是难以被观测到的。建议可以将多个策略打包,在贯穿层做长期反转实验观察,如果策略打包后观测到正向收益,则说明该实验有大盘级收益。
4. 如何避免实验相互影响?
词表实验中词表与卡绑定,会导致使用相同两个词表的实验之间正交意义失效,使得实验之间相互影响。因此,需要基于系统的检测功能,若卡和词表已经在系统中进行实验,则使用相同词表和卡的实验只能在同一层中进行;若 query 相同,卡也相同,则不能做实验;若卡相同,query 不同,则可以进行实验。同一层实验的流量互斥,多个实验之间不会相互影响。
5. 个别实验指标为负?
搜索实验具有多个指标,从统计学角度很难保证所有指标百分之百准确。常见做法是非核心指标一类错误低于 5% 可以接受。若核心指标出现问题,则需要重新做实验。
6. 指标多,数据弹出慢
由于指标数据来自多个部门,会导致弹出速度较慢,之前需要等到所有数据就位之后统一产出指标,个别产出较慢的数据将导致所有指标加载减缓。目前对指标进行溯源之后采取分批产出的策略。
7. 如何避免 trick?
词表实验中存在卡在某些词中表现良好,但在另外一些词表现一般,通过挑选表现良好的 query 会得到有偏的结论。因此要保证数据从平台出,避免挑选有优势的 query 跑数。同时,某些 query 影响面小,数据量级小,导致数据波动大、结论不稳定。因此需要保证 query 覆盖和量级达标,排除侥幸。
8. 大流量实验影响系统稳定性
保证实验平台接入 case 校验平台,实验运行前先校验,通过后再上线平台。
9. 影响其他业务?
建立各业务护栏指标关注及通知机制,做实验时勾选各关键指标,若指标出现问题需及时通知相关业务方。
10. 问题处理不过来?
收集问题并写入解决方案文档,引导文档查阅;公开接口人,专业人做专业事。